Практическое введение в сканирование Python: 250 лучших фильмов о Дубане (гарантирую, вы это знаете, но меня не ударите)
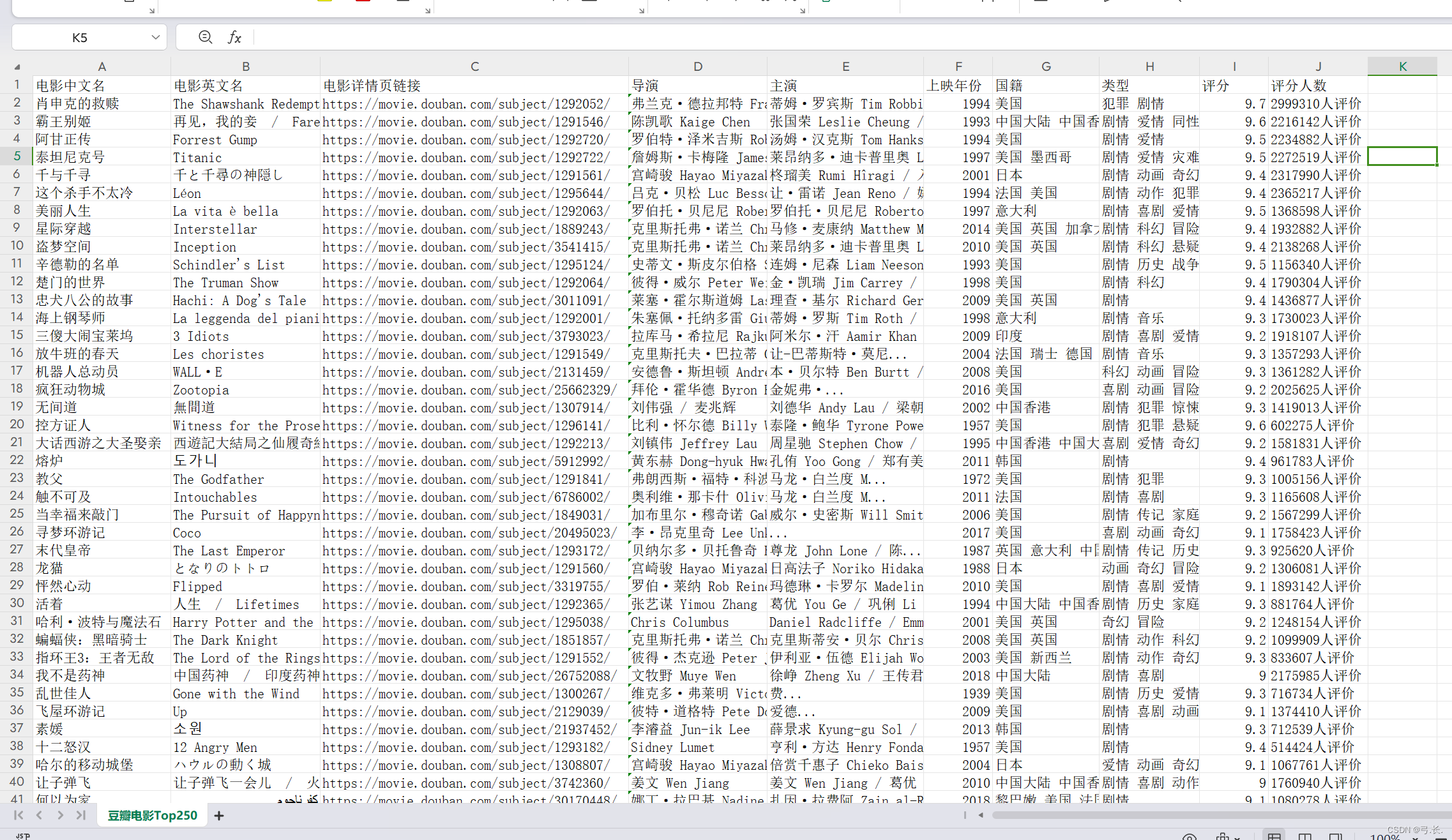
Целевой веб-сайт: https://movie.douban.com/top250 нуждаться: Ползтикитайское название фильма、Английское имя、Ссылка на страницу с описанием фильма、директор、В главных ролях、Год выпуска、национальность、тип、счет、счет Количество человек, и сохраните его в CSV-файл целевой URL:
https://movie.douban.com/top250
Требуемые сторонние библиотеки
requestslxml
Установить
requestsУстановить Заказ:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests lxmlУстановить Заказ:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple lxml
Введение
модуль запросов
Requests — это широко используемая сторонняя библиотека языка программирования Python. Она может помочь нам отправлять различные типы запросов на HTTP-серверы и обрабатывать ответы.
- Отправьте GET, POST и другие методы запроса на веб-сервер;
- Добавляйте в запрос пользовательские заголовки, параметры URL, тело запроса и т. д.;
- Автоматическая обработка файлов cookie;
- Вернуть содержимое ответа и декодировать его;
- Обработка таких операций, как сброс и переходы;
- Проверьте код состояния ответа и время, затраченное на запрос.
lxml-модуль
учиться lxml-модульиxpathграмматика
lxml да Python Широко используемая сторонняя библиотека в языках программирования, обеспечивающая эффективный и простой способ синтаксического анализа и обработки. XML и HTML документ.
- Чтение документов XML или HTML из файлов или строк;
- используйте селектор XPath или CSS для поиска и извлечения изданных в документе;
- анализировать XML или HTML документ и преобразовать его в Python объектилинить;
- Модифицировать, реконструировать и сериализовать документы;
- Работа с пространствами имени CDATA Ждите особых обстоятельств.
Чтобы извлечь конкретное содержимое из текста в формате html или xml, нам необходимо освоить грамматику lxml-модульиспользоватьxpath.
- lxml-модуль может использовать грамматику правил XPath для быстрого поиска HTML\XML. Конкретные элементы в документе и получение информации об узлах (текстовое содержимое, значения атрибутов)
- XPath (XML Path Language) да здесь HTML\XML Найдите информацию в документахизязык,доступен в HTML\XML документсерединаверноОбход элементов и атрибутов。
- W3SchoolОфициальная документация:http://www.w3school.com.cn/xpath/index.asp
- извлекатьxml、htmlсерединаизданныенуждатьсяlxml-модульиxpathграмматика Сотрудничатьиспользовать
Синтаксис xpath — базовый синтаксис выбора узла
- XPath использует выражение пути для выбора из узла или набора узлов в XML-документе.
- эти путивыражениеи Мы регулярноизвыражение, наблюдаемое в файловой системе компьютераочень похоже。
- использовать плагин Chrome при выборе вкладки,При выборе,Выбор тега из добавит атрибут class="xh-highlight"
Синтаксис Xpath для поиска узлов и извлечения атрибутов или текстового содержимого.
выражение | описывать |
|---|---|
nodename | Выберите элемент. |
/ | Из корневого узла Выбрать、или — это переход между элементами да и элементами из. |
// | Выбирает узлы в документе из текущего узла, соответствующего выделенному, независимо от их положения. |
. | Выберите текущий узел. |
… | Выберите родительский узел текущего узла. |
@ | Выберите атрибуты. |
text() | Выбрать текст. |
Синтаксис модификации узла синтаксиса xpath
Конкретные узлы можно получить на основе значения атрибута, индекса и т. д. метки.
