ПримечаниеLLM: реализация большой языковой модели в системе рекомендаций Xiaohongshu.
Сегодня я делюсь статьей от Xiaohongshu за март этого года, в которой рассказывается о применении больших языковых моделей в сценариях рекомендаций по заметкам Xiaohongshu. В основном основное внимание уделяется тому, как использовать возможности представления LLM для генерации встраивания текста, которое больше подходит для вызова i2i. Идея проста и ее легко реализовать. Лично я считаю, что ее практическая ценность очень высока и ее стоит изучить.
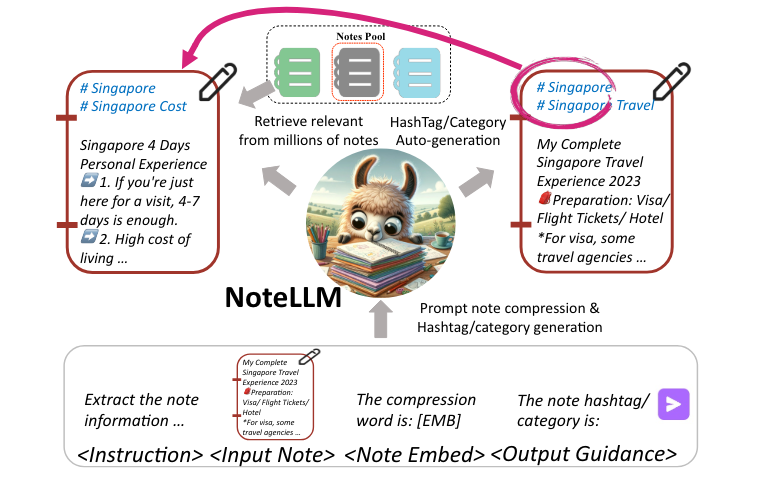
- NoteLLM: A Retrievable Large Language Model for Note Recommendation
- https://arxiv.org/abs/2403.01744
фон
Чтобы решить проблему холодного запуска рекомендуемых элементов, на этапе отзыва часто добавляется использование полного пути. i2i отзыв мультимодальных представлений контента Поскольку этот метод отзыва использует только функции чистого содержимого, его можно справедливо сравнивать со старыми элементами, и он не вызовет проблемы, заключающейся в том, что новые элементы не могут быть вызваны из-за меньшего апостериорного поведения.
Существующие мультимодальные методы возврата i2i обычно используют BERT на стороне текста для генерации вложений после предварительного обучения, а затем вызывают их на основе сходства вложений, но это также может иметь некоторые проблемы:
- Возможности представления BERT недостаточны. По сравнению с BERT, использование LLM с большим количеством параметров для генерации вложений может позволить изучить некоторую более длинную информацию. В то же время вложения, сгенерированные только с помощью BERT, могут представлять только семантическую информацию текста, которая является. несовместимо с целями последующих рекомендательных задач; несоответствие;
- Недостаточное использование информации о категории тегов。Изображение и текстпримечаниятеги и категории часто представляют его центральную идею,Решающее значение для определения того, связаны ли два примечания.,Однако существующий метод BERT рассматривает метки и категории только как неотъемлемую часть контента (фактически, когда BERT выполняет предварительное обучение, помимо задач MLM, также должны быть такие задачи, как метки/категории прогнозирования заголовков.,Этот аргумент кажется несостоятельным). Статья найдена,Процесс создания тегов и категорий с использованием контента примечания очень похож на создание встраивания примечания.,Все они посвящены ключевой информации примечания в ограниченном содержании.,поэтому Введение задачи создания меток и категорий может улучшить конечный результат.embeddingкачество。
Поэтому в статье предлагается метод многозадачного обучения под названием NoteLLM, Используйте ламу 2 в качестве магистрали с целью создания встраивания текста, более подходящего для рекомендательных задач. 。
В частности, для каждого образца сначала создается унифицированное приглашение на сжатие заметок, а затем используются две задачи предварительного обучения для улучшения встраивания текста.
- Задача называетсяГенеративное контрастивное обучение(Generative-Contrastive Learning),Это задание перенесет содержимое примечания в специальный токен.,Вектор, сгенерированный с помощью этого токена, можно использовать в качестве текстового представления примечания. В этой задаче сигналы совместной фильтрации используются в рекомендациях в качестве меток для сравнительного обучения.,Сначала рассчитываются баллы совместной встречаемости всех пар примечаний.,Затем используйте примечания с высоким показателем совпадения, чтобы соединить примечания с высокой корреляцией.,как положительный образец,Отрицательные образцы внутри партии,Обучение с использованием контрастного обучения,За счет внедрения совместной фильтрации сигналов,Таким образом, окончательно сгенерированное внедрение может быть более подходящим для последующих рекомендательных задач.
