Познакомьтесь с тремя механизмами внимания архитектуры Transformer в одной статье.
Предисловие
О механизме внимания слышали все. В конце концов, в области обработки естественного языка (NLP) и больших языковых моделей (LLM) статья «Внимание — это все, что вам нужно» в 2017 году стала знаковой; Что касается механизма внимания, и даже новейшие мультимодальные или основанные на видении модели сегодня в некоторой степени используют его, мы углубимся в механизм внимания;
1. Что такое внимание?
Когда зрительный механизм человека обнаруживает объект, он обычно не сканирует всю сцену от начала до конца, а обычно фокусируется на определенных частях в зависимости от индивидуальных потребностей;
Например, на картинке ниже мы должны увидеть животное с первого взгляда, и тогда наши глаза сначала заметят морду животного, а затем сделают предварительный вывод, что это должен быть волк, как показано на диаграмме внимания справа; , Обычно мы, люди, видим (внимание) в первую очередь более темные цвета.

Внимание сначала было применено в области машинного зрения (CV, Computer Vision), а затем было применено к областям НЛП и LLM.
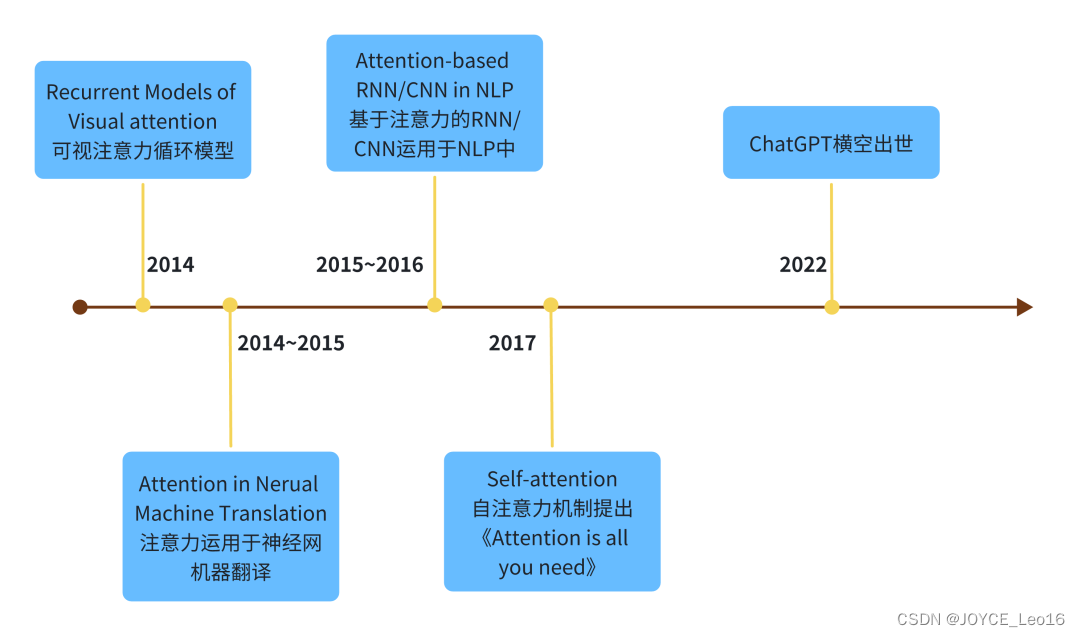
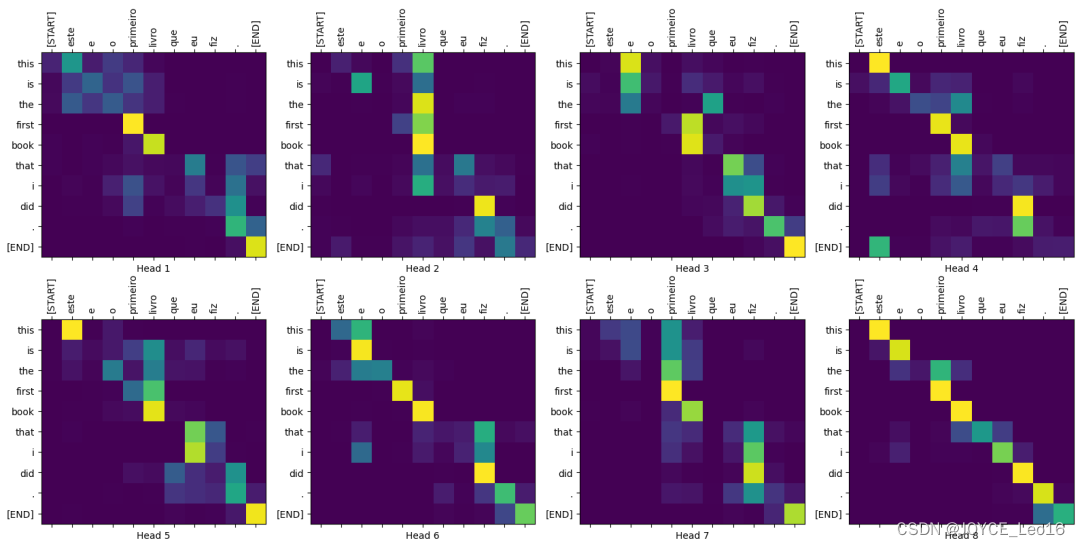
Многоголовая (2-головная) визуализация внимания к себе:
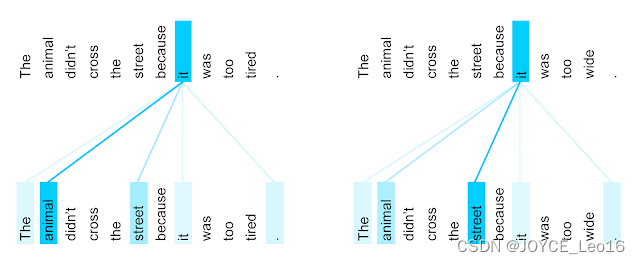
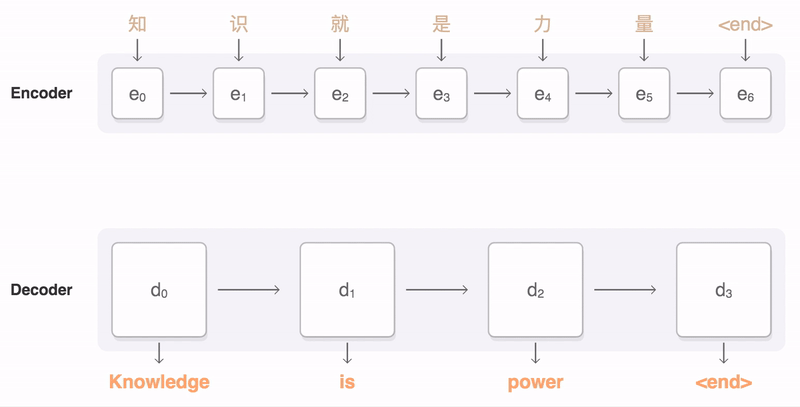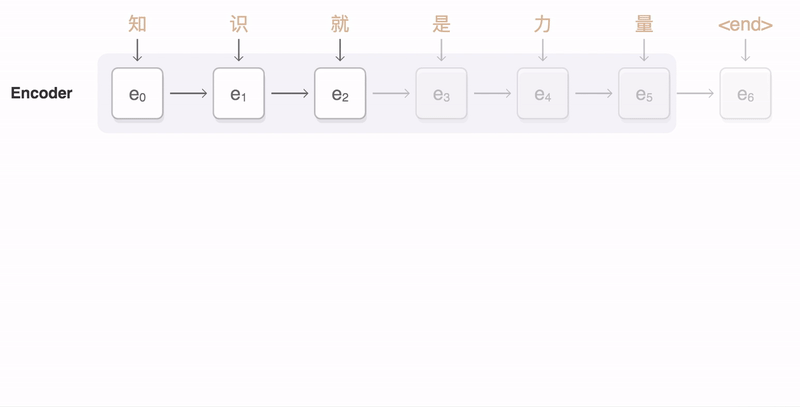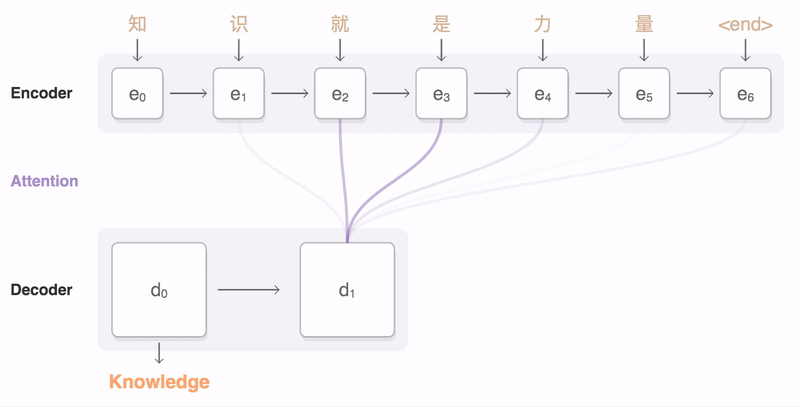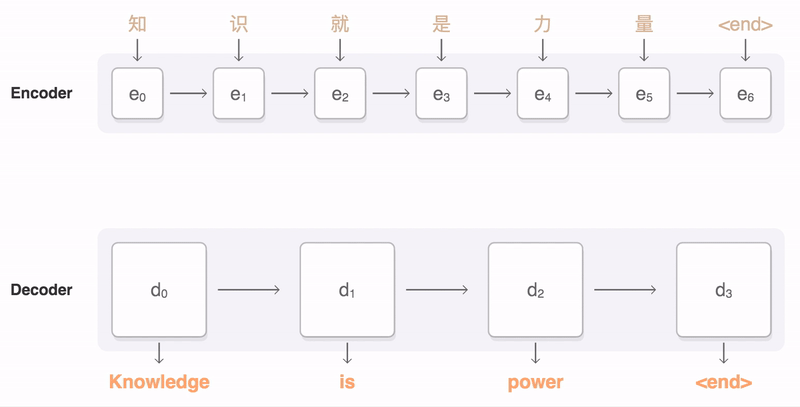
Как показано на анимации ниже, в Transformer уделяется внимание машинному переводу:
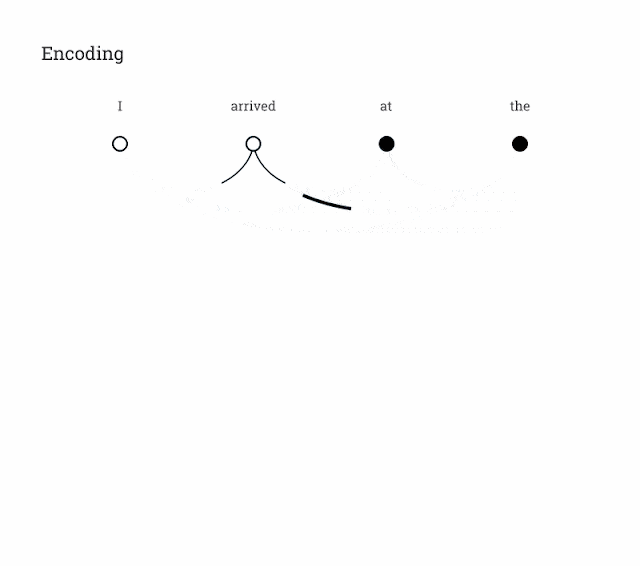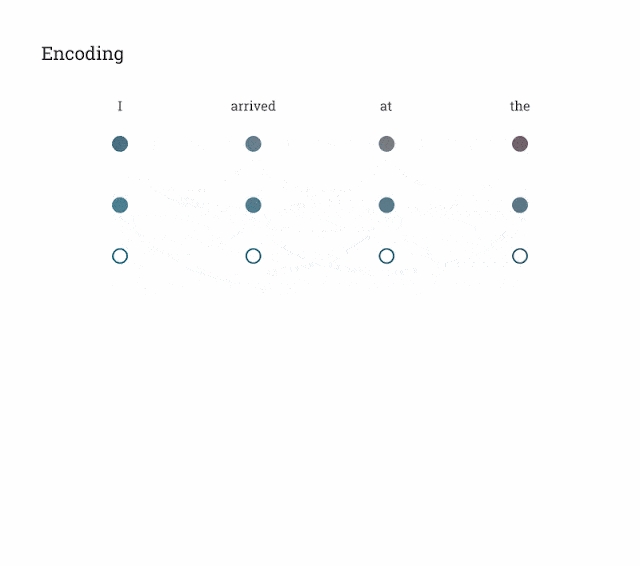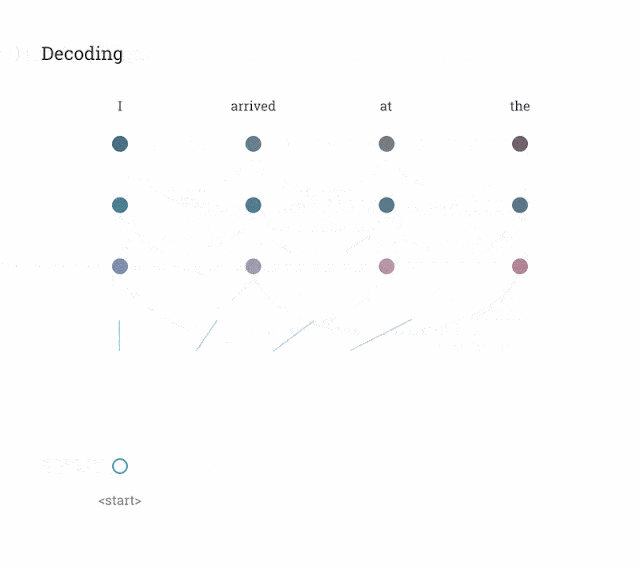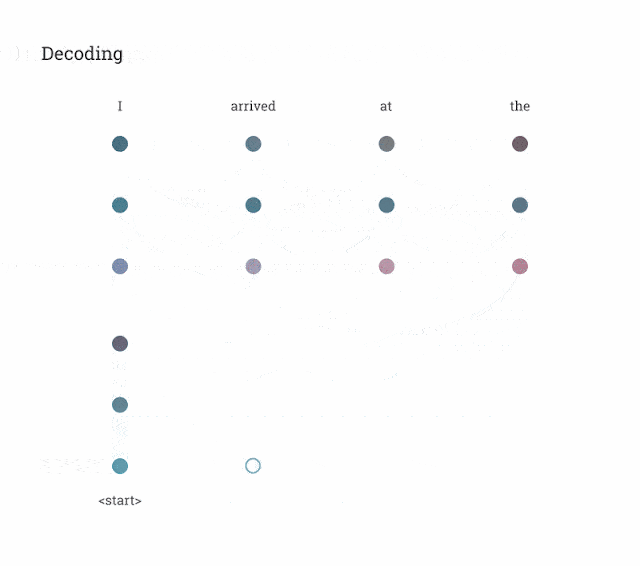
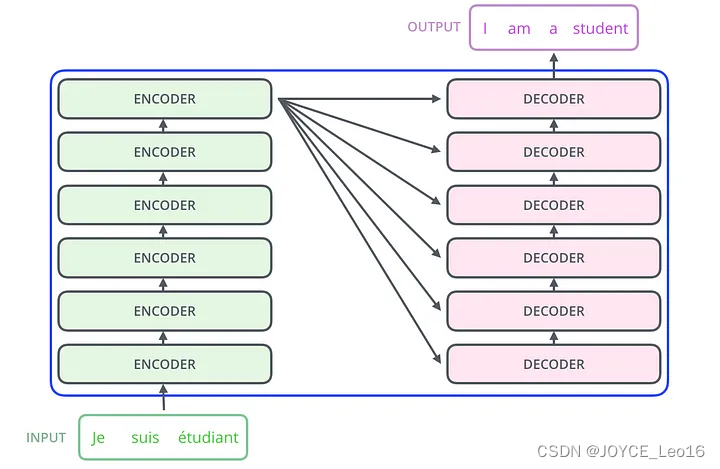
2. Уровень внимания трансформера
существоватьTransformerАрхитектурасередина,Есть два основных компонента,Они естьКодер и декодер,кодирование Устройство предназначено главным образом длявходная последовательностьСопоставить с латентнымсуществоватьсмысловое пространство(Векторы внимания также называются векторами контекста, но на самом деле векторы контекста — это внутреннее название входных векторов в механизме внимания. В этой статье выходные векторы кодера называются векторами внимания только для их различения.),Декодер преобразует скрытоесуществоватьсмысловое пространство(вектор внимания)сопоставлено свыходная последовательность。
