Применение и практика технологических решений распознавания целей на основе кадровых изображений, собранных из нескольких сложных сцен дорожного движения.
Предисловие
Мне посчастливилось работать инженером по интеллектуальному анализу данных в крупной картографической компании. Мне приходилось почти каждый день обрабатывать данные о дорожном движении нескольких сложных сцен на уровне PB или выше. Среди них технология обработки изображений с чрезмерным сбором кадров, основанная на больших данных. Можно также сказать, что многие детали оптимизации продуктов C-end и качество пользовательского опыта во многом зависят от нашей обработки и анализа этих изображений кадров, захваченных в реальном времени.
Поэтому изучение того, как преодолеть техническую обработку и анализ чрезмерного количества изображений на основе больших данных, было целью наших исследований и исследований. В процессе исследования я и моя команда попробовали немало решений и в конечном итоге добились хороших результатов. Итак, как не пойти в обход и быстро разработать общее решение для обработки и анализа больших данных за короткий период времени, с определенной степенью достижимости и стабильности, - это тема статьи, которую я хочу реализовать в этой статье. проблема.
Эта статья содержит много отраслевой терминологии и профессиональных знаний. Блогер постарался упростить ее одно за другим, чтобы ее было легко понять читателям, и убедился в осуществимости решения с помощью реальной демонстрационной практики. Читатели, глубоко заинтересованные в технологии, описанной в этой статье, могут обсудить ее с фанатами. Еще раз спасибо за вашу поддержку!
1. Предыстория спроса
Прежде всего, хотелось бы пояснить, что хотя форматы данных и эффекты в требованиях различаются, технические решения многоразовые и масштабируемые, поэтому нет необходимости учитывать слишком много несоответствий в требованиях. Здесь я кратко представлю технические требования.
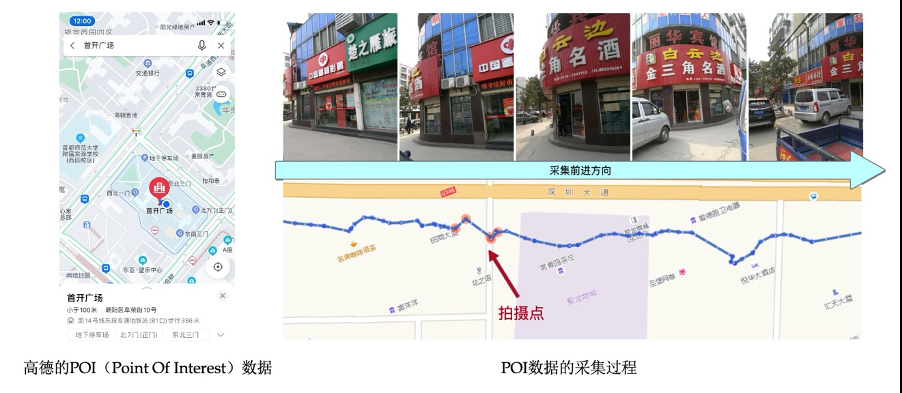
Богатство и точность картографических данных определяют пользовательский опыт (это верно для всех продуктов C-конца). Однако традиционный сбор, анализ и производство данных в основном требуют ручного вмешательства и многократного подтверждения для выхода в Интернет, что приводит к медленному обновлению данных и высокому уровню производительности. затраты на обработку. Поэтому нам необходимо собирать высокочастотные данные с транспортных средств для сбора мусора и использовать возможности алгоритмов изображений для автоматического обнаружения и идентификации содержания и местоположения различных элементов карты в наборах PB собранных изображений, а также для создания базовых картографических данных, которые обновляются в режиме реального времени. (Источник изображения: Карта Гаоде)
Это требует от нас сосредоточиться на обнаружении места происшествия. текстатехнологиясуществовать覆盖面、точностьи Проблемы со скоростью обработки。существоватьPOIВ бизнес-сценариях,Идентификация алгоритма требует не только максимально полного выявления текстовой информации вновь открывшихся магазинов на улице.,Также необходимо обеспечить точность результатов распознавания более 99%.,Поддержка автоматического создания названий POI;
В сценарии автоматизированной обработки дорожных данных,Распознавание алгоритма требует точного отслеживания тонких изменений в дорожных знаках.,Эффективно обрабатывайте огромные объемы возвращаемых данных каждый день,Чтобы своевременно обновлять ключевую информацию, такую как ограничения скорости и направления движения. в то же время,Из-за разнообразия оборудования для сбора и среды сбора,Сцены Gaode, распознающие текстовый алгоритм, часто должны иметь дело с чрезвычайно сложными условиями изображения.,В основном это отражается в следующих аспектах:
- текстовое разнообразие:письменный язык、Богатые и разнообразные шрифты и макеты, например художественные шрифты на деловых вывесках.、Различные логотипы и различные стили макета.
- сложность фона:文字所существовать背景常常复杂多样,На это могут влиять окклюзия, неравномерное освещение и другие факторы помех.
- Разнообразие источников изображений:Изображения получены с помощью недорогого краудсорсингового оборудования.,Эти устройства имеют разные параметры.,Качество изображения варьируется. Изображение может быть наклонено, не в фокусе, трястись и т. д.,еще больше увеличивает сложность идентификации.

Итак, теперь, когда мы поговорили о технических трудностях, давайте остановимся на них по порядку.
