Практика унифицированного исследования сценариев OLAP Apache Doris в Qifu Technology
Введение: В условиях быстрого роста потребительского кредитования рынок личного кредитования характеризуется особенностями, основанными на сценариях и опыте. Точный маркетинг, усовершенствованное управление рисками и оптимизация пользовательского опыта становятся все более важными. В качестве выдающейся китайской платформы обслуживания кредитных технологий, основанной на искусственном интеллекте, компания Qifu Technology выбрала Apache Doris в качестве единого механизма анализа для всего сценария OLAP и использовала Apache Doris для замены ClickHouse и MySQL, увеличив уровень соответствия SLA для сценария анализа отчетов до 99. % или более, среднее время запроса сокращается на 50%. Используя Doris вместо Elasticsearch, время импорта данных офлайн-сцены тегов сокращается с 4 часов до 1 часа, обеспечивая надежную поддержку данных для маркетинговой деятельности, рекламы и т. д. Кроме того, благодаря возможности Doris Multi-Catalog достигается ускорение запросов к озерному хранилищу, полностью решая такие проблемы, как громоздкий внешний вид конфигурации и отсутствие поддержки автоматической синхронизации метаинформации, что значительно повышает скорость обработки и анализа данных.
Qifu Technology (ранее 360 Digits), выдающаяся китайская платформа обслуживания кредитных технологий, основанная на искусственном интеллекте, стремится помочь финансовым учреждениям повысить уровень своего интеллекта. После многих лет практики в финансовой сфере компания Qifu Technology завершила свой профессиональный опыт в области искусственного интеллекта, больших данных, облачных вычислений и других технологий, опираясь на собственную мощную экосистему безопасности. В настоящее время он наладил широкое сотрудничество с банками, компаниями потребительского кредитования, трастовыми компаниями и т. д., чтобы предоставлять индивидуальные решения в соответствии с потребностями различных типов финансовых учреждений, чтобы помочь клиентам завершить цифровую и интеллектуальную модернизацию.
Потребительский кредит играет все более важную роль в стимулировании потребления и является одним из важных средств, способствующих восстановлению потребления и стимулированию потенциального спроса. В последние годы, в связи с быстрым ростом масштабов потребительского кредитования, продукты и услуги потребительского кредитования становятся все более и более распространенными, а рынок личного кредитования демонстрирует такие характеристики, как основанность на сценариях и богатый опыт. В этом контексте все большее значение приобретают точный маркетинг, усовершенствованное управление рисками и улучшение пользовательского опыта.
Чтобы лучше удовлетворять потребности сценариев и обеспечивать точную поддержку оперативных данных, компания Qifu Technology с 22 марта представила Apache Doris. Компания надеется интегрировать пользовательские многомерные данные с помощью Apache Doris и проводить точный анализ данных в режиме реального времени на основе огромные данные для разработки персонализированных маркетинговых планов и поддержки принятия решений. До сих пор Apache Doris использовался в нескольких бизнес-направлениях Qifu Technology. Каждый день в сети выполняются сотни синхронных рабочих процессов. Среднесуточный масштаб новых добавляемых и обновляемых данных достигает миллиардов, и он выполняет миллионы эффективных запросов. Применение Apache Doris не только эффективно увеличивает скорость обработки и анализа данных, но также снижает затраты на эксплуатацию и обслуживание, обеспечивает стабильность системы и обеспечивает надежную поддержку данных для технологии Qifu для достижения усовершенствованных операций и точной маркетинговой рекламы.
Бизнес-сценарии и статус заявки
Платформа больших данных Qifu Technology предоставляет универсальные услуги по управлению, разработке и анализу больших данных, охватывающие множество процессов жизненного цикла данных, таких как управление активами больших данных, разработка данных и планирование задач, анализ и визуализация самообслуживания, а также унифицированное управление индикаторами. Среди них наиболее типичными службами применения данных являются онлайн-анализ отчетов и автономные службы маркировки. Автономная служба маркировки включает в себя четыре основных службы: перечисление меток пользователей, профилирование групп клиентов, создание триггерной стратегии и выбор толпы. Чтобы удовлетворить различные потребности в бизнес-данных, ранняя архитектура распределяла хранилище данных по нескольким компонентам, таким как Clickhouse, Elasticsearch, MySQL и т. д., что создавало проблемы для приложений данных, а также для эксплуатации и обслуживания системы:
- часть SLA Не на должном уровне: слишком много архитектурных компонентов, оригинал OLAP Нестабильность и доступность двигателя не могут быть соблюдены. SLA Требовать.
- Сложное управление эксплуатацией и обслуживанием: необходимо одновременно управлять несколькими компонентами, а сложность и сложность эксплуатации и обслуживания высоки. ClickHouse сильно зависит от других компонентов и его трудно расширить. MySQL имеет ограниченную емкость одного экземпляра, требует обслуживания нескольких; экземпляров и не поддерживает перекрестные экземпляры. Запросы увеличивают затраты на управление.
- Управление данными затруднено: общие взаимоотношения между данными сложны.,Управление данными затруднено,Последующее управление происхождением данных и жизненным циклом данных приводит к более высоким затратам.
Кроме того, все еще существуют некоторые проблемы с производительностью и стабильностью, а именно:
- Высокое время запроса: MySQL/ClickHouse имеет низкую производительность при выполнении сложных запросов.,Такие проблемы, как высокая частота отказов запросов, связанных с хранилищем, и низкая скорость ответа на запросы.,Невозможно удовлетворить требования к ответу на запрос второго уровня.
- Плохая производительность импорта: ограничено MySQL Он может переносить масштаб данных (десятки миллионов) и не может удовлетворить требования к крупномасштабному импорту данных; ClickHouse Показатели импорта низкие, и существует вероятность возникновения нестабильности импорта.
Выбор технологии
Чтобы решить вышеуказанные проблемы, Qifu Technology планирует внедрить аналитическую базу данных, отвечающую потребностям большинства сценариев OLAP. База данных должна иметь следующие характеристики:
- Безопасность и простота управления: единственное требование данные могут удовлетворить большую часть OLAP нуждаться,Упростите процессы управления данными,Повышение эффективности управления данными требует идеального механизма контроля разрешений;,Для обеспечения безопасности и конфиденциальности данных.
- Точные и в режиме реального времени: поддерживает импорт и запросы данных в реальном времени, гарантируя, что импортированные данные не будут потеряны или дублированы, а также реализует семантику Exactly Once.
- Простота в использовании и низкая стоимость: он прост в развертывании, может гибко расширяться и сокращаться в соответствии с потребностями, поддерживает синтаксис MySQL, снижает порог обучения для разработчиков и повышает эффективность разработки.
Основываясь на вышеуказанных требованиях к отбору, компания Qifu Technology провела опрос по ClickHouse и Apache Doris. Среди них производительность Apache Doris в импорте, запросах, эксплуатации и обслуживании соответствует требованиям отбора, а также хорошо работает в области стандартизации сообщества, активности, открытости и устойчивого развития. Поэтому компания Qifu Technology выбрала Apache Doris в качестве единого механизма анализа для всего сценария OLAP.
Далее мы представим углубленное применение и практику оптимизации Apache Doris в технологии Qifu на основе реальных бизнес-сценариев и лучше поймем, как Apache Doris помогает технологии Qifu достичь точного маркетинга и повысить доходы от бизнеса.
Применение Apache Doris в сценариях анализа отчетов
В сценариях анализа отчетов аналитики данных обычно проводят анализ данных на основе важных бизнес-отчетов, диаграмм и отчетов об оценке текущего состояния бизнеса, стремясь обеспечить важную основу для принятия решений по бизнес-стратегии.
Когда ранняя архитектура реагировала на этот сценарий, возникала проблема больших колебаний своевременности синхронизации таблиц данных, уровня соблюдения SLA (ежедневная статистика). После углубленного анализа это было вызвано большим количеством компонентов, участвующих в данных. процесс синхронизации. Мало того, большое количество компонентов также увеличивает сложность синхронизации данных, создавая проблемы для стабильности источников данных (MySQL, ClickHouse) и задач синхронизации (таких как DataX Job, Flink Job и т. д.).
