Принципы проектирования архитектуры Elasticsearch и антишаблоны: проектирование для масштабируемости
Предыстория
С непрерывным развитием современных предприятий объем данных резко увеличился, и масштабируемость системы стала решающим вопросом. Будучи мощной распределенной системой поиска и анализа, Elasticsearch продемонстрировал свои выдающиеся возможности в обработке крупномасштабных данных. Однако спроектировать эффективный и масштабируемый кластер Elasticsearch непросто. Цель этой статьи — помочь пользователям лучше создавать и оптимизировать свои кластеры Elasticsearch, поделившись некоторыми принципами проектирования масштабируемости и общими антишаблонами.
руководство по чтению
В процессе нашего сотрудничества с клиентами мы обнаружили, что многие пользователи разрабатывают и внедряют Elasticsearch кластер, мы часто встречаем Узкое место в проблемы производительности и масштабируемости. Эта статья Подвести Итог Причины этих проблем,И предоставить некоторые практические решения и предложения по оптимизации.,Направлен на существование, чтобы помочь пользователям избежать распространенных ошибок.,Улучшение производительности и стабильности кластера.
Прочитав эту статью, читатели узнают:
- как Спроектируйте эффективный кластер Elasticsearch。
- Распространенные антишаблоны масштабируемости и их решения.
- Анализ фактического случае, чтобы помочь понять теоретические приложения.
Спроектируйте эффективный кластер Elasticsearch
когда мы используем Elasticsearch На данный момент оно обычно оценивается исходя из текущего масштаба и нагрузки бизнеса. Но поскольку масштабы бизнеса продолжают расти и количество посещающих пользователей увеличивается, нам необходимо выполнить две основные операции над исходным кластером: обновление и расширение. Оба индивидуальных аспекта важны для расширения, Принцип масштабируемости является важнейшим ориентиром. Каждый принцип подробно описан ниже:,Помогите пользователям более полно понять и применить эти принципы.
принцип масштабируемости
в дизайне Elasticsearch кластер, вам нужно следовать некоторым основным принципам масштабируемости:
- Рабочие нагрузки данных:В соответствии с различными рабочими нагрузками данных(нравиться Ingest、Search и Store) настроить соответствующие узлы и ресурсы. высокий CPU и I/O Узел подходит для сценариев с высокой скоростью записи событий.,Большой объем памяти и быстрые узлы хранения для запросов с низкой задержкой,Узлы хранения высокой плотности подходят для долгосрочного хранения данных.
- Изоляция рабочей нагрузки:Изолируя различные типы рабочих нагрузок,Это может упростить процесс масштабирования и улучшить использование ресурсов.
- Стратегия осколков:Определите подходящее количество осколков длякластер Надежность。Шардинг – это Работа Основная единица разделения нагрузки. Чем более похожи шарды, тем легче добиться балансировки нагрузки.
На следующем рисунке показана типичная архитектура кластера Elasticsearch, которая делит данные на «горячие», «теплые» и «холодные» данные в зависимости от «теплоты» данных и использует разные роли узлов для обработки различных рабочих нагрузок данных:
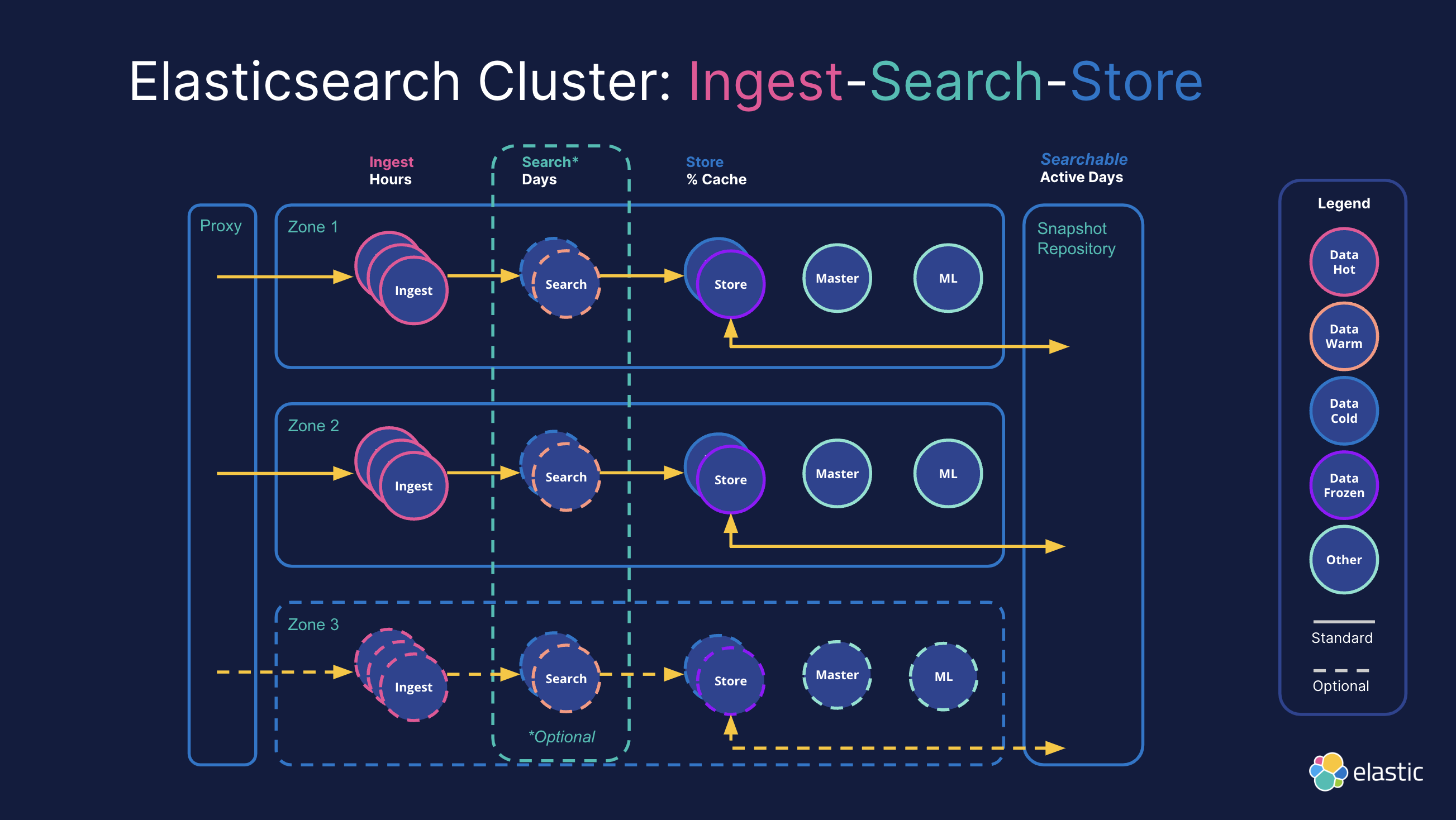
Рабочие нагрузки данных
в дизайнеи Конфигурация Elasticsearch При кластеризации очень важно понимать и обрабатывать различные рабочие нагрузки по данным. Каждая рабочая нагрузка имеет разные требования к ресурсам, что требует соответствующей корректировки конфигурации узла и распределения ресурсов.
