Подробное руководство по Python с использованием библиотеки PyPDF2 для операций с файлами PDF.
введение
PyPDF2 — это мощная библиотека Python для обработки PDF-файлов. Независимо от того, объединяете ли вы несколько файлов PDF, разделяете файлы PDF, извлекаете текст или вращаете страницы, PyPDF2 предоставляет простое и гибкое решение. В этом руководстве будут представлены основные понятия и использование библиотеки PyPDF2, а также поможет вам лучше понять, как выполнять различные операции с файлами PDF в Python.
Часть 1. Установка библиотеки PyPDF2.
Сначала нам нужно установить библиотеку PyPDF2. Его можно установить в вашу среду Python с помощью следующей команды:
bashCopy codepip install PyPDF2Убедитесь, что ваша среда Python настроена и библиотека PyPDF2 может быть успешно установлена.
Часть 2. Объединение PDF-файлов
В этой части мы узнаем, как объединить несколько файлов PDF с помощью библиотеки PyPDF2. Вот простой пример слияния:
pythonCopy codeimport PyPDF2
def merge_pdfs(input_files, output_file):
merger = PyPDF2.PdfFileMerger()
for file in input_files:
merger.append(file)
merger.write(output_file)
merger.close()
# Пример использования
input_files = ['file1.pdf', 'file2.pdf', 'file3.pdf']
output_file = 'merged.pdf'
merge_pdfs(input_files, output_file)Часть 3. Разделение PDF-файлов
Иногда нам нужно разделить большой PDF-файл на несколько файлов меньшего размера. С PyPDF2 это становится очень просто:
pythonCopy codeimport PyPDF2
def split_pdf(input_file, output_files):
pdf_reader = PyPDF2.PdfFileReader(input_file)
for i in range(pdf_reader.numPages):
pdf_writer = PyPDF2.PdfFileWriter()
pdf_writer.addPage(pdf_reader.getPage(i))
output_file = output_files[i]
with open(output_file, 'wb') as output:
pdf_writer.write(output)
# Пример использования
input_file = 'large_file.pdf'
output_files = ['split_1.pdf', 'split_2.pdf', 'split_3.pdf']
split_pdf(input_file, output_files)Часть 4. Извлечение текста PDF
PyPDF2 также позволяет нам извлекать текстовую информацию из файлов PDF. Вот простой пример:
pythonCopy codeimport PyPDF2
def extract_text(pdf_file):
with open(pdf_file, 'rb') as file:
pdf_reader = PyPDF2.PdfFileReader(file)
text = ''
for page_num in range(pdf_reader.numPages):
text += pdf_reader.getPage(page_num).extractText()
return text
# Пример использования
pdf_file = 'sample.pdf'
text_content = extract_text(pdf_file)
print(text_content)Часть 5. Поворот страниц PDF
Иногда нам нужно повернуть определенные страницы в файлах PDF. PyPDF2 предоставляет методы для поворота страниц:
pythonCopy codeimport PyPDF2
def rotate_page(input_file, output_file, page_number, rotation_angle):
pdf_reader = PyPDF2.PdfFileReader(input_file)
pdf_writer = PyPDF2.PdfFileWriter()
for page_num in range(pdf_reader.numPages):
page = pdf_reader.getPage(page_num)
if page_num + 1 == page_number:
page.rotateClockwise(rotation_angle)
pdf_writer.addPage(page)
with open(output_file, 'wb') as output:
pdf_writer.write(output)
# Пример использования
input_file = 'original.pdf'
output_file = 'rotated.pdf'
rotate_page(input_file, output_file, page_number=2, rotation_angle=90)Часть шестая: шифрование и расшифровка PDF-файлов
Используя PyPDF2, вы можете легко шифровать и расшифровывать PDF-файлы. Вот пример шифрования и дешифрования:
pythonCopy codeimport PyPDF2
def encrypt_pdf(input_file, output_file, password):
pdf_reader = PyPDF2.PdfFileReader(input_file)
pdf_writer = PyPDF2.PdfFileWriter()
for page_num in range(pdf_reader.numPages):
pdf_writer.addPage(pdf_reader.getPage(page_num))
pdf_writer.encrypt(password)
with open(output_file, 'wb') as output:
pdf_writer.write(output)
# Пример использования:шифрование
input_file = 'document.pdf'
output_file_encrypted = 'document_encrypted.pdf'
password = 'your_password'
encrypt_pdf(input_file, output_file_encrypted, password)
# Пример расшифровки
def decrypt_pdf(input_file, output_file, password):
pdf_reader = PyPDF2.PdfFileReader(input_file)
pdf_writer = PyPDF2.PdfFileWriter()
if pdf_reader.decrypt(password):
for page_num in range(pdf_reader.numPages):
pdf_writer.addPage(pdf_reader.getPage(page_num))
with open(output_file, 'wb') as output:
