Попрощайтесь с Zookeeper, используйте две команды для контейнеризации Kafka
Предисловие
При обработке больших данных в режиме реального времени, будь то с использованием Spark или Flink, взаимодействие данных с другими компонентами должно иметь смысл. Во всей обработке потока данных производительность интерактивных компонентов определяет эффективность обработки данных. Например, при взаимодействии с промежуточным программным обеспечением кэша Redis слишком высокий QPS приведет к слишком медленному отклику, что проявится в общей задержке обработки данных. программа.
Обеспечение производительности компонентов стало главным приоритетом, поэтому при выборе компонентов мы будем использовать их проверенные показатели производительности в качестве ориентира. При потоковой обработке больших данных в реальном времени Kafka является наиболее часто используемым компонентом источника данных. Его механизм секционирования улучшает параллелизм, а механизм копирования обеспечивает высокую доступность данных.
Кроме того, нулевое копирование, последовательное чтение и запись на диск, а также индексирование файлов данных значительно повысили производительность Kafka. По мере изменения версий Kafka Kafka выросла до такой степени, что больше не использует Zookeeper для управления метаданными и контроля узлов. Поэтому сегодня я буду следовать официальной документации, использовать версию Kafka 3.7.0 и использовать Docker для сборки Kafka на облачном сервере.
Зеркало Кафки
Используйте docker для сборки kafka, не нужно учитывать платформу и среду, просто используйте docker pull, чтобы напрямую получить образ. В официальной документации также приведены команды.

1. Вытащите изображение
Выполните команду, чтобы получить образ Кафки.
docker pull apache/kafka:3.7.0Извлечение не удалось, что привело к ошибке «отсутствует ключ подписи». Сначала я подумал, что это проблема со хранилищем образов, но позже обнаружил, что версия докера на облачном хосте слишком старая.
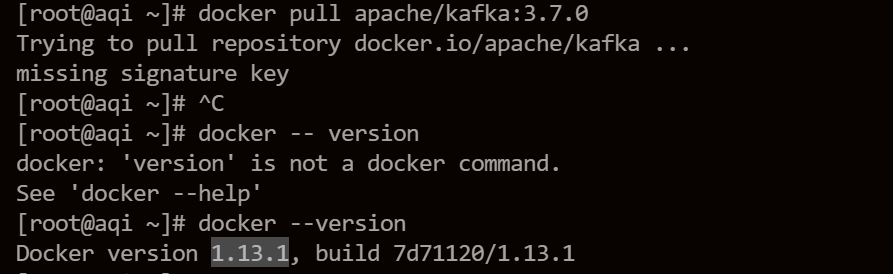
Используйте docker --version, чтобы убедиться, что текущая версия docker — 1.13.1, поэтому удалите docker и переустановите его.
yum -y remove docker docker-client docker-client-latest docker-common docker-latest docker-latest-logrotate docker-logrotate docker-engineВыполните приведенную выше команду, чтобы удалить пакеты и зависимости, связанные с Docker.
