Подробное объяснение развертывания, тонкой настройки и сравнительного выбора нескольких распространенных локальных инструментов базы личных знаний большой модели (2)
<h1>большой Модельбоковой инструмент Установить Практика развертывания
Первое, что здесь представлено, — это практика установки и развертывания инструментов на стороне большой модели. Почему мы сначала упоминаем сторону большой модели, а затем сторону базы знаний? Это связано с тем, что большие модели обычно являются основой и ядром операций и приложений базы знаний, а также механизмами, обеспечивающими интеллектуальное принятие решений. Они создают базовую способность понимать и генерировать мультимодальные ответы, такие как текст, изображения и речь, и в то же время являются сердцем всего интеллектуального приложения, поскольку на этот раз речь идет о локальной крупной модели персональной базы знаний. , установка, настройка и оптимизация большой модели. А развертывание — это первый шаг и краеугольный камень обеспечения бесперебойной работы инструмента базы знаний.
Затем я перешел к базе знаний, потому что база знаний — это уровень расширения и оптимизации приложений больших моделей. Они являются мостом между моделью и бизнес-сценарием. Базы знаний, такие как интеграция RAG, позволяют моделям точно находить и извлекать расширенную генерацию, а также улучшать интерактивные вопросы и ответы посредством понимания документов и контекста. База знаний определяет практичность модели посредством объявлений индексов, чтобы модель могла быть ближе к потребностям бизнеса и улучшать взаимодействие с пользователем. Такие инструменты, как MaxKB и Open WebUI, обеспечивают прямую загрузку, управление документами и интегрированные знания, создавая модель. и бизнес-система легко связаны между собой. Следовательно, база знаний является дополнением к большой модели и является ключом к повышению ценности модели в конкретных приложениях, поэтому она вводится после модели.
Короче говоря, сначала за моделью следует база знаний. Это необходимо для того, чтобы следовать логической последовательности технической реализации, от инфраструктуры до оптимизации приложений, чтобы обеспечить глубокое понимание развертывания модели в бизнес-сценариях и постепенное создание модели. эффективная и удобная интеллектуальная система.
<h2>Ollamaразвертывать
<h3>WindowsразвертыватьOllama
Сначала посетите официальный сайт Олламы.
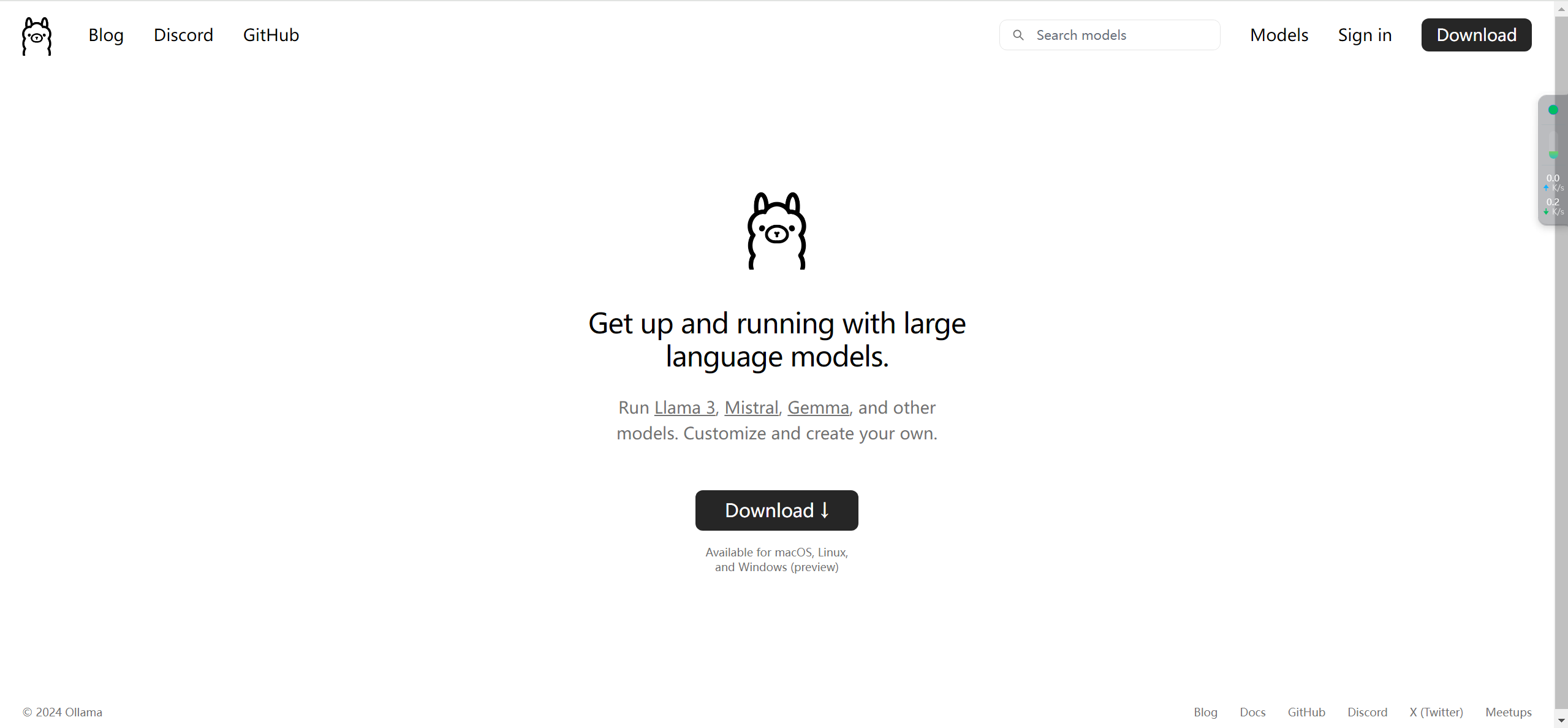
Нажмите «Загрузить» и выберите версию, подходящую для вашего компьютера.
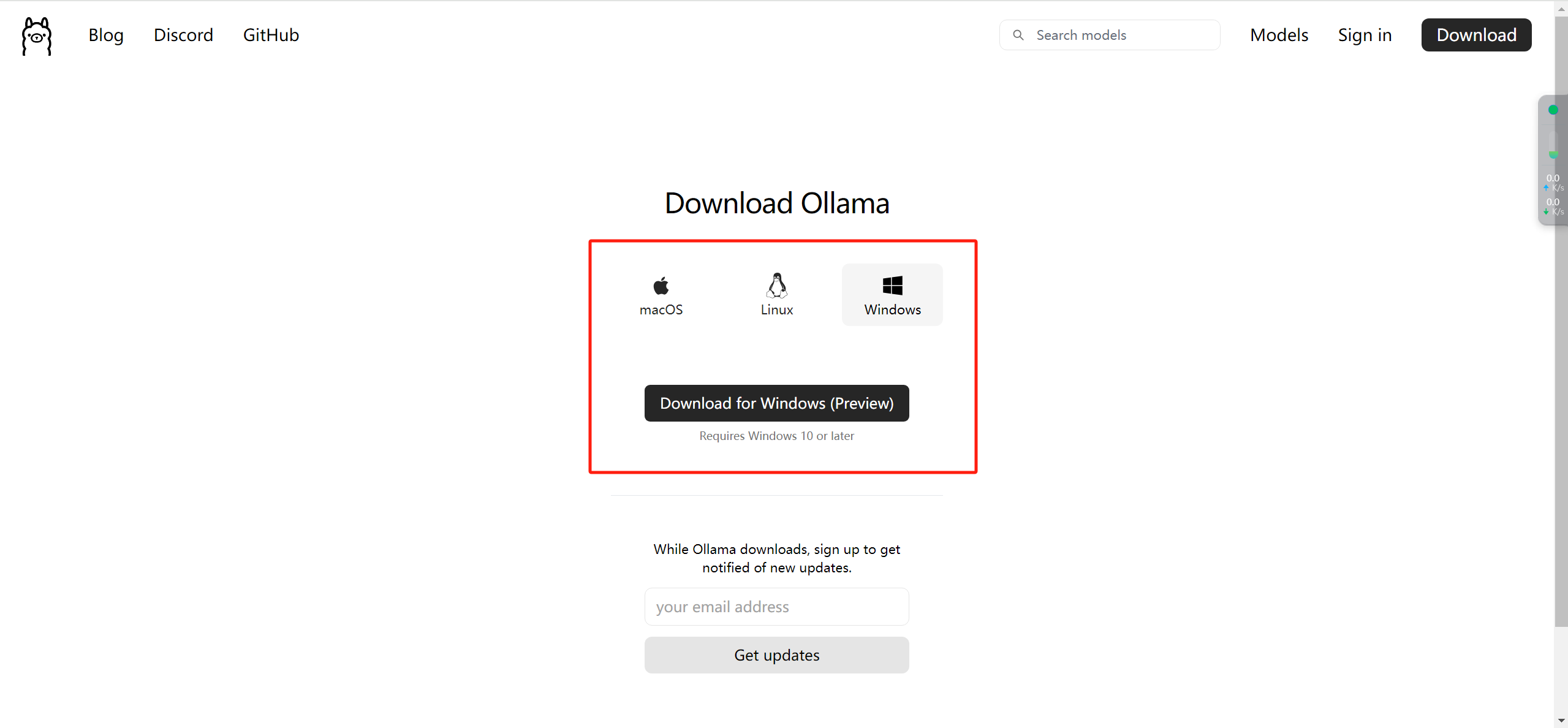
После загрузки Windows на компьютере не выскакивает ярлык метода запуска. Не знаю, ошибка ли это. Обычно я нажимаю на аббревиатуру, чтобы войти в каталог журналов, а затем щелкаю правой кнопкой мыши, чтобы открыть терминал.