Сообщить об обновлении системы
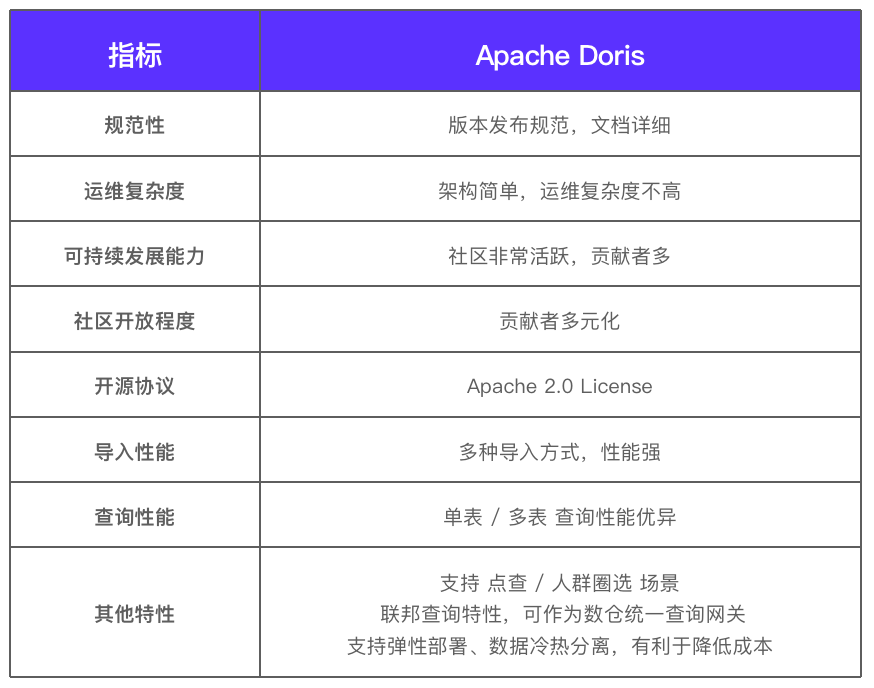
Чтобы решить эти проблемы, мы использовали Apache Doris вместо ClickHouse, а Doris предоставляет унифицированные сервисы для отчетов и упрощает источники данных отчетов. Как видно на рисунке ниже, Doris построен на верхнем уровне хранилища данных Hive, которое может полностью использовать высокую производительность запросов Doris для обеспечения ускорения запросов для сценариев анализа отчетов. В то же время Apache Doris поддерживает собственный протокол MySQL и может быть легко интегрирован с инструментами бизнес-аналитики, такими как Fanruan и Guanyuan, что повышает гибкость и простоту использования анализа отчетов.
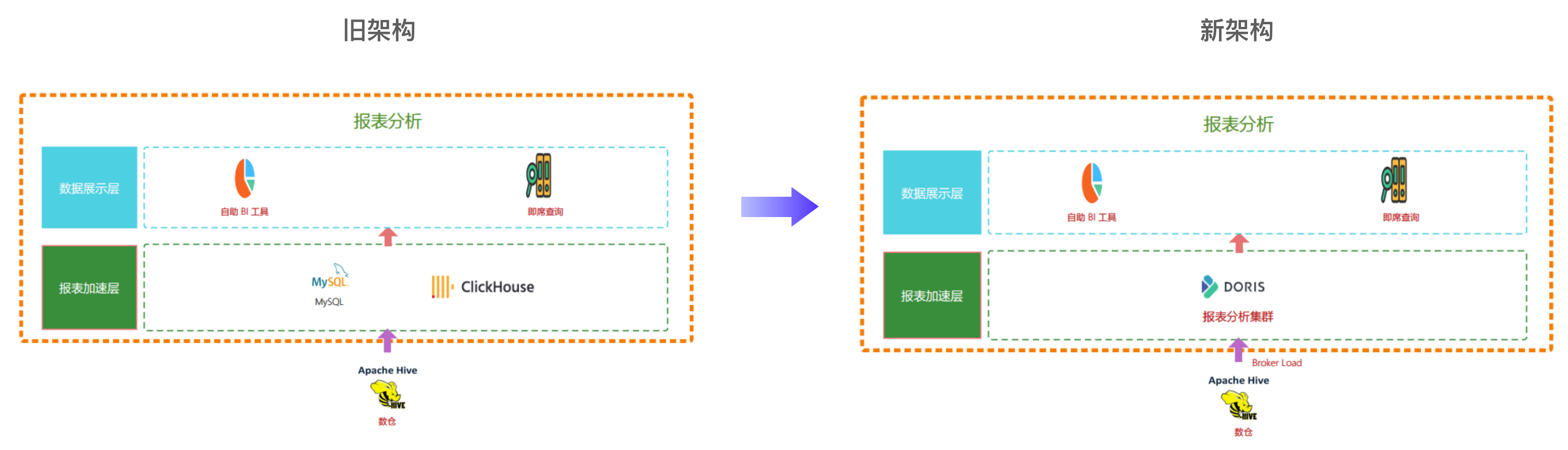
Импортировать приоритет задачи
В исходной логике Дорис Не существует понятия приоритета обработки задач импорта. Когда одновременно отправляется большое количество задач, Дорис Задачи будут выполняться по принципу «первым пришел — первым обслужен». Поэтому мы руководили разработкой и внесли свой вклад в Импортировать сообщество. приоритет функция задачи. Эту функцию можно настроить в соответствии с настройками приоритета пользователя. дело Внедряйте задачи и обеспечивайте своевременность выполнения качественных задач. Подробный процесс показан на рисунке ниже:
Благодаря установке приоритетов даже в периоды пиковой нагрузки можно обеспечить своевременность высококачественных задач, что значительно повышает уровень соблюдения SLA в отношении своевременности синхронизации таблиц данных. Обеспечивает более гибкую и эффективную поддержку передачи и применения данных.
Решение высокой доступности для двух компьютерных залов в удаленных местах
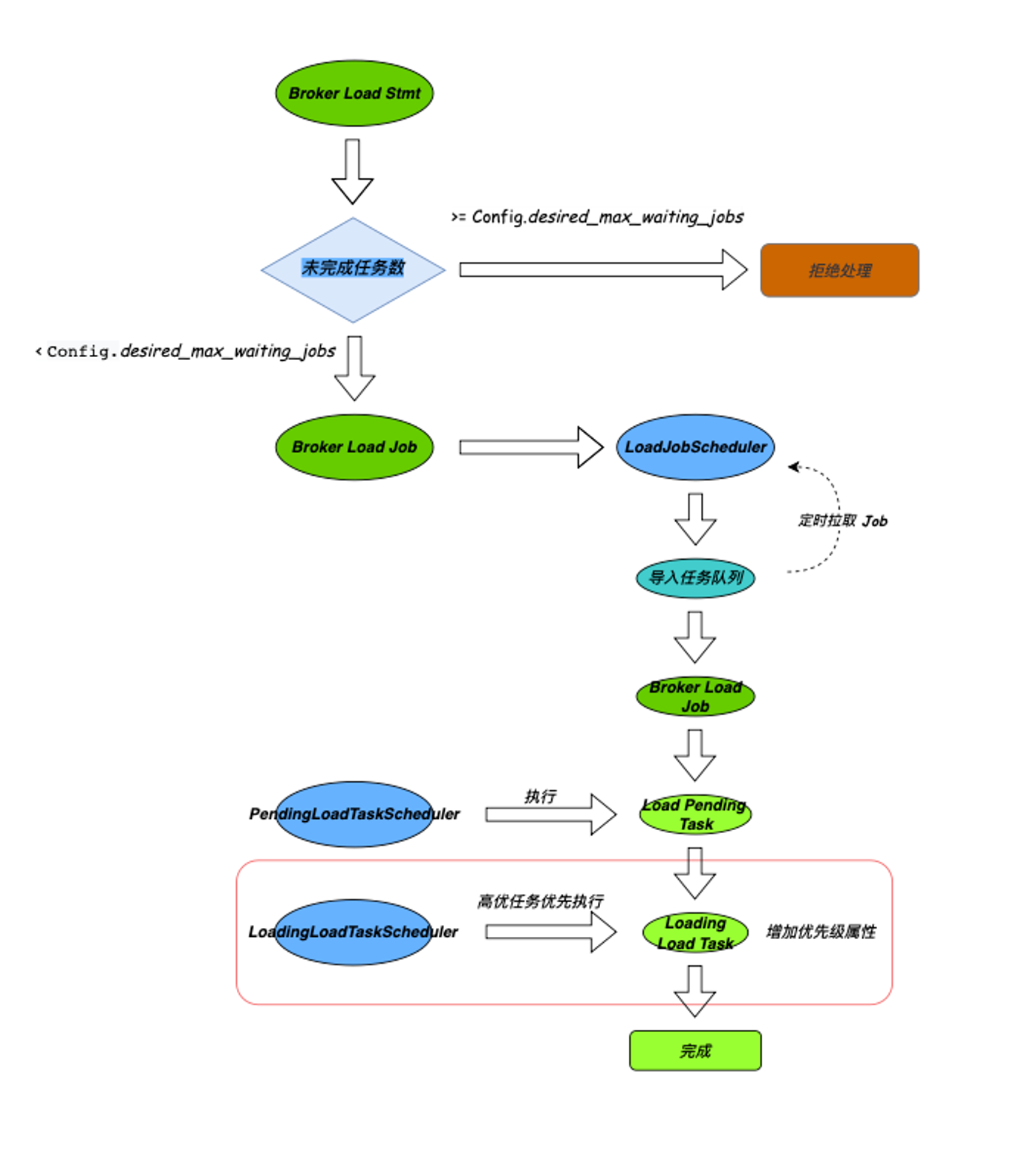
Чтобы обеспечить доступность и стабильность кластера Doris, гарантировать, что кластер по-прежнему доступен для чтения при выходе из строя компьютерного зала, а также возможность записи данных основного кластера после восстановления сбоя, необходимо обязательно оборудовать Кластер Doris с возможностью аварийного восстановления двух компьютерных залов. После исследования программы мы решили реализовать аварийное восстановление двух компьютерных залов путем самостоятельной разработки подключаемого модуля синхронизации «главный-подчиненный» репликатора. Ниже приводится конкретный проект архитектуры:
Установите плагин Replicator в основной кластер. Этот плагин может перехватывать и анализировать весь SQL, выполняемый основным кластером. После операции фильтрации он может отфильтровывать SQL, связанный с изменениями в базе данных и структуре таблиц, а также добавлением и удалением данных. и модификация. Соответствующий SQL (частичный SQL необходимо переписать) отправляется в подчиненный кластер для воспроизведения.
