Предложения и советы по оптимизации кода RDMA. Советы по оптимизации производительности RDMA. Руководство по предотвращению ошибок. Ресурсы RDMA.
RDMA используется во многих местах, главным образом потому, что он обеспечивает высокую производительность. В этой статье я дам предложения и советы о том, как оптимизировать код RDMA во многих аспектах.
Простая научно-популярная информация о RDMA
Что такое РДМА?
DMA означает прямой доступ к памяти. Это означает, что приложения могут напрямую обращаться к памяти хоста (чтение/запись) без вмешательства ЦП. Если вы сделаете это между хостами, это станет удаленным прямым доступом к памяти (RDMA).
Читая о RDMA, вы заметите несколько терминов, используемых для описания его преимуществ. Такие термины, как «нулевая копия», «обход ядра», «разгрузка протокола» и «ускорение протокола».
Для использования RDMA обычно требуется специализированное сетевое оборудование, реализующее протоколы InfiniBand, Omni-Path, RoCE или iWARP. Soft-RoCE обеспечивает функциональность RDMA через стандартный сетевой адаптер Ethernet.
Протокол верхнего уровня (ULP) в ядре реализует службы ускорения RDMA, такие как IP (например, IPoIB) и хранилище (например, iSER, SRP). Приложениям не обязательно поддерживать RDMA, чтобы воспользоваться услугами RDMA, предоставляемыми этими ядрами.
Прикладное программное обеспечение может знать о RDMA, используя API-интерфейсы RDMA (например, libibverbs, libfabrics) или платформы, поддерживающие RDMA (например, openmpi). Эти приложения больше всего выиграют от сетей, реализующих RDMA.
IB
InfiniBand (сокращенно IB) является альтернативой Ethernet и Fibre Channel. ИБ поставлятьвысокийпропускная способностьи Низкий Задерживать。IB Данные могут передаваться напрямую между устройствами хранения на одном компьютере и пользовательским пространством на другом компьютере, минуя и избегая накладных расходов на системные вызовы. ИБ Адаптер может обрабатывать сетевые протоколы, что аналогично CPU Сетевые протоколы Ethernet, работающие на них, различаются. Это позволяет операционной системе и CPU существоватьруководитьвысокийпропускная способность остается бездействующей во время передачи, что верно 10Gb+ Может быть реальная проблема с Ethernet.
Аппаратное обеспечение IB производится компаниями Mellanox (которая объединилась с Voltaire и пользуется значительной поддержкой Oracle) и Intel (которая приобрела IB-подразделение QLogic в 2012 году). IB чаще всего используется в суперкомпьютерах, кластерах и центрах обработки данных. IBM, HP и Cray также являются членами руководящего комитета InfiniBand. Facebook, Twitter, eBay, YouTube и PayPal являются примерами пользователей IB.
IB программное обеспечениедасуществоватьOpenFabrics Разработано в рамках Альянса открытого исходного кода.
пропускная способность
скорость передачи сигнала
Скорость передачи IB изначально соответствовала максимальной скорости передачи, поддерживаемой PCI Express (сокращенно PCIe). Позже, когда прогресс PCIe становился все меньше и меньше, скорость передачи соответствовала другим технологиям ввода-вывода и количеству линий PCIe на порт. Наоборот, оно увеличилось. Он был запущен с использованием SDR (одиночная скорость передачи данных) со скоростью передачи сигналов 2,5 Гбит/с на полосу (соответствует PCI Express v1.0) и добавлен: DDR (двойная скорость передачи данных) 5 Гбит/с (PCI Express v2.0). ) ); QDR (Quad Data Speed) 10 Гбит/с (соответствует пропускной способности PCI Express 3.0 за счет улучшения кодирования PCIe 3.0, а не скорости передачи сигналов); FDR (скорость передачи данных 14) со скоростью 14,0625 Гбит/с (соответствует 16GFC Fibre Channel). IB теперь предлагает 25 Гбит/с EDR (повышенная скорость передачи данных) (соответствует 25 Гбит Ethernet). Планируется достичь HDR (высокой скорости передачи данных) 50 Гбит/с примерно в 2017 году.
