Полный анализ чтения и записи файлов паркета с помощью Flink и Spark.
Введение в паркет
Parquet — это формат файлов с открытым исходным кодом для обработки плоских столбчатых форматов данных хранения, который может использоваться любым проектом в экосистеме Hadoop. Parquet хорошо работает с большими объемами сложных данных. Он известен своим высокопроизводительным сжатием данных и способностью обрабатывать различные типы кодирования. Apache Parquet разработан как эффективный и производительный формат хранения данных в виде плоских столбцов по сравнению с файлами на основе строк, такими как файлы CSV или TSV.
Parquet использует алгоритм уничтожения и сборки записей, который превосходит простое выравнивание вложенных пространств имен. Parquet оптимизирован для пакетной обработки сложных данных и имеет различные способы реализации эффективных типов сжатия и кодирования данных. Этот метод лучше всего подходит для запросов, которым необходимо прочитать определенные столбцы из большой таблицы. Parquet считывает только необходимые столбцы, что значительно снижает количество операций ввода-вывода. К преимуществам паркета можно отнести:
- Хранилища столбцов, такие как Apache Parquet, спроектированы так, чтобы быть более эффективными по сравнению с файлами на основе строк, такими как CSV. При запросе столбчатое хранилище может очень быстро пропускать ненужные данные. Таким образом, агрегированные запросы занимают меньше времени, чем базы данных, ориентированные на строки. Этот метод хранения привел к экономии оборудования и минимизации задержек при доступе к данным.
- Apache Parquet создан с нуля. Поэтому он может поддерживать расширенные вложенные структуры данных. Структура файлов данных Parquet оптимизирована для запросов, обрабатывающих большие объемы данных (гигабайтный диапазон на файл).
- Parquet предназначен для поддержки гибких вариантов сжатия и эффективных схем кодирования. Поскольку типы данных каждого столбца очень похожи, сжатие каждого столбца является простым (что ускоряет запросы). Данные можно сжимать с использованием одного из нескольких доступных кодеков, поэтому разные файлы данных можно сжимать по-разному.
- Apache Parquet лучше всего работает с интерактивными и бессерверными технологиями, такими как AWS Athena, Amazon Redshift Spectrum, Google BigQuery и Google Dataproc.
Разница между паркетом и CSV
CSV — это простой и широко используемый формат, используемый многими инструментами, такими как Excel, Google Sheets и многими другими инструментами, которые могут создавать файлы CSV. Несмотря на то, что файлы CSV являются форматом по умолчанию для конвейеров обработки данных, у него есть некоторые недостатки:
- Плата за Amazon Athena и Spectrum взимается в зависимости от объема данных, сканируемых за один запрос.
- Google и Amazon будут взимать плату в зависимости от объема данных, хранящихся на GS/S3.
- Плата за обработку данных Google зависит от времени.
Parquet помогает своим пользователям сократить требования к хранилищу для больших наборов данных как минимум на треть, кроме того, он значительно сокращает время сканирования и десериализации, тем самым снижая общие затраты.
SparkЧитай и пишиparquetдокумент
Spark SQL Поддерживает чтение и письмо Parquet файл автоматически фиксирует схему необработанных данных, а также снижает среднее значение 75% хранения данных. Spark Поддерживается по умолчанию в своей библиотеке Parquet,Поэтому нам не нужно добавлять какие-либо зависимые библиотеки.。Вот как пройтиsparkЧитай и пишиparquetдокумент.
В этой статье используется искра версии 3.0.3. Для входа в локальный режим выполните следующую команду:
bin/spark-shellЗапись данных
Сначала создайте DataFrame через Seq с именами столбцов «имя», «отчество», «фамилия», «доб», «пол», «зарплата».
val data = Seq(("James ","","Smith","36636","M",3000),
("Michael ","Rose","","40288","M",4000),
("Robert ","","Williams","42114","M",4000),
("Maria ","Anne","Jones","39192","F",4000),
("Jen","Mary","Brown","","F",-1))
val columns = Seq("firstname","middlename","lastname","dob","gender","salary")
import spark.sqlContext.implicits._
val df = data.toDF(columns:_*)Используя функцию parquet() класса DataFrameWriter, мы можем записать DataFrame Spark в файл Parquet. В этом примере мы записываем DataFrame в файл «people.parquet».
df.write.parquet("/tmp/output/people.parquet")Просмотр файлов