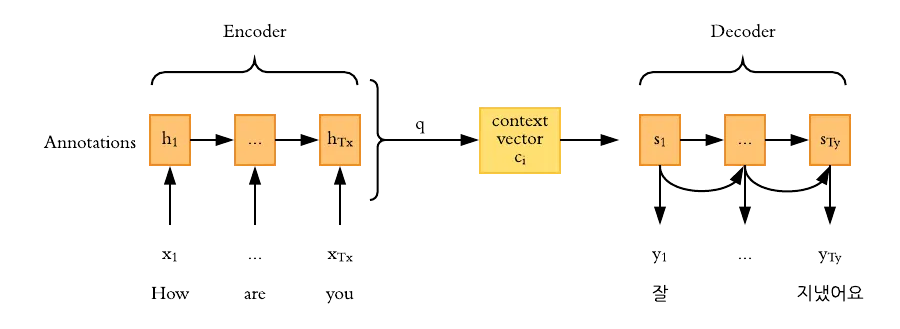
В архитектуре Transformer есть три разных уровня внимания:
- слой в декодере перекрестного внимания(Cross attention layer)
- кодированиеустройствосерединаизглобальный уровень самообслуживания(Global self attention layer)
- Уровень случайного внимания в декодере
Как показано ниже:
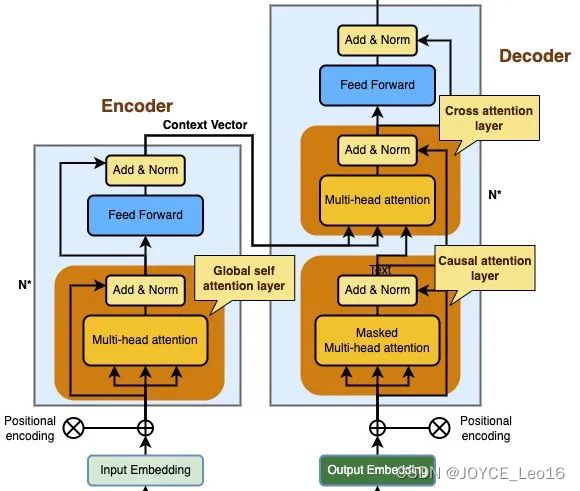
Основы механизма внимания
Математическое представление механизма внимания следующее:
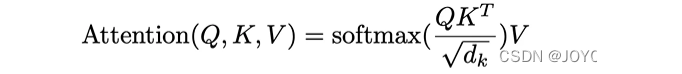
В выражении Q, K и V относятся к матрицам запроса (Query), ключа (Key) и значения (Value) соответственно. В этих трех матрицах каждая строка соответствует сегментации слова во входном тексте, а каждый столбец — сегментации слова во входном тексте. Соответствует определенному признаку или размеру этого причастия;
Проще говоря,Данные в матрице запроса представляют собой наше слово, на котором сосредоточено внимание.,в ключевой матрицеданные Используется, чтобы помочь нам вычислить сходство между этими словами.