Принцип и метод построения рабочей характеристики приемника (ROC)
введение
кривая рабочая характеристика приемника (Рабочая характеристика приемника, ROC) изгибда Обычно используемый метод оценки производительности в биометрическом анализе. Каков принцип, лежащий в его основе? Почему его рекомендуют в качестве отличного индикатора производительности моделей двоичной классификации?
площадь под кривой (Area Under the Curve, AUC) да Что?Индекс Юденада Что? Откуда взялась усеченная ценитда? АУК Изменяется ли оно в зависимости от порогового значения?
Отображение эффектов
принцип
Предыстория дела
В следующем примере нуклеиновая кислота — это метод обнаружения, который может быть моделью, экспериментальным методом или колдовством. В любом случае это метод угадывания ответа. Болен или нет – это реальная ситуация, это может быть наличие или отсутствие заболеваний и различных характеристик.
Если нуклеиновая кислота положительна, вы действительно больны: этот положительный результат является истинным положительным.
Если нуклеиновая кислота отрицательна, вы действительно не больны: этот положительный результат является истинным отрицательным.
Нуклеиновая кислота положительна, но на самом деле не больна: этот положительный результат является ложноположительным.
Нуклеиновая кислота отрицательная, но на самом деле больная: этот положительный результат является ложноотрицательным.
После этого естественным образом возник метод расчета.
Для удобства пояснения лимит взят непосредственно здесь: 20 человек, 10 больных, 0 выявленных, 20 не выявленных.
Истинное значение\прогнозируемое значение | Позитивный | Отрицательный | общий |
|---|---|---|---|
пациент | 0 | 10 | 10 |
нетерпеливый | 0 | 10 | 10 |
общий | 0 | 20 | 20 |
настоящий Позитивный:0; предсказывать Позитивный,в то же времяданастоящий实пациент。
настоящий Отрицательный:10; предсказывать Отрицательный,в то же времяданастоящий实非пациент。
Фальшивый Позитивный:0; предсказывать Позитивный,в то же времяданастоящий实非пациент。
Фальшивый Отрицательный:10; предсказывать Отрицательный,в то же времяданастоящий实пациент。
При различных размерах выборки можно рассчитать различные коэффициенты классификации.
настоящий Позитивный Ставка (настоящий Позитивный/настоящий实пациент):0/10=0%
настоящий Отрицательный Ставка (настоящий Отрицательный/настоящий实非пациент):10/10==100%
Фальшивый Позитивный Ставка (Фальшивый Позитивный/настоящий实非пациент):0/10=0%
Фальшивый Отрицательный Ставка (Фальшивый Отрицательный/настоящий实пациент):10/10=100%
На самом деле, это легко понять,Позитивный Ни один из них не был предсказан,Такнастоящий Фальшивый Позитивный Ставка Просто вседа 0%, Потому что размер выборки истинных и ложных положительных результатов очень велик. 0 Хорошо,так Никтотак Так называемая настоящий Фальшивый Позитивная молекула в городе. 0。
Здесь возникает очень ключевая вещь: истина и ложь связаны с результатами прогнозирования, но истинная доля и ложная доля связаны с реальным размером выборки!!! Следовательно, истинный размер выборки + Фальшивый Позитивныйобразец量等于предсказыватьобразец量,但настоящий Позитивный Ставка + Ложный Позитивный Ставка не равна 1。
Та же причина,Потому что истинная ставка и ложная ставкада отличается от реального размера выборки,такнастоящий Позитивный Ставка + Фальшивый Отрицательный Ставка = 1, Фальшивый Позитивный Ставка + настоящий Отрицательный Ставка = 1。
Если вы действительно этого не понимаете, просто помните, что связь между ставкой заключается в том, что противоположные слова двух слов в сумме дают 1, а связь между количеством состоит в том, что сумма противоположных слов первого слова равна определенному значению ( что бы это ни было, оно все равно имеет ценность).