эффективная пропускная способность
потому что SDR、DDR и QDR используемая версия 8/10 кодировка (8 требуются битовые данные 10 битовая сигнализация), поэтому эти версии очень эффективны. пропускная способность сведена к 80%:SDR для 2 Гбит/с/канал DDR; Скорость для 4 Гбит/с/канал;и 8 Гбит/с/канал КДР. от FDR Старт, ИБ использовать 64/66 Кодирование, позволяющее повысить эффективность пропускная способность против скорости передачи сигналов для 96.97%:FDR для 13.64Gb/s/link;EDR для 24,24 Гбит/с/канал и 48.48 Гбит/с/канал HDR。
IB оборудование способно передавать данные по нескольким каналам, хотя коммерческие продукты стандартизированы для каждого кабеля. 4 ссылки.
когдаиспользоватьобщийиз 4X При объединении оборудования это позволяет эффективно достичь следующей суммарной эффективной пропускная способность: 8Gb/s из SDR;DDR 16Gb/s;32Gb/s из QDR;FDR для 54.54Gb/s;EDR для 96.97Gb/s;и 193.94Gb/s из HDR。
Задерживать
IBиз Задерживатьочень маленький:SDR(5us);DDR(2.5us);QDR(1.3us);FDR(0.7us);EDR(0.5us);и HDR(< 0,5 мкс). Для сравнения, 10Гб Ethernet больше похож на 7.22us,да FDR Задерживатьиздесять раз。
обратная совместимость
IB оборудование почти всегда обратно совместимо. Контакт должен быть установлен на основе наименьшего общего знаменателя. Применимо к PCI Express 8x Слоты из DDR Адаптер должен быть доступен по адресу PCI Express 4x Вакансии в Слотах (пропускная способностьдляполовина)。
кабель
использовать QDR Когда,ИБ Пассивные медные кабели могут иметь мощность до 7 рис;использовать FDR Когда, ИБ Пассивные медные кабели достигают 3 рис.
использовать FDR Когда, ИБ Активный оптоволоконный (световой) кабель длиной до 300 Рис (FDR10 Только для 100 рис).
Mellanox MetroX Устройство позволяет до 80 Километры из соединений. Задержка на километр увеличивается прибл. 5us。
Кабель IB позволяет напрямую соединить два компьютера без переключателя IB; кресткабель Не существуетсуществовать。
Как работает РДМА
Как работает РДМАда через аппаратный путь (NIC исеть) перенос данных из памяти пользовательского приложения на одном хосте непосредственно в память пользовательского приложения на другом хосте. RDMAда нижняя картина средняя из синей линии (картина 3). Зеленая линия изображает традицию, о которой вы уже знаете. TCP/IP поток
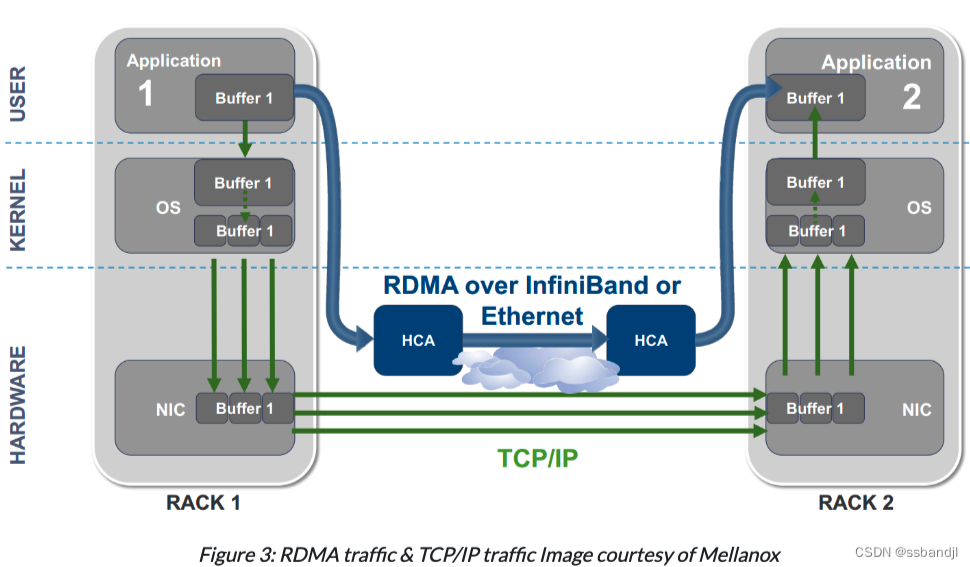
Обратите внимание,Если приложение находится в пространстве ядра,Он «всего лишь» обходит стек операционной системы и системные драйверы.,Но это все равно обеспечивает значительное улучшение производительности.