Чтение данных
val parqDF = spark.read.parquet("/tmp/output/people.parquet")
parqDF.createOrReplaceTempView("ParquetTable")
spark.sql("select * from ParquetTable where salary >= 4000").explain()
val parkSQL = spark.sql("select * from ParquetTable where salary >= 4000 ")
parkSQL.show()
Запись данных раздела
df.write.partitionBy("gender","salary").parquet("/tmp/output/people2.parquet")
val parqDF2 = spark.read.parquet("/tmp/output/people2.parquet")
parqDF2.createOrReplaceTempView("ParquetTable2")
val df3 = spark.sql("select * from ParquetTable2 where gender='M' and salary >= 4000")
df3.explain()
df3.printSchema()
df3.show()
val parqDF3 = spark.read.parquet("/tmp/output/people2.parquet/gender=M")
parqDF3.show()Получите следующие результаты

Flink читает и записывает файлы паркета
По умолчанию,Пакет Flink не содержит пакетов jar, связанных с паркетом.,Поэтому вам нужно скачать его для конкретной версии.flink-parquetдокумент.Эта статья основана наflink-1.13.3Например,Загрузите файл в каталог lib на flink.
cd lib/
wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-parquet_2.12/1.13.3/flink-sql-parquet_2.12-1.13.3.jarПрежде чем выполнять следующие тесты, запустите локальную среду автономного кластера flink.
bin/start-cluster.shВыполните следующую команду, чтобы войти в клиент Flink SQL.
bin/sql-client.shЧтение файлов паркета, написанных спарком
В предыдущем разделе мы записали данные о людях в файл паркета через Spark. Теперь мы создаем таблицу в Flink для чтения данных файла паркета, которые мы только что записали в Spark.
create table people (
firstname string,
middlename string,
lastname string,
dob string,
gender string,
salary int
) with (
'connector' = 'filesystem',
'path' = '/tmp/output/people.parquet',
'format' = 'parquet'
)
select * from people;Получите следующие результаты:


Используйте Flink для записи данных в файлы паркета.
Затем используйте flink для записи данных в только что созданную таблицу:
insert into people values('Tom', 'Mary', 'Ken', '21334', 'F', 5000);Просмотр результатов выполнения в пользовательском интерфейсе Flink

Запросите данные еще раз

Вы можете проверить недавно вставленные данные, которые мы только что вставили.
Ссылки:
- https://databricks.com/glossary/what-is-parquet
- https://sparkbyexamples.com/spark/spark-read-write-dataframe-parquet-example/
- https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/connectors/table/formats/parquet/
Эта статья является оригинальной статьей блоггера «xiaozhch5», работающего в области больших данных и искусственного интеллекта. Она соответствует соглашению об авторских правах CC 4.0 BY-SA. При перепечатке прикрепите ссылку на первоисточник и это заявление.
Исходная ссылка:https://cloud.tencent.com/developer/article/1940061


