Познакомьтесь с моделью нейронной сети Transformer в одной статье
С момента выпуска последних моделей больших языков (LLaM), таких как серия GPT OpenAI, модель с открытым исходным кодом Bloom и LaMDA от Google, модель Transformer продемонстрировала свой большой потенциал и стала передовой архитектурной моделью в области глубокого анализа. обучение.

— 01 —
Что такое модель трансформера?
За последние несколько лет модели Transformer стали горячей темой в области передового глубокого обучения и глубоких нейронных сетей. С момента своего появления в 2017 году архитектура модели глубокого обучения Transformer широко использовалась и развивалась практически во всех возможных областях. Эта модель не только хорошо работает в задачах обработки естественного языка, но также имеет большую помощь и потенциал для других областей, особенно для прогнозирования временных рядов.
Итак, что же такое нейросетевая модель Transformer?
Модель Transformer — это архитектура глубокого обучения, которая произвела революцию в области обработки естественного языка (NLP) с момента своего появления в 2017 году. Эта модель была предложена Васвани и др. и стала одной из самых влиятельных моделей в сообществе НЛП.
Вообще говоря, традиционные последовательные модели, такие как рекуррентные нейронные сети (RNN), имеют ограничения в улавливании долгосрочных зависимостей и обеспечении параллельных вычислений. Чтобы решить эти проблемы, модель Transformer вводит механизм самообслуживания. Широко используя этот механизм, модель может взвешивать важность различных позиций во входной последовательности при генерации выходных данных.
Благодаря преимуществам механизма самообслуживания и параллельных вычислений модель Transformer может лучше обрабатывать зависимости на больших расстояниях и повышать эффективность обучения и вывода модели. Он достиг значительного улучшения производительности в ряде задач НЛП, таких как машинный перевод, обобщение текста и системы ответов на вопросы.
Кроме того, революционные характеристики модели трансформатора делают ее важной частью современных исследований и приложений НЛП. Его способность улавливать сложные семантические отношения и контекстную информацию во многом способствовала развитию обработки естественного языка.
— 02 —
Историческое развитие модели трансформатора
Историю Трансформеров в нейронных сетях можно проследить до начала 1990-х годов, когда Юрген Шмидхубер предложил концепцию первой модели Трансформера. Эта модель, называемая «быстрым контроллером веса», использует механизм самообслуживания для изучения связей между словами в предложениях. Однако, хотя эта ранняя модель Трансформатора была концептуально продвинутой, она не получила широкого распространения из-за своей низкой эффективности.
Шло время и развивалась технология глубокого обучения, Transformer был официально представлен в основополагающей статье в 2017 году и добился большого успеха. Внедряя механизм самообслуживания и уровень кодирования положения, он эффективно фиксирует зависимости на больших расстояниях во входной последовательности и хорошо работает при обработке длинных последовательностей. Кроме того, возможности параллельных вычислений модели Transformer также ускоряют обучение, способствуя крупным прорывам в глубоком обучении в области обработки естественного языка, таким как модель BERT (двунаправленные представления кодировщиков от трансформаторов) в задачах машинного перевода.
Таким образом, хотя ранний «быстрый контроллер веса» не получил широкого распространения, благодаря статье Васвани и др. модель Трансформатора была переопределена и улучшена, став одной из передовых технологий современного глубокого обучения и широко используемой. в обработке естественного языка и т. д. В этой области были достигнуты замечательные достижения.
Причина успеха Transformer заключается в его способности изучать зависимости между словами в предложении на больших расстояниях, что имеет решающее значение для многих задач обработки естественного языка (NLP), поскольку позволяет модели понимать контекст слова в предложении. Transformer достигает этого за счет использования механизма самообслуживания, который позволяет модели сосредоточиться на наиболее релевантных словах в предложении при декодировании выходных токенов.
Трансформер оказал значительное влияние на область НЛП. Сейчас он широко используется во многих задачах НЛП и постоянно совершенствуется. В будущем Трансформеры, вероятно, будут использоваться для решения более широкого круга задач НЛП, и они станут более эффективными и мощными.
К некоторым ключевым событиям развития в истории нейросети Transformer можно отнести следующие:
1. 1990: Юрген Шмидхубер предложил первую модель Трансформера, «быстрый весовой контроллер».
2. 2017: Васвани и др. опубликовали статью «Внимание — это все, что вам нужно», в которой представлена основная идея модели Трансформера.