- Другая задача — сгенерировать теги и категории для примечаний, используя заголовок и содержание примечания.,называетсяСовместный контроль и тонкая настройка(Generative-Contrastive Learning),Эта задача может не только генерировать метки и категории.,в то же время,Потому что это похоже на процесс генерации вложений,Все они умеют извлекать ключевую информацию из текста.,поэтому,Введение этой задачи также улучшает встраивание примечания, созданное первой задачей.
Введение метода
Метод разделен на три части: построение входной подсказки и две предтренировочные задачи, используемые при обучении:
- Примечание. Подсказка о расширениястроения
- Генеративно-контрастное обучение
- Совместная контролируемая точная настройка
Примечание. Подсказка о расширениястроенияиспользуется для определения Модельввод во время обучения,Генеративное контрастивное обучение и совместный контроль и тонкая настройка соответствуют двум предтренировочным задачам.,Первый вводит сигналы совместной фильтрации в рекомендациях в качестве меток для сравнительного обучения с целью улучшения представления текста.,Последний фактически генерирует соответствующие теги и категории на основе содержания примечания.
Конкретный процесс заключается в следующем: во-первых, на этапе автономного обучения сначала создается большое количество соответствующих пар заметок на основе поведения пользователя в качестве обучающих выборок, а затем LLaMA 2 используется в качестве основы для обучения. с одной стороны, соответствующие пары заметок используются для сравнительного обучения, а с другой стороны, LLaMA 2 используется в качестве основы для обучения. Также была добавлена задача генерации заголовков и меток для улучшения качества предыдущего внедрения. online использует встраивание заметок, созданное моделью, для создания ИНС для вызова связанных заметок, а также может генерировать метки и категории заметок для помощи в других задачах.
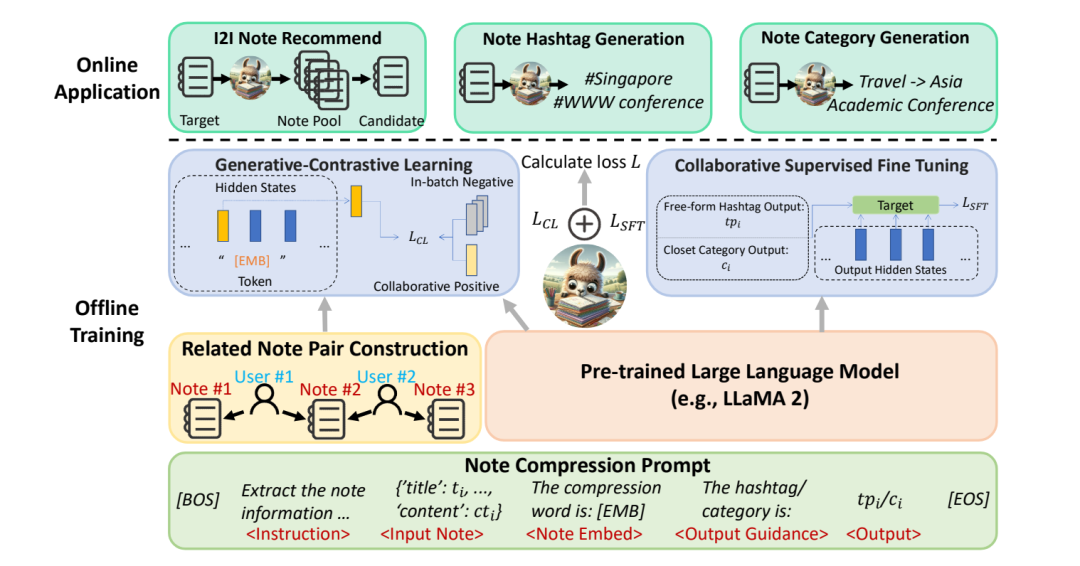
Примечание. Подсказка о сжатии
Здесь при построении подсказки были учтены две задачи предварительного обучения. С одной стороны, чтобы сжать текстовое содержимое заметки в токен, а затем использовать вектор, отображаемый этим токеном, для выполнения генеративного сравнительного обучения, которое также используется в качестве окончательного вывода. Текстовое представление, с другой стороны, мы также хотим использовать задачи создания меток и категорий для расширения возможностей текстового представления. Конкретный шаблон приглашения выглядит следующим образом:
Prompt: [BOS]<Instruction> <Input Note> The compression word is:"[EMB]". <Output Guidance> <Output>[EOS]
[BOS] представляет начало предложения, [EOS] представляет конец предложения, а [EMB] представляет токен, соответствующий окончательному текстовому представлению, которое будет выведено. Наконец, будет отображен скрытый вектор, соответствующий этому токену. через полностью связный слой для получения окончательного вектора представления.