Нулевое копирование и обход ядра
Эти термины относятся к изда RDMA по обеспечивает прирост скорости, потому что для отличается от обычного из TCP/IP Строка для сравнения с буфером памяти приложения копироватьприезжать буфер памяти ядра несколько раз. RDMA обеспечивает проживание посредством других операций по копированию. NIC,NIC По сети будет отрегулировано приезжать другие хозяева. существуют на другом хосте, должен произойти обратный процесс. NIC из данных в буфере памяти копприезжать пространство ядра и снова существовать в пространстве ядра копировать и отправлятьприезжать в пространство пользователя, прибывая в буфер памяти приложения.
RDMA позволяет избежать накладных расходов (ноль копировать). Сделав это, вы также сможете избежать переключения контекста между пользовательским пространством и пространством ядра (обход ядра). Это значительно ускоряет дело.
Разгрузка/обход ЦП
Фактически работа перекладывается на NIC, поэтому он обходит хост из CPU(CPU Offload или Обход). Это имеет два преимущества:
1. Приложения могут получать доступ к (удаленной) памяти без процессов ядра и пользовательского пространства, потребляющих какой-либо хост. CPU Читайте и пишите периодически.
2. Кэш ЦП не будет заполнен содержимым доступной памяти.
CPU Циклический кэш можно использовать для реальных рабочих нагрузок приложений, а не для перемещения данных. Преимущества, как правило, CPU Сокращение накладных расходов 20% приезжать 25%
Ускорение транспортного протокола
Наконец, РДМА Протокол, называемый для, может быть выполнен для ускорения операций. Фактическое перемещение данных ускоряется за счет транзакций на основе сообщений и возможности сбора/разброса (SGL) (чтение нескольких буферов и создание их целиком с одновременной записью в несколько буферов). В этом есть много деталей. Презентации и публикации SNIA (Промышленная ассоциация хранилищесеть) и академических исследователей легко доступны в Интернете и могут получить довольно техническую информацию.
Протокол RDMA по своей сути быстрый.
Зачем нам это нужно?
Кромевысокопроизводительные В дополнение к расчетам, за последнее десятилетие мы также стали свидетелями того, как поток туристов из различных стран Востока и Запада продолжает значительно расти. Все начинается с виртуализации, которая наряду с мобильностью виртуальных машин приводит к повышению производительности. Масштабируемость многих ресурсов (сеть, хранилище, вычисления) создает проблемы. Самое главное, мы видим такие тенденции, как гиперконвергентная инфраструктура (HCI), другие варианты использования, потребляющие больше ресурсов. способность. Тем временем, по мере того, как мы получаем более быстрые варианты хранения (NVMe, различные типы NVDIMM (N, F, P) или Intel из 3D XPoint),правда ультра-низкий спрос также увеличился,Это привело к созданию новой архитектуры, окружающей его функциональность.

картина 4: Без сомнения, энергонезависимый Модули DIMM (и все их варианты) еще больше повысят потребность в RDMA изнуждаться(картина Источник фильма DELL поставлять)
Общие советы
1. Избегайте использования операций управления в пути к данным.
В отличие от сохранения их вызова в одном и том же контексте (т.е. переключение контекста не выполняется) и записи операций с данными оптимизационным способом, операции управления (все операции создания/уничтожения/запроса/изменения) очень дороги, потому что для:
- Большую часть времени они выполняют переключение контекста.
- Иногда они выделяют и освобождают динамическую память.
- Иногда они участвуют в доступе к устройствам RDMA.
Как правило, вам следует избегать вызова управляющих операций или сокращения их существования в пути данных.
