Практика синхронизации Flink-CDC MySQL с Hive
Что такое CDC?
CDC — это аббревиатура (Change Data Capture). Основная идея состоит в том, чтобы отслеживать и фиксировать изменения в базе данных (включая INSERT данных или таблиц данных, обновление UPDATE, удаление DELETE и т. д.), полностью записывать эти изменения в том порядке, в котором они происходят, и записывать их в файл промежуточное программное обеспечение для других служб. Подписка и потребление.
Flink_CDC
1. Подготовка среды
- mysql
- Hive
- flink 1.13.5 on yarn
Примечание. Если Hadoop не установлен, вы можете использовать автономную среду Flink напрямую, без пряжи.
2. Загрузите следующие пакеты зависимостей
Загрузите пакеты зависимостей flink со следующих двух адресов и поместите их в каталог lib.
- 【flink-sql-connector-hive-2.2.0_2.11-1.13.5.jar】https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-hive-2.2.0_2.11/1.13.5/flink-sql-connector-hive-2.2.0_2.11-1.13.5.jar
Если у вас Flink другой версии, вы можете скачать его [здесь] https://repo.maven.apache.org/maven2/org/apache/flink.
Примечание. Моя версия куста — 2.1.1. Почему я выбрал здесь номер версии 2.2.0? Это соответствие версий, указанное в официальном документе:
Metastore version | Maven dependency | SQL Client JAR |
|---|---|---|
1.0.0 - 1.2.2 | flink-sql-connector-hive-1.2.2 | Download |
2.0.0 - 2.2.0 | flink-sql-connector-hive-2.2.0 | Download |
2.3.0 - 2.3.6 | flink-sql-connector-hive-2.3.6 | Download |
3.0.0 - 3.1.2 | flink-sql-connector-hive-3.1.2 | Download |
Официальный адрес документа: https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/connectors/table/hive/overview/, вы можете просмотреть его самостоятельно.
3. Запустите клиент flink-sql.
- Сначала запустите приложение на Yarn, войдите в каталог flink13.5 и выполните:
bin/yarn-session.sh -d -s 2 -jm 1024 -tm 2048 -qu root.sparkstreaming -nm flink-cdc-hive
- Введите командную строку Flink sql.
bin/sql-client.sh embedded -s flink-cdc-hive

img
4. Операция Улей
1) Предпочтительно создать каталог
CREATE CATALOG hive_catalog WITH (
'type' = 'hive',
'hive-conf-dir' = '/etc/hive/conf.cloudera.hive'
);