Синтаксис модификации узла
путьвыражение | результат |
|---|---|
//title[@lang=“eng”] | Выберите все элементы заголовка, значение атрибута lang которых равно eng. |
/bookstore/book[1] | Выбирает первый элемент book, который является дочерним элементом bookstore. |
/bookstore/book[last()] | Выбирает последний элемент book, который является дочерним элементом bookstore. |
/bookstore/book[last()-1] | Выбирает предпоследний элемент book, который является дочерним элементом bookstore. |
/bookstore/book[position()>1] | Выберите элемент книги в книжном магазине, начиная со второго. |
//book/title[text()=‘Harry Potter’] | Выделите все элементы заголовка под книгой, выберите только элемент заголовка с текстом «Гарри Поттер». |
/bookstore/book[price>35.00]/title | Выберите все элементы заголовка элемента «книга» в элементе «книжный магазин», а значение элемента «цена» должно быть больше 35,00. |
О индексах XPath
- в XPath,Первый элемент из позиции да1
- последнийэлементиз Расположениедаlast()
- Предпоследний далласт()-1
Синтаксис xpath — другой общий синтаксис выбора узла
- // цель
-
- //a Все a на текущей html-странице
- bookstore//book Все элементы книги в книжном магазине
- @ изиспользовать
-
- //a/@href Все hrefs
- //title[@lang=“eng”] Выберите тег заголовка lang=eng.
- text() изиспользовать
-
- //a/text() Получить весь текст под
- //a[texts()=’Следующая страница’] Получить текст следующей страницы изтег
- a//text() Весь текст под
- xpath, чтобы найти конкретный узел
-
- //a[1] выбирает первый s
- //a[last()] Последний
- //a[position()<4] первые три
- Включать
-
- //a[contains(text(),"Следующая страница")]Выбрать текст Включить три слова на следующей странице изтег**
- //a[contains(@class,‘n’)] classВключатьnизтег
Практическое руководство
Открыть сайт
https://movie.douban.com/top250
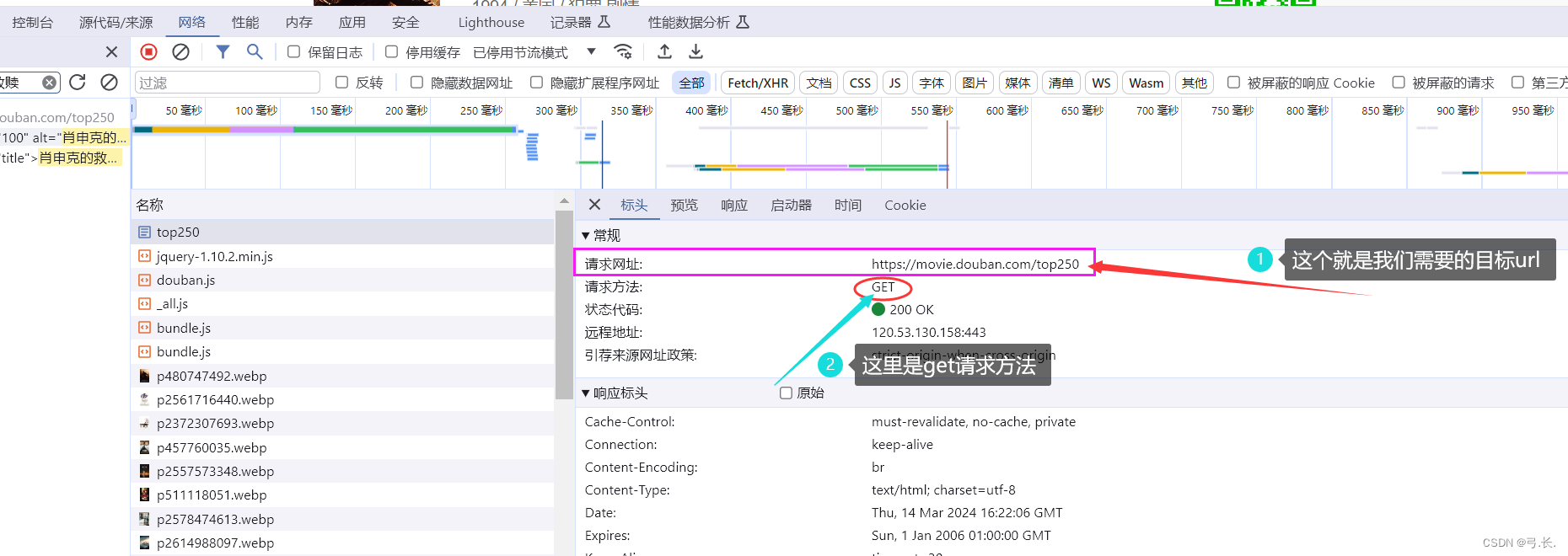
После входа на сайт щелкните правой кнопкой мышиисследовать,или ВОЗF12Подойди к консоли,Нажмитесеть,Затемобновить。
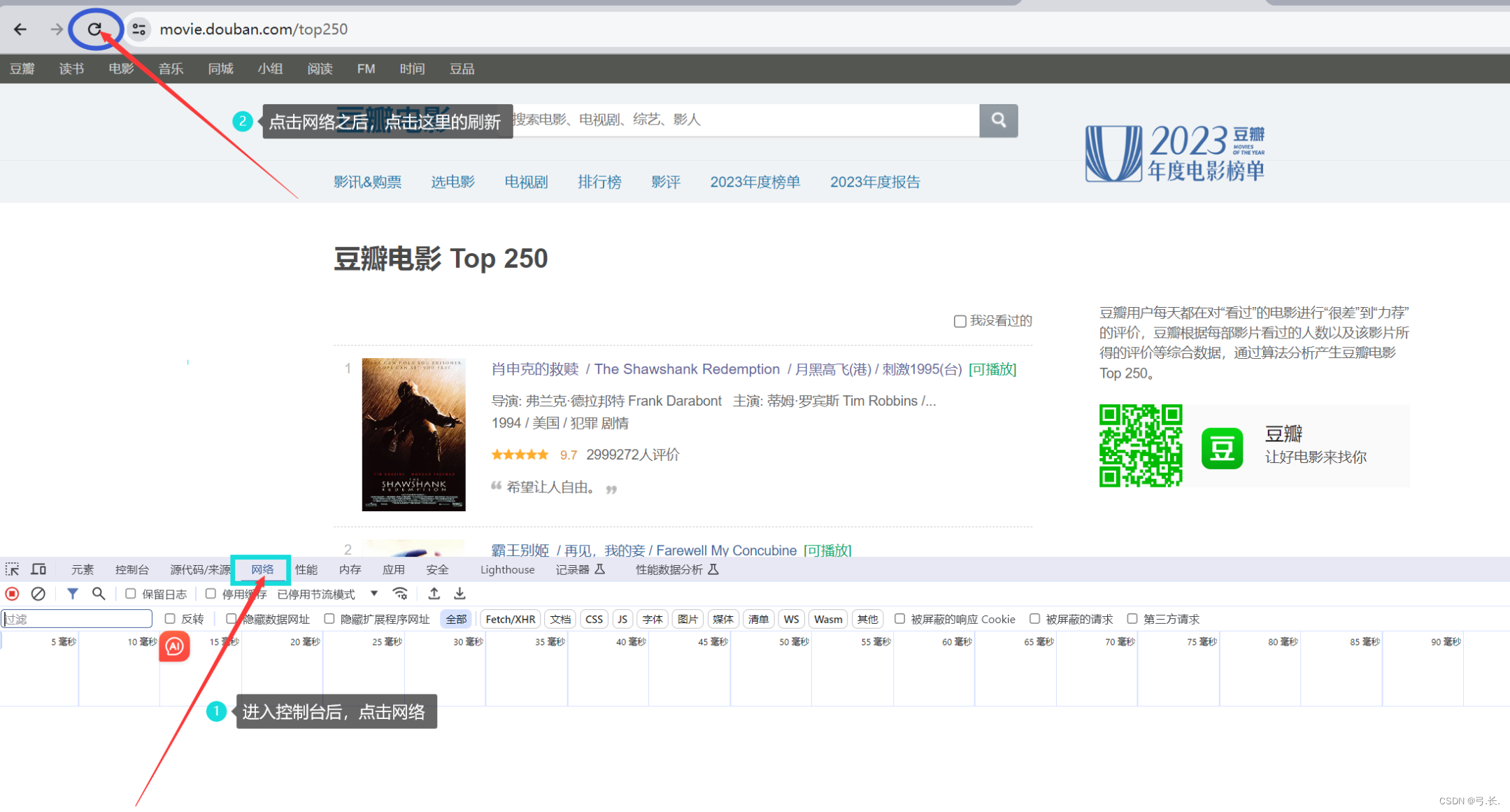
обновитьпосле,Нажмитечтолупаискать тебянуждатьсяизизданныесодержание,Таким образом, вы сможете напрямую найти нужную вам изданную посылку.