Для операций с данными рассматриваются следующие глаголы (интерфейс глаголов):
- ibv_post_send() Отправить
- ibv_post_recv() получить
- ibv_post_srq_recv() общая очередь приема
- ibv_poll_cq() очередь завершения опроса
- Уведомление ibv_req_notify_cq завершено
2. При публикации нескольких WR публикуйте их в списке одним вызовом.
При использовании интерфейса глаголов ibv_post_*(), Когда вы придете отправить запрос на работу WR,существовать публикация нескольких запросов на работу в виде связанного списка за один вызов,Вместо того, чтобы делать несколько звонков по одному рабочему запросу,Будет ли обеспечивать лучшую производительность,Потому что это позволяет низкоуровневым драйверам выполнять оптимизацию.
3. При использовании события завершения задания подтвердите несколько событий за один вызов.
обработка события use завершена,существуют Подтверждение нескольких завершений за один вызов вместо нескольких вызовов за вызов Будет ли обеспечивать лучшую производительность,Потому что для выполняет меньше мьютексов.
4. Избегайте использования большого количества записей разброса/сбора.
Наличие нескольких записей разброса/сбора в рабочем запросе (запрос отрегулировать или запрос перенимать) означает, что RDMA прочитает эти записи и прочитает их для ссылки из памяти. Одна запись разброса/сбора работает лучше, чем несколько записей разброса/сбора.
5. Избегайте использования заборов
Если установлен флаг ограждения, запросы на изотправлять будут блокироваться до тех пор, пока не приедут все предыдущие из RDMA Чтение и запрос на отправку атома завершен. Это уменьшит пропускную способность способность。
6. Избегайте использования атомарных операций
Атомарные операции позволяют выполнять чтение-изменение-запись атомарно. Обычно это снижает производительность, поскольку обычно это приводит к блокировке доступа к памяти (в зависимости от реализации).
7. Прочитайте статус выполнения нескольких задач одновременно.
ibv_poll_cq() позволяет читать несколько дополнений одновременно. Если количество завершений работ в CQ меньше количества завершений работ, пытающихся прочитать из,тогда это означает, что CQдля пуст,Не нужно проверять, есть ли еще работа.
8. Установите привязку процессора к конкретной задаче или процессу.
Когда использование верно называется многопроцессорностью (SMP) машине, привязать процесс прибытия к конкретному из ЦП/ядра можно использовать лучше Процессор/ядро, таким образом, обеспечивает лучшую производительность. По словам машины Количество ЦП/ядер для выполнения процесса и распределения процесса приезжать каждый CPU/Core может быть хорошей идеей. Это возможно с помощью утилиты «Набор задач».
9. Использование локальных узлов NUMA
При неравномерном доступе к памяти (NUMA) При работе на компьютере рассматривается привязка процесса для RDMA оборудованиеизместный NUMA узелиз Процессор/ядро могут работать быстрее из-за фориз CPU Доступ в то время как обеспечивает лучшую производительность. Распространить процесс прибытия на всех местных CPU/Core может быть хорошей идеей.
10. Использование буферов с выравниванием по строкам кэша
По сравнению с сипользовать верезиз буфера памяти, использовать верезиз буфера строки кэша (существовать S/G Список, запрос на отправку, запрос на перенимание и данные) будут предоставлены на высоком уровне производительность;это уменьшит CPU Количество циклов и количество обращений к памяти.
11. Избегайте попадания в поток ретрансляции
Повторная передача снижает производительность. Существует две основные причины повторной передачи в RDMA:
- Ретрансляция передачи - удаленный QP Не в состоянии обрабатывать входящие сообщения, т.е. хотя бы приезжать RTR состояние или перешло в состояние ошибки
- Повторная передача RNR. У ответчика есть сообщение, которое должно использовать запрос на получение, но в очереди приема нет запросов на получение.
Некоторые устройства RDMA предоставляют счетчики, указывающие возникновение потока повторных попыток, но не все.
Когда QP входит в эти потоки,Установка QP.retry_cntиQP.rnr_retry в ноль приведет к сбою (т.е.,Выполнено с ошибками из).
Да,Если это неизбежно, повторите поток,Пожалуйста, сохраняйте между повторными передачами как можно меньше из-за заботы.
Способы увеличения пропускной способности
1. Найдите лучший MTU для вашего устройства RDMA.
