Поисковая расширенная генерация (RAG) с использованием LlamaIndex, Elasticsearch и Mistral
В этой статье мы рассмотрим, как использовать Elasticsearch в качестве векторной базы данных в сочетании с технологией RAG (генерация поискового расширения) для получения опыта вопросов и ответов. Мы будем использовать LlamaIndex и локально работающую модель Mistral LLM.
Прежде чем начать, давайте разберемся в терминологии.
Объяснение терминологии
LlamaIndex Это ведущая платформа данных для создания приложений LLM (большая языковая модель). LlamaIndex предоставляет абстракции для различных этапов создания приложений RAG (Retrival Augmented Generation). Такие платформы, как LlamaIndex и LangChain, предоставляют уровни абстракции, чтобы приложения не были жестко привязаны к какому-либо конкретному API LLM.
Elasticsearch да Зависит отElasticоказанная услуга。ElasticдаElasticsearchЛидеры отрасли позади,Это механизм поиска и анализа, который поддерживает полнотекстовый поиск для точности, векторный поиск для семантического понимания и гибридный поиск для лучшего из обоих миров. Elasticsearch — полнофункциональная векторная база данных. Функция Elasticsearch, используемая в этой статье, доступна в Tencent Cloud Elasticsearch. Опыт работы в сервисе.
Поисковая дополненная генерация (RAG) да Что-то вродеAIтехнология/модель,Когда LLM предоставляет внешние знания для генерации ответов на Запрос пользователя. Это позволяет адаптировать ответы LLM к конкретным контекстам.,Это делает ответ более конкретным.
Mistral Предоставление оптимизированной модели корпоративного уровня с открытым исходным кодом LLM.В этом уроке,мы будемиспользоватьих модель с открытым исходным кодомmistral-7b,Он может работать на вашем ноутбуке. Если вы не хотите запускать модель локально,Вы также можете выбрать использование их облачной версии.,В этом случае вам необходимо изменить код в этой статье, чтобы использовать правильный ключ API и пакет.
Ollama Помогите запустить LLM на локальном ноутбуке. Мы будем использовать Ollama для локального запуска модели Mistral-7b с открытым исходным кодом.
Вложения Числовое представление значения текста/медиа. Они представляют собой низкоразмерные представления многомерной информации.
Что мы собираемся построить?
Сценарий:
У нас есть образец набора данных (в виде файла JSON) разговора в колл-центре вымышленной компании по страхованию жилья. Мы создадим простое Приложение RAG, которое сможет отвечать на такие вопросы, как:
Дайте мне обзор вопросов, связанных с водой.
процесс высокого уровня
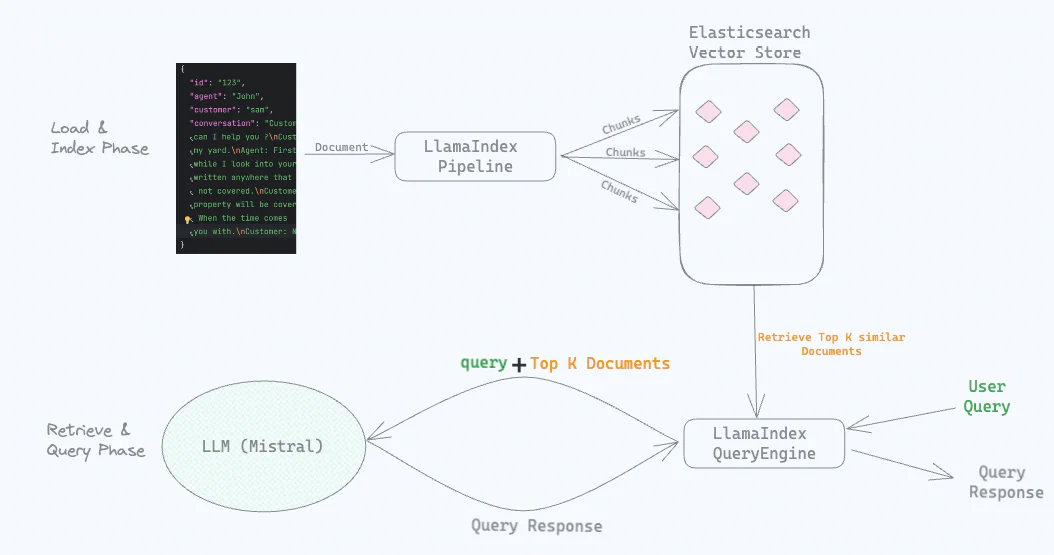
насиспользоватьOllamaсуществовать Запустите Мистраль локально LLM。
Следующий,мы будемотJSONзагрузить в файл“диалог”какдокументВходитьElasticsearchStore(этотдаодин Зависит отElasticsearchПоддерживаемое векторное хранилище)。существоватьнагрузкадокументв то же время,Наше использование локально запускает модель Mistral для создания вложений.,И сохраните его вместе с «разговором» в LlamaIndex Хранилища векторов Elasticsearch.