Обратите внимание: hive-conf-dir — это адрес файла конфигурации вашего куста, который должен содержать основной файл конфигурации hive-site.xml. Вы можете скопировать эти файлы конфигурации с узла куста на этот компьютер.
2) Запрос
На этом этапе нам следует выполнить несколько обычных операций DDL, чтобы проверить, есть ли какие-либо проблемы с конфигурацией:
use catalog hive_catalog;
show databases;
Запросить любую таблицу
use test
show tables;
select * from people;
Об ошибке может быть сообщено:

Поместите Hadoop-mapreduce-client-core-3.0.0.jar в каталог Lib файла Flink. Фактический выбор зависит от вашей версии Hadoop.
Примечание. Это очень важно. После размещения этого jar-пакета в Lib вам необходимо перезапустить приложение, а затем снова запустить приложение с помощью Yarn-session. Поскольку я обнаружил, что кеш, похоже, есть, закройте приложение и перезапустите. это:
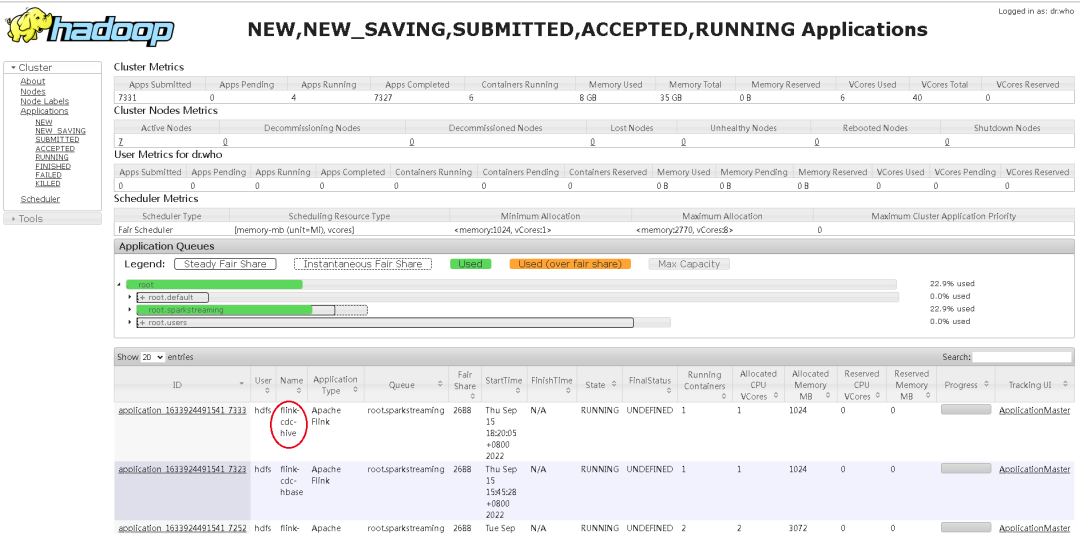
Затем данные можно запросить, и результаты запроса будут следующими:
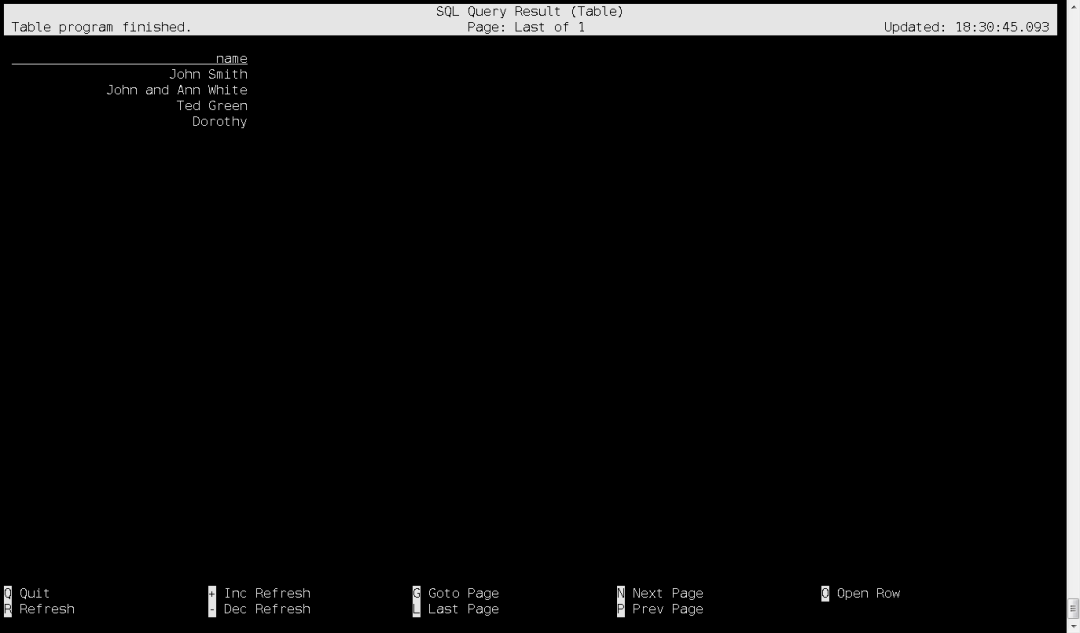
5. Синхронизируйте данные MySQL с кустом.
Данные Mysql не могут быть напрямую импортированы в улей в Flink sql. Их необходимо разделить на два этапа:
- синхронизация данных mysql с kafka;
- kafkaданныесинхронныйhive;
Что касается инкрементной синхронизации данных MySQL с Kafka, то анализ есть в предыдущей статье, и здесь я не буду делать обзор на синхронизацию данных Kafka с Hive;
1) Создайте таблицу и свяжите ее с Кафкой:
Раньше MySQL синхронизировался с Kafka, и в Flink sql создавалась таблица с разъемом = 'upsert-kafka'. Здесь есть разница:
CREATE TABLE product_view_mysql_kafka_parser(
`id` int,
`user_id` int,
`product_id` int,
`server_id` int,
`duration` int,
`times` string,
`time` timestamp
) WITH (
'connector' = 'kafka',
'topic' = 'flink-cdc-kafka',
'properties.bootstrap.servers' = 'kafka-001:9092',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
2) Создайте таблицу ульев
создаватьhiveНеобходимо указатьSET table.sql-dialect=hive;,В противном случае моргните sql Командная строка не распознает этот синтаксис создания таблицы. Зачем это нужно? Вы можете прочитать этот документ Hive? диалект.
