Полная коллекция архитектуры Flink1.13 | Одна статья поможет вам освоить все аспекты Flink, от простого до глубокого (Часть 3) SQL.
Если ты направишь свое сердце к солнцу, оно не будет пустынным.
Солнце очень хорошее, и цветы цветут весной.
Цветы распускаются прямо перед тобой
Просыпаться каждое утро — самое прекрасное начало жизни
Привет всем, в этой главе в основном рассказывается о FlinkSQL, которая также является предпоследней главой главы Flink. В конце также есть глава FlinkCEP, которая будет опубликована позже. Пожалуйста, будьте терпеливы! Хорошо, давайте перейдем к делу! ! ! !

Table API и SQL — это API верхнего уровня. Эти два API интегрированы во Flink. Объектом выполнения SQL также является таблица (Table) в Flink, поэтому мы обычно думаем о них как об одном. Flink — это унифицированная платформа обработки для пакетной и потоковой обработки. Будь то пакетная обработка (API DataSet) или потоковая обработка (API DataStream), ее можно реализовать непосредственно с использованием API таблиц или SQL в приложениях верхнего уровня. для операции запроса таблицы полученные результаты точно такие же. В качестве примера для объяснения мы в основном используем приложения потоковой обработки. Следует отметить, что Table API и SQL поначалу не были идеальными. После слияния версии Flink 1.9 с внутренней версией Blink они претерпели очень большие изменения. С тех пор они не находились в процессе быстрого развития и улучшения. до версии Flink 1.12, которая в основном достигла функционального совершенства. Даже в последней версии 1.13 Table API и SQL по-прежнему нестабильны, а использование интерфейса все еще корректируется и обновляется. Поэтому в этой части я надеюсь, что все сосредоточатся на понимании принципов и базового использования. Для конкретных вызовов API вы всегда можете обратить внимание на обновления и изменения официального сайта.
1. Хорошо работает напрямую
Если мы хорошо знакомы с реляционными базами данных и SQL, то использовать Table API и SQL на самом деле очень просто: просто получите «таблицу» (Table), а затем вызовите для нее Table API или напишите SQL напрямую. Далее мы начнем с очень простого примера, чтобы получить предварительное представление о том, как использовать этот высокоуровневый API.
1.1 Зависимости, которые необходимо ввести
Если мы хотим использовать Table API в нашем коде, мы должны ввести соответствующие зависимости.
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
Зависимость здесь представляет собой «мост» Java, который в основном отвечает за поддержку соединения между API таблиц и нижним API потока данных. Он разделен на версию Java и версию Scala в зависимости от разных языков. Если мы хотим запустить Table API и SQL в локальной интегрированной среде разработки (IDE), нам также необходимо ввести следующие зависимости:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
Основная добавленная здесь зависимость — это «планировщик», который является основным компонентом Table API и отвечает за обеспечение среды выполнения и создание плана выполнения программы. Здесь мы используем новую версию планировщика Blink. Поскольку планировщик включен в каталог lib установочного пакета Flink, задания, отправленные в среду производственного кластера, не должны упаковывать эту зависимость. Во внутренней реализации Table API некоторые связанные коды реализованы в Scala, поэтому необходимо добавить дополнительную зависимость от версии Scala обработки потоков.
1.2 Простой пример
Имея базовые зависимости, мы можем попытаться использовать Table API и SQL в коде Flink. Например, мы можем настроить некоторые события доступа пользователей типа «Событие» в качестве источника входных данных, а затем извлечь из них пользовательские поля URL-адреса и имени пользователя в качестве выходных данных; Если мы используем API DataStream, мы можем напрямую читать источник данных и использовать простую карту оператора преобразования для извлечения полей. Если это требование напрямую написано на SQL, реализация будет проще:
select url, user from EventTable;
Здесь мы вызываем таблицу, состоящую из всех данных потока EventTable. Выполните приведенный выше SQL непосредственно в этой таблице в коде Flink, чтобы получить данные, которые вы хотите извлечь. Конкретная реализация в коде выглядит следующим образом:
public class TableExample {
public static void main(String[] args) throws Exception {
// Получить среду выполнения потока
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// Чтение источника данных
SingleOutputStreamOperator<Event> eventStream = env
.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 1000L),
new Event("Alice", "./prod?id=1", 5 * 1000L),
new Event("Cary", "./home", 60 * 1000L),
new Event("Bob", "./prod?id=3", 90 * 1000L),
new Event("Alice", "./prod?id=7", 105 * 1000L)
);
// Получить среду таблицы
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// Преобразование потоков данных в таблицы
Table eventTable = tableEnv.fromDataStream(eventStream);
// Выполнить SQL с помощью Извлечь данные по
Table visitTable = tableEnv.sqlQuery("select url, user from " + eventTable);
// Преобразуйте таблицу в поток данных и распечатайте результат.
tableEnv.toDataStream(visitTable).print();
// Выполнить программу
env.execute();
}
}
Здесь нам нужно создать «Окружение таблицы» (TableEnvironment), а затем преобразовать поток данных (DataStream) в таблицу (Table), после чего мы сможем выполнить SQL для запроса данных в этой таблице;
2. Базовый API
2.1 Архитектура программы
В Flink Table API и SQL можно рассматривать как набор API, связанных вместе. Основная концепция этого набора API — «таблица». В нашей программе входные данные могут быть определены как таблица; затем запросить эту таблицу, чтобы получить новую таблицу, что эквивалентно операции преобразования потоковых данных, наконец, мы также можем определить таблицу для вывода, отвечающую за запись; результаты обработки во внешнюю систему. Базовая структура программы следующая:
// Создать среду таблицы
TableEnvironment tableEnv = ...;
// Создайте таблицу ввода и подключитесь к внешней системе для чтения данных.
tableEnv.executeSql("CREATE TEMPORARY TABLE inputTable ... WITH ( 'connector' = ... )");
// Зарегистрируйте таблицу для подключения к внешней системе для вывода
tableEnv.executeSql("CREATE TEMPORARY TABLE outputTable ... WITH ( 'connector' = ... )");
// Выполните SQL для запроса и преобразования таблицы и получения новой таблицы.
Table table1 = tableEnv.sqlQuery("SELECT ... FROM inputTable... ");
// Использовать таблицу API выполняет преобразование запроса к таблице и получает новую таблицу.
Table table2 = tableEnv.from("inputTable").select(...);
// Запишите полученный результат в Выходную таблица
TableResult tableResult = table1.executeInsert("outputTable");
Вместо преобразования потока данных в таблицу таблица создается непосредственно путем выполнения DDL. Выполняемый здесь оператор CREATE использует параметр With для указания соединителя внешней системы, поэтому вы можете подключиться к внешней системе для чтения данных. На самом деле это более общая архитектура программы, поскольку таким образом мы можем полностью отказаться от API DataStream и напрямую использовать операторы SQL для реализации всего процесса обработки потока.
2.2 Создание среды таблицы
Для фреймворков потоковой обработки, таких как Flink, структуры потоков данных и таблиц по-прежнему различаются. Поэтому для использования API таблиц и SQL требуется специальная среда выполнения, которая представляет собой так называемую «среду таблиц» (TableEnvironment). В основном он отвечает за:
(1)зарегистрироватьсяCatalogиповерхность;
(2) Исполнение SQL Запрос;
(3)зарегистрироватьсяпользователь Пользовательская функция (UDF);
(4)DataStream и Преобразование между таблицами.
Каждая таблица и выполнение SQL должны быть привязаны к табличной среде (TableEnvironment). TableEnvironment — это базовый класс интерфейса, предоставляемый в Table API. Вы можете создать экземпляр среды таблицы, вызвав статический метод create(). Методу необходимо передать параметр конфигурации среды EnvironmentSettings, который может указывать режим выполнения и планировщик текущей табличной среды. Существует два режима выполнения: пакетная обработка и потоковая обработка. По умолчанию планировщик использует режим потоковой обработки;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode() // Использовать режим потоковой обработки
.build();
TableEnvironment tableEnv = TableEnvironment.create(setting);
Для сценариев потоковой обработки на самом деле достаточно конфигурации по умолчанию. Поэтому мы также можем использовать другой, более простой способ создания окружения таблицы:
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
Здесь мы представляем «StreamTableEnvironment», который является подинтерфейсом, унаследованным от TableEnvironment. Чтобы вызвать его метод create(), вам нужно только напрямую передать текущую среду выполнения потока (StreamExecutionEnvironment), чтобы создать соответствующую среду таблицы потоковой передачи.
2.3 Создать таблицу
Таблица — это концепция, с которой мы хорошо знакомы. Это базовая форма хранения данных в реляционных базах данных и основной объект выполнения SQL. Существует два конкретных способа создания таблиц: соединители и виртуальные таблицы.
1. Таблицы соединителей
Самый интуитивно понятный способ создания таблицы — подключиться к внешней системе через соединитель и затем определить соответствующую структуру таблицы. В коде мы можем вызвать метод выполненияSql() табличной среды и передать DDL в качестве параметра для выполнения операций SQL. Здесь мы передаем оператор CREATE для создания таблицы и указываем соединитель к внешней системе с помощью ключевого слова With:
tableEnv.executeSql("CREATE [TEMPORARY] TABLE MyTable ... WITH ( 'connector' = ... )");
Ключевое слово TEMPORARY здесь можно опустить. Мы объясним конкретное определение соединителей в разделе 11.8.
2. Виртуальные столы
После регистрации в среде мы можем напрямую использовать эту таблицу в SQL для преобразования запросов.
Table newTable = tableEnv.sqlQuery("SELECT ... FROM MyTable... ");
Здесь вызывается метод sqlQuery() среды таблицы, и оператор SQL напрямую передается в качестве параметра для выполнения запроса. Результатом является объект Table. Table — это основной класс интерфейса, предоставляемый в Table API, который представляет экземпляр таблицы, определенный в Java. Поскольку newTable является объектом Table и не зарегистрирован в среде таблицы, поэтому, если мы хотим использовать его непосредственно в SQL, нам также необходимо зарегистрировать эту таблицу промежуточных результатов в среде:
tableEnv.createTemporaryView("NewTable", newTable);
Мы обнаружили, что регистрация здесь фактически создает «Виртуальную таблицу». Эта концепция очень похожа на представление в синтаксисе SQL, поэтому вызываемый метод также называется созданием «виртуального представления» (createTemporaryView).
2.4 Запрос таблиц
Созданныйповерхность,Следующее, естественно, правильноповерхность Преобразование запроса выполнено。одному Запрос таблицы(Query)действовать,Соответствует преобразованию потоковых данных(Transform)иметь дело с。FlinkПредоставляет нам два метода запроса:SQL и API таблиц.
1. Выполните SQL для запроса
Выполнение операторов SQL на основе таблиц — это метод запроса, с которым мы наиболее знакомы. В коде нам нужно только вызвать метод sqlQuery() табличной среды и передать оператор SQL-запроса в виде строки. Результатом выполнения является объект Table.
// Создать среду таблицы
TableEnvironment tableEnv = ...;
// Создать таблицу
tableEnv.executeSql("CREATE TABLE EventTable ... WITH ( 'connector' = ... )");
// Запросите событие клика пользователя Алисы и извлеките первые два поля таблицы.
Table aliceVisitTable = tableEnv.sqlQuery(
"SELECT user, url " +
"FROM EventTable " +
"WHERE user = 'Alice' "
);
В настоящее время Flink поддерживает большинство вариантов использования стандартного SQL и предоставляет множество вычислительных функций. Таким образом, мы можем перенести существующие технологии и реализовать наши собственные потребности в обработке напрямую, написав SQL, как в MySQL и Hive, что значительно снижает сложность начала работы с Flink. Например, мы также можем определить групповую агрегацию с помощью ключевого слова GROUP BY и вызывать такие функции, как COUNT() и SUM(), для выполнения статистических вычислений:
Table urlCountTable = tableEnv.sqlQuery(
"SELECT user, COUNT(url) " +
"FROM EventTable " +
"GROUP BY user "
);
В приведенном выше примере получается новый объект Table. Мы можем снова зарегистрировать его как виртуальную таблицу и продолжить вызывать ее в SQL. Кроме того, мы также можем напрямую записывать результаты запроса в зарегистрированную таблицу. Для этого необходимо вызвать метод ExecuteSql() табличной среды для выполнения DDL, передав оператор INSERT:
// Реестр
tableEnv.executeSql("CREATE TABLE EventTable ... WITH ( 'connector' = ... )");
tableEnv.executeSql("CREATE TABLE OutputTable ... WITH ( 'connector' = ... )");
// Вывод результатов запроса в OutputTable
tableEnv.executeSql (
"INSERT INTO OutputTable " +
"SELECT user, url " +
"FROM EventTable " +
"WHERE user = 'Alice' "
);
2. Вызовите Table API для запроса.
Другой метод запроса — вызов Table API. Это API запросов, встроенный в языки Java и Scala. Ядром является класс интерфейса Table. Путем пошагового объединения метода Table можно определить все операции преобразования запросов. Поскольку API таблицы вызывается на основе экземпляра таблицы Java, нам сначала нужно получить объект Java таблицы. На основе зарегистрированной таблицы в среде вы можете легко получить объект Table с помощью метода from() среды таблицы: Table eventTable = tableEnv.from("EventTable"); Переданный параметр — это имя зарегистрированной таблицы. Обратите внимание, что eventTable здесь — это объект Table, а EventTable — это имя таблицы, зарегистрированное в среде. После получения объекта Table вы можете вызвать API для выполнения различных операций преобразования. Вы получите новый объект Table:
Table maryClickTable = eventTable
.where($("user").isEqual("Alice"))
.select($("url"), $("user"));
Параметром каждого метода здесь является «выражение», которое интуитивно показывает, что вы хотите выразить в форме вызова метода. Символ «$» используется для указания поля в таблице. Приведенный выше код эквивалентен непосредственному выполнению SQL. Table API — это DSL, встроенный в язык программирования. Многие возможности и функции SQL должны иметь соответствующие реализации, прежде чем их можно будет использовать, поэтому это определенно более хлопотно, чем непосредственное написание SQL. В настоящее время API таблиц поддерживает относительно мало функций. Ожидается, что сообщество Flink в будущем сосредоточится на расширении SQL, чтобы предоставить всем более общий метод интерфейса, поэтому мы также сосредоточимся на внедрении SQL и кратко упомянем таблицу; API.
3. Совместное использование двух API
Можно обнаружить, что независимо от того, вызываете ли вы Table API или выполняете SQL, результатом является объект Table, поэтому запросы этих двух API можно легко комбинировать. (1) Независимо от того, какой объект таблицы получен каким-либо образом, вы можете продолжать вызывать API таблицы для преобразования запроса. (2) Если вы хотите выполнить операции SQL над таблицей (на которую указывает ключевое слово FROM), вы должны сначала обратиться к ней; его в среде прописать. Таким образом, мы можем добиться преобразования между ними, создав виртуальную таблицу: tableEnv.createTemporaryView("MyTable", myTable); Оба API преследуют одну и ту же цель. В реальных приложениях вы можете выбирать в соответствии со своими привычками. Однако, поскольку совместное использование может легко вызвать путаницу, а API таблиц имеет относительно мало функций и низкую универсальность, SQL часто напрямую используется в корпоративных проектах для удовлетворения требований.
2.5 Таблица вывода
Создание и запрос таблицы соответствуют чтению источника данных (Source) и преобразованию (Transform) при потоковой обработке, а последний шаг Sink, который выводит данные результата во внешнюю систему, соответствует операции вывода таблицы; . С точки зрения кода, наиболее прямой способ вывода таблицы — это вызов метода ExecutInsert() класса Table для записи таблицы в зарегистрированную таблицу. Параметр, передаваемый методом, — это имя зарегистрированной таблицы.
// Реестр,Используется для вывода данных во внешние системы
tableEnv.executeSql("CREATE TABLE OutputTable ... WITH ( 'connector' = ... )");