Вернитесь на официальный сайт Олламы и нажмите «Модели» в правом верхнем углу.
Вы можете увидеть множество моделей следующим образом:

Когда мы нажимаем llama3, мы видим следующий интерфейс:
Нажмите «Последние», чтобы выбрать тип модели. Рекомендуется запускать 8b для ноутбуков и 70b для серверов (видеокарта ноутбука автора — RTX4070).
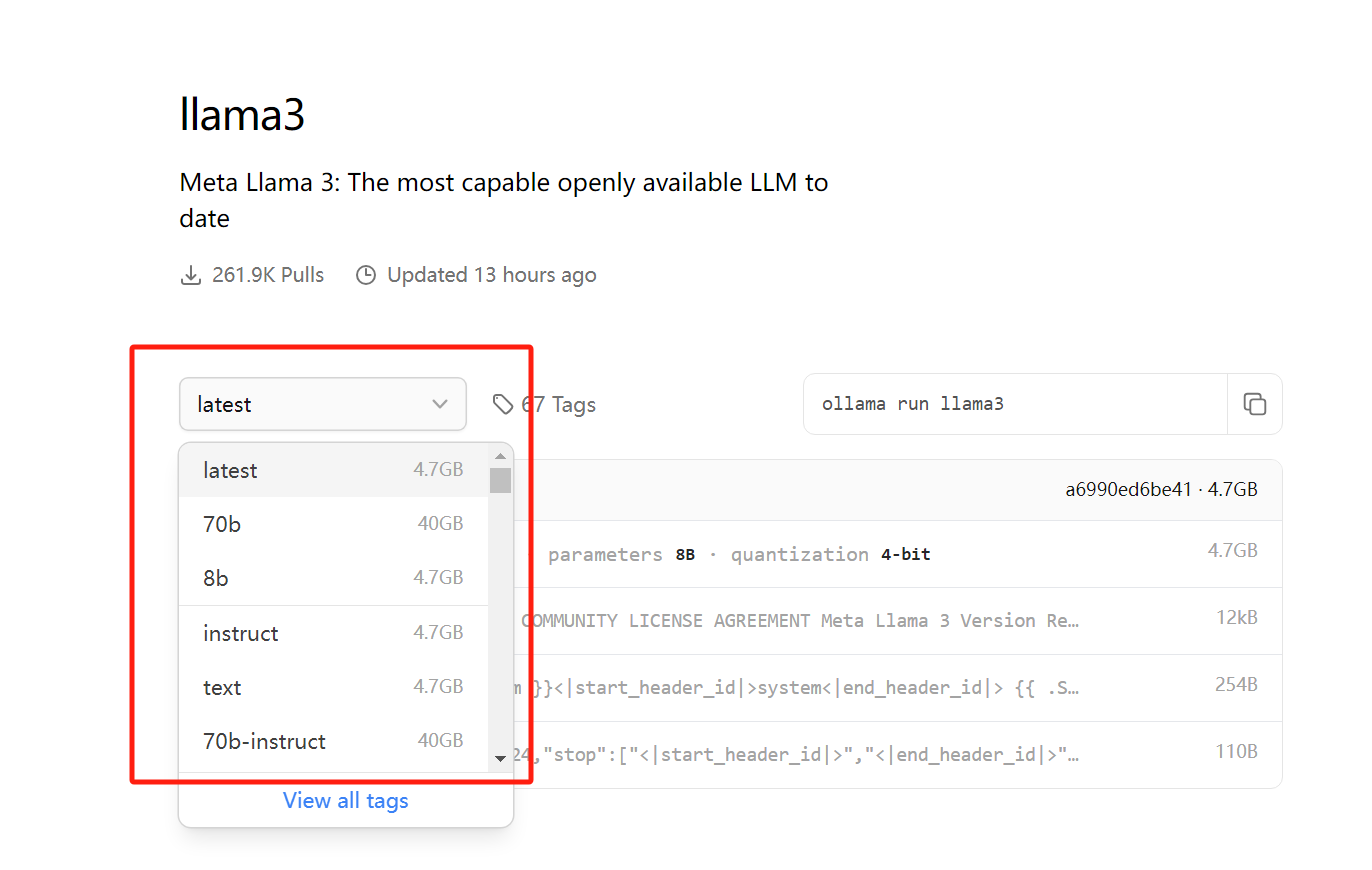
Нажмите кнопку копирования, вставьте командную строку в окно терминала и выполните ее.
ollama run llama3:8b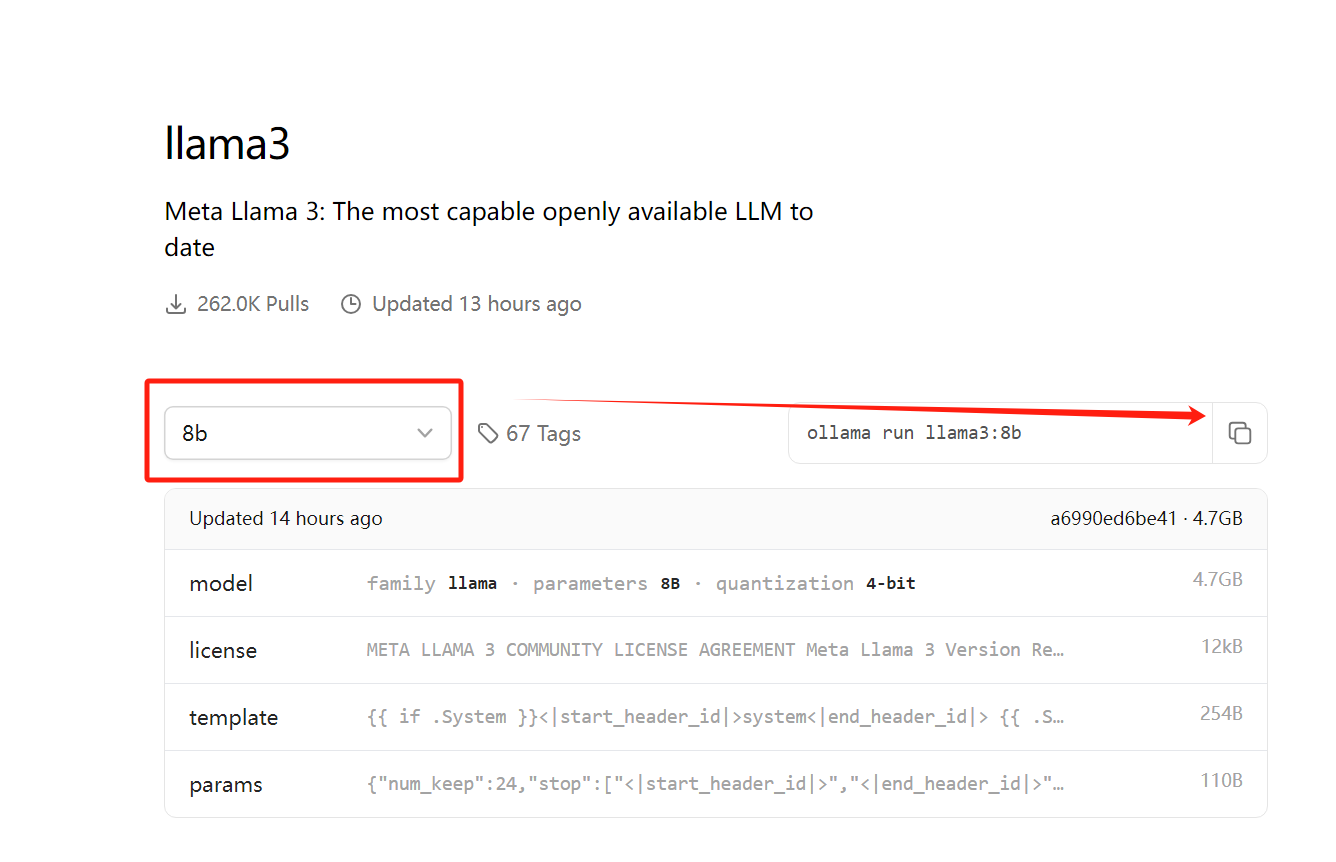
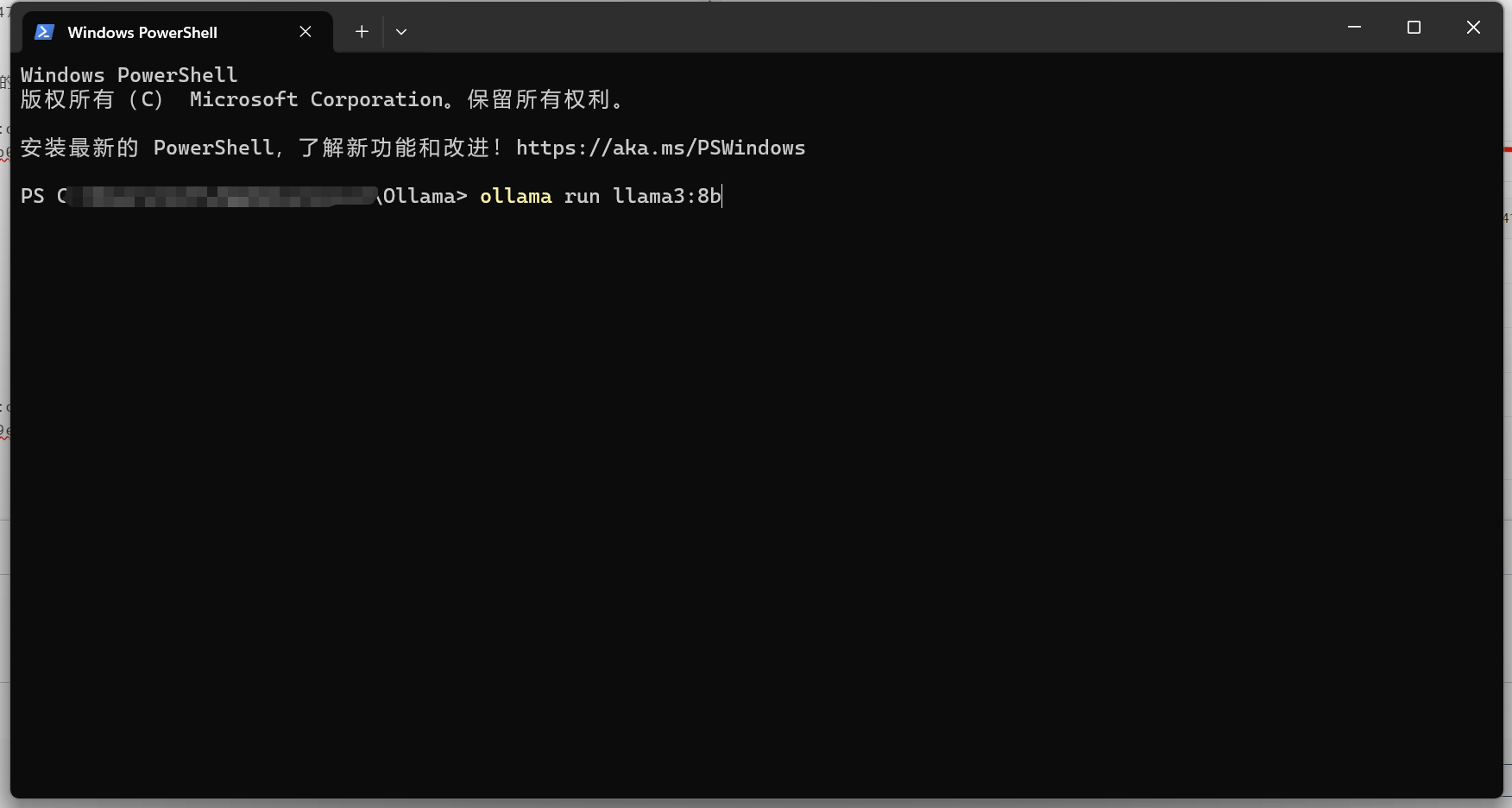
После установки это выглядит так:


Конечно, вы действительно можете использовать Docker для развертывания Ollama в среде Windows, но я не упомянул об этом здесь. Одна из причин заключается в том, что процесс настройки немного затруднителен, а вторая причина заключается в том, что развертывание Docker в Windows потребует определенных усилий. определенное влияние на производительность компьютера. Друзьям, имеющим базовые знания по работе с Linux, не обязательно пробовать это. Просто посмотрите раздел по развертыванию Linux ниже.
<h3>LinuxразвертыватьOllama
существоватьLinuxсреда,Для развертывания Ollama требуется только одна команда. Информацию о базовом построении виртуальной машины на ранней стадии вы можете найти в моих предыдущих статьях.,Операция установки виртуальной машины Linux。