При этом для генерации категорий и меток используются разные подсказки, но шаблоны одни и те же. В частности, если это генерация категории, то подсказка такая:
<Instruction>: Extract the note information in json format, compress it into one word for recommendation, and generate the category of the note. <Input Note>: {’title’: , ’topic’: , ’content’: }. <Output Guidance>: The category is: <Output>:
Если он используется для генерации меток, то приглашение будет таким:
<Instruction>: Extract the note information in json format, compress it into one word for recommendation, and generate <j> topics of the note. <Input Note>: {’title’: , ’content’: }. <Output Guidance>: The <j> topics are: <Output>: <j> topics from
Поскольку тегов много, большие модели могут создаваться непрерывно, поэтому теги j случайным образом выбираются из исходных тегов в качестве сгенерированного содержимого, и в приглашении указывается, что могут быть сгенерированы только теги j.
После завершения ввода конструкции подсказки скрытый вектор, окончательно выведенный специальным токеном [EMB], можно рассматривать как текстовое представление заметки, а соответствующие теги и категории также могут быть сгенерированы на основе содержимого заметки.
Генеративно-контрастное обучение
Хотя большая модель может представлять большой объем семантической информации после предварительного обучения с помощью SFT и RLHF, не обязательно использовать ее непосредственно в последующих рекомендательных задачах, главным образом потому, что задача предварительного обучения большой модели состоит в получении семантической информации. Информация, а задача последующей рекомендации не обязательно хороша. Целью рекомендации является рейтинг кликов, и между этими двумя целями существует разрыв. Таким образом, это генеративное сравнительное обучение заключается во внедрении рекомендуемых сигналов совместной фильтрации в предварительном обучении. больших моделей, так что сгенерированное внедрение больше подходит для последующих рекомендательных задач.
В частности, мы сначала подсчитываем, сколько раз каждый пользователь нажимает на ноту A, а затем нажимает на ноту B в течение одной недели, а затем рассчитывает показатель совместного появления в качестве сигнала для совместной фильтрации. Формула для расчета co. -оценка появления двух нот следующая:
Здесь U — количество пользователей,
Количество кликов, представляющих пользователей, на самом деле снижает вес активных пользователей, чтобы некоторые высокоактивные пользователи не нажимали на все заметки, что приводит к неточным расчетам оценок совместного появления.
После расчета показателя совместного появления всех нот затем применяется порог для фильтрации нот ниже или выше определенного порога. Наконец, для каждой ноты получается набор связанных с ней нот, а затем положительные выборки пар нот. строятся попарно в качестве входных данных.
Далее для каждой ноты используйте
Вектор, полученный путем сопоставления скрытого вектора этого специального токена через полносвязный слой, используется в качестве вектора текстового представления.
, вы можете использовать сравнительное обучение для обучения. Положительный образец — это построенная связанная пара нот, а соответствующий вектор обозначается как.
, отрицательные образцы принимают отрицательную выборку внутри партии, и соответствующий вектор обозначается как
, функция потерь использует Info-NCE контрастного обучения:
При вычислении сходства используется косинусное сходство, sim(a,b)=a^\top b/(|a||b|)
Обучая таким образом, LLM может получить некоторую информацию, связанную с поведением пользователей, тем самым создавая более качественные текстовые представления для выполнения последующих задач по рекомендациям.
Кстати, эта идея на самом деле аналогична CB2CF, упомянутой в другой статье, опубликованной Сяохуншу ранее, за исключением того, что в другой статье использовались как текстовые, так и графические функции, а функция потерь использовала перекрестную энтропию.
Совместная контролируемая точная настройка
На самом деле эта задача представляет собой SFT, выполняющую задачи по созданию меток/категорий. Можно добавить слово «совместная работа», поскольку оно соответствует GCL, в котором ранее была введена совместная фильтрация сигналов. Почему в статье упоминаются две причины:
- Создание встраивания предложений с использованием только LLM немного похоже на стрельбу по комарам из пушки.,Мощные генерирующие возможности LLM не используются полностью. Предполагается, что сгенерированные метки и категории также могут использоваться в некоторых других сценариях.,Например, когда у некоторых примечаний не хватает тегов,Или, если категория неверна, для дополнения информации можно использовать LLM.