Кроме того, чтобы справиться с непредвиденными ситуациями, которые могут возникнуть в основном кластере, Qifu Technology разработала гибкий механизм переключения адресов разрешения DNS. Если главный кластер недоступен, переключите адрес разрешения DNS на подчиненный кластер, чтобы завершить переключение между главным и подчиненным кластерами.
Кроме того, мы также разработали модуль проверки данных Validator в консоли Doris (внутренне разработанная служба обслуживания и управления кластером Doris), который может регулярно проверять и сообщать о согласованности таблиц данных Doris главного-подчиненного кластера, включая метаданные. , количество строк и т. д.
Доход от приложений
Если взять в качестве примера время синхронизации таблицы, то метод Doris Broker Load используется для эффективного снижения сложности импорта данных, повышения своевременности импорта данных и успешного повышения уровня своевременности синхронизации данных отчетов в соответствии с SLA до более чем 99%.
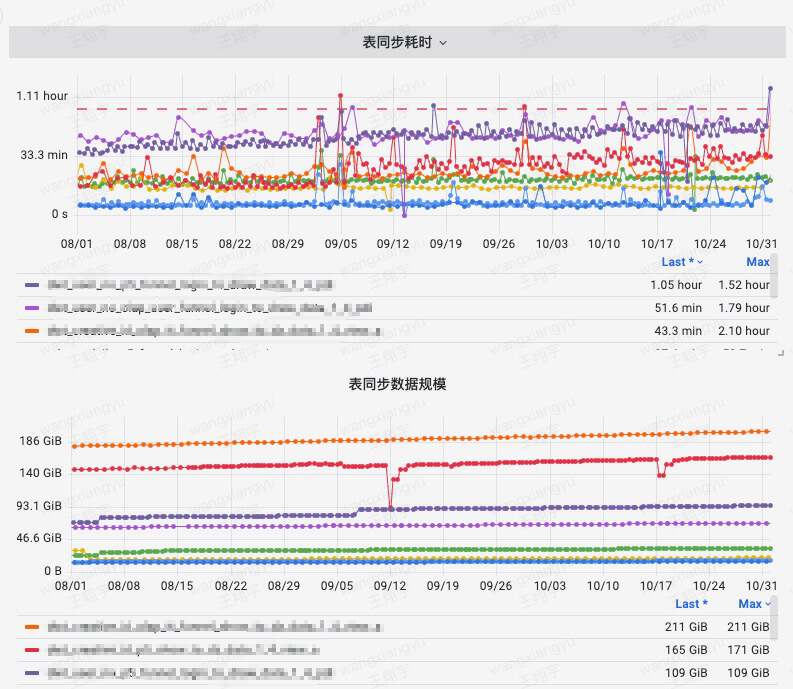
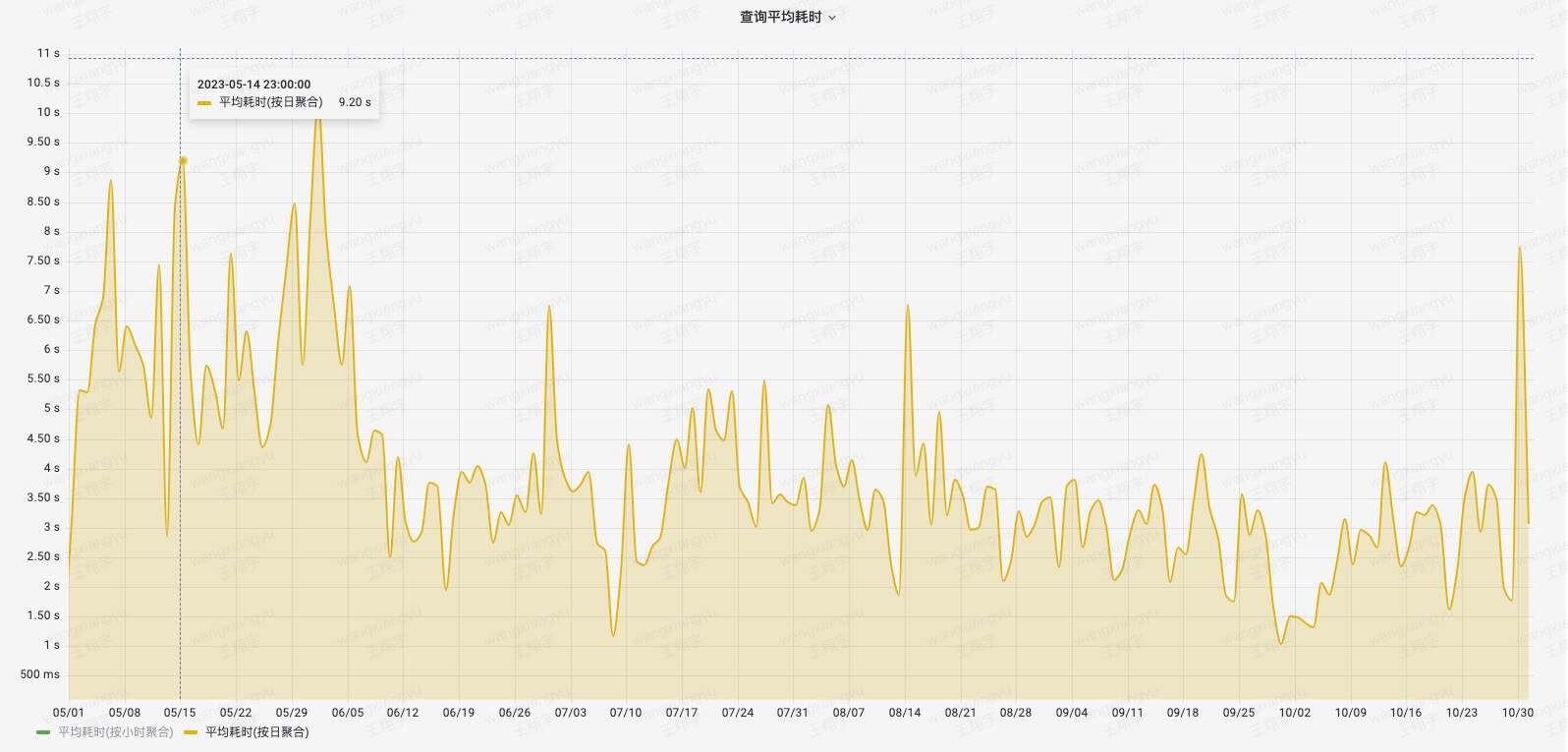
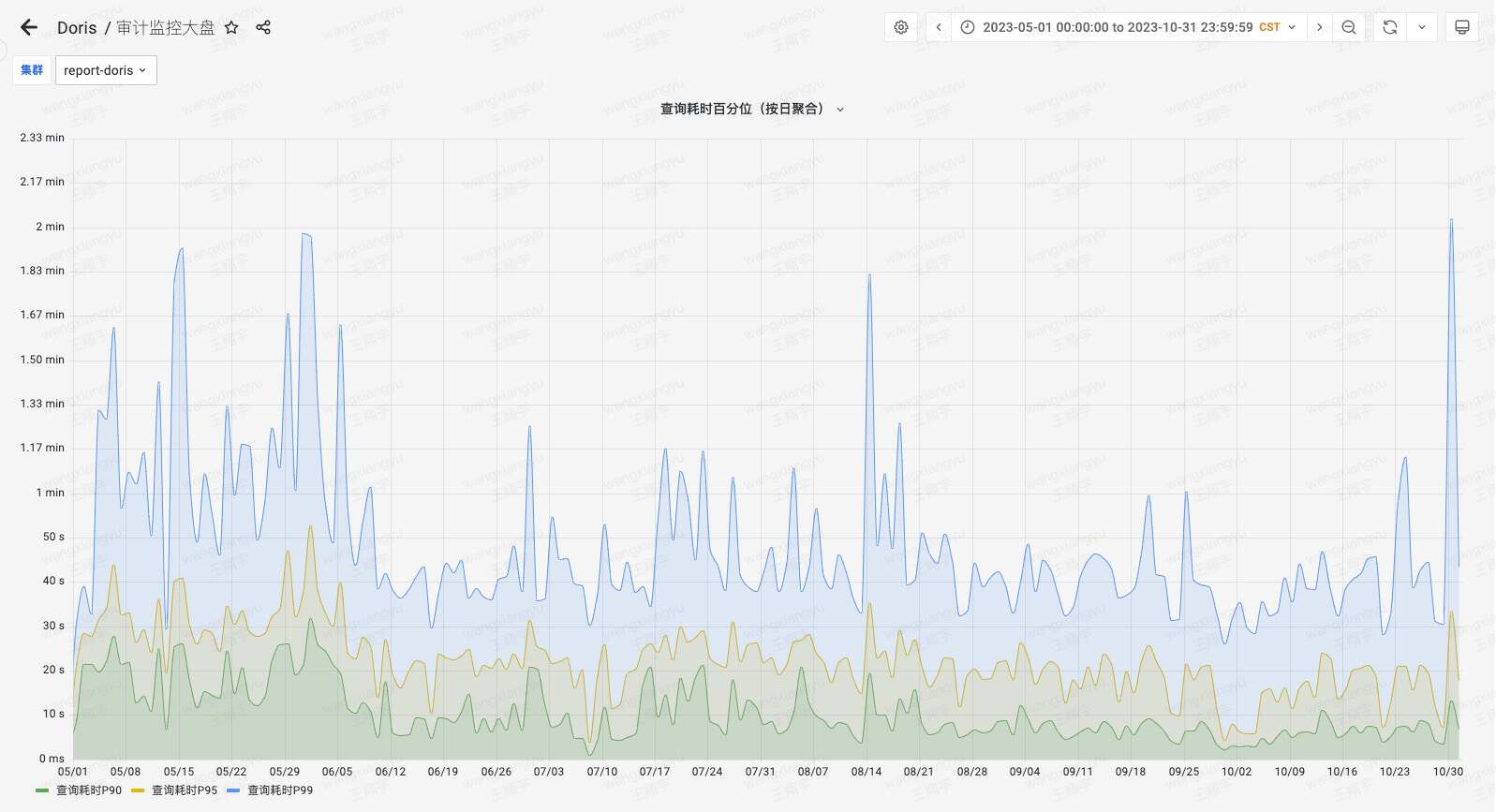
На следующем рисунке показан мониторинг своевременности запросов в кластере анализа отчетов после внедрения Apache Doris. Среднее потребление времени стабильно в течение 10 секунд, а время запроса P90 стабильно в течение 30 секунд. при старой архитектуре среднее потребление времени снижается на 50%. С углублением применения и ростом масштаба данных производительность запросов еще больше улучшилась, получив признание со стороны большего числа внутренних бизнес-направлений.