pdf_writer.write(output)
else:
print("Incorrect password!")
# Пример использования:Расшифровать
input_file_encrypted = 'document_encrypted.pdf'
output_file_decrypted = 'document_decrypted.pdf'
decrypt_pdf(input_file_encrypted, output_file_decrypted, password)Часть седьмая: добавьте водяной знак
Добавление водяных знаков к существующим PDF-файлам является распространенной необходимостью. Вот простой пример, показывающий, как добавить текстовый водяной знак на каждую страницу с помощью PyPDF2:
pythonCopy codeimport PyPDF2
def add_watermark(input_file, output_file, watermark_text):
pdf_reader = PyPDF2.PdfFileReader(input_file)
pdf_writer = PyPDF2.PdfFileWriter()
watermark = PyPDF2.PdfFileReader(watermark_text)
for page_num in range(pdf_reader.numPages):
page = pdf_reader.getPage(page_num)
page.merge_page(watermark.getPage(0))
pdf_writer.addPage(page)
with open(output_file, 'wb') as output:
pdf_writer.write(output)
# Пример использования
input_file = 'original_document.pdf'
output_file_watermarked = 'document_with_watermark.pdf'
watermark_text = 'watermark.pdf'
add_watermark(input_file, output_file_watermarked, watermark_text)В этом примере предполагается, что водяной знак представляет собой PDF-файл, содержащий текст водяного знака. При необходимости вы можете настроить содержимое и стиль водяного знака.
Часть 8. Вставка новой страницы
Вставка новых страниц в существующие файлы PDF является распространенной необходимостью. Используя PyPDF2, вы можете легко выполнить эту задачу. Вот простой пример:
pythonCopy codeimport PyPDF2
def insert_page(input_file, output_file, page_number, new_page_content):
pdf_reader = PyPDF2.PdfFileReader(input_file)
pdf_writer = PyPDF2.PdfFileWriter()
for page_num in range(pdf_reader.numPages):
if page_num + 1 == page_number:
pdf_writer.addPage(new_page_content)
pdf_writer.addPage(pdf_reader.getPage(page_num))
with open(output_file, 'wb') as output:
pdf_writer.write(output)
# Пример использования
from reportlab.pdfgen import canvas
from PyPDF2.pdf import PageObject
input_file = 'original_document.pdf'
output_file_inserted = 'document_with_new_page.pdf'
# Создать новую страницу
packet = io.BytesIO()
can = canvas.Canvas(packet)
can.drawString(100, 100, "This is a new page")
can.save()
packet.seek(0)
new_page_content = PyPDF2.PdfFileReader(packet).getPage(0)
# Вставить новую страницу
insert_page(input_file, output_file_inserted, page_number=3, new_page_content)В этом примере мы использовали библиотеку ReportLab, чтобы создать новую страницу, содержащую текст, и вставить ее после третьей страницы исходного PDF-файла.
Часть 9: Удаление страницы
Если вам нужно удалить страницы из PDF-файлов, PyPDF2 также предоставляет соответствующие методы. Вот пример удаления страницы:
pythonCopy codeimport PyPDF2
def delete_page(input_file, output_file, page_number):
pdf_reader = PyPDF2.PdfFileReader(input_file)
pdf_writer = PyPDF2.PdfFileWriter()
for page_num in range(pdf_reader.numPages):
if page_num + 1 != page_number:
pdf_writer.addPage(pdf_reader.getPage(page_num))
with open(output_file, 'wb') as output:
pdf_writer.write(output)
# Пример использования
input_file = 'original_document.pdf'
output_file_deleted = 'document_with_page_deleted.pdf'
delete_page(input_file, output_file_deleted, page_number=2)В этом примере мы удалили вторую страницу исходного PDF-файла.
Часть 10. Поворот всего PDF-файла
Иногда нам может потребоваться повернуть весь PDF-файл, а не только определенную страницу. Вот пример поворота всего PDF-файла:
pythonCopy codeimport PyPDF2
def rotate_pdf(input_file, output_file, rotation_angle):
pdf_reader = PyPDF2.PdfFileReader(input_file)
pdf_writer = PyPDF2.PdfFileWriter()
for page_num in range(pdf_reader.numPages):
page = pdf_reader.getPage(page_num)
page.rotateClockwise(rotation_angle)
pdf_writer.addPage(page)
with open(output_file, 'wb') as output:
pdf_writer.write(output)
# Пример использования
input_file = 'original_document.pdf'
output_file_rotated = 'document_rotated.pdf'
rotate_pdf(input_file, output_file_rotated, rotation_angle=180)В этом примере мы поворачиваем весь PDF-файл на 180 градусов против часовой стрелки.


