Подробное руководство по использованию стратегий предварительного разбиения для повышения производительности в HBase.
HBase — это платформа на базе системы распределенных баз данных HDFS.,Способен обрабатывать крупномасштабные структурированные и полуструктурированные данные. В отличие от традиционных реляционных баз данных,HBase чрезвычайно масштабируем и имеет высокую пропускную способность.,Способен обрабатывать очень большие данные с миллионами строк и тысячами столбцов. Во многих сценариях больших данных,такие как аналитика в реальном времени и хранение данных Интернета вещей.,HBaseэто очень эффективное решение。HBaseТаблица состоит из несколькихRegionкомпозиция,Регион — это осколок таблицы,Сохраняет определенный диапазон ключей строк. Во избежание горячих точек при записи данных (то есть большое количество операций записи сосредоточено в определенном Регионе),Стратегия предварительного разделенияспособен Создание таблицывыделить несколькоRegion,Тем самым равномерно распределяя операции записи по разным регионам.,Значительно улучшить производительность.
В дизайне таблицы HBase,По умолчанию,Таблица имеет только один регион при ее создании.,Поскольку данные продолжают записываться,Регион достигнет установленного ограничения размера,тогда пройдиАвто-разделение,Разделите данные на новые регионы. Эта стратегия по умолчанию может легко привести к «горячим точкам» при записи больших объемов данных на ранних этапах.,Все операции записи сосредоточены в одном регионе.,Это создает узкое место в производительности.
Чтобы решить эту проблему,Стратегия предварительного разделения(Pre-Splitting)как эффективное средство,существовать Создание В таблице несколько регионов разделены заранее, чтобы избежать горячих точек и обеспечить равномерное распределение операций записи по разным регионам. В этой статье мы углубимся в то, как использовать Стратегию с HBase. предварительного Раздел повышает производительность написания и демонстрирует подробный процесс реализации посредством анализа примеров и кода.
Преимущества стратегии предварительного разбиения HBase
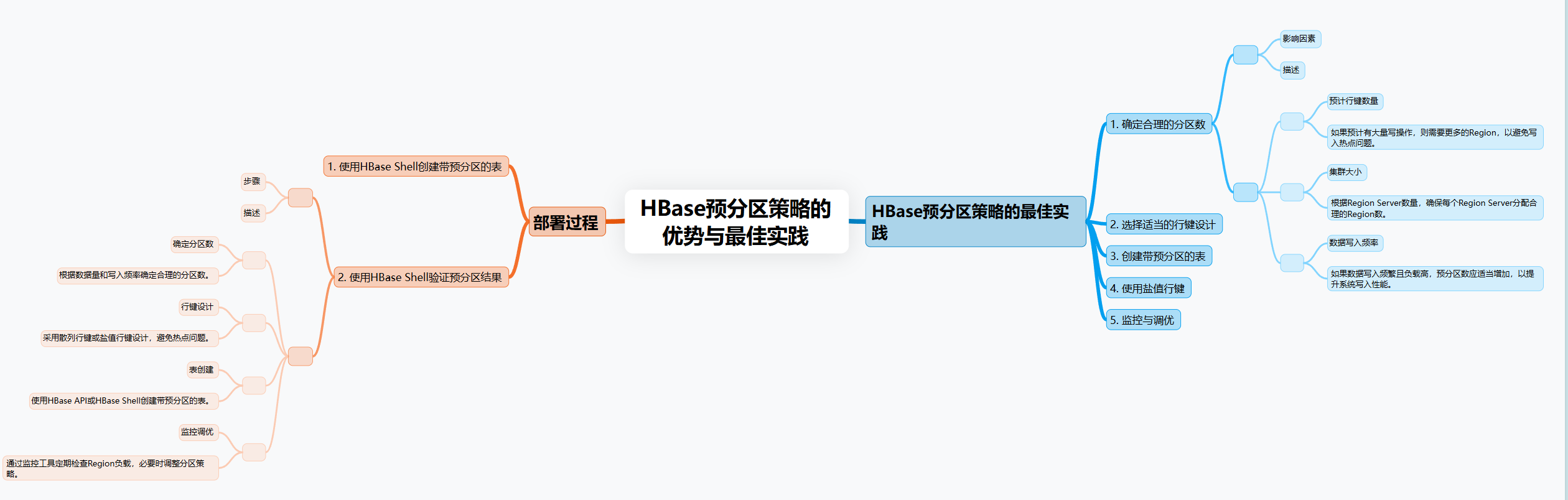
Стратегия предварительного разделения имеет следующие преимущества:
преимущество | описывать |
|---|---|
Избегайте горячих точек записи данных | За счет предварительного разделения регионов запросы на запись распределяются по нескольким регионам, чтобы избежать узких мест в производительности. |
Улучшение производительности записи | Распределение данных становится более равномерным, а запись выполняется на нескольких региональных серверах параллельно, что повышает общую пропускную способность. |
преимущество | описывать |
|---|---|
Оптимизация балансировки нагрузки | Предварительное разделение позволяет равномерно распределять регионы, сокращая накладные расходы на автоматическое разделение и улучшая эффект балансировки нагрузки. |
лучшая масштабируемость | В сценариях с высоким уровнем параллелизма стратегии предварительного разделения помогают обрабатывать крупномасштабные данные и обеспечивать масштабируемость системы. |
Лучшие практики для стратегий предварительного разбиения HBase