.NET Как загрузить файлы через HttpWebRequest

[Веселый проект Docker] Обновленная версия 2023 года! Создайте эксклюзивный инструмент управления паролями за 10 минут — Vaultwarden
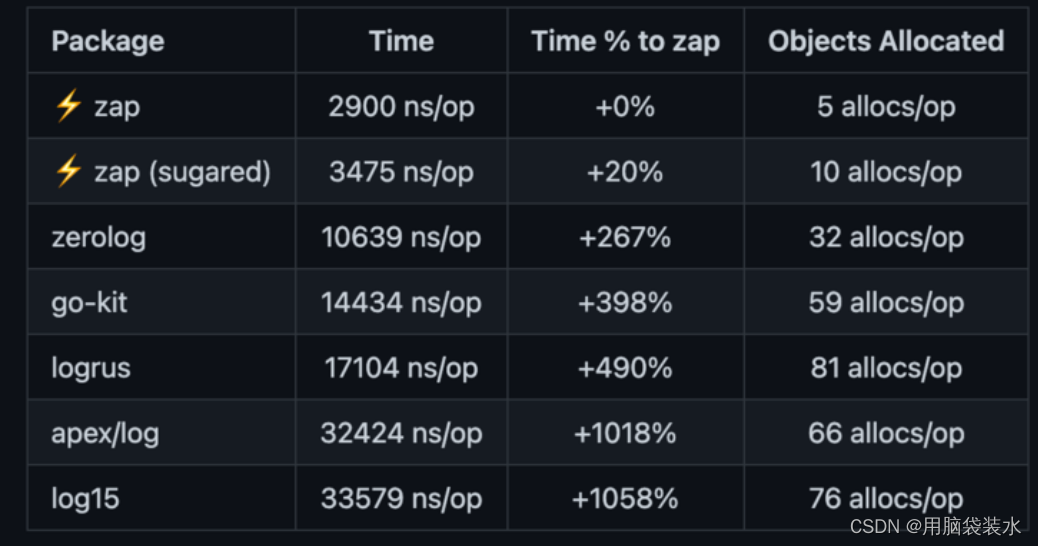
Высокопроизводительная библиотека бревен Golang zap + компонент для резки бревен лесоруба подробное объяснение

Концепция и использование Springboot ConstraintValidator

Новые функции Go 1.23: точная настройка основных библиотек, таких как срезы и синхронизация, значительно улучшающая процесс разработки.

[Весна] Введение и базовое использование AOP в Spring, SpringBoot использует AOP.

Чтобы начать работу с рабочим процессом Flowable, этой статьи достаточно.

Байтовое интервью: как решить проблему с задержкой сообщений MQ?
ASP.NET Core использует функциональные переключатели для управления реализацией доступа по маршрутизации.
[Проблема] Решение Невозможно подключиться к Redis; вложенное исключение — io.lettuce.core.RedisConnectionException.
От теории к практике: проектирование чистой архитектуры в проектах Go
Решение проблемы искажения китайских символов при чтении файлов Net Core.
Реализация легких независимых конвейеров с использованием Brighter

Как удалить и вернуть указанную пару ключ-значение из ассоциативного массива в PHP
Feiniu fnos использует Docker для развертывания учебного пособия по AList
Принципы и практика использования многопоточности в различных версиях .NET.
Как использовать PaddleOCRSharp в рамках .NET

CRUD используется уже два или три года. Как читать исходный код Spring?

Устраните проблему совместимости между версией Spring Boot и Gradle Java: возникла проблема при настройке корневого проекта «demo1» > Не удалось.

Научите вас шаг за шагом, как настроить Nginx.
Это руководство — все, что вам нужно для руководства по автономному развертыванию сервера для проектов Python уровня няни (рекомендуемый сборник).

Не удалось запустить docker.service — Подробное объяснение идеального решения ️

Настройка файлового сервера Samba в системе Linux Centos. Анализ NetBIOS (супер подробно)
Как настроить метод ssh в Git, как получить и отправить код через метод ssh

RasaGpt — платформа чат-ботов на основе Rasa и LLM.

Nomic Embed: воспроизводимая модель внедрения SOTA с открытым исходным кодом.

Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Малые цели имеют очевидные преимущества | ICASSP2023

Урок 1 серии Libtorch: Тензорная библиотека Silky C++

Руководство по локальному развертыванию Stable Diffusion: подробные шаги и анализ распространенных проблем