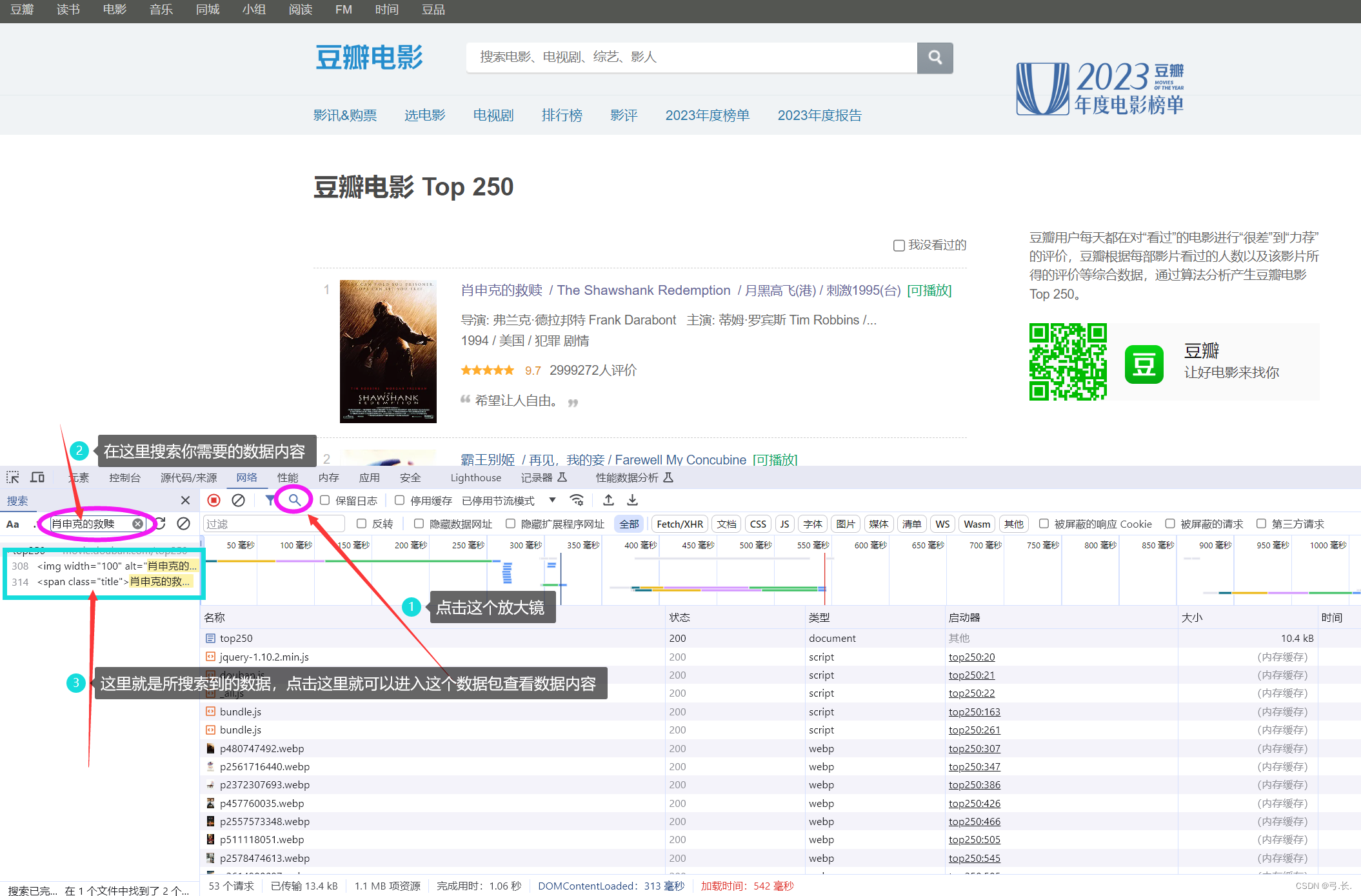
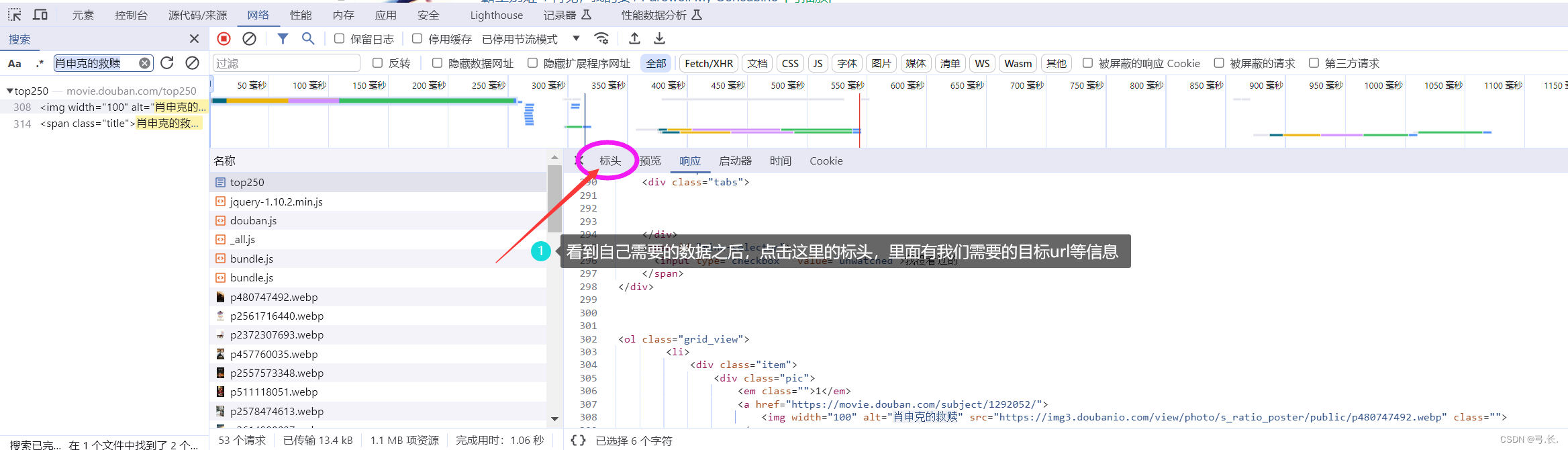
После нажатия на пакет данных,Прежде всего, нам нужно проверить, все ли необходимые нам изданные находятся в этом пакете данных.,Если нам нужны изданные, в этом пакете данных их нет.,Тогда этот пакет может быть не тем, что нам нужно.,Для поиска отдельно, если нам нужны изданные, это все есть в этом пакете данных;,Вот эта сумка с данными — все, что нам нужно, — это изданная сумка.,Далее мы будем Нажмитезаголовок,внутри Мы тамнуждатьсяизurlи другая информация。
# Модуль импорта
import requests
# целевой URL
url = 'https://movie.douban.com/top250'
# отправить запрос, Получить ответ
res = requests.get(url) # Внутри заголовка метода запроса даGET, Итак, здесь мы используем метод запроса get
print(res.text)
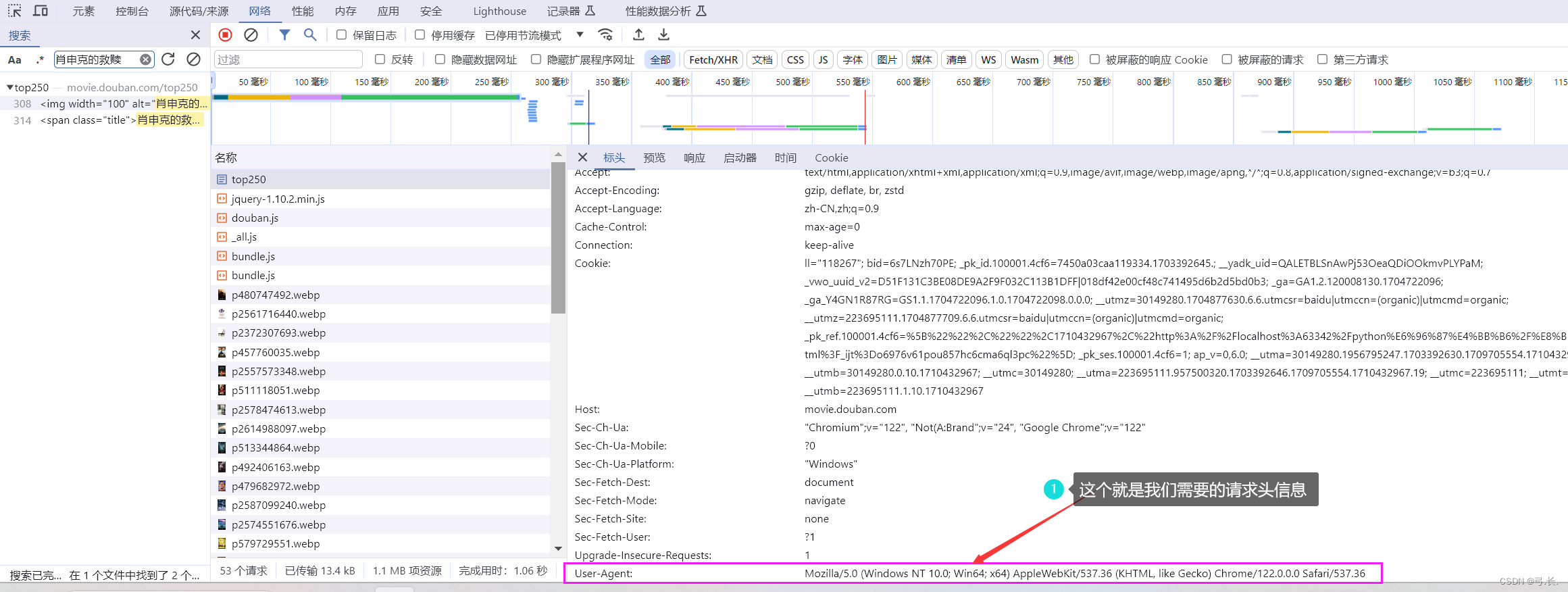
После печати мы обнаружили, что содержимое не выводится. Это связано с тем, что в случае рептилий веб-сайт может принимать некоторые меры против рептилий, чтобы предотвратить чрезмерный доступ программы рептилии к веб-сайту и получение данных веб-сайта. Так, чтобы избежать антисканирования, нам нужно установить соответствующую информацию заголовка запроса, чтобы имитировать реальное поведение браузера, и установить соответствующую информацию заголовка запроса. User-Agent идругой Запросить информацию заголовка,Делает запрос более похожим на обычный доступ из браузера.
Так User-Agent Где его найти?
Не волнуйтесь, это тоже есть в нашем заголовке. Мы можем найти его, проведя мышью вниз. User-Agent 。
# Модуль импорта
import requests
# целевой URL
url = 'https://movie.douban.com/top250'
# Добавить информацию заголовка запроса
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