Как настроить размер экрана в PR. Учебное пособие по настройке размера видео в PR [подробное объяснение]
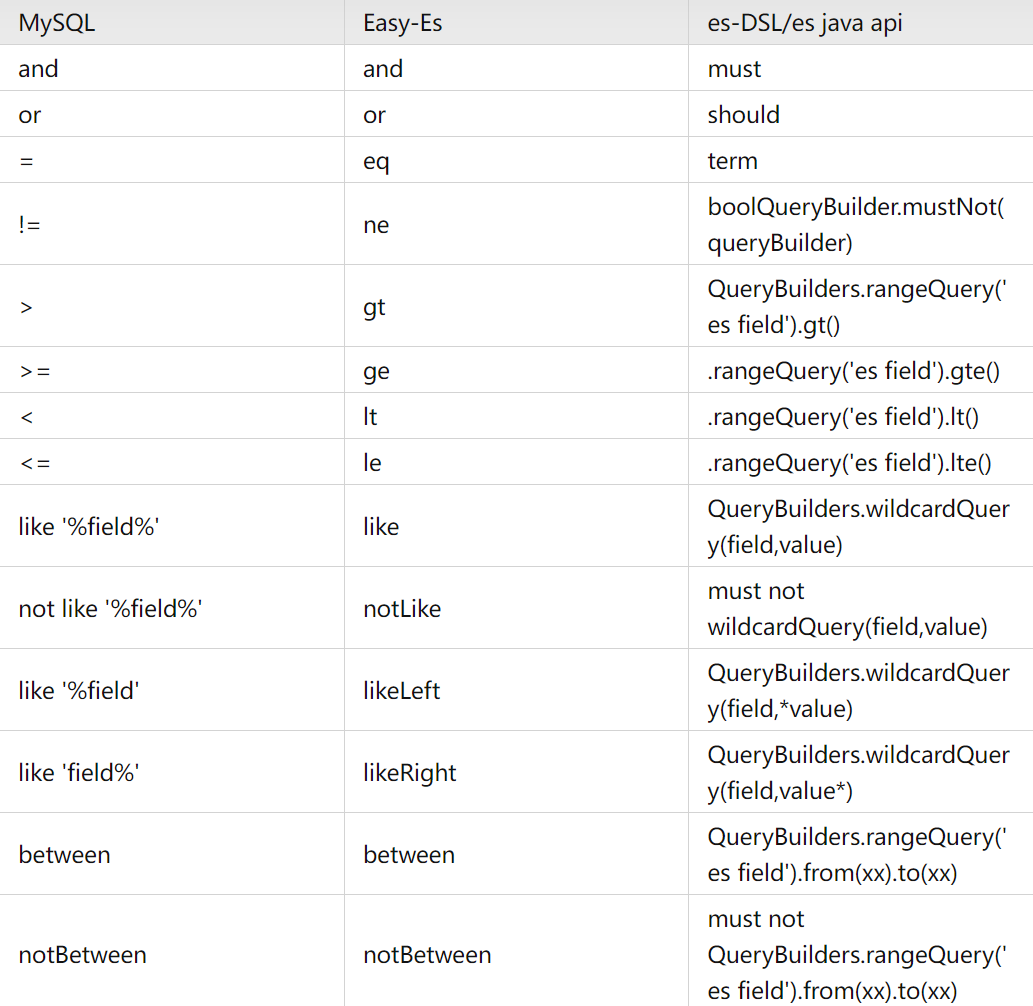
Элегантный и мощный: упростите операции ElasticSearch с помощью easy-es