3. 2018: Модели-трансформеры достигают самых современных результатов в различных задачах НЛП, включая машинный перевод, обобщение текста и ответы на вопросы.
4. 2019: Transformer используется для создания больших языковых моделей (LLM), таких как BERT и GPT-2, которые позволили добиться важных прорывов в различных задачах НЛП.
5. 2020: Transformer продолжает использоваться для создания более мощных моделей, таких как GPT-3, который достигает потрясающих результатов в генерации и понимании естественного языка.
В целом, внедрение модели Трансформера оказало революционное влияние на область НЛП. Его способность изучать долгосрочные зависимости и понимать контекст делает его предпочтительным методом для решения многочисленных задач НЛП и открывает широкие возможности для будущего развития.
— 03 —
Общий архитектурный проект модели трансформатора
Архитектура Transformer черпает вдохновение из архитектуры кодировщика-декодера RNN (рекуррентной нейронной сети), которая представляет механизм внимания. Он широко используется в задачах последовательной обработки (seq2seq), и по сравнению с RNN, Transformer отказывается от последовательной обработки.
В отличие от RNN, Transformer обрабатывает данные параллельно, обеспечивая более масштабные параллельные вычисления и более быстрое обучение. Это связано с механизмом самообслуживания в архитектуре Transformer, который позволяет модели учитывать все позиции во входной последовательности одновременно без необходимости обрабатывать их шаг за шагом по порядку. Механизм самообслуживания позволяет модели собирать глобальную контекстную информацию путем взвешивания каждой позиции на основе взаимосвязи между различными позициями во входной последовательности.
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture. Base for this and many
other models.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
return self.decode(self.encode(src, src_mask), src_mask,
tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
class Generator(nn.Module):
"Define standard linear + softmax generation step."