(То есть оценка внимания: оценка внимания, векторное скалярное произведение может вычислить сходство.),Данные в матрице значений используются для расчета конечного выходного результата на основе этих сходств;
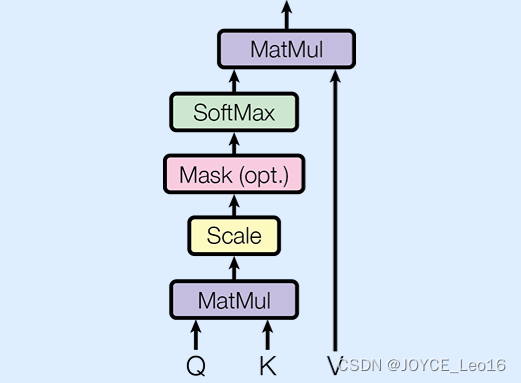
Чтобы гарантировать, что данные во время расчета не взрываются из-за слишком больших размеров (т. е. размера ключей).,Или слишком маленький и исчезнуть,Затем оценка внимания масштабируется по квадратному корню из размера ключа;,Преобразуйте эти оценки в веса с помощью функции softmax.,Наконец, эти веса умножаются на матрицу значений,получить окончательный результат(вектор внимания)。
Когда оценка внимания визуализируется в виде тепловой карты, она может четко показать, какие слова в последовательности более важны для прогнозирования каждого выходного слова. (На рисунке ниже представлен пример машинного перевода. Вертикальная ось — это оригинальный английский текст, а горизонтальная ось — соответствующий перевод на португальский язык).
Ниже приводится расчетмеханизм самообслуживаниявыходвектор процесс внимания. (исключая Scale и SoftMax).

