Предварительное исследование векторной базы данных pgvector
Обзор
pgvector — это расширение PostgreSQL с открытым исходным кодом, которое действует как управляющий векторными данными, обрабатывая все: от встраивания хранилища до поиска сходства векторов. В качестве важного вспомогательного средства для больших языковых моделей, таких как большая модель Tencent Hunyuan, он использует векторы для представления данных и находит соответствующие результаты путем измерения сходства между этими векторами. Это выводит скорость и точность получения актуальной информации на новый уровень. Можно сказать, что pgvector очень подходит для сценариев, в которых обрабатываются крупномасштабные данные, и имеет отличную производительность в задачах, требующих корреляционного поиска и обработки многомерных данных.
Процесс использования pgvector подобен созданию эксклюзивного векторизатора данных, шаги просты и понятны. Сначала включите «векторное» расширение PostgreSQL и создайте таблицу данных для хранения векторов. Затем характеристические данные каждого образца можно сохранить в базе данных в векторной форме. После того, как все настроено, вы можете использовать pgvector для выполнения запросов на сходство ко всем вашим векторным данным.
Прелесть pgvector в том, что он не только специализируется на обработке векторных данных, но и предоставляет разработчикам все преимущества PostgreSQL как объектно-реляционной системы баз данных, которая разрабатывалась и оптимизировалась на протяжении 35 лет. Другими словами, pgvector не только сохраняет надежность, устойчивость и производительность PostgreSQL, но также расширяет возможности PostgreSQL за счет эффективной технологии векторного поиска и обработки. Мощные возможности векторной обработки и богатые функции делают pgvector, несомненно, лучшим выбором для обработки векторных данных.
В этой статье в основном показан процесс создания таблицы библиотеки pgvector и использования Python для доступа к измененной таблице библиотеки.
Используйте Docker для создания pgvector
Входитьhttps://hub.docker.com/r/ankane/pgvector,Получить загрузку Docker Команда зеркального отображения изображения.
docker pull ankane/pgvector
docker run --name pgvector -v $(pwd)/data:/var/lib/postgresql/data -e POSTGRES_PASSWORD=Ваш пароль -p 5432:5432 -d ankane/pgvectorИспользуйте psql для создания библиотечных таблиц
psql --help
psqlдаPostgreSQL интерактивный клиентский инструмент.
Как использовать:
psql [параметры]... [имя базы данных [имя пользователя]]
Распространенные варианты:
-c, --command=команда Выполните одну команду (SQL или внутреннюю команду) и завершите
-d, --dbname=DBNAME Укажите базу данных для подключения (По умолчанию: «хуйян»)
-f, --file=имя файла Выполнить команду из файла и выйти
-l, --list Вывести список всех доступных баз данных и выйти.
-v, --set=, --variable=NAME=VALUE
Установите для переменной psql ИМЯ значение ЗНАЧЕНИЕ.
(Например, -v ON_ERROR_STOP=1)
-V, --version Информация о версии вывода, затем выйдите
-X, --no-psqlrc Не читает файл запуска (~/.psqlrc)
-1 ("one"), --single-transaction
Выполнить командный файл как одну транзакцию (если он неинтерактивный)
-?, --help[=options] Показать эту помощь,затем выйдите
--help=commands Список команд обратной косой черты,затем выйдите
--help=variables список специальных переменных,затем выйдите
Варианты ввода и вывода:
-a, --echo-all Показать все входные данные из сценария
-b, --echo-errors Эхо неудавшихся команд
-e, --echo-queries Отображение команд, отправленных на сервер
-E, --echo-hidden Показать запросы, созданные внутренними командами
-L, --log-file=имя файла Записать журнал сеанса в файл
-n, --no-readline Отключить расширенное редактирование командной строки (readline)
-o, --output=FILENAME Записывать результаты запроса в файл (или |Трубопровод)
-q, --quiet Запуск в тихом режиме (без сообщений, только результаты запроса)
-s, --single-step одношаговый режим (подтвердите каждый запрос)
-S, --single-line однострочный режим (Только одна строка в строке) SQL Заказ)
Параметры формата вывода :
-A, --no-align Использовать режим вывода невыровненной таблицы
--csv Режим вывода таблицы CSV (значения, разделенные запятыми)
-F, --field-separator=STRING
Установить разделитель для полей, используемый для неаккуратного вывода (по умолчанию: «|»)
-H, --html HTML Режим вывода таблицы
-P, --pset=переменная[=параметр] Установите опции для печати переменных в параметрах (см. \pset Заказ)
-R, --record-separator=STRING
Устанавливает символ-разделитель для неаккуратного вывода (по умолчанию: новая строка)
-t, --tuples-only Распечатать только запись i
-T, --table-attr=текст настраивать HTML Свойства разметки таблицы (например, ширина, поля)
-x, --expanded Включить расширенный вывод таблицы
-z, --field-separator-zero
Установите разделитель полей на байт 0 для неаккуратного вывода.
-0, --record-separator-zero
Установите разделитель записей на байт 0 для неаккуратного вывода.