// После преобразования запроса получается таблица результатов
Table result = ...
// Записать таблицу результатов зарегистрированным Выходная таблицасередина
result.executeInsert("OutputTable");На самом деле вывод таблицы осуществляется путем записи данных в TableSink. TableSink — это общий интерфейс, предоставляемый в Table API для записи данных во внешние системы. Он может поддерживать различные форматы файлов (например, CSV, Parquet), базы данных хранения (например, JDBC, Elasticsearch) и очереди сообщений (например, Kafka).
2.6 Преобразование таблиц и потоков
1. Преобразовать таблицу (Table) в поток (DataStream)
(1) Вызов метода toDataStream(). Преобразование объекта Table в DataStream очень просто. Просто вызовите метод toDataStream() среды таблицы. Например, мы можем преобразовать таблицу aliceClickTable, полученную в результате преобразования запроса в разделе 2.4, в потоковую распечатку:
Table aliceVisitTable = tableEnv.sqlQuery(
"SELECT user, url " +
"FROM EventTable " +
"WHERE user = 'Alice' "
);
// Преобразовать таблицу в поток данных
tableEnv.toDataStream(aliceVisitTable).print();
(2) Вызовите метод toChangelogStream(). Статистика группового агрегирования выполняется в таблице urlCountTable, поэтому каждая строка в таблице будет «обновлена». Для такой таблицы с операциями обновления нам не следует напрямую преобразовывать ее в DataStream для распечатки, а записывать ее «журнал изменений». Таким образом, все операции обновления таблицы становятся потоком журналов обновлений, и мы можем преобразовать их в потоковую распечатку. В коде необходимо вызвать метод toChangelogStream() табличного окружения:
Table urlCountTable = tableEnv.sqlQuery(
"SELECT user, COUNT(url) " +
"FROM EventTable " +
"GROUP BY user "
);
// Преобразование таблицы в поток журнала обновлений
tableEnv.toDataStream(urlCountTable).print();
2. Преобразовать поток (DataStream) в таблицу (Table).
(1) Вызов метода fromDataStream(). Преобразовать DataStream в таблицу также очень просто. Этого можно добиться, вызвав метод fromDataStream() среды таблицы. Возвращается объект Table. Например, мы можем напрямую преобразовать поток событий в таблицу:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Получить среду таблицы
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// Чтение источника данных
SingleOutputStreamOperator<Event> eventStream = env.addSource(...)
// Преобразование потоков данных в таблицы
Table eventTable = tableEnv.fromDataStream(eventStream);
Поскольку данные в самом потоке представляют собой определенное событие типа POJO, после преобразования потока в таблицу каждая строка данных соответствует событию, а имена столбцов в таблице соответствуют атрибутам в событии. Кроме того, мы также можем добавить параметры в метод fromDataStream(), чтобы указать, какие атрибуты следует извлечь в качестве имен полей в таблице, а позиция может быть указана произвольно:
// Извлеките временную метку события в виде столбца таблицы.
Table eventTable2 = tableEnv.fromDataStream(eventStream, $("timestamp"), $("url"));
Следует отметить, что временная метка сама по себе является ключевым словом в SQL, поэтому нам следует избегать ее при определении имен таблиц и столбцов. На этом этапе поле можно переименовать с помощью метода as() выражения:
// Переименуйте поле временной метки в ts
Table eventTable2 = tableEnv.fromDataStream(eventStream, $("timestamp").as("ts"), $("url"));
(2) Вызов метода createTemporaryView() и метода fromDataStream() прост и интуитивно понятен и позволяет напрямую преобразовать DataStream в таблицу, однако, если мы хотим напрямую ссылаться на эту таблицу в SQL, нам также необходимо вызвать createTemporaryView(; ) метод табличной среды. Создайте виртуальное представление. Для этого сценария существует также более краткий метод вызова. Мы можем напрямую вызвать метод createTemporaryView() для создания виртуальной таблицы. Первый из двух переданных параметров по-прежнему является зарегистрированным именем таблицы, а второй может быть непосредственно DataStream. Вы все равно можете передать несколько параметров позже, чтобы указать поля в таблице.
tableEnv.createTemporaryView("EventTable", eventStream, $("timestamp").as("ts"),$("url"));
Таким образом, мы можем напрямую ссылаться на таблицу EventTable в SQL.
3. Поддерживаемые типы данных
В целом типы данных, поддерживаемые в DataStream, также поддерживаются в Table, но при преобразовании необходимо обратить внимание на некоторые детали. (1) Атомарные типы. В Flink базовые типы данных (Целое, Двойное, Строковое) и общие типы данных (то есть типы данных, которые нельзя разделить снова) вместе называются «атомарными типами». Поток данных атомарного типа после преобразования становится таблицей только с одним столбцом. Тип данных поля столбца (поля) можно вывести из атомарного типа. Кроме того, вы также можете добавить параметры в метод fromDataStream() для переименования полей столбца.
StreamTableEnvironment tableEnv = ...;
DataStream<Long> stream = ...;
// Преобразуйте поток данных в динамическую таблицу. Динамическая таблица имеет только одно поле и переименуйте его в myLong.
Table table = tableEnv.fromDataStream(stream, $("myLong"));
(2) Тип кортежа. Если атомарный тип не переименован, именем поля по умолчанию является «f0». Легко подумать, что на самом деле это результат обработки атомарного типа как кортежа Tuple1. Таблица поддерживает тип кортежа Tuple, определенный в Flink, а соответствующие имена полей в таблице по умолчанию являются именами атрибутов элементов в кортеже: f0, f1, f2... Все поля можно переупорядочить или можно извлечь подмножество полей. Поля также можно переименовать, вызвав метод выражения as().
StreamTableEnvironment tableEnv = ...;
DataStream<Tuple2<Long, Integer>> stream = ...;
// Преобразуйте поток данных в таблицу, содержащую только поле f1.
Table table = tableEnv.fromDataStream(stream, $("f1"));
// Преобразуйте поток данных в таблицу, содержащую поле f0иf1, и поменяйте местами позицию f0иf1 в таблице.
Table table = tableEnv.fromDataStream(stream, $("f1"), $("f0"));
// Назовите поле f1 myInt и f0 myLong.
Table table = tableEnv.fromDataStream(stream, $("f1").as("myInt"), $("f0").as("myLong"));
(3) Тип POJO Flink также поддерживает «составные типы», состоящие из нескольких типов данных, наиболее типичным из которых являются простые объекты Java (типы POJO). Поскольку в POJO определены читаемые имена полей, преобразование этого типа потока данных в таблицу происходит очень гладко. Преобразуйте поток данных типа POJO в таблицу. Если имя поля не указано, имя поля исходного типа POJO будет использоваться напрямую. Поля в POJO также можно переупорядочивать, извлекать и переименовывать.
StreamTableEnvironment tableEnv = ...;
DataStream<Event> stream = ...;
Table table = tableEnv.fromDataStream(stream);
Table table = tableEnv.fromDataStream(stream, $("user"));
Table table = tableEnv.fromDataStream(stream, $("user").as("myUser"), $("url").as("myUrl"));
(4) Тип строки Flink также определяет более распространенный тип данных в реляционных таблицах — строку, которая является базовой организационной формой данных в таблице. Тип Row также является составным типом. Его длина фиксирована, и тип каждого поля не может быть напрямую выведен, поэтому при его использовании необходимо указать конкретную информацию о типе; оператор CREATE, который мы вызываем при создании таблицы, будет указывать все поля. и указываются тип, который называется «схемой» (Schema) таблицы во Flink.
4. Подробные примеры применения
Теперь мы можем интегрировать все представленные API и написать полноценный фрагмент кода. Это также набор событий кликов пользователя. Мы можем запросить список URL-адресов, на которые нажал пользователь (например, Алиса), а также подсчитать совокупное количество кликов для каждого пользователя. Этого можно добиться с помощью двух операторов SQL. Конкретный код выглядит следующим образом:
public class TableToStreamExample {
public static void main(String[] args) throws Exception {
// Получить потоковую среду
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// Чтение источника данных
SingleOutputStreamOperator<Event> eventStream = env
.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 1000L),
new Event("Alice", "./prod?id=1", 5 * 1000L),
new Event("Cary", "./home", 60 * 1000L),
new Event("Bob", "./prod?id=3", 90 * 1000L),
new Event("Alice", "./prod?id=7", 105 * 1000L)
);
// Получить среду таблицы
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// Преобразование потоков данных в таблицы
tableEnv.createTemporaryView("EventTable", eventStream);
// Запросить список URL-адресов доступа Алисы
Table aliceVisitTable = tableEnv.sqlQuery("SELECT url, user FROM EventTable WHERE user = 'Alice'");
// Подсчитайте количество кликов для каждого пользователя
Table urlCountTable = tableEnv.sqlQuery("SELECT user, COUNT(url) FROM EventTable GROUP BY user");
// Преобразовать таблицу в поток данных,существуют распечатка консоли
tableEnv.toDataStream(aliceVisitTable).print("alice visit");
tableEnv.toChangelogStream(urlCountTable).print("count");
// Выполнить программу
env.execute();
}
}
3. Таблицы в потоковой обработке. Мы можем сравнить реляционные таблицы/SQL с потоковой обработкой, как показано в таблице.
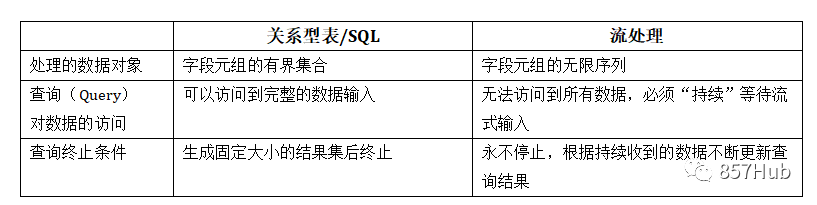
Как видите, на самом деле реляционные таблицы и SQL в основном предназначены для пакетной обработки, которая по своей сути отличается от потоковой обработки. Далее давайте углубимся в концепцию таблиц в потоковой обработке.
3.1 Динамические таблицы и непрерывные запросы
Данные, с которыми сталкивается потоковая обработка, являются непрерывными, что делает «таблицу» потоковой обработки совершенно отличной от таблиц в привычной нам реляционной базе данных, а операции запроса, основанные на таблице, имеют новое значение;
1. Динамические таблицы
При поступлении новых данных в поток в исходную таблицу будет вставлена строка и SQL-запрос, определенный на основе этой таблицы, должен обновить результаты на основе предыдущей; Таблицы, полученные таким образом, будут постоянно динамически изменяться и называются «Динамическими таблицами». Динамические таблицы — это основные концепции Flink в Table API и SQL, которые обеспечивают поддержку таблиц и SQL для потоковой обработки данных. Знакомые нам таблицы обычно используются для пакетной обработки, ориентированы на фиксированные наборы данных и могут считаться «статическими таблицами». Динамические таблицы совершенно разные, и данные в них со временем меняются;
2. Непрерывный запрос
Динамические таблицы можно запрашивать так же, как статические пакетные таблицы. Поскольку данные постоянно меняются, определенный на их основе SQL-запрос не может быть выполнен один раз и получить окончательный результат. Таким образом, наши запросы к динамической таблице никогда не остановятся и будут продолжать выполняться по мере поступления новых данных. Такой запрос называется «Непрерывный запрос». Все операции запроса, определенные в динамической таблице, являются непрерывными запросами, и результатом непрерывного запроса также будет динамическая таблица. Поскольку каждое поступление данных запускает операцию запроса, можно считать, что набор данных, к которому обращается запрос, — это все данные, полученные в текущей входной динамической таблице. Это эквивалентно созданию «снимка» входной динамической таблицы и обработке его как ограниченного набора данных для пакетной обработки; поступление потоковых данных вызовет непрерывные запросы моментальных снимков, которые связаны как анимация, образуя «непрерывный запрос».
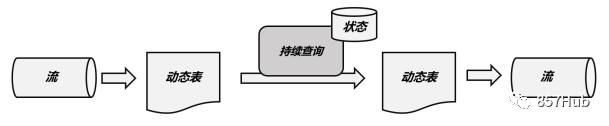
Шаги для непрерывного запроса следующие:
(1)поток(stream)преобразован в динамическийповерхность(dynamic table);
(2) Непрерывный запрос динамических таблиц (непрерывный запрос), сгенерировать новую динамическую таблицу;
(3) Сгенерированная динамическая таблица преобразуется в поток.
Таким образом, пока API инкапсулирует преобразование между потоками и динамическими таблицами, мы можем напрямую выполнять SQL-запросы к потоку данных и выполнять обработку потока так же, как обработку таблиц.
3.2 Преобразование потоков в динамические таблицы
Чтобы использовать SQL для обработки потока, мы должны сначала преобразовать поток в динамическую таблицу. Конечно, ранее, объясняя базовый API, мы уже рассказывали, как конвертировать DataStream и Table в коде, теперь нам нужно отложить в сторону конкретные типы данных и понять принцип преобразования между потоками и динамическими таблицами; Если поток рассматривать как таблицу, то поступление каждых данных в поток следует рассматривать как операцию вставки в таблицу, и в конец таблицы будет добавлена строка данных. Поскольку поток является непрерывным, а предыдущие выходные результаты не могут быть изменены и могут быть добавлены только позже, поэтому мы фактически создаем таблицу с помощью потока журнала обновлений (журнала изменений), предназначенного только для вставки. Например, когда приходит событие щелчка пользователя, оно соответствует операции вставки в динамическую таблицу, и каждый фрагмент данных представляет собой строку в таблице; по мере вставки новых событий щелчка результирующая динамическая таблица будет продолжать расти.
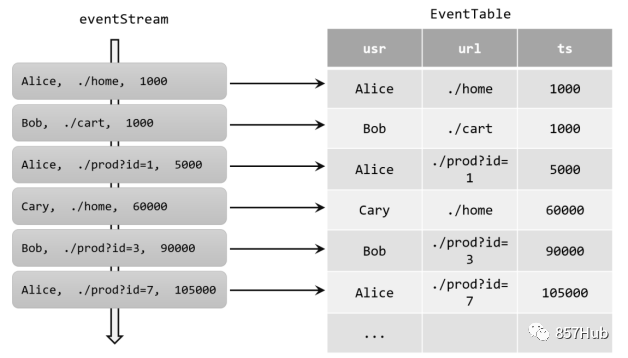
3.3 Непрерывный запрос с использованием SQL
1. Обновить запрос
Мы определяем SQL-запрос в нашем коде.
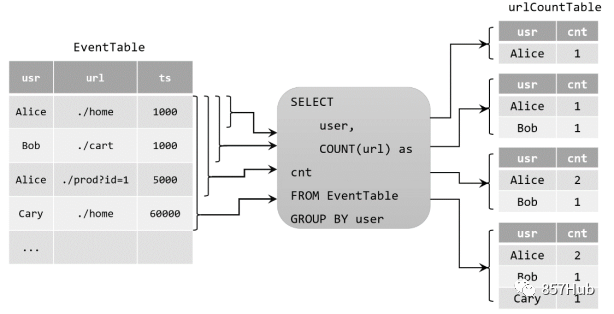
Table urlCountTable = tableEnv.sqlQuery("SELECT user, COUNT(url) as cnt FROM EventTable GROUP BY user");
Когда исходная динамическая таблица постоянно вставляет новые данные, urlCountTable, полученная по запросу, будет продолжать изменяться. Поскольку счетчик может увеличиваться, операция изменения здесь может представлять собой простую вставку (Вставка) или обновление (Обновление) предыдущих данных. Этот тип непрерывного запроса называется запросом на обновление (запрос на обновление). Если вы хотите преобразовать таблицу результатов, полученную в результате запроса на обновление, в поток данных, вы должны вызвать метод toChangelogStream().
2. Добавить запрос
В приведенном выше примере в процессе запроса используется групповая агрегация, а в таблице результатов будут выполняться операции обновления. Если мы выполним простой условный запрос, таблица результатов будет похожа на исходную таблицу EventTable, только с операциями вставки.
Table aliceVisitTable = tableEnv.sqlQuery("SELECT url, user FROM EventTable WHERE user = 'Cary'");
Такой непрерывный запрос называется запросом на добавление, который определяет только операции INSERT в потоке журнала изменений таблицы результатов. Нет ограничений на вызывающий метод преобразования таблицы результатов, полученной запросом на добавление, в DataStream. Вы можете использовать toDataStream() напрямую или вызвать toChangelogStream() как запрос на обновление.
Поскольку статистические результаты окна сразу записываются в таблицу результатов, поток журнала обновлений таблицы результатов содержит только операцию INSERT, но не операцию UPDATE. Таким образом, непрерывный запрос здесь по-прежнему является запросом на добавление. Если результат таблицы результатов преобразуется в DataStream, метод toDataStream() можно вызвать напрямую.
3.4 Преобразование динамических таблиц в потоки
Подобно таблицам в реляционных базах данных, динамические таблицы также могут подвергаться постоянным изменениям посредством операций вставки, обновления и удаления. Когда вы конвертируете динамическую таблицу в поток или записываете ее во внешнюю систему, вам необходимо закодировать эти операции изменения и сообщить внешней системе, что делать, отправив закодированное сообщение. В Flink Table API и SQL поддерживают три метода кодирования:
Потоки только для добавления
Динамические таблицы, которые изменяются только с помощью вставки изменений, можно преобразовать непосредственно в поток, предназначенный только для добавления. Данные, отправляемые в этом потоке, фактически представляют собой каждую новую строку в динамической таблице.
Втягивание потока
Поток вывода — это поток, который содержит два типа сообщений: сообщения добавления и сообщения отзыва. Конкретными правилами кодирования являются: операция INSERT кодируется как сообщение добавления; операция DELETE кодируется как сообщение отзыва, а операция обновления UPDATE кодируется как сообщение отзыва для измененной строки и сообщение добавления для обновленной строки ( новая строка). Таким образом, мы можем указать все добавления, удаления и модификации посредством закодированных сообщений, а динамическую таблицу можно преобразовать в поток отзыва.