# отправить запрос, Получить ответ Здесь изheaders=да ключевое слово
res = requests.get(url, headers=headers) # Внутри заголовка метода запроса даGET, Итак, здесь мы используем метод запроса get
print(res.text)Уведомление:здесьизЗапросить информацию заголовка Словарьиз Форматписать

можно увидеть,Мы добавили Запросить информацию заголовканазад,Запустите его еще раз, и результат будет,мы можем использоватьCTRL + FНайдите немногоданные,Посмотрите на эту распечатку: Нет, нам нужно из,Также проверьте печать данных да, чтобы убедиться, что чего-то не хватает.,если есть,Это доказывает, что анти-альпинизма до сих пор нет.,Вам также необходимо добавить некоторые другие параметры защиты от сканирования.,Разные веб-сайты требуют разных параметров защиты от сканирования.。Но ты не можешь сделать все это сразуиз Добавить все параметры,Некоторые возможные ловушки параметров,Если добавлено, будет сообщено об ошибке.
Затем извлеките данные на да,То естьнуждаться Мы импортируемlxmlмодуль。
lxml-модульизиспользовать
Импортируйте библиотеку etree lxml.
from lxml import etree
Используйте etree.HTML,Преобразовать строку html (bytestypepilstrtype) в объект Element,Объект элемента имеет метод xpathiz.,Вернуться к списку результатов
html = etree.HTML(text)
ret_list = html.xpath("Строка правила xpathграмматики")Три ситуации, в которых метод XPath возвращает список
- Возвращает пустой список: строка в соответствии с правилами грамматики XPath.,Ни один элемент не расположен
- Возвращает список, состоящий из строк: строковое правило xpath соответствует определенному текстовому содержимому или определенному атрибуту из значения.