Проект аутентификации по микросервисному токену: концепция и практика

【Java】Решено: org.springframework.http.converter.HttpMessageNotWritableException.
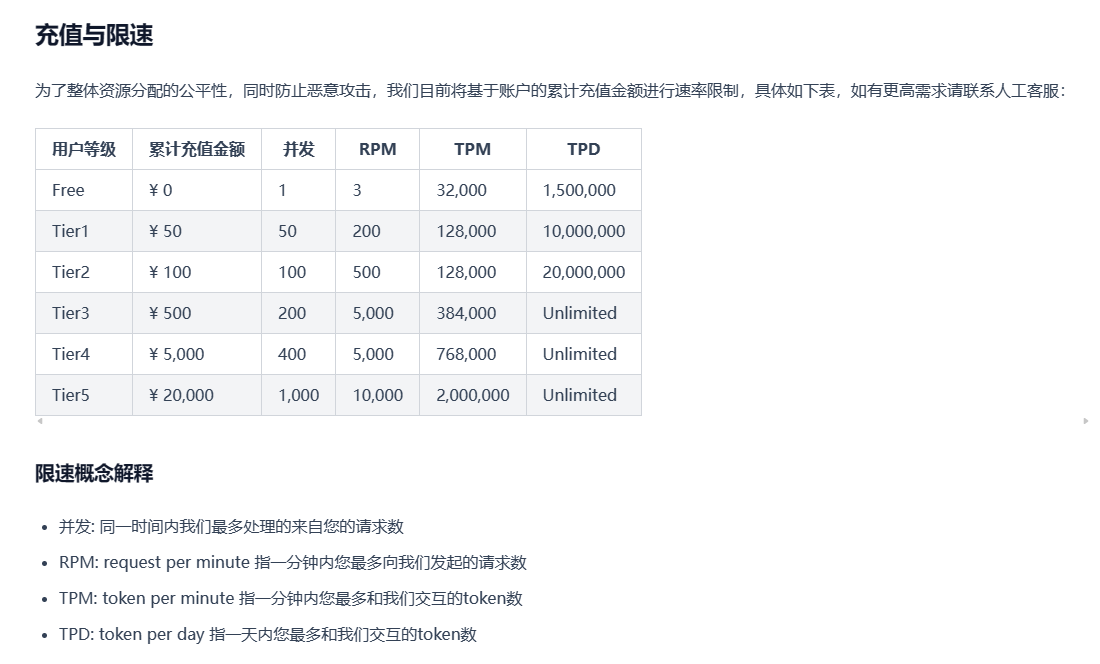
Изучите Kimi Smart Assistant: как использовать сверхдлинный текст, чтобы открыть новую сферу эффективной обработки информации
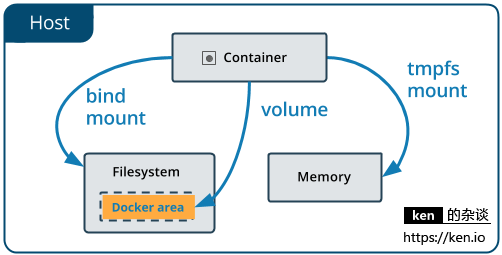
Начало работы с Docker: использование томов данных и монтирования файлов для хранения и совместного использования данных