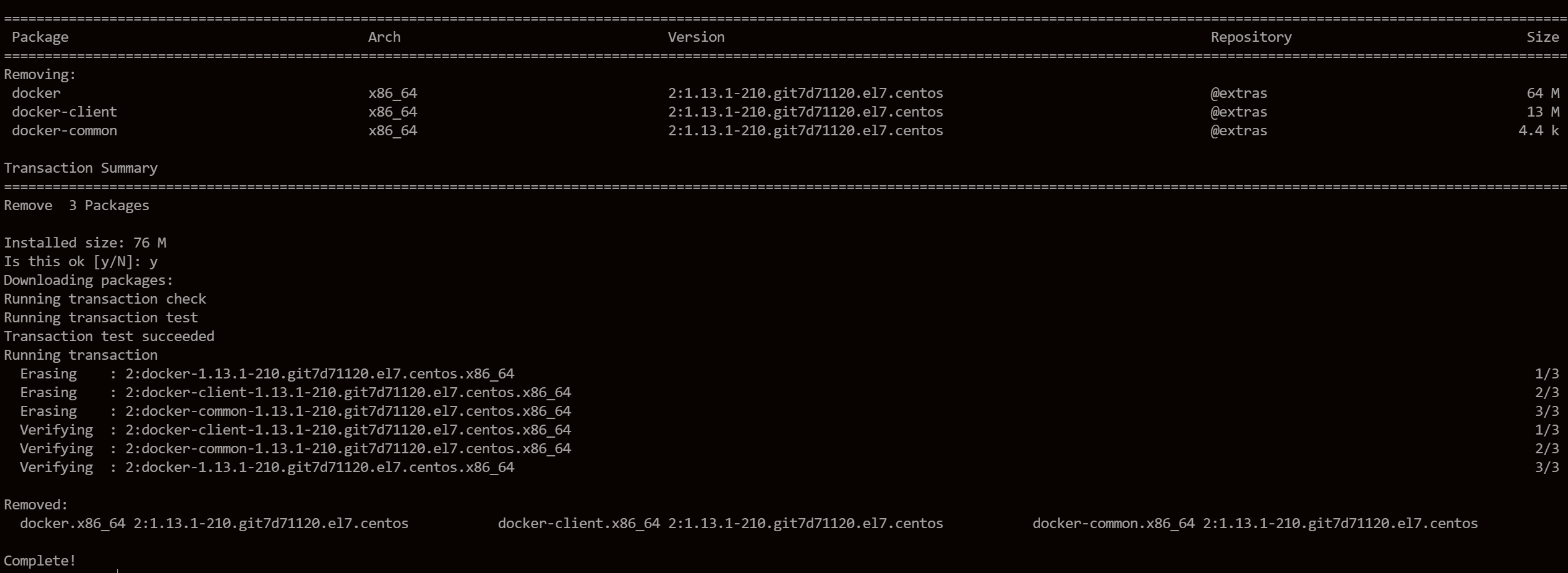
После завершения удаления переустанавливаем новую версию докера.
yum install -y yum-utils
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum install -y docker-ce docker-ce-cli containerd.io
systemctl restart dockerДобавьте источник docker-ce yum, установите docker-ce и перезапустите службу docker. Когда мы снова проверяем версию докера, она стала 26.1.4.

Затем мы снова успешно извлекли изображение.
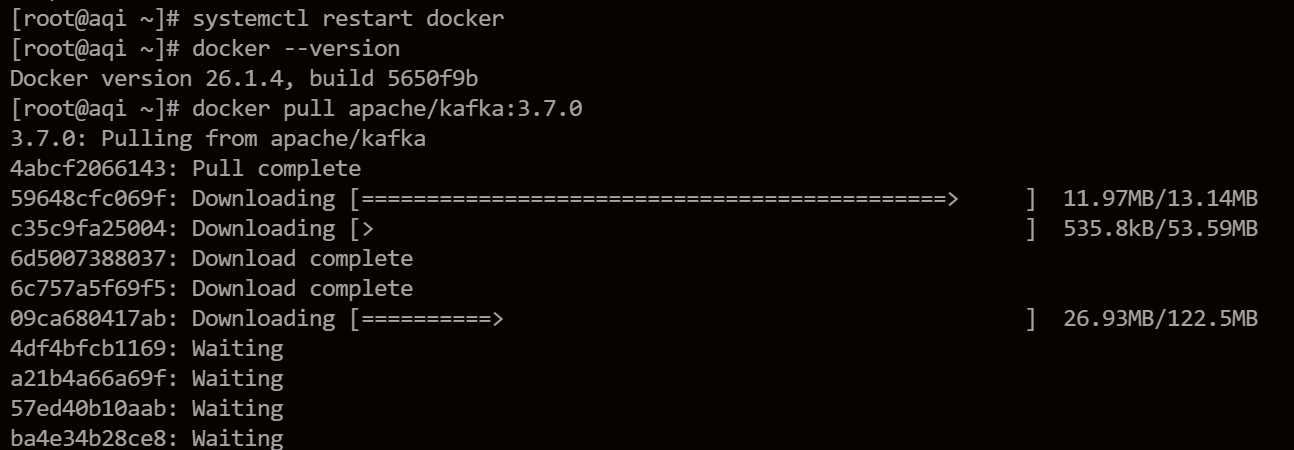
2. Запустите контейнер
Далее мы можем использовать только что полученное изображение для запуска контейнера Kafka.