- Можно улучшить предыдущий шаг Генеративное контрастивное обучение Качество генерируемого встраивания. Это связано с тем, что генерация тегов/категорий аналогична генерации встраивания примечания, которое предназначено для подвести. Итог всего примечания к содержанию. Следовательно, добавление этой задачи предварительного обучения может улучшить качество окончательно сгенерированного внедрения.
В частности, в CSFT прогнозирование категорий и меток должно выполняться одновременно. В статье упоминается, что для повышения эффективности обучения и предотвращения проблем с забыванием из каждого пакета для задачи создания метки будут выбраны r заметок, а остальные заметки. будет выделено для задач генерации категорий. Функция потерь CSFT выглядит следующим образом. Она фактически рассчитывает потери токена в выходной части:
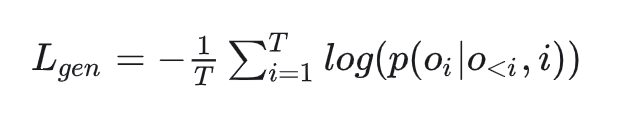
Потеря окончательной модели представляет собой сумму двух членов и выражается выражением
В качестве суперпараметра контролируйте вес двух потерь:
Результаты эксперимента
Офлайн-эксперимент
Офлайн-эксперимент в основном сравнивается с онлайн-базой SentenceBERT и некоторыми другими методами генерации вложений текста с использованием больших моделей.,Используйте Recall@k в качестве индикатора оценки.,Эффект будет лучше,Вывод:NoteLLM>=Точная настройка другими методамиLLM>>BERTтонкая настройка>>LLM zero-shot
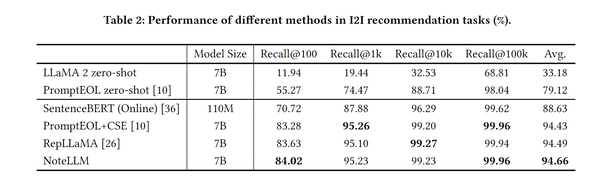
В то же время, разделив показатели на банкноты с разными уровнями воздействия, было обнаружено, что NoteLLM более последовательно улучшался на банкнотах с разными уровнями воздействия. Кроме того, можно обнаружить, что скорость запоминания каждого метода на банкнотах с низким уровнем воздействия. намного выше, чем у заметок с высоким уровнем воздействия, что указывает на то, что метод встраивания на основе содержимого может более эффективно вызывать элементы с холодным запуском.
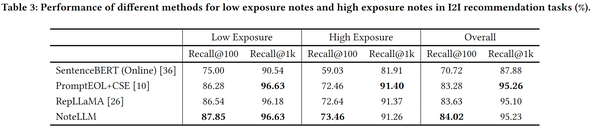
эксперимент по абляции
Эта статья также представляет собой эксперимент по абляции,Удалите задачу CSFT и задачу GCL соответственно.,И используйте разные соотношения данных для создания категорий ярлыков в GCL.,Оказывается, есть две незаменимые части.,здесь можно узнать, что задача GCL играет наиболее важную роль,Задачи прогнозирования категорий и создания меток кажутся необязательными для общего эффекта.,Кажется, что использование только цели совместной фильтрации для контрастного обучения также может сработать.
Онлайн-эксперимент
В статье говорилось, что после недели экспериментов с ab по сравнению с предыдущим базовым показателем SentenceBERT рейтинг кликов NoteLLM увеличился на 16,20%, количество комментариев увеличилось на 1,10%, а среднее количество еженедельных издателей (WAP) увеличилось на 0,41. %. Результаты показывают, что внедрение LLM в задачи рекомендаций i2i может улучшить производительность рекомендаций и удобство работы пользователей. Кроме того, наблюдался значительный рост на 3,58% количества комментариев к новым заметкам за один день. Это показывает, что внедрение LLM выгодно при холодном запуске. NoteLLM наконец-то полностью запущен в режиме онлайн.
Подвести итог
Хотя существует бесконечный поток документов, используемых LLM для выработки рекомендаций, сколько из них действительно можно реализовать? В настоящее время лучший способ реализовать большие модели в бизнес-алгоритмах, таких как поиск и рекомендации, — это использовать их для маркировки и создания полезных вложений или других функций для последующих задач. Эта статья представляет собой очень хороший пример, достойный внимания не только. Может ли он генерировать более качественные текстовые представления для выполнения последующих задач рекомендаций, он также может генерировать некоторые метки и категории, которые можно использовать для помощи в задачах в других сценариях. Общая реализация по-прежнему очень проста.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