- Определите разумное количество разделов
Нам необходимо определить разумное количество разделов в зависимости от ожидаемого объема данных и нагрузки. Число разделов не должно быть слишком малым, чтобы избежать перегрузок, и не должно быть слишком большим, чтобы избежать ненужной траты ресурсов. В целом его можно определить по следующим принципам:
Факторы влияния | описывать |
|---|---|
Примерное количество ключей строк | Если ожидается большое количество операций записи, потребуется больше регионов, чтобы избежать горячих точек записи. |
Размер кластера | В зависимости от количества серверов регионов убедитесь, что каждому серверу региона выделено разумное количество регионов. |
Факторы влияния | описывать |
|---|---|
Частота записи данных | Если данные записываются часто и нагрузка высока, количество предварительных разделов следует соответствующим образом увеличить, чтобы повысить производительность записи системы. |
- Выберите подходящий дизайн клавиш строк
Конструкция ключей строк имеет решающее значение для эффективности предварительного разделения. Вообще говоря,Ключи строк HBase сортируются в словарном порядке.,Если дизайн строк клавиш неуместен (например, увеличение или фиксированный префикс),Приведет к записи определенных конкретных регионов в набор данных.,Это все равно вызовет горячие точки. поэтому,использоватьКлюч хэш-строкиилиключ от соляного рядаможно эффективно избежать этой ситуации。
- Создайте таблицу с предварительным секционированием
HBase предоставляет несколько способов предварительного разделения при создании таблицы. Наиболее распространенным способом является предварительное разделение на основе диапазона ключей строки или пользовательского ключа раздела.
Пример: предварительное разделение на основе диапазона ключей строк
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
public class HBasePreSplitTable {
public static void main(String[] args) throws Exception {
// Настройка соединения HBase
Configuration config = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(config);
Admin admin = connection.getAdmin()) {
// Определите имена таблиц и семейства столбцов
TableName tableName = TableName.valueOf("pre_split_table");
HTableDescriptor tableDescriptor = new HTableDescriptor(tableName);
HColumnDescriptor columnDescriptor = new HColumnDescriptor("info");
tableDescriptor.addFamily(columnDescriptor);
// Настройка предварительного разделения
byte[][] splitKeys = {
Bytes.toBytes("row1000"),
Bytes.toBytes("row2000"),
Bytes.toBytes("row3000"),
Bytes.toBytes("row4000"),
Bytes.toBytes("row5000")
};
// Создайте таблицу с предварительным секционированием
admin.createTable(tableDescriptor, splitKeys);
System.out.println("Table created with pre-split regions.");
}
}
}splitKeysОпределены 5 ключей разделов, разделяющих таблицу на 6 регионов (регион формируется между каждыми двумя ключами разделов).admin.createTable(tableDescriptor, splitKeys)Метод используется для создания таблицы с предварительным секционированием.- Каждый регион будет отвечать за запись данных в соответствующем диапазоне ключей строк, чтобы обеспечить равномерное распределение операций записи.