Обновить процесс вставки (Upsert)
Поток обновления-вставки содержит только два типа сообщений: сообщения обновления-вставки (upsert) и сообщения удаления (удаления). Так называемое «upsert» на самом деле представляет собой составное слово «обновление» и «вставка», поэтому для потока обновления и вставки операция вставки INSERT и операция обновления UPDATE единообразно кодируются как сообщения upsert, а операция удаления DELETE; кодируется как информация об удалении.
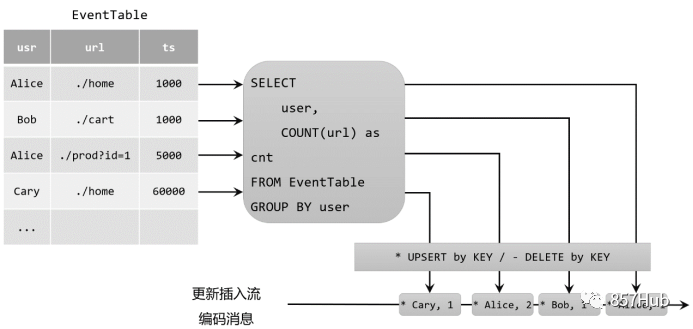
Следует отметить, что при преобразовании динамической таблицы в DataStream в коде поддерживаются только потоки только для добавления и возврата. То, что мы получаем, вызывая toChangelogStream(), на самом деле является потоком возврата. При подключении к внешней системе могут поддерживаться разные методы кодирования, в зависимости от характеристик самой внешней системы.
4. Атрибуты времени и окна
Операции, основанные на времени (например, временные окна), должны определять соответствующую семантику времени и информацию об источнике данных времени. В Table API и SQL для таблицы будет предоставлено поле логического времени, специально используемое для указания времени в программе обработки таблицы. Таким образом, так называемые атрибуты времени на самом деле являются частью схемы каждой таблицы. Его можно определить непосредственно как поле в DDL, создающем таблицу, или его можно определить при преобразовании DataStream в таблицу. После определения атрибута времени на него можно ссылаться как на обычное поле и использовать его в операциях, основанных на времени. Тип данных атрибута времени — TIMESTAMP, который ведет себя как обычная временная метка, к нему можно обращаться напрямую и рассчитывать его. В соответствии с различной семантикой времени определение атрибутов времени можно разделить на две ситуации: время события и время обработки.
4.1 Время проведения мероприятия
Атрибуты времени события могут быть определены в таблице создания DDL или в преобразовании потока данных и таблицы.
1. Определите его в DDL, который создает таблицу.
В операторе DDL (оператор CREATE TABLE), создающем таблицу, вы можете добавить поле и определить атрибуты времени события с помощью оператора WATERMARK. Конкретное определение выглядит следующим образом:
CREATE TABLE EventTable(
user STRING,
url STRING,
ts TIMESTAMP(3),
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
...
);
Здесь мы определяем поле ts как атрибут времени события и устанавливаем 5-секундную задержку водяного знака на основе ts.
2. Определите, когда поток данных преобразуется в таблицу.
Свойства времени события также можно определить при преобразовании DataStream в таблицу. Когда мы вызываем метод fromDataStream() для создания таблицы, мы можем добавить параметры для определения структуры поля в таблице. В это время мы можем добавить к полю суффикс .rowtime(), что означает, что текущее поле; обозначается как атрибут времени события. Это поле может быть дополнительным «логическим полем», которого нет в данных, или собственным полем. Независимо от метода, поле атрибута времени сохраняет метку времени события (тип TIMESTAMP). Следует отметить, что этот метод отвечает только за указание атрибута времени, а извлечение временных меток и создание водяных знаков должно было быть определено в DataStream заранее. В коде это определено следующим образом:
// Способ первый:
// Данные в потоке представляют собой кортеж Tuple2, содержащий два поля, в которых необходимо настроить извлечение меток времени и генерацию водяных знаков;
DataStream<Tuple2<String, String>> stream = inputStream.assignTimestampsAndWatermarks(...);
// Объявите дополнительное логическое поле как время. событиясвойство
Table table = tEnv.fromDataStream(stream, $("user"), $("url"), $("ts").rowtime());
// Способ второй:
// Данные в потоке представляют собой тройку Tuple3, а последнее поле — время. событияштамп
DataStream<Tuple3<String, String, Long>> stream = inputStream.assignTimestampsAndWatermarks(...);
// Никаких дополнительных полей не объявляется, просто используйте последнее поле в качестве времени. событиясвойство
Table table = tEnv.fromDataStream(stream, $("user"), $("url"), $("ts").rowtime());
4.2 Время обработки
При определении атрибута времени обработки необходимо объявить дополнительное поле специально для сохранения текущего времени обработки. Аналогично, существует два способа определения атрибутов времени обработки: они определяются в DDL при создании таблицы или определяются при преобразовании потока данных в таблицу.
1. Определите его в DDL, который создает таблицу.
В операторе DDL (оператор CREATE TABLE), создающем таблицу, вы можете добавить дополнительное поле и указать текущий атрибут времени обработки, вызвав встроенную системную функцию PROCTIME().
CREATE TABLE EventTable(
user STRING,
url STRING,
ts AS PROCTIME()
) WITH (
...
);
2. Определите, когда поток данных преобразуется в таблицу.
Свойства времени обработки также можно определить при преобразовании DataStream в таблицу. Когда мы вызываем метод fromDataStream() для создания таблицы, мы можем использовать суффикс .proctime(), чтобы указать поле атрибута времени обработки. Поскольку время обработки является системным временем и в исходных данных нет такого поля, атрибут времени обработки не должен определяться в существующем поле. Он может быть определен только в конце всех полей в структуре таблицы и отображаться как. дополнительное логическое поле. Метод определения атрибута времени обработки в коде следующий:
DataStream<Tuple2<String, String>> stream = ...;
// Объявите дополнительное поле как время поле атрибута обработки
Table table = tEnv.fromDataStream(stream, $("user"), $("url"), $("ts").proctime());
4.3 Окно
Затем с помощью атрибута времени вы можете определить окно для расчета. API DataStream предоставляет интерфейсы для определения и обработки различных типов окон. Подобные функции также могут быть реализованы в API таблиц и SQL.
1. Окно группы (старая версия)
В версиях до Flink 1.12 API таблиц и SQL предоставляли набор функций «Группового окна». Часто используемые временные окна, такие как прокручивающиеся окна, скользящие окна и окна сеанса, имеют соответствующие реализации, специально в SQL, они просто вызывают TUMBLE(). , HOP(), SESSION() и передайте поле атрибута времени, размер окна и другие параметры. В качестве примера возьмем скользящее окно: TUMBLE(ts, INTERVAL '1' HOUR), где ts — определенное поле атрибута времени, а размер окна определяется «интервалом времени» INTERVAL. При выполнении оконных вычислений окно группировки использует само окно в качестве поля для группировки данных, и данные внутри группы можно агрегировать. Основное использование следующее:
Table result = tableEnv.sqlQuery(
"SELECT " +
"user, " +
"TUMBLE_END(ts, INTERVAL '1' HOUR) as endT, " +
"COUNT(url) AS cnt " +
"FROM EventTable " +
"GROUP BY " + // Группировка по окну и имени пользователя
"user, " +
"TUMBLE(ts, INTERVAL '1' HOUR)" // Определить 1-часовое скользящее окно
);
Функция сгруппированных окон относительно ограничена и поддерживает только агрегирование окон, поэтому в настоящее время она устарела.
2. Оконные ТВФ (новая версия)
Начиная с версии 1.13, Flink начинает использовать оконные табличные функции (Windowing TVF) для определения окон. Функция с табличным значением окна — это полиморфная табличная функция (PTF), определенная Flink, которая может расширять таблицу и возвращать ее. Табличную функцию можно рассматривать как функцию, возвращающую таблицу. Эту часть мы рассмотрим в разделе 11.6. В настоящее время Flink предоставляет следующие оконные TVF:
Поворотное окно Windows)
Сдвижное окно (Hop Окна, окно прыжка)
Окно «Кумулировать» (Кумулировать Windows)
Окно сеанса Windows, пока не полностью поддерживается)
Производительность оконной табличной функции была оптимизирована и имеет более мощные функции, которые могут полностью заменить традиционную сгруппированную оконную функцию. В настоящее время функция окна TVF еще не идеальна, а окно сеанса и многие дополнительные функции еще не поддерживаются, но они быстро обновляются и совершенствуются. Ожидается, что в будущих версиях окно TVF станет все более мощным и станет единственным входом для обработки окон. Метод объявления в SQL аналогичен предыдущему окну группировки. Непосредственный вызов TUMBLE(), HOP() и CUMULATE() может реализовать прокручивающиеся, скользящие и накопительные окна, но передаваемые параметры будут другими. Ниже мы представим эти типы оконных TVF соответственно.
(1) Подвижное окно (TUMBLE)
Концепция скользящего окна в SQL точно такая же, как определение в API DataStream. Это окно с фиксированной длиной, выравниванием по времени и без перекрытия. Обычно оно используется для периодических статистических вычислений. В SQL вы можете объявить скользящее окно, вызвав функцию TUMBLE(). Единственный основной параметр — это размер окна (size). Окна подсчета не учитываются в SQL, поэтому скользящие окна — это скользящие временные окна, и поле атрибута текущего времени необходимо передавать в качестве параметров. Кроме того, окно TVF по сути является табличной функцией и может расширять таблицу, поэтому текущее время; Поле атрибута также должно быть передано. Запрашиваемая таблица передается целиком как параметр. Конкретное заявление звучит следующим образом:
TUMBLE(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOUR)
(2) Раздвижное окно (HOP)
Использование скользящих окон аналогично скользящим окнам. Частоту вывода статистических данных можно контролировать, устанавливая размер скользящего шага. В SQL скользящее окно объявляется вызовом HOP(), кроме имени таблицы и атрибутов времени, также требуются два параметра: размер окна (size) и шаг скольжения (slide);
HOP(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '5' MINUTES, INTERVAL '1' HOURS));
Следует отметить, что третий параметр, следующий сразу за полем атрибута времени, — это размер шага (слайда), а четвертый параметр — размер окна (размер).
(3) Окно накопления (КУМУЛЯТ)
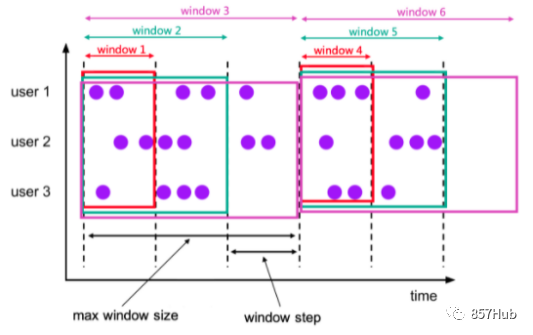
Окно накопления — это новая оконная функция в окне TVF, которая выполняет вычисления накопления в течение определенного статистического периода. В окне накопления есть два основных параметра: максимальная длина окна (max window size) и шаг накопления (шаг). Так называемая максимальная длина окна на самом деле является тем, что мы называем «статистическим периодом». Конечная цель — подсчитать данные за этот период. Ее можно определить в SQL с помощью функции CUMULATE() следующим образом:
CUMULATE(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOURS, INTERVAL '1' DAYS))
Обратите внимание, что третий параметр — это размер шага, а четвертый параметр — максимальная длина окна. Все приведенные выше операторы определяют только окно, аналогично распределителю окон в API DataStream; полный вызов окна в SQL также должен взаимодействовать с операциями агрегации и другими операциями;
5. Агрегирующий запрос
SQL в Flink — это продукт комбинации потоковой обработки и стандартного SQL, поэтому запросы агрегации также можно разделить на два типа: агрегация, уникальная для потоковой обработки (в основном оконная агрегация), и собственный метод запроса агрегации SQL.
5.1 Агрегация групп
Мы все знакомы с общей агрегацией в SQL, которая в основном реализуется с помощью некоторых встроенных функций агрегации, таких как SUM(), MAX(), MIN(), AVG() и COUNT(). Их особенностью является вычисление нескольких входных данных и получение уникального значения, которое представляет собой преобразование «многие к одному». Например, мы можем вычислить количество входных данных с помощью следующего кода:
Table eventCountTable = tableEnv.sqlQuery("select COUNT(*) from EventTable");