Применение Apache Doris в сценариях автономной службы тегов
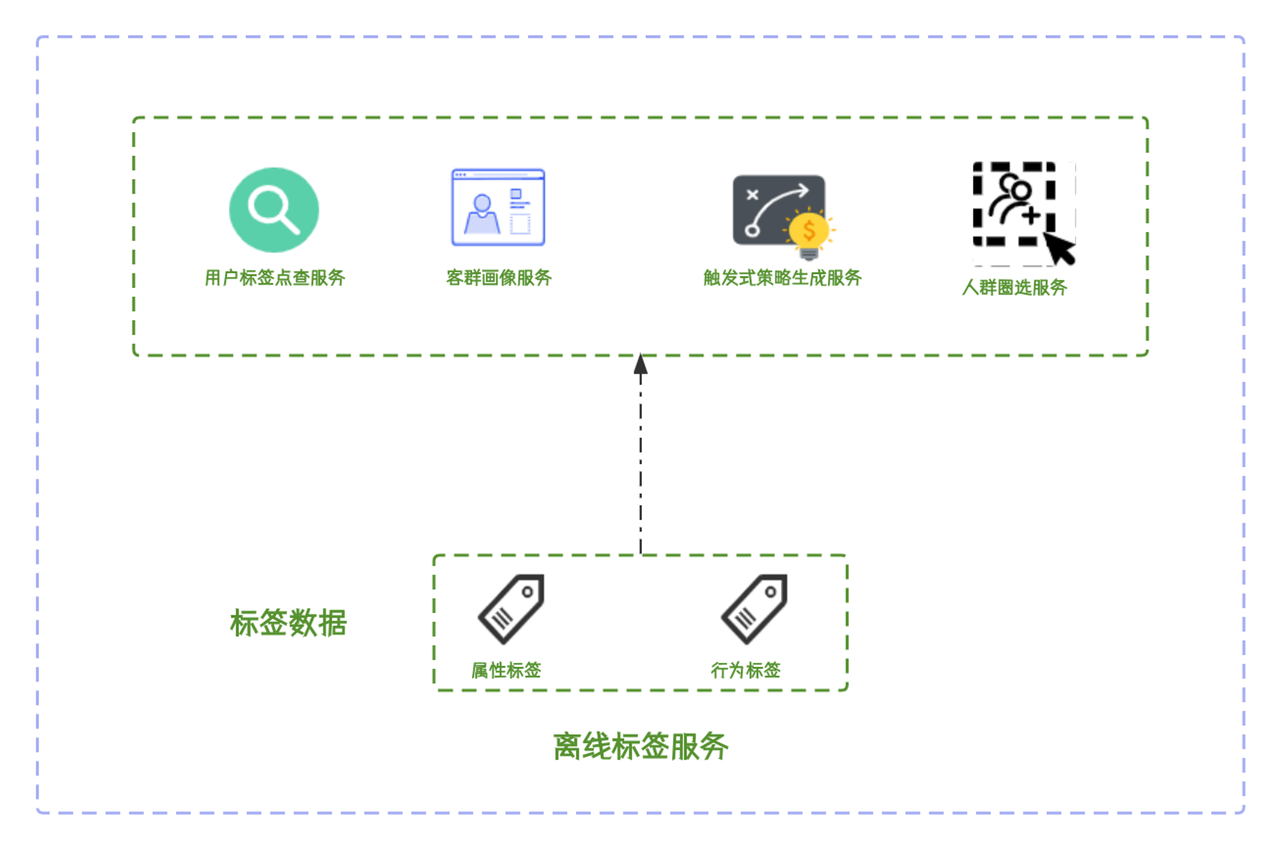
В сценарии службы тегов аналитики данных будут помечать пользователей на основе определенных стратегий на основе их многомерной информации. Теги в основном включают теги поведения и теги атрибутов. Автономная служба тегов основана на приведенных выше тегах и предоставляет услуги для следующих четырех сценариев:
- Сервис проверки тегов пользователей: существует в процессе контроля рисков,Функциональная платформа запросит информацию о теге пользователя.,и на на основе информации тега конструируются характеристические переменные пользователя.
- Служба профилирования групп клиентов: опишите портреты клиентов на основе информации тегов пользователей, чтобы обеспечить поддержку данных для отделов электронных продаж, маркетинга и других отделов для формулирования бизнес-стратегий.
- Услуга формирования триггерной стратегии: Отдел телемаркетинга на основе Информация о теге пользователя,Генерируйте пакеты толпы с помощью триггерных стратегий,И совершать исходящие звонки выбранным группам клиентов.
- Сервис краудселектинга: Отдел маркетинга на на основе информации тегов и генерации массовых пакетов для персонализированной рекламы.
Поскольку сервису автономной маркировки необходимо одновременно удовлетворять потребности четырех сценариев, к нему предъявляются высокие требования к своевременности и доступности импорта данных для обеспечения непрерывной и стабильной работы сервиса. В то же время необходимо обеспечить производительность перечисления запросов пользовательских тегов и поддерживать запрос информации тегов в режиме реального времени. С точки зрения массового отбора также необходимо иметь возможность точно удалять дубликаты и настраивать операции пересечения и объединения, чтобы обеспечить точность и эффективность маркетинговой деятельности и рекламы.
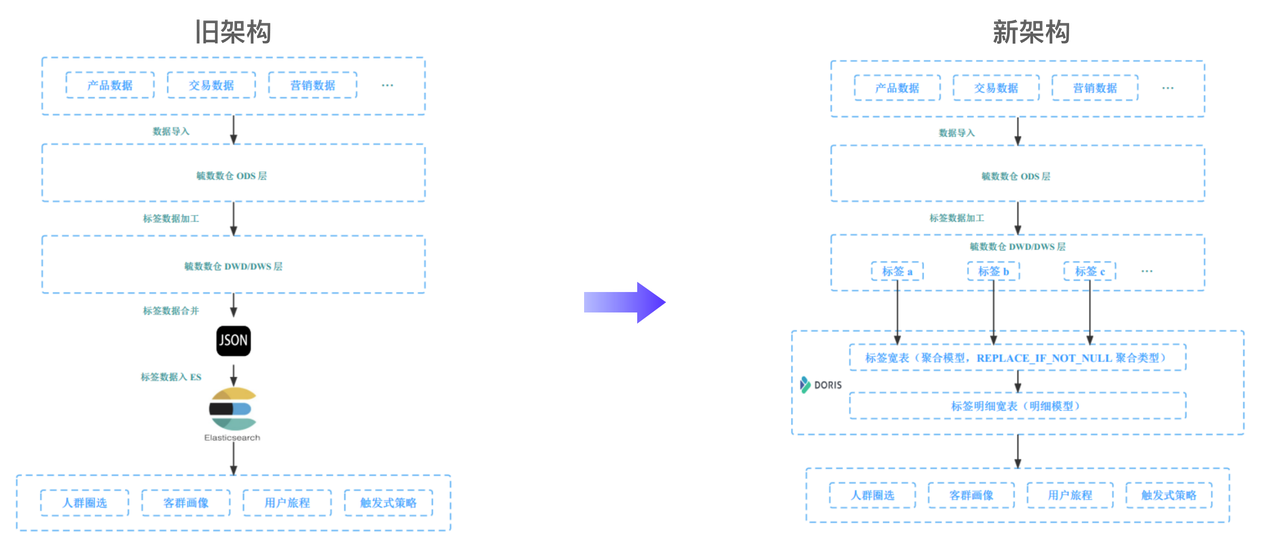
В исходной архитектуре (как показано на левом рисунке выше) импортированные данные будут постепенно генерировать информацию тегов, обрабатывать информацию тегов и объединять их в файл JSON (операция объединения предназначена для уменьшения количества обновлений и загрузки Elasticsearch). ). После слияния файл JSON импортируется в Elasticsearch для предоставления услуг передачи данных. Однако этот подход приносит две проблемы:
- Старый сервис меток слишком сильно полагается на операции слияния,Если возникла проблема с данными определенного сервиса тегов,Тогда вся операция слияния тега не может быть завершена.,Это повлияет на нормальную работу службы меток.