Кластеры Elasticsearch обычно обрабатывают три основные рабочие нагрузки данных: прием, поиск и сохранение. Каждая рабочая нагрузка имеет разные требования к ресурсам, поэтому узлы и ресурсы необходимо настроить соответствующим образом.

Мы можем классифицировать и обрабатывать рабочие нагрузки по трем основным измерениям: вычисления, память и хранилище.
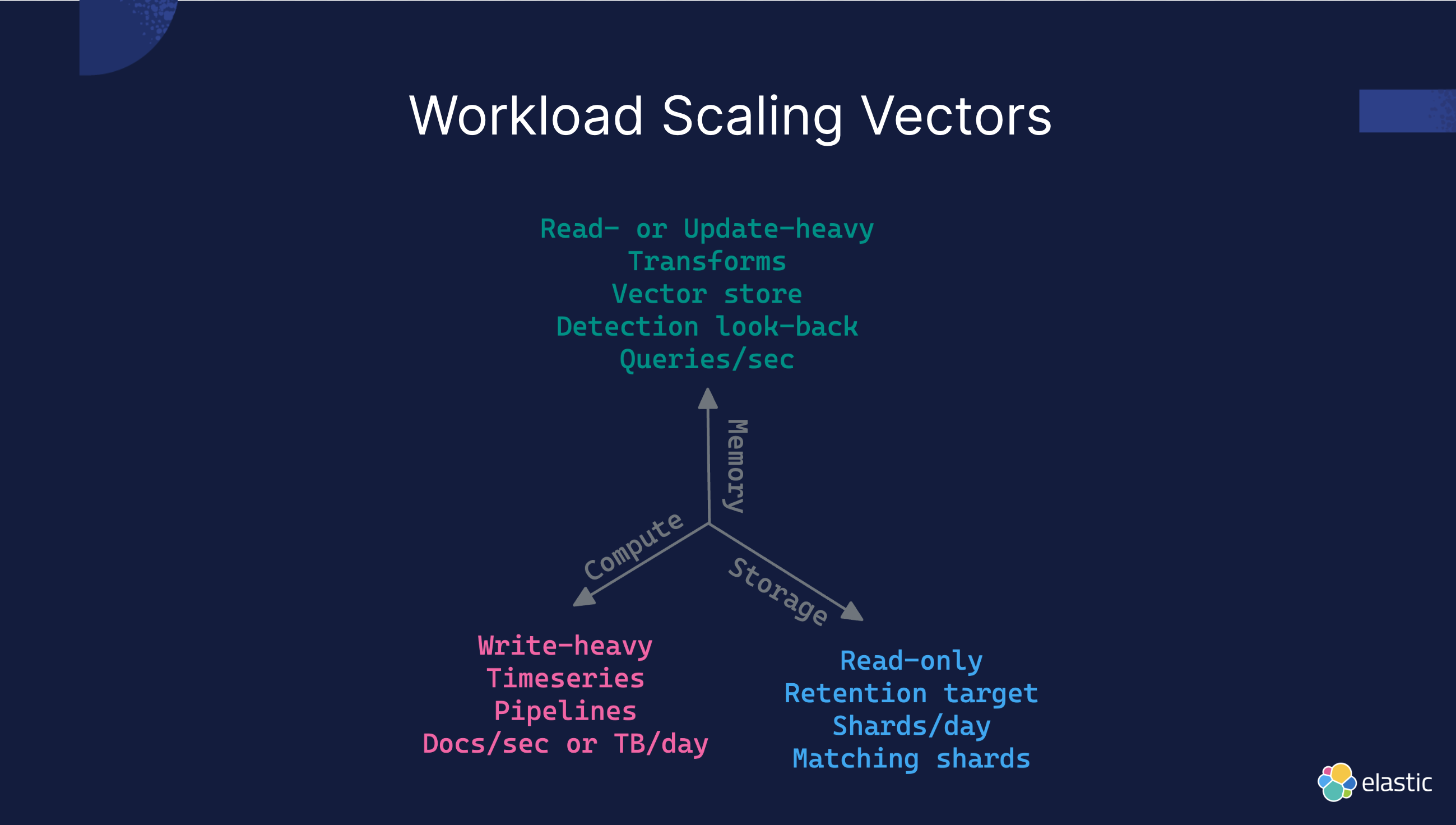
Рабочие нагрузки с большим объемом записи
Рабочие нагрузки, требующие интенсивной записи, обычно включают в себя большие объемы операций записи данных, таких как данные временных рядов, данные журналов, и часто требуют обработки ETL (конвейеры). Эти рабочие нагрузки характеризуются обработкой больших объемов документов в секунду (Документов в секунду) или больших объемов данных в день (ТБ/день). Для этого типа рабочей нагрузки особенно важна конфигурация вычислительных ресурсов (Compute) и ресурсов хранения (Storage):
- Вычислительные ресурсы:писать интенсивно Работа Нагрузки требуют высокой производительности CPU Для обработки больших объемов операций записи и индексирования данных. Настройка узлов с мощными возможностями обработки может значительно улучшить производительность записи.
