Портреты пользователей — заметки из «Практики машинного обучения Meituan»
Недавно я узнал о портретах пользователей. Эта статья в основном посвящена чтению заметок из «Практики машинного обучения Meituan».
Что такое портрет пользователя?
Разница между моделями пользователей и портретами пользователей.Модели пользователей — это виртуальные представления реальных пользователей.,Модель пользователя, абстрагированная на основе реальных данных,Это концепция, используемая продуктами при описании потребностей пользователей. Портреты пользователей создаются на основе огромных пользовательских данных.,Моделирование абстрагирует систему меток атрибутов каждого пользователя.,Эти атрибуты обычно имеют определенную коммерческую ценность.
В частности, проблема, которую необходимо решить при профилировании пользователей, заключается в создании системы атрибутов пользователей, которая могла бы напрямую направлять бизнес-операции на основе сложных данных, не имеющих прямой коммерческой ценности, посредством очистки, анализа и сортировки, таких как демографические атрибуты, поведенческие траектории и группы пользователей. . Потребительские предпочтения и т. д., эти данные должны иметь четкую иерархию и понятность, поэтому портреты пользователей также можно рассматривать как маркировку данных. Я понимаю, что профилирование пользователей — это также процесс уменьшения размерности. Чтобы получить большие данные из хранилища данных, мы не можем сразу передать все данные приложениям верхнего уровня, а извлекаем данные в измерении меток и отправляем их на верхний уровень. -слой.
Первым шагом в построении портретов пользователей является определение того, какие теги необходимо создать. Это определяется потребностями бизнеса и фактической ситуацией с данными. Особое внимание необходимо уделять детализации тегов. не приведет к различию, а слишком мелкая детализация приведет к созданию системы тегов. Она слишком велика, чтобы быть универсальной, и имеет высокую сложность алгоритма.
Система меток портретов пользователей обычно может быть представлена в виде древовидной диаграммы (ассоциативной карты), и система обычно делится на несколько основных категорий (классификация первого уровня). Каждая основная категория разделена на несколько подкатегорий (вторичных классификаций), а также могут существовать многоуровневые классификации с разной глубиной.
Классификация первого уровня обычно включает в себя: демографические атрибуты, предпочтения по интересам, группы характеристик, классификацию пользователей, атрибуты LBS, поведение пользователей, бизнес-теги и т. д.
Интеллектуальный анализ данных портретов пользователей
Портретная архитектура интеллектуального анализа данных
Система портретных меток пользователя,Внедрено из разработки,Обычно делят на две категории: посредством стратегического статистического анализа (с помощью статистики, посредством модели машинного обучения);
Данные профилирования пользователей обычно включают в себя данные, очистка данных, генерация признаков, моделирование этикеток,Прогнозные расчеты,Оценка эффекта,Онлайн-заявка,Обратная связь по эффекту,Итерационный процесс оптимизации.
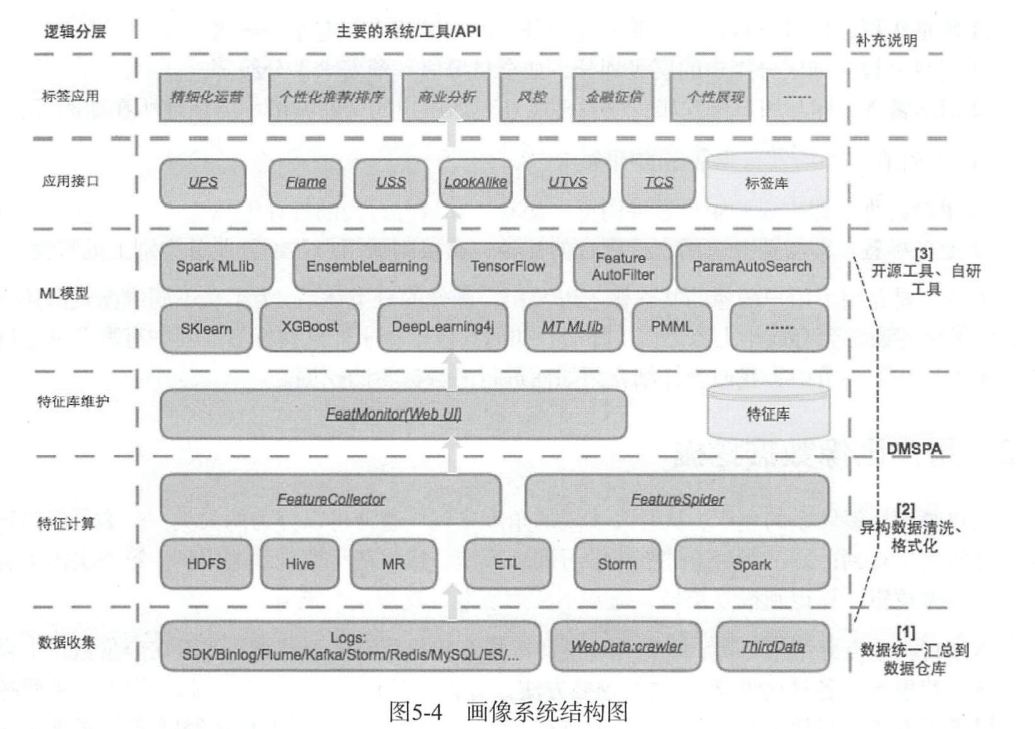
сбор данных
сбор данные необходимо использовать по-разному, внутренние данные журнала,Данные отчетов о торговых точках,Мониторинг бизнеса и другие методы,Внешние общедоступные данные Интернета,Сканировать данные,Сотрудничать со сторонними данными. Окончательные данные собираются в хранилище данных на базе экосистемы Hadoop.
Расчет функции
Очистка данных Преобразование его в функции является важным шагом.,напрямую влияет на конечный эффект. Основная работа здесь — Обработка. данных (фильтрация выбросов, неоднородность данных по изоморфизму), обработка данных (статистика, сглаживание, нормализация). Подход Meituan: приведите пример данных,Автоматически сканировать таблицы структурированных данных (обычно Hive).,По некоторым показателям корреляции (коэффициент корреляции,Хи-квадрат,p-значение и т. д.),Найдите столбцы данных, которые тесно связаны с метками образцов.,После небольшой обработки добавьте библиотеку объектов.
Ведение базы данных объектов
После создания функций должно быть единое место управления для облегчения сбора новых функций, обновления и автономного использования старых функций, а также визуализации статистических показателей функций. Самое главное — иметь обходную систему для отслеживания колебаний характеристик и раннего предупреждения о наличии рисков качества.