2. Технические проблемы
Во-первых, позвольте мне представитьSTRтехнология,сценараспознавание текста(Scene Text Технология распознавания (STR) — это технология искусственного интеллекта, ориентированная на извлечение и распознавание текстовой информации из изображений естественных сцен. Это типичное приложение, которое сочетает в себе компьютерное зрение и обработку естественного языка и широко используется в таких областях, как аннотирование карт, обработка документов, беспилотное вождение, дополненная реальность и интеллектуальное обслуживание клиентов.
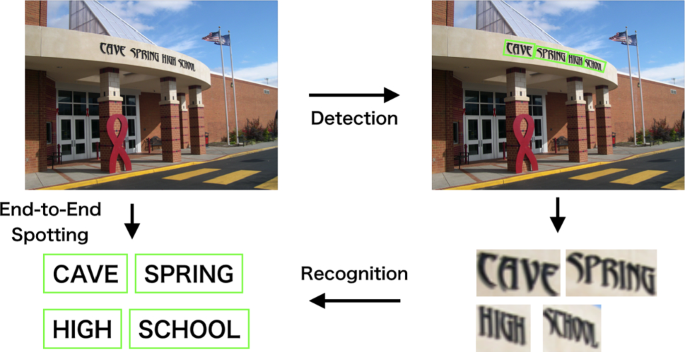
В настоящее время STR больше направлен на укрепление сквозной модели STR.,Давайте пока не будем упоминать STR перед глубоким обучением.,Ожидается, что конечный эффект одновременно выполнит задачи Обнаружения текстовой строки текста с помощью одной модели.,Это позволяет быстро добиться живописного извлечения POI.,Но реальная работа не так проста,До этих двух еще существовало множество стратегий более точной обработки снимков, сделанных в разных сценах.,Реализация End-to-End фреймворка требует большого количества качественных данных аннотации текстовых строк и результатов их распознавания.,Стоимость маркировки данных очень высока.
В то же время синтетические виртуальные данные не могут полностью заменить действие реальных данных. Таким образом, становится более эффективным выбором разделить задачи обнаружения и распознавания текста и оптимизировать две независимые модели соответственно.
Обнаружение текстовой строкимодуль:Отвечает за позиционирование текстовой области.,и создадим маску для текста,Исправить вертикаль, добавление, Проблемы с искажениями, такие как изгиб.
Модуль распознавания последовательностей:Определите обнаруженную текстовую область,Извлеките полную текстовую информацию. Однако,Для художественных шрифтов или специально организованного текста,Могут быть недостатки в работе этого модуля.
Обнаружение и распознавание одного словамодуль:существовать Идентификация последовательности效果欠佳изсцена中,Дополняется обнаружением и распознаванием на уровне слов.,Повысьте общую точность распознавания и адаптируемость.
Благодаря такому дизайну подмодулей мы можем лучше решать разнообразные текстовые проблемы в сложных сценах и оптимизировать производительность каждого модуля.
Обнаружение текстовой строки
В настоящее время существует два основных метода: один основан на регрессии, а второй — на сегментации:
1. Методы, основанные на регрессии
Этот тип метода напрямую прогнозирует положение и форму текстовых областей с помощью регрессионных моделей и подходит для позиционирования текстовых строк в сложных сценах.
Типичный алгоритм: EAST (эффективный и точный детектор текста сцены).
- Основная идея:EASTНепосредственно вернуть ограничивающую рамку текстовой области каждого пикселя.,Сложные этапы постобработки исключены.
- Этапы реализации:
- использовать полностью сверточную сеть (полностью Convolutional Network, FCN) для извлечения особенностей изображения.
- Прогноз делается на основе геометрических свойств пикселей (таких как повернутые ограничивающие рамки и четырехугольники).
- Во время постобработки используется немаксимальное подавление (NMS) для удаления избыточных кадров обнаружения.
Процесс расширения сложен, производительность в реальном времени низкая, а на захваченные изображения легко влияют препятствия, поэтому этот метод был отвергнут в начале эксперимента.
2. Методы на основе сегментации
Метод сегментации Воля Обнаружение текстовой строки рассматривается как задача семантической сегментации и определяет текстовую область посредством классификации на уровне пикселей.
Репрезентативный алгоритм: PSENet (сеть прогрессивного расширения масштаба).
- Основная идея:Постепенно расширяйте основную область текста(text ядра), чтобы получить полную текстовую область.
- Этапы реализации:
- Текстовые ядра в нескольких масштабах извлекаются с помощью моделей семантической сегментации.
- Постепенно расширяйтесь от мелкомасштабного ядра к крупномасштабному, чтобы создать полную текстовую область.
- Во время постобработки соседние текстовые ядра объединяются в единую текстовую строку.
Процесс расширения также сложен, производительность в реальном времени низкая, а интервалы текста на табличке большие, поэтому этот метод также отвергается.
3. Методы, основанные на обнаружении целей
Этот тип метода основан на технологии обнаружения целей (например, YOLO, Faster R-CNN) и рассматривает позиционирование текстовой строки как задачу обнаружения целей.
Репрезентативный алгоритм: текстовые поля/текстовые поля++.
- Основная идея:существоватьSSD(Single Shot MultiBox Детектор), отрегулируйте соотношение кадров обнаружения в соответствии с областью длинного текста.
- Этапы реализации:
- использовать Сверточная сеть Извлечение функций。
- Создавайте кадры обнаружения, адаптированные к форме текста в соответствии с разными масштабами (более длинное соотношение сторон).