Варианты присоединения:
-h, --host=имя хоста Каталог хоста или сокета сервера базы данных (по умолчанию: «локальный интерфейс»)
-p, --port=порт Порт сервера базы данных (по умолчанию: «5432»)
-U, --username=имя пользователя Укажите имя пользователя базы данных (по умолчанию: «postgres»)
-w, --no-password Никогда не запрашивать пароль
-W, --password Принудительный запрос пароля (автоматический)
Для получения дополнительной информации введите «\?» (для внутренних команд) в psql или "\help" (для SQLЗаказ),
Или обратитесь к главе psql в документации PostgreSQL.
Сообщайте о постельных клопах<pgsql-bugs@lists.postgresql.org>.
PostgreSQL Дом: <https://www.postgresql.org/>Войдите в PostgreSQL
поэтому,Используйте следующую команду Войдите в PostgreSQL,
psql -h localhost -p 5432 -U postgres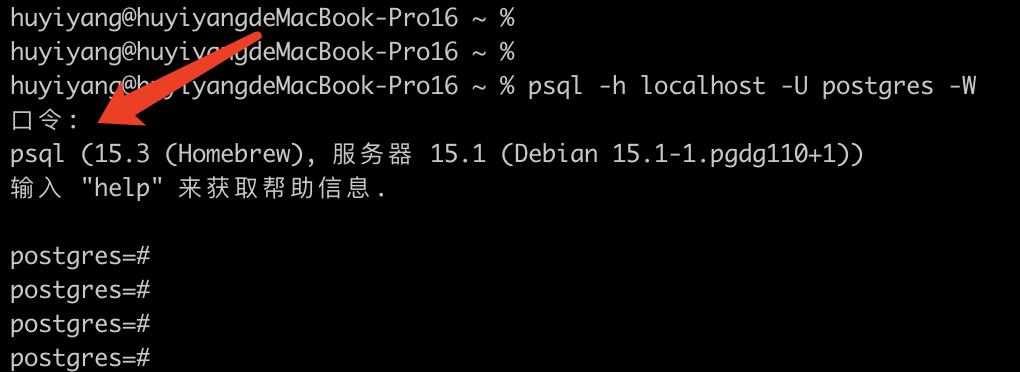
Введите пароль для входа в PostgreSQL.
Посмотреть список всех баз данных
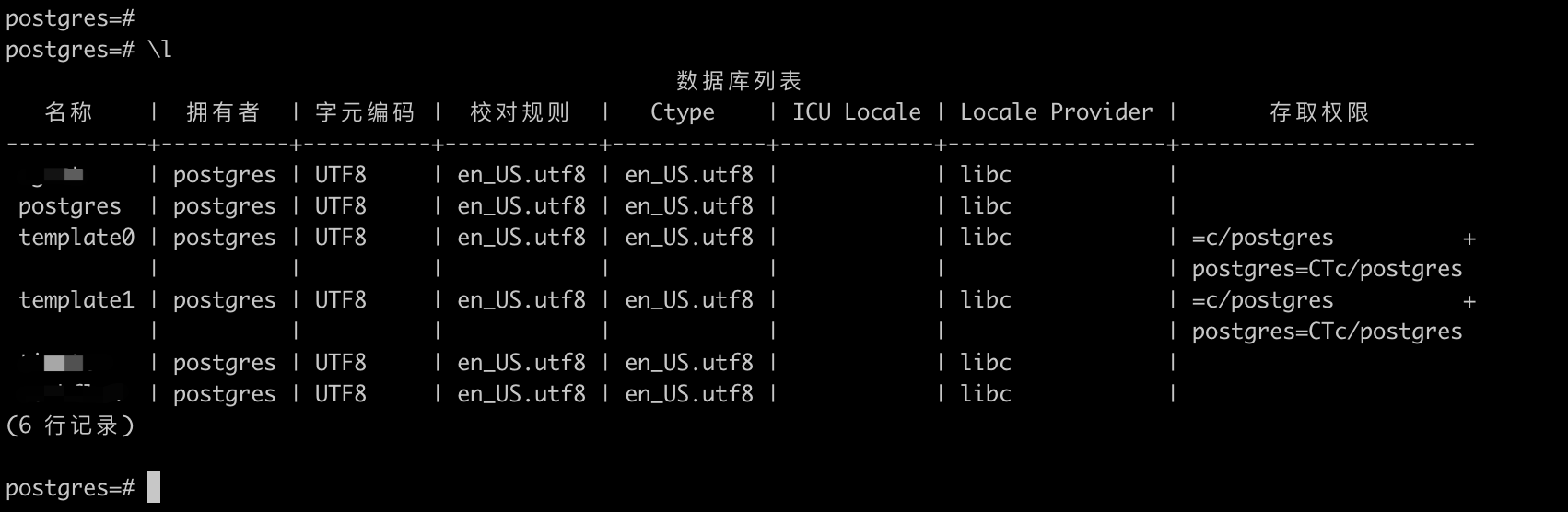
Чтобы просмотреть список всех баз данных в текущей базе данных, вы можете использовать следующую команду SQL:
\lВыполнение этой команды в командной строке psql отобразит список всех баз данных, включая имя базы данных, владельца, кодировку, описание и другую информацию.