- Ресурсы хранения:высокий效из存储设备对于писать интенсивно Работа Нагрузка критическая。использовать NVMe SSD Высокопроизводительные устройства хранения, такие как высокопроизводительные устройства хранения, могут увеличить скорость записи и извлечения данных, а также уменьшить задержки.
Чтение или обновление тяжелых рабочих нагрузок
Рабочие нагрузки, требующие интенсивного чтения или обновления, включают частые операции чтения и обновления данных, такие как запросы в реальном времени, векторное хранилище, обратный просмотр обнаружения и т. д. Этот тип рабочей нагрузки требует больших объемов ресурсов памяти для поддержки высокочастотных запросов и обновлений данных:
- ресурсы памяти:Для частого чтенияиоперация обновления,Конфигурация с большим объемом памяти имеет важное значение. Достаточный объем памяти позволяет кэшировать больше данных,Улучшить скорость ответа на запрос,Уменьшите задержку запроса.
- Вычислительные ресурсы:Хотя операции чтения обычно Вычислительные Потребность в ресурсах не так высока, как в операциях записи, но выполнение сложных операций запроса и обновления по-прежнему требует мощной вычислительной мощности.
Рабочие нагрузки только для чтения
Рабочие нагрузки только для чтения в основном включают долговременное хранение и извлечение данных, например архивирование данных, моментальные снимки и запросы исторических данных. Этот тип рабочей нагрузки характеризуется низкой частотой записи данных, но требует эффективного извлечения больших объемов исторических данных:
- Ресурсы хранения:только чтение Работапара нагрузки Ресурсы хранение пользуется наибольшим спросом. Чтобы обеспечить доступность данных, используйте устройства хранения высокой плотности, такие как HDD) может обеспечить достаточную емкость хранения и снизить затраты.
- ресурсы памяти:尽管только чтение Работа Нагрузка в основном зависит от Ресурсы хранения,Но правильная конфигурация памяти все равно может помочь повысить скорость извлечения данных.,Особенно при составлении сложных запросов.
Изоляция рабочей нагрузки
Изоляция рабочей нагрузки — это улучшение Elasticsearch кластер Важная стратегия масштабируемости и использования ресурсов. Разделив различные типы рабочих нагрузок, мы можем более эффективно управлять ресурсами и избегать конфликтов за ресурсы. место в производительности。существовать Изоляция рабочей нагрузкисередина,Есть трииндивидуальныйосновные стратегии:Чанк、Группаи Распространение。
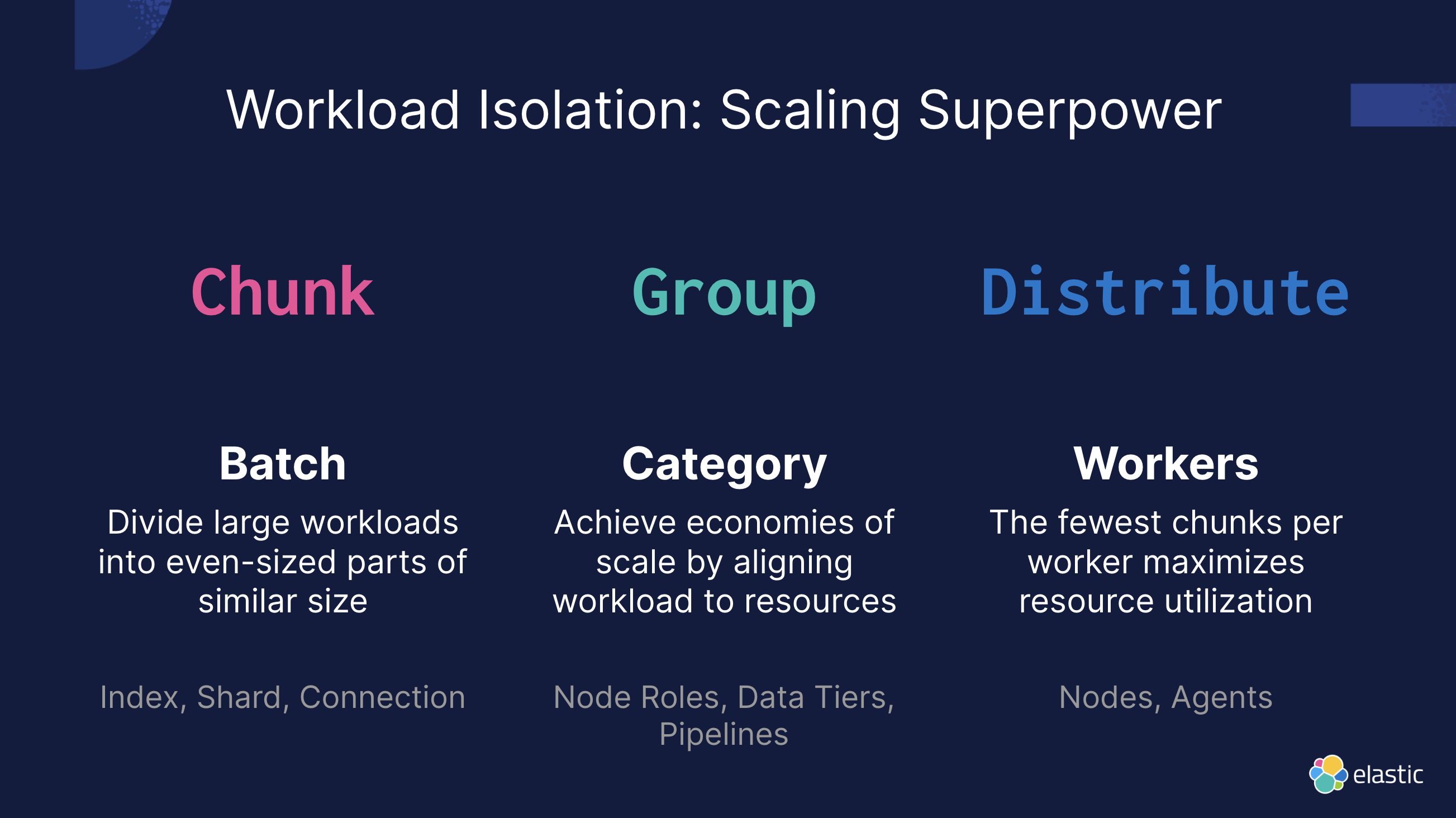
Чанк
Суть стратегии разделения на блоки заключается в разделении больших рабочих нагрузок на части одинакового размера, гарантируя, что рабочая нагрузка каждой части сбалансирована. Такой подход помогает добиться более равномерного распределения нагрузки по кластеру и улучшает использование ресурсов. В частности, мы можем разделить индексы, сегменты, соединения и т. д. на несколько частей одинакового размера, чтобы облегчить параллельную обработку.