- Во время постобработки перекрывающиеся кадры обнаружения объединяются посредством NMS.
Этот метод считается идеальным, быстрым и простым в интеграции. Маска R-CNN Это этапная маска задачи сегментации экземпляра. R-CNN наследует Faster Система обнаружения целей R-CNN впервые проходит в регионе Proposal Сеть (RPN) генерирует регионы-кандидаты, а затем точно регрессирует ограничивающую рамку и маску для каждого региона-кандидата. Этот механизм очень подходит для Обнаружения. текстовой строки Сложная компоновка текста в задачах(например, шахматное расположение、согнуть текстиплотные строки текста)。существоватьсцена文字中,Особенно на рекламных щитах и придорожных табличках.,Перекрывающиеся текстовые области встречаются очень часто. Сегментация экземпляров может точно различить эти перекрывающиеся области.,Модели семантической сегментации имеют тенденцию путать эти регионы.

Стоит отметить появление Transformer, чьи мощные возможности глобального моделирования также применяются к позиционированию текстовых строк. В некоторых старых кварталах и густонаселенных районах по-прежнему сложно найти ключевую информацию о POI. Добавление Transformer принесло некоторые новые идеи.
распознавание текста
В автоматизированном процессе получения дорожных данных POIи распознавание Результаты текста должны удовлетворять два аспекта потребностей бизнеса. С одной стороны, требуется максимально полно распознавать содержимое текстовой строки, с другой стороны, алгоритм должен уметь различать части результатов распознавания с чрезвычайно высокой точностью. Ошибки в названиях POI приведут к ухудшению пользовательского опыта и даже повлияют на надежность картографических сервисов. И это отличается от распознавания, которое обычно оценивается по отдельным словам. стандартный текст, следует уделять больше внимания Результаты распознавания всей текстовой строки:
Распознавание строк текста с полной точностью:Относится к текстовому контентуи顺序完全正确из文本行существовать所有文本行中из占比,用于评估существоватьPOIимя、Название дороги и т. д. Общее распознавание Текст Результат выполнения задачи.
Распознавание текстовой строки с высоким коэффициентом достоверности:Относится к высокому уровню достоверности результатов распознавания.(Точность превышает99%)Пропорция текстовых строк,Используется для измерения способности алгоритма разделять детали с высокой точностью.
В реальном бизнесе ошибки распознавания одного слова могут привести к тому, что вся текстовая строка не будет соответствовать требованиям использования. Например, если «Китайский строительный банк» ошибочно распознается как «Китайский строительный банк», даже если скорость распознавания одного слова высока, это серьезно повлияет на точность текстовой строки. Таким образом, общая точность текстовой строки (полная точность) больше соответствует требованиям оценки бизнес-сценариев.
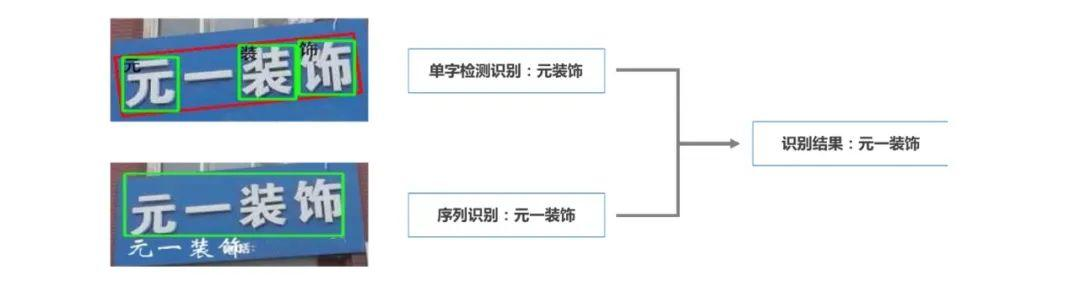
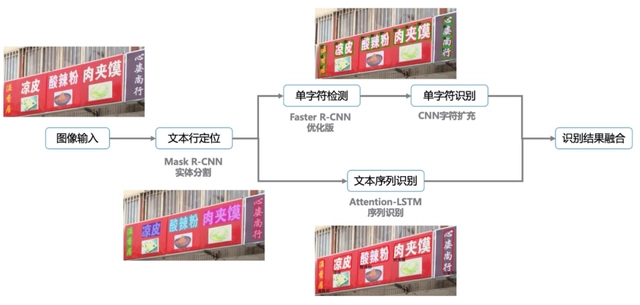
Поэтому для достижения этой цели Обнаружение и распознавание одного словаи Идентификация последовательность результатов слияния предназначена для улучшения распознавания Текст Важная стратегия для общей производительности системы, особенно в сценариях обнаружения. текста По задаче,Сочетая преимущества обоих подходов,Высокая точность может быть обеспечена,Он также может решать сложные проблемы в особых сценариях.
Обнаружение и распознавание одного словаи Идентификация последовательности У каждого свои достоинстванедостаток:
- Обнаружение и распознавание одного слова:Обнаружение и распознавание слово за словом,Подходит для обработки изогнутого текста, сложных аранжировок, художественных шрифтов и т. д.,но в длинных строках текста,Результаты на уровне слов могут не соответствовать контексту.
- Идентификация последовательности:Последовательное моделирование,Возможность распознавать содержимое текстовой строки в целом,Иметь сильные навыки контекстуального понимания,Однако он менее устойчив к сложным сценам (таким как окклюзия, деформация глифов) и локальному шуму.