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return F.log_softmax(self.proj(x), dim=-1)Об общей архитектуре модели Трансформера можно сказать следующее:
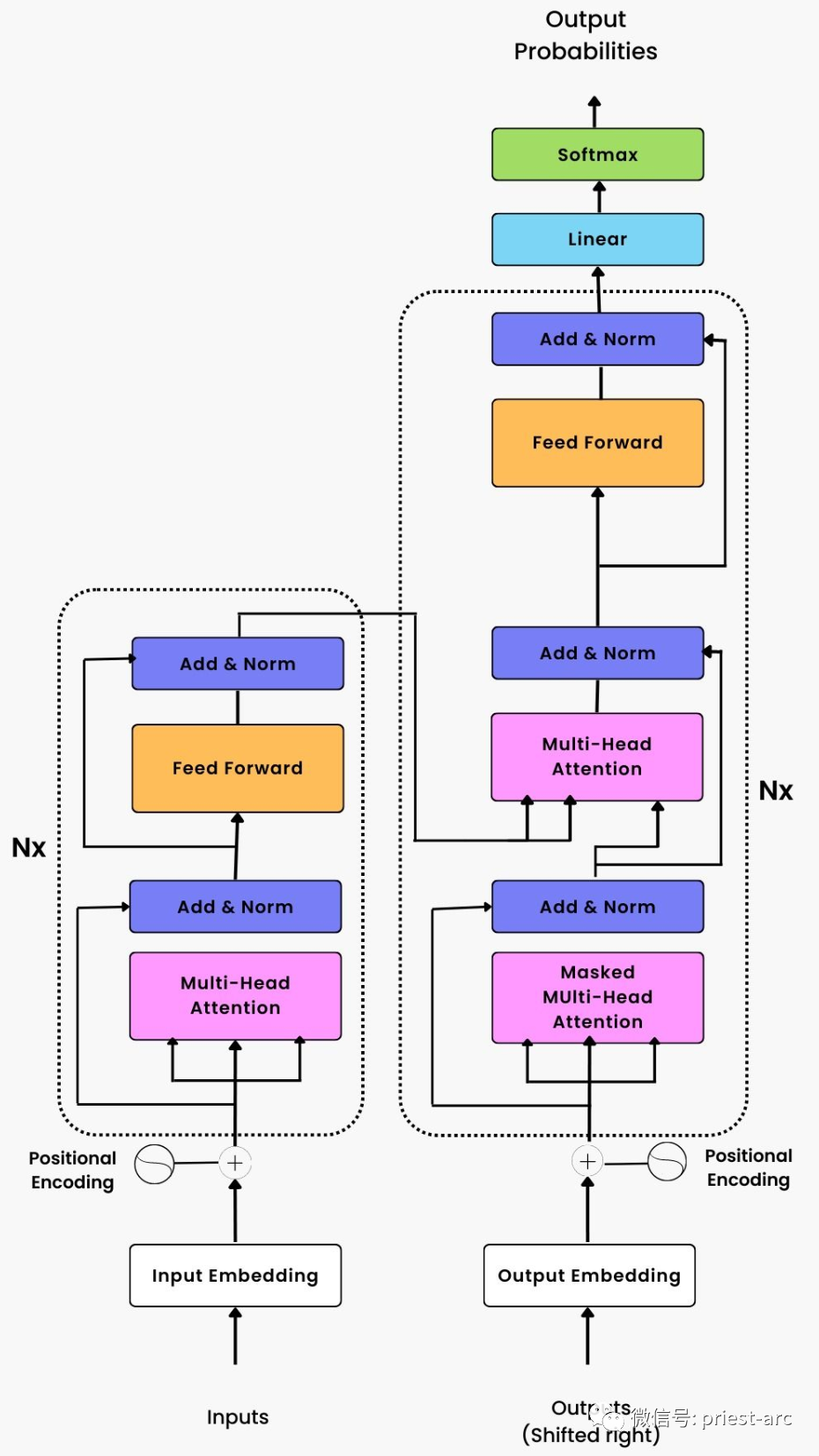
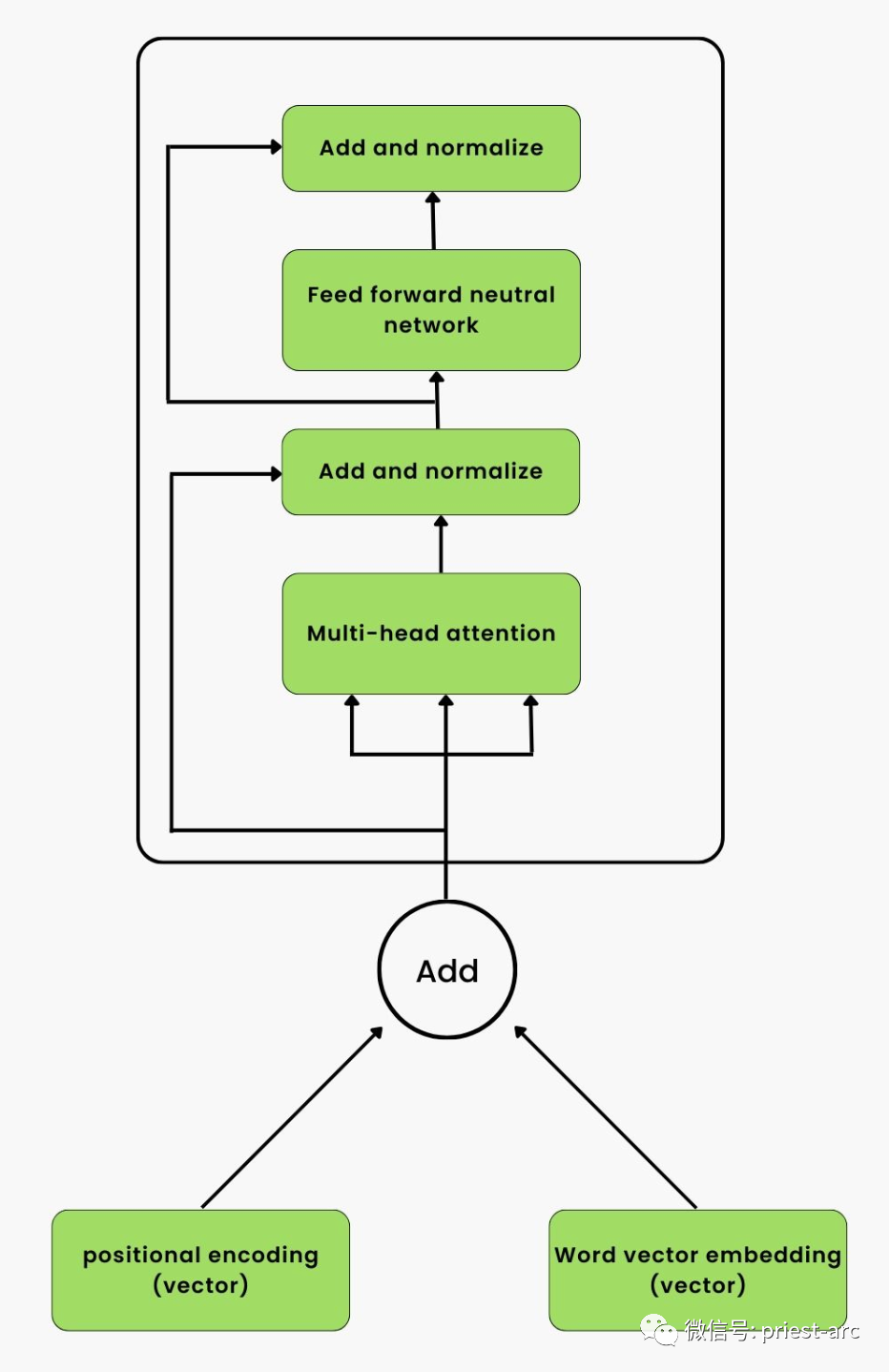
На основе диаграммы общей эталонной модели архитектуры модели глубокого обучения Transformer, приведенной выше, мы видим, что она состоит из двух основных компонентов:
1. Стек кодировщика
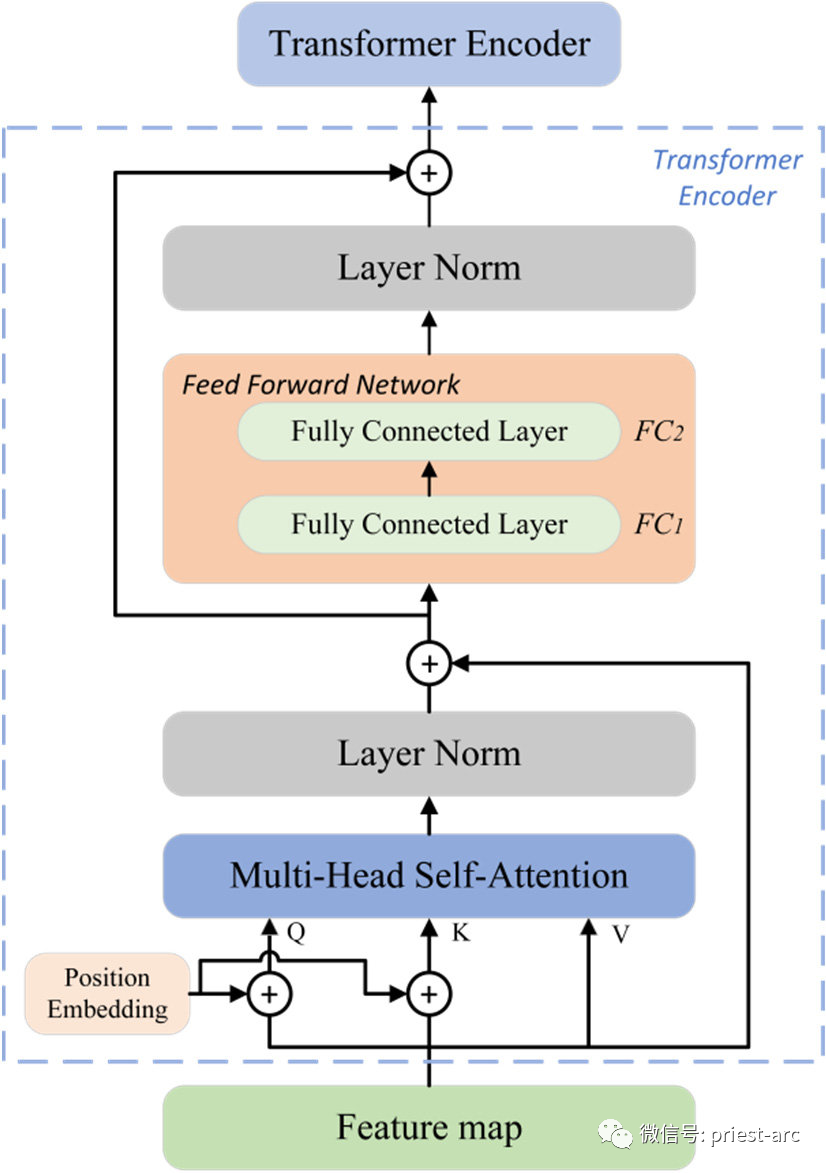
Это стек Nx идентичных слоев кодера (в оригинальной статье Nx=6). Каждый уровень кодера состоит из двух подуровней: многоголовочного механизма самообслуживания и нейронной сети прямой связи. Механизм самообслуживания с несколькими головками используется для моделирования взаимосвязи между различными позициями во входной последовательности, а нейронная сеть прямой связи используется для выполнения нелинейных преобразований для каждой позиции. Роль стека кодировщика заключается в преобразовании входной последовательности в серию представлений функций высокого уровня.
