Практика обработки веб-страниц и сканирования веб-страниц Python: использование библиотеки Requests для сканирования данных веб-страниц
Оглавление
Практика обработки веб-страниц и сканирования веб-страниц Python: использование библиотеки Requests для сканирования данных веб-страниц
Обзор проблемы
Python и обработка веб-страниц
Установить библиотеку запросов
веб-сканер
Расширение: Соглашение об исключении роботов
Использование библиотеки запросов
обзор библиотеки запросов
Функция запроса веб-страницы в библиотеке запросов
Функция запроса веб-страницы
Свойства объекта Response
Методы объекта Response
Получить содержимое веб-страницы
Практика обработки веб-страниц и сканирования веб-страниц Python: использование библиотеки Requests для сканирования данных веб-страниц

Обзор проблемы
Введение в проблемы реализации веб-сканеров на языке Python

Python и обработка веб-страниц
- Python В развитии языка произошло знаковое прикладное событие, а именно США Гугл ( GOOGLE) Компания использует Python Язык связан с обработкой и развитием, то есть развитием языка. Важный признак зрелости. Питон Простота языка и возможности сценариев Отлично подходит для связывания и обработки веб-страниц.
- Быстрое развитие Всемирной паутины (WWW) привело к появлению большого количества доступа и Необходимость обмена сетевой информацией породила серию «сетевых рептилий» и других приложение.
- Python Язык предоставляет множество подобных функций Библиотека, включая urllib. 、urllib2、urllib3、wget、scrapy、запросы ожидания. Эти библиотеки имеют разные функции.、Различные способы использования、Пользовательский опыт отличается.
- Для обратного сканирования веб-контента вы можете использовать re (регулярное выражение (формула), beautifulsoup4 и другие функции Библиотеки для обработки, с полем Разработка каждой предметной функции Библиотека, в этой главе будут подробно представлены наиболее важные и важные Две основные функции Библиотека: запросы иbeautifulsoup4, Все они являются сторонними библиотеками.
Приложения веб-сканера обычно делятся на два этапа:
(1) Получение веб-контента через сетевое соединение.
(2) Обработать полученное содержимое веб-страницы.
Эти два шага используют разные функции. Библиотека: запросы и beautifulsoup4.
Установить библиотеку запросов
Принять пип Инструкция Запросы на установка Библиотека, если в системе сосуществуют Python2 и Python3, используйте pip3 инструкция :\>pip install requests # или pip3 install requests
Используйте инструкцию pip или pip3 для установки библиотеки beautifulsoup4.,Уведомление,Не устанавливать beautifulsoupБиблиотека,Последний из-за своего возраста и ветхости. , больше не поддерживается :\>pip install beautifulsoup4 # или pip3 install beautifulsoup4
веб-сканер
использоватьPythonсеть языковой реализациирептилияи Подать информацию очень просто количество строк кода очень мало, и нет необходимости знать о сетевой связи и других аспектах, поэтому он очень подходит для Для неспециалистов-читателей. Однако бессмысленное сканирование сетевых данных не является цивилизованным явлением. , также несправедливо конкурировать за конкурентные ресурсы, автоматически отправляя контент через программы. как те Подобно бессмысленным рекламным звонкам, они игнорируют пожелания получателя и не только раздражают, но и Могут возникнуть юридические споры.
Расширение: Соглашение об исключении роботов
Robots соглашение об исключении(Robots Exclusion Протокол), также известный как протокол сканера, это Метод, позволяющий администраторам веб-сайтов указать, хотят ли они, чтобы сканеры автоматически получали информацию о сети. Менеджеры могут выйти в онлайн Поместите robots.txt в корень сайта. файл и список в файле, ссылки на которые не разрешено сканировать сканерам . Как правило, сканеры поисковых систем сначала захватывают этот файл и сканируют содержимое веб-сайта в соответствии с требованиями к файлу.