- Операции слияния данных основаны на Spark и MapReduce продолжай, иметь дело Время выдержки может составлять четыре часа или даже больше, поэтому это долгое время изиметь дело Затраты времени приведут к тому, что службы сцены пропустят основное время маркетинга, что приведет к потере доходов бизнеса.
Для решения вышеперечисленных проблем мы опирались на Apache Doris Архитектура была преобразована, как показано в правой части рисунка выше. В процессе обработки данных этикетки. Apache Doris Сохраните и обработайте общую таблицу тегов, которую можно будет использовать, когда восходящий тег будет готов. Aggregate Key + replace_if_not_null Реализуйте эффект объединения меток и частичного обновления столбцов. После того как все теги будут обновлены в общей таблице тегов, продолжайте синхронизировать их с Duplicate Key Сведения о метках модели находятся в широкой таблице, что позволяет повысить производительность запросов.
Эта трансформация позволяет нам реагировать более оперативно дело с Данные этикетки,Данные этикеткиизимпортироватьстарениеот 4 часы сокращены до 1 в течение нескольких часов。Кроме того, с помощью Doris идеальный Bitmap индекс, а также высокийи Производительность запросов,Достигнут выбор толпы второго уровня.。существовать Нажмите, чтобы узнать,QPS достигать 700+,Обеспечивает быстрый ответ на запросы.
Практика ускорения запросов к хранилищу Lake на основе Apache Doris
Чтобы сократить цикл принятия бизнес-решений и повысить эффективность работы аналитиков данных, важность ускорения запросов на автономные хранилища становится все более заметной. Поэтому с 22 сентября мы начали применять Apache Doris в сценариях ускорения запросов в автономном режиме. В то время Doris поддерживал только запросы в форме внешних таблиц Hive. Поскольку при изменении метаданных Hive внешние таблицы необходимо настраивать с учетом связей. Требуется обновление вручную, а затраты на обслуживание вручную высоки, поэтому мы решили импортировать данные из Hive в Doris, чтобы ускорить выполнение запросов.
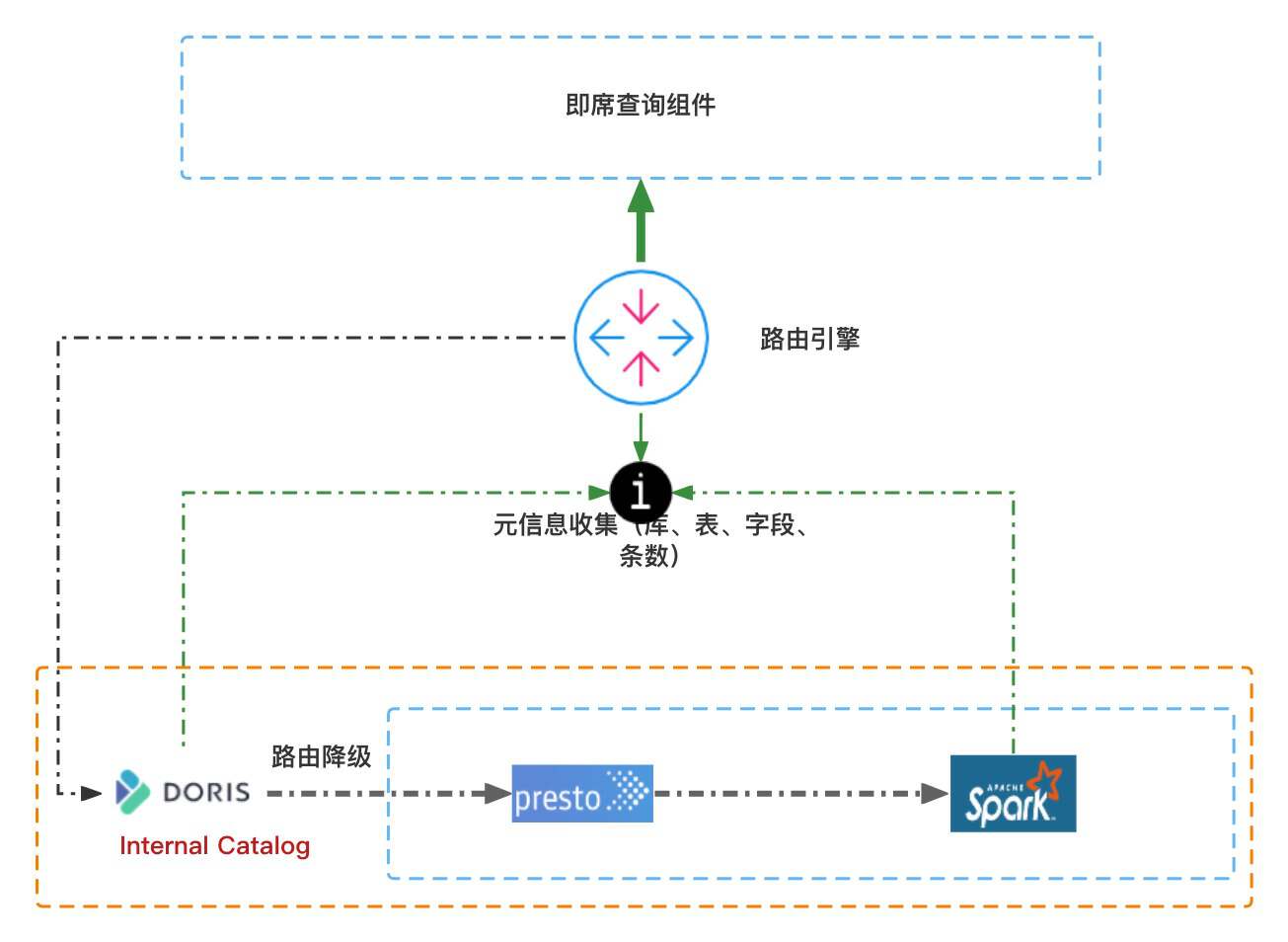
В частности, таблицам данных будет присвоен приоритет в соответствии с частотой запросов, а таблицы данных с 500 наиболее часто встречающимися запросами будут импортированы из Hive в Doris через Doris Broker Load. Собирайте метаинформацию таблиц данных в Doris и Hve посредством регулярного планирования механизма маршрутизации, включая поля, типы слов и масштаб данных таблиц. При получении запроса запроса маршрутизатор определяет, находятся ли данные в Doris. Если они существуют, они будут перенаправлены в механизм Doris для ускорения запросов.
Это решение не идеально и основано на импорте данных Hive. При выполнении крупномасштабных задач импорта данных ресурсы кластера могут быть перегружены, что приводит к снижению производительности запросов и импорта. Это может даже привести к нестабильности кластера, что отрицательно скажется на использовании в бизнесе.