Общая архитектура кодировщика Transformer. Мы используем встраивание абсолютного положения в кодировщик Transformer. Для получения подробной информации см. следующее:
2. Стек декодера
Это также стек Nx идентичных слоев декодера (в оригинальной статье Nx=6). Каждый уровень декодера содержит дополнительный подуровень многоголовочного механизма самообслуживания в дополнение к двум подуровням уровня кодера. Этот дополнительный механизм самообслуживания используется для того, чтобы обращать внимание на выходные данные стека кодера и помогает декодеру декодировать информацию во входной последовательности и генерировать выходную последовательность.
Между стеками кодера и декодера также имеется уровень позиционного кодирования. Роль этого уровня кодирования позиции заключается в использовании информации о последовательности для обеспечения фиксированного представления кодирования для каждой позиции во входной последовательности. Таким образом, модель может использовать уровни позиционного кодирования для обработки последовательной информации последовательности без рекурсивных или сверточных операций.
Общая архитектура декодера Transformer выглядит следующим образом:
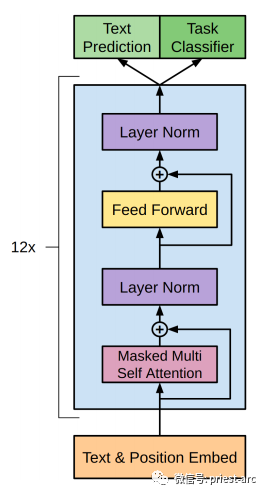
В реальных сценариях интерактивные отношения между ними следующие:
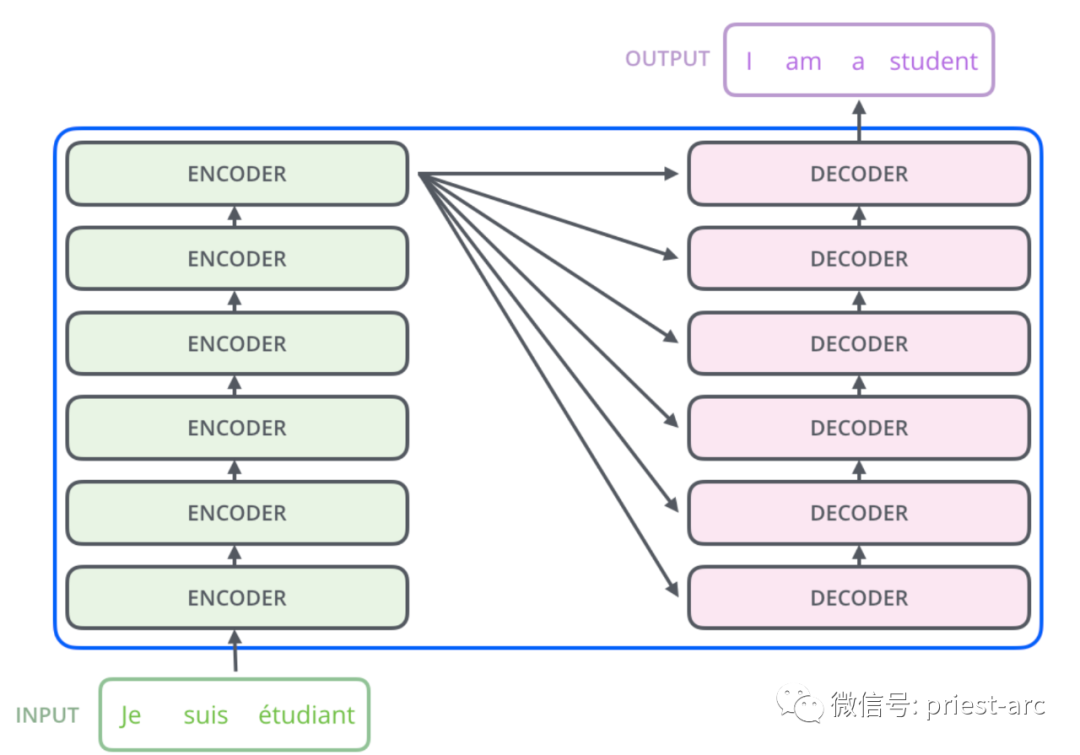
— 04 —
Что такое нейронная сеть-трансформер?
