[Правила ассоциации Data Mining |] Подробное объяснение алгоритма роста FP (с подробным кодом, практическими примерами и учебными ресурсами).

🤵♂️ Персональная домашняя страница: @AI_magician 📡Адрес домашней страницы: Об авторе: CSDN-контент-партнер, качественный создатель в сфере full-stack. 👨💻Видение: стремление расти вместе с большим количеством партнеров, которые любят компьютеры! ! 🐱🏍 🙋♂️заявление:Сейчас я учусь на втором курсе колледжа,Научные интересы Искусственный интеллект&аппаратное обеспечение(虽然аппаратное обеспечение还没开始玩,Но мне всегда было интересно!Я надеюсь, что босс поможет тебе) 【Глубокое обучение | Основные понятия] Вы уверены, что хотите взглянуть на те основные концепции, которые вам необходимо пройти на пути к глубокому обучению? (один) автор: компьютерный волшебник Версия: 1.0 ( 2023.8.27 )
Аннотация: Целью этой серии является популяризация основных концепций, которые необходимо передать на пути к глубокому обучению. Содержание статей собрано и написано блоггерами. Добро пожаловать на поддержку Sanlian! Эта серия будет постоянно обновляться, и основная концептуальная серия будет постоянно обновляться! Приветствую всех подписавшихся
@toc
Алгоритм роста FP
Алгоритму Apriori необходимо сканировать данные несколько раз, а ввод-вывод является большим узким местом.。Чтобы решить эту проблему,FP-Growth(Frequent Pattern Рост) путем построения дерева ФП (Частые Pattern Tree)чтобы избежать создания наборов элементов-кандидатов,тем самым уменьшая пространство поиска,Повышена эффективность алгоритма. Независимо от того, сколько данных,Нужно только сканировать набор данных дважды,Таким образом, эффективность работы алгоритма повышается.
Алгоритм FP Tree вводит некоторые структуры данных для временного хранения данных. Эта структура данных состоит из трех частей, как показано на рисунке ниже:
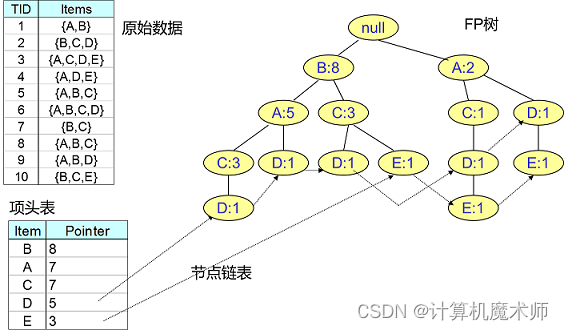
1. Список заголовков(линейная структура):В нем все записано1Сколько раз элемент появляется в частом наборе,Отсортируйте по убыванию времени. Например, на рисунке выше буква B появляется 8 раз во всех 10 группах данных.,Так что это на первом месте.
- FP Tree(древовидная структура):он преобразует наш оригиналданные Набор сопоставлен с ячейкой памятиFPДерево。
- Связанный список узлов:все Список 1 частый набор в заголовках - Связанный список Заголовок узлов, который, в свою очередь, указывает на позицию, где в дереве ФП появляется частый набор из 1 элемента. Это в основном для удобства заголовковиFP Связи между деревьями для поиска и обновления.
Шаги алгоритма:
- Построить список заголовков(Header Таблица): Просмотр набора данных,Подсчитайте поддержку каждого элемента, удалите элементы, поддержка которых ниже порогового значения, и, наконец, отсортируйте их в порядке убывания поддержки.。построить Список заголовков,Каждый элемент «Список заголовков» содержит имя элемента, количество поддержки и указатель на первый узел элемента в дереве FP. В реальной работе необходимо дважды сканировать данные.,Впервые используется для операции поддержки статистических элементов.,Второе сканирование используется для удаления предметов, поддержка которых ниже порога в делах. (Такой порядок обусловлен тем, что при создании дерева FP,Как можно больше делитесь родительскими узлами)
- Построение дерева ФП: обход набора данных,Прочитайте каждое дело, чтобы построить дерево ФП. По каждому предмету в делах,Начать с корневого узла,Если элемент существует в дочернем узле текущего узла,В противном случае увеличьте количество поддержки дочернего узла;,Создать новый дочерний узел,并更新Список заголовковвыиграть этот предметсвязанный список。最后构建得到的Дерево称为FPДерево。
