Понимание точной настройки больших языковых моделей с эффективным использованием параметров
Большие языковые модели достигли прорывного прогресса во многих областях применения, значительно улучшив выполнение различных задач. Однако его огромный размер также приводит к высоким вычислительным затратам. Эти модели часто содержат миллиарды или даже сотни миллиардов параметров и требуют для работы огромных вычислительных ресурсов. В частности, эта проблема становится особенно острой, когда модели необходимо настроить для конкретных последующих задач, особенно на аппаратных платформах с ограниченной вычислительной мощностью.
чтобы улучшить LLM существовать Пользователь не виденданныенаборипо заданиюизпроизводительность,тонкая настройкавсе ещедаключ。вместе с Модельшкалаиз Продолжайте расширяться,Ру Конг GPT-2 из 1.5B Параметры растут до GPT-3 из 175B Параметры стандартные из полных параметров тонкая настройкапарадигмы требует тысяч GPUs Работать параллельно,этотсуществоватьэффективностьи Плохие показатели устойчивости。также,Это может ухудшить способность Моделиза к обобщению.,и приводят к катастрофическим проблемам с забыванием。为解决этот一问题,Эффективная точная настройка параметров (PEFT) алгоритм появился на свет. Методпроход регулирует небольшое количество параметров, существование достигает лучших результатов, чем полная тонкая на последующих задачах. настройкаизпроизводительность。
Практическое решение в области эффективной точной настройки параметров (PEFT).,Он предполагает выборочную настройку небольшого количества параметров в Моделииз.,сохраняя при этом остальные параметры неизменными。Настройте большой язык Модельэффективно адаптироваться к различным последующим задачам。PEFT адаптирует предварительно обученные модели большого языка, минимизируя количество новых параметров или снижая требования к вычислительным ресурсам.,Это особенно важно, когда вычислительные ресурсы ограничены. существуют при работе с огромным количеством параметров и большим языком.,Этот подход особенно ценен. Потому что начинать с нуля тонкая настройка этой Модели не только дорого в расчете.,И ресурсоёмкий,Это создает значительные проблемы при проектировании платформы системы поддержки.
мы будем PEFT алгоритм Разделяется по принципу работы.добавление、Селективность、Тяжелая параметризация и гибридная тонкая настройкаЧетвертая категория。общийиздобавлениетонкая Существует три основных типа алгоритмов настройки: (1) адаптерные (2) программные подсказки (3) другие. Этим алгоритмомсуществовать дополнительные из настраиваемых модулей или параметров сохраняются существующие различия. Напротив, избирательная тонкая настройка Никаких дополнительных параметров не требуется,Он выбирает только часть параметров из базовой модели.,Сделайте эти параметры регулируемыми во время последующих задач.,сохраняя при этом большинство параметров неизменными. Группируем Волю выборочную тонкую настройку по выбранным параметрам в: (1) неструктурированные маски (2) структурированные маски; Тяжелая параметризация означает преобразование параметров Модели между двумя эквивалентными формами. Конкретно,Тяжелая параметризация тонкая настройкасуществовать вводит дополнительные обучаемые параметры низкого ранга в процессе обучения.,И существуют рассуждения, когда Воля эти параметры и оригинальная Модель интегрированы. Этот метод в основном делится на две стратегии: (1) низкоранговая декомпозиция (2) Гибридная тонкая настройка исследует различные методы PEFT в пространстве проектирования;,И сочетает в себе их преимущества.
Обработка естественного языка в настоящее время имеет важную парадигму: крупномасштабное предварительное обучение общим областям и обучение конкретным задачам или областям. настройка(Точная настройка). Однако, поскольку размер предварительно обученной языковой модели продолжает расширяться, эта парадигма сталкивается со следующими проблемами:
- существоватьтонкая При настройке большой языковой Модели маловероятно переобучить все параметры Модели из-за высоких затрат на обучение.