Модель машинного обучения
После того, как у вас есть база данных объектов, вам необходимо выполнить машинное моделирование меток. Алгоритмы необходимо использовать для выполнения: выбора функций, обучения модели, оценки эффекта и прогнозирования. Распространенные инструменты для обучения моделей: spark MLib, sklearn, XGBoost, Tensorflow и др.
интерфейс приложения
После прогнозирования этикеток с помощью портретного моделирования вам необходимо рассмотреть возможность размещения этикеток в Интернете и отслеживания отзывов о доходах. Компания Meituan разработала систему TCS, отвечающую за сбор различных меток на основе иерархической классификации, а также за контроль количества и качества меток. Для использования данных предусмотрено два режима: запрос меток пользователя по идентификатору пользователя (UPS) по набору атрибутов пользователя, обведение группы пользователей, соответствующих условиям (UTVS);
Портретное приложение
Последний шаг — применение тегов портретов пользователей к различным направлениям бизнеса. К основным направлениям относятся: уточнение операций, персонализированные рекомендации, бизнес-анализ, персонализированное отображение и т. д.
ID пользователя
В реальной жизни идентификатор удостоверения личности человека может идентифицировать человека. В процессе профилирования пользователей предприятия обычно используют идентификатор пользователя для идентификации человека. Однако последующий анализ данных внутри бизнеса очень низок, и пользователям обычно необходимо войти в систему для записи данных. Кроме того, многие люди регистрируют несколько идентификаторов. Таким образом, в дополнение к userID мы также можем формировать пользователя на основе идентификатора устройства, payaccount и других бизнес-идентификаторов компании. Все идентификаторы пользователя единообразно сопоставляются с уникальным номером NPI (физическое лицо).
Однако если суммировать данные различных идентификаторов, объем данных очень велик, а вычислительный процесс расчета связанного графа очень велик. Если сложно распараллелить алгоритм поиска объединения и использовать метод MapReduce для поиска связного графа, обращенного к связному подграфу с очень большим радиусом, возникнет проблема невозможности сходимости после нескольких итераций, которые Meituan использует оптимизацию MapReduce. алгоритм Hash-to-min может уменьшить временную сложность до O(logN)
Данные объекта
В процессе разработки различных этикеток,Многие функции данных одинаково действительны,Во избежание повторного извлечения данных объекта,Перед майнингом тегов,Во-первых, необходимо выполнить планирование и создание базы данных пользовательских объектов.
Сначала разберитесь и классифицируйте пользовательские данные в целом. Пользовательские данные обычно делятся на статические данные учетной записи (время регистрации, уровень, наполнение информацией и т. д.), данные LBS (область активности и т. д.) и данные о динамическом поведении (покупки, просмотр, сбор и т. д.). Затем данные далее разделяются на основе приведенной выше классификации.
образец данных
Проблема с выборками также является большой проблемой в процессе пользовательского моделирования. Основными проблемами являются отсутствие выборок, небольшое количество выборок и одиночные выборки. В ответ на эти проблемы Meituan применила три метода их решения: найти, передать и попробовать.
Для недостающих образцов (есть много этикеток, которые необходимо смоделировать, но есть образцы для нескольких типов этикеток) образцы можно «найти» различными путями, через анкеты, внутренние данные сотрудников, маркировку вручную и т. д.; также можно использовать «передачу» для передачи некоторых образцов. Проблема преобразуется, например, проблема пользовательских предпочтений преобразуется в задачу прогнозирования, а реальные клики пользователя используются в качестве аннотаций для получения обучающих данных.
Для проблем с небольшим количеством образцов (количество образцов невелико из-за стоимости приобретения образцов) и проблем с одним образцом (в некоторых сценариях есть только положительные образцы и нет отрицательных образцов) главное — «тестировать», и экспериментальные результаты в экспериментальных научных статьях являются хорошим алгоритмом. Такие как алгоритмы самообучения, трансдуктивный SVM, PU-обучение (технология One-Class-SVM/Biased-SVM/SPY/NB и т. д.).
Моделирование этикеток
Моделирование этикеток Помимо выбора и оптимизации модели алгоритма проектирования, существует также большое количество инженерных вопросов. На основе экологии Hadoop разработана серия крупных Обработка. инструменты и фреймворки для работы с данными, представленные HDFS, HBase, MongoDB, RocksDB, большими Хранилище данных может обеспечить масштабируемое запоминающее устройство большой емкости. Платформы автономных пакетных вычислений, представленные MapReduce, Hive и Spark, делают возможными массовые вычисления данных. Платформы вычислений в реальном времени, представленные Storm, Spark-Streaming и Flink, позволяют расчеты данных становятся мгновенно доступными.
На следующем рисунке показана схема архитектуры хранилища данных портрета пользователя.
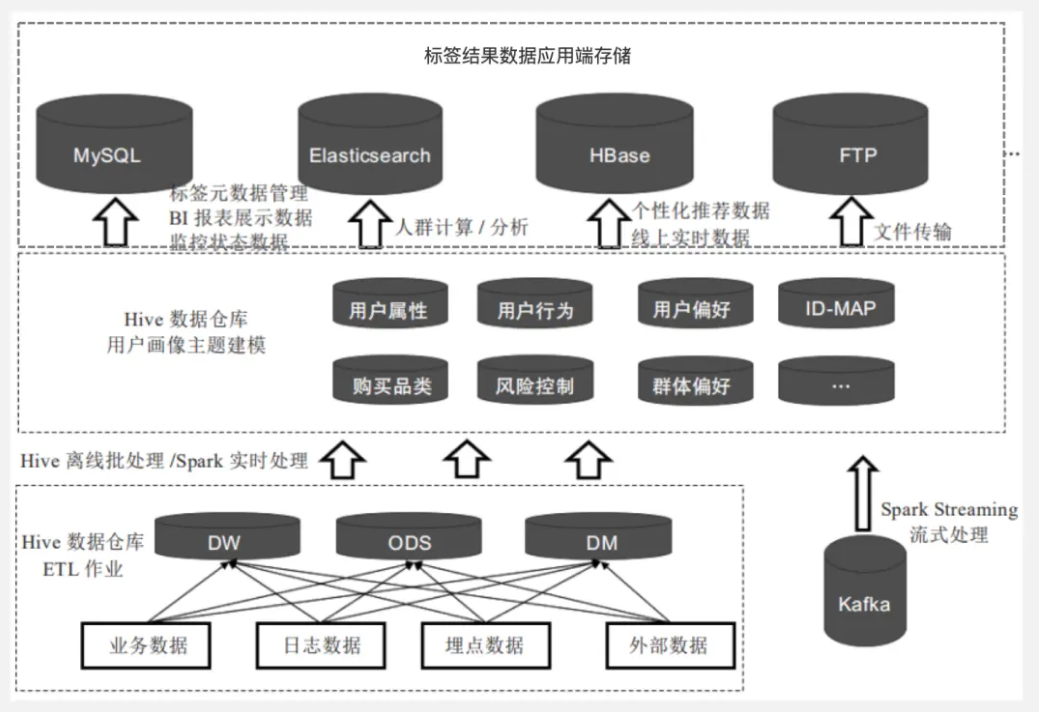
● Пунктирный прямоугольник под заданием ETL хранилища данных Hive — это процесс обработки ETL хранилища данных сценария. Ежедневные бизнес-данные, данные журналов, внедренные данные и т. д. обрабатываются посредством процесса ETL на соответствующем уровне ODS, уровне DW и т. д. DM уровня хранилища данных.