Использование Python для реализации автоматической публикации статей в публичном аккаунте WeChat
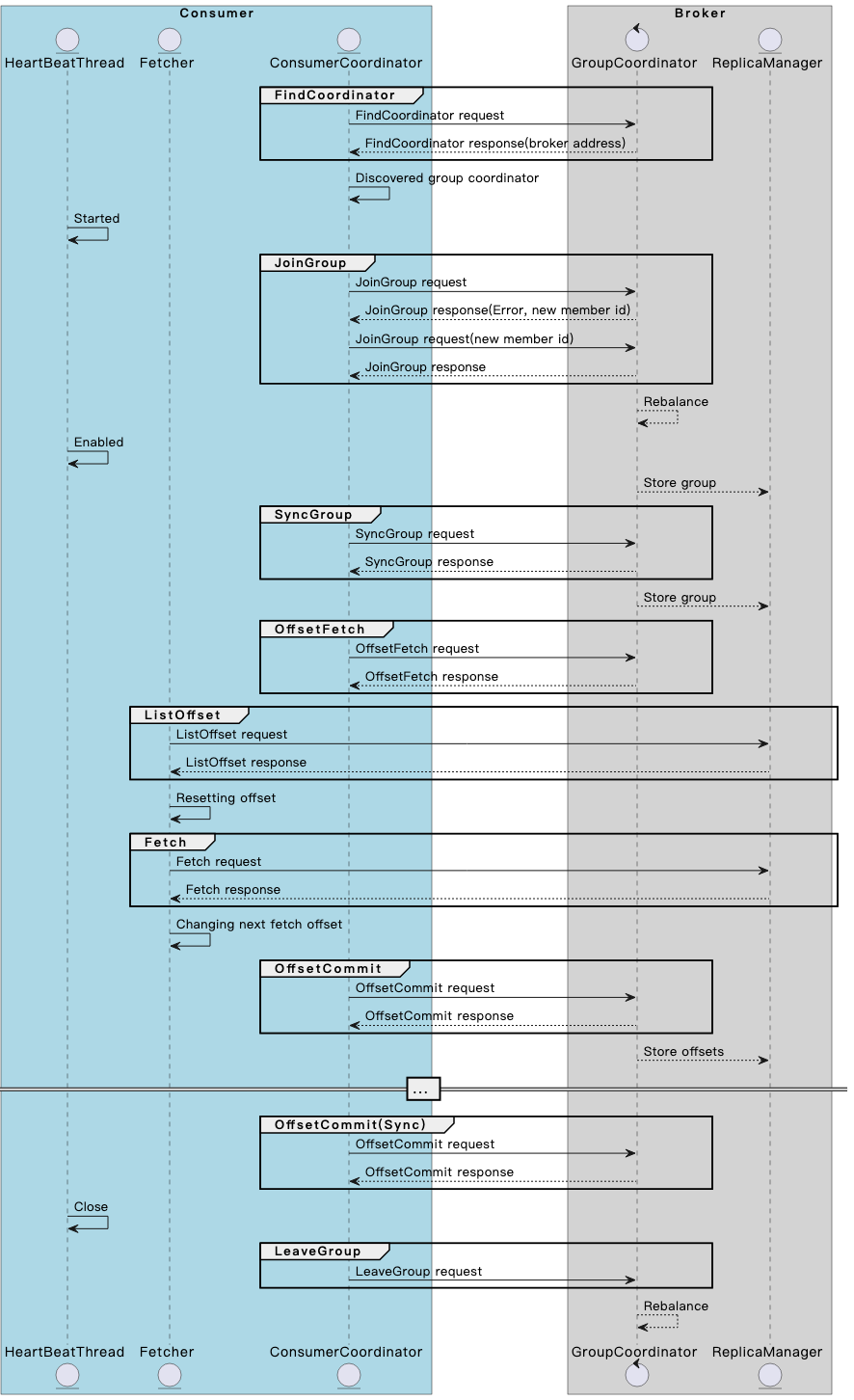
Разберитесь в механизме и принципах взаимодействия потребителя и брокера Kafka в одной статье.
Spring Boot — использование Resilience4j-Circuitbreaker для реализации режима автоматического выключателя_предотвращения каскадных сбоев