Известно, что Transformer играет ключевую роль в проектировании нейронных сетей для обработки текстовых последовательностей, последовательностей генома, звуковых и временных рядов и т. д. Среди них обработка естественного языка является наиболее распространенной областью применения нейронной сети Transformer.
При получении последовательности векторов нейронная сеть Transformer кодирует эти векторы и декодирует их обратно в исходную форму. Механизм внимания Трансформера — его незаменимый основной компонент. Механизм внимания демонстрирует важность контекстной информации других токенов, окружающих его, при кодировании данного токена во входной последовательности.
Например, в модели машинного перевода механизм внимания позволяет Трансформатору правильно переводить слово «это» на английском языке в соответствующие по полу слова на французском или испанском языке в зависимости от контекста всех связанных слов. Трансформеры способны использовать механизмы внимания, чтобы определить, как перевести текущее слово, принимая во внимание влияние окружающих его слов.
Однако следует отметить, что нейронная сеть Transformer заменила ранние модели, такие как рекуррентная нейронная сеть (RNN), длинная кратковременная память (LSTM) и вентилируемая рекуррентная единица (GRU), как более продвинутый и эффективный выбор.
Обычно нейронная сеть Transformer принимает входное предложение и кодирует его в две разные последовательности:
1. Последовательность встраивания вектора слова
Вложения слов — это числовые представления текста. В этом случае нейронная сеть может обрабатывать только слова, преобразованные во встраиваемые представления. Слова в словаре представлены в виде векторов во внедренном представлении.
2. Последовательность действий датчика положения
Позиционные кодеры представляют позиции слов в исходном тексте в виде векторов. Трансформатор сочетает в себе встраивание векторов слов и позиционное кодирование. Затем он отправляет объединенные результаты отдельным кодерам, а затем декодерам.
В отличие от RNN и LSTM, которые предоставляют входные данные последовательно, Transformer предоставляет входные данные одновременно. Каждый кодер преобразует свои входные данные в другую последовательность векторов, называемую кодировкой.
Декодер работает в обратном порядке. Он преобразует кодировку обратно в вероятности и генерирует выходные слова на основе вероятностей. Используя функцию softmax, Transformer может генерировать предложения на основе выходных вероятностей.
В каждом декодере и кодере есть компонент, называемый механизмом внимания. Он позволяет обрабатывать входное слово с использованием соответствующей информации из других слов, блокируя при этом слова, которые не содержат соответствующей информации.
Чтобы в полной мере использовать возможности параллельных вычислений, предоставляемые графическими процессорами, Transformer использует механизм многоголовочного внимания для параллельной реализации. Механизм внимания с несколькими головками позволяет одновременно обрабатывать несколько механизмов внимания, тем самым повышая эффективность вычислений.
По сравнению с LSTM и RNN одним из преимуществ модели глубокого обучения Transformer является ее способность обрабатывать несколько слов одновременно. Это связано с возможностями параллельных вычислений Transformer, которые позволяют ему более эффективно обрабатывать данные последовательности.
— 05 —
Распространенные модели трансформаторов
На данный момент Transformer является одной из основных архитектур, используемых для создания большинства самых передовых моделей в мире. Он добился больших успехов в различных областях, включая, помимо прочего, следующие задачи: распознавание речи в преобразование текста, машинный перевод, генерация текста, перефразирование, ответы на вопросы и анализ настроений. В результате этих задач возникли некоторые из лучших и наиболее известных моделей.