● Моделирование темы портрета пользователя хранилища данных Hive. Пунктирный прямоугольник посередине — это основное звено моделирования портрета пользователя. Вторичное моделирование и обработка пользовательских данных на основе уровней ODS, DW и DM хранилища данных. быть выполнено.
● Хранение данных результатов тегов на стороне приложения. В процессе моделирования темы портрета пользователя результаты расчета тегов пользователя будут записываться в Hive.
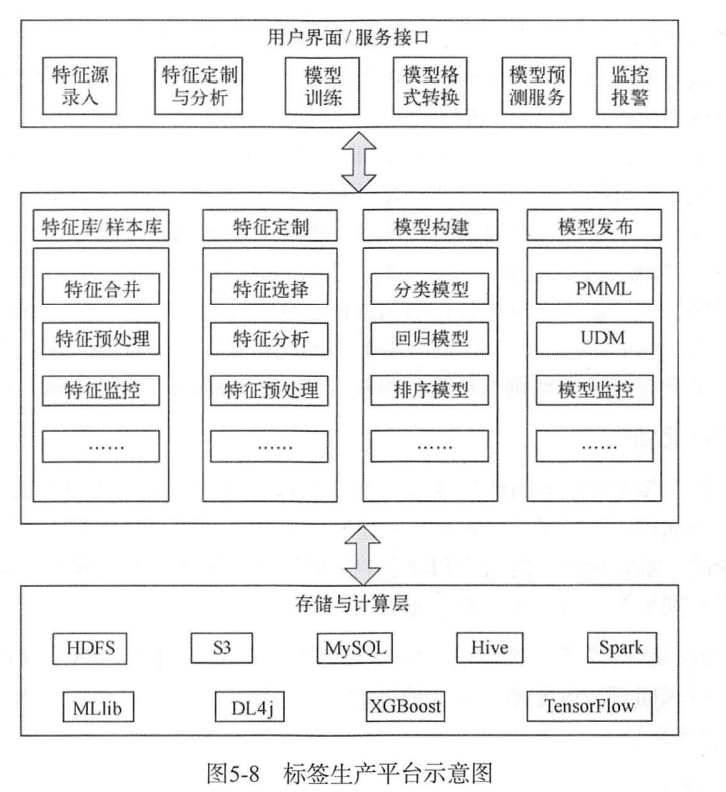
Оффлайн Моделирование этикетокструктура
На рисунке ниже показаны структурная схема и блок-схема офлайн-системы Моделирование этикеток Meituan.
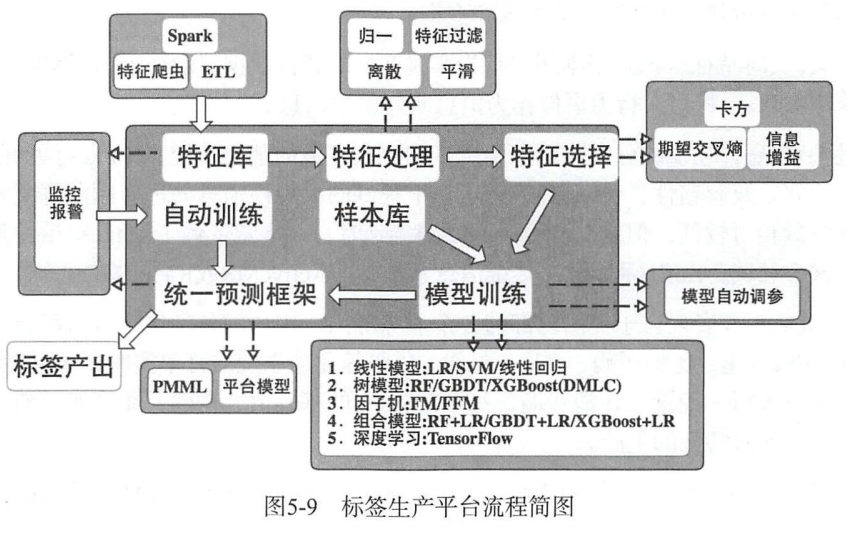
Вышеупомянутая платформа генерации тегов основана на офлайн-данных, и некоторые компании больше внимания уделяют сценариям в реальном времени. На самом деле, для требований к маркировке в реальном времени платформы, основанные на автономных системах Spark и Hive, не могут гарантировать производительность в реальном времени. Чтобы решить эту проблему, компания Meituan разработала Моделирование в реальном времени Flame. этикетоксистема。
в реальном времени Моделирование этикетокструктура
Функции реального времени должны создаваться в реальном времени на основе поведения пользователя. объекта,Данные о поведении пользователей поступают из самых разных источников.,Meituan единообразно использует Kafka для обработки событий поведения пользователя как сообщений в очереди сообщений. Kafka — распределенная система обмена сообщениями с высокой пропускной способностью.,Имеет очень хорошую пропускную способность. Производители сообщений Кафки представляют различные предприятия.,Каждое поведение в реальном времени записывается в очередь в виде сообщения. Со стороны потребителя,Мейтуань основан на шторме,Создайте топологию для обработки сообщений в реальном времени.,Выполните генерацию функций в реальном времени. Обмен сообщениями о шторме,Автоматически обрабатывайте потоковые вычисления одновременно в кластере.