Для решения вышеуказанных проблем мы дополнительно модернизировали архитектуру. Apache Doris версии 1.2 поддерживает каталог данных с несколькими источниками Multi-Catalog. Благодаря этой возможности таблица данных кластера Hive может быть полностью синхронизирована с Doris посредством простой настройки, что решает проблемы громоздкого внешнего вида конфигурации и невозможности автоматической синхронизации. метаинформация. Ниже представлено новое решение для ускорения запросов к хранилищу данных:
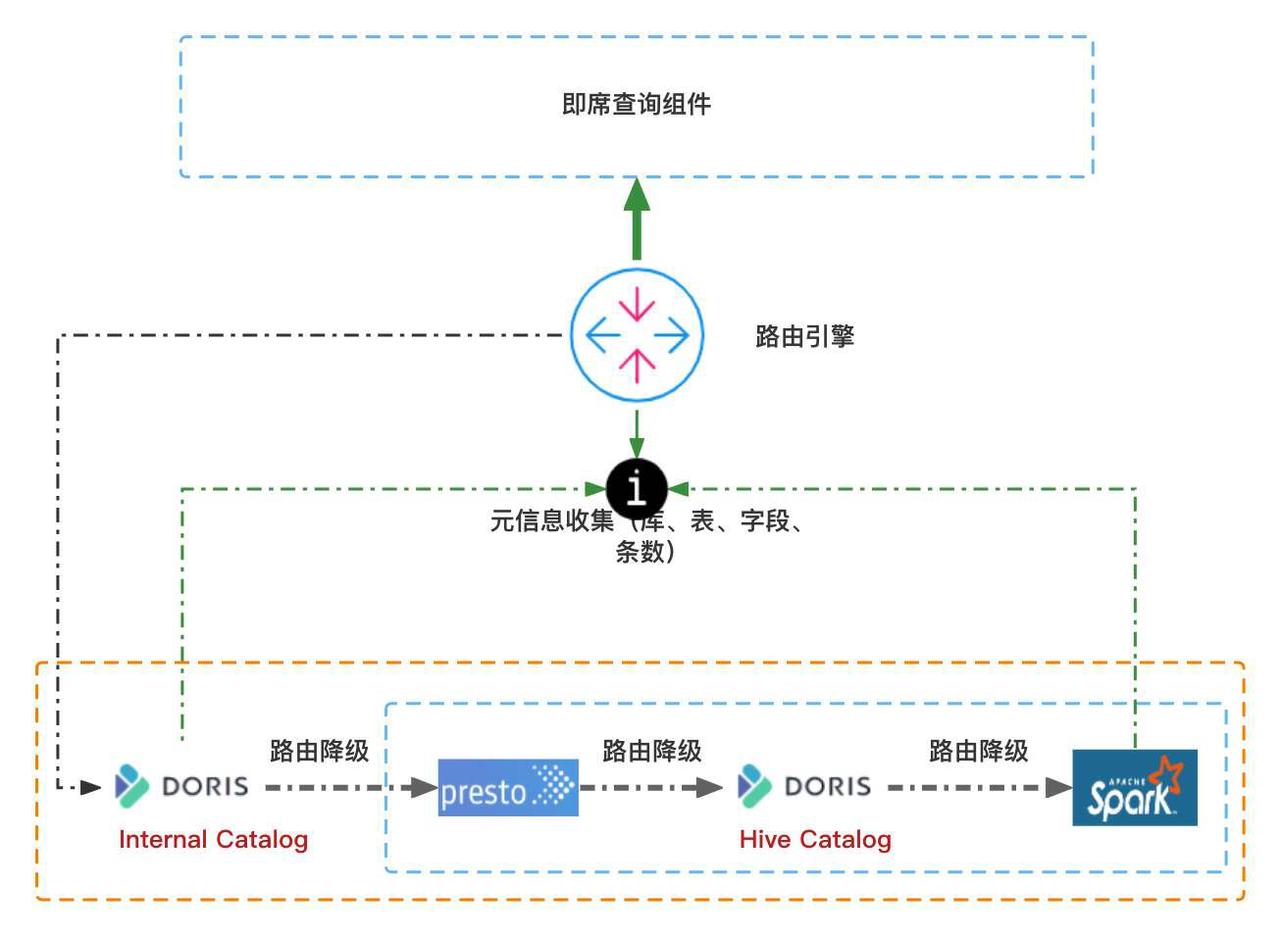
В новом решении решение по ускорению запросов к хранилищу данных в основном реализуется за счет следующих шагов:
- на основе Doris Multi-Catalog способность, воля Doris Механизм добавляется в стратегию маршрутизации механизма запросов (Внутренний Catalog и Hive Catalog);
- Внедрите гибкость Вычислительный узел и земля Deploy on Yarn Решение упрощает процесс развертывания, обеспечивая быструю итерацию обновления, а также поддержку быстрого расширения и сокращения в течение периода оттенков серого;
- Механизм запросов реализует автоматическую маршрутизацию, и выбор механизма прозрачен для пользователей.
Когда пользователь отправляет оператор запроса, механизм маршрутизации (т. е. шлюз запросов) будет принимать решения на основе собранной информации об элементах данных и подбирать оптимальный путь запроса для оператора запроса. Механизм маршрутизации также будет анализировать количество секций и строк таблицы, участвующих в запросе, чтобы подобрать наилучший механизм выполнения (Doris, Presto, SparkSQL). Например, когда все таблицы данных, от которых зависит оператор запроса, существуют во внутренней системе Doris. таблица и метаданные согласованы. Они будут напрямую перенаправлены во внутреннюю таблицу Doris для запроса. Если запрос не может быть выполнен, запрос будет отправлен вниз, и запрос будет выполнен каталогом Doris Hive или через Presto.
с помощью этой стратегии,Пользователям не нужно заботиться о том, какой механизм выполняет запрос.,Нет необходимости акцентировать внимание на синтаксических различиях между механизмами запросов. Запросы всегда выполняются наиболее эффективным образом,Достичь ускорения запросов,и гарантировать точность результатов。При использовании вышеуказанных решений также возникали некоторые проблемы.,Далее мы поделимся стратегиями преодоления трудностей и планом оптимизации.
Синхронизация метаданных Hive в квазиреальном времени
Если при использовании вышеуказанного решения для ускорения запросов метаинформацию Hive невозможно синхронизировать с Doris практически в реальном времени после обновления, при запросе пользователей будут возникать противоречивые результаты. Чтобы избежать этой проблемы, вы можете использовать функцию автоматического обновления метаданных Doris (реализованную на основе прослушивателя событий HMS) для достижения синхронизации метаинформации в квазиреальном времени. Этот метод требует открытия прослушивателя событий HMS на стороне Hive и включения переключателя потребления событий HMS на стороне Doris. Конкретная реализация показана на рисунке ниже:
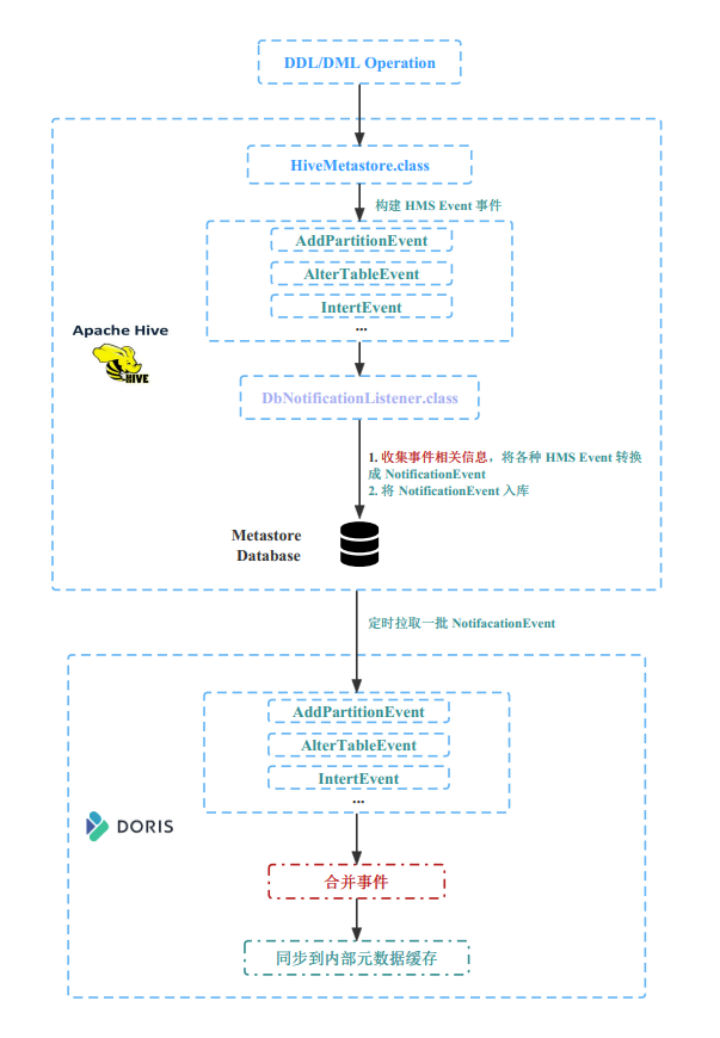
для Hive конец,при включении Listener Позже, потому что Hive Он имеет встроенный Listener понял, это будет Hive в кластере DDL операции, а также Insert Операция по перехвату. После начала операции по перехвату соответствующее HMS Событие (событие) и пишем Hive база данных метаинформации.
для Doris конец,при включении Потребление HMS Event После переключения Дорис из Master FE Узел запустит фоновый поток и запланирует пакетное извлечение. HMS Event,потребляя HMS Event получать Hive конецизм Изменения метаданных Будет Изменения синхронизированы с Doris Внутреннее обслуживание Hive В метаинформации данные могут быть синхронизированы в квазиреальном времени.。существовать В процессе внедрения мы также столкнулись с некоторыми новымиизвопрос,существоватьэта пара План оптимизация Поделиться:
План оптимизации 1:Hive DDL блокировка на долгое время:
запускать Hive конециз HMS Event Listener После, Улей иметь дело с При добавлении таблицы и раздела вам понадобятся имя таблицы и раздела, а также информация о файле для создания соответствующей информации о файле. HMS Событие, пока Doris Воспроизведение HMS Event Информация о файле не требуется. Итак, когда Hive Если таблиц и файлов разделов слишком много, операция получения информации о файле будет продлена, когда файл занят. HMS Event время генерации, что приводит к Hive DDL Время работы увеличивается.
На основании этого мы переписали Hive DbNotification Слушатель, экранированная пара Hive Сбор информации о файлах таблиц и разделов таблиц эффективно уменьшает извлечение и сбор ненужной информации и сокращает время. Hive конециз Эффективность исполнения.
