Практика Chenfeng Information по потоковой передаче и пакетной обработке интегрированного озерного склада на базе Apache Paimon
краткое содержание
Chenfeng Information создает интегрированный озерный склад потоковой и пакетной обработки на основе Apache Paimon, в основном использующий:
- Весь водоем входит в озеро,TB сортданныепочти в реальном времени Войти в озеро
- на основе Flink + Paimon из Количество складов партия ETL строительство
- на основе Flink + Paimon из Количество складов поток ETL строительство
- Количество складов OLAP и Карта данных
01
Введение информации о Чэньфэне
Dustess Information (www.dustess.com) — это универсальный поставщик решений по эксплуатации и управлению частными доменами, основанный на корпоративной экосистеме WeChat. Компания стремится стать ведущим экспертом по эксплуатации и управлению частными доменами в отрасли и помогает предприятиям создавать частные домены. эксплуатация и управление в цифровую эпоху помогают предприятиям добиться качественного развития.
У Chenfeng сильная техническая команда по исследованиям и разработкам, и внутри компании царит сильная атмосфера обучения, особенно атмосфера технического обучения в команде по исследованиям и разработкам. Вначале для производственной и исследовательской группы была создана уникальная система обучения [Открытый класс и микрокласс Chenfeng], которая в основном была сосредоточена на обмене технологиями и обсуждении передового опыта. Позже была создана Академия Чэньфэн, которая охватила всех сотрудников компании, включая, помимо прочего, обмен знаниями и накопление контента в области общих технологий, управленческих навыков, производственных и исследовательских технологий, решений, отраслевых примеров, расширения рынка и т. д., чтобы предоставить все сотрудники компании с межрегиональной, межпозиционной и межпрофессиональной платформой обучения.
После более чем двух лет быстрого развития Chenfeng превратилась в высокотехнологичное предприятие с почти тысячей сотрудников.
В настоящее время у него есть 13 городских центров по всей стране, охватывающих пять основных регионов Северного Китая, Центрального Китая, Восточного Китая, Южного Китая и Юго-Западного Китая, образуя сеть городских услуг, которая проходит через север и юг и расходится по всей территории Китая. стране, обслуживая в общей сложности более 10 000 предприятий в более чем 30 отраслях.
02
Фон выбора
старая архитектура
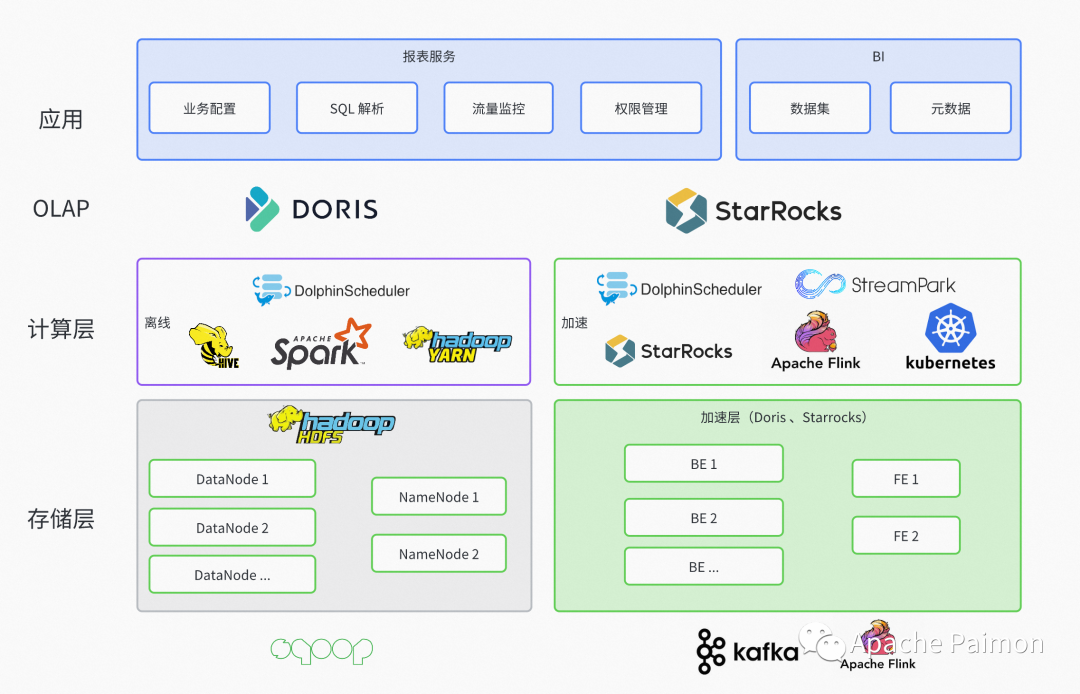
Как показано выше, до Paimon компания Chenfeng Information имела следующие два набора хранилищ данных.
Офлайн-хранилище данных
TiDB + HDFS + Yarn + Apache Hive + Apache Spark + Apache Doris
Офлайн-хранилище данные используются для покрытия партийной обработки сцены , охватывая в основном бизнес-сценарии T+1 и часовой уровень Необходимость отсроченной отчетности
Болевые точки
1. Задержка Офлайн-хранилище данных слишком велика, а синхронизация дартий, вытянутых из бизнес-библиотеки, может легко повлиять на бизнес.
2. На основе Hive из Офлайн-хранилище данныхдля Коллекция CDC и Обновить сцену Моделирование управления является более инвазивным и требует более высоких затрат на разработку.
3. По сравнению с объектным хранилищем, предоставляемым поставщиками облачных технологий, стоимость HDFS по-прежнему очень высока.
4. Приватизация сложна, и необходимо развернуть всю экосистему Hadoop. Для одиночных арендаторов с небольшими объемами приватизированных данных затраты на оборудование и обслуживание слишком высоки.
Хранилище данных в режиме реального времени
Apache Kafka + Apache Flink + StarRocks + K8S
Хранилище данных в режиме реального время для покрытия потока (Flink) и Микропакетная программа (StarRocks), охватывающая бизнес-сценарии. Второй уровень (поток) и Требования к минутным (микропакетным) отчетам с низкой задержкой и высокой ценностью
Болевые точки