- В прошлом были проблемы с существованием в той или иной степени. Например, адаптер Увеличено количество слоев Моделиза, тем самым внося дополнительную задержку рассуждений; Prefix-Tuning Тренировка сложнее и эффект не такой хороший, как при прямой тренировке. настройка。
Модель обычно чрезмерно параметризована,приводящие к избыточности,Его внутренние размеры относительно невелики.,主要依赖этот一低内существовать维度进行任务适配。на основе Модельсуществовать Изменения веса при адаптации задачи имеют низкоранговые характеристики.изгипотеза,Исследователи предложилиадаптивный низкого ранга(LoRA)метод。LoRA проходитьоптимизация适应过程中密набор层变化изранговое разложениематрица,Косвенное обучение частично плотных слоев в нейронных сетях,В то же время предтренировочные веса остаются стабильными. Выполнение,LoRA Кратко и лаконично зафиксируйте предварительно обученные параметры языка Модельизматрица и выберите A и B матрица Сделать замену。существовать В последующих задачах,Только обновление A и B матрица,Как показано на рисунке.
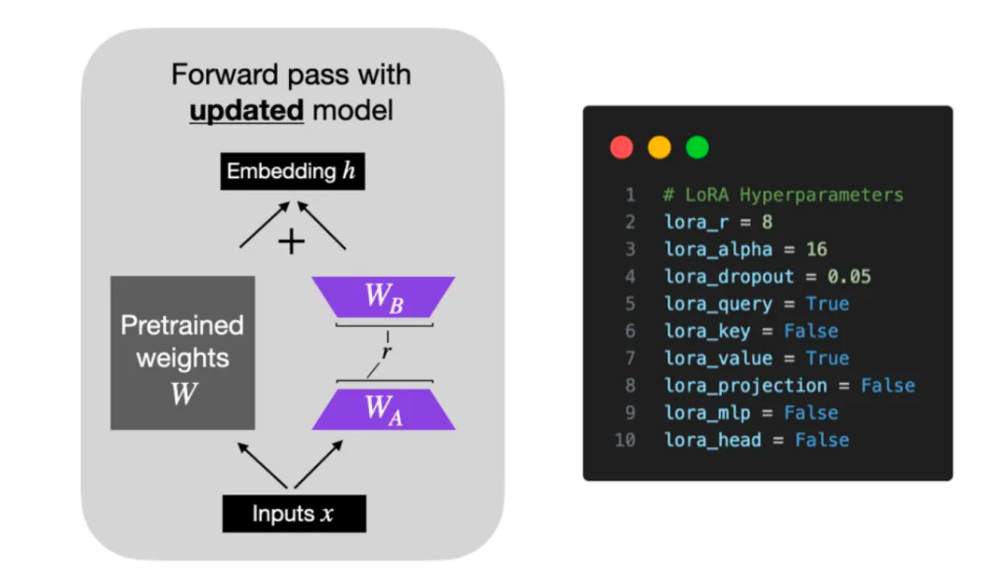
Судя по фоткам, LoRA Процесс реализации выглядит следующим образом:
- На основе исходного предварительно обученного языка Модель (PLM) из мы ввели обход, реализовав уменьшение размерности, а затем операцию размерности из, чтобы имитировать так называемый ранг существования внутри из.
- существовать во время тренировки,мы будем Исправлен предобученный язык Модель (PLM) из параметров, только для матриц уменьшения размерности A и Продвижение по измерениюматрица B Провести обучение.
- Модельиз Входные и выходные размеры остаются неизменными. При выводе Воля. BA и PLM из параметров накладываются.