План оптимизации 2: Скорость потребления не соответствует скорости генерации событий.:
Hive Когда кластер занят, DDL или Insert Частота событий высока, и Doris Потребление в однопоточном последовательном режиме HMS Событие, может появиться Doris Скорость потребления и Улей Несоответствие скорости генерации времениизвопрос。
чтобы улучшить Doris Скорость потребления, мы Doris Добавлено предварительное объединение событий (HMS Event Объединить) шаг, отфильтровать часть HMS Мероприятие, существенно снижающее необходимое потребление из HMS Even количество. Основная идея предварительного объединения событий заключается в определении размера пакета. HMS Event Есть ли что-нибудь, что могло бы компенсировать предыдущее? HMS Event Произвести эффект, если да, пропустите предыдущее HMS Event。через этоиз Способ,HMS Event Количество можно значительно уменьшить, а затем увеличить. Doris иметь дело с HMS Event изскорость потребления。
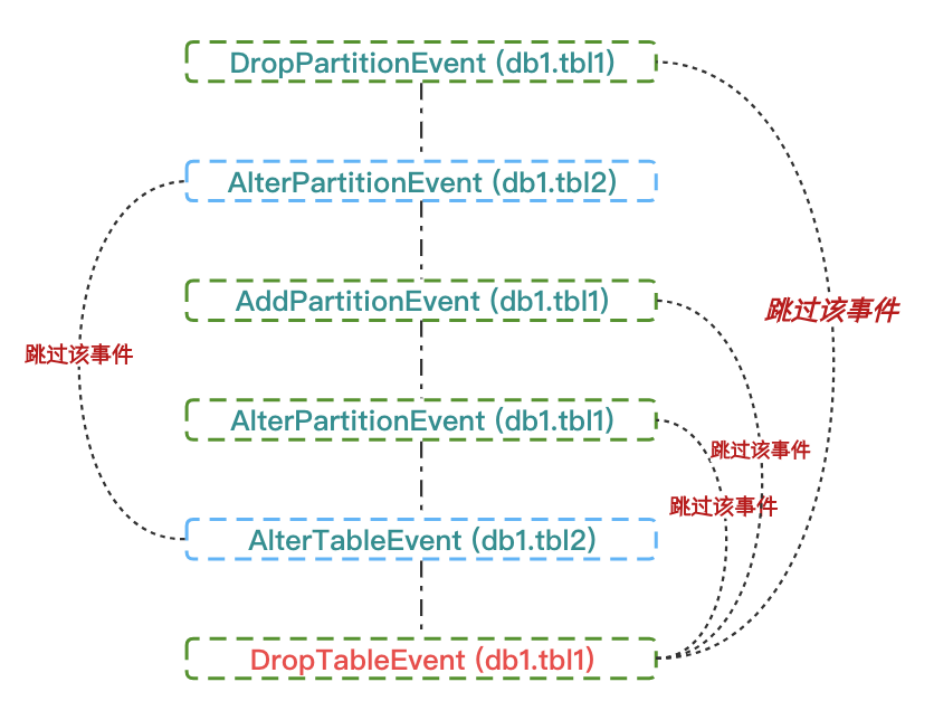
Принцип предварительного объединения событий показан на рисунке выше. Первое событие. DropPartitionEvent(db1.tbl1) и последнее событие DropTableEvent (db1.tbl1) для той же таблицы Hive поверхность. DropPartitionEvent Происходит раньше, DropTableEvent происходитьсуществоватьназад。существоватьиметь дело с DropPartitionEvent Дорис удалит Hive Таблица из должна разделять информацию кэша; дело с DropTableEvent Дорис удалит Hive Таблица из таблицы кэша информации. Из-за последнего HMS Event Создание эффекта может полностью компенсировать предыдущий. HMS Event Производит эффект из, поэтому предыдущий из можно пропустить. HMS Event。
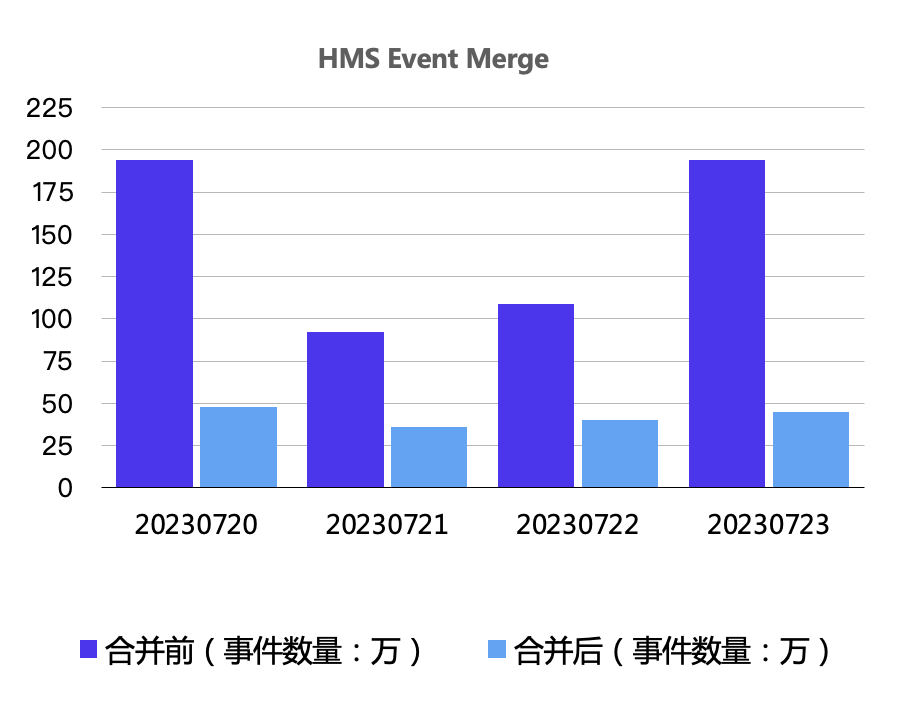
Наш кластер 4 Все в день дело с HMS Event иметь дело Извлечение в зависимости от ситуации,Как вы можете видеть на картинке выше,через HMS Event Merge После операции Дорис Количество событий потребления значительно сократилось, примерно на 10% меньше, чем раньше. 2-5 разизколичество。Полная оптимизацияназад,Скорость потребления уже не ниже скорости производства.извопрос。
План оптимизации 3:HMS Event Тип отсутствует, влияние FE стабильность
против CDH или ВОЗ HDP кластер Hive Версия создает сжатый формат из Event , добавлен GzipJSONMessageDeserializer Десериализатор для иметь дело с. Причина в том Slave FE Узлы обычно проходят Journal Log способ потребления HMS Event , если потребление не удастся, это приведет к FE Выйти из службы напрямую,Добавив Fallback Эта стратегия может повысить надежность логики потребления и попытаться избежать FE Проблема с выходом из службы。
Представляем эластичные вычислительные узлы. Развертывание на Yarn для достижения эластичного расширения и сжатия.
При необходимости иметь дело При выполнении высокопроизводительных вычислений с крупномасштабными данными для их поддержки требуется больше вычислительных ресурсов. Если развернут из Doris BE кластер. При наличии сотен узлов каждому узлу требуется несколько ЦП, то существующий, требует огромной поддержки ресурсов во время работы, что приведет к большим затратам ресурсов и затратам на развертывание. Чтобы сократить затраты на ресурсы и развертывание, мы решили представить Doris изэластичность Вычислительный узел(Elastic Compute Node) и выберите объединение узла эластичных вычислений с Hadoop кластериз Другие компоненты (такие как DataNode Узлы) гибридное развертывание позволяет лучше управлять вычислительными ресурсами и оптимизировать их.
На этом основании, исходя из Doris Вычислительный узелиз Свойство без сохранения состояния, можно передать Skein Упрощайте дальше Doris Вычислительный узел Deploy on Yarn из Процесс развертывания,Добиться эластичного расширения и сжатия узлов. существуют во время фактической эксплуатации,Мы основываем наши поисковые привычки на пользователях,существуют уменьшать мощность ночью, когда запросов меньше, и увеличивать мощность днем, когда бизнес пиковый.,Максимизируйте использование ресурсов и улучшите их использование.

Как показано выше, в Yaml определено в файле Doris Вычислительный узелиз Количество и Необходимая информация о ресурсах Установочный пакет, файлы конфигурации и сценарии запуска упакованы в распределенную файловую систему. Когда необходимо обновить версию, запустить и остановить ее, всего одна строка команды может завершить весь процесс за несколько минут. узелиз запуска и остановки работы.