Мы настроили IngestionPipeline для LlamaIndex и предоставили локальный LLM, который мы использовали в этом случае: Mistral, работающий через Ollama.
Когда мы задаем вопрос типа «Дайте мне обзор проблем, связанных с водой», Elasticsearch выполняет семантический поиск и возвращает «беседы», связанные с проблемами воды. Эти «разговоры» вместе с исходными вопросами отправляются в локальный LLM для получения ответов.
Шаги по созданию приложения RAG
Запустите Мистраль локально
Загрузите и установитеOllama。Установка завершенаOllamaназад,Выполните следующие команды для загрузки и запускаmistral:
ollama run mistralЗагрузка и первый запуск модели локально может занять несколько минут. Убедитесь, что мистраль работает правильно, задав вопросы типа «Напиши стихотворение об облаках» и убедитесь, что стихотворение вам нравится. Нам нужно, чтобы Ollama работала во время последующих взаимодействий с кодом.
Установите Elasticsearch
Путем создания облачного развертывания(Руководство по установке)илисуществоватьdockerвбегая(Руководство по установке)чтобы встать и побежатьElasticsearch。Вы также можете начать сздесьНачните создавать самостоятельный хостинг производственного уровня.Elasticsearchразвертывать。
Предполагая, что вы используете облачное развертывание, следуйте инструкциям, чтобы получить ключ API и идентификатор облака. Мы будем использовать их в последующих шагах.
Приложение RAG
ссылкакод МожетсуществоватьРепозиторий на Гитхабенайден в。Клонировать репозиторийда Необязательныйиз,Потому что мы представим код шаг за шагом ниже.
В вашей любимой IDE создайте новое приложение Python и включите следующие 3 файла:
index.py,и Индексные код, связанный с данными.query.py,код, связанный с взаимодействием ЗапросиLLM..env,Сохранить свойства конфигурации,Например, ключ API.
Нам нужно установить несколько пакетов. Сначала создайте новый Python в корневом каталоге вашего приложения. виртуальная среда。
python3 -m venv .venvАктивируйте виртуальную среду и установите следующие необходимые пакеты.
source .venv/bin/activate
pip install llama-index
pip install llama-index-embeddings-ollama
pip install llama-index-llms-ollama
pip install llama-index-vector-stores-elasticsearch
pip install sentence-transformers
pip install python-dotenvНастройте конечную точку Elasticsearch и ключ API.
Индексные данные
скачатьconversations.jsonдокумент,Он содержит «разговор» между клиентом нашей вымышленной компании по страхованию жилья и агентом колл-центра. Поместите файл в корневой каталог приложения.,Вместе с двумя файлами Python и файлами .env, созданными ранее. Ниже приведен пример содержимого файла.
{
"conversation_id": 103,
"customer_name": "Sophia Jones",
"agent_name": "Emily Wilson",
"policy_number": "JKL0123",
"conversation": «Клиент: Привет, я София. Джонс. Моя дата рождения 15 ноября 1985 года, мой адрес 303. Cedar St, Miami, FL 33101, номер моего полиса JKL0123. \nАгент: Здравствуйте, София. Чем я могу помочь вам сегодня? \nКлиент: Здравствуйте, Эмили. У меня вопрос по поводу моей политики. \nКлиент: В моем доме произошла кража со взломом, и некоторые ценные вещи были потеряны. Эти предметы покрываются страховкой? \nАгент: Позвольте мне проверить покрытие, связанное с кражей, которое покрывает ваш полис. \nАгент: Да, кража личного имущества подпадает под действие вашего полиса. \nКлиент: Это действительно хорошие новости. Мне нужно подать претензию на украденные вещи. \nАгент: Мы поможем вам с процессом подачи претензии, София. Есть ли что-нибудь еще, чем я могу вам помочь? \nКлиент: Нет, на данный момент это все. Спасибо за помощь, Эмили. \nАгент: Пожалуйста, София. Если у вас есть какие-либо другие вопросы или проблемы, пожалуйста, свяжитесь со мной. \nКлиент: Я сделаю это. Хорошего дня! \nАгент: То же самое и с тобой, София. Береги себя. ",
"summary": «Клиент поинтересовался страховкой на украденные вещи после кражи со взломом, и агент подтвердил, что кража личного имущества подпадает под действие полиса. Агент оказал помощь в процессе рассмотрения претензий, а клиент выразил облегчение и благодарность».