Понять Q, K, V
В механизме внимания есть два входа:
- Последовательность запроса (Q):толькосуществовать Обработанная последовательность(существоватьнижний)。
- Контекстная последовательность (K, V):одеялососредоточиться напорядок рангов(существоватьлевая сторона)。
Размеры выходной последовательности такие же, как и у последовательности запроса.
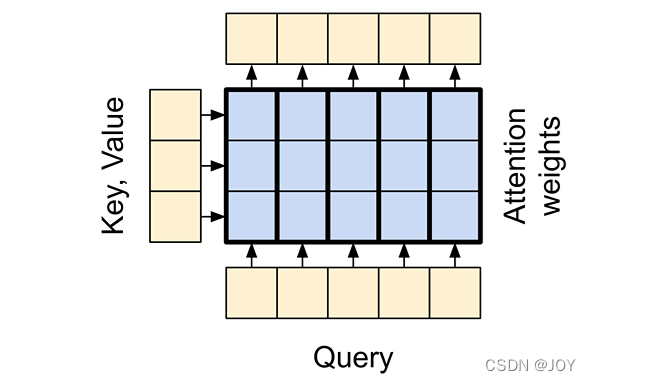
Эту операцию часто сравнивают с поиском по словарю, но это нечеткий, дифференцируемый, векторизованный поиск по словарю.
Например, предположим, что у вас есть обычный словарь Python с 3 ключами и 3 значениями, которому передается один запрос:
d = {'color': 'blue', 'age': 22, 'type': 'pickup'}
result = d['color']здесь,Запрос (Q) — это то, что вы ищете,Ключ (К) указывает, какая информация находится в словаре.,Значение (V) представляет собой соответствующую информацию, существующую при обычном поиске по словарю;,Словарь найдет совпадающие ключи,и возвращает соответствующее значение, если запрос не может найти точно соответствующий ключ;,может быть, ты будешьОжидает вернуть ближайшее значение,Например, в приведенном выше примере существуют,Если вы ищете "d["виды"]",Вы можете ожидать, что «самовывоз» будет возвращен.,Потому что это наиболее близкое соответствие запросу.
Минимальный уровень внимания похож на такой нечеткий поиск, но он не просто находит лучший ключ; он объединяет векторы запроса (Q) и ключа (K), чтобы определить, насколько хорошо они совпадают, то есть «показатель внимания». Затем на основе «оценки внимания» выполняется средневзвешенное значение всех значений; на уровне внимания последовательность запроса (Q) для каждой позиции предоставляет вектор запроса, а последовательность контекста действует как словарь, предоставляя вектор запроса для каждой позиции. Векторы ключей и значений перед использованием этих векторов слой внимания проецирует входные векторы с помощью полносвязного слоя;
слой перекрестного внимания
существовать Transformer середина,Угол перекрестного внимания находится буквально в центре; он соединяет преобразователь кодирования и декодер.,Это самый прямой способ использовать внимание в Модели существования.
чтобы добиться этого,нужноцелевая последовательностькак запрос,ВоляПорядок верхнего и нижнего предложениякак ключ/Передавать по значению。
- Q = причинный в декодере слой Выходной вектор внимания
- K = кодированиеустройствовыходизвектор внимания
- V = кодированиеустройствовыходизвектор внимания
Как показано ниже, каждый столбец представляет собой взвешенную сумму контекстной последовательности.
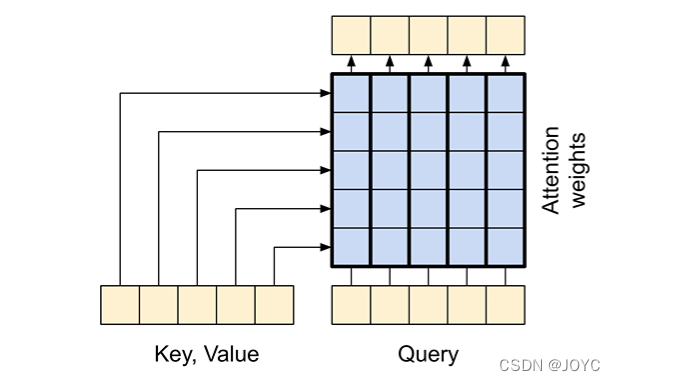
(Остаточные соединения для простоты не показаны)
глобальный уровень самообслуживания
Глобальное самообслуживание является частью кодера Transformer, который отвечает за обработку всей входной последовательности.
Это позволяет каждому элементу последовательности иметь прямой доступ ко всем другим элементам последовательности, просто рассматривая всю последовательность как Q, K, V, и все выходные данные могут рассчитываться параллельно.
- Q = вектор слова текущей позиции во входной последовательности.
- K = входная Все векторы слов позиции в последовательности
- V = входная Все векторы слов позиции в последовательности
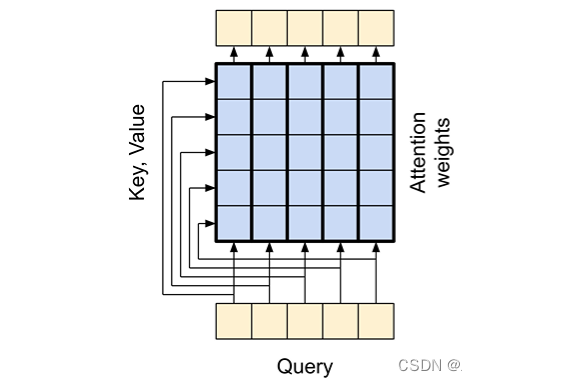
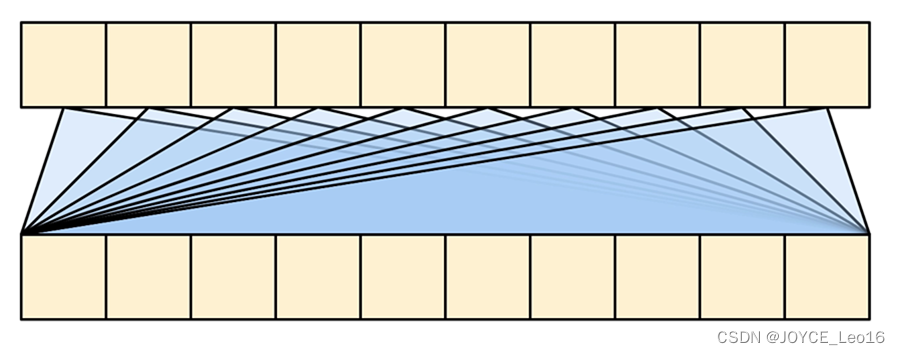
причинный слой внимания
причинный слой внимания对解码устройствосерединавыходная последовательность Исполнение аналогичноглобальный уровень самообслуживанияработа;Но скодированиеинструментаглобальный уровень самообслуживания Есть разные способы справиться с этим。
Трансформатор — это «авторегрессионная» модель, которая генерирует текстовый токен за токеном и передает выходные данные обратно на входные данные; чтобы сделать этот процесс эффективным, эти модели гарантируют, что выходные данные каждого элемента последовательности зависят только от предыдущего элемента последовательности; причинно-следственная».
Построить причинно-следственный слой внимания к себе,существования Необходимо использовать соответствующие маски при подсчете показателей внимания и суммировании значений внимания.,Потому что выходная последовательность также является одноразовым вводом.,Но когда существование вычисляет предыдущее причастие, оно не хочет, чтобы последующие причастия также участвовали в вычислении.
- Q = выходная Вектор слова текущей позиции в последовательности
- K = выходная Все векторы слов позиции в последовательности
- V = выходная Все векторы слов позиции в последовательности
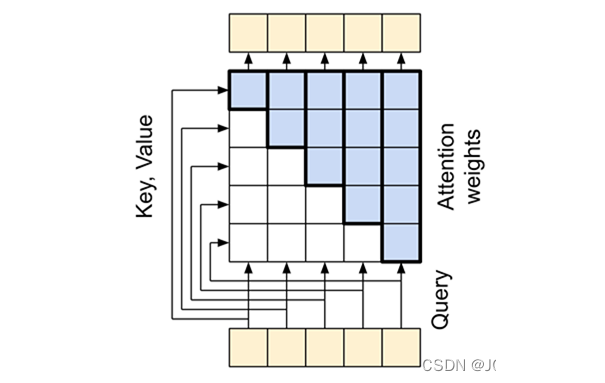
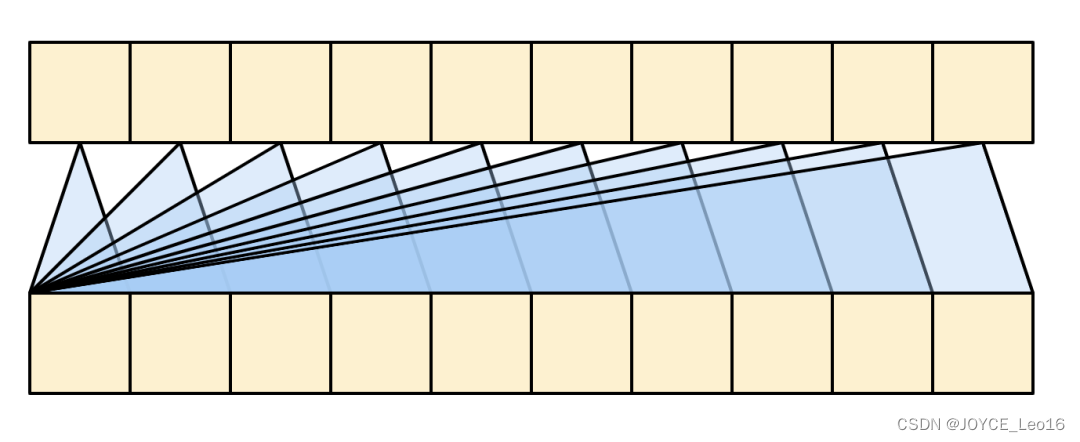
3. Кодирование позиции
В отличие от RNN, LSTM и т. д., которые получают сегменты входного слова один за другим по порядку, а вычисление, естественно, содержит информацию о позиции, Transformer обрабатывает все сегменты входного слова одновременно. Хотя это делает Transformer быстрее, он теряет информацию, связанную с порядком. сегментов слов; однако позиция Информация имеет решающее значение для большей части обработки информации. Например, «Я люблю тебя» и «Ты любишь меня» имеют совершенно разную семантику, чтобы решить эту проблему, к кодировке позиции необходимо добавить; входная последовательность для создания окончательного вектора внимания. Он содержит информацию о местоположении.

