Проблема миллионов одновременных подключений: углубленный анализ тестирования высокой параллелизма wrk
В настоящее время тестирование производительности стало ключевым звеном в обеспечении качества программного обеспечения. Среди них wrk, легкий и высокопроизводительный инструмент тестирования производительности HTTP, известный своим простым интерфейсом командной строки и отличной производительностью. wrk может моделировать высококонкурентные сетевые запросы с помощью параметра -c, чтобы помочь нам оценить производительность сервера при экстремальной нагрузке. Если вы планируете проводить тесты порядка C10K для десятков тысяч одновременных подключений, подойдет wrk (по сравнению с такими инструментами, как ab/jmeter). Однако если вы хотите попытаться провести тесты с высоким параллелизмом в масштабе миллионов). , официальная работа ничего сделать не может.
Прежде всего, wrk не поддерживает пользовательские исходные IP-адреса, что особенно неудобно, когда вам нужно имитировать запросы от разных клиентов. Количество TCP-соединений не может увеличиваться при одновременном тестировании (на данный момент, когда вы проверяете команду Curl). , вы увидите что-то вроде «Невозможно назначить ошибку адреса запроса»). Во-вторых, память, предварительно выделяемая wrk для каждого соединения, относительно велика. Это приведет к быстрому исчерпанию ресурсов памяти при попытке установить большое количество соединений на одной машине. Процесс wrk будет завершен ядром. OOM (если вдруг пропадает процесс wrk, обычно можно увидеть логи вида Out of Memory в /var/log/messages). Эти ограничения, несомненно, являются большим препятствием для разработчиков, которым необходимо оценивать высокопроизводительные сервисы.
В следующем материале я расскажу, как решить вышеуказанные проблемы путем изменения исходного кода wrk, чтобы помочь читателям лучше использовать wrk для тестирования экстремального параллелизма.
проблемы тестирования WRK и высокого параллелизма
В практике разработки программного обеспечения тестирование производительности является основным звеном, обеспечивающим соответствие производительности приложений стандартам. Например, тестирование производительности позволит оценить максимальную вычислительную мощность системы; стресс-тестирование оценит поведение системы при высокой нагрузке; тестирование узких мест выявит ограничения системы, которые могут повлиять на производительность при высокой нагрузке. В этой статье в основном основное внимание уделяется тесту одновременного подключения/сессии в тесте емкости, то есть тому, как добиться заранее определенного количества одновременных подключений, и не рассматриваются такие показатели, как одновременная пропускная способность и количество новых подключений в секунду.
Основное преимущество wrk заключается в его легкости и высокой производительности. Благодаря асинхронной архитектуре языка C + epoll, он может генерировать большое количество HTTP-запросов за короткое время для проверки времени ответа и пропускной способности целевого сервера. . Философия дизайна wrk — прежде всего простота. Он предоставляет краткий интерфейс командной строки. Пользователи могут быстро запустить тест с помощью параметра -c, чтобы указать количество одновременных потоков, -d, чтобы указать продолжительность запроса, -t, чтобы указать количество. количество используемых потоков и т. д. Незаконные сертификаты автоматически игнорируются при тестировании SSL (что эквивалентно добавлению параметра -k в команду Curl).
При проведении параллельного тестирования C10M существует неизбежное ограничение: цель тестирования обычно ориентирована на один бизнес, а это означает, что VIP (виртуальный IP-адрес) и порт, отслеживаемые бизнесом, фиксированы. В пяти кортежах TCP-соединения (включая IP-адрес источника, порт источника, IP-адрес назначения, порт назначения и тип протокола, как показано на рисунке ниже), тип протокола, IP-адрес назначения и порт были определены в целях бизнеса. требования, что ограничивает нас поиском возможности установления нескольких соединений по исходному IP и исходному порту. Сеансы UDP также сталкиваются с той же проблемой.
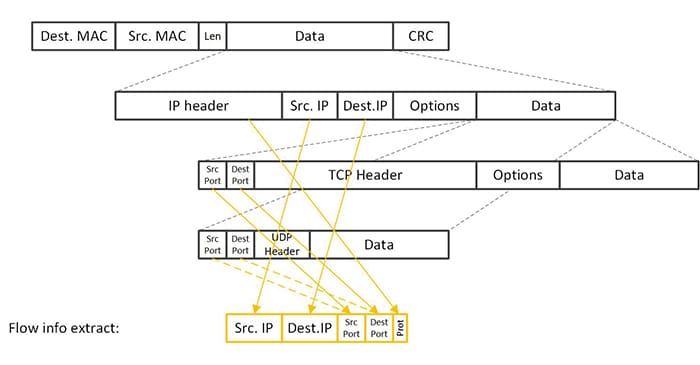
Даже если мы создадим множество доступных IP-адресов с помощью команды ip или nmcli, мы сможем использовать только IP-адрес хоста по умолчанию при доступе к IP-адресу назначения в качестве исходного IP-адреса во время теста работы. Поскольку исходный IP-адрес не настраивается и его число может быть только 1, мы можем полагаться только на разнообразие исходных портов для достижения одновременных подключений. Однако номер порта представляет собой короткую переменную длиной 2 байта с ограниченным диапазоном значений. Даже если мы ослабим ограничения диапазона портов операционной системы (net.ipv4.ip_local_port_range можно настроить через sysctl в Linux), количество портов будет равно. только оно может достигать более 60 000, что далеко от удовлетворения потребностей миллионов одновременных подключений.