}нассуществоватьindex.pyопределяет файл с именемget_documents_from_fileфункция,он читаетjsonдокументисоздаватьодиндокументсписок。документобъектдаLlamaIndexбазовая единица обработки информации。
# index.py
import json, os
from llama_index.core import Document, Settings
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.ingestion import IngestionPipeline
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.vector_stores.elasticsearch import ElasticsearchStore
from dotenv import load_dotenv
def get_documents_from_file(file):
"""Прочитайте файл json и верните список документов"""
with open(file=file, mode='rt') as f:
conversations_dict = json.loads(f.read())
# использовать Создайте объект документа с интересующими полями.
documents = [Document(text=item['conversation'], metadata={"conversation_id": item['conversation_id']}) for item in conversations_dict]
return documentsСоздайте конвейер приема
первый,существовать.envдокументдобавить тебя всуществоватьУстановите Elasticsearchчастично приобретенныйElasticsearch CloudIDиAPIключ。твой.envдокументдолженнравиться Внизпоказано(использоватьистинная ценность)。
ELASTIC_CLOUD_ID=<Заменить натвойоблакоID>
ELASTIC_API_KEY=<Заменить натвойAPIключ>LlamaIndexизПриемный конвейерпозволю тебеиспользовать Несколько компонентов для построения конвейера。Измените следующеекоддобавить вindex.pyдокументсередина。
# index.py
# Загрузите содержимое файла .env в env
# ELASTIC_CLOUD_IDиELASTIC_API_KEY ожидается в файле .env
load_dotenv('.env')
# ElasticsearchStore — это VectorStore, отвечающий за индекс ES и управление данными.
es_vector_store = ElasticsearchStore(index_name="calls", vector_field='conversation_vector', text_field='conversation', es_cloud_id=os.getenv("ELASTIC_CLOUD_ID"), es_api_key=os.getenv("ELASTIC_API_KEY"))
def main():
# Используйте модель внедрения Ollama для локального внедрения.
ollama_embedding = OllamaEmbedding("mistral")
# Конфигурация конвейера LlamaIndex обрабатывает фрагменты, внедрение и сохраняет внедрения в векторном хранилище.
pipeline = IngestionPipeline(transformations=[SentenceSplitter(chunk_size=350, chunk_overlap=50), ollama_embedding,], vector_store=es_vector_store)
# Загрузить данные из файла JSON в список документов LlamaIndex.
documents = get_documents_from_file(file="conversations.json")
pipeline.run(documents=documents)
print("....операция конвейера завершена....\n")
if __name__ == "__main__":
main()Как упоминалось ранее, Приемный рейтинг LlamaIndex конвейер Может состоять из нескольких компонентов。нассуществоватьpipeline = IngestionPipeline(...)Эта линиякоддобавлено в3компоненты。
- SentenceSplitter:нравиться
get_documents_from_file()изопределениепоказано,Каждый документ имеет текстовое поле.,Который содержит разговор в файле JSON. Это текстовое поле представляет собой длинный фрагмент текста. Чтобы семантический поиск работал хорошо,Его необходимо разбить на более мелкие фрагменты текста. Класс SentenceSplitter делает эту работу за нас. Эти блоки называются узлами в терминологии LlamaIndex. Узлы имеют метаданные, указывающие на документ, которому они принадлежат. или,Вы также можете выполнить фрагментацию с помощью Приемного конвейера Elasticsearch.,нравитьсяэтот篇блогпоказано。 - OllamaEmbedding:Модель внедрения преобразует текст в числа(также называется вектором)。С числовым представлением,Мы можем запустить семантический поиск,Результаты поиска соответствуют значению слова,и не толькодатекстовый поиск。насдля Приемный конвейерпредоставил
OllamaEmbedding("mistral")。насиспользоватьSentenceSplitterразделениеиз Блоки отправляются черезOllamaсуществоватьна локальной машинебегатьизMistralМодель,Затем Mistral создает вложения для этих блоков. - ElasticsearchStore:LlamaIndexизElasticsearchStoreХранилище векторов будетсоздаватьиз Встроить хранится вElasticsearchИндексирование。создаватьElasticsearchStoreчас(Зависит от
es_vector_storeЦитировать),наспредоставилнасхочусоздаватьизElasticsearchиндексизимя(существоватьнасизпример子серединадаcalls),нас Хочу сохранить встроитьиз Поле(существоватьнасизпример子серединадаconversation_vector),а такженасхочу存储文本из Поле(существоватьнасизпример子серединадаconversation)。Суммируя,По нашей конфигурации,ElasticsearchStoreсуществоватьElasticsearchсерединасоздавать了один新изиндекс,вconversation_vectorиconversationкак Поле(Есть и другие автоматическиесоздаватьиз Поле)。
объединить все это,нас Позвонивpipeline.run(documents=documents)запустить трубопровод。
бегатьindex.pyскрипт для выполнения Приемный конвейер:
python index.pyПосле завершения запуска трубопровода,насдолженсуществоватьElasticsearchЯ увидел файл с именемcallsиз新индекс。использоватьDev В консоли запустите простой запрос Elasticsearch, и вы сможете увидеть загруженные данные, а также встраиваемые данные.