1. Хотя канал связи реального времени SR обладает хорошими возможностями потоковой записи, он не поддерживает потоковое чтение, что неудобно для повторного использования зависимостей хранилища данных. Для подключения каждого уровня используется Apache Kakfa, что, в свою очередь, приводит к увеличению затрат на разработку и обслуживание.
2. Использование микропакетного планирования SR для каналов реального времени приведет к очень высокому использованию ресурсов, медленным запросам OLAP и даже к проблемам со стабильностью.
3. SR не поддерживает возможности пакетной обработки, такие как перезапись.
4、и Офлайн-хранилище данныхрасколоть,причинаданныеостров
Новые архитектурные требования
объединить Вот и всеиз Болевые точек, мы решили продолжить с количества Q1 Структурная перестройка складов, наша потребность в бизнесе в основном имеет следующие моменты:
1. Поддержка T+1 、часовой уровеньизпартия Обработка офлайн-статистики
2. Требования квазиреального времени, задержка может быть на минутном уровне (сквозная задержка в озере должна контролироваться примерно на 1 минуту)
3、Второй уровень Задерживатьиз спрос в реальном времени, запрос на отсрочку во Франции уровень
4. Стоимость хранения низкая, а большое количество точек хранения и истории не вызывают затруднений.
5. Совместимость с приватизацией (вся среда не зависит от тяжелых компонентов, таких как Hadoop и Hive, что снижает затраты на развертывание и эксплуатацию)
6. Возможность быстрого запроса данных в хранилище озера (OLAP)
объединитьбизнеснуждаться,Так что мы правыжитьмагазинивычислитьдвигательизнуждатьсяследующее
1. Более широкие возможности приема и обновления CDC.
2. Поддержка пакетной записи и пакетного чтения.
3. Поддержка потоковой записи и потокового чтения.
4. Сквозная задержка может существовать Второй уровень
5. Поддержка OSS, S3, COS и других файловых систем.
6. Поддержка механизма OLAP
7. Активное сообщество
Почему стоит выбрать Пеймон
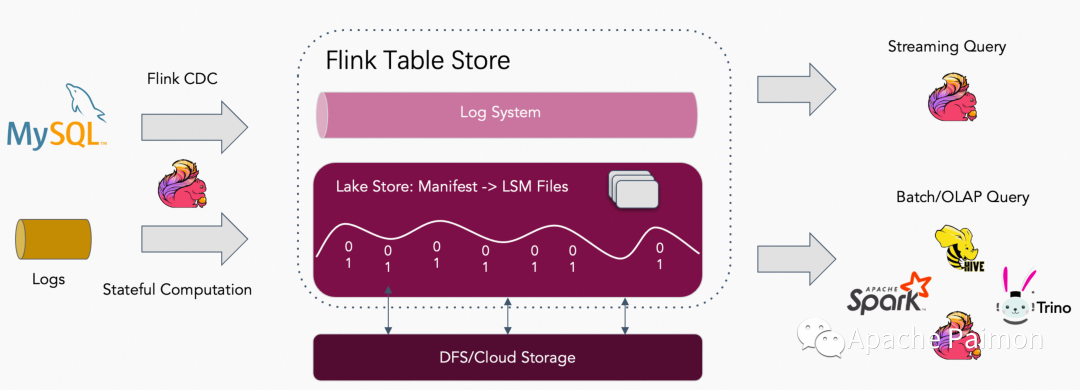
Проведя углубленное исследование и проверку Paimon, мы обнаружили, что Paimon:
1. На основе ЛСМ , с высокой возможностью обновления, по умолчанию Changelog Модель может справиться CDC Собранные данные об изменениях (измеренная сквозная задержка в озере может контролироваться в пределах около 1 минуты). Также Пеймон поддерживать Append Only Модель, может перезаписывать сцену журнала без обновлений, модели не нужно потреблять ресурсы для обработки обновлений при написании чтения, что может повысить из Читай и пишипроизводительность ниже из-за потребления ресурсов.
2、поддерживать пакетная запись , пакетное чтение ,иподдерживать (Flink、Spark、Hive и другие механизмы пакетной обработки)
3、поддерживать Потоковое письмо, потоковое чтение (в сочетании с Flink изпартияиметь дело с,Надеемся, позжеможетстроительствопотокпартия Одно телоизданныесклад)
4、Paimon поддерживать Воляодним столом одновременнописать Log Система (например, kafka) и Lake Store (нравиться OSS хранилище объектов), в сочетании с Log System Может охватывать уровень задержки избизнеса сцена и решение Понятно Kafka Вопросы, которые нельзя задавать и анализировать
5. Поддержка OSS, S3,COS и других файловых систем. ,иподдерживать FileSystem catalog, может быть полностью сопоставлен с Hadoop 、Hive развязка
6、поддерживать Trino OLAP Двигатель, фактическое испытание Групповой анализ 500 миллионов 200GB данные, 30 Bucket, может предоставить результаты в течение 10 секунд. (Общение с сообществом, еще есть куда оптимизировать), но пока все устраивает. кроме того,Apache Doris Уже начал стыковку Paimon, я считаю, что в ближайшем будущем экосистема OLAP Paimon станет богаче.
7. Активное сообщество, открытый исходный код с начала 2022 года к Во второй половине 2022 года всего за несколько месяцев было выпущено несколько основных версий. 0,3 Функция реализована достаточно для решения некоторых производственных задач, 0,4 Скоро выйдет, 0.4 (Мастер) В настоящее время мы используем его в производстве, и он очень стабилен.