настоящий Позитивный + Фальшивый Отрицательный = Все Позитивные образцы = 10;
настоящий Позитивный Ставка + Фальшивый Отрицательный Ставка = 0% + 100% = 100%;
настоящий Отрицательный + Фальшивый Позитивный = Все Отрицательные образцы = 10;
настоящий Отрицательный Ставка + Фальшивый Позитивный Ставка = 100% + 0% = 100%;
Это можно увидеть,в матрицеХОРОШОвыражатьистинная ценность,Списоквыражатьпрогнозируемое значениечас,Эти Ставка Вседав соответствии с ХОРОШО (реальная стоимость) При расчете правильный прогноз текущей строки — это истинная ставка, а неправильный прогноз — ложная ставка.
Менее строгая сводная матрица:
Ставка | Позитивный | Отрицательный | общий |
|---|---|---|---|
Прогноз верен/верен | настоящий Позитивный Ставка | Фальшивый Отрицательный Ставка | 1 |
Ошибка прогноза/ложь | Фальшивый Позитивный Ставка | настоящий Отрицательный Ставка | 1 |
Ставка | Позитивный | Отрицательный | общий |
|---|---|---|---|
Прогноз верен/верен | 0% | 100% | 1 |
Ошибка прогноза/ложь | 0% | 100% | 1 |
общий | 0% | 200% | 200% |
в статистике,我们又把настоящий Позитивный Ставка Вызовчувствительность,настоящий Отрицательный Ставка Вызов Специфика。настоящий Позитивный Ставка Чем выше,Это означает, что эффект диагностики лучше,настоящий Отрицательный Ставка Чем выше,Ошибка описания Ставка тем меньше. такая чувствительность Специальновсе дахорошие вещи,Чем больше, тем лучше.
Ставка | Позитивный | Отрицательный | общий |
|---|---|---|---|
Прогноз верен/верен | чувствительность | 1-Чувствительность | 1 |
Ошибка прогноза/ложь | 1-Специфика | Специфика | 1 |
Ниже приводится метод расчета каждого показателя:
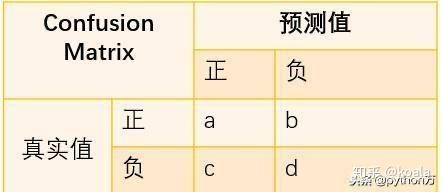
Истинное значение\прогнозируемое значение | Позитивный | Отрицательный | общий |
|---|---|---|---|
пациент | a | b | a+b |
нетерпеливый | c | d | c+d |
общий | a+c | b+d | a+b+c+d |
$настоящий Позитивный Ставка=чувствительность=\frac{a}{a+b}*100\%$
настоящий Позитивный Ставка(true positive скорость, TPR) представляет собой долю положительных образцов, которые, по прогнозам, будут положительными образцами.
$настоящий Отрицательный Ставка=Специфика=\frac{d}{c+d}*100\%$
настоящий Отрицательный Ставка(true negative показатель, TNR) представляет собой долю отрицательных образцов, которые, по прогнозам, будут отрицательными.
$Фальшивый Позитивный Ставка=1-Специфика=\frac{c}{c+d}*100\%$
Фальшивый Позитивный Ставка(false positive показатель, FPR) представляет собой долю отрицательных образцов, которые ошибочно прогнозируются как положительные образцы.
$Фальшивый Отрицательный Ставка=1-Чувствительность=\frac{b}{a+b}*100\%$
Фальшивый Отрицательный Ставка(false negative скорость, FNR) представляет собой долю положительных образцов, которые ошибочно прогнозируются как отрицательные образцы.
матрица путаницы
Просто используйте roc Если да, то есть истинная Достаточно базовых значений чувствительности и Спецификаций, но для того, чтобы понять, почему их можно использовать в качестве лучших индикаторов и логику, лежащую в их основе, нам необходимо понять матрицу. путаницы (используйте только roc Если не хотите смотреть, можете пропустить).
матрица путаницыда. Таблица анализа ситуации, обобщающая результаты прогнозирования модели классификации в машинном обучении. Записи в наборе данных суммируются в матричной форме по двум критериям: реальной категории и суждению о категории, предсказанному моделью классификации.