- использоватьключ от соляного ряда
Чтобы избежать горячих точек, вызванных сортировкой ключей строк, вы можете ввести значения соли, чтобы нарушить порядок ключей строк и равномерно распределить данные.
Пример: дизайн ключа строки значения соли
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseSaltedRowKey {
private static final int SALT_BUCKETS = 10;
public static void main(String[] args) throws Exception {
Configuration config = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(config);
Table table = connection.getTable(TableName.valueOf("salted_table"))) {
// Для записи данных используйте ключ от соляного ряда
for (int i = 0; i < 1000; i++) {
String rowKey = getSaltedRowKey("user" + i);
Put put = new Put(Bytes.toBytes(rowKey));
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"),Bytes.toBytes("имя" + я));
таблица.put(поместить);
}
System.out.println("Данные вставлены с помощью ключей строк с солью.");
}
}
// генерироватьпереключатель от соляного ряда
частная статическая строка getSaltedRowKey (String originalKey) {
int salt = Math.abs(originalKey.hashCode()) % SALT_BUCKETS;
вернуть соль + «_» + originalKey;
}
}SALT_BUCKETSКоличество значений соли определяется и определяет степень дисперсии данных.getSaltedRowKeyМетод генерирует вспомогательное значение из хеш-значения ключа строки и присоединяет его перед исходным ключом строки, нарушая порядок ключей строки.- Такая конструкция гарантирует, что записанные данные могут быть равномерно распределены в разных регионах, избегая горячих точек.
- Мониторинг и настройка
Когда работает кластер HBase, очень важно следить за нагрузкой каждого Региона. Если вы обнаружите, что загрузка некоторых регионов слишком высока или слишком низка, вы можете оптимизировать ее, скорректировав стратегию разделения или вручную разделив/объединив регионы. HBase предоставляет множество инструментов мониторинга и API для просмотра статуса региона и данных о производительности.
Процесс развертывания
В крупномасштабных производственных средах создание таблиц и реализация стратегии предварительного секционирования с помощью HBase Shell или API являются очень распространенными операциями. Ниже описан процесс реализации предварительного разделения с помощью HBase Shell.
- Использование HBase ShellСоздайте таблицу с предварительным секционированием
hbase(main):001:0> create 'pre_split_table', 'info', SPLITS => ['row1000', 'row2000', 'row3000', 'row4000', 'row5000']- Использование HBase Результаты проверки оболочки перед разделением
hbase(main):002:0> describe 'pre_split_table'После выполнения приведенной выше команды вы можете увидеть разделение таблицы, а также ключ начальной и конечной строки каждого региона.
в практическом применении,Предположим, у нас есть платформа электронной коммерции.,Ключ строки данных пользователя — user.ID(нравитьсяuser123)。существовать По умолчанию,HBase расположит эти ключи строк в лексикографическом порядке.,Вызывает запись определенных регионов в наборы данных с ключами закрытия строк.,Вызвать острые проблемы.
По заявке Стратегия предварительного разделения,Мы можем заранее разделить данные идентификатора пользователя на несколько регионов в соответствии с интервалом.,нравитьсяuser1000приезжатьuser2000、user2000приезжатьuser3000ждать,Тем самым равномерно распределяя нагрузку на запись по разным регионам.,Горячих вопросов удалось избежать,И улучшить общую производительность записи.
Правильно разрабатывая ключи строк и применяя стратегии предварительного разделения, HBase может значительно повысить производительность записи, избежать горячих точек и улучшить возможности балансировки нагрузки системы. В реальных производственных средах стратегия предварительного секционирования является одним из важных средств обработки крупномасштабной записи данных.
шаг | описывать |
|---|---|
Определить количество разделов | Определите разумное количество разделов в зависимости от объема данных и частоты записи. |
Дизайн клавиш строки | Используйте ключ хэш-строки или ключ солевой строки, чтобы избежать горячих точек. |
Создание таблицы | Создайте таблицу с предварительным секционированием с помощью HBase API или HBase Shell. |
Мониторинг и настройка | Регулярно проверяйте загрузку региона с помощью инструментов мониторинга и при необходимости корректируйте стратегию разделения. |



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