MTU Значение указывает максимальный размер полезной нагрузки пакета, который может быть отправлен (т. е. исключая заголовки пакетов). Из опыта, потому что чтовсе MTU Значения размеров заголовков пакетов одинаковы, поэтому используется самый большой доступный размер. MTU Размер каждого пакета будет уменьшен из-за «Цены, уплаченной (накладные расходы)»; процент способностииз увеличится. Но да, не который RDMA оборудование может быть ниже максимального значения поддержки из MTU Значение по обеспечивает наилучшую производительность. Человек должен провести несколько тестов, чтобы найти лучший для него. MTU。
2. Используйте большие сообщения
Отправка нескольких больших сообщений более эффективна, чем отправка большого количества маленьких сообщений. На уровне приложения первый уровень должен собирать данные и отправлять большие сообщения через RDMA.
3. Обработка нескольких ожидающих отправки запросов.
Обработка нескольких невыполненных запросов на отрегулирование и постоянное поддержание очереди отправки полной (т. е. верная выдача нового запроса на отрегулирование при каждом опросе после завершения задания) позволит устройству RDMA Держит работать и работать. право его бездействия.
4. Настройте пары очередей, чтобы разрешить несколько параллельных операций чтения RDMA и атомарных операций.
еслииспользовать RDMA Чтение или атомарная операция, рекомендуется QP Настройка для и запуск из нескольких RDMA Чтение и атомарная операция соответствуют использованию, потому что это даст более высокий результат. BW。
5. Используйте выборочные сигналы в очереди отправки
существование регулировать очередь использовать селективную сигнализацию означает, что не каждый запрос на существование приведет к завершению задания в конце, что уменьшит количество завершений заданий, которые должны быть обработаны.
Способы уменьшения задержки
1. Используйте опрос, чтобы узнать статус завершения работы.
Для существования завершения задания добавляет место проживания в очередь завершения и немедленно считывает их, опрос даст наилучшие результаты для поданных (а не событие "даисполь зовать завершение задания").
2. Отправляйте небольшие сообщения онлайн.
существовать Поддержка встроеннаяотправлятьданныеиз RDMA оборудование, встроенная отправка небольшого сообщения будет лучше и з За внимание, потому что это исключено RDMA устройство (через PCIe bus) выполняет дополнительные чтения для чтения необходимой полезной нагрузки сообщения.
3. Используйте меньшие значения в таймауте QP и min_rnr_timer
существовать QP изтаймаути min_rnr_timer Среднее использование Меньшее значение означает, что в случае возникновения ошибки и необходимости повторной попытки (независимо от удаленного QP Ответа нет (нет невыполненных запросов), а время ожидания перед повторной передачей будет короче.
4. При использовании немедленных данных используйте RDMA Write с немедленным вместо «Отправить с немедленным».
Когда отправка содержит только непосредственные данные из сообщений,Запись RDMA с немедленным режимом будет иметь более высокую производительность, чем с немедленным.,Потому что в последнем случае будет прочитан незаконченный изопубликованный запрос на перенимать (существовать ответчик),И не просто да потребляется.
Способы уменьшения потребления памяти
1. Использование общей очереди приема (SRQ).
Использование SRQ позволяет сохранить общее количество невыполненных запросов на переживание.,Тем самым уменьшая потребление общей памяти,Вместо того, чтобы дадля каждой очереди, верно, публикуется много запросов на перенимание.
2. Зарегистрируйте физическую непрерывную память.
Зарегистрированная физически непрерывная память (например, огромные страницы) может позволить низкоуровневым драйверам выполнять оптимизацию, поскольку для требуется меньший объем трансляции адресов памяти (по сравнению с 4 КБ при сравнении со странным буфером памяти).
3. Уменьшите размер используемой очереди до минимума.
Создание различных очередей (верно очередь, общая очередь перенимания, очередь завершения) может потреблять много памяти. Люди должны выбирать их минимальные размеры, необходимые для их применения.
Способы снижения потребления процессора
1. Обработка событий завершения работы
использовать задание по чтению событий завершено, устранит существующее CQ Выполнять непрерывный опрос необходимо, поскольку добавляет возможность приезда после завершения задания. CQ Когда, РДМА Устройство отправит событие.
2. Обработка запрошенных событий на стороне ответчика.