Оптимизация запросов представления Hive
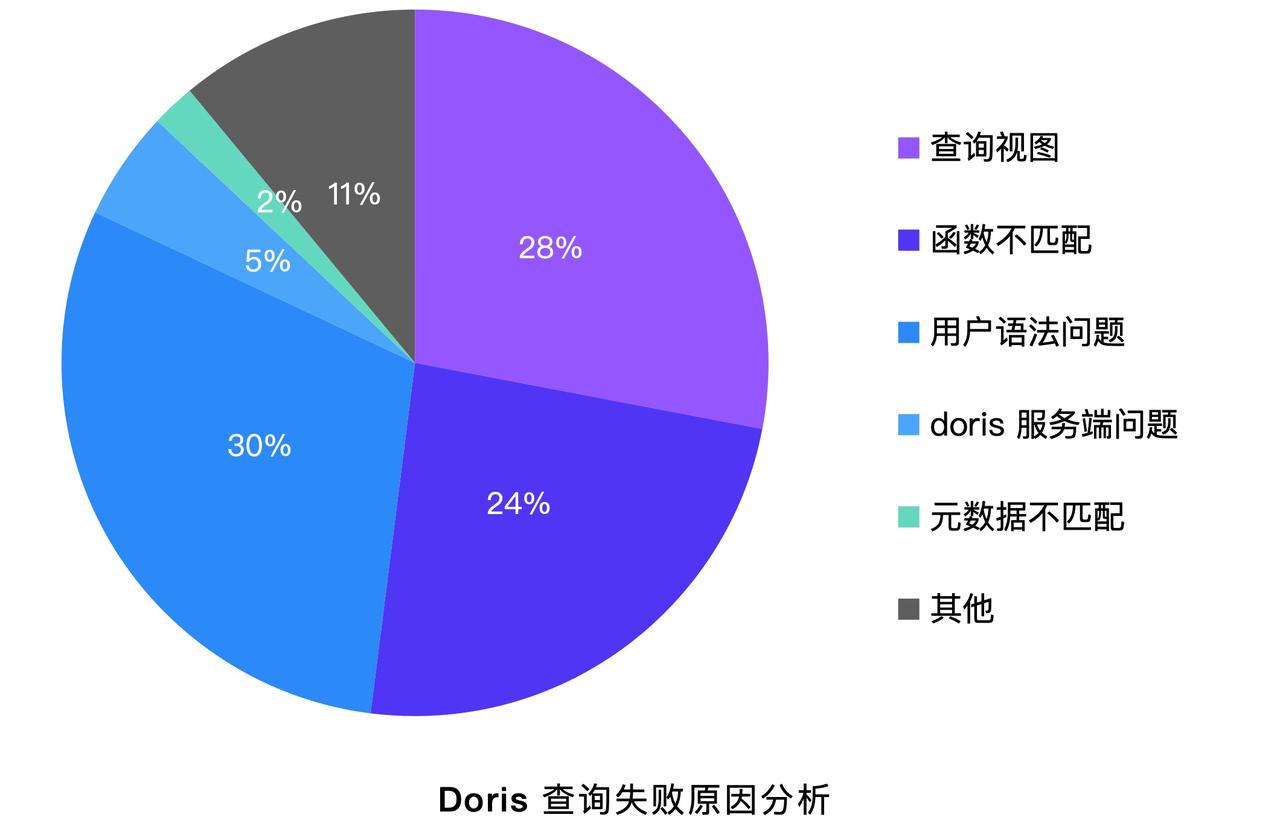
существовать Hive Catalog Во время выполнения запроса время от времени будут возникать проблемы со сбоем запроса. Мы провели углубленный анализ причин сбоя запросов для сотен бизнес-пользователей и обнаружили, что 28% вызвано просмотрами запросов, 24% Это потому, что пользователи используют Doris Вызвано невозможностью соответствия из функции.
Как показано ниже,Когда пользователь отправляет запрос запроса,существовать Doris Внутри он пройдет четыре этапа: лексический анализ, синтаксический анализ, план логического выполнения и план распределенного выполнения. Улей Осуществляется третий этап идентификации вида существующего, то есть когда формируется этап логического плана выполнения. Hive ScanNode После этого инициализируйте его определит, является ли таблица Hive вид. в случае Hive View напрямую выдаст исключение запроса, что приведет к сбою запроса.
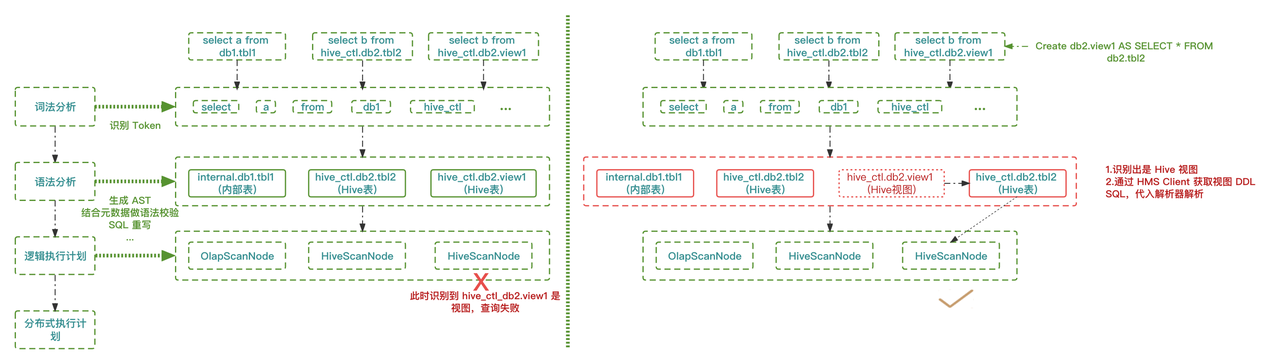
Поэтому мы Hive Выполнение запроса оптимизировано для Hive Просмотр распознавания переходит на этап синтаксического анализа (второй этап). Hive посмотреть, пройти HMS Client Клиент окончаниеполучать Это определение видаиз DDL и будет DDL принести Doris Устранение зависимостей представления из Hive сущностьповерхность.существовать Фаза создания логического плана выполнения(Третий этап),будет генерироваться с Hive Таблица сущностей соответствует HiveScanNode, запрос продолжится. Путем простой модификации Дорис Вы можете пройти Hive Catalog Понимать Hive Просмотр поддержки запросов.
Доход от приложений
Ускорение запросов в основном выигрывает от Apache Doris из Multi-Catalog Свойства, фаза для внешней таблицы, Мультикаталог Нет необходимости создавать отношения сопоставления между таблицами.,Возможно подключение уровня метаданных,как упоминалось вышеБлагодаря простой конфигурации весь Hive Таблица кластеризданных полностью синхронизирована с Doris , полностью решающий предыдущие проблемы громоздкого внешнего вида конфигурации и не поддерживающий автоматическую синхронизацию метаинформации.。
Кроме того, с помощью Doris Multi-Catalog Он заменяет несколько компонентов данных в ранней архитектуре, унифицирует вход источника данных и выход запроса данных, снижает сложность архитектуры и сокращает длину данных. дело с и процесс запроса, что значительно повышает эффективность запроса данных.
Заключение
от 22 введено в Doris с,Обладая превосходными характеристиками, низкой сложностью эксплуатации и обслуживания, а также высокой стабильностью.,Множество бизнес-сценариев в рамках Qifu Technology были быстро применены в больших масштабах. До сих пор,Имеется почти десять комплектов производственных сред, сотни БЭ Узел, ЦП Core Превосходить 1000+, общий размер данных — десятки TB ,Ежедневно запускаются сотни синхронизированных рабочих процессов,Масштаб ежедневных новых данных и обновлений достигает почти 10 миллиардов,Поддерживает миллионы эффективных запросов от деловых кругов каждый день。проходить Doris Приложение значительно упрощает архитектуру и эффективно повышает качество данных. дело си анализизскорость,Снижение затрат на эксплуатацию и техническое обслуживание,Обеспечена нестабильность системы.
В будущем мы продолжим использовать Apache Doris и представить 2.0 версия, предоставляющая пользователям больше унифицированных данных в реальном времени дело или проанализировать опыт. В дальнейшем мы сосредоточимся на фокусе Архитектура разделения хранилища и вычислений, функции анализа озера данных и Doris Manager Компоненты и приложения.
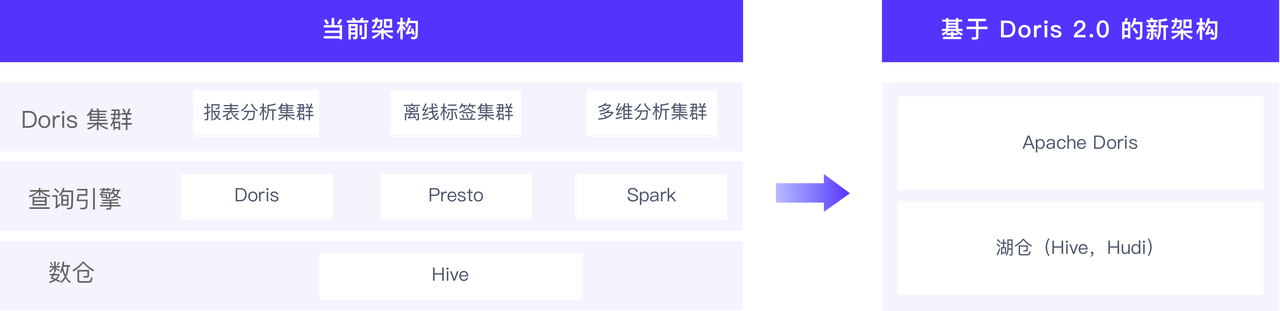
- Архитектура разделения хранения и вычислений. Благодаря архитектуре разделения хранения и вычислений реализуется интеграция кластеров и устраняется время между различными кластерами. Doris Различия версий обеспечивают более гибкую стратегию изоляции нагрузки и поддержку эластичного развертывания, предоставляя пользователям более стабильные и надежные данные. дело Среда для удовлетворения различных потребностей бизнеса.
- Функции анализа озера данных: непрерывное всестороннее использование,Упростите процесс внутреннего и внешнего потока данных с помощью унифицированного механизма запросов.,Нижние данныеиметь дело сиз сложности.
- Doris Manager Компоненты: Чтобы облегчить пользователям выполнение действий. данныеиз Управление эксплуатацией и техническим обслуживанием, Feilun Technology разработала универсальную базу данных данныхкластер Инструменты управления Cluster Manager for Apache Дорис (сокращенно Doris Менеджер). Инструмент обеспечивает простое развертывание и прием Doris кластериз Функция,Поддержка физической машины и среды виртуальной машины. С интуитивно понятным интерфейсом,Он предоставляет пользователям простой и удобный визуальный интерфейс для управления и обслуживания. В то же время пользователи также могут быстро расширять, сжимать и перезапускать узлы.,Установите сигналы мониторинга и другие операции. Это значительно повысит эффективность эксплуатации и технического обслуживания.,Уменьшите количество ошибок и перерывов,Повышение стабильности качества обслуживания.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