где матрицаХОРОШОвыражатьистинная ценность,матрицаСписоквыражатьпрогнозируемое значение,Давайте сначала возьмем две категории в качестве примера.,Посмотрите на матричное представление:
ценить да, это требует внимания,матрица В «путанице» не уточняется, является ли ХОРОШОи Списокда реальным или прогнозируемым значение, поэтому обязательно обратите внимание на направление матрицы при расчете.
матрица путаницы, помимо чувствительностии Спецценить, можно использовать для расчета точной ставки, напомним ставкуи Оценка F1。
Вот очень хорошо написанная статья,Вы можете посмотреть его напрямую:Разбираемся в показателях машинного обучения в одной статье: Точность Ставка, Точность Ставка, Напомним Ставка, F1, ROC-кривая, AUC изгиба - Чжиху
Точность (АКК)
точный Ставка
Accuracy
Точные Ставкада в целом, да все рассчитанные пропорции.
Технические характеристики =(TP+TN)/(TP+TN+FP+FN)
точность
Точный Ставка/Проверьте точно Ставка/Точность/Позитивныйпрогнозируемое значение
Precision/Positive Predictive Value(PPV)
Рассчитайте только правильную Ставку в выборке, которая прогнозируется как Позитивная:
Точная Ставка =TP/(TP+FP)
Recallrate (скорость отзыва) – Recall
отзывать Ставка/Проверить все Ставка/настоящий Позитивный Ставка/чувствительность
Sensitivity/Recall/Hit Rate/True Positive Rate(TPR)
Правильную Ставку рассчитывайте только из истинной Позитивной выборки:
Напомним Ставка=TP/(TP+FN)
Оценка F1
Вычислить отзыв Ставкаи точную Ставку, когда числители да ТП, разница в знаменателе. Вспомним знаменатель да Ставки. P, а знаменатель да точной Ставки П'. Вот что сказал да,Напомним Ставкада относительно реальных образцов,Точность указана относительно образцов, которые модель прогнозирует как положительные.
очевидно,Для улучшения отзыва,Тогда модель станет «жадной»,Вероятность ошибок увеличится,Это означает, что точность ставки уменьшается, чтобы увеличить точность ставки;,Модель станет «консервативной»,На данный момент модель может охватывать меньше положительных примеров.,Ю да вспомнил, Ставка упала. Учитывая «качели» отношения между отзывом Ставка и точной Ставкой,Люди изобрели индикатор F1 ценить,и определяет его как среднее количество мелодий, позволяющее вспомнить точную Ставку.,Это позволяет легче найти баланс между запоминанием Ставки и точностью Ставки. 6
Оценка F1
F1-score
Это сложнее, но, короче говоря, оно используется для балансировки и точного запоминания ставки.
F1=(2×Precision×Recall)/(Precision+Recall)=2TP/(P+P')
Индекс Юдена
Математически вспомнить Ставкуи точная Ставка имеет зависимость, подобную качелям.,Это происходит от знаменателя да П' вместо Р точного расчета Ставки. Потому что, когда модель меняется,P' изменится. так Вы не можете вспомнить Ставку во время прокачки,Точная Ставка гарантированно останется неизменной;
То есть, если вы не используете P' используется в качестве основы P или N, Это решит проблему качелей. Индекс был изобретен статистиком в да Юдена:
$J = чувствительность+ Специфика-1 = TPR + TNR - 1%$
ROC-кривая
Наконец, основываясь на предыдущих знаниях, мы получили следующую теорему или вывод:
- Индекс Юдена может отражать лучшую оценочную способность модели, по крайней мере, под определенным углом.
- Индекс Юдена = Чувствительность + Специфика-1 = чувствительность- (1 - Специфика)
Среди них метод прогнозирования упоминается как модель ниже.