Чтобы решить эту проблему, мы рассмотрим, как расширить функции wrk и добиться крупномасштабного параллельного тестирования путем изменения официального исходного кода wrk.
анализ исходного кода wrk: снять ограничения на исходный адрес по умолчанию
работа не была написана для уровня testC10M одновременно,Но его гены на самом деле поддерживают это. Сначала нам нужно найти код, который wrk ограничивает исходный адрес.,То естьwrkИнициировать на сервереTCPсоединятьфрагмент исходного кода–src/wrk.cв файлеconnect_socketфункция:
static int connect_socket(thread *thread, connection *c) {
struct addrinfo *addr = thread->addr;
struct aeEventLoop *loop = thread->loop;
int fd, flags;
fd = socket(addr->ai_family, addr->ai_socktype, addr->ai_protocol);
if (connect(fd, addr->ai_addr, addr->ai_addrlen) == -1) {
if (errno != EINPROGRESS) goto error;
}
...
}Видно, что эта функция использует структуру addrinfo в структуре потока для определения информации об адресе целевого сервера, а исходный IP-адрес автоматически выбирается системой. Если вам необходимо настроить адрес источника для имитации запросов с определенного IP-адреса, вы можете использовать функцию привязки для привязки дескриптора файла (fd) к указанному адресу источника перед вызовом функции подключения. Таким образом, вы можете контролировать, с какого локального IP-адреса и порта инициируется соединение, чтобы удовлетворить ваши конкретные потребности в тестировании.
Конечно, вам не нужно указывать исходный порт при параллельном тестировании, поэтому, указав sin_port как 0, можно продолжать использовать порт, назначенный операционной системой.
Кроме того, какие IP-адреса необходимо указать в качестве исходного адреса, необходимо провести подготовку до начала работы. После получения этих адресов в основной функции и последующего использования их в функции connect_socket можно указать исходный адрес. Таким образом, мы обходим пятикратное ограничение TCP при тестировании с высоким уровнем параллелизма!
Уменьшите потребление памяти на одно соединение
Чтобы wrk мог достичь одновременных подключений на уровне C10M на одном компьютере, необходимо решить еще одну проблему: как избежать проблемы нехватки памяти? Эта проблема эквивалентна тому, как заставить каждое тестовое соединение использовать как можно меньше памяти.
Прежде чем углубляться в то, как уменьшить объем памяти, потребляемой TCP-соединениями, мы должны сначала понять характеристики потребления памяти протоколами TCP и HTTP. wrk, как профессиональный инструмент тестирования производительности HTTP, реализует свою эффективную производительность на основе способа обработки потоковых сообщений TCP. wrk кэширует потоковые сообщения TCP в памяти через сокеты и системные API и поддерживает сообщения HTTP только посредством ссылок на указатели, тем самым значительно уменьшая объем памяти в процессе пользовательского режима.
Однако, хотя wrk эффективно управляет памятью в процессах пользовательского режима, стеки протоколов TCP и IP реализуются ядром операционной системы, а это означает, что ядру также необходимо выделять ресурсы памяти для каждого TCP-соединения. Выделение памяти ядром в основном используется для поддержания состояния соединения, управления буфером и других необходимых сетевых операций. Эти ресурсы памяти имеют решающее значение для поддержания стабильности и производительности TCP-соединений.
Чтобы уменьшить потребление памяти каждого соединения, нам нужно рассматривать его с двух уровней:
- Память оптимизации в пользовательском режиме: в работе,Найдите код для кэширования, отправки и получения сообщений,Уменьшите его размер на основе конкретных сценариев тестирования.,Или используйте более эффективную структуру данных, чтобы уменьшить выделение Память.
- Управление состоянием ядра «Память». Для TCP-соединения использования «Память» в ядре операционной системы вы можете оптимизировать использование «Память», настроив параметры ядра, такие как настройка размера TCP-буфера, оптимизация стратегии выделения «Память» TCP и т. д.