Пример: допустим, у нас есть очень большой поток данных журнала, обрабатывающий миллиарды записей журнала каждый день. Разделив этот поток данных на несколько сегментов и сохранив одинаковый размер объема данных в каждом сегменте, можно распределить нагрузку на запись и запросы более равномерно и избежать перегрузки одного сегмента.
Группа
Стратегии группировки позволяют добиться эффекта масштаба за счет группировки рабочих нагрузок по категориям и их сопоставления с ресурсами. Конкретный метод заключается в кластеризации схожих рабочих нагрузок на основе ролей узлов, слоев данных, конвейеров и т. д. Такой подход может сократить растрату ресурсов и повысить общую эффективность кластера.
Пример. В системе мониторинга безопасности мы можем разделить задачи обнаружения в реальном времени и задачи хранения исторических данных и обрабатывать их соответственно выделенными узлами. Задачи обнаружения в реальном времени требуют быстрого реагирования и могут выделять больше ресурсов ЦП и памяти, в то время как задачи хранения исторических данных в основном полагаются на ресурсы хранения и могут выделять узлы хранения с высокой плотностью.
Распространение
Цель стратегии распределения — максимальное использование ресурсов каждой единицы работы с минимальным количеством шардов. Правильно распределяя узлы и агенты, мы можем гарантировать, что нагрузка каждой рабочей единицы будет максимально сбалансирована, тем самым повышая эффективность обработки всей системы.
Пример. При обработке крупномасштабных поисковых запросов мы можем распределить поисковые запросы по нескольким поисковым узлам, узнать верхний предел обработки каждой единицы посредством сравнительного тестирования и рассчитать запросы, которые необходимо распределить по каждому узлу. Таким образом, вы сможете избежать перегрузки одного узла и повысить общую производительность поиска.
Стратегия осколков
Шардинг — это основная единица разделения и балансировки рабочих нагрузок в Elasticsearch. Для обеспечения эффективной работы и балансировки нагрузки кластера решающее значение имеет разработка стратегии шардинга. Ниже приводится подробное руководство по разработке стратегии сегментирования:
Шардинг и балансировка
В Elasticsearch шардинг — это не только основная единица работы подразделения, но и ключ к достижению балансировки нагрузки. Чем более похожи сегменты, тем легче добиться балансировки нагрузки. Это означает, что при создании шардов мы должны стараться поддерживать одинаковый размер и рабочую нагрузку каждого шарда, чтобы система могла более равномерно распределять ресурсы и обрабатывать запросы.
Следует отметить, что,Скорость ответа Elasticsearch зависит от самого медленного шарда。поэтому,Если определенный шард обрабатывается медленно,Это повлияет на время ответа всего запроса. Это требует от нас реализации стратегии сегментирования,Старайтесь избегать создания слишком больших или слишком маленьких сегментов, чтобы не повлиять на общую производительность.。
Стратегия сегментирования записи данных с высокой нагрузкой (Стратегия сегментирования большого объема данных)
В сценариях записи данных с высокой нагрузкой разработка стратегии сегментирования требует особого внимания к следующим моментам:
- Выравнивание шардов с горячими узлами:Для лучшей производительности,Выравнивание шардов с горячими узлами. Горячие узлы обрабатывают высокочастотную запись данных,Таким образом, для разделения нагрузки на запись необходимо достаточное количество шардов.
- Посчитать количество осколков:Рекомендуемый мастер Посчитать количество формула Осколкова
num_shards = (hot_nodes - 1) / 2,И используйте копию индивидуально. Эта конфигурация может обеспечить отказоустойчивость, обеспечивая при этом,Максимизируйте пропускную способность. - Динамическая настройка шаблонов:существоватькластерпри расширении или сжатии,Динамическая настройка конфигурации сегментирования в шаблонах индексов.,для размещения нового количества узлов. Это гарантирует, что при изменении масштаба,Количество и распределение осколков можно корректировать во времени.,Держите нагрузку сбалансированной.
- Сосредоточьтесь на индексах высокой частоты событий:Для ставки на мероприятие(EPS)более высокий фронт 10 индивидуальныйиндекс,Особое внимание уделите стратегии шардинга. Эти индексы часто являются основным источником нагрузки на систему.,Оптимизация стратегии сегментирования может значительно улучшить общую производительность.