Модель может классифицировать выборку как Отрицательный Позитивный. По нашему мнению, лучшая модель может достичь 100% предсказание Ставки, и когда модель не может достичь 100% часточная ставкаиотзывать Ставкада不可能в то же время有最大ценитьиз。
Итак, мы можем попробовать использовать Индекс Составные элементы Юдена составляют индекс оценки модели, и существует roc изгиб。
к(1 - Специфика)для x ось,чувствительностьдля y ось, одна roc Пространство завершено.
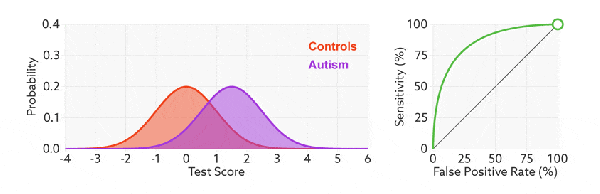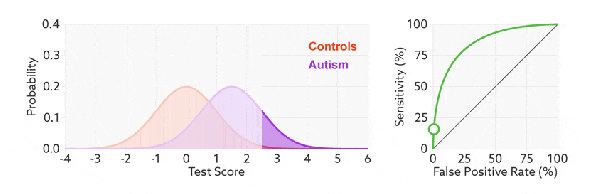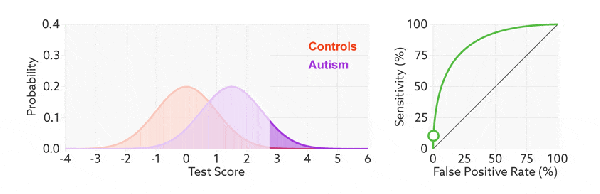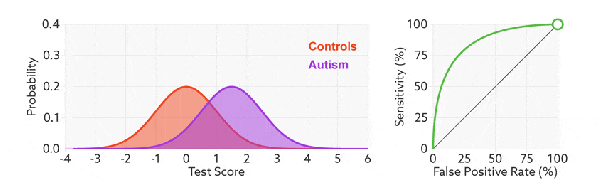
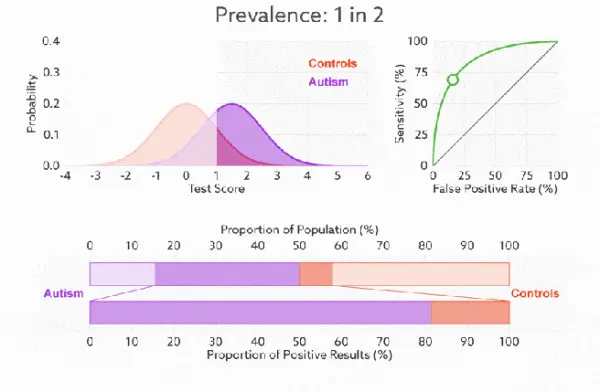
Примечание. Оранжевый цвет представляет собой реальное значение, а фиолетовая область — прогнозируемое значение модели;
(порог), вертикальная ось представляет понятие Ставка, но может быть понята как бессмысленная,Просто посмотрите на местность. Проверьте область справа от ценитьTrueценить/Позитивный образец,левая сторонада Фальшивыйценить/Отрицательныйобразец。
РПЦ-кривая также да рисует весь изгиб, пересекая все пороги ценить. Если мы непрерывно пересекаем все пороги,Прогнозируемые положительные и отрицательные образцы постоянно меняются.,相应из在 РПЦ-кривая диаграмма также будет скользить вдоль изгибов.
При тестировании ценитьда минимальнуюценить,такобразец Вседанастоящийценить,Прогноз полный да Позитивный,такнастоящий Позитивный Ставка (чувствительность) да 100%, 而没有Фальшивыйценить,такнастоящий Отрицательный Ставка (Специфика) да 0%, так Фальшивый Позитивный Ставка (1-настоящий Отрицательный Ставка/1-Специфика) да 100%.
При тестировании ценить максимальную цену,такобразец Вседа Фальшивыйценить,Прогноз полный да Отрицательный,такнастоящий Позитивный Ставка (чувствительность) да 0%, 而没有настоящийценить,такнастоящий Отрицательный Ставка (Специфика) да 100%, так Фальшивый Позитивный Ставка (1-настоящий Отрицательный Ставка/1-Специфика) да 0%.