Кодирование местоположения также может быть достигнуто разными способами.,Включает использование выученных причастий (употребляется в существованииBert),Синусоидальная функция или относительное положение. Мы сосредоточимся на кодировании синусоидального позиционирования;,Этот подход также принят в оригинальной статье Васвани и др.
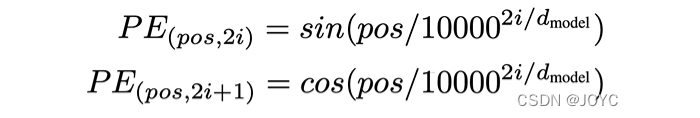
Синусоидальное кодирование позиции — это функция, которая отображает положение токена в вектор размера d, где d — размерность входного и выходного векторов.
ЧтосерединаposвыражатьtokenМестосуществоватьрасположение,и i Представляет размерность вектора; синусоидальное кодирование позиции использует разные частоты для каждого измерения, создавая тем самым уникальный и регулярный шаблон для каждой позиции. По сравнению с изученными внедрениями синусоидальное кодирование позиции имеет несколько очевидных преимуществ: оно фиксировано, может обобщаться на невидимые данные; и легко расширяется.
Позиционное кодирование должно иметь те же размеры, что и входная последовательность, чтобы можно было добавить два вектора (по сути, вводя позиционную информацию во входное представление внедрения).
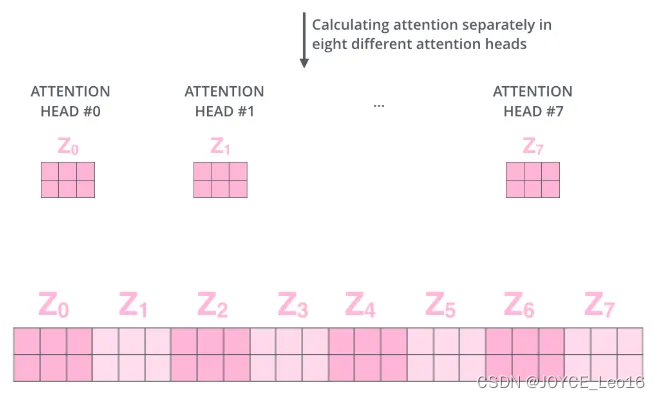
4. Многоголовочный механизм внимания.
Многоголовый механизм внимания существует Основы. механизма Инновация в области внимания позволяет модели одновременно концентрироваться. на Введите ивыходная несколько различных характеристик или размеров последовательности Проще; говоря,Это делается путем помещения запроса (Q),Ключ (К),Три матрицы значений (V) разделены на несколько небольших блоков.,Каждый блок называется «головой»; каждая «голова» выполняет операции самообслуживания независимо.,Затем соедините результаты всех «головок» вместе.,выполнить другое конкретное преобразование,Получите окончательный результат.

