Проект 3: Flume собирает данные журналов в HDFS.
Введение
- Flume — это распределенная система для сбора, агрегирования и передачи больших объемов данных журналов. Он часто используется в сочетании с HDFS (распределенной файловой системой Hadoop) в экосистеме Hadoop и может хранить данные в HDFS.
- Благодаря следующей конфигурации Flume может эффективно и в режиме реального времени собирать данные журналов из локального каталога и сохранять их в HDFS для облегчения последующего анализа и обработки данных.
- Файл конфигурации Flume обычно содержит следующие части: источники (источники данных), приемники (назначение данных), каналы (каналы данных).
Начало рабочего процесса
- Сначала создайте файл конфигурации для flume для сбора данных в hdfs в каталоге /opt/module/flume/conf/job.
# Перейдите в каталог вакансий
cd /opt/module/flume/conf/job
# Редактировать файл конфигурации
vim hdfs.conf
hdfsAgent.sources = hdfsSource
hdfsAgent.sinks = hdfsSinks
hdfsAgent.channels = hdfsChannel
hdfsAgent.sources.hdfsSource.type = spooldir
hdfsAgent.sources.hdfsSource.channels = hdfsChannel
hdfsAgent.sources.hdfsSource.spoolDir = /opt/module/flume/conf/data/hdfs
hdfsAgent.sources.hdfsSource.fileHeader = true
hdfsAgent.sinks.hdfsSinks.type = hdfs
hdfsAgent.sinks.hdfsSinks.hdfs.path = hdfs://master:8020/flume/events/%y-%m-%d/%H%M/%S
hdfsAgent.sinks.hdfsSinks.hdfs.filePrefix = events
hdfsAgent.sinks.hdfsSinks.hdfs.fileSuffix = log
hdfsAgent.sinks.hdfsSinks.hdfs.round = true
hdfsAgent.sinks.hdfsSinks.hdfs.roundValue = 10
hdfsAgent.sinks.hdfsSinks.hdfs.roundUnit = minute
hdfsAgent.sinks.hdfsSinks.hdfs.minBlockReplicas = 1
hdfsAgent.sinks.hdfsSinks.hdfs.rollInterval = 0
hdfsAgent.sinks.hdfsSinks.hdfs.rollSize = 134217728
hdfsAgent.sinks.hdfsSinks.hdfs.rollCount = 0
hdfsAgent.sinks.hdfsSinks.hdfs.idleTimeout = 60
hdfsAgent.sinks.hdfsSinks.hdfs.fileType = DataStream
hdfsAgent.sinks.hdfsSinks.hdfs.useLocalTimeStamp = true
hdfsAgent.channels.hdfsChannel.type = memory
hdfsAgent.channels.hdfsChannel.capacity = 1000
hdfsAgent.channels.hdfsChannel.transactionCapacity = 100
hdfsAgent.sources.hdfsSource.channels = hdfsChannel
hdfsAgent.sinks.hdfsSinks.channel = hdfsChannelПодробное объяснение параметров файла конфигурации
- Источники
hdfsAgent.sources = hdfsSource
Здесь файл с именем hdfsSource источник данных.
hdfsAgent.sources.hdfsSource.type = spooldir
Тип источника данных: каталог спулинга, значит Flume Будет прослушивать и собирать файлы из указанного каталога.
hdfsAgent.sources.hdfsSource.channels = hdfsChannel
Этот источник данных будет использовать файл с именем hdfsChannel канал для передачи данных.
hdfsAgent.sources.hdfsSource.spoolDir = /opt/module/flume/conf/data/hdfs
Это Flume Путь к каталогу для мониторинга. Он будет проверять наличие новых файлов в этом каталоге.
hdfsAgent.sources.hdfsSource.fileHeader = true
это означает Flume Информация заголовка файла будет включена в собранные файлы, обычно используемые для записи метаданных.- Куда идут данные (приемники)
hdfsAgent.sinks = hdfsSinks
Здесь файл с именем hdfsSinks куда идут данные.
hdfsAgent.sinks.hdfsSinks.type = hdfs
Тип назначения данных: HDFS, что указывает на то, что данные будут записаны в HDFS середина.
hdfsAgent.sinks.hdfsSinks.hdfs.path = hdfs://master:8020/flume/events/%y-%m-%d/%H%M/%S
Эти данные хранятся в HDFS Формат пути в формате , включая дату и время. лоток Каталог будет автоматически создан по этому пути в зависимости от времени сбора.
hdfsAgent.sinks.hdfsSinks.hdfs.filePrefix = events
Префикс выходного файла: “events”。
hdfsAgent.sinks.hdfsSinks.hdfs.fileSuffix = log
Суффикс выходного файла: “.log”。
hdfsAgent.sinks.hdfsSinks.hdfs.round = true
Указывает, что механизм прокрутки включен и файлы разделены по времени.
hdfsAgent.sinks.hdfsSinks.hdfs.roundValue = 10
Прокрутка данных срабатывает каждые 10 минут.
hdfsAgent.sinks.hdfsSinks.hdfs.roundUnit = minute
Указанная здесь единица времени — минуты.
hdfsAgent.sinks.hdfsSinks.hdfs.minBlockReplicas = 1
Минимальное количество копий 1, означает письмо HDFS Будет копия данных.
hdfsAgent.sinks.hdfsSinks.hdfs.rollInterval = 0
Установка значения 0 означает, что прокрутка не будет принудительной в зависимости от времени, в основном через round Механизм прокрутки файлов.
hdfsAgent.sinks.hdfsSinks.hdfs.rollSize = 134217728
Размер файла достигает 128MB будет прокручиваться.
hdfsAgent.sinks.hdfsSinks.hdfs.rollCount = 0
Установка значения 0 означает прокрутку без ограничения количества записей.
hdfsAgent.sinks.hdfsSinks.hdfs.idleTimeout = 60
Если данные не поступают, файл будет закрыт через 60 секунд.
hdfsAgent.sinks.hdfsSinks.hdfs.fileType = DataStream
Этот параметр указывает, что тип файла является потоком, а это означает, что данные будут записываться в виде потока.
hdfsAgent.sinks.hdfsSinks.hdfs.useLocalTimeStamp = true
Включите локальную временную метку в качестве временной метки файла.- Каналы передачи данных
hdfsAgent.channels.hdfsChannel.type = memory
Тип канала — канал памяти, что означает, что данные передаются в памяти.
hdfsAgent.channels.hdfsChannel.capacity = 1000
Канал памяти может хранить до 1000 событий.
hdfsAgent.channels.hdfsChannel.transactionCapacity = 100
В каждой транзакции может быть обработано не более 100 событий.Создание связанных каталогов
# Создайте каталог /flume/events на hdfs.
hadoop fs -mkdir -p /flume/events
# Добавить разрешения
hadoop fs -chmod 777 -R /flume/*
# Создать путь к файлу журнала
mkdir -p /opt/module/flume/conf/data/hdfsСкрипт создания журнала моделирования
- Функция этого сценария — создать смоделированный файл журнала и поместить его в указанный каталог для тестирования или сбора данных.
- Создайте каталог для хранения файлов журналов.
- Создает 5 смоделированных файлов журнала, каждый из которых содержит запись журнала с отметкой времени.
- Каждый файл журнала создается с интервалом в 1 секунду для имитации фактического процесса создания журнала.
# Создайте каталог для хранения скрипта
mkdir -p /opt/module/flume/job-shell
# Переключиться в этот каталог
/opt/module/flume/job-shell
# Редактировать сценарий
vim logData_To_Hdfs
#!/bin/bash
# Установить путь сохранения
SPOOL_DIR="/opt/module/flume/conf/data/hdfs"
# создавать spoolDir путь (если его нет)
mkdir -p "${SPOOL_DIR}"
# генерировать 5 случайные файлы журналов
for i in {1..5}; do
LOG_FILE="${SPOOL_DIR}/logfile_${i}.log"
echo "INFO: This is a simulated log entry $(date '+%Y-%m-%d %H:%M:%S')" > "${LOG_FILE
echo "Generated ${LOG_FILE}"
sleep 1 # Аналоговое сокращение интервалов
done
# Добавить разрешения
chmod 777 ./*скрипт запуска Flume
- Этот сценарий удобно запускает задачи Flume без ручного ввода всех команд. Он также гарантирует, что процесс Flume продолжает работать в фоновом режиме, что делает его пригодным для использования в производственных средах.
cd /opt/module/flume/job-shell
vim hdfs
#!/bin/bash
echo " --------запускать master Соберите данные журнала дляHDFS --------"
nohup /opt/module/flume/bin/flume-ng agent -n hdfsAgent -c /opt/module/flume/conf/ -f /opt/module/flume/conf/job/hdfs.conf >/dev/null 2>&1 &
# Добавить разрешения
chmod 777 ./*Начать процесс
# Сначала запустите все процессы Hadoop
allstart.sh
# Переключиться на путь запуска скрипта
cd /opt/module/flume/job-shell
# Запустите скрипт сбора лотковhdfs
# Запустить скрипт создания файла журнала
logData_To_Hdfs- Запустите скрипт сбора лотков