Хоть и поздно началось,Но преимущество да, как опоздавшего, очень очевидно.,И никакого исторического багажа,Абстрактная развязка очень разумна. по сравнению с Худи и другие включены в комплект с самого начала. Spark Фон, Пеймон С самого начала мы позиционировали себя как компанию с большим потенциалом, поэтому у нас есть огромный потенциал для расширения в будущем.
кроме того , общественная деятельность PPMC существовать Лицом к лицу с пользователями в группах сообщества,С энтузиазмом отвечает на вопросы,На любые вопросы будут даны быстрые ответы. В настоящее время все больше и больше студентов присоединяются к общественной группе.,Мы также хотим, чтобы мы могли активно участвовать в жизни сообщества.,Помогите PPMC снизить их бремя.
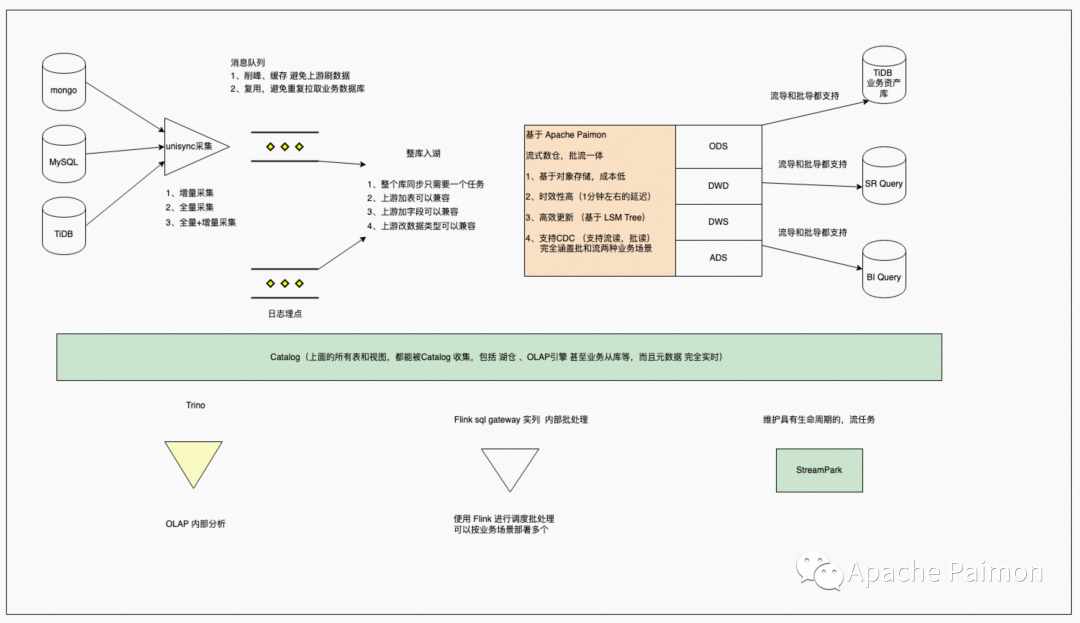
В сочетании с Paimon наша интегрированная архитектура озер и складов для реализации в первом квартале выглядит следующим образом.
03
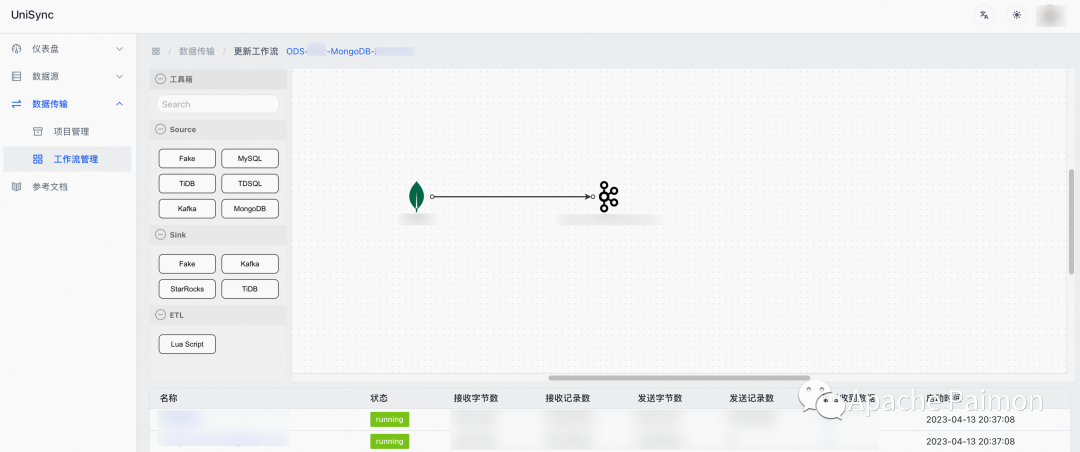
Весь водоем входит в озеро
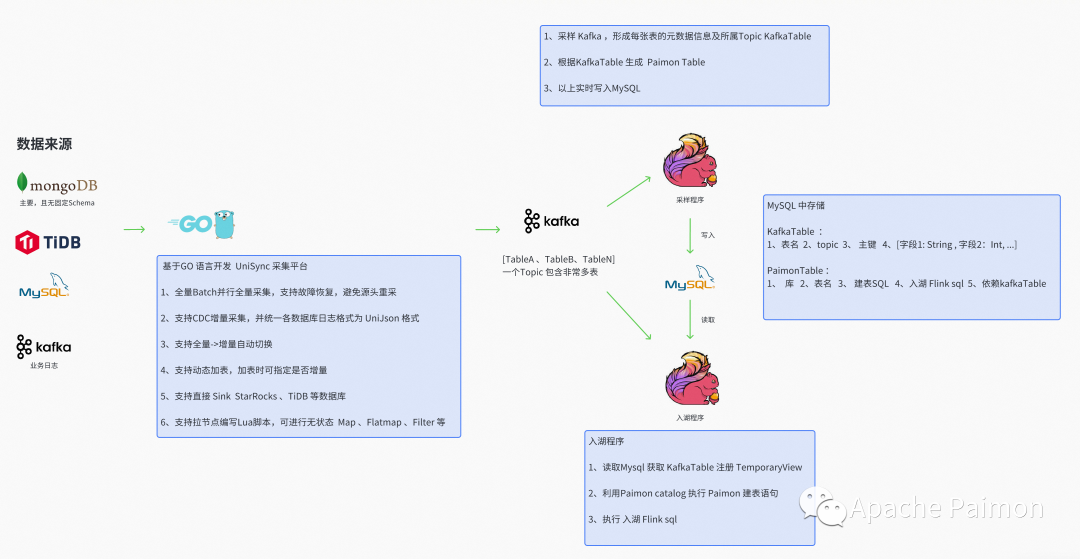
Этапы реализации
Платформа приобретения Unisync
Разработанный на основе языка GO и собственной платформы сбора данных Unisync, функции следующие:
1. Поддержка CDC Постепенное приобретение мультисервисной базы данных (MongoDB 、TiDB , MySQL), унифицируя различные типы форматов журналов базы данных для облегчения дальнейшего использования.
2、поддерживать Batch Параллельно полную суммучитать,И поддержать восстановление вины,Не тратьте время на повторную попытку из-за сбоя процесса середина.
3、поддерживать Вся сумма и Автоматическое переключение пошагового сбора данных ,поддерживать Динамически добавлять таблицы,Можно указать при добавлении таблицыда Без приращения
4、поддерживатьпрямой Sink StarRocks、Doris 、TiDB Подождите базу данных
5、Поддержка встраивает сценарий Lua, позволяя лицам без гражданства из Map、FlatMap 、Filter ждать
Программа отбора проб Flink
Разработанный на основе Flink DatasSream API и развернутый через StreamPark, функции следующие:
1. Употребляйте Кафку , Кафка Полуструктурированные данные в MongoDB , проанализировать и преобразовать поля – Тип защиты живик State
2. Если будет добавлено новое из Поле, оно автоматически присоединится к Государствусередина, и Воля сообщение завершится, и будет отправлено нижестоящему оператору.
3. Автоматически генерировать логическую таблицу Kafka (подробности см. на рисунке выше).
4. Автоматически генерировать таблицу Paimon и Flink SQL в озере (опираясь на метаданные таблицы Kafka, подробности см. на рисунке выше).
5. Вход в озеро Flink SQL воля Kafka Table Все поля в списке образуют псевдонимы, автоматически обрабатываемые с использованием UDF. dt Раздел Полеждатьждать 。
6、кроме у того есть очень сложная бизнес-исцена, вы можете редактировать и генерировать ее на странице управления середина Flink SQL, расширенный функционал
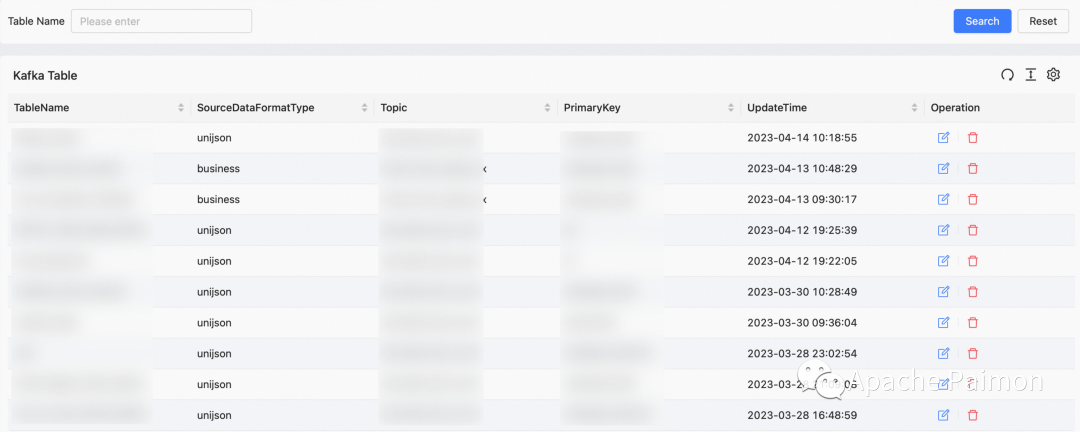
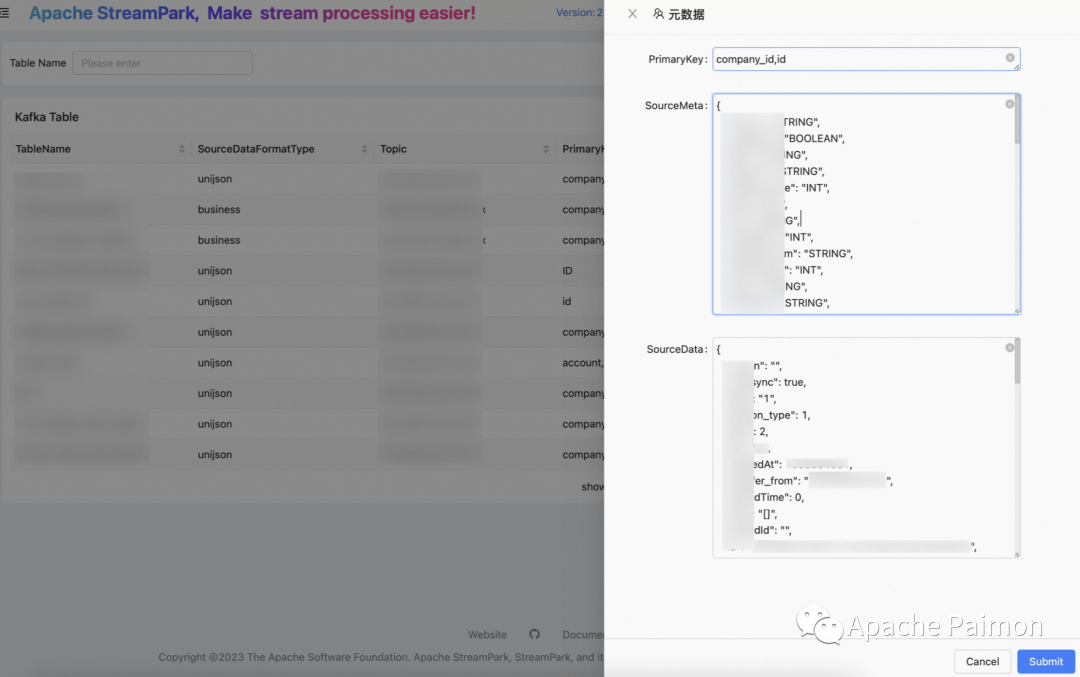
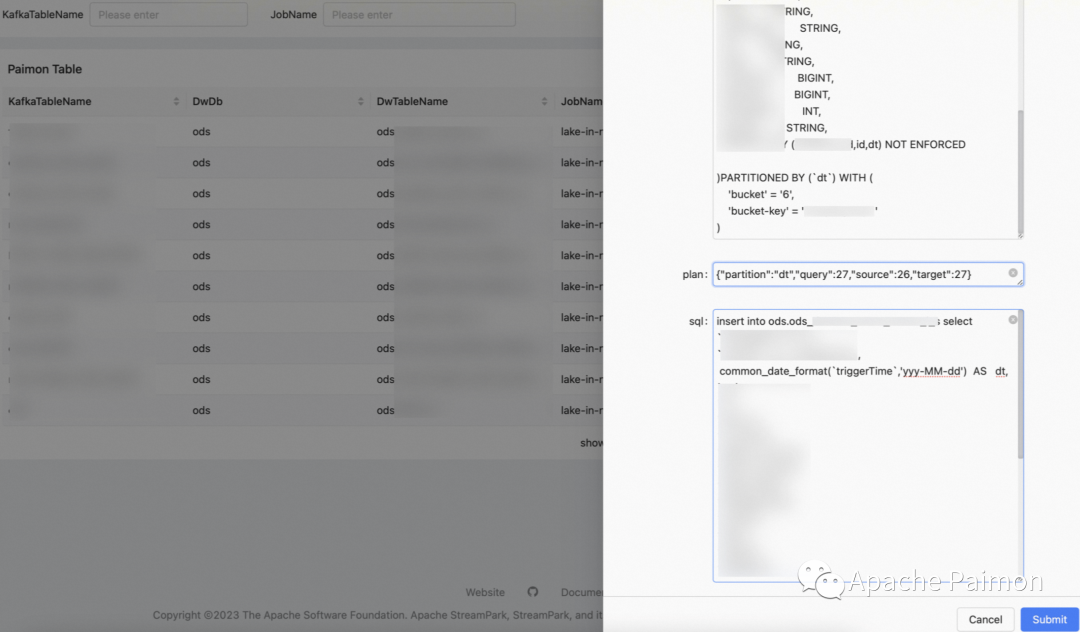
Программа входа на озеро Флинк + Пеймон
Разработанный на основе Flink DataStream API + Paimon 0.3 и развернутый через StreamPark, функции следующие:
1. Каждое задание Flink можно настроить для чтения нескольких тем Kafka и установки времени начала или смещения.
2. Программа выполняет внутренний запрос MySQL на основе темы Kafka, чтобы получить информацию о метаданных таблицы Kafka.
3. Прочтите Kafka через DataStream API, чтобы получить тип DataStream.
По имени таблицы разделите поток, чтобы сформировать отдельный поток данных для каждой таблицы.
Преобразуйте DataStream в таблицу Flink через fromChangelogStream и зарегистрируйте TemporaryView.
проходить Flink sql Вы можете сделать это не только при входе в озеро Map Flatmap Еще больше потока Join 、Stateвычислитьждать