Robots соглашение об Исключения Ключевое соглашение заключается в том, что вы не хотите, чтобы контент получался рептилиями. Если такого файла нет, значит, в сети. Содержимое сайта может быть получено сканерами, однако роботы Соглашение не является приказом или средством принуждения, это международный договор. Интернетуниверсальный этический кодекс。Самые зрелые поисковые системырептилия Всевстречаследуйте этому протоколу , рекомендуется, чтобы отдельные лица также могли разумно использовать краулерную технологию в соответствии со стандартами Интернета.
——Джентльменское соглашение——
Использование библиотеки запросов
requests Библиотекаэто краткий и простой процессHTTP请求的第三方Библиотека。
обзор библиотеки запросов
requests Самым большим преимуществом является то, что процесс программирования приближен к обычному. URL процесс доступа.
- Эта библиотека основана на библиотеке urllib3 на языке Python.,Аналогично этому и в других функциях Библиотека Кроме того, функция инкапсулирована, чтобы сделать ее более удобной для пользователя.Pythonна языкеОчень часто。существоватьPythonв экосистеме,любой Все Выражайте мнения посредством технологических инноваций или инноваций на основе опыта Возможность проявить свой талант.
- request Библиотека поддерживает очень богатые функции доступа по ссылкам, включая: международные доменные имена и URL Получить, HTTP Длинное соединение и кэш соединений, HTTP встречаразговариватьиCookie Сохранять Поддержка, стиль использования браузера SSL Аутентификация, базовая дайджест-аутентификация, действительные ключи Пара значений cookie Запись, автоматическая распаковка, автоматическое декодирование контента и загрузка файлов частями.、Функция HTTP(S)-прокси、Обработка тайм-аута соединения、потокданныескачатьждать.
- связанный requests Для получения дополнительной информации о Библиотеке посетите: http://docs.python‐requests.org
Функция запроса веб-страницы в библиотеке запросов
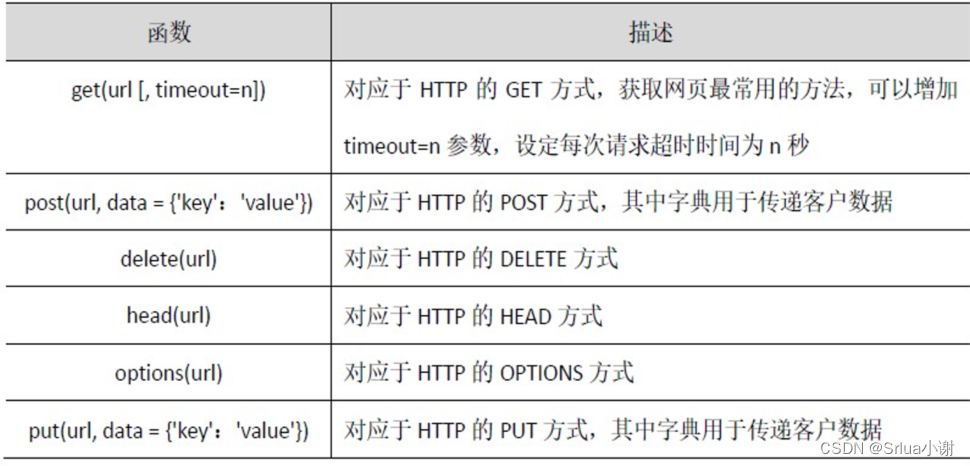
get() — наиболее часто используемый способ получения веб-страниц. После вызова функции request.get() возвращаемое содержимое веб-страницы будет сохранено как объект Response. Среди них должен быть URL-адрес параметра функции get(). доступ через HTTP или HTTPS.
Функция запроса веб-страницы
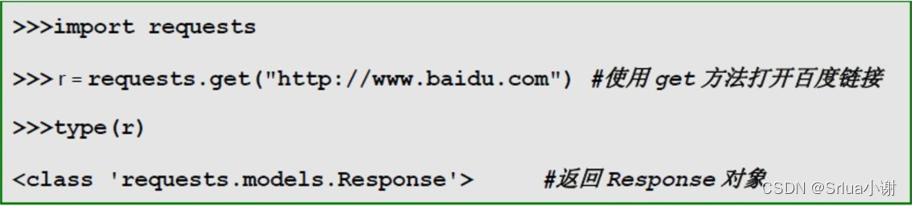
Интерактивный процесс браузера тот же, Requests.get() представляет запрос Процедура, ответ, который она возвращает Объект представляет собой ответ. Возврат контента Поскольку объект более удобен в эксплуатации, Свойства объекта Ответ как Как показано в таблице ниже,Необходимо принять<a>.<b>формаиспользовать。
Свойства объекта Response
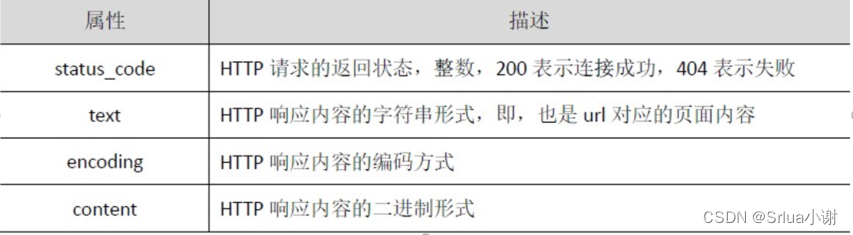
- status_code Запрос на возврат имущества HTTP Окончательный статус должен быть определен до обработки данных. Если на запрос не получен ответ, Обработку контента необходимо прекратить.
- text Атрибут — это запрошенное содержимое страницы, отображаемое в виде строки.
- encoding Атрибут очень важен. Он предоставляет метод кодирования для возврата содержимого страницы. Вы можете изменить кодировку, присвоив значение атрибуту кодировки. способ облегчить обработку китайских иероглифов
- content Свойства — это двоичные формы содержимого страницы.

Методы объекта Response

- json() метод способен анализировать наличие JSON данных, это принесет удобство парсинга HTTP.
- Метод raise_for_status() может генерировать исключение после неудачного ответа, то есть, пока возвращаемый код статуса запроса не равен 200, этот метод будет генерировать исключение для оператора try...кроме. Использование операторов обработки исключений позволяет избежать создания множества сложных операторов if. Вам нужно вызвать этот метод только после получения ответа, и вы сможете избежать различных непредвиденных ситуаций, кроме слова состояния 200.
- запросы порождают несколько распространенных исключений. При возникновении сетевых проблем, таких как: сбой DNS-запроса, отказ в соединении и т. д., запросы выдают исключение ConnectionError; при обнаружении недопустимого ответа HTTP запросы выдают исключение HTTPError, если истекает время ожидания URL-адреса, возникает исключение Timeout; быть выброшено Если запрос превышает установленное максимальное количество перенаправлений, будет выдано исключение TooManyRedirects.
Получить содержимое веб-страницы




Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