Объединив эти два подхода, вы сможете в полной мере воспользоваться их преимуществами:
- Обнаружение и распознавание одного словасоставитьИдентификация последовательностисуществовать细粒度局部处理上из不足。
- Идентификация последовательностиУлучшенныйОбнаружение и распознавание одного словасуществовать上下文一致性и Производительность при обработке длинных строк текста。
Обнаружение и распознавание одного слова
Обнаружение и распознавание одного словамейнстрималгоритмоснован наГлубокое обучение методам обнаружения и распознавания на уровне символов,вCRAFT(Character Region Awareness for Text Detection) Это самый классический и эффективный метод распознавания слов.алгоритм№1。Этот метод позволяет добиться сложного фона.и Точное обнаружение неправильно расположенных символов,обеспечивая при этом высококачественные входные данные для распознавания на уровне символов。CRAFTОбнаружение проходаобласть персонажаиобласть межсимвольных ссылок,Проблема обнаружения на уровне символов Воля трансформируется в проблему сегментации на уровне пикселей. Возможность непосредственного обнаружения областей с одним словом,Избегайте распространения ошибок при обнаружении текстовой строки.
Характеристики алгоритма
- Высокая точность уровня персонажа:CRAFTизобласть Обнаружение персонажей может быть точным до уровня пикселей и подходит для задач распознавания отдельных слов.
- Адаптируйтесь к сложным сценариям:Изогнутый текст、Текст с неравномерным расположением и сложным фоном имеет лучшую надежность.
- Облегченная реализация:Путем оптимизации магистральной сети(нравитьсяиспользоватьMobileNetзаменятьVGG16),Может быть достигнута высокая производительность в реальном времени.
Конечно, было протестировано и немало алгоритмов:
алгоритм | преимущество | недостаток | Применимые сценарии |
|---|---|---|---|
CRAFT | Обнаружение символов на уровне пикселей, высокая точность, адаптируемость к сложному фону | Постобработка более сложна, и эффект на плотных сценах немного хуже. | Изогнутый текст, сложный фон, многоязычные сцены |
PAN | Эффективный и легкий, высокая производительность в реальном времени, адаптируемая к плотным сценариям | Эффект обнаружения на больших областях символов средний. | Периферийные устройства, сценарии обнаружения в реальном времени |
DBNet | Дифференцируемая бинаризация, качественная сегментация, четкие границы | Постобработка основана на бинаризованной карте сегментации. | Обнаружение мелких символов, сценарии сканирования документов |
TextSnake | Изогнутый текст обладает высокой адаптируемостью и генерирует высококачественные рамки обнаружения отдельных символов. | Низкая эффективность для линейных текстовых сцен. | Изогнутый текст, художественные шрифты |
EAST | Высокая скорость обнаружения, простая структура и высокая масштабируемость. | Эффект обнаружения одного слова ограничен | Сценарий обнаружения одного слова, оптимизированный для задач в реальном времени и обнаружения текстовой строки |
Оптимальный алгоритм расчета может быть выбран исходя из текущего бизнеса.
Распознавание текстовой последовательности
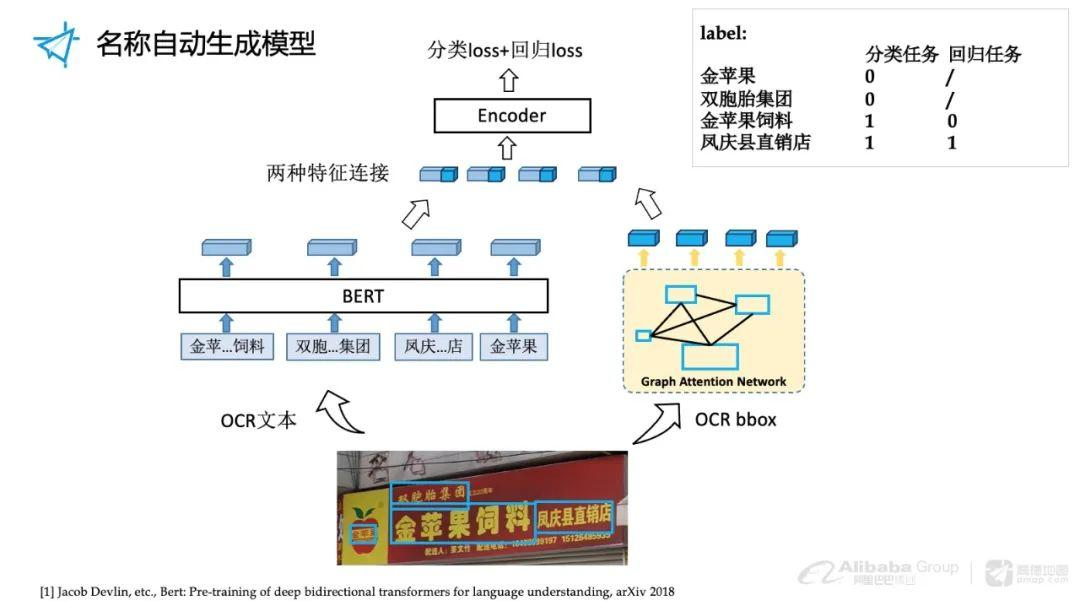
Распознавание текстовой последовательность — одно из основных звеньев в задачах оптического распознавания символов. В настоящее время это наиболее распространенное и эффективное распознание. текстовой последовательностиалгоритм主要基于深度学习из序列建模方法,включатьМеханизм вниманияиСтруктура трансформатораиз应用。CRNNклассическийалгоритм Я больше не буду об этом упоминать,Давайте сосредоточимся на Трансформере-БЕРТалгоритме.,Transformer в настоящее время находится Распознание текстовой Последним достижением в области последовательности с ее мощными возможностями глобального моделирования и преимуществами параллельных вычислений стало Распознание. текста сложной Предпочтительный метод для сцен. Преобразуйте визуальные объекты в предварительные текстовые последовательности, а затем вводите текстовые последовательности в BERT Модель. Воля BERT Семантические и визуальные функции интегрированы для получения более точного окончательного результата распознавания.