13. Springboot интегрирует Protobuf

Примечание. Инструмент управления батареями Dell Dell Power Manager

Общая интерпретация класса LocalDate [java]
[Базовые знания ASP.NET Core] -- Веб-API -- Создание и настройка веб-API (1)
Настоящий бой! Подключите Passkey к своему веб-сайту для безопасного входа в систему без пароля.

Руководство по настройке Nginx: как найти, интерпретировать и оптимизировать настройки Nginx в Linux

Typecho отображает использование памяти сервера

Как вставить элемент перед указанным ключом в ассоциативный массив в PHP

swagger2 экспортирует API как текстовый документ (реализация Java) [легко понять]

Выбор фреймворка nodejs Express koa egg MidwayJS сравнение NestJS

Руководство по загрузке, установке и использованию SVN «Рекомендуемая коллекция»

Интерфейс PHPforwarding_php отправляет запрос на получение

Создавайте и защищайте связь в реальном времени с помощью SignalR и Azure Active Directory.

ВичатПубличная платформаразвивать(три)——ВичатQR-кодгенерировать&Сканировать кодсосредоточиться на
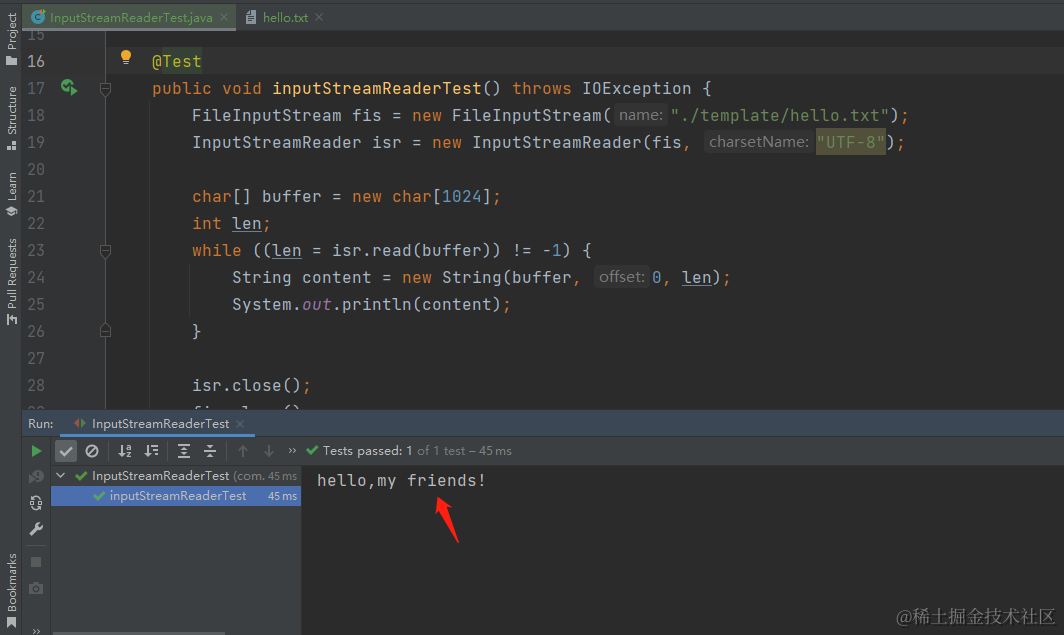
[Углубленное понимание Java IO] Используйте InputStreamReader для чтения содержимого файла и легкого выполнения задач преобразования текста.