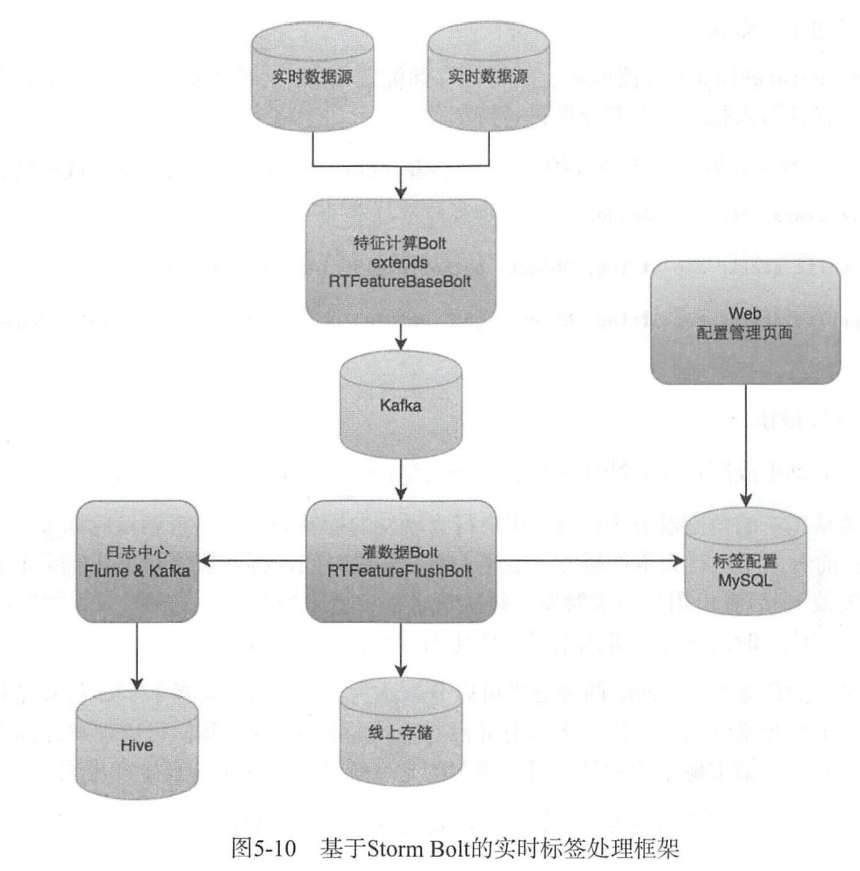
С точки зрения производства теги реального времени делятся на два типа: теги, активируемые поведением пользователя, и теги, активируемые запросами пользователей. В первом случае тег не будет меняться в течение определенного периода времени после того, как он будет сгенерирован и сохранен в базе данных; во втором каждый запрос приведет к изменению значения тега из-за таких факторов, как текущий контекст. Между событиями поведения пользователя и вызовами системных запросов нет прямой связи. Можно понимать, что теги генерируются асинхронно и сохраняются в базе данных. Теги, запускаемые запросами, можно понимать как синхронно вычисляемые во время запроса;
Опыт работы с алгоритмами майнинга тегов
Система интеллектуального анализа тегов Meituan представлена выше. Они также предоставляют опыт обработки функций и моделей.
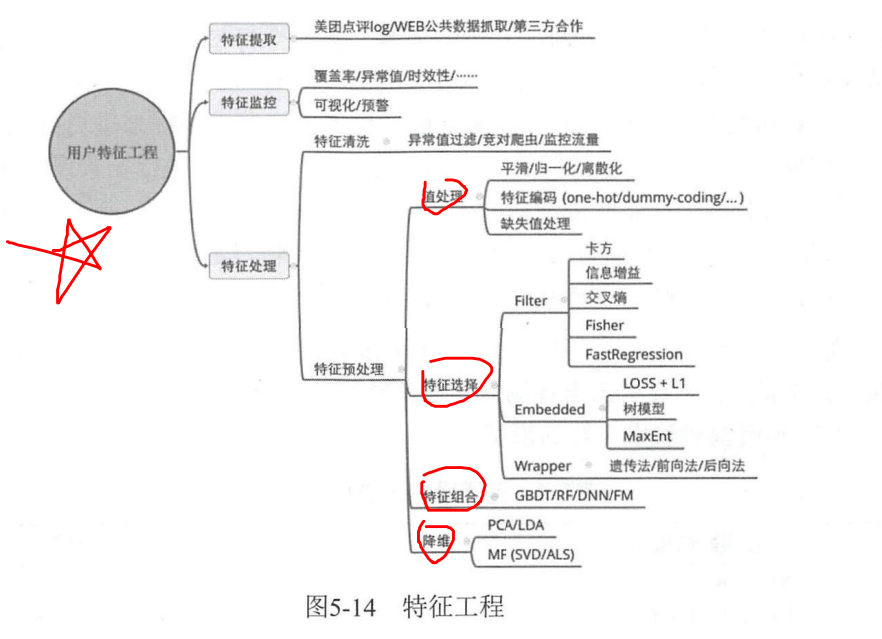
разработка функций
Извлечение функций в основном используется для форматирования данных на основе бизнес-сценариев; мониторинг функций используется для упаковки качества функций и обеспечения использования эффектов модели для обработки ненормальных функций, удаления ненужных функций и анализа потенциальных функций;
Использование модели
В процессе анализа тегов пользовательского моделирования вы столкнетесь с различными проблемами разработки тегов, такими как статистика, семантический анализ, классификация, регрессия, кластеризация и т. д. Различные модели предназначены для разных задач, таких как EM, Kmeans и GM в кластеризации; логистическая регрессия, Байес и случайные леса в классификации, FP-рост и т. д. в правилах ассоциации;
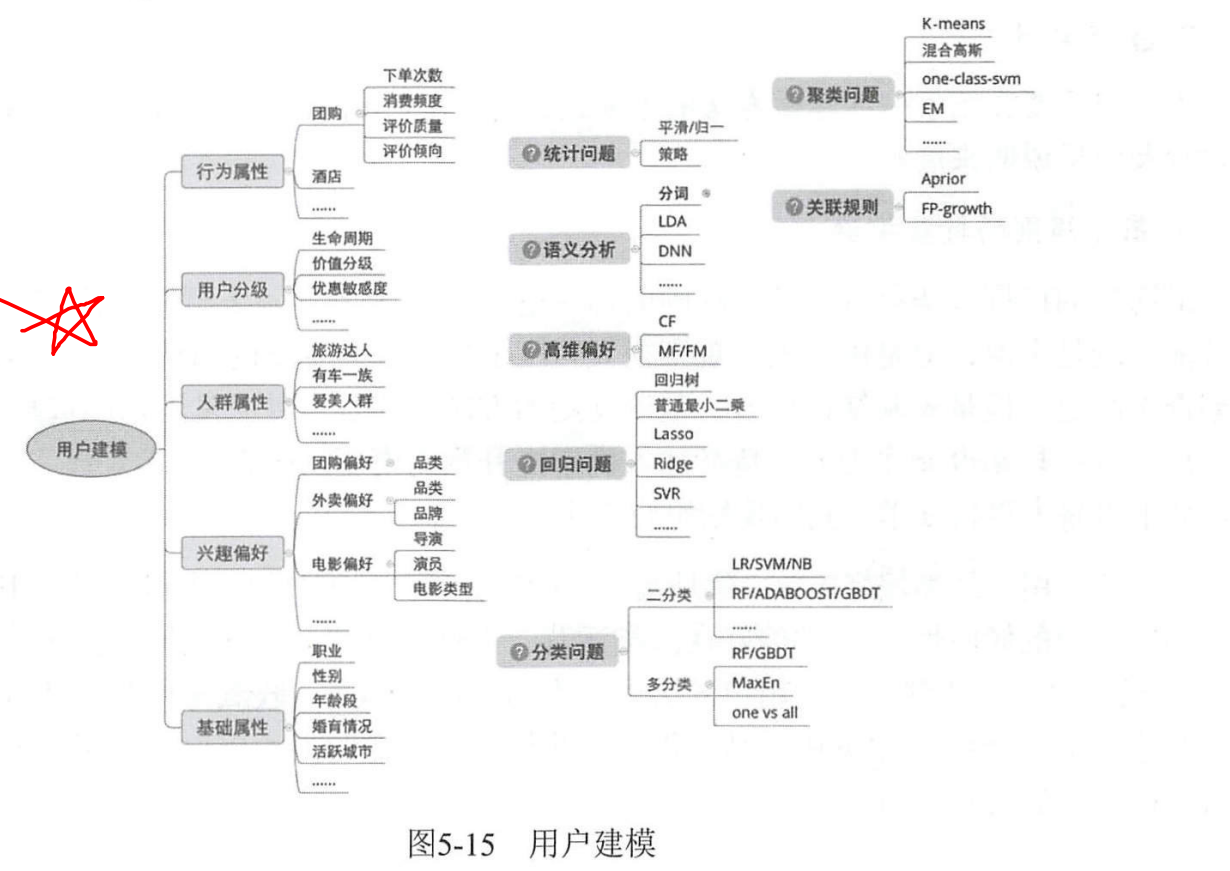
По опыту Meituan, XGBoost хорошо работает в процессе майнинга с несколькими метками, LR+RF/LR+GBDT работает в целом хорошо, а простые линейные модели, такие как LR/SVM, более рентабельны. DNN не очень хорошо справляется с процессом интеллектуального анализа меток.

Анализ тегов на основе правил
Преимущество интеллектуального анализа меток, основанного на искусственных правилах, заключается в том, что при недостатке образцов имеется много предварительных знаний.
1. Явный анализ образцов по меткам
Мы можем анализировать поведение пользователей на основе полученных нами отмеченных пользователей, использовать контролируемую модель обучения, чтобы найти связь между поведением пользователей и тегами, а также прогнозировать неотмеченных пользователей.