После входа в виртуальную машину откройте командную строку и введите
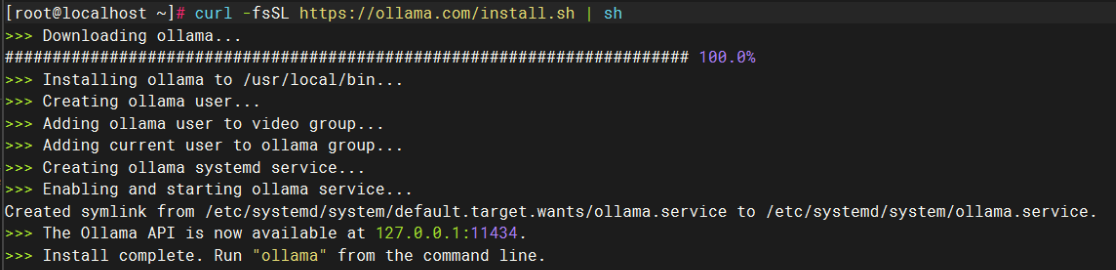
curl -fsSL https://ollama.com/install.sh | shВ это время вам будет предложено обновить пакет.

Выполните следующую команду, чтобы обновить пакет:
sudo apt install curlПосле завершения обновления выполните его еще раз, чтобы начать развертывание и запуск Ollama:
Во время этого процесса весьма вероятно, что произойдет тайм-аут. Вам необходимо изменить файл хостов, создать указатель IP и войти на следующую страницу редактирования:
sudo vim /etc/hostsПосле ввода добавьте следующую конфигурацию:
# github Обратите внимание, что между IP-адресом и именем домена ниже есть пробел.
140.82.114.3 github.com
199.232.69.194 github.global.ssl.fastly.net
185.199.108.153 assets-cdn.github.com
185.199.109.153 assets-cdn.github.com
185.199.110.153 assets-cdn.github.com
185.199.111.153 assets-cdn.github.comЕсли вы повторите попытку, тайм-аут не произойдет напрямую, но поскольку это домашняя среда, скорость все еще не идеальна.
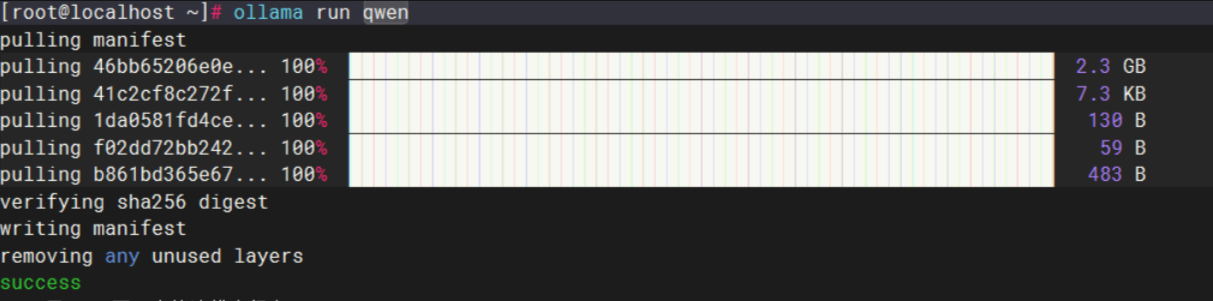
После завершения установки Ollama служба Ollama обычно запускается автоматически, и она автоматически запускается при загрузке. Затем я напрямую запускаю модель Qianwen, и вы можете видеть, что операция прошла успешно.