сравнение строк PHP
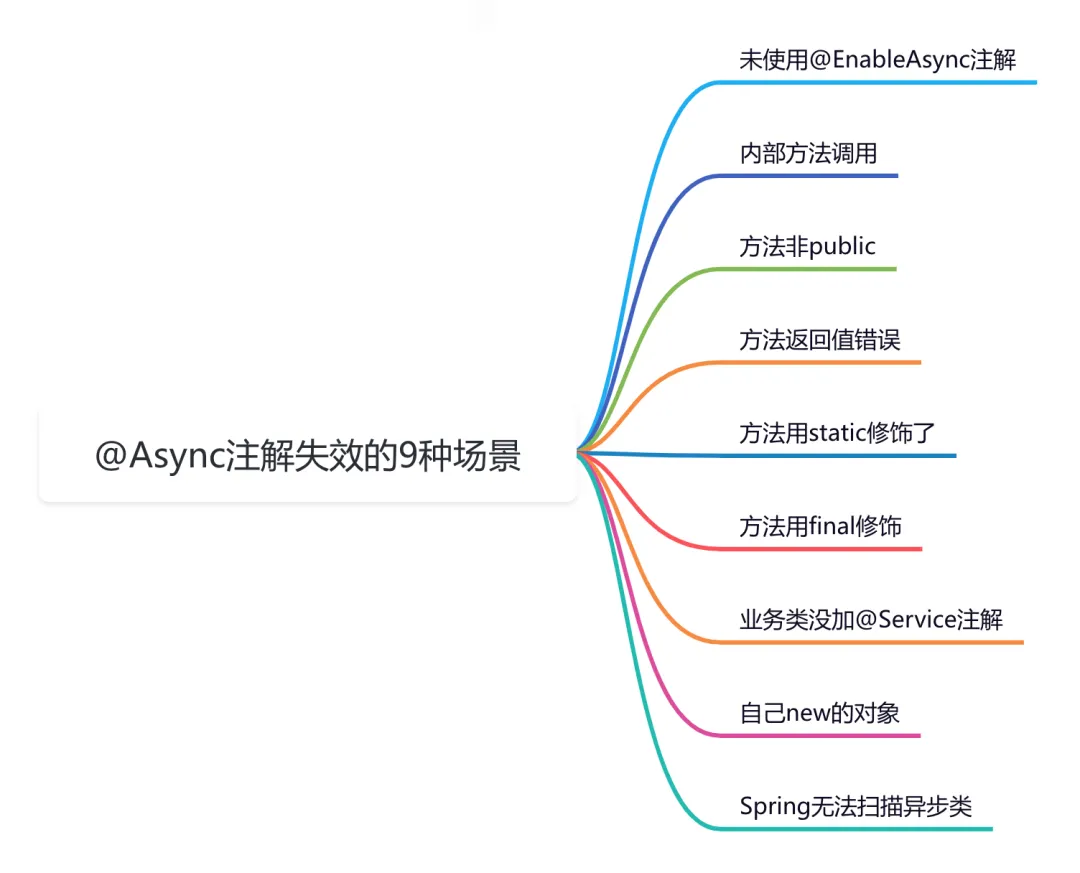
9 сценариев асинхронного сбоя @Async

Эффективная обработка запланированных задач: углубленное изучение секретов библиотеки APScheduler на Python

Рекомендации по облегченному артефакту развязки внутренних компонентов Spring Event (событие Spring)
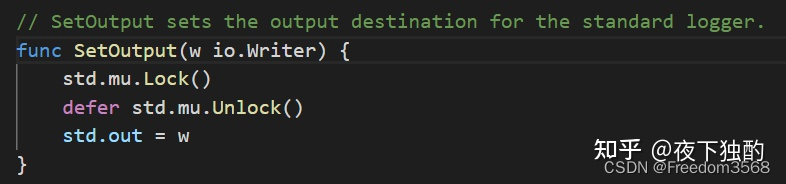
Go: Лесоруб-лесоруб на колесах Введение