По данным 2016 года, xgboost оказывает наилучшее влияние на набор статистических данных. Поскольку древовидная модель сильно нелинейна, она может изучать комбинации признаков высокого порядка из выборок, что невозможно для традиционных линейных моделей. Машина факторизации может изучать только комбинации второго порядка на не очень разреженных наборах данных, и фактический эффект не так хорош, как простая логистическая регрессия. Глубокое обучение требует глубокой настройки параметров, но это данные за 16 лет, и нынешнее глубокое обучение должно быть значительно улучшено.
2. Проблема небольшой выборки и анализ данных одной выборки
Иногда мы рекламируем продукт только определенной группе пользователей, например группам фанатов, где есть небольшая проблема с образцом или только несколько положительных образцов. При анализе таких ярлыков толпы точность важнее запоминаемости.
Решение: Обучение на небольшом количестве размеченных и неразмеченных данных называется обучением Лу, а обучение на положительных образцах и нестандартных данных называется обучением Пу.
Лу обучения, самый ранний метод использования немаркированных данных в обучении — это самообучение. Основная идея состоит в том, чтобы сначала спрогнозировать немаркированные данные, а затем добавить те, которые имеют высокую достоверность, к обучению и выполнять итерацию до тех пор, пока они не будут соответствовать выходной модели.
Существует два метода обучения Pu: прямой метод и двухэтапный метод. Прямой метод заключается в непосредственном моделировании одной выборки, такой как V-SVM, одноклассовая SVM, смещенная SVM и т. д. Двухэтапный метод заключается в преобразовании обучения Pu в общую задачу классификации посредством преобразования. Сначала найдите несколько надежных отрицательных образцов из нестандартизированных данных, вы можете использовать шпионскую технологию, технологию IDNF, технологию NB и т. д., а затем использовать модель классификации.
3. Добыча тегов пользователя в реальном времени
Один из них заключается в количественной оценке на основе таких действий, как покупки или клики; другой заключается в использовании обратной связи с дисплеем пользователя в качестве сигнала и прогнозировании будущих кликов и поведения пользователя в качестве целевого сигнала.
Приложение для создания портретов пользователей
Метод моделирования для создания данных портретов пользователей обсуждался ранее. В практических приложениях ценность портретов пользователей должна быть действительно реализована путем реализации портретов в реальном времени с помощью инженерных методов.