Математическое представление выглядит следующим образом:
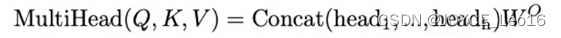
По сравнению с традиционным самообслуживанием с одной головой,Насколько велико внимание быков?преимущество:например,Он может определять различные отношения между причастиями.,Будь то отношение субъект-сказуемое, глагол-дополнение или существительное-форма одновременно;,Многонаправленное внимание также может улучшить способности и производительность Модели.,Поскольку Модель может одновременно учиться на нескольких представлениях последовательности;,Многоголовое внимание также может сделать операции Модельсуществовать более эффективными и простыми в параллельной обработке.,Потому что это уменьшает размер каждой головки,Это позволяет одновременно обрабатывать несколько головок.
Кроме того, Transformer также может накладывать несколько слоев для дальнейшего расширения возможностей и выразительности модели.
5. Резюме
Мы представили в Transformer три различных уровня внимания, а также методы реализации внимания, кодирование позиции и механизм внимания с несколькими головами, охватывающий большую часть знаний, связанных с вниманием. Мы надеемся, что друзья смогут лучше понять это. .
Трансформатор использует механизм внимания, чтобы делать более точные прогнозы,Успех от ChatGPT,было проверено, хотя рекуррентная нейронная сеть RNN также пытается достичь аналогичных функций;,Но поскольку они ограничены кратковременной памятью,Поэтому при работе с длинными последовательностями существуют,Особенно при существовании кодирования или при генерации длинных последовательностей.,Transformer стал еще лучше благодаря Transformer Architecture;,Индустрия обработки естественного языка (НЛП) достигла беспрецедентных результатов.
Ссылка: AlwithGary