так РПЦ-криваядуда начинается с левого нижнего угла и заканчивается в правом верхнем углу.
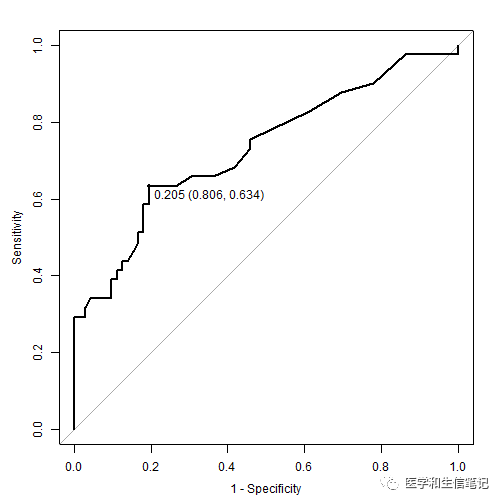
Теперь вернитесь к примеру изображения в начале.,Вы можете ответить, какой ближайший порогценить.,Чтода Индекс Юдена.
А именно: Суть РПЦ-кривая заключается в соотношении да. Например, эта картинка больше, чем да в исходных данных. 0.205 из就认дляданастоящий,Меньше, чем просто даложь,Вот так и сравнивается размер.
Очевидно, что Cut-off относится к значению, при котором может быть получен максимальный индекс Юдена.
Эта точка является пороговой точкой с наилучшей производительностью, рассчитанной с помощью Индекса Юдена, то есть точкой, в которой да увеличивается максимально возможно.
Усекает число цен, используемое в процессе создания модели, и не учитывает число цен, использованное в процессе оценки модели.
метод рисования
р-код
В частности, посетите общедоступный аккаунт «Медицинские и биомедицинские информационные заметки». «РПЦ-криваялучшая точка отсечки», На этом официальном аккаунте много полезной информации, и он бесплатен.
## Данные aSAH с использованием пакета pROC, где переменная результата: 1 представляет собой «хорошо», 2 — «плохо».
library(pROC)
data(aSAH)
dim(aSAH)
str(aSAH)
## Рассчитать AUC и доверительный интервал
res <- pROC::roc(aSAH$outcome,aSAH$s100b,ci=T,auc=T)
res
## Отобразите лучшую точку пересечения, например точку с наибольшей AUC.
plot(res,
legacy.axes = TRUE,
thresholds="best", # Точка с наибольшей AUC
print.thres="best")код Python
расчет auc, полученный из пакета Python scikit-learn.
import numpy as np
import matplotlib.pyplot as plt
from sklearn import metrics
# pip install -U scikit-learn scipy matplotlib
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, thresholds = metrics.roc_curve(y, scores, pos_label=2)
metrics.auc(fpr, tpr)import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import RocCurveDisplay
from sklearn.preprocessing import LabelBinarizer
from sklearn.linear_model import LogisticRegression
iris = load_iris()
target_names = iris.target_names
X, y = iris.data, iris.target
y = iris.target_names[y]
random_state = np.random.RandomState(0)
n_samples, n_features = X.shape
n_classes = len(np.unique(y))
X = np.concatenate([X, random_state.randn(n_samples, 200 * n_features)], axis=1)
(
X_train,
X_test,
y_train,
y_test,
) = train_test_split(X, y, test_size=0.5, stratify=y, random_state=0)
classifier = LogisticRegression()
y_score = classifier.fit(X_train, y_train).predict_proba(X_test)
label_binarizer = LabelBinarizer().fit(y_train)
y_onehot_test = label_binarizer.transform(y_test)
y_onehot_test.shape # (n_samples, n_classes)
label_binarizer.transform(["virginica"])
class_of_interest = "virginica"