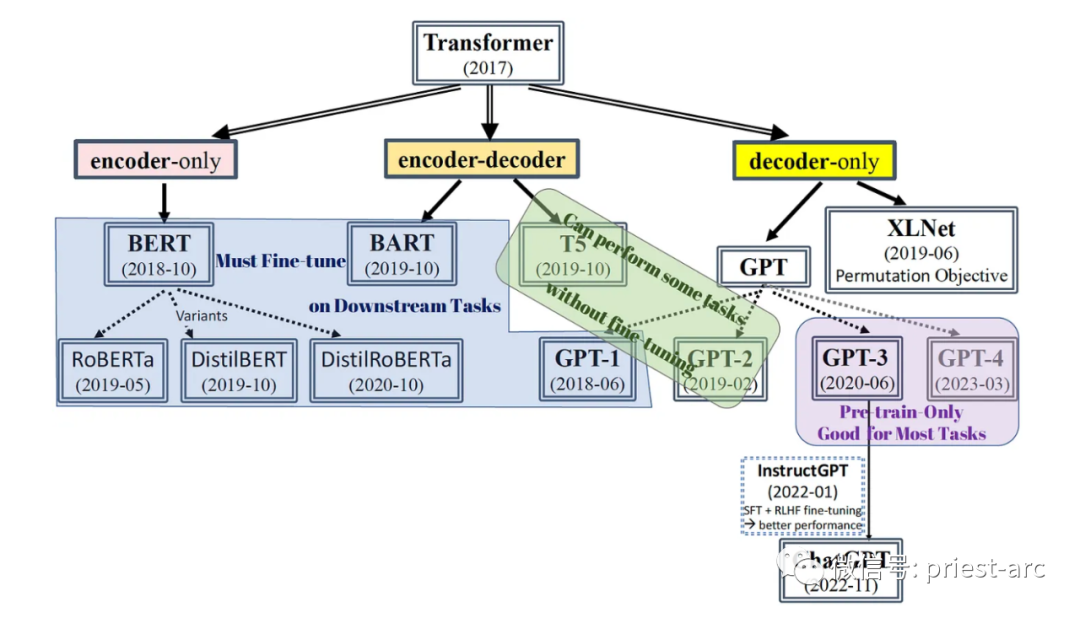
Схема системы модели на базе Трансформера
1. BERT (трансформатор в виде двунаправленного энкодера)
Как технология, разработанная Google и разработанная для обработки естественного языка, она основана на предварительно обученной модели Transformer и в настоящее время широко используется в различных задачах НЛП.
В этой технологии двунаправленные представления кодеров превращаются в важную веху в обработке естественного языка. Представление двунаправленного кодировщика (BERT) позволило добиться значительных прорывов в задачах понимания естественного языка благодаря предварительно обученным моделям Transformer. BERT настолько важен, что в 2020 году почти каждый английский запрос в поисковой системе Google был основан на технологии BERT.
Основная идея BERT заключается в том, чтобы позволить модели изучать богатые языковые представления путем предварительного обучения на крупномасштабных неразмеченных текстовых данных. Модель BERT является двунаправленной и может одновременно учитывать левую и правую информацию слова в контексте, тем самым лучше улавливая семантику и контекст слова.
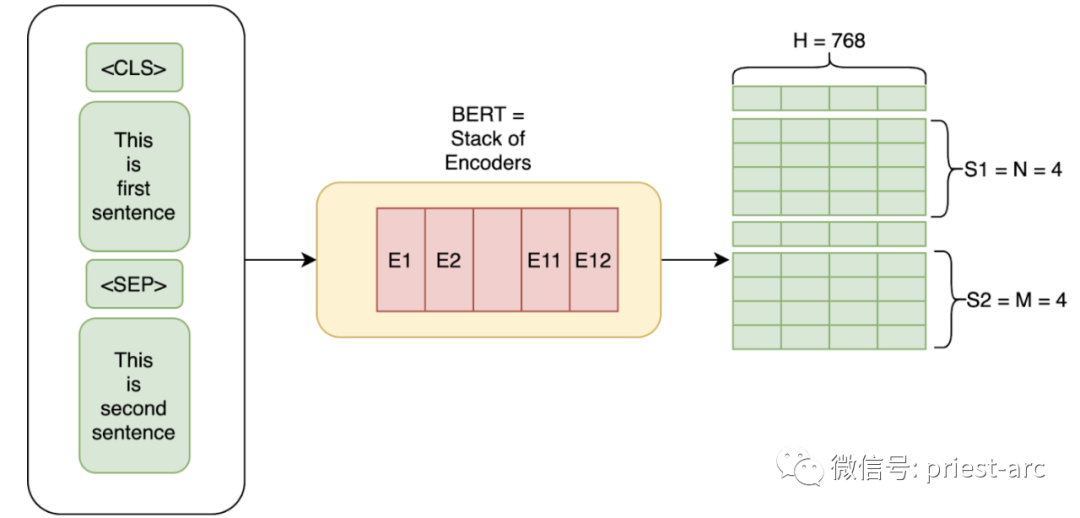
Успех BERT отмечает важную позицию архитектуры Transformer в области НЛП и оказал огромное влияние на практические приложения. Он вносит значительный прогресс в область обработки естественного языка и обеспечивает более точное и интеллектуальное семантическое понимание для таких приложений, как поисковые системы.