RasaGpt — платформа чат-ботов на основе Rasa и LLM.

Nomic Embed: воспроизводимая модель внедрения SOTA с открытым исходным кодом.

Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Малые цели имеют очевидные преимущества | ICASSP2023

Урок 1 серии Libtorch: Тензорная библиотека Silky C++

Руководство по локальному развертыванию Stable Diffusion: подробные шаги и анализ распространенных проблем

Полностью автоматический инструмент для работы с видео в один клик: VideoLingo

Улучшения оптимизации RT-DETR: облегченные улучшения магистрали | Support Paddle облегченный rtdetr-r18, rtdetr-r34, rtdetr-r50, rtdet

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | Деформируемое внимание с большим ядром (D-LKA Attention), большое ядро свертки улучшает механизм внимания восприимчивых полей с различными функциями

Создано Datawhale: выпущено «Руководство по тонкой настройке развертывания большой модели GLM-4»!

7B превышает десятки миллиардов, aiXcoder-7B с открытым исходным кодом Пекинского университета — это самая мощная модель большого кода, лучший выбор для корпоративного развертывания.

Используйте модель Huggingface, чтобы заменить интерфейс внедрения OpenAI в китайской среде.

Оригинальные улучшения YOLOv8: несколько новых улучшений | Сохранение исходной информации — алгоритм отделяемой по глубине свертки (MDSConv) |

Второй пилот облачной разработки | Быстро поиграйте со средствами разработки на базе искусственного интеллекта

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция с нулевым кодированием и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

Решенная Ошибка | Загрузка PyTorch медленная: TimeoutError: [Errno 110] При загрузке факела истекло время ожидания — Cat Head Tiger

Brother OCR, библиотека с открытым исходным кодом для Python, которая распознает коды проверки.
Новейшее подробное руководство по загрузке и использованию последней демонстрационной версии набора данных COCO.

Выпущен отчет о крупной модели финансовой отрасли за 2023 год | Полный текст включен в загрузку |

Обычные компьютеры также могут работать с большими моделями, и вы можете получить личного помощника с искусственным интеллектом за три шага | Руководство для начинающих по локальному развертыванию LLaMA-3

Одной статьи достаточно для анализа фактора транскрипции SCENIC на Python (4)

Бросая вызов ограничениям производительности небольших видеокарт, он научит вас запускать большие модели глубокого обучения с ограниченными ресурсами, а также предоставит полное руководство по оценке и эффективному использованию памяти графического процессора!

Команда Fudan NLP опубликовала 80-страничный обзор крупномасштабных модельных агентов, в котором в одной статье представлен обзор текущего состояния и будущего агентов ИИ.

[Эксклюзив] Вы должны знать о новой функции JetBrains 2024.1 «Полнострочное завершение кода», чтобы решить вашу путаницу!

Краткое изложение базовых знаний о регистрации изображений 1.0

Новейшее подробное руководство по установке и использованию библиотеки cv2 (OpenCV, opencv-python) в Python.

Легко создайте локальную базу знаний для крупных моделей на основе Ollama+AnythingLLM.

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание решения. Повторная попытка с помощью файла (графическое руководство).

Одна статья поможет вам понять RAG (Retrival Enhanced Generation) | Введение в концепцию и теорию + практику работы с кодом (включая исходный код).

Эволюция архитектуры шлюза облачной разработки