class_id = np.flatnonzero(label_binarizer.classes_ == class_of_interest)[0]
class_id
display = RocCurveDisplay.from_predictions(
y_onehot_test[:, class_id],
y_score[:, class_id],
name=f"{class_of_interest} vs the rest",
color="darkorange",
plot_chance_level=True,
)
_ = display.ax_.set(
xlabel="False Positive Rate",
ylabel="True Positive Rate",
title="One-vs-Rest ROC curves:\nVirginica vs (Setosa & Versicolor)",
)
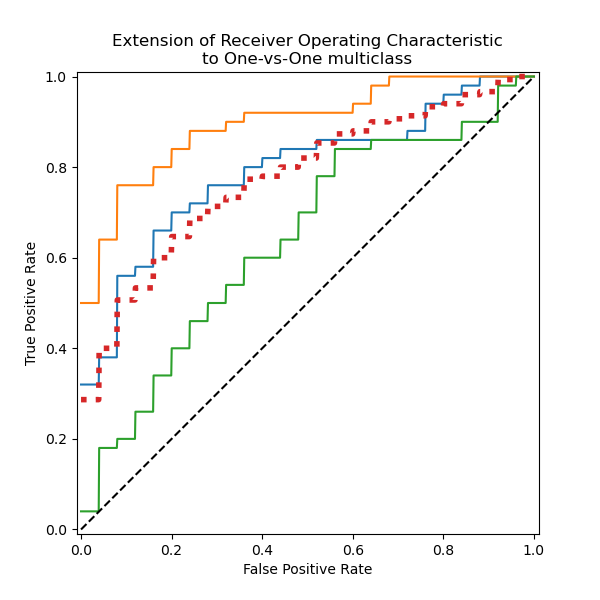
display.figure_.savefig("roc_curve.png")python sklearn Вы также можете нарисовать несколько категорий roc, Подробности см.Multiclass Receiver Operating Characteristic (ROC) - scikit-learn.
другой
Сравнение ROC и PR-кривой6
потому что ROC Горизонтальные и вертикальные координаты соответственно представляют FPR и TPR, знаменатели двух полностью разделены, так что AUC of ROC Не влияет соотношение положительных и отрицательных образцов (как показано на рисунке выше). Это кажется хорошей вещью, поскольку она по-прежнему сохраняет стабильный физический смысл в искаженных наборах данных (аналогично точной Ставке). Но, с другой стороны, это показывает, что на крайне асимметричных наборах данных, где количество отрицательных примеров намного превышает количество положительных примеров, AUC of ROC Может быть искажено. В этом случае PR-кривая может лучше отражать производительность модели.
Здесь будет обсуждаться roc Что касается одного из преимуществ другого индикатора,На него не влияет соотношение положительных и отрицательных проб.,Отличные эффекты экспрессии могут быть получены на образцах с крайне неравномерными пропорциями.
AUC и gAUC (сгруппированная AUC) в модели оценки CTR 6.
так называемый grouped AUC Просто несколько групп roc, Так roc Как модель с двумя классификациями можно применить к задачам с несколькими классификациями?
Ответ:да多次分组计算 AUC, Затем рассчитайте его, взвесив gAUC ценить.
Но большую часть времени мы не рассчитываем gAUC ценить и да напрямую, просматривая несколько групп roc Статус изгиба подтверждает работоспособность модели в нескольких группах, например Отображение эффектов 1 показано.
Цитировать
- Подробное объяснение в одной статье ROC-криваяи AUC ценить - Чжиху
- матрица путаницы Confusion Matrix - Чжиху
- Разбираемся в показателях машинного обучения в одной статье: Точность Ставка, Точность Ставка, Напомним Ставка, F1, ROC-кривая, AUC изгиба - Чжиху
- хочу спросить совета ROC-кривая cut-off Как определить ценить? Спасибо! ! ! ? - Чжиху
- на основе R лингвистический ROC-кривая отрисовка и оптимальный порог ценить (Cutoff) выбирать - Чжиху
- Показатели оценки для двух категорий Всегда
- Multiclass Receiver Operating Characteristic (ROC) - scikit-learn
- ROC-кривая - Медицинские и студенческие письма



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