2. GPT-2/GPT-3 (генерация предварительно обученной языковой модели)
Генеративные преобразователи предварительного обучения 2 и 3 соответственно представляют собой наиболее совершенные модели обработки естественного языка. Среди них GPT (генеративный предварительно обученный преобразователь) — это модель искусственного интеллекта с открытым исходным кодом, которая фокусируется на обработке задач, связанных с обработкой естественного языка (NLP), таких как машинный перевод, ответы на вопросы, обобщение текста и т. д.
Наиболее существенные различия между двумя вышеперечисленными моделями заключаются в «масштабе» и «функциональности». В частности, GPT-3 — это новейшая модель, в которой представлено множество новых функций и улучшений по сравнению с GPT-2. Кроме того, емкость модели GPT-3 достигает ошеломляющих 175 миллиардов параметров машинного обучения, тогда как GPT-2 имеет только 1,5 миллиарда параметров.
Благодаря такому огромному набору параметров GPT-3 демонстрирует впечатляющую производительность в задачах обработки естественного языка. Он обладает более мощными возможностями понимания и генерации языка, а также может более точно понимать и генерировать текст на естественном языке. Кроме того, GPT-3 особенно хорош в создании текста, способного создавать связные и логичные статьи, разговоры и истории.
Улучшение производительности GPT-3 обусловлено большим масштабом параметров и более совершенной архитектурной конструкцией. Это позволяет модели изучать более глубокие и полные языковые знания путем предварительного обучения на крупномасштабных текстовых данных, что позволяет GPT-3 стать одной из самых мощных и продвинутых генеративных моделей Transformer для предварительного обучения в настоящее время.
Конечно, помимо двух вышеупомянутых основных моделей, T5, BART и XLNet также являются членами семейства Transformer (Vaswani et al., 2017). Эти модели используют кодер, декодер или и то, и другое Transformer для понимания языка или генерации текста. Из-за нехватки места мы не будем вдаваться в подробности в этой статье.
— 05 —
Модель Трансформера не идеальна
По сравнению с моделью seq2seq на основе RNN, хотя модель Transformer добилась больших успехов в области обработки естественного языка, она также имеет некоторые ограничения, в основном включающие следующие аспекты:
1. Высокие требования к вычислительным ресурсам.
Модели трансформаторов обычно требуют значительных вычислительных ресурсов для обучения и вывода. Из-за большого количества и сложности параметров модели для поддержки ее работы требуются значительные вычислительные мощности и ресурсы хранения, что делает относительно сложным применение модели Трансформера в средах с ограниченными ресурсами.
2. Сложность обработки длинного текста.
В некоторых конкретных сценариях из-за особенностей механизма самообслуживания в модели Трансформера возникают определенные трудности при обработке длинных текстов. По мере увеличения длины текста значительно возрастают вычислительная сложность и требования к хранению модели. Таким образом, модель Transformer может столкнуться с ухудшением производительности или неспособностью обрабатывать очень длинные тексты.
3. Отсутствие практического механизма рассуждения.
В реальных бизнес-сценариях модели Transformer обычно предварительно обучаются на крупномасштабных данных, а затем настраиваются для конкретных задач для достижения высокой производительности, что делает модель адаптируемой к новым областям или конкретным задачам во время фактического процесса рассуждения. Поэтому для новых полей или конкретных задач нам часто необходимо провести дополнительное обучение или корректировки для повышения производительности модели.
4. Зависимость от обучающих данных
Модель «Трансформер» требует большого количества неразмеченных данных для обучения на этапе предварительного обучения, что затрудняет применение модели «Трансформер», когда ресурсы ограничены или данных в конкретной области недостаточно. Кроме того, модель также имеет определенную зависимость от качества и разнообразия обучающих данных. Данные разного качества и полей могут влиять на производительность модели.
5. Отсутствие здравого смысла и навыков рассуждения.
Хотя модель Трансформера добилась значительного прогресса в задачах генерации языка и понимания, она все еще имеет определенные ограничения в рассуждениях на основе здравого смысла и возможностях рассуждения. Модели могут плохо работать при решении таких задач, как сложные рассуждения, логические выводы и абстрактные рассуждения, и требуют дальнейших исследований и улучшений.
Несмотря на эти ограничения, модель Transformer в настоящее время остается одной из самых успешных и передовых моделей обработки естественного языка, предоставляя мощные решения для многих задач НЛП. Будущие исследования и разработки помогут преодолеть эти ограничения и продвинуть область обработки естественного языка дальше.
Reference :
[1] https://developers.google.com/machine-learning
[2] https://www.turing.com/kb/brief-introduction-to-transformers-and-their-power
Adiós !



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