В большинстве случаев мы можем использовать предложение GROUP BY, чтобы указать ключ группировки (ключ) для выполнения групповой статистики по данным в соответствии с определенным полем. Например, в примере, который мы приводили ранее, мы можем группировать по имени пользователя и подсчитывать количество раз, когда каждый пользователь нажимает на URL-адрес:
SELECT user, COUNT(url) as cnt FROM EventTable GROUP BY user
Этот метод агрегации называется «групповой агрегацией». Если вы хотите преобразовать таблицу результатов в поток или вывести ее во внешнюю систему, вы должны использовать метод кодирования потока возврата или потока upsert. Если вы напрямую преобразуете ее в DataStream для печати в коде, вам нужно вызвать; toChangelogStream() .
Групповая агрегация — это как собственный запрос агрегации SQL, так и операция агрегации при потоковой обработке. Это наиболее распространенный метод агрегации в практических приложениях. Конечно, используемые агрегатные функции обычно встроены в систему, и вы можете настроить их, если хотите удовлетворить особые потребности.
5.2 Агрегация окон
В Table API и SQL Flink расчет окна реализован посредством «агрегирования окон». Подобно групповой агрегации, агрегация окон также требует вызова агрегатных функций, таких как SUM(), MAX(), MIN() и COUNT(), и указания полей группировки с помощью предложения GROUP BY. Однако при агрегировании окон информация об окне должна быть определена как часть ключа группировки.
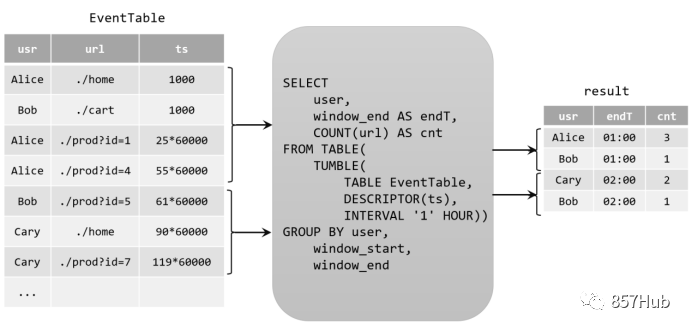
До версии Flink 1.12 само окно помещалось непосредственно после GROUP BY в качестве ключа группировки, поэтому его также называли «агрегацией групповых окон», в то время как версия 1.13 начала использовать «функцию с табличным значением окна» (Windowing TVF); само окно возвращает таблицу, поэтому окно появится после FROM, а за GROUP BY находятся новые поля window_start и window_end окна. Например:
Table result = tableEnv.sqlQuery(
"SELECT " +
"user, " +
"window_end AS endT, " +
"COUNT(url) AS cnt " +
"FROM TABLE( " +
"TUMBLE( TABLE EventTable, " +
"DESCRIPTOR(ts), " +
"INTERVAL '1' HOUR)) " +
"GROUP BY user, window_start, window_end "
);
В настоящее время Flink SQL предоставляет три табличные функции (TVF): скользящее окно TUMBLE(), скользящее окно HOP() и накопительное окно (CUMULATE). В конкретных приложениях нам также необходимо заранее определить атрибут времени. Ниже приведен полный код агрегирования окон на примере окна накопления:
public class CumulateWindowExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// Чтение источника данных,ивыделять времяштамп、Создать уровень воды
SingleOutputStreamOperator<Event> eventStream = env
.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 1000L),
new Event("Alice", "./prod?id=1", 25 * 60 * 1000L),
new Event("Alice", "./prod?id=4", 55 * 60 * 1000L),
new Event("Bob", "./prod?id=5", 3600 * 1000L + 60 * 1000L),
new Event("Cary", "./home", 3600 * 1000L + 30 * 60 * 1000L),
new Event("Cary", "./prod?id=7", 3600 * 1000L + 59 * 60 * 1000L)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
);
// Создать среду таблицы
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// Преобразование потоков данных в таблицы,иуказанное времясвойство
Table eventTable = tableEnv.fromDataStream(
eventStream,
$("user"),
$("url"),
$("timestamp").rowtime().as("ts")
);
// для удобствасуществоватьSQLсередина Цитировать,существоватьсредасередина РеестрEventTable
tableEnv.createTemporaryView("EventTable", eventTable);
// Установите окно накопления и выполните статистический запрос SQL.
Table result = tableEnv
.sqlQuery(
"SELECT " +
"user, " +
"window_end AS endT, " +
"COUNT(url) AS cnt " +
"FROM TABLE( " +
"CUMULATE( TABLE EventTable, " + // Определить окно накопления
"DESCRIPTOR(ts), " +
"INTERVAL '30' MINUTE, " +
"INTERVAL '1' HOUR)) " +
"GROUP BY user, window_start, window_end "
);
tableEnv.toDataStream(result).print();
env.execute();
}
}
Агрегация на основе окон — это функция агрегирования статистики при потоковой обработке, а также самое большое отличие от стандартного SQL. В реальных проектах многие статистические показатели фактически рассчитываются на основе временных окон, поэтому агрегация окон является очень важной функцией в Flink SQL. В будущем агрегация на основе окна TVF также будет иметь более расширенную поддержку таких функций, как окно TOP -N; , окно сеанса, соединение окон и т. д.
5.3 Агрегация окон (сверху)
В стандартном SQL есть еще один специальный тип метода агрегирования, который может вычислять агрегированное значение для каждой строки. Это так называемая «оконная функция». Агрегация оконных функций существенно отличается от двух предыдущих агрегаций: групповая агрегация и оконная агрегация TVF имеют отношение «многие к одному». После группировки данных каждая группа получит только один результат агрегации, в то время как оконная функция; представляет собой парную агрегацию. Каждая строка должна подвергаться оконной агрегации, поэтому количество строк в таблице не будет уменьшаться после агрегации. Это отношение «многие ко многим».
В соответствии со стандартным SQL функция оконной обработки в Flink SQL также реализована посредством предложения OVER, поэтому агрегацию окон иногда называют «OVER Aggregation» (Over Aggregation). Основной синтаксис следующий:
SELECT
<агрегатная функция> OVER (
[PARTITION BY <Поле1>[, <Поле2>, ...]]
ORDER BY <времясвойство Поле>
<Диапазон открытия окна>),
...
FROM ...
Ключевому слову OVER здесь предшествует агрегатная функция, которая будет применена к окну, определенному OVER, позже. В предложении OVER в основном имеются следующие части:
РАЗДЕЛЕНИЕ ПО (необязательно)
Используется для указания ключа раздела, аналогично группировке GROUP BY. Эта часть является необязательной;
ORDER BY
ORDER BY необходимо использовать в предложении OVER, чтобы четко указать, на каком поле основаны данные. В потоковой обработке Flink в настоящее время поддерживается только возрастающий порядок атрибутов времени, поэтому поля, следующие за ORDER BY, должны быть определены атрибутами времени.
Диапазон открытия окна
Зависит от МЕЖДУ <Пустота> AND <верхняя граница> Определение, то есть диапазон «от нижней границы до верхней границы». В настоящее время поддерживается только верхняя граница CURRENT. ROW, то есть определяет диапазон «от предыдущей строки до текущей строки», поэтому общая форма такова:
BETWEEN ... PRECEDING AND CURRENT ROW
Диапазон выбора окна может зависеть от времени или объема данных. Итак, диапазон открытия окно также должно выбирать между двумя режимами: интервал диапазона(RANGE интервалы) и интервалы строк (ROW intervals)。
интервал диапазона
интервал партии имеет префикс RANGE, который основан на ORDER. BY указывает поле времени для выбора диапазона, который обычно представляет собой период времени до отметки времени текущей строки. Например Диапазон открытия окно Выберите данные за 1 час до текущей строки:
RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW
междурядье
междурядье начинается с ROWS,Просто определите, сколько строк выбрать.,Просто начните с текущей строки и выберите вперед. Например, Диапазон открытия окна выбирает 5 строк данных перед текущей строкой (окончательное агрегирование будет включать текущую строку).,Итак, всего 6 фрагментов данных):
ROWS BETWEEN 5 PRECEDING AND CURRENT ROW
Вот конкретный пример:
SELECT user, ts,
COUNT(url) OVER (
PARTITION BY user
ORDER BY ts
RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW
) AS cnt
FROM EventTable
Оконная агрегация существенно отличается от оконной агрегации (оконной TVF-агрегации), но некоторые сходства все же есть: они обе определяют диапазон в неограниченном потоке данных и перехватывают ограниченные наборы данных для агрегирования статистики. Фактически, все они основаны на методе агрегации; идея «окна». Фактически, в Table API действительно определены два типа окон: окно группы (GroupWindow) и окно окна (OverWindow), а в SQL вы также можете использовать предложение WINDOW для определения отдельного окна OVER вне SELECT;
SELECT user, ts,
COUNT(url) OVER w AS cnt,
MAX(CHAR_LENGTH(url)) OVER w AS max_url
FROM EventTable
WINDOW w AS (
PARTITION BY user
ORDER BY ts
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
Приведенный выше SQL определяет окно OVER, которое выбирает две предыдущие строки данных и переименовывает их, после чего вы можете вызвать на их основе несколько агрегатных функций для расширения и извлечения большего количества столбцов.
5.4 Примеры применения – TOP-N
В настоящее время не существует функции TOP-N, которую можно было бы вызвать непосредственно во Flink SQL, но предусмотрен немного более сложный альтернативный метод реализации. Ниже приведена реализация кода для конкретного случая. Поскольку в событии доступа пользователя нет информации, связанной с продуктом, мы подсчитываем пользователей с наибольшим количеством действий при доступе в час и берем двух первых, что эквивалентно запросу на количество активных пользователей в час.
public class WindowTopNExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// Чтение источника данных,ивыделять времяштамп、Создать уровень воды
SingleOutputStreamOperator<Event> eventStream = env
.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 1000L),
new Event("Alice", "./prod?id=1", 25 * 60 * 1000L),
new Event("Alice", "./prod?id=4", 55 * 60 * 1000L),
new Event("Bob", "./prod?id=5", 3600 * 1000L + 60 * 1000L),
new Event("Cary", "./home", 3600 * 1000L + 30 * 60 * 1000L),
new Event("Cary", "./prod?id=7", 3600 * 1000L + 59 * 60 * 1000L)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
);
// Создать среду таблицы
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// Преобразование потоков данных в таблицы,иуказанное времясвойство
Table eventTable = tableEnv.fromDataStream(
eventStream,
$("user"),
$("url"),
$("timestamp").rowtime().as("ts")
// Укажите временную метку как время события и назвали ts
);
// для удобствасуществоватьSQLсередина Цитировать,существоватьсредасередина РеестрEventTable
tableEnv.createTemporaryView("EventTable", eventTable);
// Определите подзапросы для выполнения агрегирования окон, получить информацию об окне, пользователь а также Результат таблицы посещений
String subQuery =
"SELECT window_start, window_end, user, COUNT(url) as cnt " +
"FROM TABLE ( " +
"TUMBLE( TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOUR )) " +
"GROUP BY window_start, window_end, user ";
// Определить внешний запрос TOP-N
String topNQuery =
"SELECT * " +
"FROM (" +
"SELECT *, " +
"ROW_NUMBER() OVER ( " +
"PARTITION BY window_start, window_end " +
"ORDER BY cnt desc " +
") AS row_num " +
"FROM (" + subQuery + ")) " +
"WHERE row_num <= 2";
// Выполните SQL, чтобы получить таблицу результатов
Table result = tableEnv.sqlQuery(topNQuery);
tableEnv.toDataStream(result).print();
env.execute();
}
}
6. Присоединиться к запросу
В стандартном SQL несколько соединений таблиц могут быть объединены для запроса необходимой информации. Эта операция представляет собой объединение таблиц. В Flink SQL также поддерживаются различные запросы гибкого соединения, а рабочими объектами являются динамические таблицы. При потоковой обработке соединение динамической таблицы соответствует операции соединения двух потоков данных. Запросы соединения в Flink SQL обычно можно разделить на две категории: собственный метод запроса соединения SQL и запросы соединения, уникальные для потоковой обработки.
6.1 Общий запрос соединения