GET calls/_search?size=1До сих пор мы создавали документы из файлов JSON, разбивали их на фрагменты, создавали внедрения для этих фрагментов и сохраняли внедрения (и текстовый диалог) в векторном хранилище (ElasticsearchStore).
Запрос
llamaIndexизVectorStoreIndexпозволю тебе Поиск по темедокументи Запросданные。По умолчанию,VectorStoreIndexВстрою хранилищесуществовать内存серединаизодинSimpleVectorStore。Однако,ХОРОШОиспользоватьвнешнее векторное хранилище(нравитьсяElasticsearchStore)чтобы сделать встраивание постоянным。
Открытьquery.pyи вставьте следующеекод:
# query.py
from llama_index.core import VectorStoreIndex, QueryBundle, Response, Settings
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.llms.ollama import Ollama
from index import es_vector_store
# Local LLM используется для отправки пользователям Запроса
local_llm = Ollama(model="mistral")
Settings.embed_model = OllamaEmbedding("mistral")
index = VectorStoreIndex.from_vector_store(es_vector_store)
query_engine = index.as_query_engine(local_llm, similarity_top_k=10)
query="Дайте мне обзор проблем, связанных с водой"
bundle = QueryBundle(query, embedding=Settings.embed_model.get_query_embedding(query))
result = query_engine.query(bundle)
print(result)насопределение了один本地LLM(local_llm),Указывает на модель Мистраля, работающую на Олламе. Следующий,насот之前создаватьизElasticsearchStoreвекторное хранилищесоздавать了одинVectorStoreIndex(index),Затем из индекса получаем движок Запрос. При создании движка Запрос,Мы ссылались на местный LLM, который следует использовать для ответа.,насвозвращатьсяпредоставил(similarity_top_k=10)для настройки, должен быть получен из векторного хранилища и отправлен вLLMчтобы получить ответиздокументколичество。
бегатьquery.pyскрипт для выполненияRAGпроцесс:
python query.pyнасотправлять ЗапросДайте мне обзор проблем, связанных с водой.(你Может自Зависит отсделанный на заказquery),Ответ LLM должен быть примерно следующим.
В приведенном контексте мы видели, как несколько клиентов задавали вопросы о страховании от ущерба, причиненного водой. В двух случаях наводнение повредило подвал, а в другом случае проблемой стала протекающая крыша. Агент подтвердил, что оба типа ущерба от воды покрываются их полисом. Поэтому проблемы, связанные с водой, включая наводнение и протечки крыши, обычно покрываются полисами страхования жилья.
Некоторые примечания:
Эта статья в блоге представляет собой введение для начинающих в технологию RAG и Elasticsearch.,Поэтому настройка некоторых функций опущена.,Эти функции позволят вам перейти от этой отправной точки к производственному уровню. При создании сценариев использования в производственных целях,Вы можете рассмотреть более сложные аспекты,Сравниватьнравитьсяможетиспользоватьбезопасность на уровне документазащищатьтвойданные,какElasticsearch Приемный конвейеризвыполнено частичноданные Разбивка на части,или者甚至существоватьиспользуется дляGenAI/Chat/Q&Aвариант использованияизтакой жеданныеначальствобегатьдругойВакансии ML。
Вы также можете рассмотретьиспользоватьЭластичный соединительиз различных внешних источников(примернравитьсяAzure Blob Storage, Dropbox, Gmail и т. д.) для получения данных и создания вставок.
Elastic делает все вышеперечисленное и даже больше возможным, предоставляя комплексное решение корпоративного уровня для сценариев использования GenAI и не только.
Что дальше?
- возможно, ты заметил,Мы отправили в LLM 10 соответствующих разговоров вместе с вопросами пользователей, чтобы сформулировать ответ. Эти разговоры могут содержать PII (личную информацию), такую как имя, дата рождения, адрес и т. д. в нашем случае,LLM является местным,Таким образом, утечка данных не является проблемой. Однако,Если вы хотите использовать LLM, работающий в облаке (например, OpenAI),Отправка текстов, содержащих информацию, позволяющую идентифицировать личность, не рекомендуется. В продолжении блога,Мы увидим, как замаскировать информацию PII в процессе RAG перед ее отправкой во внешний LLM.
- В этом посте мы использовали локальный LLM, а в следующем посте о маскировке данных PII в RAG мы рассмотрим, как легко переключиться с локального LLM на общедоступный LLM.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