О настройке состояния ядра Память,Вы можете посмотреть мою серию статей «Высокопроизводительное сетевое программирование».,Всего семь статей.,Нет.7Поговорим о ключевых моментах Память Корректирование:«Высокопроизводительное сетевое программирование с использованием 7-памяти TCP-соединений»
Далее мы сосредоточимся на том, как wrk выделяет память для TCP-соединений.
анализ исходного кода wrk: выделение памяти для каждого соединения
Когда мы указываем количество одновременносоединять через -c,wrk.cв файлеparse_argsфункция Параметры будут сохранены вcfg->connectionsсередина:
static struct config {
uint64_t threads;
uint64_t connections;
...
} cfg;
static int parse_args(struct config *cfg, char **url, struct http_parser_url *parts, char **headers, int argc, char **argv) {
...
while ((c = getopt_long(argc, argv, "a:t:c:d:s:H:T:R:LUBrv?", longopts, NULL)) != -1) {
switch (c) {
case 't':
if (scan_metric(optarg, &cfg->threads)) return -1;
break;
case 'c':
if (scan_metric(optarg, &cfg->connections)) return -1;
break;
}
}
...
}Прежде чем функция main начнет тест wrk, количество выделяемых соединений будет рассчитано для каждого тестового потока на основе количества потоков, указанного в -t:
int main(int argc, char **argv) {
...
uint64_t connections = cfg.connections / cfg.threads;
}Затем в функции thread_main, запускаемой каждым потоком, предварительно выделите память, которую может использовать каждое соединение:
void *thread_main(void *arg) {
thread *thread = arg;
aeEventLoop *loop = thread->loop;
thread->cs = zcalloc(thread->connections * sizeof(connection));
...
}ДалееКлючевая часть:каждыйсоединятьпотребляется Память Предварительно выделено какsizeof(connection)размер,Насколько это велико??Давайте продолжим видетьwrk.hв файлеconnectionСтруктура:
#define RECVBUF 8192
typedef struct connection {
thread *thread;
http_parser parser;
enum {
FIELD, VALUE
} state;
int fd;
SSL *ssl;
double throughput;
double catch_up_throughput;
uint64_t complete;
uint64_t complete_at_last_batch_start;
uint64_t catch_up_start_time;
uint64_t complete_at_catch_up_start;
uint64_t thread_start;
uint64_t start;
char *request;
size_t length;
size_t written;
uint64_t pending;
buffer headers;
buffer body;
char buf[RECVBUF];
uint64_t actual_latency_start;
bool has_pending;
bool caught_up;
// Internal tracking numbers (used purely for debugging):
uint64_t latest_should_send_time;
uint64_t latest_expected_start;
uint64_t latest_connect;
uint64_t latest_write;
} connection;Видно, что wrk сохраняет только одну копию содержимого HTTP-запроса, который инициирует тест глобально, который используется всеми соединениями (см. член char *request), а сообщения, полученные каждым соединением, хранятся в 8 КБ памяти. (wrk необходимо проанализировать результаты HTTP-ответа)! Другими словами, за исключением массива buf, структура соединения почти не потребляет памяти (http_parser поддерживает только некоторые необходимые состояния).
Уменьшив размер массива buf (изменив значение макроса RECVBUF), мы можем уменьшить объем памяти, необходимый для каждого соединения. Этот метод прост и удобен в реализации, поскольку он напрямую уменьшает объем памяти, выделяемый в процессе пользовательского режима для каждого соединения. Это не только помогает снизить общее потребление памяти, но и позволяет устанавливать больше соединений с ограниченными ресурсами памяти, тем самым увеличивая количество одновременных подключений.
Конечно, такой подход требует тщательного рассмотрения потребностей тестового сценария. Если буфер установлен слишком маленьким, в некоторых случаях он может не соответствовать потребностям приема данных, что влияет на точность теста. Следовательно, для правильного определения размера буфера необходимо найти баланс между потреблением памяти и потребностями тестирования.
Конечно, вы также можете разработать более гибкие стратегии управления памятью для дальнейшей оптимизации использования памяти. Например, можно реализовать стратегии динамического выделения памяти, общие буферы, отложенное выделение и т. д. Эти методы могут еще больше повысить эффективность использования памяти при сохранении точности тестирования.
краткое содержание
Соответствующим образом изменив официальный исходный код wrk, мы можем эффективно сократить потребление памяти каждым TCP-соединением, тем самым избегая проблем с переполнением памяти, и в то же время расширить верхний предел TCP-соединений, указав несколько исходных адресов. Эти изменения в сочетании с оптимизацией памяти TCP-соединений ядра системы Linux позволяют тесту работы на одной машине достичь уровня C10M, что представляет собой тест производительности на уровне миллиона параллелизма. Это обеспечивает эффективное средство оценки параллельного выполнения высокопроизводительных систем. при экстремальных нагрузках.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