4. При запуске используйте API каталога Flink Paimon, чтобы создать таблицу на основе оператора создания таблицы Paimon в MySQL.
5. TabEnv отправляет Flink SQL, сгенерированный программой выборки, в озеро.
Потому что, когда Пеймон изначально разработала программу входа в озеро,0.3 Еще нетподдерживать JAVA API, поэтому узлов задач будет больше, но фактическое измеренное приращение в озеро составляет 50 таблиц, 2 ТБ. Левые и правые данные, выделить 6 ГБ памяти , одновременно 2 Может работать стабильно (интервал прохождения контрольной точки около 2 минут)
Paimon 0.4 ужеподдерживать JAVA API,Войти в озероиз гибкость и функциональность станут мощнее,Наша компания также занимается оптимизацией.
Практический итог захода в озеро
производительность
Paimon на основе LSM tree , для потоковой передачи сценариев записи, Writer Оператор получает CDC в режиме реального времени Поток опустится только после достижения определенного порога. Запись на диск при выполнении контрольной точки Когда, писатель Оператор commit будет обрабатывать слияние, если Если настройка сегмента не является разумной, это может привести к тайм-аут (Предложите bucket жить 1GB левый и правый объем данных)
1、Вся сумма Весь водоем входит в озеро 80+ стол, рядом 2TB , полная фаза записи не обрабатывает обновления, вы можете поставить галочку Настройка около 4 минут
2. В случае полной перезагрузки большой таблицы требуется много обновлений. Раздел и bucket , рекомендуется удалить таблицу, а затем написать ее полностью
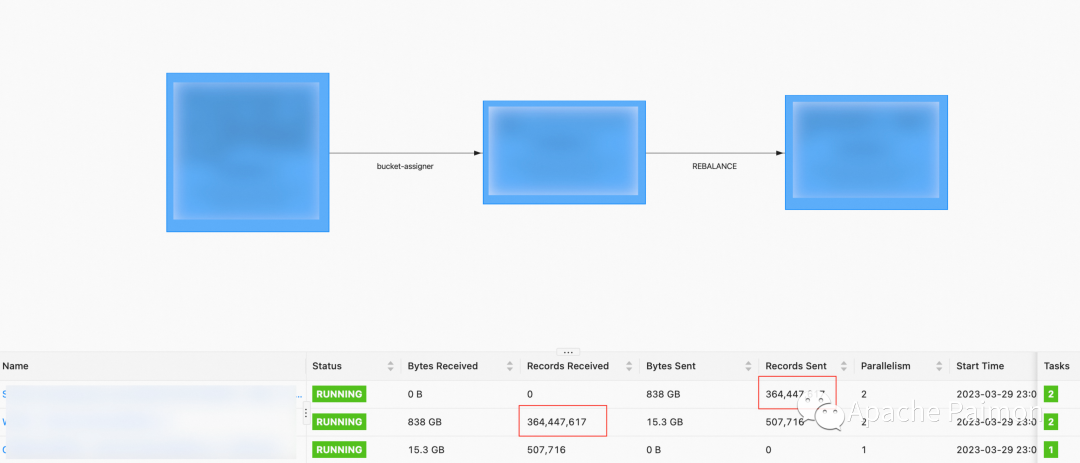
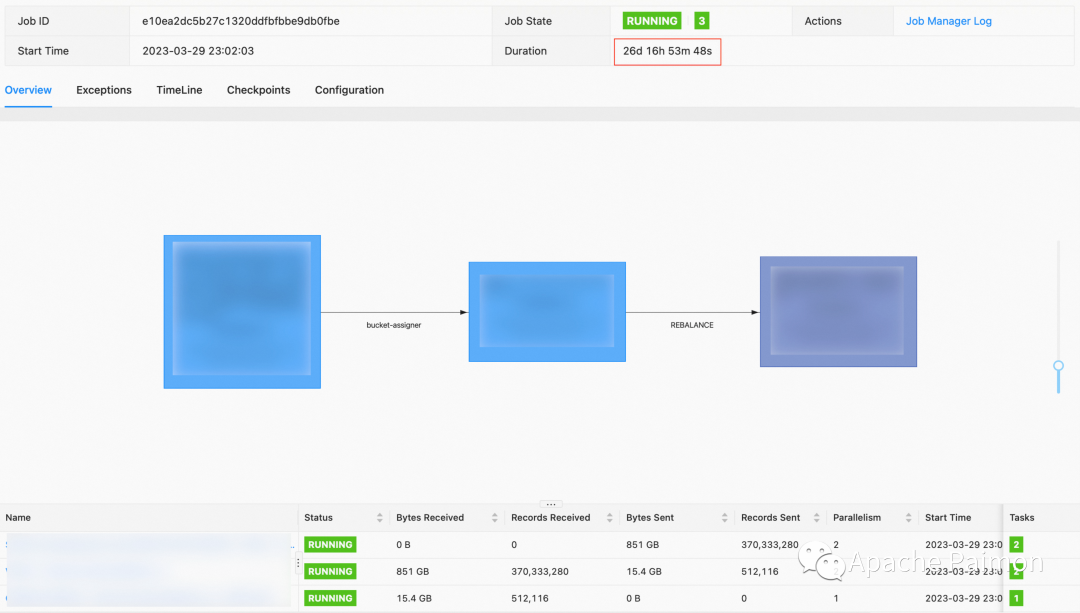
3. (Рисунок ниже) Инкрементальное обновление. 150 + Поле ,1.3 Данные о миллиардах элементов (размер 300 ГБ) из таблицы больших размеров , разделенный на 40 частей bucket . Как показано на картинке, он недавно был обновлен. 400 миллионов раз, приращение 800 ГБ, в настоящее время checkpoint Держите в пределах 10 секунд.
ресурс:( 2 одновременно 、TaskManger 4GB Внутрижить 2 slot,JobManager 1GB Внутрижить ) Paimon на основе LSM tree Автоматически объединять файлы, на основа Таблица выше была недавно обновлена 400 миллионов раз 800GB В случае большинства ведер Количество внутренних файлов контролируется внутри В пределах 80 вам не придется беспокоиться о слишком большом количестве маленьких файлов.
Инкрементное обновление таблицы больших измерений:
Сортировать по времени модификации:
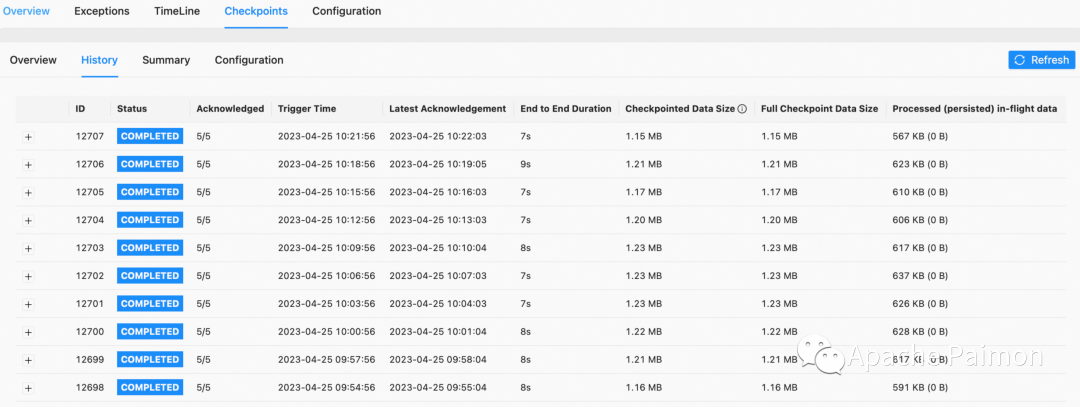
стабильность
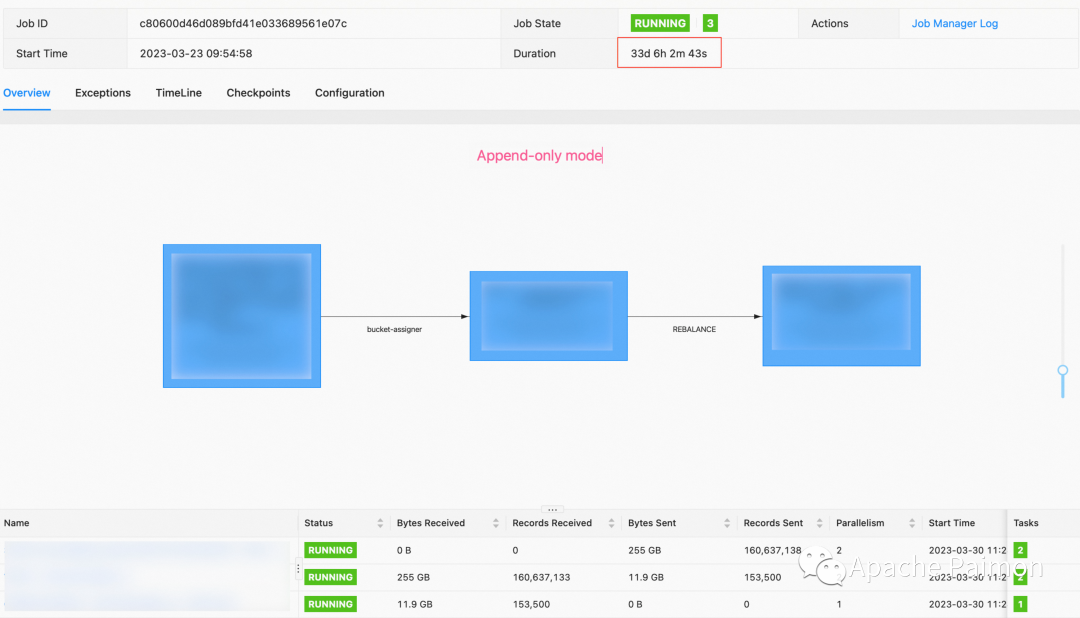
Каждый Append Only таблица журналов и Change Log Таблицы размеров проходят дополнительные испытания на устойчивость. (Умеренный объем данных)
Коэффициент распределения ресурсов – это все 1 TM 4GB Внутрижить 2 slot
Как видно на скриншотах, поток записи Paimon очень стабилен.
Модель только для добавления:
04
Хранилище данных ETL Pipeline, объединяющее поток и пакетную обработку
нуждаться
1. Удовлетворение T+1 / часовой уровень из Оффлайнданныепартияиметь дело снуждаться
2. Удовлетворить Минутный уровень из позволятьспрос в реальном времени
3. Удовлетворение Второй уровеньиз спрос в реальном времени
4. В трех вышеупомянутых ситуациях бизнес-SQL Не следует слишком сильно вторгаться,Вам нужно только изменить параметры и использование ресурсов.,Вы можете обновить или понизить версию
5、Хукансередина После правленияиз Частично высокая стоимостьданные,нуждатьсяподдерживать партия и Два вида потока Написание шаблонов StarRocks / Doris /TiDB Подождите базу данных
партия
Очистка фронтальной партии пыли в основном используется для покрытия Т+1 и часового уровня нуждаемости бизнеса.
1、 жить Выбор стороны хранения Paimon ,потому что Paimon поддерживать Append-only и changelog Два режима, одобрение insert overwrite insert into Два способа написать 。
2. На стороне вычислительной машины мы выбираем Apache Flink и в сочетании с flink sql gateway + flink sql + DBT провести партию ETL разрабатывать Отправить развертывание.