Извлечение визуальных признаков: использовать CNN、ResNet или Vision Transformer Извлекайте визуальные особенности текстовых изображений.
Моделирование текстовой последовательности: Преобразуйте визуальные объекты в предварительные текстовые последовательности, а затем вводите текстовые последовательности в BERT Модель.
Модуль Fusion: Воля BERT Семантические и визуальные функции интегрированы для получения более точного окончательного результата распознавания.
Можно сказать, что структуру распознавания текста модели слияния Vision + BERT можно рассматривать как лучшую стратегию на данный момент. В практических приложениях, поскольку объектами распознавания являются в основном короткие и средние тексты в естественных сценах, геометрические искажения, искажения и размытие текста сцены чрезвычайно серьезны.
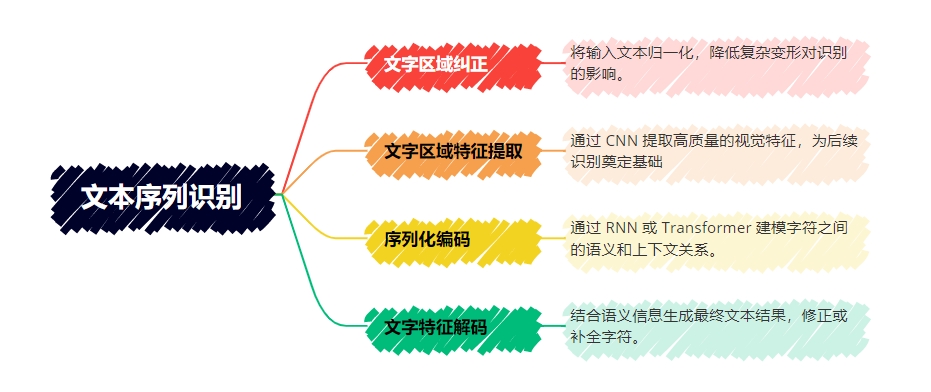
Воля Распознавание текстовой последовательностиразложен начетыре подзадачииз优势существовать于各个环节из分工明确,сотрудничать друг с другом,Формируется сквозной эффективный процесс идентификации:
- Коррекция текстовой области:Воля Нормализация входного текста,Уменьшите влияние сложной деформации на распознавание.
- Извлечение признаков текстовой области:проходить CNN Извлечение высококачественных визуальных характеристики, закладывающие основу для последующей идентификации.
- кодирование сериализации:проходить RNN или Transformer Моделируйте смысловые и контекстуальные отношения между персонажами.
- Декодирование текстовых объектов:объединитьсмысловая информация Создать окончательный текстовый результат,исправлениеили Завершающие символы。Этот метод разложения особенно подходит дляРаспознавание текста сложной сцены,нравиться弯曲文本、художественный шрифтили不规则文本行из识别。проходитьвизуальные характеристикиисмысловая информацияиз有效объединить,алгоритм, обеспечивая при этом точность распознавания,Значительно расширяет способность понимать сложную компоновку и контекстную информацию.
Примеры практического применения
- ASTER
- использовать STN Внесите исправления в текст → CNN Извлечение функций → RNN+Attention Кодирование и декодирование → Выведите результаты распознавания.
- Подходит для изогнутого и неправильного текста.
- SATRN
- использовать Transformer Конструктивное завершение Кодирование и декодирование → Захват глобального контекста → Выходная текстовая последовательность.
- Подходит для сложных фонов и длинных текстовых сцен.
- TRBA(Transformer with Backbone Attention)
- Волявизуальные характеристики прекрасно интегрируется с семантическим моделированием, используя Attention Улучшите эффекты выравнивания на уровне персонажа.