Обычное соединение — это метод соединения, определенный в SQL, и наиболее распространенный тип операции соединения. Его конкретный синтаксис точно такой же, как и у стандартного соединения SQL. Две таблицы соединяются посредством ключевого слова JOIN, а ключевое слово ON используется позже для указания условия соединения. В соответствии со стандартным SQL, обычные соединения Flink SQL также можно разделить на внутренние соединения (INNER JOIN) и внешние соединения (OUTER JOIN). Разница заключается в том, содержат ли результаты строки, не соответствующие условиям соединения. В настоящее время в качестве условия соединения поддерживается только «условие эквивалентности», то есть за ключевым словом ON должно следовать логическое выражение, определяющее равенство полей в двух таблицах.
1. ВНУТРЕННЕЕ Equi-JOIN
Внутренние соединения определяются с помощью INNER JOIN, который возвращает комбинацию всех строк в двух таблицах, соответствующих условиям соединения, что является так называемым декартовым произведением. В настоящее время поддерживаются только условия равносоединения. Например:
SELECT *
FROM Order
INNER JOIN Product
ON Order.product_id = Product.id
2. ВНЕШНЕЕ Equi-JOIN
Подобно внутренним соединениям, внешние соединения также возвращают декартово произведение всех строк, соответствующих условиям соединения. Кроме того, строки, которые не могут найти совпадений в одной боковой таблице, также могут быть возвращены отдельно; Flink SQL поддерживает LEFT JOIN, RIGHT JOIN и FULL OUTER JOIN, что означает, что соответственно будут возвращены строки без каких-либо совпадений в левой таблице, правой таблице и двусторонней таблице. Конкретное использование заключается в следующем:
SELECT *
FROM Order
LEFT JOIN Product
ON Order.product_id = Product.id
SELECT *
FROM Order
RIGHT JOIN Product
ON Order.product_id = Product.id
SELECT *
FROM Order
FULL OUTER JOIN Product
ON Order.product_id = Product.id
Эта часть знаний точно такая же, как и в стандартном SQL.
6.2 Запрос на соединение интервалов
Мы изучили соединение двух потоков в API DataStream, включая соединение окон и соединение интервалов. Соединение двух потоков соответствует соединению двух таблиц в SQL, что является уникальным методом соединения при потоковой обработке. В настоящее время Flink SQL не поддерживает соединения окон, но реализованы интервальные соединения. Возвращаемое интервальное соединение также является декартовым произведением двух фрагментов данных, соответствующих ограничениям. Просто помимо обычных условий подключения здесь «ограничительные условия» имеют еще и ограничение по временному интервалу. Конкретный синтаксис имеет следующие моменты:
Объединить две таблицы
Нет необходимости использовать ключевое слово JOIN для интервальных соединений. Просто перечислите две объединяемые таблицы сразу после FROM, разделив их запятыми. Это соответствует синтаксису стандартного SQL и представляет собой «перекрестное соединение», которое возвращает декартово произведение всех строк в двух таблицах.
условие соединения
условие Соединение определяется предложением WHERE и описывается эквивалентным выражением. После перекрестного соединения используйте WHERE для выполнения условной фильтрации, и эффект будет таким же, как INNER. JOIN ... ON ...очень похоже.
ограничение временного интервала
мы можемсуществоватьWHEREпунктсередина,условие После соединений используйте AND, чтобы добавить ограничение временного интервала. Метод заключается в извлечении левой и правой частей; таблицеизвремя Поле,Затем используйте выражение поверхности, чтобы указать интервальные ограничения, которым должны соответствовать эти два объекта. Существует три конкретных метода определения:,Используется здесь соответственноltimeиrtimeповерхность Показать слева и справав таблицеизвремя Поле:
(1)ltime = rtime
(2)ltime >= rtime AND ltime < rtime + INTERVAL '10' MINUTE
(3)ltime BETWEEN rtime - INTERVAL '10' SECOND AND rtime + INTERVAL '5' SECOND
Например, помимо таблицы заказов Order, у нас теперь есть еще и «стол отгрузки» Shipment, доставка которого требует доставки в течение четырех часов после получения заказа. Затем мы можем использовать запрос интервального соединения, чтобы объединить все заказы и соответствующую им информацию о доставке и вернуть их вместе.
SELECT *
FROM Order o, Shipment s
WHERE o.id = s.order_id
AND o.order_time BETWEEN s.ship_time - INTERVAL '4' HOUR AND s.ship_time
7. Функция
В SQL мы можем упаковать некоторые операции преобразования данных и встроить их в SQL-запросы, чтобы вызывать их единообразно. Это называется «функциями». Table API и SQL Flink также предоставляют функциональные функции. Они немного отличаются при вызове: функции в Table API реализуются посредством вызовов методов объектов данных, тогда как SQL напрямую обращается к имени функции и передает данные в качестве параметров; Например, чтобы преобразовать строку str в верхний регистр, Table API записывается путем вызова метода UpperCase() объекта String str:
str.upperCase();
Чтобы написать это на SQL, нужно напрямую указать функцию UPPER() и передать str в качестве параметра:
UPPER(str)
Поскольку API таблиц встроен в язык Java, в класс необходимо добавить множество методов, поэтому расширять функцию затруднительно. В настоящее время поддерживается меньше функций, и API таблиц не так универсален, как SQL; как правило, больше. Используйте экономно. Ниже мы в основном знакомим с использованием функций в Flink SQL.
Функции в Flink SQL можно разделить на две категории: одна — это встроенная системная функция SQL, которую можно вызывать непосредственно через имя функции и которая может реализовывать некоторые распространенные операции преобразования, такие как COUNT() и CHAR_LENGTH(). используется до , UPPER() и т. д.; другой тип функции — это определяемая пользователем функция (UDF), которую необходимо зарегистрировать в среде таблицы, прежде чем ее можно будет использовать.
7.1 Системные функции
Системные функции, также называемые встроенными функциями, представляют собой предварительно реализованные функциональные модули в системе. Мы можем вызвать ее напрямую через фиксированное имя функции для достижения желаемой операции преобразования. Flink SQL предоставляет большое количество системных функций и поддерживает практически все операции стандартного SQL, что обеспечивает нам большое удобство использования SQL для написания программ потоковой обработки.
Flink SQLсерединаиз Системная функция В основном его можно разделить на две категории:Скалярная функция (Скалярная Функции) и агрегатные функции (Агрегатные Functions)。
1. Скалярные функции
Скалярная функция — это функция, которая выполняет только операции преобразования входных данных и возвращает значение. Скалярные функции — самый распространенный и простой тип системных функций. Их огромное количество, и многие из них также определены в стандартном SQL. Поэтому здесь мы перечисляем только некоторые функции некоторых распространенных типов и даем краткий обзор. Для конкретных приложений вы можете проверить полный список функций на официальном сайте.
Функции сравнения
Функция сравнения на самом деле представляет собой выражение сравнения, используемое для определения связи между двумя значениями и возвращающее логическое значение. Это выражение сравнения можно использовать <、>、= Символы равенства соединяют два значения или это может быть своего рода суждение, определяемое ключевыми словами. Например:
(1)value1 = value2 Определить, равны ли два значения;
(2)value1 <> value2 Определить, не равны ли два значения
(3)value IS NOT NULL Определить значение не пусто
Логические функции
Логическая функция — это логическое выражение, использующее И, ИЛИ и НЕ для соединения логических значений. Вы также можете использовать операторы оценки (IS, IS NOT) для выполнения оценок истинностного значения; возвращаемое значение по-прежнему имеет логический тип. Например:
(1)boolean1 OR boolean2 Логическое значение boolean1 и логическое значение boolean2 объединяются логическим ИЛИ.
(2)boolean IS FALSE Определите, является ли логическое значение false
(3)NOT boolean Логическое значение логическое принимает логическое отрицание
Арифметические функции
Функции, выполняющие арифметические вычисления, включая операции, связанные с арифметическими символами, и сложные математические операции. Например:
(1)numeric1 + numeric2 Добавить два числа
(2)POWER(numeric1, numeric2) Операция возведения в степень, возводящая число numeric1 в степень numeric2.
(3)RAND() возврат (0,0, 1.0) Двойное псевдослучайное число внутри интервала
Строковые функции
Функции для обработки строк. Например:
(1)string1 || string2 Объединение двух строк
(2)UPPER(string) Преобразование строки строки в верхний регистр
(3)CHAR_LENGTH(string) Вычислить длину строки string
Временные функции
Функции, выполняющие операции, связанные со временем. Например:
(1)DATE string Проанализируйте строку в соответствии с форматом «гггг-ММ-дд» и верните тип в виде SQL. Date
(2)TIMESTAMP string По формату «гггг-ММ-дд» ЧЧ:мм:сс[.SSS]» анализируется и возвращается в виде SQL. timestamp
(3)CURRENT_TIME Возвращает текущее время в местном часовом поясе, тип — SQL. время (эквивалент МЕСТНОГО ВРЕМЕНИ)
(4)INTERVAL string range Возвращает временной интервал.
2. Агрегатные функции
Агрегатная функция — это функция, которая принимает несколько строк таблицы в качестве входных данных, извлекает поля для операций агрегации и возвращает в качестве результата уникальное агрегатное значение. Функции агрегирования широко используются независимо от групповой агрегации, оконной агрегации или оконной (Over) агрегации, операции агрегирования данных могут быть определены с помощью одной и той же функции. Flink SQL поддерживает общие агрегатные функции в стандартном SQL и в настоящее время расширяется для предоставления более мощных функций для приложений потоковой обработки. Например:
(1)COUNT(*) Возвращает количество всех строк и подсчитывает их.
(2)SUM([ ALL | DISTINCT ] expression) Выполните операцию поиска по определенному полю. По умолчанию ключевое слово ALL опущено, что означает, что поиск осуществляется по всем строкам; если указано DISTINCT, данные будут дедуплицированы, и каждое значение будет накладываться только один раз.
(3)RANK() Возвращает рейтинг текущего значения в наборе значений.
(4)ROW_NUMBER() После сортировки набора значений возвращает номер строки текущего значения.
Среди них RANK() и ROW_NUMBER() обычно используются в окне OVER.
7.2 Пользовательские функции (UDF)
Хотя системные функции огромны, невозможно охватить все функции; если есть требования, которые не поддерживаются системными функциями, для их реализации необходимо использовать пользовательские функции (User Defined Functions, UDF). Table API и SQL Flink предоставляют множество пользовательских интерфейсов функций, определенных в форме абстрактных классов. В настоящее время UDF в основном делятся на следующие категории:
Скалярная функция (Скалярная Функции): Преобразование входного скалярного значения в новое скалярное значение;
Табличная функция (Таблица Функции): Преобразовать скалярное значение в одну или несколько новых строк данных, то есть развернуть в таблицу;
Агрегатная функция (Агрегатная Функции): Преобразование скалярного значения в нескольких строках данных в новое скалярное значение;
Агрегатная функция таблицы (Таблица Aggregate Функции): Преобразование скалярных значений в нескольких строках данных в одну или несколько новых строк данных.
1. Общий процесс вызовахочусуществоватькодсерединаиспользовать Настроитьизфункция,Нам нужно сначала настроить реализацию соответствующего абстрактного класса UDF.,исуществоватьповерхностьсредасерединазарегистрироватьсяэтотфункция,Тогда ты сможешь таблице Вызывается через API и SQL.
(1) Функция регистрации
При регистрации функции необходимо вызвать метод createTemporarySystemFunction() табличного окружения, передав зарегистрированное имя функции и объект Class класса UDF:
// Функция регистрации
tableEnv.createTemporarySystemFunction("MyFunction", MyFunction.class);