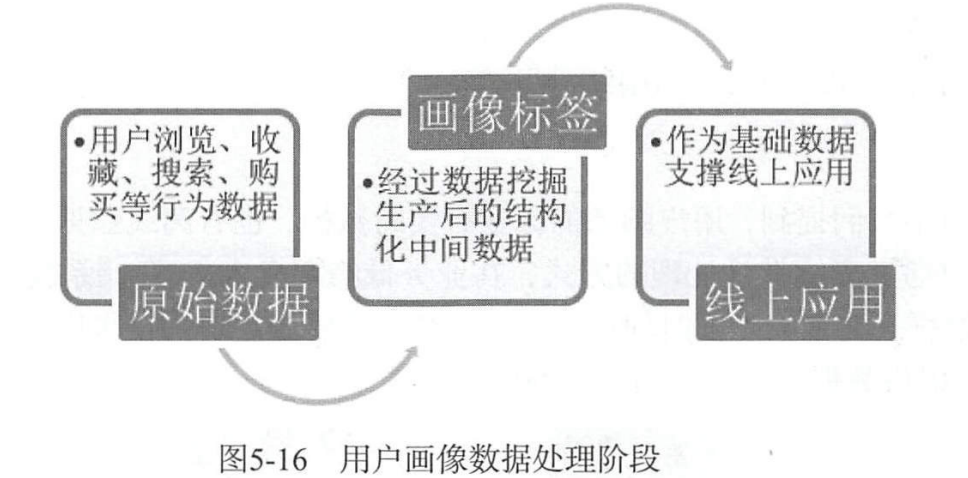
С точки зрения сценариев применения портретов пользователей,Пользователь может позвонить идентификатору пользователя, чтобы запросить портретные данные пользователя.,Вы также можете найти список пользователей, соответствующих условиям, по портретным данным пользователя.,Шэньчжэнь использует портретные данные в качестве ограничений для определения групп людей.,Затем проводится дальнейший совокупный анализ на основе совокупности.,Визуальное отображение и т. д.
В качестве примера возьмем рекомендательный бизнес Meituan: рекомендательный бизнес составляет персональные рекомендации на основе портрета каждого пользователя Meituan и отображает групповые заказы на покупку или магазины, которые могут быть интересны пользователю. Важным шагом здесь является запрос портрета пользователя на основе уникального представления пользователя (uerID), а затем выдача различных рекомендаций на основе портрета.
В качестве примера возьмем push-бизнес Meituan: push-бизнес выбирает целевые группы пользователей из числа крупных пользователей Meituan и отправляет им купоны или рекламные уведомления. Важной частью этого является поиск людей по портретам.
Согласно этим двум сценариям применения,Meituan отдельно построила Система запросов портрета пользователя в режиме реального времении Система анализа портретов толпы。
Система запросов портрета пользователя в режиме реального времени
Проблемы, с которыми сталкиваются при создании системы портретных запросов в реальном времени, — это большой объем данных, низкие требования ко времени отклика и высокие требования к доступности системы. Столкнувшись с этими проблемами, компания Meituan разработала систему с учетом аспектов проектирования архитектуры, выбора хранилища и обеспечения надежности.
Архитектурный дизайн
Ярлыки портретов пользователей включают данные в реальном времени и офлайн-данные. Автономные данные могут обрабатываться посредством автономной пакетной обработки и помещаться в систему хранения в непиковые периоды. Система хранения просто предоставляет запрос.
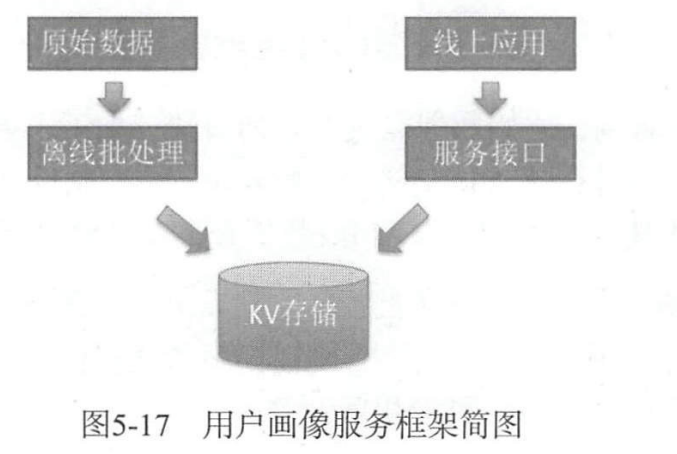
Однако для данных этикеток в реальном времени запись данных должна обеспечивать производительность в реальном времени, а архитектура системы должна быть оптимизирована и настроена для удовлетворения потребностей маркировки в реальном времени.
Идеи лямбда-архитектуры
Для систем больших данных в реальном времени трудно отследить большой объем накопленных исторических данных, используя только вычислительные среды реального времени (шторм, искровая потоковая передача и т. д.), поэтому офлайн-данные и данные реального времени необходимо объединить. обеспечить временную целостность и характер данных в реальном времени.
Архитектура Lambda объединяет автономные вычисления и вычисления в реальном времени, объединяет ряд архитектурных примитивов, таких как неизменяемость, разделение чтения и записи и изоляцию сложности, а также может легко интегрировать различные компоненты больших данных, такие как Hadoop, Kafka, Storm, Spark и HBase. .
Архитектура Lambda делит систему на три уровня: уровень пакетных данных, уровень данных в реальном времени и уровень обслуживания.
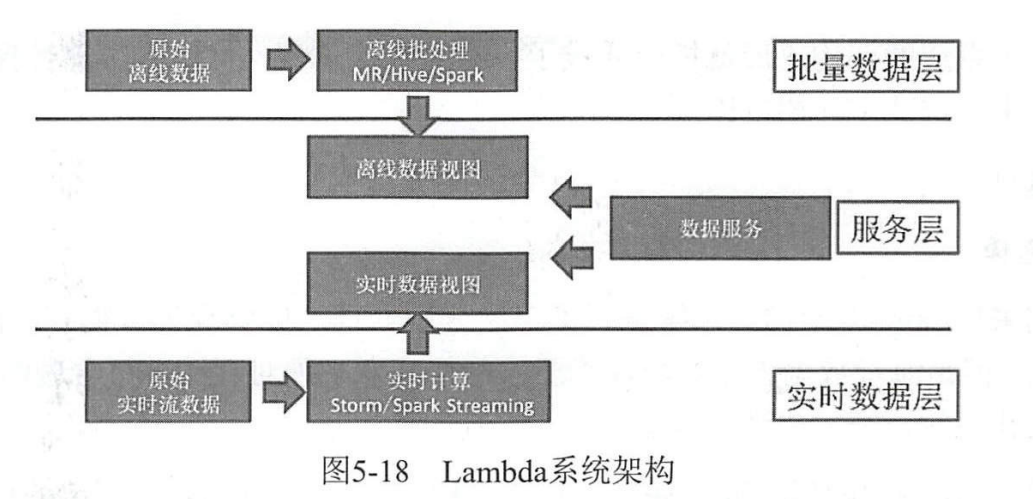
Уровень пакетных данных выполняет пакетную обработку данных в автономном режиме и использует вычисления в реальном времени для данных после последнего выполнения, так что все временные диапазоны покрываются слоем данных. Уровень обслуживания считывает представления пакетных данных и данных в реальном времени, принимает последнее время выполнения пакета в качестве границы, объединяет два данных и предоставляет окончательный результат вывода во внешний мир.