Переключиться на другую базу данных
существовать PostgreSQL середина,хотеть Переключиться на другую базу данных,Вы можете использовать следующее Заказ:
\c database_nameЭто соединит вас с базой данных с именем имя_базы_данных. Если подключение установлено успешно, в командной строке отобразится имя новой базы данных, что указывает на то, что вы успешно переключились на нее.

Создать новую базу данных
хотетьсуществовать PostgreSQL середина Создать новую базу данных,ты Вы можете использовать следующее Заказ:
CREATE DATABASE database_name;существоватьэта командасередина,database_name — имя базы данных, которую вы хотите создать. После выполнения этой команды появится новый файл с именем database_name база данных.
Показать список всех таблиц
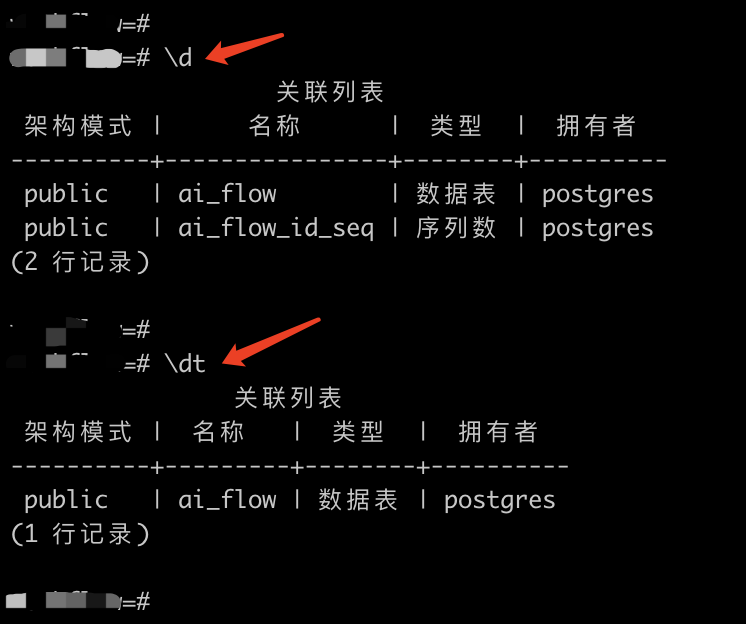
существовать PostgreSQL в,\д Используется для отображения информации об объектах базы данных. Вы можете запустить его одним из двух способов:
\d
\dtПриведенная выше команда отобразит список всех таблиц в текущей базе данных. Он отображает имя таблицы, тип таблицы (например, таблица, представление и т. д.), владельца и другую информацию.
С другой стороны, \dt да \d Подмножество команд, предназначенное для вывода списка всех таблиц в базе данных. Это связано с \d Разница между существованием и \d Также перечислены другие типы объектов базы данных, такие как представления, индексы, последовательности и т. д.
Если вас интересуют только таблицы, использование \dt более интуитивно понятно и конкретно.
Посмотреть структуру таблицы
существовать PostgreSQL в,\д table_name используется для отображения структуры таблицы базы данных.
\d table_name
Доступ к pgvector с помощью Python sqlalchemy
SQLAlchemy
SQLAlchemy да Python Набор языков программирования ORM структуру, которая обеспечивает всеобъемлющую SQL интерфейс. Его основная цель — помочь существующим разработчикам работать с базовой базой данных, предоставляя при этом мощный и простой в использовании инструмент. Python API。
Пример кода
from sqlalchemy import create_engine, Table, MetaData
from sqlalchemy.dialects.postgresql import array
from sqlalchemy.sql import select
engine = create_engine('postgresql://username:password@localhost/dbname')
metadata = MetaData()
vector_table = Table('vector_table', metadata, autoload_with=engine)
# Insert vectors
with engine.connect() as connection:
data = {'id': 1, 'vector': array([0.1, 0.2, 0.3, 0.4])}
connection.execute(vector_table.insert().values(data))
# Query vectors
with engine.connect() as connection:
query = select([vector_table.c.vector]).where(vector_table.c.id == 1)
result = connection.execute(query)
for row in result:
print(row)существуют в приведенном выше примере,Мы создали движок SQLAlchemy, включающий базу данных PostgreSQL, с которой можно взаимодействовать. Затем,Определяем таблицу (vector_table),Эта таблица существует и фактически хранится в базе данных.,Содержит наши векторные данные.
затем,Вставьте новый вектор в нашу базу данных существования.,Затем запросите таблицу существования для идентификатора равного 1 вектора.
Обратите внимание, что это только базовый пример, в реальных ситуациях может потребоваться обработка более сложных запросов и операций.
Подвести итог
в общем,pgvector как расширение векторного поиска,Функциональное расширение PostgreSQL нельзя игнорировать. Путем воплощения существования векторного поиска сходства и обработки встраивания и т.д.,Практическая польза, которую оно приносит, вполне заслужена. Являетесь ли вы разработчиком,Также специалист по машинному обучению,Если вы ищете эффективный способ работы с векторными данными,pgvector — вариант, который стоит попробовать.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