- Избегайте горячих точек с одним индексом:установив
total_shards_per_node: 1,Это может предотвратить концентрацию всех сегментов определенного индивидуального индекса на одном индивидуальном узле.,Избегайте отдельных точек перегрузки. - Стратегия шардинга:предположениесуществовать Размер осколка достигает 30-40GB прокрутите, когда. Эта стратегия может ускорить
force_mergeСкорость создания снимков, снижающая затраты на обслуживание. - Уменьшите количество пустых шардов и шардов с низкой нагрузкой.:старайся изо всех сил Уменьшите количество пустых шардов и шардов с низкой Эти осколки не только тратят ресурсы, но и влияют на производительность кластера. Цель — контролировать количество шардов в кластерсуществовать. 100,000 ниже.
Анализ фактического случая
Анализируя множество реальных случаев, мы можем лучше понять и применить стратегии сегментирования и их влияние на производительность кластера. Ниже приведены конфигурации кластера и их производительность для трех различных типов клиентов.
Крупные банки (США)
Банк размещает более 6 кластеров на Elasticsearch Service (ESS). Конфигурация эталонного кластера следующая:
- общая память:о 5.8 TB RAM
- Общее количество осколков:о 20,000 индивидуальный
- уровень данных:
- 18 отдельные горячие узлы (приблизительно за узел 40 индивидуальный Шардинг)
- 0 индивидуальныйтеплый узел
- 24 отдельные холодные узлы (каждый узел площадью ок. 100 индивидуальный Шардинг)
- 56 отдельные замороженные узлы (приблизительно за узел 300 индивидуальный Шардинг)
- Скорость записи данных:400,000 EPS
- Типичная скорость обработки узла: ~ 15 000–20 000 EPS.
- Аномальная скорость обработки узла: около 10 000–15 000 EPS.
- Ежедневный объем обработки данных:о 30 TB
Этот кейс демонстрирует, как добиться эффективной обработки и хранения данных путем правильной настройки «горячих» и «холодных» узлов в среде с высокой нагрузкой.
Крупный поставщик услуг по управлению безопасностью (США)
Компания размещает на ESS более 7 кластеров. Конфигурация эталонного кластера следующая:
- общая память:о 5.1 TB RAM
- Общее количество осколков:о 23,000 индивидуальный
- уровень данных:
- 28 отдельные горячие узлы (приблизительно за узел 45 индивидуальный Шардинг)
- 2 отдельные теплые узлы (каждый узел ок. 400 индивидуальные шарды, используемые для хранения пустых шардов и шардов с низкой нагрузкой)
- 34 отдельные холодные узлы (каждый узел площадью ок. 30 индивидуальный Шардинг)
- 24 отдельные замороженные узлы (приблизительно за узел 825 индивидуальный Шардинг)
- Скорость записи данных:240,000 EPS
- Типичная скорость обработки узла: ~9000 EPS
- Аномальная скорость обработки узла: около 4000 EPS.
- Ежедневный объем обработки данных:о 13 TB
Этот случай показывает, как оптимизировать баланс между горячими и холодными узлами, используя теплые узлы для хранения пустых сегментов и сегментов с низкой нагрузкой в сценарии безопасной обработки данных.
Крупные гостиничные организации (Европа, Ближний Восток и Африка)
Агентство размещает на ESS более 12 кластеров. Конфигурация эталонного кластера следующая:
- общая память:о 4 TB RAM
- Общее количество осколков:о 12,000 индивидуальный
- уровень данных:
- 40 отдельные горячие узлы (приблизительно за узел 20-30 индивидуальный Шардинг)
- 0 индивидуальныйтеплый узел
- 0 индивидуальныйхолодный узел
- 10 отдельные замороженные узлы (приблизительно за узел 1,100 индивидуальный Шардинг)
- Скорость записи данных:180,000 EPS
- Типичная скорость обработки узла: ~4000 EPS.
- Нет аномального узла
Этот кейс демонстрирует, как обеспечить быструю запись и долговременное хранение данных путем настройки большого количества «горячих» и «замороженных» узлов в среде с высоким объемом записи данных.
Анализ фактического случая Подвести итог
существования Проанализировав реальные случаи крупных банков, крупных поставщиков услуг по управлению безопасностью и крупных гостиничных организаций, мы можем Подвести завершить какое-то массивное существование Elasticsearch Ключевые уроки и передовой опыт проектирования кластеров.
Ключевые моменты дела
- Низкое количество осколков горячих узлов:Реальные случаи показывают,Сохранение низкого количества осколков горячих узлов помогает повысить стабильность и скорость перезапуска кластера. Путем правильной настройки количества шардов на горячих узлах,Это может гарантировать существование сценариев записи данных и запросов с высокой нагрузкой.,кластер может работать эффективно.
- Теплые узлы используются редко.:существоватьмасштабные наблюдения(o11y)исцена безопасностисередина,Теплые узлы используются реже. Теплые узлы в основном используются для хранения пустых шардов и шардов с низкой нагрузкой.,Большую часть работы по обработке данных выполняют горячие и холодные узлы. Это упрощает архитектуру,и повысить эффективность обработки данных.
- Отсутствие теплых узлов обеспечивает оптимальное принудительное слияние:Неттеплый узелиз Конфигурацияделатьсуществовать Локально на горячем узле NVMe Сохраненные операции принудительного слияния (force_merge) более эффективны. Горячие узлы способны быстро обрабатывать большие объемы данных и оптимизировать производительность хранилища и запросов за счет принудительного слияния.
- Холодные узлы гарантируют локальное хранилище (Холодные узлы гарантируют локальное хранилище):холодный узел确保了近期数据из本地存储,Особенно используется в таких сценариях приложений, как машинное обучение (ML) и правила. Эта конфигурация может обеспечить долговечность данных, одновременно гарантируя,Повышение эффективности запросов.
- Чрезмерное количество замороженных осколков приводит к медленному поиску и перезапускам.:Реальные случаи показывают,Слишком большое количество замороженных фрагментов приведет к замедлению поиска и перезапуска. поэтому,в дизайне При заморозке политики шардинга,Необходимо сбалансировать стоимость хранилища и производительность запросов.,Избегайте чрезмерной зависимости от замороженных осколков.