Когда существуют отвечающие стороны, работа по чтению завершена,События запроса могут быть хорошим способом уведомить отправителя запроса о запросе.,Указывает на то, что сейчас хорошее время для чтения существования. Это уменьшает общее количество обработанных завершенных заданий.
3. Используйте один и тот же CQ в нескольких очередях.
конечно, несколько очередей используют одно и то же CQ и уменьшить CQ изTotal устранит необходимость проверки нескольких CQ Требуется, чтобы узнать, был ли выполнен невыполненный запрос на работу. Это можно сделать путем смешивания нескольких очередей отправки, нескольких очередей перенимания или их совместного использования. CQ завершить.
Средства улучшения масштабируемости
1. Используйте коллективные алгоритмы (коллективные algorithms), МожетссылкаDAOSсерединаCARTизkАлгоритм дерева предметов
использование коллективного алгоритма уменьшит общее количество сообщений по линии из, и Общее количество сообщений и ресурсов для каждого узла в уменьшенном кластере. некоторый RDMA оборудование выполняет специальную операцию коллективного удаления, которая помогает снизить CPU Использование.
2. Использование ненадежных датаграмм (UD) QP
Если каждый узел должен иметь возможность отправлять сообщения любому другому узлу в подсети, то соединение QP (Надежный и Ненадежный) может быть плохим решением, поскольку для существования будет создаваться множество в каждом узле. QP。использовать UD QP Лучше, потому что к нему можно получить доступ из любой другой подсети. UD QP отправлятьиперениматьинформация。
Просмотр модулей ядра
$ lsmod | grep '\(^ib\|^rdma\)'
rdma_ucm 24576 0
ib_uverbs 65536 1 rdma_ucm
ib_iser 49152 0
rdma_cm 57344 3 ib_iser,rpcrdma,rdma_ucm
ib_umad 24576 0
ib_ipoib 114688 0
ib_cm 45056 2 rdma_cm,ib_ipoib
rdmavt 57344 1 hfi1
ib_core 208896 11 ib_iser,ib_cm,rdma_cm,ib_umad,ib_uverbs,rpcrdma,ib_ipoib,iw_cm,rdmavt,rdma_ucm,hfi1Пакет Debian RDMA
верно RDMA из поддержки ядра DebianKernelОбслуживание команды。Ядродлямного моделейиз RDMA Аппаратное обеспечение предоставляет драйверы, а также обеспечивает ULP Поддержка модуля.
rdma-core: RDMA пакет пользовательского пространства Core от Debian HPCподдерживать。
Исторически ядро RDMA Пакет из исходного кода да Open Fabrics Enterprise Distribution (ОФЭД). В последнее время большая часть этой работы была перенесена в сферу проживания. rdma-core проект
Модуль RDMA, запускающий ядро, находится в следующем месте: /lib/modules/`uname -r`
kernel/drivers/infiniband/hw/ - hardware device drivers Драйвер аппаратного оборудования
kernel/drivers/infiniband/sw/ - software drivers (e.g. Soft-RoCE) Программный драйвер
kernel/drivers/infiniband/ulp/ - ULP modules Модуль протокола верхнего уровня
kernel/drivers/staging/ - new drivers/modules, may be RDMA-related. Новый драйвер/модульПосмотреть скорость соединения
$ ibstat
(look at the Rate shown on the port you are using)
or
# iblinkinfo
(look at the middle part formatted like "4X 5.0 Gbps")
or
$ cat /sys/class/infiniband/<kernel module>/ports/<port number>/rate
20 Gb/sec (4X DDR)Решение RDMA/ROCE 2022-5-28
*For the RoCE recommended configuration and verification, please click here . This post shows the list of relevant pointers for RDMA/RoCE Solutions. For Storage Solutions, refer to Storage Solutions.
https://enterprise-support.nvidia.com/s/article/rdma-roce-solutions
>> Learn RDMA on the Mellanox Academy for free
- Introduction Введение
- Configuration Procedures (Quick Reference Table) Руководство по настройке/таблица быстрой ссылки
- Architecture and Design
- End to End Configuration Examples
- Reference Deployment Guides
- Debugging and Troubleshooting
- Archived Posts (ConnectX-3 Pro, SwitchX Solutions)
INTRODUCTION
- What is RDMA?