3. Практическая работа
Итак, после стольких разговоров о реальном бою, это абстрактно и скучно.,Если бы мы шаг за шагом практиковали весь проект идентификации целей, накопивший к этому времени несколько лет технических итераций,,Ситуаций наверняка будет много,因此существовать这里还是推荐использовать Интеллектуальное структурированное распознавание Tencent CloudDEMOпочувствуй это:Идентификация по фотографии торговой двери Демо。
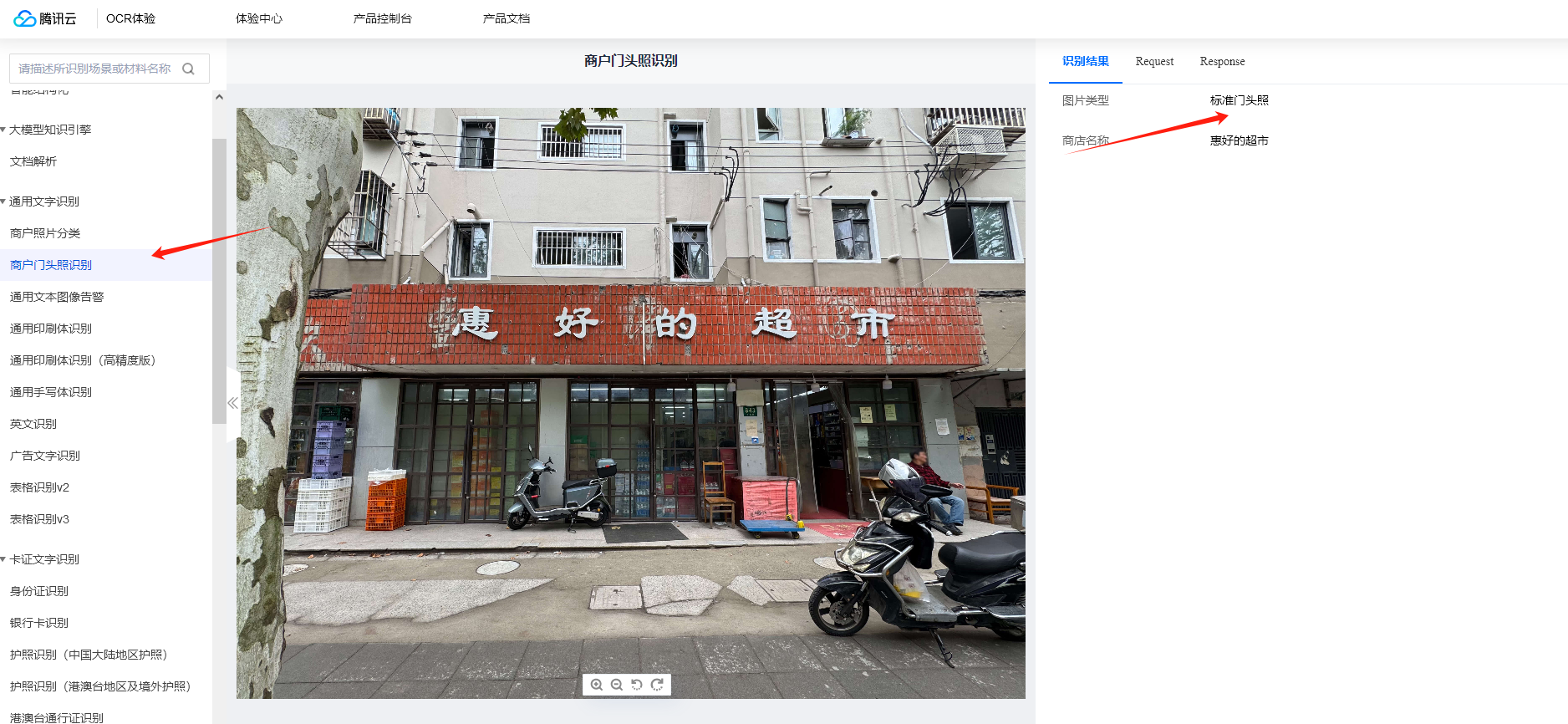
В настоящее время на рынке все еще мало зрелых продуктов интеллектуального структурированного распознавания OCR.,Потому что общая конструкция очень сложна,Тем не менее, Tencent Technology накопила большой опыт в распознавании изображений WeChat и технологии многосценарного оптического распознавания символов.,Если нам не придется разрабатывать собственные продукты оптического распознавания символов,Вполне возможно использовать интеллектуальные продукты структурированного распознавания Tencent Cloud для выполнения быстрой итеративной разработки. С помощью приведенной выше демонстрации вы также можете быстро научиться использовать API.,Также доступна подробная документация по продукту.,Можно сказать, что это очень удобно.
Для практической работы в этой экспериментальной операции используется сторонний интерфейс Tencent Cloud OCR.,Сначала завершите развертывание общей архитектуры.,Часть алгоритма может быть полностью выполнена как черный ящик.,Если в будущем возникнет необходимость самоисследования, его можно постепенно заменить.,В противном случае я все же настоятельно рекомендую использовать стороннюю разработку интерфейса.,Сэкономьте много рабочей силы и материальных ресурсов.
Сначала нам нужно активировать услугу:распознавание текст обеспечивает универсальный、Карточная карта、счет、Печать в различных сценариях, например отраслевых документах、Распознавание рукописного ввода и интеллектуальное сканирование кода、Карточная картасчет Услуги проверки。

Активируйте, чтобы автоматически выдать 1000 бесплатных раз.,И этоОтправляйте 1000 бесплатных пакетов ресурсов каждый месяц.:
Разработка API 3.0 Explorer
Если вы новичок в разработке и имеете навыки программирования, это будет полезно. HTTP запрос и API Вызов имеет определенное понимание, вы можете использовать этот метод использовать распознавание текстовый сервис. Этот метод может реализовать онлайн-вызовы, проверку подписи, SDK. кодгенерироватьи Интерфейс быстрого поиска и другие возможности:API Explorer

Для каждого параметра есть подробное объяснение в документации, я объясню его подробно здесь:
Region:HTTP Заголовок запроса: X-TC-Region. Параметры региона используются для определения данных, в каком регионе вы хотите работать. Значения см. в главе входных параметров в документе интерфейса, посвященном общедоступным параметрам. Region из说明。Примечание. Некоторым интерфейсам не требуется передавать этот параметр. Это будет специально указано в документе интерфейса. Даже если этот параметр будет передан, он не вступит в силу.