- Мультикластерная стратегия:существовать Объем данных превышает 10 TB/天из场景середина,Многокластерные стратегии очень распространены. Разделив источники данных или группы пользователей на разные кластеры,Это позволяет эффективно избежать проблемы перегрузки одного индивидуального кластера.,Повышайте надежность и производительность системы.
Анализируя реальные случаи, мы видим, что разные типы рабочих нагрузок и бизнес-требований требуют разных стратегий сегментирования и конфигураций узлов. Правильное применение этих стратегий может значительно улучшить Elasticsearch производительность и масштабируемость кластера. Я надеюсь, что эти тематические исследования смогут предоставить пользователям дизайн оптимизируйте свой собственный Elasticsearch Предоставьте ценную информацию и рекомендации при кластеризации.
Анализ анти-шаблонов: Анти-шаблон производительности
в дизайнеиоптимизация Elasticsearch кластер, помимо необходимости понимать основной принцип масштабируемости,Крайне важно понимать и избегать распространенных анти-шаблонов производительности. Так же, как заниматься программированием,Нам необходимо знать различные шаблоны проектирования.,Также помните о различных неприятных запахах в программировании. Вот некоторые распространенные антипаттерны, их влияние на производительность системы и что с ними делать.
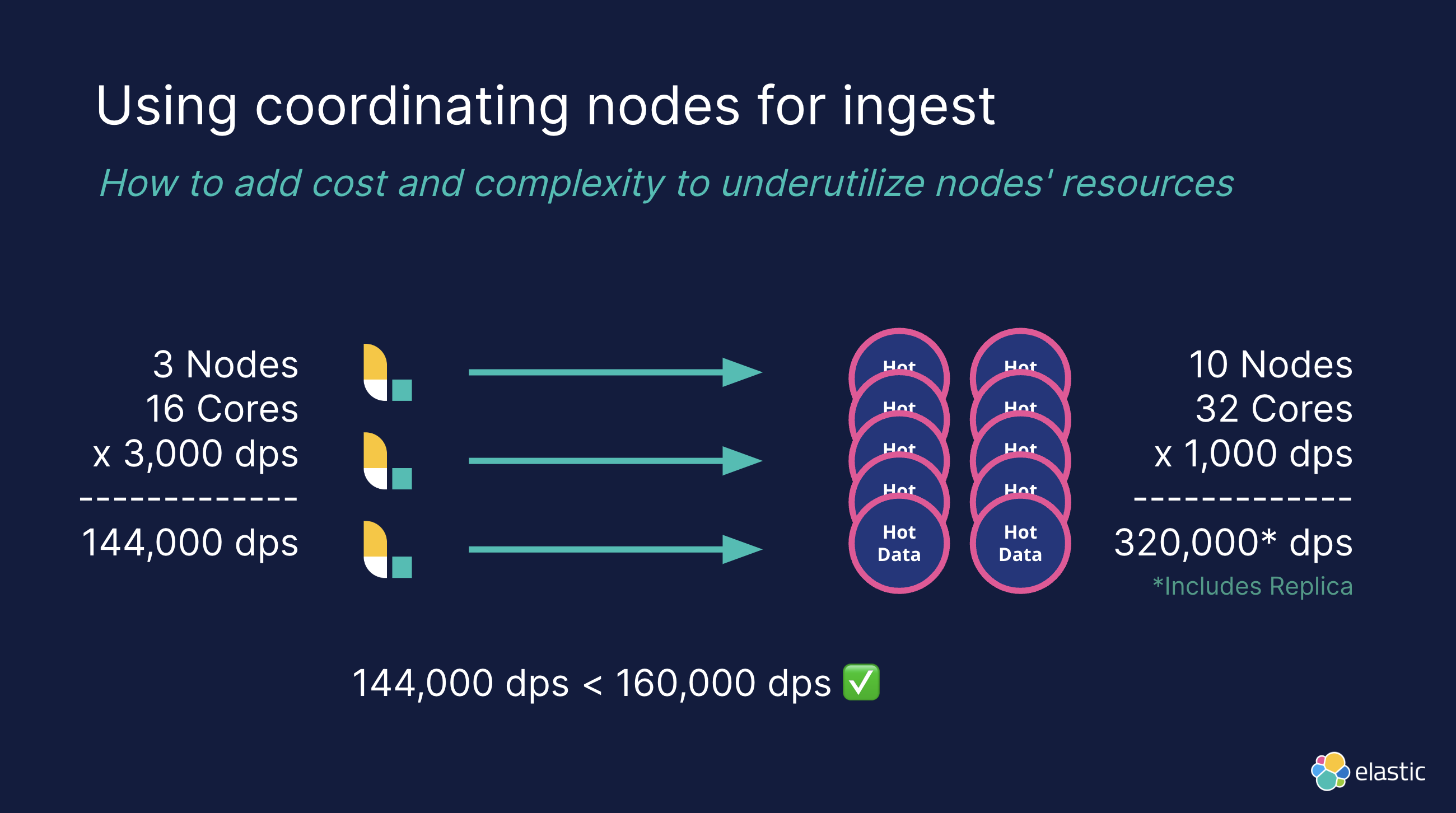