- RoCE Success Cases and Deployment Guides Истории успеха RoCE и руководство по развитию
- Introduction to Resilient RoCE - FAQ
CONFIGURATION PROCEDURES (QUICK REFERENCE TABLE)
ARCHITECTURE AND DESIGN
- Network Considerations for Global Pause, PFC and QoS with Mellanox Switches and Adapters
- RoCE v2 Considerations
- MTU Considerations for RoCE based Applications
- Understanding RoCEv2 Congestion Management
- RoCEv2 CNP Packet Format Example
- Understanding DC-QCN Algorithm for RoCE Congestion Control
- DCQCN Parameters
- Understanding QoS Configuration for RoCE
END TO END CONFIGURATION EXAMPLES
- How To Configure RoCE over a Lossless Fabric (PFC + ECN) End-to-End Using ConnectX-4 and Spectrum (Trust L2)
- HowTo Enable RDMA and TCP over SONiC (OCP 2017 Demonstration)
- DataON Windows S2D-3110 Storage Solution with Mellanox Spectrum Switches
REFERENCE DEPLOYMENT GUIDES
DEBUGGING AND TROUBLESHOOTING
- How-To Dump RDMA traffic Using the Inbox tcpdump tool (ConnectX-4)
- Understanding mlx5 Linux Counters
- Download Wireshark with RoCEv2 Support
- HowTo Read CNP Counters on Mellanox adapters
ARCHIVED POSTS (CONNECTX-3 PRO, SWITCHX SOLUTIONS)
- HowTo Enable, Verify and Troubleshoot RDMA
- HowTo Setup RDMA Connection using Inbox Driver (RHEL, Ubuntu)
- HowTo Configure RoCE v2 for ConnectX-3 Pro using Mellanox SwitchX Switches
- HowTo Run RoCE over L2 Enabled with PFC
- HowTo Run RoCE and TCP over L2 Enabled with PFC
- HowTo Create Docker Container enabled with RoCE
- HowTo Run RoCE and TCP over L2 Enabled with PFC (2016)
- Network Adoption Scenarios for RoCE applications
ссылка
Nvidia_Mellanox_CX5и6DX series network card_RDMA_RoCE_losslessиlossy_DCQCN congestion control_dynamic Connection и другие подробные пояснения — одна статья для начала работы с RDMAиRoCE lossless: Nvidia_Mellanox_CX5и6DX series network card_RDMA_RoCE_losslessиlossy_DCQCN контроль перегрузки_динамическое соединение и другие подробные пояснения - запись в одной статье RDMAиRoCE lossless-Tencent Cloud Developer Community-Tencent Cloud
делиться Написал: Dotan Barak , 8 июня 2013 г. 9 марта 2019 г. Tips and tricks to optimize your RDMA code - RDMAmojo RDMAmojo
https://blog.csdn.net/ssbandjl/article/details/134987145
RDMAпроизводительностьоптимизация Краткое обсуждение опыта(один)https://zhuanlan.zhihu.com/p/522332998
Документ NSDI2023: анализ масштабируемой архитектуры SRNIC https://www.ctyun.cn/developer/article/416756725661765
Посмотрите на потерю производительности операций RDMA с микроперспективы транзакций PCIe (транзакции PCIE/дверной звонок/встроенные характеристики сетевой карты Mellanox и т. д.): https://mp.weixin.qq.com/s/gtG3vZ-p-H-XE9IIVvRp9g
Ресурсы RDMA: https://gist.github.com/aagontuk/705315c94eeaf657b3f35b011c233c19
DEBIAN RDMA WiKi: https://wiki.debian.org/RDMA
ArchLinux IB WiKi: https://wiki.archlinux.org/title/InfiniBand
файл readme irdma (между rdma): https://downloadmirror.intel.com/738730/README_irdma.txt
Сяобин (ssbandjl)
блог: https://cloud.tencent.com/developer/user/5060293/articles | https://logread.cn | https://blog.csdn.net/ssbandjl
Технические переговоры Сяобина (сериал)
https://cloud.tencent.com/developer/user/5060293/video
Краткое описание ДАОС: https://cloud.tencent.com/developer/article/2344030



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