Помимо прямого развертывания, также поддерживается развертывание с помощью Docker. Автор также рекомендует этот метод.
Первый — установить docker и docker-compose.
sudo apt install docker.io
sudo apt-get install docker-compose
sudo usermod -aG docker $USER
sudo systemctl daemon-reload
sudo systemctl restart docker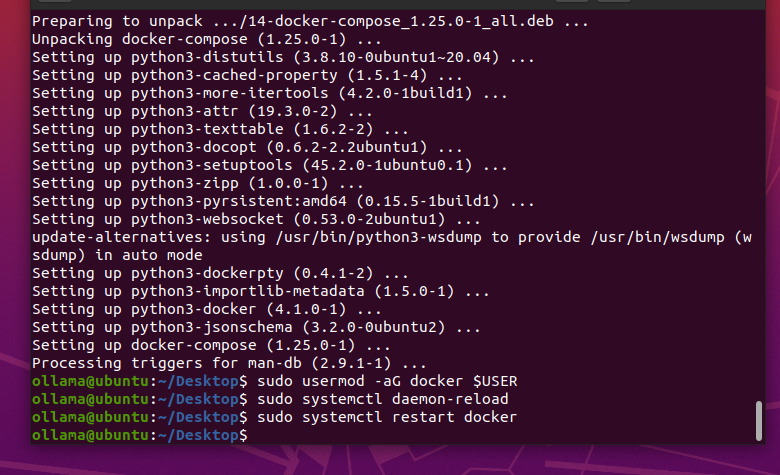
Затем настройте источник внутреннего образа Docker, измените /etc/docker/daemon.json и добавьте следующую конфигурацию:
{
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn",
"https://hub-mirror.c.163.com"
]
}После настройки перезапустите докер.
sudo systemctl daemon-reload
sudo systemctl restart dockerВытащить изображение
docker pull ollama/ollama
В Docker также есть несколько различных режимов запуска (**пожалуйста, измените соответствующий путь в соответствии с реальной ситуацией**):
**Режим процессора**
docker run -d -v /opt/ai/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama**Режим графического процессора (требуется поддержка видеокарты NVIDIA)**
docker run --gpus all -d -v /data/ai/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama**докер развертывает веб-интерфейс ollama**
docker run -d -p 8080:8080 --add-host=host.docker.internal:host-gateway --name ollama-webui --restart always ghcr.io/ollama-webui/ollama-webui:mainНапример, если я запускаю в режиме процессора:

Вы можете получить к нему доступ и просмотреть его через IP-адрес сервера: 11434 в браузере. Как показано ниже, он запускается нормально.
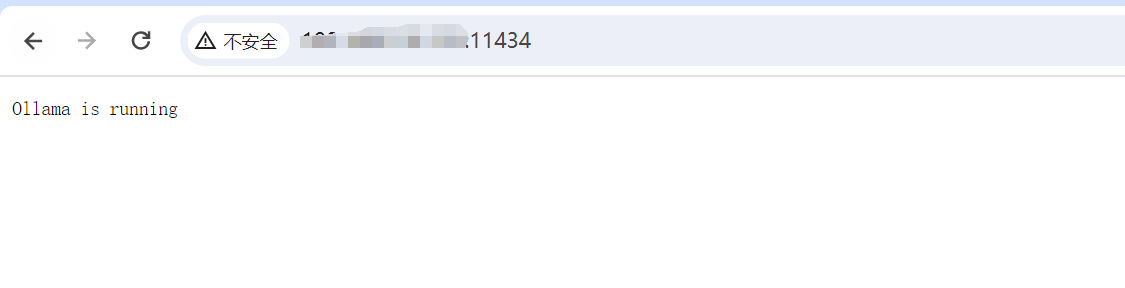
Затем запустите модель:
docker exec -it ollama ollama run llama3
После завершения установки вы можете работать в обычном режиме. Если вы чувствуете, что командная строка выглядит не очень хорошо, вы также можете попробовать развертывание веб-интерфейса, описанное выше.
<h3>OllamaСоветы
<h4>Модель Заменить хранилищепуть
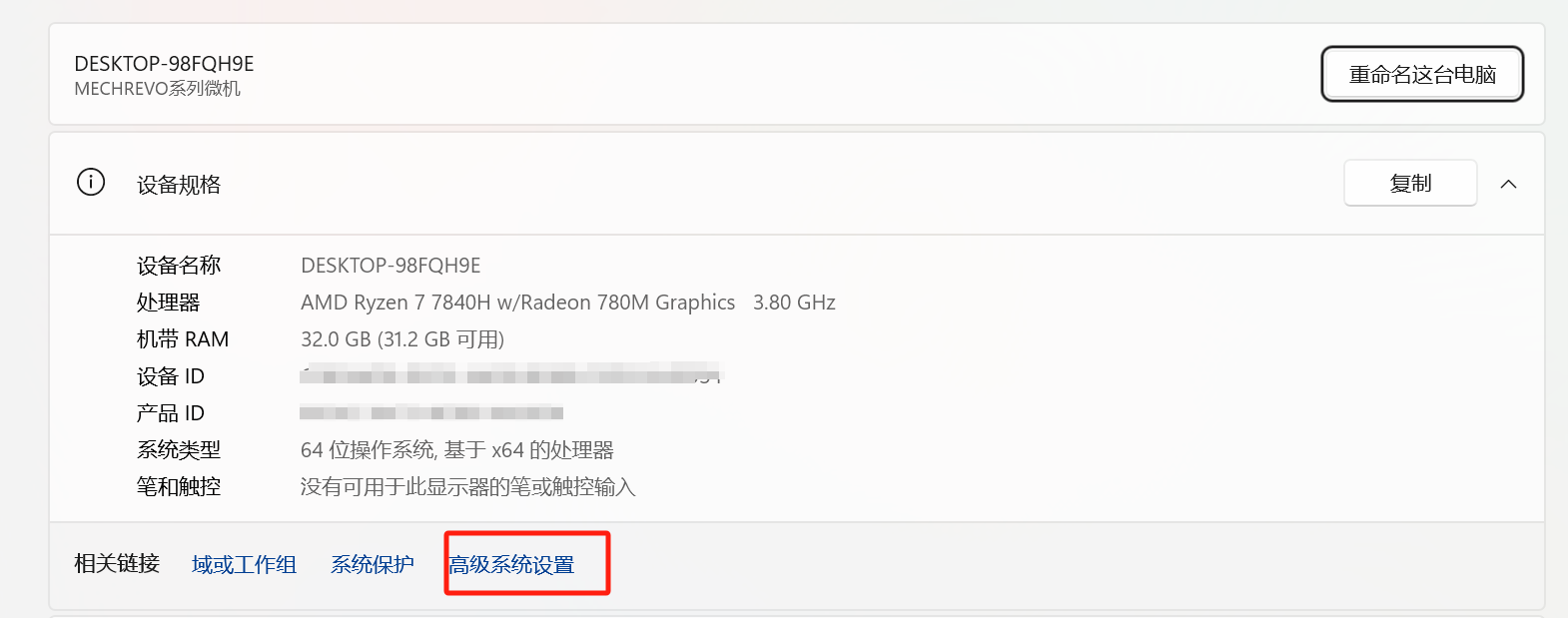
При загрузке в системе Windows очень ненаучный момент заключается в том, что для хранения файлов модели по умолчанию используется диск C. Изначально диска C недостаточно, и скачанная модель потеряет минимум семь-восемь ГБ. Но не паникуйте, мы можем установить местоположение каталога указанной модели, изменив переменную среды.