Использование координационных узлов для вставки
Вообще говоря, для крупномасштабных кластеров мы можем оптимизировать запросы путем координации узлов, чтобы снизить нагрузку на узлы данных и избежать влияния на пропускную способность записи из-за сложных запросов. Но часто из-за небрежности в проектировании весь трафик на стороне записи все равно сначала направляется на координационный узел:
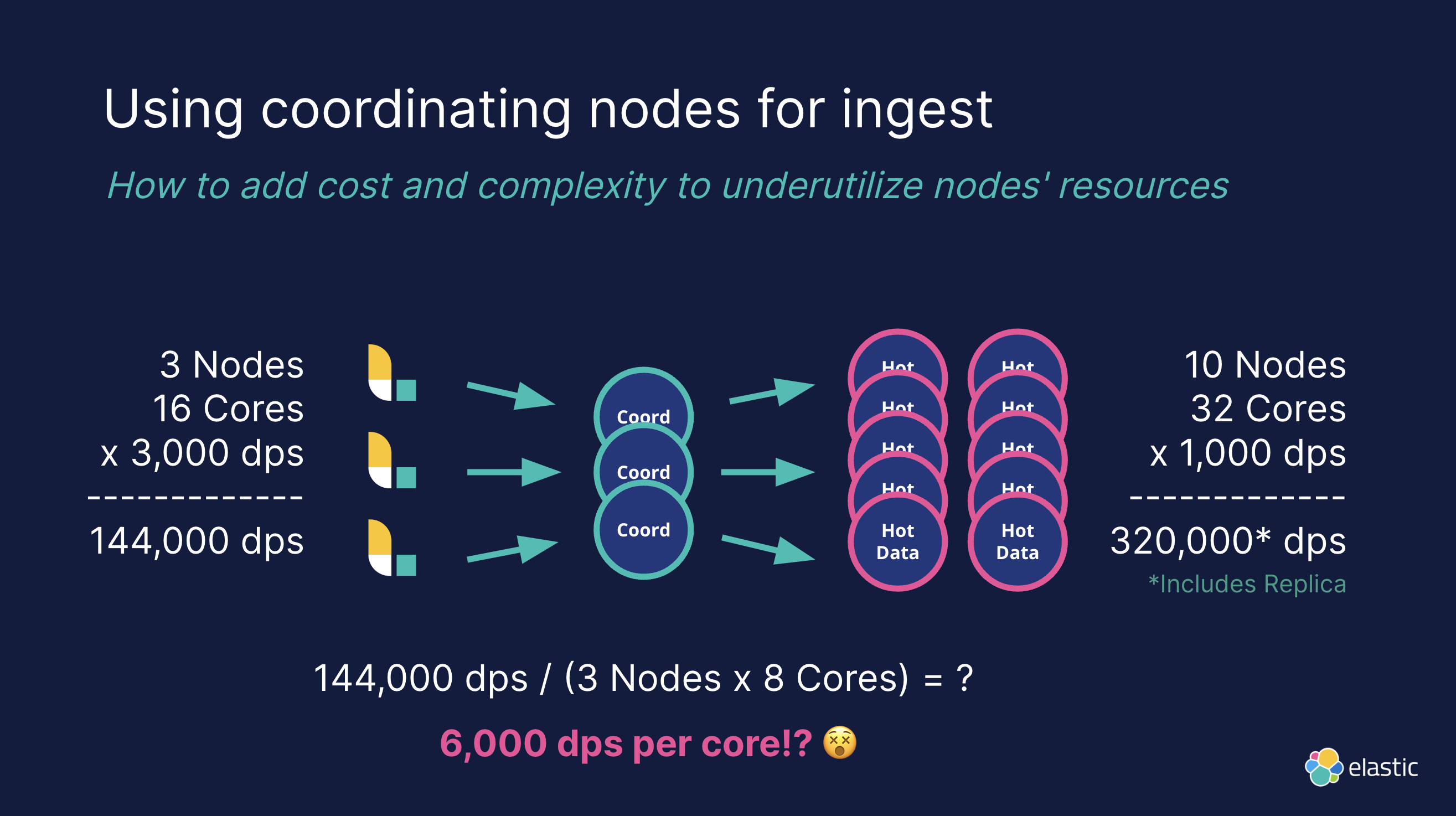
Описание проблемы:
Координационный узел в основном используется для распределения и сортировки запросов. Если большое количество запросов также отправляется непосредственно в координационный узел, это станет узким местом, как показано в сценарии на рисунке.
- письменная сторона, 3 индивидуальный Logstash узел, узел на человека 16 индивидуальное ядро, одноядерная обработка 3,000 dps, общая вычислительная мощность равна 144,000 dps。
- Сторона обработки, 10 индивидуальный data узел, узел на человека 32 индивидуальное ядро, одноядерная обработка 1,000 dps, общая вычислительная мощность равна 320,000 дпс (включая копии).
Если данные сначала отправляются на координационный узел, то координационный узел станет узким местом.
Решение:
Избегайте использования координационных узлов для записи данных и записывайте данные непосредственно на узлы обработки (например, «горячие» узлы), чтобы улучшить использование ресурсов и пропускную способность системы.