docker run -d --name kafka -p 9092:9092 apache/kafka:3.7.0Проверьте журнал запуска:
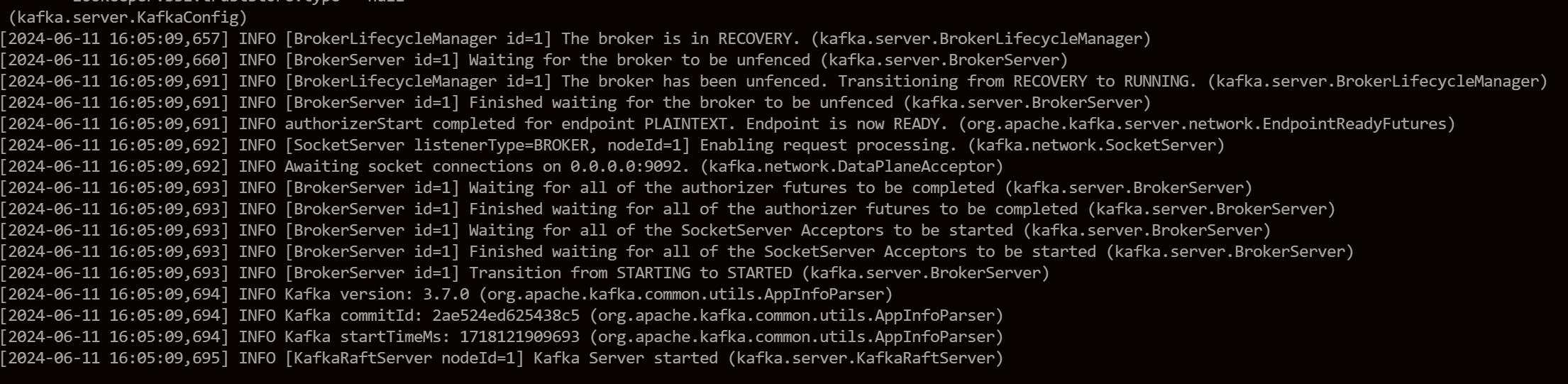
Таким образом создается новый контейнер Kafka, а также у нас есть одноузловая Kafka. Из журнала нетрудно увидеть, что в контейнере Kafka не запускается Zookeeper, а есть KafkaRaftServer (аббревиатура: KRaft). KRaft заменяет Zookeeper и запускается на узле Kafka.
В настоящее время Kafka предоставляет два метода запуска: KRaft и Zookeeper, и существуют различия как в конфигурации server.properties, так и в методе запуска кластера. Это будет обсуждаться позже при построении кластера. Здесь мы можем увидеть процесс контейнера Kafka.

клиент Кафки
Теперь, когда брокерская служба Kafka работает в Docker, и если мы хотим подключиться к этой Kafka в Linux, нам понадобятся некоторые команды Kafka. Итак, нам нужно загрузить установочный пакет Kafka. После его распаковки в каталоге bin мы найдем ряд команд Kafka для управления Kafka.
Фактически, наиболее часто используемыйkafka-topic.sh、kafka-console-consumer.sh、kafka-console.producer.shЭти три команды,соответствующий соответственноtopicуправлять、Потребление、Произведите три операции.
1. Создать тему
В Kafka данные хранятся в темах, поэтому нам необходимо создать темы. Перед созданием мы можем проверить, есть ли темы в кластере Kafka.
