Попытка объединить отчеты о покрытии кода Jacoco с использованием большой модели.
prompt
Недавно я научился писать подсказки с помощью псевдодо, но у меня не было возможности попробовать это. Недавно я обсуждал объединение покрытия Jacoco, поэтому хотел попробовать это с большой моделью. :
You major at merge cover report by jacoco.Both reports are for different versions of the same project.
Ваша основная задача — объединить отчеты о покрытии кода, созданные Jacoco. Оба отчета предназначены для разных версий кода одного и того же проекта. Эти два файла соответствуют файлам двух входных отчетов report1 и report2.
Вот код о том, как это сделать:
def same_line_fc(report1,report2):
# report2 is nearly cover report
# comparte two coverage reports.You find line number of the same line that the the html class is nc in report2 and fc in report1.
# the line number of report2 append to a list
# the same line is the same java code,not the line number.
#the line number append to a list
def merge_coverage_reports(report1, report2):
# Merge two coverage reports
same_list_number = same_line_fc(report1, report2)
# change report2's html the line in the same_list_number html class to fc.And return the new report2
print(merge_coverage_reports(report1, report2))
Большой отзыв о модели
Я загрузил два HTML-файла в большую модель, а затем использовал приведенную выше команду prmopt, чтобы получить окончательный результат. Фактически, для каждого слияния требуется большая модель, а стоимость очень высока. Но чего я не ожидал, так это того, что большая модель вместо результата напрямую выдала мне код обработки.
from bs4 import BeautifulSoup
def same_line_fc(report1_content, report2_content):
soup1 = BeautifulSoup(report1_content, 'html.parser')
soup2 = BeautifulSoup(report2_content, 'html.parser')
# Получить все строки
lines1 = soup1.find_all('span', class_='fc')
lines2 = soup2.find_all('span', class_='nc')
same_line_numbers = []
# Создайте словарь для сохранения каждой строки кода и соответствующего номера строки.
lines_dict1 = {line.get_text(): line['id'] for line in lines1}
lines_dict2 = {line.get_text(): line['id'] for line in lines2}
# Найдите строку fc в отчете1 и nc в отчете2.
for code_line, line_id in lines_dict1.items():
if code_line in lines_dict2:
same_line_numbers.append(lines_dict2[code_line].replace('L', ''))
return same_line_numbers
def merge_coverage_reports(report1_content, report2_content):
same_list_number = same_line_fc(report1_content, report2_content)
soup2 = BeautifulSoup(report2_content, 'html.parser')
# Измените класс соответствующей строки в отчете2.
for line_number in same_list_number:
line_span = soup2.find('span', id=f'L{line_number}')
if line_span:
line_span['class'] = 'fc'
return str(soup2)
# Чтение содержимого HTML-файла
with open('./to/report1.html', 'r', encoding='utf-8') as file1:
report1_content = file1.read()
with open('./to/report2.html', 'r', encoding='utf-8') as file2:
report2_content = file2.read()
# Консолидированная отчетность
merged_report_content = merge_coverage_reports(report1_content, report2_content)
# Вывод объединенного отчета
output_path = './to/merged_report.html'
with open(output_path, 'w', encoding='utf-8') as file_out:
file_out.write(merged_report_content)
print(f"Merged report saved to {output_path}")
Я просто использовал его, не изменяя список случаев, и результат оказался на удивление хорошим.
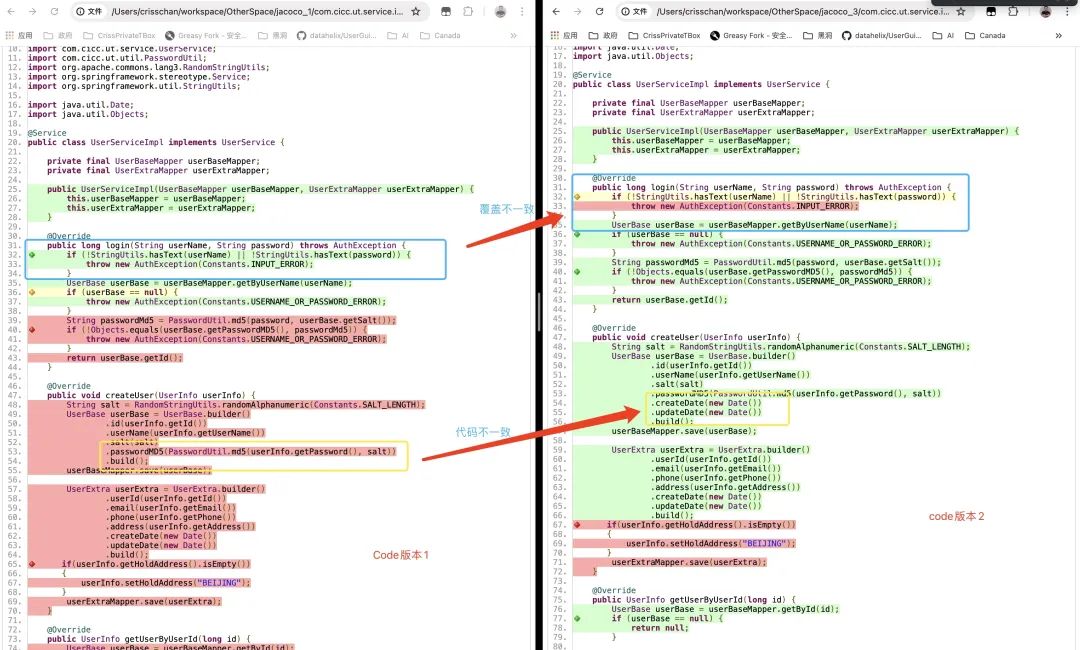
Объединенный скриншот выглядит следующим образом:

особое внимание
На самом деле, описанное выше слияние не является научным в соответствии с принципом решения Жакоко. Некоторые коды, которые имеют красный цвет до слияния и зеленый после слияния, не обязательно являются разумными и правильными. Это может быть просто визуальное слияние, а не реальное. объединение Code Coverage, использование больших моделей открыло для меня новые идеи.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