**【компьютер】——>Щелкните правой кнопкой мыши【свойство】——>【продвинутая системанастраивать】——>【передовой】——>【переменные среды】**
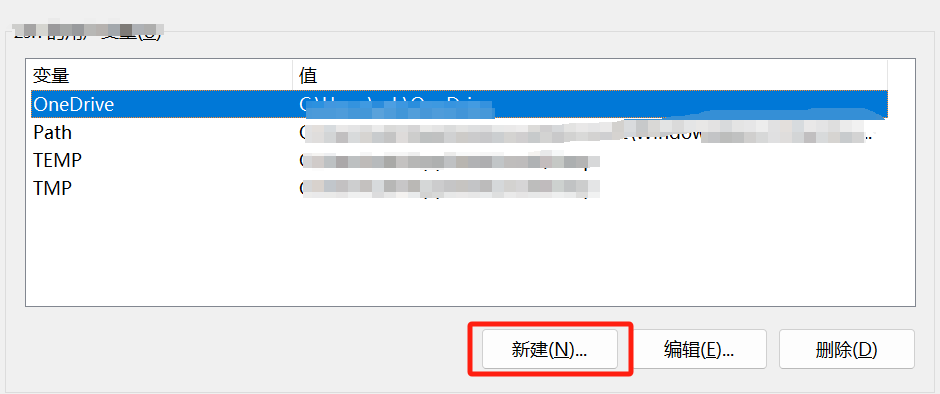
Мы указываем каталог модели, задав переменную среды (OLLAMA_MODELS), которую можно настроить через системные настройки (системные переменные или пользовательские переменные).
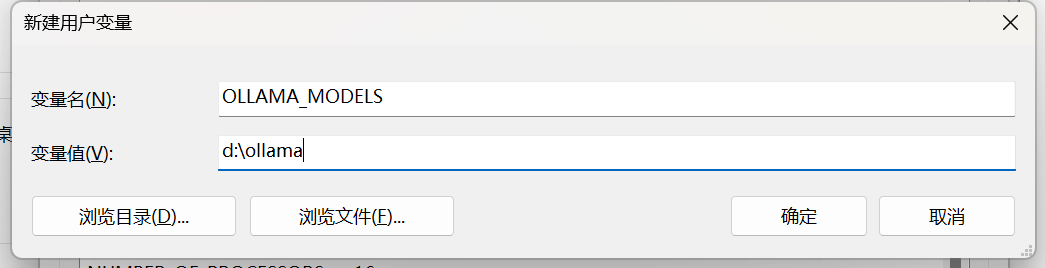
В системах Linux адрес по умолчанию — ~/.ollama/models. Если вы хотите перейти в другой каталог, вы также устанавливаете переменную среды OLLAMA_MODELS:
export OLLAMA\_MODELS=/data/ollama<h4>Экспортировать Модель
В качестве примера мы возьмем llama3:8b. Сначала проверьте информацию о модели:
ollama show --modelfile llama3:8b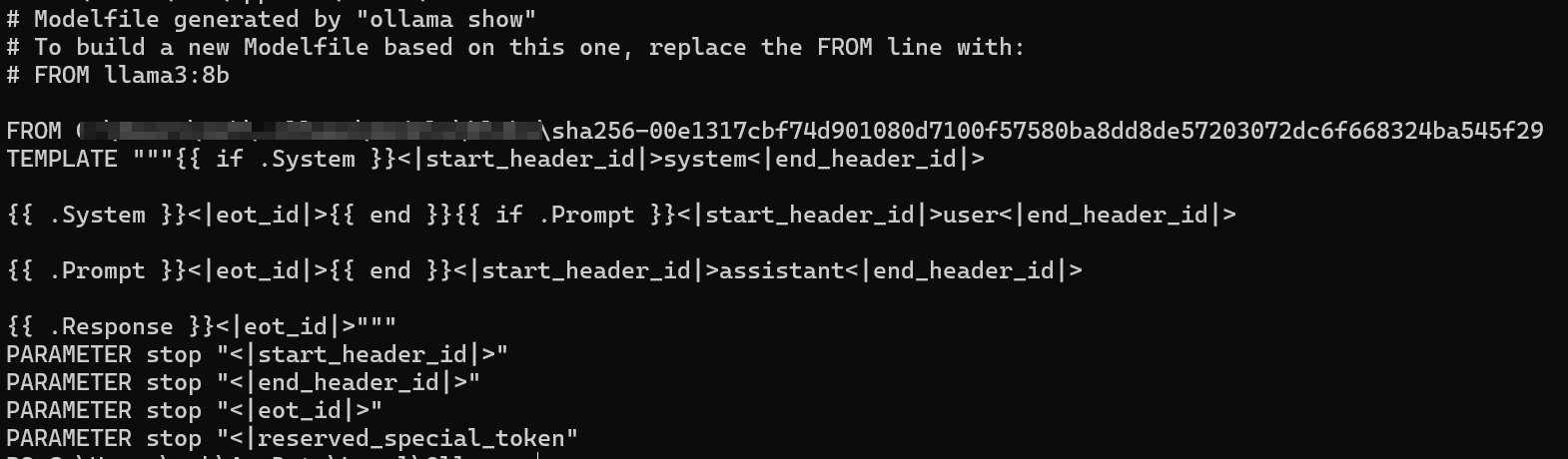
Из информации о файле модели мы знаем, что /xxx/xxx/xxx/xxx/xxx/sha256-00e1317cbf74d901080d7100f57580ba8dd8de57203072dc6f668324ba545f29 — это нужный нам llama3:8b (формат — gguf):
**Система Linux**
cp /xxx/xxx/xxx/xxx/xxx/sha256-00e1317cbf74d901080d7100f57580ba8dd8de57203072dc6f668324ba545f29**Система Windows**
copy /xxx/xxx/xxx/xxx/xxx/sha256-00e1317cbf74d901080d7100f57580ba8dd8de57203072dc6f668324ba545f29<h4>Импортировать Модель
Например, если мы выберем ссылку https://hf-mirror.com/brittlewis12/Octopus-v2-GGUF/tree/main Скачать Octopus-v2.Q8_0.gguf
Подготовьте файл модели
From /path/to/qwen\_7b.ggufЭто самый простой способ. Конечно, вы можете создать полную версию файла модели на основе приведенной выше информации о модели.
# Modelfile generated by "ollama show"
# To build a new Modelfile based on this one, replace the FROM line with:
# FROM qwen:7b
FROM /path/to/qwen\_7b.gguf
TEMPLATE """{{ if .System }}<|im\_start|>system
{{ .System }}<|im\_end|>{{ end }}<|im\_start|>user
{{ .Prompt }}<|im\_end|>
<|im\_start|>assistant
"""
PARAMETER stop "<|im\_start|>"
PARAMETER stop "\"<|im\_end|>\""Не забудьте заменить полный путь к вашей модели. Кроме того, параметры шаблона и остановки у разных моделей разные. Если вы этого не знаете, не записывайте или поищите в Интернете и выполните:
ollama create qwen:7b -f ModelfileПри импорте модели убедитесь, что доступное пространство на жестком диске как минимум в два раза превышает размер модели.
<h3>краткое содержание
Судя по приведенному выше реальному опыту развертывания и использования, могу только сказать, что неудивительно, что Ollama в последнее время стала популярной. Она действительно поразила сердца многих разработчиков (в том числе и меня). С помощью нее можно легко завершить развертывание локальных моделей. Несколько щелчков мыши, эта модель «подключи и работай», полностью изменила области применения крупномасштабных языковых моделей, для участия в которых раньше требовалась глубокая техническая подготовка, что позволило реализовать больше идей и проектов. Кроме того, он также предоставляет богатый выбор моделей. Число библиотек моделей, поддерживаемых в Ollama, достигло 92, охватывая широкий спектр потребностей от фундаментальных исследований до промышленных приложений, и даже включена последняя версия qwen2.
С точки зрения использования, хотя Ollama не предоставляет прямого визуального способа извлечения моделей одним щелчком мыши, я думаю, что это приемлемо из-за его кратких команд и понятного руководства.
Подводя итог, можно сказать, что Ollama действительно является инструментом для больших моделей с **удобным развертыванием моделей**, **богатыми ресурсами моделей** и **высокой масштабируемостью**. По состоянию на 8 июня 2024 г. я по-прежнему считаю, что это лучший вариант. **лучший выбор** для локального развертывания больших моделей.