# Посмотреть тему
kafka-topics.sh --bootstrap-server localhost:9092 --list
# Создать тему
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic aqi_test --partitions 10 --replication-factor 1Создайте файл с именемaqi_testизtopic,Разделов установлено на 10.,Реплика установлена на 1.
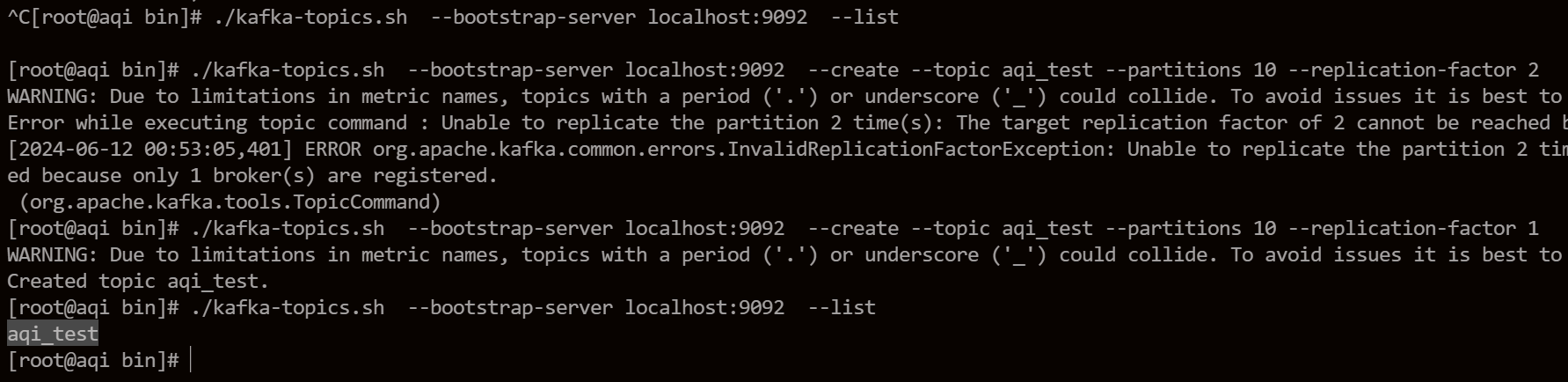
Поскольку существует только один узел брокера Kafka, когда я впервые устанавливаю реплику на 2, будет сообщено об ошибке.
2. Производственные данные
мы используемkafka-console-producerКaqi_testэтотtopicсерединапроизводственные данные。
kafka-console-producer.sh --topic aqi_test --bootstrap-server localhost:9092Эта командная строка запустит интерактивный сеанс. После того, как мы введем строку данных, мы запишем ее в тему с помощью возврата каретки и перевода строки.

Как показано на рисунке, мы записали всего четыре фрагмента данных.
3. Данные о потреблении
использоватьkafka-console-consumeПотреблениеtopicсерединапродюсер пишетизданные。
kafka-console-consumer.sh --topic aqi_test --bootstrap-server localhost:9092 --from-beginningВ механизме потребления в Kafka, если при потреблении не указана специальная конфигурация, потребитель может использовать только самые последние данные. Другими словами, потребитель может использовать данные только после запуска потребителя.
Хотетьиспользоватьfrom-beginning,или в Потреблениеили конфигурациясерединаобозначениеearliestПотребление Стратегия。

Как показано на рисунке, мы использовали четыре фрагмента данных, записанные ранее.
Заключение
Это я использую докера Создайте один узел на облачном сервереKafkaизпроцесс。А потому что это облачный сервер,нуждатьсяиспользоватьЭластичный публичный IP-адреспосетить,И официальное изображениесерединаизadvertised.listenersВнешняя трансляцияиз Адрес
localhost, поэтому я не могу получить доступ к этим данным Kafka на своем ноутбуке.
Само собой разумеется, что вы можете войти в контейнер Kafka через docker exec и изменить Advertised.listeners в server.properties. Однако этот файл имеет разрешения только для чтения и не может быть изменен. Поэтому следующая статья в основном будет решать проблему недоступности из внешней сети.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