- Возвращает список, состоящий из объектов Element: строка правила xpath, соответствующая тегу изда,объекты изElement в списке могут продолжать xpath
# Модуль импорта
import requests
from lxml import etree
# целевой URL
url = 'https://movie.douban.com/top250'
# Добавить информацию заголовка запроса
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
# отправить запрос, Получить ответ Здесь изheaders=да ключевое слово
res = requests.get(url, headers=headers) # Внутри заголовка метода запроса даGET, Итак, здесь мы используем метод запроса get
# Исходный код веб-страницы
html = res.text
# Создайте экземпляр объекта etree
tree = etree.HTML(html)Извлечение данных с использованием синтаксиса XPATH
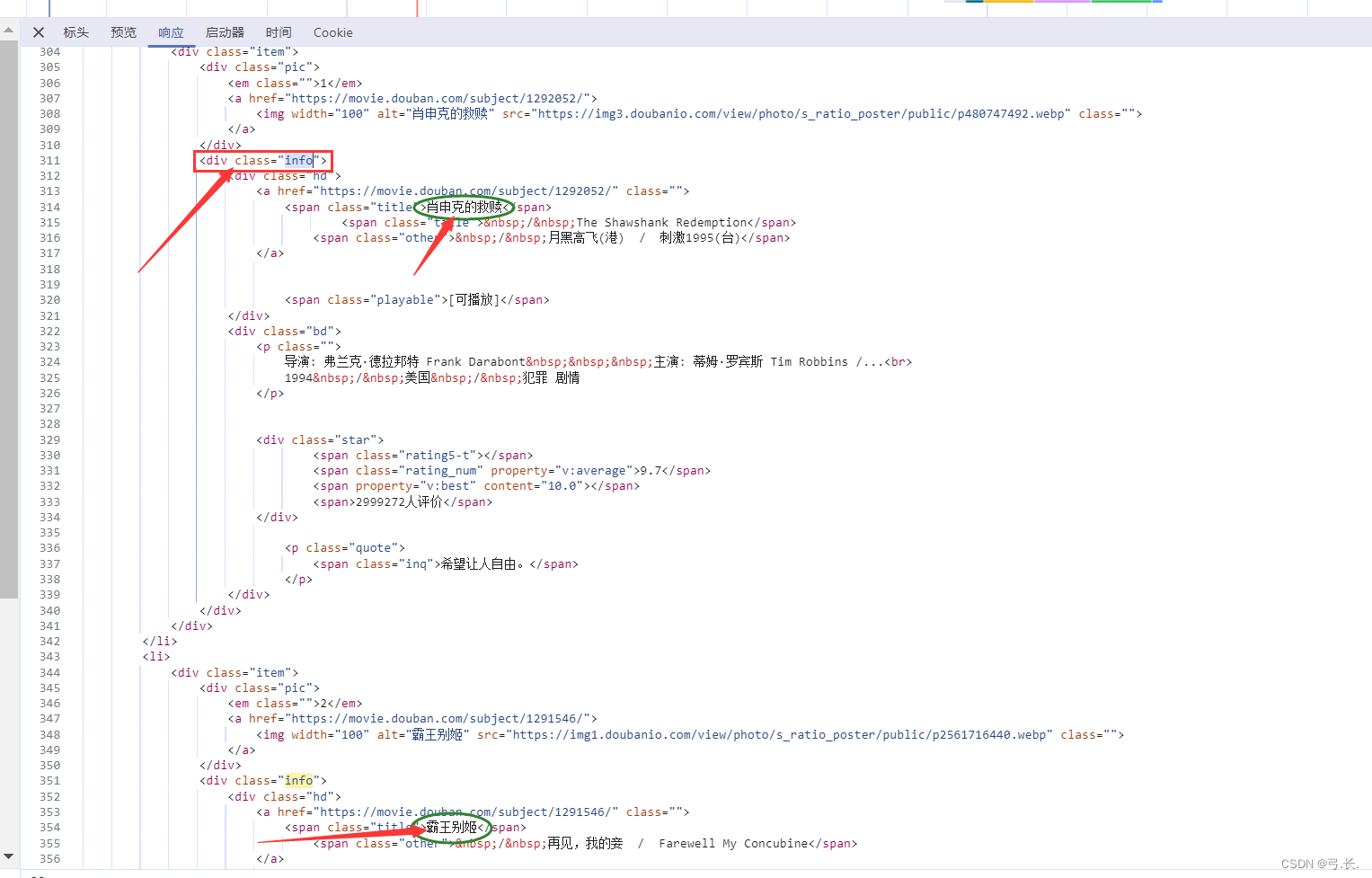
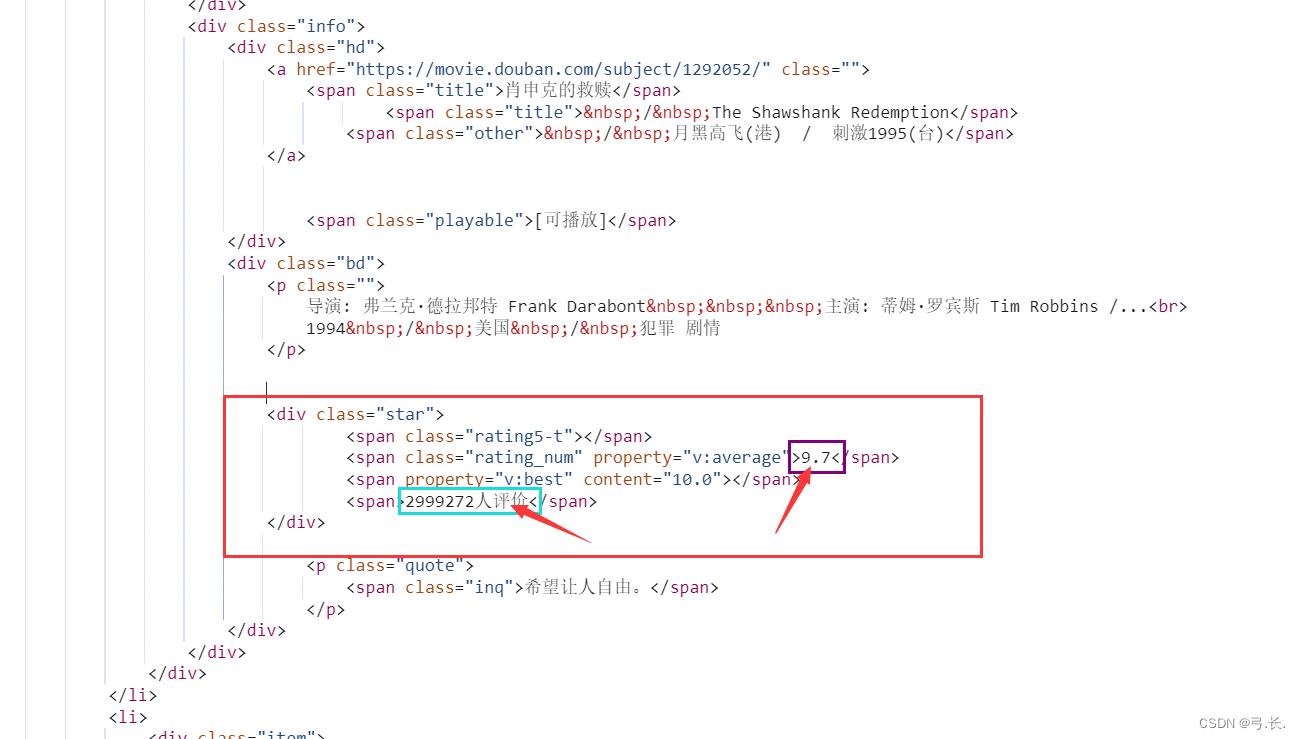
Нажмите, чтобы ответить,мы можем видеть,Что мынуждатьсяиз Фильмимяи другая информация Все в этом<div class="info">внутри этого тега,Так Мы можем напрямую использоватьxpathграмматиканайди этот тег。
# использоватьxpathоказаться<div class="info">этот ярлык
divs = tree.xpath('//div[@class="info"]')
print(divs)
можно увидеть,Распечатать список изда,Поскольку я перечислю,Мы можем использовать цикл для обхода элементов списка.,И нам нужно, чтобы из Фильмданные также находились внутри этих элементов тега. Вот пример фильма,Распределение данных остальных фильмов аналогично первому фильму.,Закончил первый,другойиз Вот и всеРеализовано через циклы。
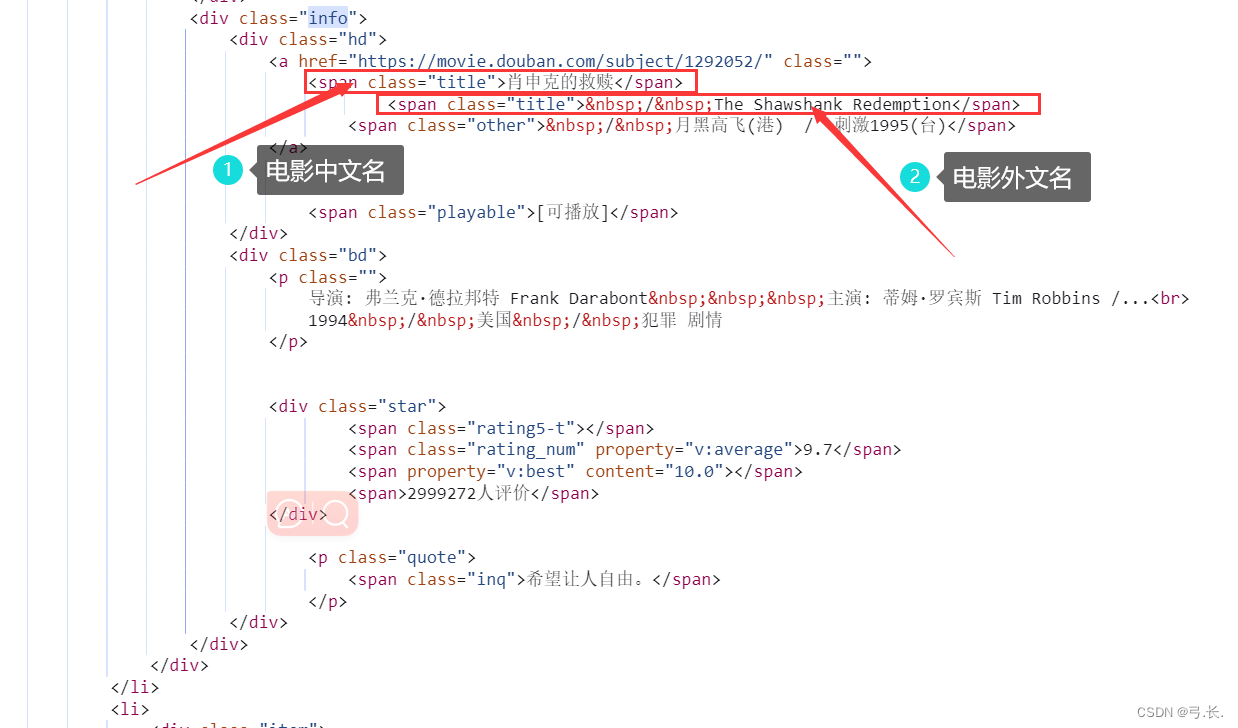
У нас уже естьоказаться Понятно<div class="info">этот ярлык,возвращатьсяизданныетипдаонсписок,Перебирать элементы в этом списке,Так Мы поищем его дальше Этикеткаэлемент Вот и все Непосредственно с<div class="info">Найдите его для родительского узлаиз Дочерние теги。