<h2>LM Развертывание студии
<h3>WindowsразвертыватьLM Studio
ВходитьОфициальный сайт студии LM,Загрузка занимает около минуты,Нажмите [Загрузить LM Studio для Windows]:
Эта скорость загрузки действительно заставляет меня замолчать:
После окончательной загрузки я также предоставлю здесь ресурсы Baidu Cloud, чтобы друзья не отвлекались:
Код извлечения: ниго

Нажмите, чтобы начать напрямую, интерфейс выглядит следующим образом:
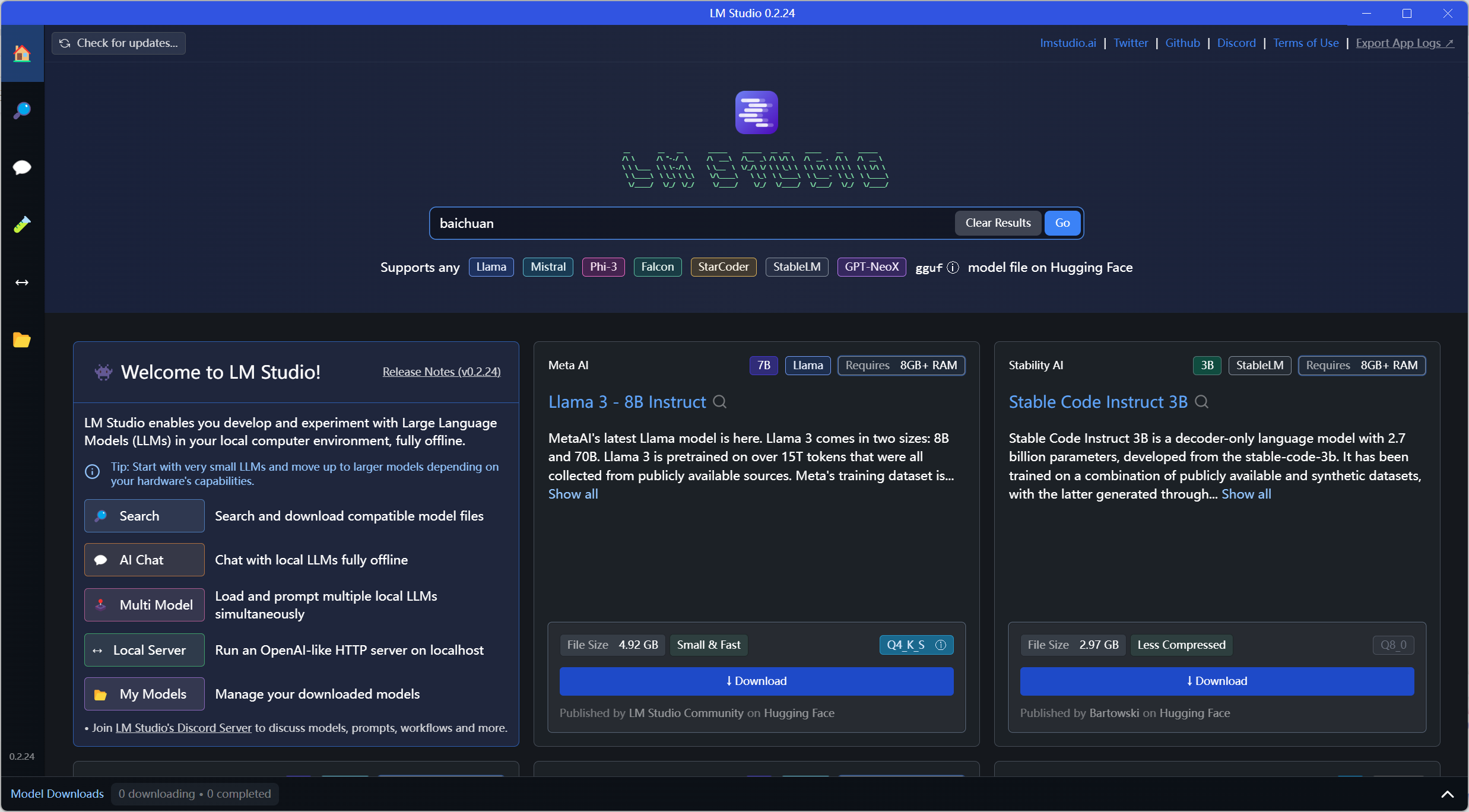
- Главная страница: область главного экрана,Порекомендуйте различные типы больших моделей позже.
- Поиск: Найдите и загрузите все виды больших моделей.
- AI Chat: область диалога модели
- Мультимодель: диалоги с несколькими моделями, видеопамять должна быть 24G+.
- Local Server:создаватьwebСлужить
- My Модели: Скачанные Модели в документе по настройке
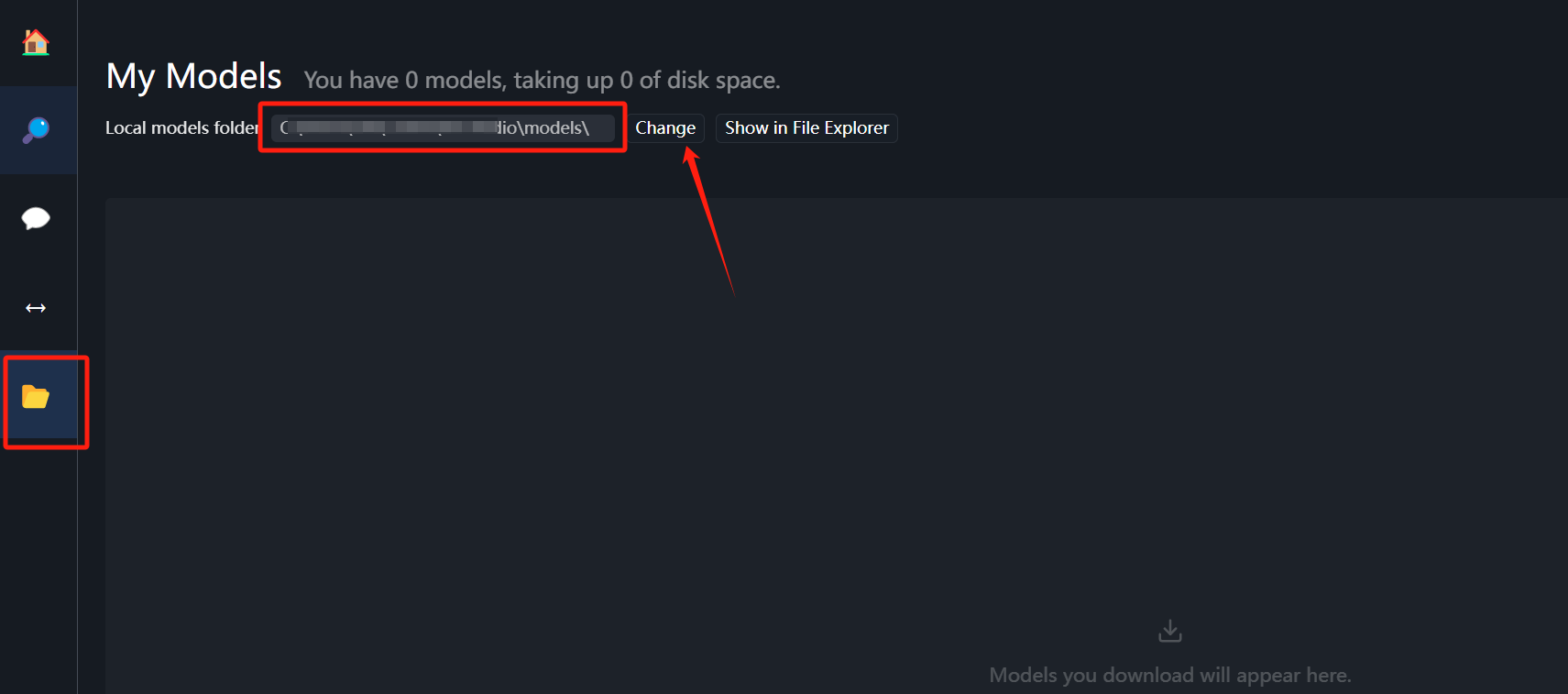
Сначала заходим в папку и меняем путь загрузки модели на диск D:
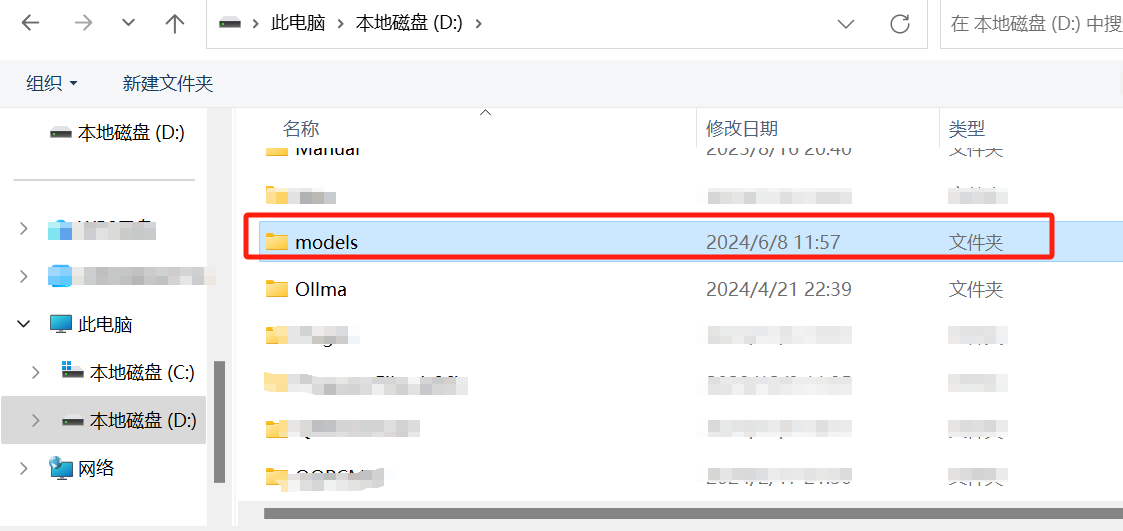
Структура каталогов должна быть создана на диске D:
D:\models\Publisher\RepositoryНо если нажать **Изменить**, можно выбрать собственный путь к слою /models.