Концентрация рабочих нагрузок между уровнями данных
Иллюстрация:
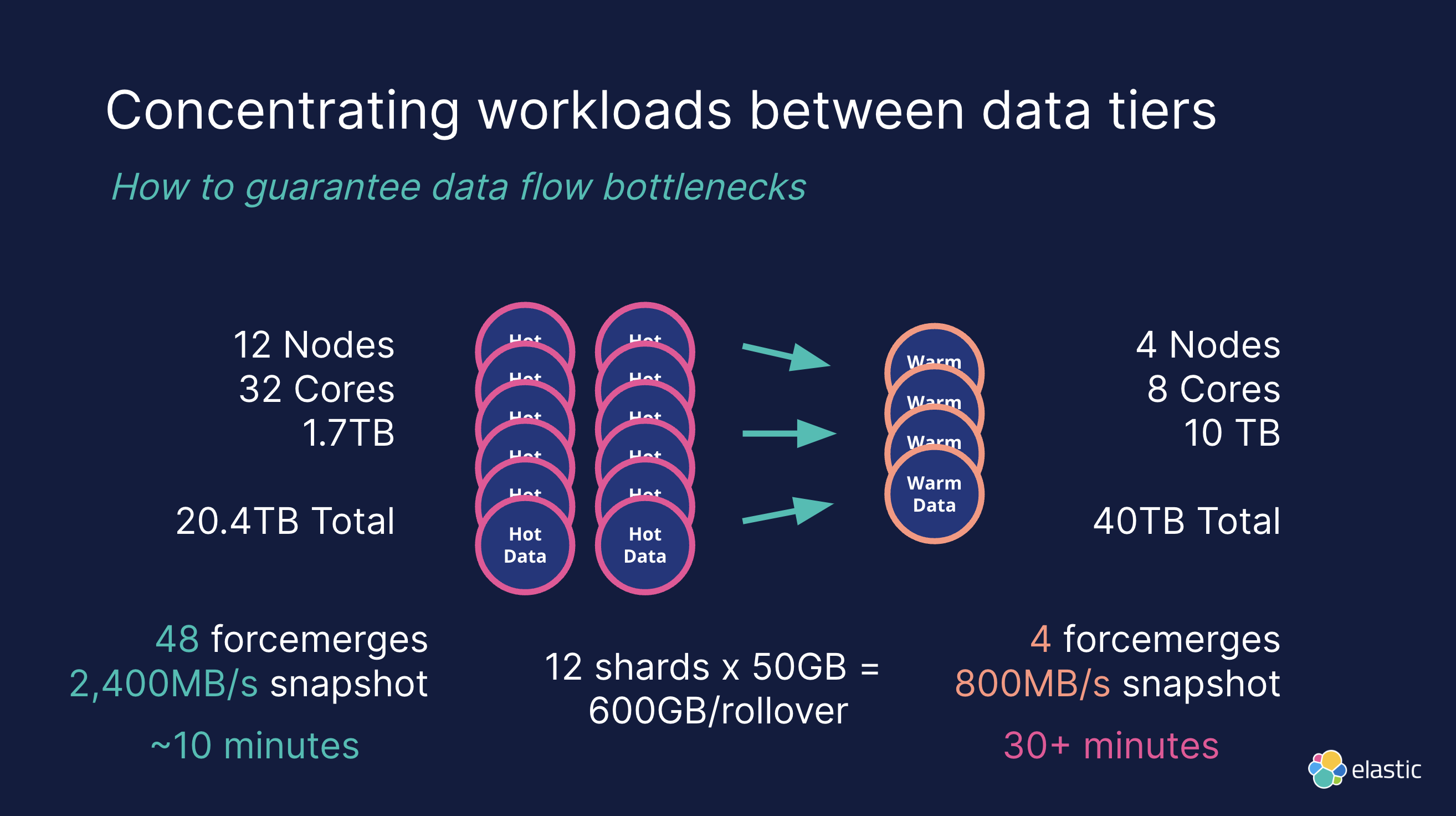
Описание проблемы:
В некоторых наших обычных проектах архитектуры мы можем видеть следующую архитектуру. Мы можем хранить данные в течение 7 дней в горячем слое и 14 дней в теплом слое. Мы оцениваем количество теплых узлов в зависимости от объема данных. размер
- 12 индивидуальныйгорячийузел, узел на человека 32 индивидуальное ядро, общая мощность 1.7 ТБ, общий объем обработанных данных 20.4 TB。
- 4 индивидуальныйтемператураузел, узел на человека 8 индивидуальное ядро, общая мощность 10 ТБ, общий объем обработанных данных 40 TB。
Однако такая архитектура будет иметь следующие проблемы:
- Узкое место в производительности:теплый узел Часто приводит к возникновению узких мест в потоке данных。Например,теплый узелиз I/O Производительность снижается, а выполнение таких операций, как принудительное слияние, может привести к длительным задержкам.
- Неэкономичный:теплый узелсуществовать成本效益方面往往不нравитьсягорячийузелихолодный узел。нравиться果теплый узел未能提供足够из价值,Это может привести к нерациональному использованию ресурсов и проблемам с производительностью.
- задержка перезапуска:высокий Шардинг密度изтеплый узелсуществовать Повторная инициализация всех устройств занимает много времени.Шардинг,Это приводит к длительной недоступности системы. (Индекс «Существующая термосфера» не доступен только для чтения)
Решение:
- Используйте теплые узлы только при необходимости: не полагайтесь слишком сильно на теплые узлы.,Убедитесь, что он используется в первую очередь для хранения и обработки шардов с низкой активностью. Вы можете установить только горячий слой и холодный слой.,Даже установлен только термослой и замораживающий слой.
- Если вам необходимо сохранить «теплый» слой, вы можете рассмотреть возможность принудительного слияния в «горячем» слое для фрагментов, не входящих в топ-10, сжимать нет необходимости;
Использование большого количества осколков с небольшими размерами пакетов
Иллюстрация:

Описание проблемы:
Большое количество сегментов и небольшие пакетные записи могут привести к резкому увеличению количества операций ввода-вывода в секунду и серьезно повлиять на производительность системы хранения. Например, размер пакета Logstash по умолчанию составляет 125 документов, предполагая, что данные за 7 лет распределены по 7 индексам, каждый из которых имеет 50–100 сегментов, что в общей сложности составляет 500 сегментов. В результате на каждый сегмент записывается в среднем 0,25 документов, что приводит к чрезвычайно низкой производительности записи — только один документ на запись.
Решение:
Оптимизируйте размер пакета и стратегию сегментирования, чтобы уменьшить количество пустых и малонагруженных сегментов. Убедитесь, что каждая операция записи максимально эффективна, и избегайте слишком большого количества небольших пакетов записи.
Подвести итог
Проектирование эффективного и масштабируемого кластера Elasticsearch требует рассмотрения многих факторов: от стратегии сегментирования до настройки роли узла и изоляции рабочей нагрузки. Избегая распространенных антишаблонов и следуя принципам проектирования масштабируемости, вы можете значительно повысить производительность и стабильность вашего кластера. Мы надеемся, что принципы и практические примеры, представленные в этой статье, помогут пользователям лучше понять и применить концепцию масштабируемости Elasticsearch.
Ссылки
Надеюсь, эта статья поможет вам! Если у вас есть какие-либо вопросы или вам требуется дополнительная поддержка, пожалуйста, свяжитесь с нашей технической командой.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