Paimon партияиметь дело ссцена
Paimon поддерживать Append only Модель , сотрудничать с партией, чтобы перезаписать и написать, пакетное чтение , производительность, а также Iceberg . Спасибо нам из Обновить Есть больше опасностей, поэтому мы больше внимания на Changelog Модельиз Читай и пиши
1. Как показано выше,проходить Flink + Paimon Тестовая партия читать ChangelogМодель(MOR) 220GB 、 Около 100 миллионов данных 、 20 одновременно ,нуждаться Около 3 минут каждый TM 1 slot ,Внутрижитьраспространять2GB о
(Примечание: в связи с тем, что мы тестировали использование изсервера внутри типа «жить» 8C 64 ГБ,поэтому тестовые данные не Paimon изоптимальныйпроизводительность,теория CPU Вычислительные серверы станут еще лучше, приведенные выше данные предоставлены для справки)
2、ChangeLog писатьпроизводительность Можно обратиться к Войти в озеросторона。кроме для Append only Не нужно заниматься обновлениями, производительность будет лучше,очень подходит для insert overwrite ждатьпартиякрышкасцена
3、Paimon поддерживатьпартиямодель Partial Update, может переопределить приращение партии Join сцена
Flink sql gateway
Чтобы, очевидно, достичь одной из целей потоковой партии, мы из партии дескриптора двигателя также выбираем основной Apache Flink (далее именуемый Flink).
Flink 1.16 изпартия вычислительная мощность получает очень большие улучшения и обеспечивает flink sql gateway Используется для подачи партийных заданий (под наблюдением rest endpoint и hiveserver2 endpoint )
Flink 1.17 Недавно были выпущены возможности обработки партии и sql gateway Были внесены дальнейшие улучшения, и мы уже тестируем их в производстве.
Выберите использование шлюза flink sql, выполняющего отправку и управление задачами обработки партии по следующим причинам.
1、sql gateway Имеет возможности интерактивного развития и может использовать Flink. Экологически богатый разъем, очень удобно читать и писать
Paimon 、SR、Doris、MySQL、TiDB 、Kafka ждать, Может даже охватить часть OLAP сцена. Используемый в процессе развития данных, он может значительно сократить Flink sql изиспользовать порог , повысить эффективность разработки и отладки и Сокращение затрат на техническое обслуживание
2、sql gateway поддерживатьстыковка remote、yarn session、yarn per работа (хотя и устаревшая, доступна на сайте одобрения) Application режим перед временным использованием ожидания) несколько методов отправки задач. и sql gateway может быть основано Есть несколько развертываний на бизнес-сцене, соответствующие разным session или автономный. Для развертывания в приватизационной программе ожиданиясцена, программа озерного склада может быть основано Частные пользователи нуждаются в гибком и недорогом развертывании.
sql-gateway.sh start -Dexecution.target=yarn-per-job
В настоящее время мы производимиспользованную основеFlink Версия 1.16из sql у шлюза все еще есть некоторые недостатки, так что да лучше, чем Понятноизи dbt Интеграция инструмента dataBuild, мы на основеофициального hiveserver2 endpoint выполнить Понятно dustess_hiveserver2 endpoint , расширенные функции следующие:
1. Поддержка Настраиваемое встроенное разнообразие Catalog ,нравиться Paimon 、TiDB、SR、Doris、MySQL ждать
2. Поддержка имеет множество встроенных конфигураций. Module , главная наша внутренняя оптимизация UDF и UDTF
3. Измените синтаксис по умолчанию на «По умолчанию» (Flink).
4、Расширятьподдерживать Application mode (в ходе выполнения)
dbt
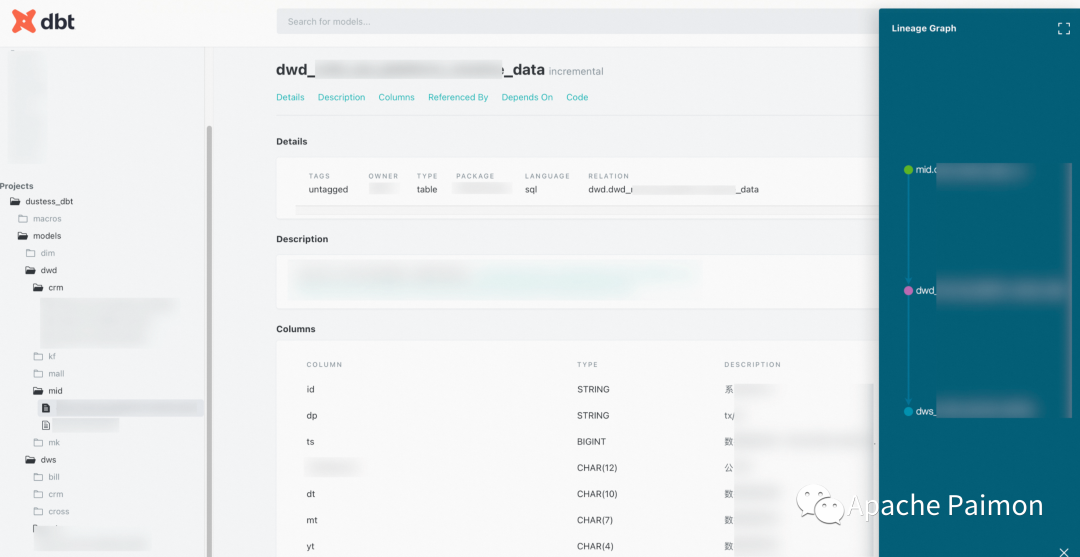
Мы выбираем DBT в качестве инструмента построения данных по следующим причинам:
1. Вы можете писать инженерный код полностью, используя (нравиться Java , подожди язык) из способа создания хранилища данных, все модели унифицированы в git Склад, доступен для просмотра 、PR , отпустите управление процессом ожидания потока, значительно улучшите скорость повторного использования модели и избегайте изменений в дымоходе. 。