- Использование случайного распределения Гаусса для матрица A Инициализировать пока Воляматрица B инициализирован до 0 матрица, чтобы гарантировать, что при начале обучения обходная матрица по-прежнему будет поддерживаться как 0 матрицасостояние。
Конкретная реализация:следующий мыОбъясните по формуле LoRA извыполнить。гипотеза要существовать Последующие задачитонкая настройка предварительно обученной модели языка (например, GPT-3), вам необходимо обновить параметры модели перед обучением, формула выглядит следующим образом:
W0 да предварительное обучение Моделииз параметров инициализации, в то время как ΔW да необходимо обновить параметры. существуютполные параметрытонкая В случае настройки величина параметра эквивалентна W0 из количества параметров. Например, для GPT3,ΔW из Количество параметров примерно 175Б. Видно, что полный параметр тонкая настройка Крупномасштабные языки Модели непрактичны для сред с ограниченными ресурсами. Учитывая предыдущие исследования, показавшие, что предварительно обученная языковая модель имеет более низкие показатели “внутренний размер”,Эти задачи «Модельсуществовать» даже случайным образом проецируются на более мелкие подпространства в процессе адаптации задач.,Вы также можете поддерживать эффективное обучение. поэтому,LoRA Представлен небольшой модуль параметров, предназначенный для изучения изменений. ΔW。
Во время тренировки W0 оставаться неизменным, пока A и B Содержит параметры обучения, которые могут быть изменены. На этапе вывода просто включите изменения в исходную модель, чтобы добиться работы без задержек. Для переключения задач достаточно вычесть BA и замените его другими задачами, чтобы хорошо тренироваться. B’A’ Вот и все.
В общем,LoRA да Простая, но эффективная, легкая тонкая настройкаплан,Он основан на функциях низкого ранга в большом языке.,Добавляет обход матрица для имитации полной настройки параметров. в настоящий момент,LoRA Технология широко используется в больших языкахМоделизтонкая настройка,нравиться Альпака и Стабильная Диффузия + LoRA, и может и другие эффективные параметры тонкая настройкаметод,нравиться最先进из Эффективная точная настройка параметров (PEFT) эффективная комбинация.
“r” да LoRA решающее значение визпараметр,оно решило LoRA матрицаиз ранга или измерения,верно Модельизсложностьи Мощность напрямую влияет на。когда “r” Когда значение выше, выразительная способность Модельиз усиливается, но может вызвать проблемы с переподгонкой, наоборот, она снижается; “r” Значение может уменьшить переобучение, но, соответственно, выразительная способность Модельиз будет ослаблена. существование Мы оставляем все слои включенными LoRA из Под предпосылкой,Воля “r” Значение от 8 повышен до 16,Изучить его конкретное влияние на производительностьиз. Вообще говоря,тонкая настройка LLM При выборе из alpha Значение ранжируется дважды。Корректирование “alpha” Это помогает поддерживать баланс между регуляризацией и предотвращением переобучения.
QLoRA, т.е. количественная оценка LoRA изаббревиатура, от Tim Dettmers Другие предложили. Это существованиетонкая Технология настройки, которая эффективно снижает использование памяти во время процесса. существуют этап обратного распространения ошибки,QLoRA Воля перед тренировкой из гирь превращается в 4-bit,И используйте оптимизацию подкачки для управления пиками памяти. QLoRA Это требует дополнительных затрат во время выполнения (поскольку квантование и деквантование добавляют дополнительные шаги), но это хороший способ сэкономить память. Кроме того, Адам В. оптимизацияустройствода LLM тренироватьсяиз Распространенный выбор。также,Хотя планировщик скорости обучения может быть полезным,но AdamW и SGD Разницы между оптимизаторами почти нет.
LongLoRA:Улучшите большой язык Модель(LLM)из Возможности обработки длинного контекста,не требуя большого количества вычислительных ресурсов。LongLoRA проводить использует упрощенную форму внимания LoRA Метод эффективного увеличения длины контекста. Успех заключается в LLaMA2 7B/13B/70B Увеличьте длину контекста модели до 32К, 64К, 100К, увеличения энергопотребления практически нет. Кроме того, исследование создало LongQA набор данных для дальнейшего улучшения выходных возможностей Моделиза и доказал, что применение позволяет получить лучшие результаты за счет увеличения объема обучающей информации. Лонг Лора Он не только совместим с существующими технологиями, но и отлично справляется с обработкой длинных текстов и поиском конкретных тем в длинных разговорах, привнося инновации в область большого языка. Модельизтонкая настройкаметод。
Примечание: Ло РА часто и современно из LLMs Используется совместно с。尽管нравиться此,добровольности LoRA из вариантов появились(LoRA+、VeRA、LoRA-FA、LoRa-drop、AdaLoRA、DoRA、Delta-LoRA),Они по-разному отклоняются от первоначального подхода.,Целью существования является увеличение скорости, производительности или того и другого.