- Построение базы условного шаблона: для каждого Список Срок в заголовках, из Список заголовковсвязанный Начиная с конца списка, рекурсивно проходим по связанному элементу. список генерирует базу условного шаблона с этим элементом в качестве суффикса пути. Каждая база условного шаблона содержит другие элементы пути, помимо текущего элемента, и соответствующие им счетчики поддержки. Базовый условный шаблон D показан ниже. Установите количество всех узлов-предков равным количеству конечных узлов, которое станет {A:2, C:2,E:1 G:1,D:1, D:1} В это время узел E и узел G удаляются нами, поскольку их поддержка в базе условного шаблона ниже порога. Наконец, после удаления узлов с низкой поддержкой и исключения конечных узлов, база условного шаблона. из D есть {A :2, C:2}。
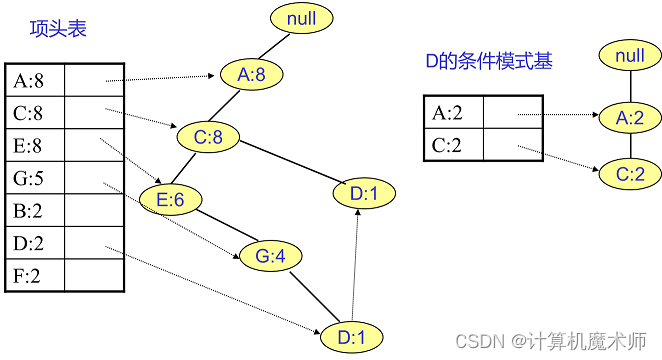
- Рекурсивно извлекаем дерево FP: для каждого списка Элементы в заголовках объединяются с базой условного шаблона для формирования нового часто встречающегося набора элементов. Если база условного шаблона не пуста, процесс построения и анализа дерева FP вызывается рекурсивно с базой условного шаблона в качестве входных данных. Получив основу условного шаблона на предыдущем шаге, объедините ее, чтобы получить Часто встречающийся набор из двух элементов D — это {A:2,D:2}, {С:2,Д:2}. Рекурсивно объедините биномиальные наборы, чтобы получить часто встречающийся набор из трех членов {A:2,C:2,D:2}. Самый большой частый набор элементов, соответствующий D, — это частый набор из трех элементов.
FP Treeалгоритм устраняет узкое место ввода-вывода в Aprioriалгоритме.,Умное использование древовидной структуры,Эталонная кластеризация BIRCH,BIRCHКластеризация также Умное использование древовидной структурыулучшитьалгоритм Скорость бега。использоватьОбмен пространства на время в структурах данных памяти является распространенным методом устранения узкого места во времени работы алгоритма.。
На практике алгоритм FP Tree представляет собой алгоритм корреляции, который можно использовать в производственных средах, а алгоритм Apriori является пионером и служит путеводной звездой для алгоритмов корреляции. Помимо FP Tree, такие алгоритмы, как GSP и CBA, принадлежат фракции Apriori.
Классические случаи и реализация кода:
Ниже приведен пример кода, реализующего Алгоритм роста FP с использованием библиотеки Python mlxtend:
from mlxtend.frequent_patterns import fpgrowth
from mlxtend.preprocessing import TransactionEncoder
import pandas as pd
# Создать образец набора данных
dataset = [['Milk', 'Eggs', 'Bread'],
['Milk', 'Butter'],
['Cheese', 'Bread', 'Butter'],
['Milk', 'Eggs', 'Bread', 'Butter'],
['Cheese', 'Bread', 'Butter']]
# Преобразование набора данных в логическую матрицу с помощью TransactionEncoder
te = TransactionEncoder()
te_ary = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_ary, columns=te.columns_)
# Используйте функцию fpgrowth для поиска часто встречающихся наборов элементов.
frequent_itemsets = fpgrowth(df, min_support=0.2, use_colnames=True)
print(frequent_itemsets)используется здесьmlxtendв библиотекеfpgrowthфункция для выполнения Алгоритм роста ФП. первый,Преобразовать сделанный набор в представление логической матрицы,а потом позвониfpgrowth函数来寻找指定最小支持度阈值的频繁项набор。
кроме того,Если вы хотите использовать собственную реализацию Алгоритма роста FP, вы можете обратиться к соответствующей реализации с открытым исходным кодом и подробностям алгоритма. Вот несколько учебных ресурсов, которые помогут вам узнать больше об Алгоритме. роста FP:
- Han, J., Pei, J., & Yin, Y. (2000). Mining frequent patterns without candidate generation. In Proceedings of the 2000 ACM SIGMOD international conference on Management of data (pp. 1-12).
- Agrawal, R., Imieliński, T., & Swami, A. (1993). Mining association rules between sets of items in large databases. ACM SIGMOD Record, 22(2), 207-216.
- mlxtend documentation: https://rasbt.github.io/mlxtend/
- Python implementation of FP-Growth algorithm: https://github.com/evandempsey/fp-growth
Справочная статья:
https://www.cnblogs.com/pinard/p/6307064.html




Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