ImageBase64:живописный Base64 ценить.
Поддерживаемые форматы изображений: PNG, JPG, JPEG, формат GIF пока не поддерживается.
Поддерживаемый размер изображения: загруженное изображение не превышает 7 МБ после кодирования Base64. Загрузка изображения занимает не более 3 секунд.
Поддерживаемые пиксели изображения: должны быть в пределах 20–10 000 пикселей.
живописный ImageUrl、ImageBase64 Должен быть указан один, если указаны оба, используйте только ImageUrl。
Пример значения: /9j/4AAQSkZJRg…..s97n//2Q==
Для вашего удобства изображения, представленные здесь, преобразованы в Base64. Реализация кодирования:
import base64
# Определить путь к изображению
image_path = 'your_image.jpg'
# Изображение Воля конвертировано в Base64
with open(image_path, 'rb') as image_file:
# Прочитайте содержимое изображения и преобразуйте его в кодировку Base64.
base64_encoded = base64.b64encode(image_file.read()).decode('utf-8')
# Распечатать строку Base64
print("Base64 Результат кодирования: ")
print(base64_encoded)Исходное изображение:

Соответствующий результат интерфейса:
{
"Response": {
"Angle": -5.7148051261901855,
"RequestId": "c3e51da5-80f5-480e-9749-518e2f130e26",
"StoreInfo": [
{
"Name": "название магазина",
"Rect": {
"Height": 137,
"Width": 280,
"X": 491,
"Y": 238
},
"Value": "Миксу Ледяной Город"
},
{
"Name": "название магазина",
"Rect": {
"Height": 153,
"Width": 276,
"X": 1144,
"Y": 208
},
"Value": "Миксу Ледяной Город"
}
],
"StoreLabel": [
«Стандартное фото входной двери»
]
}
}Имя параметра | тип | описывать |
|---|---|---|
StoreInfo | Array of StoreInfo | Пример значений имени фотографии двери: { "Name": "Название магазина", "Rect": { "Высота": 263, "Ширина": 1132, "X": 232, "Y": 366 }, " Ценность» : «Супермаркет городской жизни» } |
Angle | Float | Угол поворота изображения (система углов), горизонтальное направление текста — 0°, по часовой стрелке — положительное, против часовой стрелки — отрицательное. Пример значения: 0,988696813583374. |
StoreLabel | Array of String | Тег с фотографией двери Пример значения: «Стандартное фото двери» |
RequestId | String | Для каждого запроса будет возвращен уникальный идентификатор запроса, сгенерированный сервером (если запрос не может достичь сервера по другим причинам, запрос не получит RequestId). При обнаружении проблемы вам необходимо указать RequestId запроса. |
PythonSDK
Вы можете быстро найти нужную информацию о SDK с помощью API Explorer. Например, если мы используем Python для интеграции API, сначала установите пакет SDK:
pip install tencentcloud-sdk-python-ocr -i https://pypi.tuna.tsinghua.edu.cn/simple
SecretId и SecretKey добавлены в application.yaml.,Авторизоватьсяhttps://console.cloud.tencent.com/cam/capi Доступный.
import json
import types
from tencentcloud.common import credential
from tencentcloud.common.profile.client_profile import ClientProfile
from tencentcloud.common.profile.http_profile import HttpProfile
from tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKException
from tencentcloud.ocr.v20181119 import ocr_client, models
try:
# Создайте экземпляр объекта аутентификации. Входные параметры необходимо передать в учетную запись Tencent Cloud. SecretId и SecretKey, здесь также нужно обратить внимание на конфиденциальность пары ключей
# Утечка кода может привести к SecretId и SecretKey Утечка и угроза безопасности всех ресурсов под аккаунтом. Следующий пример кода предназначен только для справки. Рекомендуется более безопасный способ использования, см. https://cloud.tencent.com/document/product/1278/85305.
# Ключ можно найти в консоли официального сайта. https://console.cloud.tencent.com/cam/capi Получать
cred = credential.Credential(SecretId, SecretKey)
# Создать экземпляр опции http, необязательно, можно пропустить, если нет особых требований.
httpProfile = HttpProfile()
httpProfile.endpoint = "ocr.tencentcloudapi.com"
# Создать экземпляр опции клиента, необязательно, можно пропустить, если нет особых требований.
clientProfile = ClientProfile()
clientProfile.httpProfile = httpProfile
# Создайте экземпляр объекта клиента для запроса продукта, clientProfile не является обязательным.
client = ocr_client.OcrClient(cred, "", clientProfile)
# Создайте экземпляр объекта запроса. Каждый интерфейс будет соответствовать объекту запроса.
req = models.RecognizeStoreNameRequest()
params = {
"ImageBase64": base64_encoded
}
req.from_json_string(json.dumps(params))
# Возвращенный ответ является экземпляром RecounceeStoreNameResponse, соответствующим объекту запроса.
resp = client.RecognizeStoreName(req)
# Выходная строка возвращает пакет в формате json
print(resp.to_json_string())
except TencentCloudSDKException as err:
print(err)Вызов возвращает результат:

Разработка происходит быстро и легко. Здесь мы анализируем развитие обработки OCR изображений кластера больших данных.