Наш собственный класс UDF называется MyFunction и должен представлять собой конкретную реализацию одного из четырех абстрактных классов UDF, описанных выше, и зарегистрируйте его как функцию с именем MyFunction в среде;
(2) Используйте Table API для вызова функций.
В Table API вам нужно использовать метод call() для вызова пользовательской функции:
tableEnv.from("MyTable").select(call("MyFunction", $("myField")));
Здесь метод call() имеет два параметра: один — зарегистрированное имя функции MyFunction, а другой — сам параметр при вызове функции. Здесь мы определяем, что при вызове MyFunction параметром, который необходимо передать, является поле myField.
(3) Вызов функций в SQL
После того, как мы зарегистрировали функцию как системную, вызов в SQL будет точно таким же, как и у встроенной системной функции:
tableEnv.sqlQuery("SELECT MyFunction(myField) FROM MyTable");
Видно, что метод вызова SQL более удобен. Мы по-прежнему будем использовать SQL в качестве примера, чтобы представить использование UDF в будущем.
2. Скалярные функции
Пользовательская скалярная функция может конвертировать 0, 1 или более скалярных значений в скалярное значение. Ее соответствующий вход — это поле в строке данных, а ее выход — уникальное значение. Следовательно, судя по соответствию данных строк во входной и выходной таблицах, скалярная функция представляет собой преобразование «один к одному». Чтобы реализовать пользовательскую скалярную функцию, нам нужно определить класс, наследующий абстрактный класс ScalarFunction, и реализовать метод оценки, называемый eval(). Поведение скалярной функции зависит от определения метода оценки, который должен быть общедоступным и иметь имя eval. Метод оценки eval можно перегружать несколько раз, и любой тип данных можно использовать в качестве параметра и типа возвращаемого значения метода оценки.
Что здесь требует специального объяснения, так это то, что метод eval() не определен в абстрактном классе ScalarFunction, поэтому мы не можем напрямую переопределить его в коде, но базовая структура API таблиц требует, чтобы метод оценки назывался eval(); . Именно здесь Table API и SQL в настоящее время несовершенны, и будущие версии должны быть улучшены. Давайте рассмотрим конкретный пример ниже. Мы реализуем специальную хэш-функцию HashFunction для поиска хеш-значения входящего объекта.
public static class HashFunction extends ScalarFunction {
// Принять любой ввод и вернуть INT тип вывода
public int eval(@DataTypeHint(inputGroup = InputGroup.ANY) Object o) {
return o.hashCode();
}
}
// Функция регистрации
tableEnv.createTemporarySystemFunction("HashFunction", HashFunction.class);
// существовать SQL Вызов зарегистрированной функции в
tableEnv.sqlQuery("SELECT HashFunction(myField) FROM MyTable");
Здесь мы настроили ScalarFunction, реализовали метод оценки eval(), передали объект любого типа и вернули хэш-значение типа Int. Конечно, конкретная хэш-операция опускается, и можно напрямую вызвать метод объекта hashCode().
Также обратите внимание, что поскольку API таблиц необходимо извлечь ссылку на тип параметра метода оценки при анализе функции, мы используем DataTypeHint (inputGroup = InputGroup.ANY) для аннотации типа входного параметра, указывая, что параметр eval может быть любого типа.
3. Табличные функции
Как и скалярная функция, входные параметры табличной функции также могут быть 0, 1 или более скалярными значениями, разница в том, что она может возвращать любое количество строк данных. «Несколько строк данных» фактически составляют таблицу, поэтому «табличную функцию» можно рассматривать как функцию, возвращающую таблицу. Это отношение преобразования «один ко многим». Окно TVF, которое мы представили ранее, по сути, является табличной функцией.
Аналогичным образом, чтобы реализовать пользовательскую табличную функцию, требуется собственный класс, наследующий абстрактный класс TableFunction, а метод оценки с именем eval должен быть реализован внутри. В отличие от скалярных функций, сам класс TableFunction имеет общий параметр T, который представляет собой тип данных, возвращаемых табличной функцией; метод eval() не имеет типа возвращаемого значения, и внутри него нет оператора возврата. метод Collect() для отправки данных строки, которые вы хотите вывести.
Чтобы вызвать табличные функции в SQL, вам необходимо использовать LATERAL TABLE() для создания расширенной «латеральной таблицы», а затем объединить ее с исходной таблицей. Операцией соединения здесь может быть прямое перекрестное соединение (перекрестное соединение), просто используйте запятую для разделения двух таблиц после FROM. Это также может быть левое соединение (LEFT JOIN) с условием ON TRUE;
Ниже приведен конкретный пример табличной функции. Мы реализовали функцию SplitFunction, которая разделяет строки и может преобразовать строку в кортеж (строка, длина).
// Обратите внимание на аннотацию типа. Вывод: Тип строки. Строка содержит два поля: длина слова.
@FunctionHint(output = @DataTypeHint("ROW<word STRING, length INT>"))
public static class SplitFunction extends TableFunction<Row> {
public void eval(String str) {
for (String s : str.split(" ")) {
// Используйте метод Collect() для отправки строки данных.
collect(Row.of(s, s.length()));
}
}
}
// Функция регистрации
tableEnv.createTemporarySystemFunction("SplitFunction", SplitFunction.class);
// существовать SQL Вызов зарегистрированной функции в
// 1. перекрестное соединение
tableEnv.sqlQuery(
"SELECT myField, word, length " +
"FROM MyTable, LATERAL TABLE(SplitFunction(myField))");
// 2. При включении Левое соединение с условием TRUE
tableEnv.sqlQuery(
"SELECT myField, word, length " +
"FROM MyTable " +
"LEFT JOIN LATERAL TABLE(SplitFunction(myField)) ON TRUE");
// Переименование полей в боковых таблицах
tableEnv.sqlQuery(
"SELECT myField, newWord, newLength " +
"FROM MyTable " +
"LEFT JOIN LATERAL TABLE(SplitFunction(myField)) AS T(newWord, newLength) ON TRUE");
Здесь мы непосредственно определяем тип вывода табличной функции как ROW, который является типом данных в полученной боковой таблице, после преобразования каждая строка данных имеет только одну строку; Мы использовали перекрестное соединение и левое соединение для выполнения вызовов SQL соответственно, а также можем переименовать среднее поле боковой таблицы.
4. Агрегатные функции
Определяемая пользователем агрегатная функция (Пользователь Defined AGGregate функция UDAGG) объединяет одну или несколько строк данных (то есть таблицу) в скалярное значение. Это стандартное преобразование «многие к одному». Мы уже много раз сталкивались с концепцией агрегатных функций. SUM(), MAX(), MIN(), AVG() и COUNT() — это распространенные встроенные агрегатные функции системы. А если есть какие-то потребности, которые нельзя прямо назвать Системной функциярешать,мы должны Настроитьагрегатная функция Чтобы реализовать функцию。Настроитьагрегатная функция Необходимо наследовать абстрактный классAggregateFunction。AggregateFunctionЕсть два общих параметра<T, ACC>,Tповерхность представляет собой результат агрегирования.,ACCноповерхностьуказывает на агрегациюизсерединасостояниетип。
Агрегатные функции в Flink SQL работают следующим образом:
(1) Сначала,Требуется создать аккумулятор,используется для хранения агрегатовизсерединамеждурезультат。Это связано сDataStream AggregateFunction в API очень похожа, и аккумулятор можно рассматривать как агрегатное состояние. Вызовите метод createAccumulator(), чтобы создать пустой аккумулятор.
(2) Для каждой строки входных данных вызывается метод накопления() для обновления аккумулятора, что является основным процессом агрегирования.
(3) После обработки всех данных вычислите и верните окончательный результат, вызвав метод getValue().
Следовательно, каждая AggregateFunction должна реализовывать следующие методы:
createAccumulator()
Вот как создать аккумулятор. Если входные параметры отсутствуют, возвращайте тип в виде аккумулятора типаACC.
accumulate()
Это основной метод статистических вычислений, который будет вызываться для каждой строки данных. Его первый параметр определен, это текущий аккумулятор, тип — ACC, указывающий текущее промежуточное состояние агрегации. Следующие параметры — это параметры, передаваемые при вызове агрегатной функции, их может быть несколько, тип также может быть другим; Этот метод в основном обновляет статус агрегации, поэтому не возвращает тип. Следует отметить, что метод накопления() аналогичен предыдущему методу оценки eval() и также требуется базовой архитектурой. Он должен быть общедоступным, а имя метода должно быть накопленным. Его нельзя переопределить напрямую, и его можно реализовать только вручную. .
getValue()
Вот как вы получите конечный результат. Входным параметром является аккумулятор ACCтип, а выходным типом — T.
При обнаружении сложных типов вывод типов Флинком может не дать правильных результатов. Таким образом, AggregateFunction также может специально объявлять тип аккумулятора и возвращать результат, который указывается с помощью двух методов getAccumulatorType() и getResultType(). Все методы AggregateFunction должны быть публичными, а не статическими, а их имена должны быть точно такими, как написано выше. Методы createAccumulator, getValue, getResultType и getAccumulatorType определены в абстрактном классе AggregateFunction и могут быть переопределены, тогда как остальные являются методами, согласованными базовой архитектурой.
Приведем конкретный пример. Мы рассчитываем средневзвешенный балл каждого учащегося из таблицы оценок учащегося ScoreTable.
// Тип аккумулятора Определение
public static class WeightedAvgAccumulator {
public long sum = 0; // взвешенный
public int count = 0; // Количество данных
}
// Настраиваемая функция агрегирования, выходное значение представляет собой среднее значение длинного целого числа, а аккумулятор WeightedAvgAccumulator
public static class WeightedAvg extends AggregateFunction<Long, WeightedAvgAccumulator> {
@Override
public WeightedAvgAccumulator createAccumulator() {
return new WeightedAvgAccumulator(); // Создать аккумулятор
}
@Override
public Long getValue(WeightedAvgAccumulator acc) {
if (acc.count == 0) {
return null; // Не допускать, чтобы делитель был равен 0
} else {
return acc.sum / acc.count; // Рассчитаем среднее и вернёмся
}
}
// Метод накопительного расчета будет вызываться для каждой строки данных.
public void accumulate(WeightedAvgAccumulator acc, Long iValue, Integer iWeight) {
acc.sum += iValue * iWeight;
acc.count += iWeight;
}
}
// Зарегистрируйте пользовательскую агрегатную функцию
tableEnv.createTemporarySystemFunction("WeightedAvg", WeightedAvg.class);
// Вызов функции для расчета средневзвешенного значения
Table result = tableEnv.sqlQuery(
"SELECT student, WeightedAvg(score, weight) FROM ScoreTable GROUP BY student"
);
Метод накопления() агрегатной функции имеет три входных параметра. Первый — это аккумулятор типа WeightedAvgAccum; два других — это поля, вводимые при вызове функции: вычисляемое значение ivalue и соответствующий вес iweight. Здесь мы не рассматриваем реализацию других методов, главное, чтобы было три необходимых метода.
5. Агрегатные функции таблицы.
Определяется пользователемповерхностьагрегатная функция(UDTAGG)Вы можете поместить одну или несколько строк данных(Это одинповерхность)объединиться в другойповерхность,Результат в таблице Может иметь несколько строк и столбцов。Это очевидно,это какповерхностьфункцияиагрегатная функцияизкомбинация,это“многие ко многим”преобразование。Настроитьповерхностьагрегатная функция Необходимо наследовать абстрактный классTableAggregateFunction。TableAggregateFunctionструктураи Принцип иAggregateFunctionочень похоже,такой же Есть два общих параметра<T, ACC>,Используйте аккумулятор ACCтип для хранения промежуточных результатов агрегирования. Три метода, которые необходимо реализовать в агрегатных функциях,В таблицаAggregateFunction также должна быть реализована соответствующим образом:
createAccumulator()
Создать аккумуляторметод,иAggregateFunctionсередина То же использование。
accumulate()
Основной метод расчета агрегатов такой же, как и в AggregateFunction.
emitValue()
все входные строкииметь дело с После завершения,окончательный выводвычислитьрезультатметод。Этот метод соответствуетAggregateFunctionсерединаизgetValue()метод;разницасуществовать ВemitValueнет выводатип,Есть два входных параметра: первый — аккумулятор ACCтип.,Второй — «сборщик» для вывода данных.,еготипдляCollect<T>。кроме того,emitValue()существоватьабстрактный класссередина Нет определения,Невозможно переопределить,Должен быть реализован вручную.Функции агрегирования таблиц относительно сложны, и одним из типичных сценариев их применения являются запросы TOP-N. Например, мы хотим выбрать два лучших после сортировки набора данных. Это самый простой запрос TOP-2. Если готовой системной функции нет, мы можем настроить функцию агрегации таблиц для достижения этой функции. Аккумулятор должен иметь возможность сохранять два текущих наибольших значения. Всякий раз, когда поступает новый фрагмент данных, он сравнивается и обновляется в методе накопления(). Наконец, метод out.collect() вызывается дважды в методе emmitValue() для сохранения значения. первые два вывода. Конкретный код выглядит следующим образом:
// Определение совокупного аккумулятора содержит самые большие первые и вторые данные.
public static class Top2Accumulator {
public Integer first;
public Integer second;
}
// Настройте функцию агрегирования таблиц для запроса двух самых больших чисел в наборе и возврата двоичного кортежа (значение, рейтинг).
public static class Top2 extends TableAggregateFunction<Tuple2<Integer, Integer>, Top2Accumulator> {
@Override
public Top2Accumulator createAccumulator() {
Top2Accumulator acc = new Top2Accumulator();
acc.first = Integer.MIN_VALUE; // Для облегчения сравнения начальное значение указано как минимальное.
acc.second = Integer.MIN_VALUE;
return acc;
}
// Вызывается один раз для каждого фрагмента данных, чтобы определить, следует ли обновлять аккумулятор.
public void accumulate(Top2Accumulator acc, Integer value) {
if (value > acc.first) {
acc.second = acc.first;
acc.first = value;
} else if (value > acc.second) {
acc.second = value;
}
}
// Выведите кортеж (значение, рейтинг) и выведите две строки данных.
public void emitValue(Top2Accumulator acc, Collector<Tuple2<Integer, Integer>> out) {
if (acc.first != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.first, 1));
}
if (acc.second != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.second, 2));
}
}
}
В настоящее время нет возможности напрямую использовать функции агрегирования таблиц в SQL, поэтому вам необходимо использовать API таблиц для вызова:
// Реестрагрегатная функцияфункция
tableEnv.createTemporarySystemFunction("Top2", Top2.class);
// В таблице Вызов функций в API
tableEnv.from("MyTable")
.groupBy($("myField"))
.flatAggregate(call("Top2", $("value")).as("value", "rank"))
.select($("myField"), $("value"), $("rank"));
Здесь используется метод FlatAggregate(), который представляет собой интерфейс, специально используемый для вызова функций агрегирования таблиц. Сгруппируйте и агрегируйте данные в MyTable по полю myField и подсчитайте два поля с наибольшим значением; переименуйте два поля результата агрегирования в значение и ранжирование, а затем используйте select() для их извлечения.
8. Подключение к внешним системам
В программах Flink, написанных с использованием Table API и SQL, вы можете использовать предложение With для указания соединителя при создании таблицы, чтобы вы могли подключаться к внешним системам для взаимодействия с данными. API таблиц и SQL Flink поддерживают множество различных коннекторов. Конечно, самое простое — подключиться к консоли и распечатать вывод:
CREATE TABLE ResultTable (
user STRING,
cnt BIGINT
WITH (
'connector' = 'print'
);
Здесь вам нужно только определить соединитель как печать в With. Для других внешних систем необходимо добавить некоторые элементы конфигурации.
8.1 Kafka
SQL-коннектор Kafka может считывать данные из тем Kafka и преобразовывать их в таблицы, а также записывать данные таблиц в темы Kafka. Другими словами, если при создании таблицы вы укажете соединитель как Kafka, таблицу можно будет использовать либо как входную, либо как выходную таблицу.
1. Введение зависимостей
Если вы хотите использовать коннектор Kafka в программе Flink, вам необходимо ввести следующие зависимости:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
Соединители Flink и Kafka, которые мы здесь представляем, такие же, как и соединители, представленные ранее в API DataStream. Если вы хотите использовать коннектор Kafka в SQL-клиенте, вам также необходимо загрузить соответствующий jar-пакет и поместить его в каталог lib. Кроме того, Flink предоставляет ряд «форматов таблиц» для различных коннекторов, таких как CSV, JSON, Avro, Parquet и т. д. Эти форматы таблиц определяют метод преобразования между базовыми хранимыми двоичными данными и столбцами таблицы, что эквивалентно инструменту сериализации таблицы. Для Kafka поддерживаются основные форматы, такие как CSV, JSON и Avro. В зависимости от формата, настроенного в коннекторе Kafka, нам может потребоваться ввести соответствующую поддержку зависимостей. Возьмем CSV в качестве примера:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
Поскольку в SQL-клиенте уже есть встроенная поддержка CSV и JSON, нет необходимости специально вводить их при использовании для форматов без встроенной поддержки (таких как Avro), все равно необходимо скачать соответствующий jar-пакет.
2. Создайте таблицу, подключенную к Kafka.
Чтобы создать соединение с таблицей Kafka, вам нужно использовать CREATE TABLEизDDLсерединасуществоватьWITHпункт里指定连接器дляKafka,и определить необходимые параметры конфигурации. Вот конкретный пример:
CREATE TABLE KafkaTable (
`user` STRING,
`url` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'events',
'properties.bootstrap.servers' = 'hadoop102:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
)
3. Upsert Kafka
В обычных обстоятельствах Kafka служит очередью сообщений, поддерживающей порядок данных. Как чтение, так и запись должны быть потоковыми данными, что соответствует режиму только добавления в таблицу. Если мы хотим записать таблицу результатов операции обновления (например, групповой агрегации) в Kafka, возникнет исключение, поскольку Kafka не может распознать сообщение об отзыве или обновлении. Чтобы решить эту проблему, Flink специально добавил коннектор «Upsert Kafka». Этот соединитель поддерживает чтение и запись данных в темы Kafka в режиме обновления и вставки (UPSERT). Вот пример создания и использования таблицы Upsert Kafka:
CREATE TABLE pageviews_per_region (
user_region STRING,
pv BIGINT,
uv BIGINT,
PRIMARY KEY (user_region) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'pageviews_per_region',
'properties.bootstrap.servers' = '...',
'key.format' = 'avro',
'value.format' = 'avro'
);
CREATE TABLE pageviews (
user_id BIGINT,
page_id BIGINT,
viewtime TIMESTAMP,
user_region STRING,
WATERMARK FOR viewtime AS viewtime - INTERVAL '2' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'pageviews',
'properties.bootstrap.servers' = '...',
'format' = 'json'
);
-- вычислить pv、uv и вставить в таблица upsert-kafka
INSERT INTO pageviews_per_region
SELECT
user_region,
COUNT(*),
COUNT(DISTINCT user_id)
FROM pageviews
GROUP BY user_region;
8.2 Файловая система
Еще одним очень распространенным типом внешней системы является файловая система. Flink предоставляет соединитель файловой системы, который поддерживает чтение и запись данных из локальных или распределенных файловых систем. Этот коннектор встроен во Flink, поэтому его использование не требует введения дополнительных зависимостей. Вот пример подключения к файловой системе:
CREATE TABLE MyTable (
column_name1 INT,
column_name2 STRING,
...
part_name1 INT,
part_name2 STRING
) PARTITIONED BY (part_name1, part_name2) WITH (
'connector' = 'filesystem', -- тип разъема
'path' = '...', -- путь к файлу
'format' = '...' -- Формат файла
)
Здесь PARTITIONED BY используется перед оператором With для разделения данных. Соединитель файловой системы поддерживает доступ к файлам разделов.
8.3 JDBC
Коннектор JDBC, предоставляемый Flink, может читать и записывать данные в любую реляционную базу данных, например MySQL, PostgreSQL, Derby и т. д., через драйвер JDBC. При записи данных в базу данных в качестве TableSink режим работы зависит от того, определяет ли DDL, создавший таблицу, первичный ключ. При наличии первичного ключа JDBC-коннектор будет работать в режиме обновления-вставки (Upsert) и может отправлять операции обновления (UPDATE) и удаления (DELETE) согласно указанному ключу (ключу) во внешнюю базу данных, если его нет; определен первичный ключ, то он будет работать в режиме добавления, операции обновления и удаления не поддерживаются.
1. Введение зависимостей
Если вы хотите использовать соединитель JDBC в программе Flink, вам необходимо ввести следующие зависимости:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
Кроме того, для подключения к определенной базе данных мы также вводим связанные зависимости драйверов, например MySQL:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
2. Создайте таблицу JDBC.
Метод создания таблицы JDBC такой же, как и в предыдущем Upsert. Кафка почти такой же. Вот конкретный пример:-- Создайте ссылку на Таблица MySQL
CREATE TABLE MyTable (
id BIGINT,
name STRING,
age INT,
status BOOLEAN,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://hadoop102:3306/mydatabase',
'table-name' = 'users'
);
-- поставь еще один стол Данные T записываются в MyTable в таблице
INSERT INTO MyTable
SELECT id, name, age, status FROM T;
Первичный ключ определен в DDL, который создает здесь таблицу, поэтому данные будут записываться в таблицу MySQL в режиме Upsert, а соединение с MySQL определяется через URL-адрес в предложении With.
8.4 Elasticsearch
Как система анализа распределенного поиска, Elasticsearch имеет множество сценариев в приложениях для работы с большими данными. Соединитель Elasticsearch SQL, предоставляемый Flink, можно использовать только в качестве TableSink, который может записывать данные таблицы в индекс Elasticsearch. Использование соединителя Elasticsearch очень похоже на использование соединителя JDBC. Режим записи данных также определяется наличием определения первичного ключа в DDL, создающем таблицу.
1. Введение зависимостей
Хочу Во При использовании коннектора Elasticsearch в программе Флинке необходимо ввести соответствующие зависимости. Конкретные зависимости связаны с версией сервера Elasticsearch. Для версии 6.x Введение. зависимостейследующее:
<dependency>
<groupId>org.apache.flink</groupId> <artifactId>flink-connector-elasticsearch6_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
Для Elasticsearch Для версий 7 и выше представлены следующие зависимости:
<dependency>
<groupId>org.apache.flink</groupId> <artifactId>flink-connector-elasticsearch7_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
2. Создайте таблицу, подключенную к Elasticsearch.
создаватьElasticsearchповерхностьметодиJDBCповерхность В основном то же самое。Вот конкретный пример:
-- Создайте ссылку на Elasticsearch. поверхность
CREATE TABLE MyTable (
user_id STRING,
user_name STRING
uv BIGINT,
pv BIGINT,
PRIMARY KEY (user_id) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://hadoop102:9200',
'index' = 'users'
);
Здесь определяется первичный ключ, поэтому данные будут записываться в Elasticsearch в режиме обновления-вставки (Upsert).
END