Выбор компонентов
Трехуровневая иерархия архитектуры Lambda — это всего лишь архитектурная идея.,Мы можем в соответствии с потребностями бизнеса,Выберите, какие компоненты использовать для каждого слоя.,Постройте большую Обработку система запросов данных. На рисунке ниже представлен выбор системы запросов пользователей Meituan. компонентов(вCellerЭто собственная разработка Meituan.KVхранилищесистема,На основе LevelDB,Squrrel основан на Redis)
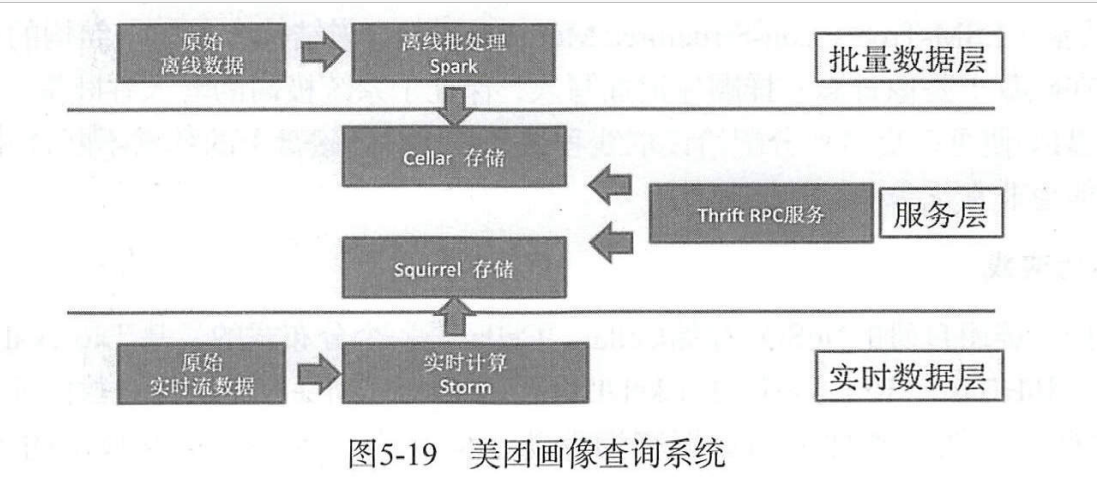
Выбор хранилища
1. Выбор оборудования
Как правило, случайное чтение памяти занимает десятки наносекунд, случайное чтение жесткого диска SSD — десятки микросекунд, а случайное чтение механического диска SATA — десятки миллисекунд. Но и цена обратно пропорциональна. Память стоит дорого. Жесткие диски SSD и механические диски SATA, производительность первых на три порядка выше, чем вторых, но цена лишь примерно в два раза дороже. Поэтому выбор SSD более экономичен.
2.SQL или NoSQL
Существует множество вариантов компонентов хранения данных на основе жесткого диска. Давайте сначала посмотрим, стоит ли выбирать традиционное семейство SQL или присоединиться к лагерю NoSQL, популярному в эпоху больших данных.
Традиционная реляционная база данных SQL (RDBMS) имеет очень развитую и стабильную поддержку хранения структурированных, неразреженных данных, а поддержка блокировок и транзакций делает ее идеальной для ACID данных (атомарность, согласованность, изоляция, изоляция); , персистентность) характеристики широко используются в сценариях с высокими требованиями. Однако данные портрета пользователя не предъявляют строгих требований к согласованности данных и имеют высокую устойчивость к некорректному чтению данных. Более того, разреженная структура данных также делает традиционные реляционные базы данных неспособными удовлетворить требования гибкости и масштабируемости.
Напротив, многие компоненты в лагере NoSQL очень подходят для сценариев портретных запросов. Будь то HBase, Riak или Tair, его формат хранения основан на структуре LSM-Tree (дерево слияния с журнальной структурой), поэтому операции записи последовательно добавляются на диск, как журнал, гарантируя, что система имеет чрезвычайно высокую скорость записи. пропускная способность. В то же время большая часть сохраненного дискового ввода-вывода может быть выделена для использования потоками чтения, а данные на диске постоянно объединяются в упорядоченную структуру, что обеспечивает очень хорошую производительность запросов.
3. Практика
Meituan имеет собственное хранилище NoSQL Cellar. Cellar — это распределенная двухъядерная база данных, основанная на RocksDB+MDB. Подобно HBase.Riak, RocksDB также сохраняет данные на основе структуры хранения LSM-Tree, которая обеспечивает высокую производительность записи данных и производительность запросов данных. В то же время Cellar также представляет механизм полного хранения данных MDB для хранения горячих данных.
В реальном процессе применения, чтобы еще больше повысить пропускную способность и экстремальную нагрузочную способность системы, в ходе стресс-тестирования мы обнаружили, что если производительность всего кластера хранения достигает предела, то это происходит потому, что чтение данных в реальном времени Представление в трехуровневой архитектуре Lambda первым достигает узкого места. Это связано с тем, что охват представления данных в реальном времени очень низок (короткий промежуток времени), что приводит к тому, что большое количество запросов не попадает в MDB и, таким образом, не проникает в кеш для доступа к дисковым данным RocksDB. Доступ к диску, очевидно, с большей вероятностью достигнет узкого места. Чтобы решить эту проблему, Meituan представила Squirrel для хранения представлений данных в реальном времени. Squirrel — это решение для кластеризации на основе Redis, разработанное Meituan. Все данные хранятся в памяти и могут достигать чрезвычайно высокой пропускной способности независимо от частоты обращений.
4. Гарантия надежности
Портрет пользователя — это базовый сервис данных, который часто находится в самом низу цепочки фоновых вызовов, поэтому требования к его надежности очень высоки. Meituan приняла такие меры, как мультиактивное резервное копирование IDC, поддержку автоматических выключателей зависимости и несколько стратегий перехода на более раннюю версию.
Система анализа портретов толпы
Как было сказано выше, в дополнение к запросу Приложение для создания портретов пользователей, еще один тип приложения — портрет толпы. Система анализа портретов Исследование толпы направлено на соответствие условиям маркировки на основе портретов пользователей.,Поиск подходящих групп пользователей среди большого количества пользователей,и необходимость совокупного статистического анализа ярлыков этой группы людей,Может широко использоваться при анализе данных,целевой маркетинг,Таргетированный пуш и другие сервисы.