- Запустить скрипт создания файла журнала
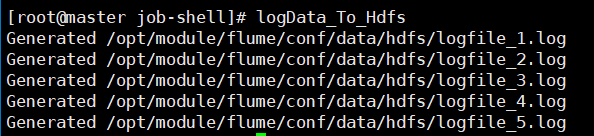
- Просмотр содержимого одного из файлов журнала

Результаты испытаний
- Команда просмотра результатов сбора файлов
hadoop fs -ls -R /flume
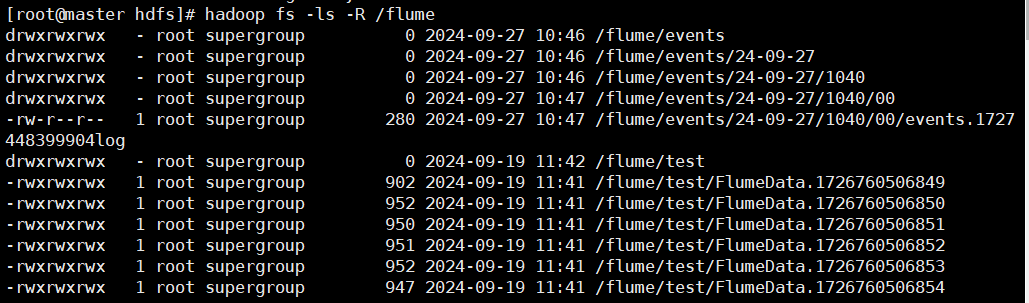
- Результаты просмотра файловой системы



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