Вот китайское название фильма Например,<div class="info">из Ярлык следующего уровняда<div class="hd">Просто на следующем уровнедаонтег,Затем Сразудакитайское название фильмарасположениеиз<span class="title">Этикетка。
# использоватьxpathоказаться<div class="info">этот ярлык
divs = tree.xpath('//div[@class="info"]')
# print(divs)
for div in divs:
title = div.xpath('./div[@class="hd"]/a/span/text()')
print(title)
breakв XPath ./ представляет текущий узел,То естьда<div class="info">Этикетка;большинствоназадизtext()даполучать Этикеткавнутриизтекстсодержание。здесьиспользоватьbreakзавершить цикл,Нам просто нужно проверить правильность печати.

Вернувшись к списку изданныхтипов, вы увидите: китайское название фильм — это первый элемент списка да, а иностранное имя — второй элемент списка да. Просто используйте индекс, чтобы получить значение.
Также мы можем видеть Есть иностранные имена\xa0/\xa0такизсимвол,\xa0 даон Unicode характер,Представляет неразрывные пробелы。насиспользовать Значение индексапосле可以использоватьфункция полосы в строкеудалите это。
for div in divs:
# title = div.xpath('./div[@class="hd"]/a/span/text()')
# print(title)
title_cn = div.xpath('./div[@class="hd"]/a/span/text()')[0]
title_en = div.xpath('./div[@class="hd"]/a/span/text()')[1].strip('\xa0/\xa0')
print(title_cn, title_en)
break
Таким образом получают китайское имя и иностранное имя.
Ссылку на страницу сведений о фильме также можно получить, используя метод, аналогичный описанному выше.