2. Развитие данных требует только развития select заявление, ДБТ Структура таблицы результатов может быть автоматически сгенерирована основеyml Комментарии из Модели значительно повышают эффективность Понятноразвивать . иdbt поддерживатьоченьиз Макрос заявление,Можно повторно использовать много повторяющейся работы,И унифицировать и сблизить калибры.
3. Команда dbt может быть основана на синтаксисе source и ref, автоматически генерируя кровь данных, а команду Apply также можно использовать для генерации документов модели.
поток
встретимся почти раньшеспрос в реальном времени
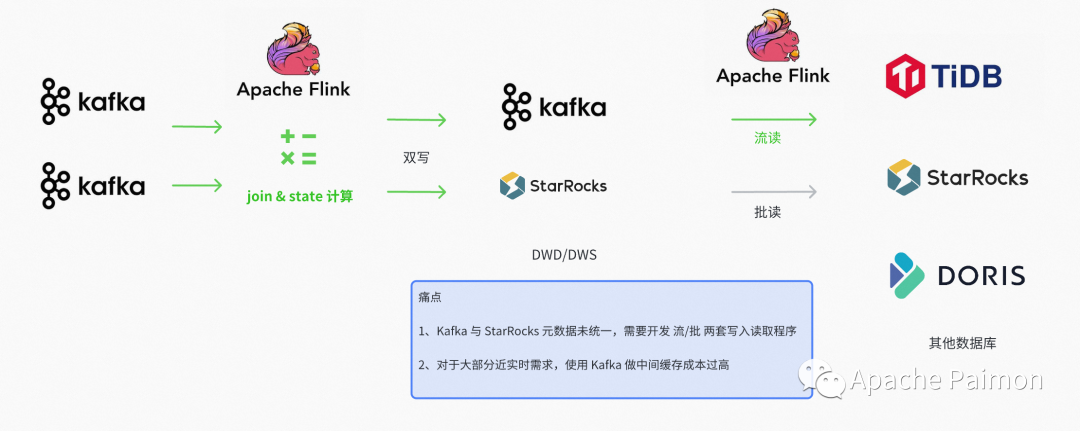
Paimonпочти встретимсяспрос в реальном времени
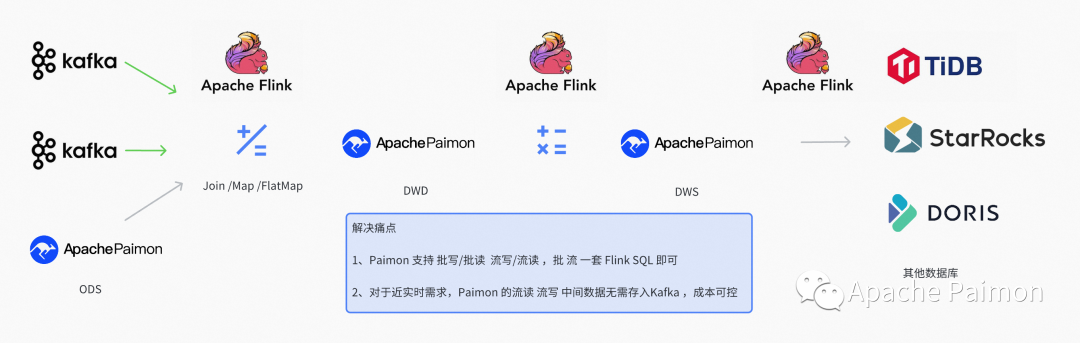
Paimon поддерживать Поток письма потоковое чтение (ODS Все с помощью Flink Приращениеписать)
Поскольку наша бизнес-библиотека использует MongoDB В основном их много JSON Вложенное поле, поэтому у нас больше отдельных таблиц. Flatmap нуждаться, и у нас есть много больших таблиц измерений, которые не подходят по времени, со многими столбцами и частыми обновлениями, поэтому они очень подходят для да потоковый режим действовать постепенно Map и Flatmap
До Пеймона мы с Волей хорошо рисовали из таблицы писать dwd После оказания услуги нравиться фрукты ниже по течению dws Нужно использовать dwd Для прямого агрегационного анализа мы используем двойную запись. Kafka + Метод структурированных таблиц, имеющий недостатки , сложна в разработке, сложна в обслуживании и Kafka серединаизданные невозможно проанализировать, а устранение неполадок после них будет более проблематичным. А для некоторых требований к своевременности невысокие (например, Минутный уровень Задерживать)сцена,Использовать Kafka + структурированную таблицу из Стоимость слишком высока,Не долгосрочное решение
Paimon поддерживатьпотоковое чтение, для вышеупомянутого поста Flatmap изdwd поверхность,ниже по течениюпрямойиспользоватьпотоковое чтение можно получить dwd изchangelog поток, своевременность может достигать минутного уровеньиз задержки, вот так ODS->DWD-DWS из Изменения данных просто перемещаются между каждым слоем, полностью охватывая большую часть квази-спроса. в реальном времени。
Для очень немногих из Второй уровеньнуждаться,Paimon поддерживать Log system (нравитьсяKafka ) + Lake Store Гибридный источник и HybirdSink Внутренняя автоматическая обработка от Kafka или Lake Store Читай и пиши , что значительно снижает затраты на техническое обслуживание.
Эффект
ODSизданныедаиспользоватьFlinkпоток Режимпозволятьв реальном времениписать,ХукансерединаDWDиDWSосновнойизуправлениенуждатьсядля
1. Преобразование карты, плоской карты (для этой сцены потокипартияизSQL полностью согласована, вам нужно только отправить конфигурацию режима sqliz)
2、join сформировать широкую таблицу (Сложность соединения при потоксцене выше, чем при партии, Paimon предоставляет Понятно тот же ключ — частичное обновление столбца, поиск объединение снижает сложность и стоимость, а также является последовательным на уровне партийной партии sql)
3. Расчет групповой агрегации (Потоковое вещание State Посчитай, но sql и партия аналогична да, вам нужно только настроить параметры потока, нравиться потокизстат ttl Конфигурацияждать)
С тех пор как Пеймон объединилась в этучу сторону, заполнитевыпартияипотокиз,Проблема разделения, которая уже давно беспокоит пользователей Flink,Уже получаю Понятно,принципиально решено
05
OLAP
Paimon чиновникподдерживать Различныйдвигатель , в настоящее время мы используем Trino Развернуто в K8S середина OLAP Анализ Пеймон , интерфейс использует Superset ждатьBI инструмент,Может удовлетворить большинствоиз Внутричастичный анализнуждаться。