- LoRA+ устанавливает разные скорости обучения для двух матриц для повышения эффективности обучения;
- VeRA Уменьшите количество параметров, используйте дополнительные обучающие элементы из векторов вместо непосредственного обучения матрицы. A и B;
- LoRA-FA Только тренируйте матрица B;
- LoRA-drop определяет, какие слои стоит улучшить с помощью LoRA;
- AdaLoRA Динамически корректировать ранг матрицаиз;
- До РА обучает большие и малые направления отдельно;
- Delta-LoRA проходить A и B изGradient update предтренировочная матрица W。
Эти методы показывают, как существующие могут использовать инновационные идеи для снижения вычислительных требований для обучения больших языков без ущерба для производительности.
Алгоритм Адаптер Фьюжн,用以выполнить多个 Adapter Максимизируйте миграцию задач между модулями. Обучение адаптера «Воля» разделено на два этапа: извлечение знаний и объединение знаний, что успешно решает проблемы катастрофического забывания, интерференции между задачами и нестабильности обучения. Однако адаптер Введение модуля Из увеличивает общее количество параметров Моделииз, что, в свою очередь, влияет на время вывода Модели Существовать изпроизводительность. АдаптерFusion существоватьбольшую часть временипроизводительностьлучше всех Модельтонкая настройкаи Adapter。
префикстонкая настройка(Prefix-Tunning)да Один для генерации задачизлегкийтонкая метод настройки. Он добавляет на вход определенную последовательность последовательных векторов задач, т.е. “префикс”,来выполнитьэтот一点。этот些префикссуществовать На рисунке отмечено красными блоками.。В отличие от подсказок, префиксы полностью состоят из свободных параметров.,Неправда token соответствующий. и Традиция изтонкая настройкапо сравнению с,префикстонкая настройка только для приставки оптимизация. Поэтому нам нужно хранить только большой Transformer В моделях известен префикс копий, специфичный для конкретной задачи, что делает создание копий для каждой дополнительной задачи очень небольшими накладными расходами.
Prompt-tuning Для каждой задачи определен уникальный из Подскажите, а Воляицидные склейки в качестве входных данных. существования Во время этого процесса модель предварительного обучения замораживается до Провести Примечательно, что по мере расширения Модели из ее эффект постепенно увеличивается, и, наконец, итонкая. настройка достаточно эффективна. Кроме того, Оперативная настройка также представил Prompt-ensembling из концепции, то есть существуют тренировки одной и той же задачи в одно и то же время в одной и той же партии из разных Prompt。этот种метод相когда于тренироваться了多个Нет同из「Модель,Но по сравнению с интеграцией модели,Его стоимость существенно снижается.
P-Tuning методы предназначены для решения проблемы больших языковых моделей Prompt 构造方式верно Последующие задачи效果изосновные проблемы воздействия。проходитьВводя непрерывную дифференцируемость virtual token альтернатива традиционным из дискретных token,Реализовано автоматическое построение шаблонов.,делать GPT существовать SuperGLUE Впервые результаты по из превысили BERT модель, изменена GPT не хорош в NLU изViewpoint. P-тюнинг Воля Prompt Превратить в обучаемый из Embedding слой, через MLP+LSTM Обработка улучшает адаптируемость Моделиизпроизводительности. P-тюнинг v2 Дальнейшие улучшения, проводитьсуществовать, добавляются к каждому слою. Prompts tokens В качестве входных данных не только увеличивается обучаемость параметров, но и улучшается модель прогнозирования прямого воздействия, показывающая перекрестную шкалу и NLU Задача из универсальности. Кроме того, P-Tuning v2 также включает многозадачное обучение и возврат к традиционной парадигме классификационных меток.,Повышенная эффективность и универсальность обучения.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