Проектирование системы
Самый интуитивно понятный способ поиска людей по условиям тегов — сканировать всех пользователей. Этот неэффективный, но наиболее интуитивно понятный метод может быть реализован на основе мощных возможностей пакетных вычислений платформы пакетной обработки Hadoop/Spark. Но он не может удовлетворить толпу поисковиков в реальном времени за считанные секунды.
поиск в реальном времени
Как повысить эффективность поиска? В частности, особенно важны такие проблемы, как проверка пользователей на основе их атрибутов и вопросы эффективности. Чтобы решить эту проблему, пришло время инвертированному индексу проявить свои таланты.
Инвертированный индекс возникает из-за необходимости поиска записей на основе значений атрибутов в практических приложениях. Каждая запись в такой индексной таблице включает значение атрибута и адрес каждой записи с этим значением атрибута. Этот тип индекса называется инвертированным индексом, поскольку значение атрибута не определяется записью, а местоположение записи определяется значением атрибута.
Elasticsearch — это поисковая система с открытым исходным кодом, основанная на Apache Lucene и имеющая следующие функции:
Распределенное хранилище файлов в режиме реального времени, где каждое поле индексируется и доступно для поиска.
Распределенная поисковая система анализа в реальном времени
Может масштабироваться до сотен серверов для обработки петабайт структурированных или неструктурированных данных.
Elasticsearch полностью поддерживает экосистему больших данных. С помощью компонента Spark2ES данные меток можно легко загружать в кластер Elasticsearch пакетами для построения индексов. Meituan также выполнила итеративную оптимизацию в различных аспектах, таких как данные меток, количество узлов Elasticsearch, количество сегментов и методы индексации, исходя из реальной ситуации.
Онлайн-заявка
Портреты пользователей широко используются в Meituan как наиболее важная базовая конструкция данных. Ниже представлена общая ситуация применения в каждом сценарии.

К основным применениям портретов пользователей относятся: бизнес-анализ, точный маркетинг, персонализированные рекомендации и т. д.
1. Бизнес-анализ
После того, как данные тегов системы портретов пользователей поступают в систему анализа через API, они могут расширять измерения данных анализа и поддерживать бизнес-анализ нескольких бизнес-объектов.
Ниже приведены некоторые показатели, на которые рыночный, операционный и продуктовый персонал будут обращать внимание при анализе:
1) Анализ трафика
источник трафика;
Количество потока: УФ, PV;
Качество трафика: глубина просмотра (UV, PV), продолжительность пребывания, конверсия источника, рентабельность инвестиций (возврат инвестиций, возврат инвестиций);
2) Анализ пользователей
Количество пользователей: количество новых пользователей, количество старых пользователей, соотношение новых/старых пользователей;
Качество пользователя: количество новых пользователей (запуск приложения), количество активных пользователей (запуск приложения), удержание пользователей (запуск приложения - запуск приложения), вовлеченность пользователей, сонливость, цена за единицу клиента;
3) Анализ продукта
Продажи продукта: GMV, цена за единицу, количество заказов, количество отмен, количество возвратов, доля повторных покупок на каждом конце, распределение частоты покупок, конверсия покупок на месте эксплуатации;
Категории продуктов: статус платежного поручения (количество раз, количество людей, тенденции, обратные покупки), посещения покупок, заявки на возврат, отмена заказов, внимание/;
4) Анализ заказа
Показатели заказа: общий объем заказа, объем возвращенного заказа, сумма к оплате заказа, фактическая сумма оплаты заказа, количество человек, разместивших заказы;
Индикаторы конверсии: новый заказ/UV посещения, эффективный заказ/UV посещения;
5) Анализ каналов
Пользователь активен:
Активные пользователи: УФ, PV
Новые пользователи: количество регистраций, количество регистраций по сравнению с прошлым годом.
Пользовательское качество:
Удержание: коэффициент удержания на следующий/7/30-й день.
Доход канала:
Заказы: объем заказа, средний дневной объем заказа, заказы за год.
Доход: сумма платежа, средняя дневная сумма платежа, сумма в годовом исчислении.
Пользователи: объем заказа на душу населения, сумма заказа на душу населения.
6) Анализ продукта
Функция поиска: количество поисков/количество поисков, уровень проникновения функции поиска, ключевые слова поиска;
Анализ функционального дизайна продукта, такой как воронка критического пути;
2. Точный маркетинг
1) SMS/электронная почта/push-маркетинг
В нашей повседневной жизни мы часто получаем маркетинговую информацию из многих каналов: SMS-сообщение о прибытии красного конверта может побудить пользователей открыть приложение, которое они давно не посещали, а сообщение электронной почты о снижении цен на книги. в своем списке желаний может побудить пользователей открыть push-ссылку и разместить заказ напрямую.
Какие конкретные виды маркетинговых методов существуют?
Условно его можно разделить на следующие 4 категории:
На основе поведенческого маркетинга: просмотр товара, добавление в корзину, сканирование кода магазина, отмена заказа, возврат заказа и т. д.;
Маркетинг, основанный на местоположении: близлежащие магазины, близлежащие мероприятия, часто посещаемые места и т. д.;
Фестивальный маркетинг: дни рождения, праздник весны, Double Eleven, Double Twelve, Рождество и т. д.;
Маркетинг на основе участников: приветствие к присоединению, напоминания о картах и купонах, изменение баллов, изменение уровней, преимущества для участников и т. д.;
2) Навыки обслуживания клиентов.
Когда мы жалуемся, консультируемся или оставляем отзыв в отдел обслуживания клиентов определенной платформы, сотрудники службы поддержки могут точно рассказать нам о наших покупках на платформе, результатах последней консультации и другой информации, а также предоставить целевые решения. пользователям предоставляются специальные услуги, такие как каналы обслуживания VIP-клиентов.
3. Персонализированные рекомендации и услуги.
Операторы приложений могут рекомендовать пользователям различный контент с учетом пола, возрастной группы, хобби, поведения при просмотре и покупках, а также других тегов в личных портретах пользователей в твитах, таких как персонализированные рекомендации по содержанию статей на Toutiao, рекомендации пользователей на Douyin и т. д. Персонализированный видеоконтент; рекомендации на основе портретов, персонализированные рекомендации по продуктам на Taobao на основе поведения пользователей в Интернете и других портретных данных и т. д.
ссылка:



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