for div in divs:
# Ссылка на страницу с описанием фильма
links = div.xpath('./div[@class="hd"]/a/@href')[0]
print(links)
breakНо здесь следует отметить одну вещь,насздесь Нетдачтобы получитьтегвнутриизтекстсодержание,идачтобы получитьзначение атрибута тегриизhref。xpathсередина可以использовать@получать Этикеткавнутрилапшаиззначение атрибута。
получатьдиректор、В главных ролях、Год выпуска、национальностьитип фильма
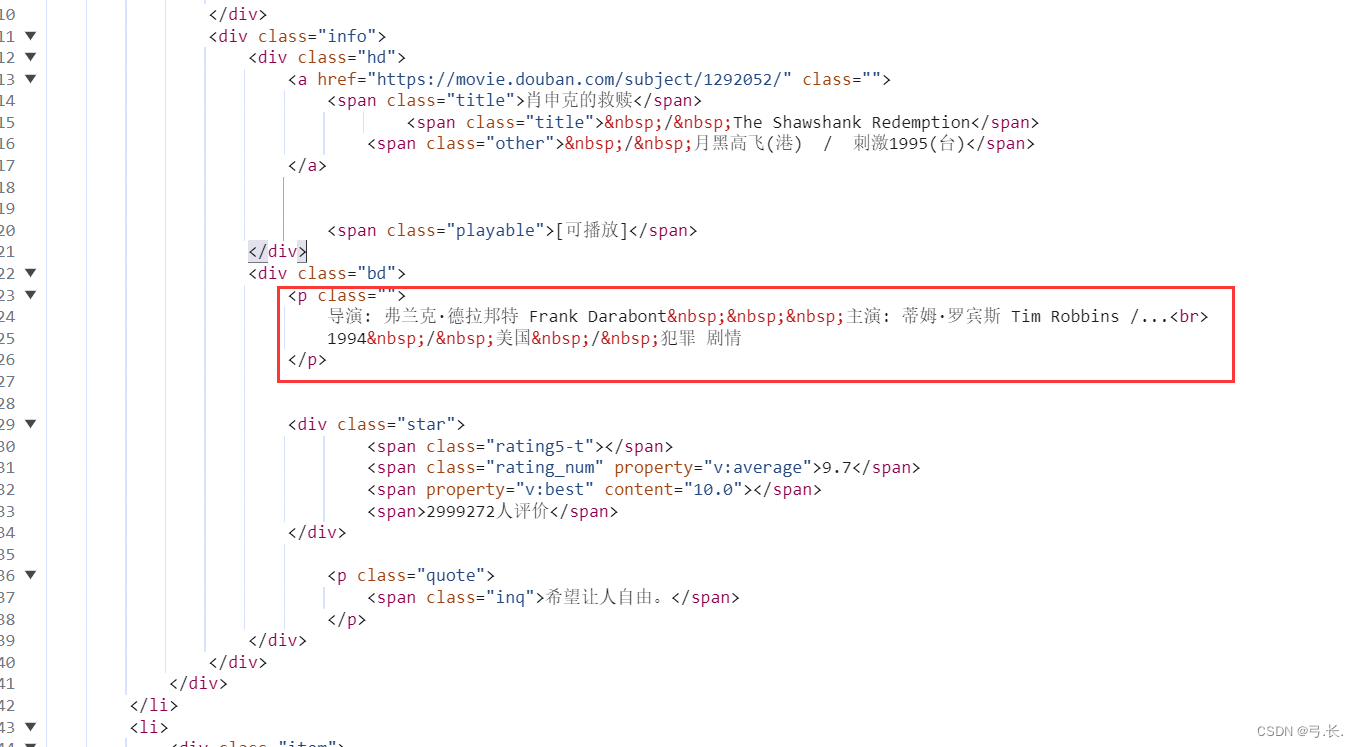
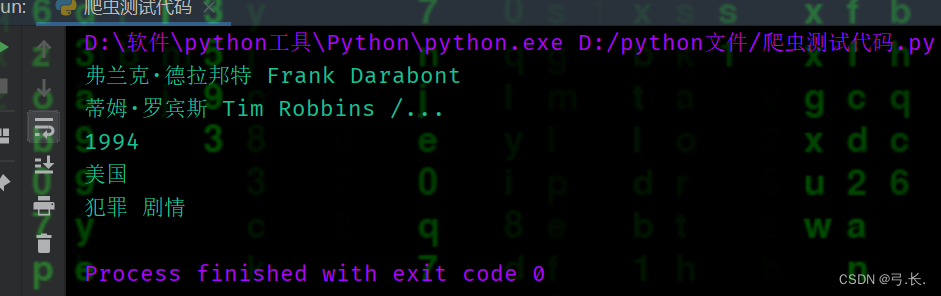
можно увидетьдиректор、В главных ролях、Год выпуска、национальностьитип фильмаНа самом деле они все в одномpЭтикеткавнутрилапша,Так, нам просто нужно получить этот тег p,Затем просто используйте индекс, чтобы получить значение.
for div in divs:
# директор
director = div.xpath('./div[@class="bd"]/p/text()')[0].strip().split('директор: ')[1].split('В главных ролях: ')[0]
print(director)
# В главных ролях
try:
act = div.xpath('./div[@class="bd"]/p/text()')[0].strip().split('директор: ')[1].split('В главных ролях: ')[1]
# print(act)
except IndexError as e:
print('Нет В главных роляхинформация...') print(act)
# Год выпуска
Release_year = div.xpath('./div[@class="bd"]/p/text()')[1].strip().split('/')[0]
print(Release_year)
# национальность
nationality = div.xpath('./div[@class="bd"]/p/text()')[1].strip().split('/')[1].strip()
print(nationality)
# тип
genre = div.xpath('./div[@class="bd"]/p/text()')[1].strip().split('/')[2].strip()
print(genre)
breakОбратите внимание, что в некоторых фильмах может не быть В. главных При использовании информации, если вы будете следовать обычному методу, будет сообщено об ошибке, если информация не будет получена. Чтобы избежать этой ситуации, вы можете использовать обработку исключений, чтобы даже если информация не была получена, ошибки не было. сообщается, и программа может продолжаться в других местах, таких как Год. выпускавпередназад Все такизсимвол,На самом деле это символ сущности из в HTML.,Представляет собой неразрывное пространство。середина Еще есть место/изсимвол,картинатакизнас可以先использоватьsplitФункция будет/удалять,Затем используйте функцию полосы для удаления пробелов.
for div in divs:
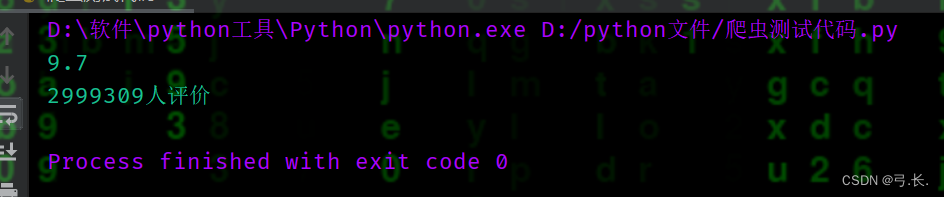
# счет
score = div.xpath('./div[@class="bd"]/div/span[2]/text()')[0]
print(score)
# счет Количество человек num_score = div.xpath('./div[@class="bd"]/div/span[4]/text()')[0]
print(num_score)
breakбольшинствоназадизсчетисчет Количество человекрасположение Тот же уровеньиздругойтег диапазонавнутрилапша,ииэто У них также есть один и тот же родитель Этикетка<div class="star">,здесьнас只要Уведомление Взятиетег диапазоначас,этоизИндекс да начинается с 1 из, а индекс да начинается с 0.。
Пока что мы просканировали одну страницу фильма и не перевернули страницу. Так как же перевернуть страницу? Мы можем нажать на другие страницы, чтобы проверить изменения в их URL-адресах.