-- Создание операции куста пользователя каталога
CREATE CATALOG hive_catalog WITH (
'type' = 'hive',
'hive-conf-dir' = '/etc/hive/conf.cloudera.hive'
);
use catalog hive_catalog;
-- Вы можете увидеть, какие базы данных находятся в нашем улье
show databases;
use test;
show tables;
Выше мы теперь можем видеть, какие базы данных и таблицы находятся в кусте дальше, создайте таблицу куста:
CREATE TABLE product_view_kafka_hive_cdc (
`id` int,
`user_id` int,
`product_id` int,
`server_id` int,
`duration` int,
`times` string,
`time` timestamp
) STORED AS parquet TBLPROPERTIES (
'sink.partition-commit.trigger'='partition-time',
'sink.partition-commit.delay'='0S',
'sink.partition-commit.policy.kind'='metastore,success-file',
'auto-compaction'='true',
'compaction.file-size'='128MB'
);
Затем выполните синхронизацию данных:
insert into hive_catalog.test.product_view_kafka_hive_cdc
select *
from
default_catalog.default_database.product_view_mysql_kafka_parser;
Примечание. Здесь указывается имя таблицы. Я использую каталог.база данных.таблица. Поскольку это две разные библиотеки, этот формат требует явного указания каталога-базы данных.
В Интернете есть и другие решения, касающиеся добавочной синхронизации MySQL с Hive в реальном времени:
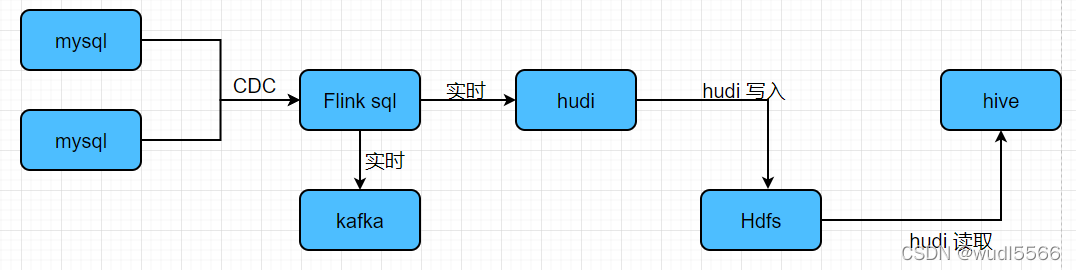
Я увидел в Интернете статью о плане архитектуры хранилища данных в реальном времени и подумал, что все в порядке:
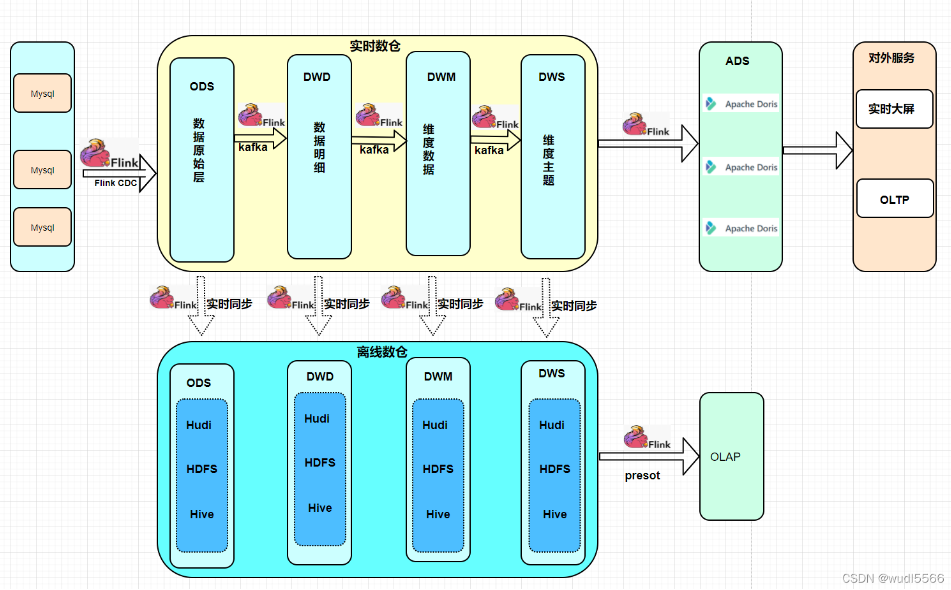
Ссылки
https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/connectors/table/hive/hive_dialect/
Отказ от ответственности:Статьи, опубликованные в этом общедоступном аккаунте, являются оригинальными для этого общедоступного аккаунта.,или представляет собой редактирование и компиляцию отличных статей, найденных в Интернете.,Авторские права на статью принадлежат первоначальному автору,Он предназначен только для изучения и ознакомления читателей. Для неоригинальных статей, которыми поделились,Некоторые потому, что настоящий источник не может быть найден.,В случае неправильного указания источника ответственность за использованные в статье картинки, ссылки и т.п., включая, помимо прочего, программное обеспечение, материалы и т.п., несет автор.,Если есть нарушения,Пожалуйста, свяжитесь с серверной частью напрямую,Опишите конкретные статьи,Серверная часть устранит неудобства как можно скорее.,Глубоко сожалею.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