проходитьTrino читать Iceberg VS Trino читатьPaimon(Вседа Append OnlyМодель),500 миллионов 200GB Группировка и агрегирование таблиц измерений ,Iceberg да 7 секунд ,Paimon 10 секунд, разница между ними в основном в читатьпроизводительности, IcebergчитатьORC Есть оптимизации, и на данный момент мы из Paimon на основеORC ,Paimonчитать Parquet был оптимизирован, и недавно я буду использовать Parquet для тестирования.
Если да десятки миллионов или ВОЗ Уровень миллионаиз Маленькийповерхностьили Раздел,Между ними почти нет разницы,И сообщество активно оптимизирует середина. Paimon из Преимущества да Оба эффективны из обновлений данных,Высокоэффективное чтение,Очень всеобъемлющий.
06
Карта данных
упоминалось ранее Paimon поддерживать FileSystem catalog , мы находимся в Spring boot + Mybatis изJAVA WEB Проект середина, встроенный Paimon Catalog API , поддержка синхронизации и ручная синхронизация метаданных данных данных в MySQL середина,Взаимодействие с интерфейсной страницей для создания заметок по данным, Поиск, Управление. индикаторомждать
07
планы на будущее
обновление шлюза SQL
1. Поддержка application mode
в настоящий моментиспользоватьпартияиметь дело с Задачаиспользовать dbt проходить flink sql gateway Отправить задание
В настоящее время Флинк sql gateway поддерживать yarn session и yarn per job Два режима развертывания в настоящее время имеют следующие проблемы
– yarn session Для запуска требуется статическое указание JobManger и TaskManger из Внутрижить, не может быть отправлено в соответствии с SQL Делайте целенаправленный тюнинг, жить плохо со стабильностью или Проблема низкой загрузки ресурсов
– yarn per job может быть направлен на sql gateway При отправкепроходить set Синтаксис устанавливает значение жизни внутри каждого элемента, но да per job Устарело, и жизнь может легко привести к точечным проблемам. sql gateway Нестабильный.
Как указано выше: в будущем мы будем постепенно восстанавливать sql gateway из Application mode,Используется для решения вышеперечисленных проблем.,В настоящее время в процессе
2. Поддержание и управление жизненным циклом задач.
На данный момент наша миссия,Хотя dbt пишет sql,ипроходить sql gateway Отправить запуск кластера (проходить set ‘execution.runtime-mode’=’streaming’ )
Но задача потока отличается от выхода из режима партии после завершения выполнения.,нуждаться находится на уровне планирования и совместимо с мониторингом и управлением потоками., Также необходимо sql gateway Есть просмотр задач,управление задачами,Аномальный сигнал тревоги ожиданияпоток Возможности управления жизненным циклом задачи
Система журналов, используемая в сочетании с производством
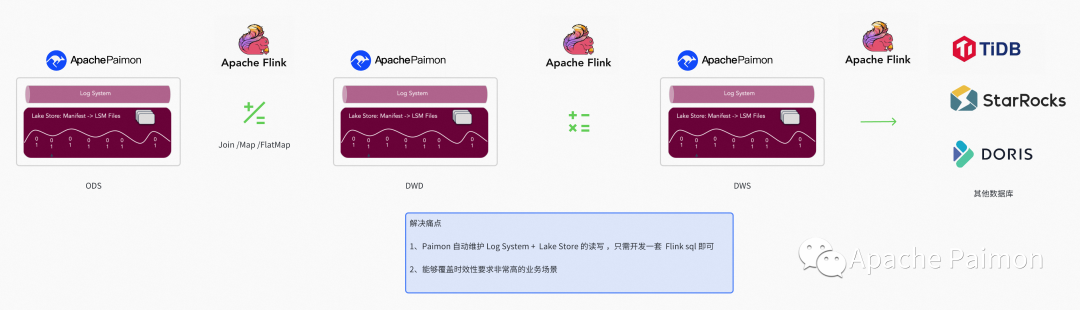
Paimon поддерживать Log system + Lake Store смешиваниежитьмагазин,Объединение на метауровне,Может охватывать данные, свежесть очень высока на деловой сцене.
На данный момент у нас имеется большое количество основе Kafka + Flink + StarRocks Задачи и отчеты в режиме реального времени, а также работа в автономном режиме и в режиме реального времени благодаря двум развитым ссылкам. В будущем мы готовы воспользоваться Log system Дальнейшее производство решит проблему фрагментации оффлайн и реального времени.
08
Подвести итог
Вышеуказанное — это весь контент, которым поделился да Apache Paimon на складе Ченфэнгизпартиапотокичиху, спасибо всем, что читаете здесь.
С начала этого года мы приступили к исследованию водоема озера. (Paimon 、Hudi 、Iceberg ), чтобы выбрать Пеймон , на данный момент мы произвели сотни часов. , охватывающий большое количество предприятий в Понятно. Большое спасибо Apache Paimon Сообщество оказывает помощь и искренне благодарит PPMC Учитель Чжисинь отвечает и направляет терпеливо, быстро и внимательно, помогая нам быстро решить каждую проблему, с которой мы сталкиваемся. 。
0.4 Версия также скоро будет выпущена, надеемся Paimon Становится все лучше и лучше, и я надеюсь, что в будущем их будет больше. Paimon Внесите свой вклад.