Распределенные кластерные вычисления больших данных
Архитектура кластера больших данных каждой компании непоследовательна.,Рекомендация по кластеру Hadoop: используйте Pyspark, который справится с этим лучше.,Конкретный принцип показан на рисунке:
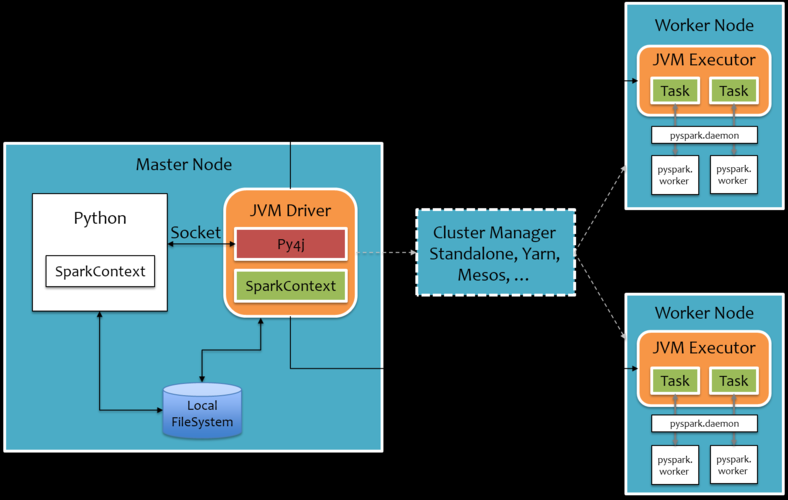
Основные вычисления передаются распределенному выполнению Hadoop, а не загружаются и обрабатываются на клиентских узлах PySpark, что является ключом к исправлению PySpark.
import pandas as pd
import numpy as np
from pyspark.sql import HiveContext
from pyspark.sql import SparkSession
from pyspark.sql import SQLContext
from pyspark import SparkContext
import json
import types
from tencentcloud.common import credential
from tencentcloud.common.profile.client_profile import ClientProfile
from tencentcloud.common.profile.http_profile import HttpProfile
from tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKException
from tencentcloud.ocr.v20181119 import ocr_client, models
def get_sparksession():
spark = SparkSession.builder \
.master("yarn")\
.appName("pyspark_TencentOCR") \
.enableHiveSupport()\
.getOrCreate()
return spark
def TencentOCR(base64_encoded):
cred = credential.Credential(SecretId, SecretKey)
# Создать экземпляр опции http, необязательно, можно пропустить, если нет особых требований.
httpProfile = HttpProfile()
httpProfile.endpoint = "ocr.tencentcloudapi.com"
# Создать экземпляр опции клиента, необязательно, можно пропустить, если нет особых требований.
clientProfile = ClientProfile()
clientProfile.httpProfile = httpProfile
# Создайте экземпляр объекта клиента для запроса продукта, clientProfile не является обязательным.
client = ocr_client.OcrClient(cred, "", clientProfile)
# Создайте экземпляр объекта запроса. Каждый интерфейс будет соответствовать объекту запроса.
req = models.RecognizeStoreNameRequest()
params = {
"ImageBase64": base64_encoded
}
req.from_json_string(json.dumps(params))
# Возвращенный ответ является экземпляром RecounceeStoreNameResponse, соответствующим объекту запроса.
resp = client.RecognizeStoreName(req)
# Выходная строка возвращает пакет в формате json
print(resp.to_json_string())
if __name__ == '__main__':
spark=get_sparksession()
sql_str="Извлечь изображение Base64"
df_dataframe=get_stable_link(sql_str)
df_test=TencentOCR(df_dataframe)
spark.stop()Кроме того, задача разработки была завершена, что можно назвать очень эффективным и удобным. В сочетании с ежемесячной бесплатной квотой Tencent Cloud на нее можно полностью положиться, если не будет принудительного самоисследования технологий для внутреннего спроса.
4. Перспективы транспортного OCR
Сочетание новейших технологий больших моделей с технологией оптического распознавания символов.,Точность информации о статусе дорожного движения повлияет на впечатления пользователя во время путешествия. традиционные дорожные условия,В основном он основан на предоставлении пользователями информации о траектории движения, пользовательских загрузках, общедоступной информации и других элементах, которые должны быть предоставлены пользователям после обработки с помощью технологии. Но на дорогах с небольшим количеством пользователей и ненормальным поведением при вождении.,Этот метод не может полностью гарантировать точность информации о состоянии трафика.
Если мы сможем идентифицировать алгоритм по видеоизображениям,Дорожные условия наблюдаются по видеоизображениям,Включая количество автотранспортных средств, ширину и открытость дороги, а также другие факторы для определения состояния дорожного движения (плавное, медленное, перегруженное).,Это повышает точность оценки состояния дороги.,Тем самым улучшая качество путешествий для пользователей карт.
Заглядывая в будущее, поскольку технологии больших моделей и OCR технологияиз深度融合,交通сцена下из智能识别Воляв дальнейшем расширен доАнализ состояния трафика、Динамические обновления данных в реальном времени等应用сцена。проходитьалгоритм提升对道路通行状态из准确判断,Картографический сервис Воля становится умнее,Повысьте точность и удобство путешествий для конечных пользователей C. я фанатик,Читатели, глубоко заинтересованные в технологии этой статьи, могут обсудить ее вместе.,Еще раз спасибо всем читателям за поддержку!



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