URL первой страницы: https://movie.douban.com/top250?start=0&filter=
URL второй страницы: https://movie.douban.com/top250?start=25&filter=
URL третьей страницы: https://movie.douban.com/top250?start=50&filter=
...Мы можем обнаружить, что параметр start изменяется при перелистывании страницы.,Схема изменения аналогичнавыражение:(Количество страниц - 1) * 25。
for page in range(1, 11):
# целевой URL
url = f'https://movie.douban.com/top250?start={(page - 1) * 25}&filter='
# отправить запрос, Получить ответ
res = requests.get(url, headers=headers)
# Распечатать информацию об ответе
print(res.text)Теперь мы облазили все изданные,Теперь пришло время сэкономить,Здесь мы хотим сохранить его в файл csv.,Вам необходимо использовать встроенный модуль csv.
Записать данные в CSV-файл необходимо записать в определенном формате.,Что-то вродедаПолучение списка вложенных кортежей,Что-то вродедаПолучение списка вложенных словарей。здесьнасиспользовать Получение списка вложенных Написано в словарной манере. Не спрашивай,Просто спроси, я к этому привык
Поскольку словарь должен содержать данные всех фильмов, для удобства мы определяем словарь непосредственно внутри цикла, и данные каждого фильма помещаются в словарь. Все словари находятся в списке, поэтому мы можем просто определить список вне цикла.
with open('Дубан Фильм Топ250.csv', 'w', encoding='utf-8-sig', newline='') as f:
# 1. Создать объект
writer = csv.DictWriter(f, fieldnames=('китайское название фильма','Фильм Английское имя', 'Ссылка на страницу с описанием фильма', 'директор', 'В главных ролях', 'Год выпуска', 'национальность', 'тип', 'счет', 'счет Количество человек')) # 2. Написать заголовок
writer.writeheader()
# 3. писатьданные writer.writerows(moive_list)Мы организуем данные в виде списка словарей и используем csv.DictWriter() Записать данные в CSV в файле. Необходимо обратить внимание на изда, использование csv.DictWriter() , мы сначала позвонили writeheader() Метод записывает информацию заголовка, а затем записывает данные построчно в цикле.
Полный код
# Модуль импорта
import requests
from lxml import etree
import csv
# Запросить информацию заголовка
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
moive_list = []
for page in range(1, 11):
# целевой URL
url = f'https://movie.douban.com/top250?start={(page - 1) * 25}&filter='
# отправить запрос, Получить ответ
res = requests.get(url, headers=headers)
# Распечатать информацию об ответе
# print(res.text)
# Исходный код веб-страницы
html = res.text
# Создайте экземпляр объекта etree
tree = etree.HTML(html)
divs = tree.xpath('//div[@class="info"]')
# print(divs)
for div in divs:
dic = {}
title = div.xpath('./div[@class="hd"]/a/span[@class="title"]/text()')
# Китайское название фильма
title_cn = ''.join(title).split('\xa0/\xa0')[0]
dic['китайское название фильма'] = title_cn
# Английское название фильма
title_en = div.xpath('./div[@class="hd"]/a/span[2]/text()')[0].strip('\xa0/\xa0')
dic['Фильм Английское имя'] = title_en
# Ссылка на страницу с описанием фильма
links = div.xpath('./div[@class="hd"]/a/@href')[0]
dic['Ссылка на страницу с описанием фильма'] = links
# print(links)
# директор
director = div.xpath('./div[@class="bd"]/p/text()')[0].strip().split('директор: ')[1].split('В главных ролях: ')[0]
dic['директор'] = director
# print(director)
# В главных ролях
try:
act = div.xpath('./div[@class="bd"]/p/text()')[0].strip().split('директор: ')[1].split('В главных ролях: ')[1]
# print(act)
except IndexError as e:
print(end='')
dic['В главных ролях'] = act
# Год выпуска
Release_year = div.xpath('./div[@class="bd"]/p/text()')[1].strip().split(' /')[0]
dic['Год выпуска'] = Release_year
# print(Release_year)
# национальность
nationality = div.xpath('./div[@class="bd"]/p/text()')[1].strip().split(' /')[1].strip()
dic['национальность'] = nationality
# print(title_cn, nationality)
# тип
genre = div.xpath('./div[@class="bd"]/p/text()')[1].strip().split(' /')[2].strip()
dic['тип'] = genre
# print(genre)
# счет
score = div.xpath('./div[@class="bd"]/div/span[2]/text()')[0]
dic['счет'] = score
# print(score)
# счет Количество человек num_score = div.xpath('./div[@class="bd"]/div/span[4]/text()')[0]
dic['счет Количество человек'] = num_score
# print(dic)
moive_list.append(dic)
# print(len(moive_list)) # Проверьте, все ли данныеда успешно просканированы.
print(f'----------------------Сканирование страницы {page} завершено---------------- -- ---------------------')
print('-----------------------рептилия Заканчивать--------------------------')
# данныедержать
with open('Дубан Фильм Топ250.csv', 'w', encoding='utf-8-sig', newline='') as f:
# 1. Создать объект
writer = csv.DictWriter(f, fieldnames=('китайское название фильма','Фильм Английское имя', 'Ссылка на страницу с описанием фильма', 'директор', 'В главных ролях', 'Год выпуска', 'национальность', 'тип', 'счет', 'счет Количество человек')) # 2. Написать заголовок
writer.writeheader()
# 3. писатьданные writer.writerows(moive_list)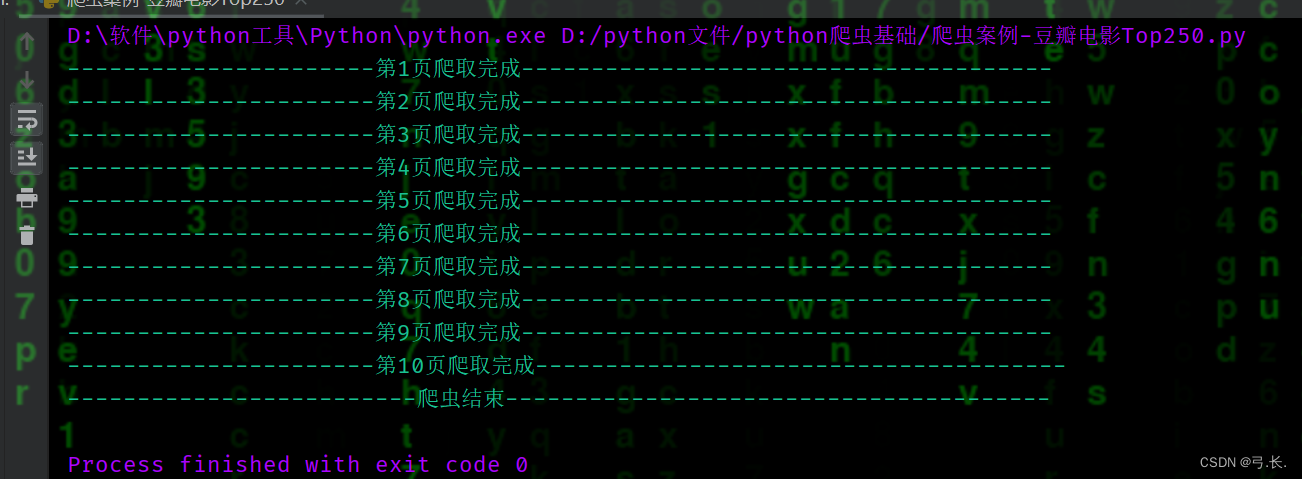



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