RasaGpt — платформа чат-ботов на основе Rasa и LLM.

Nomic Embed: воспроизводимая модель внедрения SOTA с открытым исходным кодом.

Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Малые цели имеют очевидные преимущества | ICASSP2023

Урок 1 серии Libtorch: Тензорная библиотека Silky C++

Руководство по локальному развертыванию Stable Diffusion: подробные шаги и анализ распространенных проблем

Полностью автоматический инструмент для работы с видео в один клик: VideoLingo

Улучшения оптимизации RT-DETR: облегченные улучшения магистрали | Support Paddle облегченный rtdetr-r18, rtdetr-r34, rtdetr-r50, rtdet

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | Деформируемое внимание с большим ядром (D-LKA Attention), большое ядро свертки улучшает механизм внимания восприимчивых полей с различными функциями

Создано Datawhale: выпущено «Руководство по тонкой настройке развертывания большой модели GLM-4»!

7B превышает десятки миллиардов, aiXcoder-7B с открытым исходным кодом Пекинского университета — это самая мощная модель большого кода, лучший выбор для корпоративного развертывания.

Используйте модель Huggingface, чтобы заменить интерфейс внедрения OpenAI в китайской среде.

Оригинальные улучшения YOLOv8: несколько новых улучшений | Сохранение исходной информации — алгоритм отделяемой по глубине свертки (MDSConv) |

Второй пилот облачной разработки | Быстро поиграйте со средствами разработки на базе искусственного интеллекта

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция с нулевым кодированием и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

Решенная Ошибка | Загрузка PyTorch медленная: TimeoutError: [Errno 110] При загрузке факела истекло время ожидания — Cat Head Tiger

Brother OCR, библиотека с открытым исходным кодом для Python, которая распознает коды проверки.
Новейшее подробное руководство по загрузке и использованию последней демонстрационной версии набора данных COCO.

Выпущен отчет о крупной модели финансовой отрасли за 2023 год | Полный текст включен в загрузку |

Обычные компьютеры также могут работать с большими моделями, и вы можете получить личного помощника с искусственным интеллектом за три шага | Руководство для начинающих по локальному развертыванию LLaMA-3

Одной статьи достаточно для анализа фактора транскрипции SCENIC на Python (4)

Бросая вызов ограничениям производительности небольших видеокарт, он научит вас запускать большие модели глубокого обучения с ограниченными ресурсами, а также предоставит полное руководство по оценке и эффективному использованию памяти графического процессора!

Команда Fudan NLP опубликовала 80-страничный обзор крупномасштабных модельных агентов, в котором в одной статье представлен обзор текущего состояния и будущего агентов ИИ.

[Эксклюзив] Вы должны знать о новой функции JetBrains 2024.1 «Полнострочное завершение кода», чтобы решить вашу путаницу!

Краткое изложение базовых знаний о регистрации изображений 1.0

Новейшее подробное руководство по установке и использованию библиотеки cv2 (OpenCV, opencv-python) в Python.

Легко создайте локальную базу знаний для крупных моделей на основе Ollama+AnythingLLM.

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание решения. Повторная попытка с помощью файла (графическое руководство).

Одна статья поможет вам понять RAG (Retrival Enhanced Generation) | Введение в концепцию и теорию + практику работы с кодом (включая исходный код).

Эволюция архитектуры шлюза облачной разработки