Устраните проблему совместимости между версией Spring Boot и Gradle Java: возникла проблема при настройке корневого проекта «demo1» > Не удалось.

Научите вас шаг за шагом, как настроить Nginx.
Это руководство — все, что вам нужно для руководства по автономному развертыванию сервера для проектов Python уровня няни (рекомендуемый сборник).

Не удалось запустить docker.service — Подробное объяснение идеального решения ️

Настройка файлового сервера Samba в системе Linux Centos. Анализ NetBIOS (супер подробно)
Как настроить метод ssh в Git, как получить и отправить код через метод ssh

RasaGpt — платформа чат-ботов на основе Rasa и LLM.

Nomic Embed: воспроизводимая модель внедрения SOTA с открытым исходным кодом.

Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Малые цели имеют очевидные преимущества | ICASSP2023

Урок 1 серии Libtorch: Тензорная библиотека Silky C++

Руководство по локальному развертыванию Stable Diffusion: подробные шаги и анализ распространенных проблем

Полностью автоматический инструмент для работы с видео в один клик: VideoLingo

Улучшения оптимизации RT-DETR: облегченные улучшения магистрали | Support Paddle облегченный rtdetr-r18, rtdetr-r34, rtdetr-r50, rtdet

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | Деформируемое внимание с большим ядром (D-LKA Attention), большое ядро свертки улучшает механизм внимания восприимчивых полей с различными функциями

Создано Datawhale: выпущено «Руководство по тонкой настройке развертывания большой модели GLM-4»!

7B превышает десятки миллиардов, aiXcoder-7B с открытым исходным кодом Пекинского университета — это самая мощная модель большого кода, лучший выбор для корпоративного развертывания.

Используйте модель Huggingface, чтобы заменить интерфейс внедрения OpenAI в китайской среде.

Оригинальные улучшения YOLOv8: несколько новых улучшений | Сохранение исходной информации — алгоритм отделяемой по глубине свертки (MDSConv) |

Второй пилот облачной разработки | Быстро поиграйте со средствами разработки на базе искусственного интеллекта

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция с нулевым кодированием и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

Решенная Ошибка | Загрузка PyTorch медленная: TimeoutError: [Errno 110] При загрузке факела истекло время ожидания — Cat Head Tiger

Brother OCR, библиотека с открытым исходным кодом для Python, которая распознает коды проверки.
Новейшее подробное руководство по загрузке и использованию последней демонстрационной версии набора данных COCO.

Выпущен отчет о крупной модели финансовой отрасли за 2023 год | Полный текст включен в загрузку |

Обычные компьютеры также могут работать с большими моделями, и вы можете получить личного помощника с искусственным интеллектом за три шага | Руководство для начинающих по локальному развертыванию LLaMA-3

Одной статьи достаточно для анализа фактора транскрипции SCENIC на Python (4)

Бросая вызов ограничениям производительности небольших видеокарт, он научит вас запускать большие модели глубокого обучения с ограниченными ресурсами, а также предоставит полное руководство по оценке и эффективному использованию памяти графического процессора!

Команда Fudan NLP опубликовала 80-страничный обзор крупномасштабных модельных агентов, в котором в одной статье представлен обзор текущего состояния и будущего агентов ИИ.

[Эксклюзив] Вы должны знать о новой функции JetBrains 2024.1 «Полнострочное завершение кода», чтобы решить вашу путаницу!