Чтобы просмотреть различные большие языковые модели, потяните вниз прямо в главном интерфейсе. Однако для загрузки некоторых моделей может потребоваться посещение иностранных веб-сайтов:
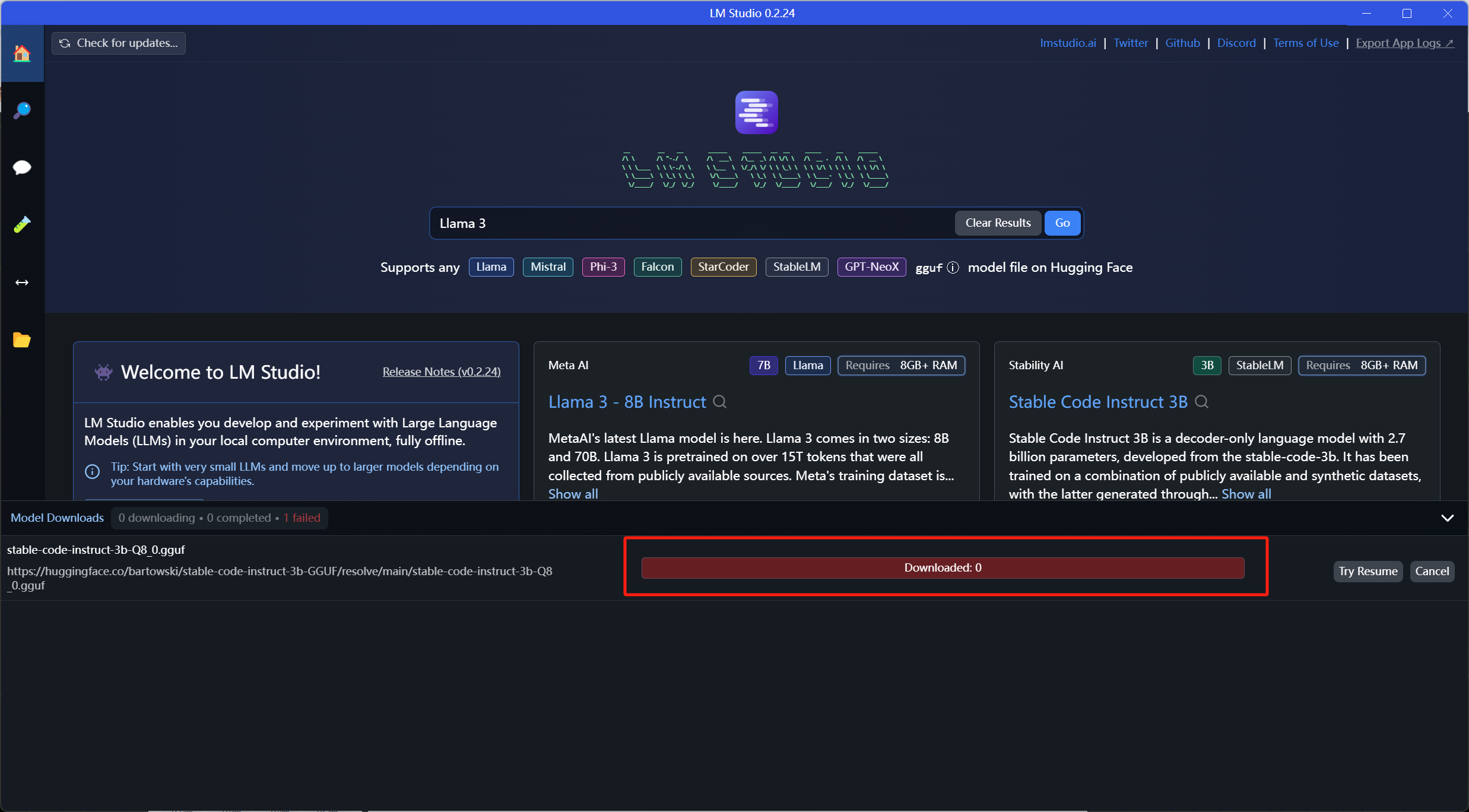
В то же время вы также можете напрямую найти модель, которую хотите скачать, в строке поиска:
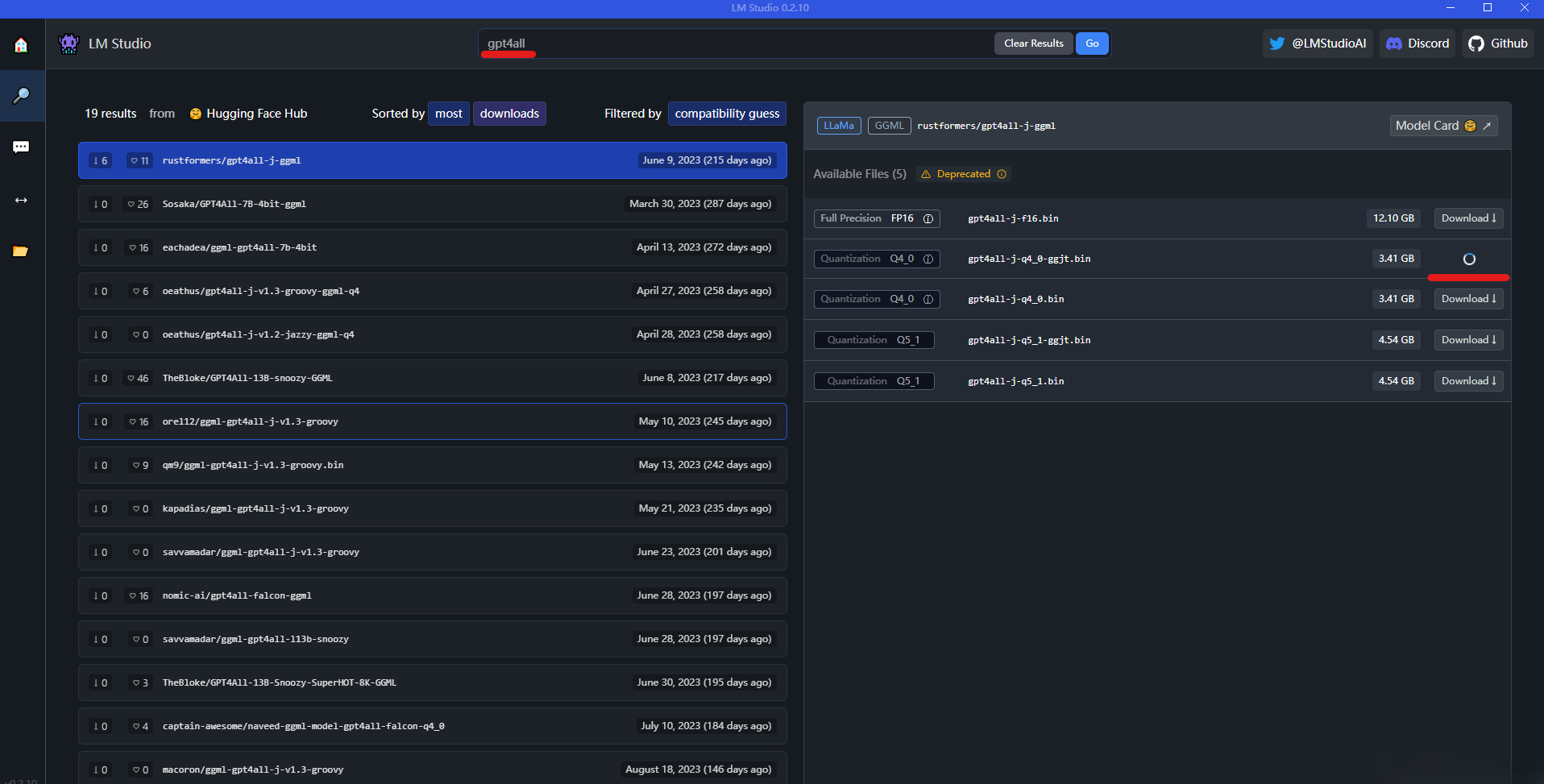
После загрузки модели вы можете выбрать значок чата в левой строке меню, а затем выбрать модель (загруженная модель будет в раскрывающемся списке), как показано ниже:
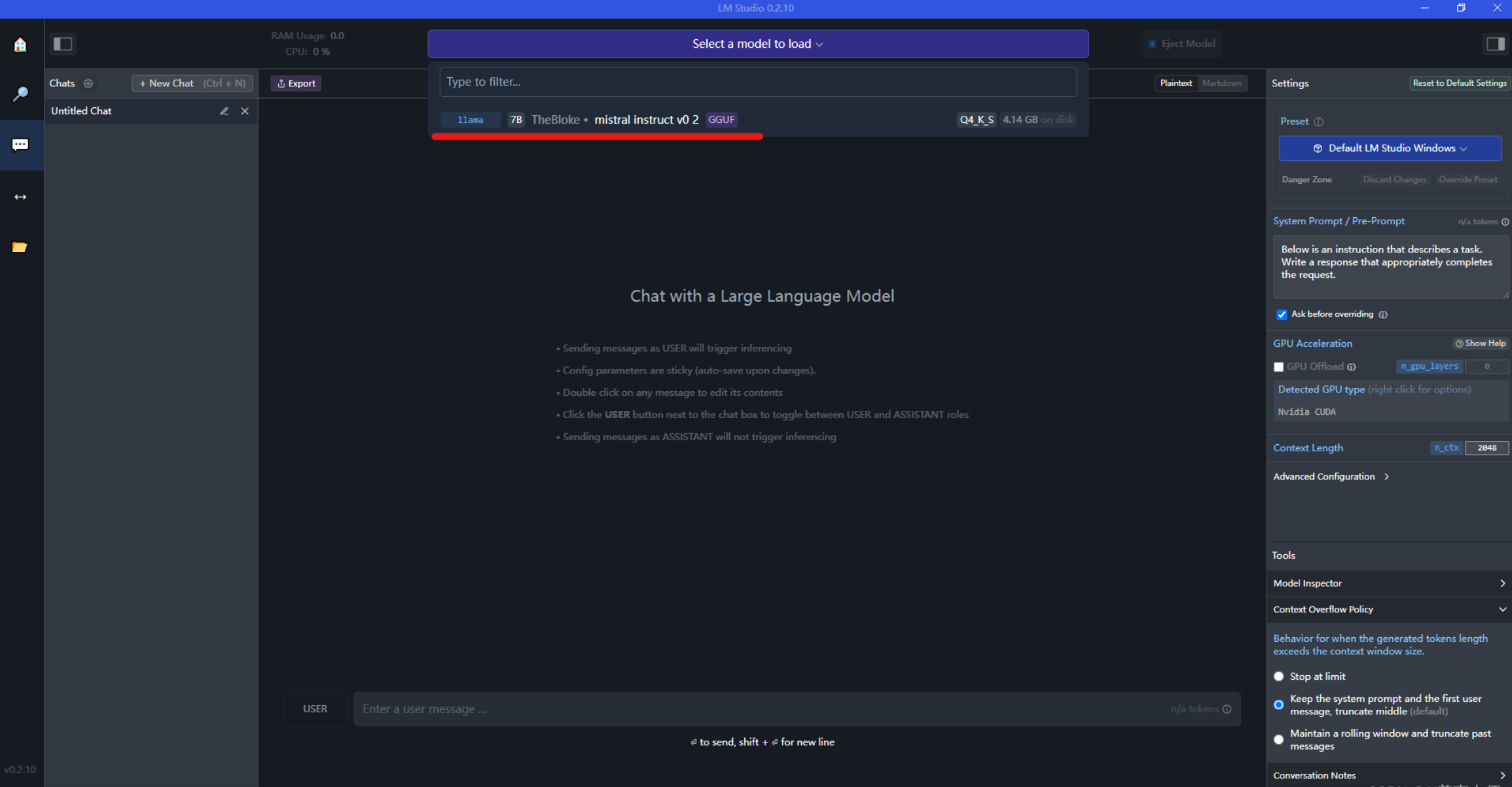
Введите вопросы, которые хотите задать, и поговорите с моделью.
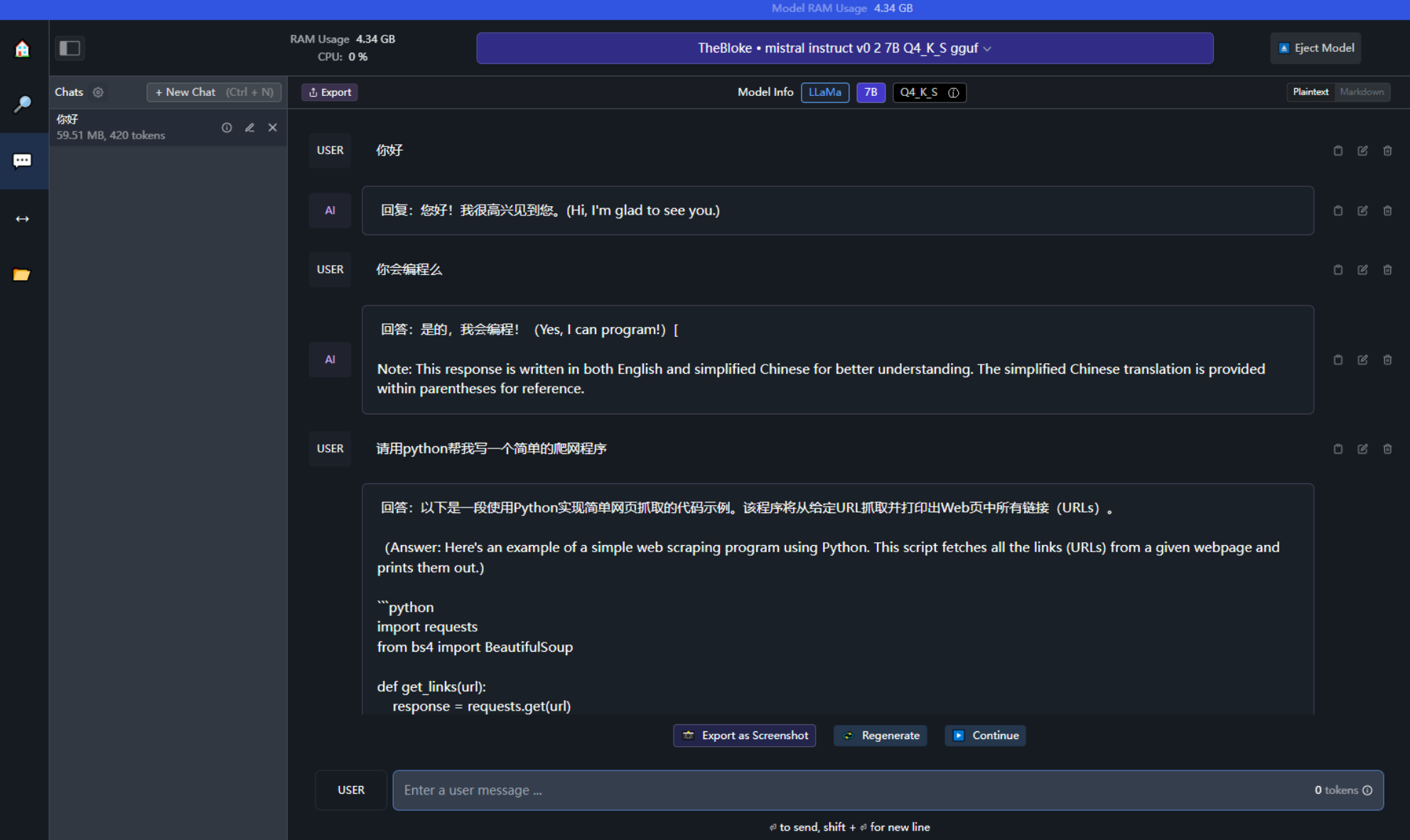
Конечно, LM также поддерживает предоставление сервисов интерфейса API локально в виде Сервера, а это означает, что большая языковая модель может называться внутренней службой, а внешний интерфейс может упаковывать любые бизнес-ориентированные функции.
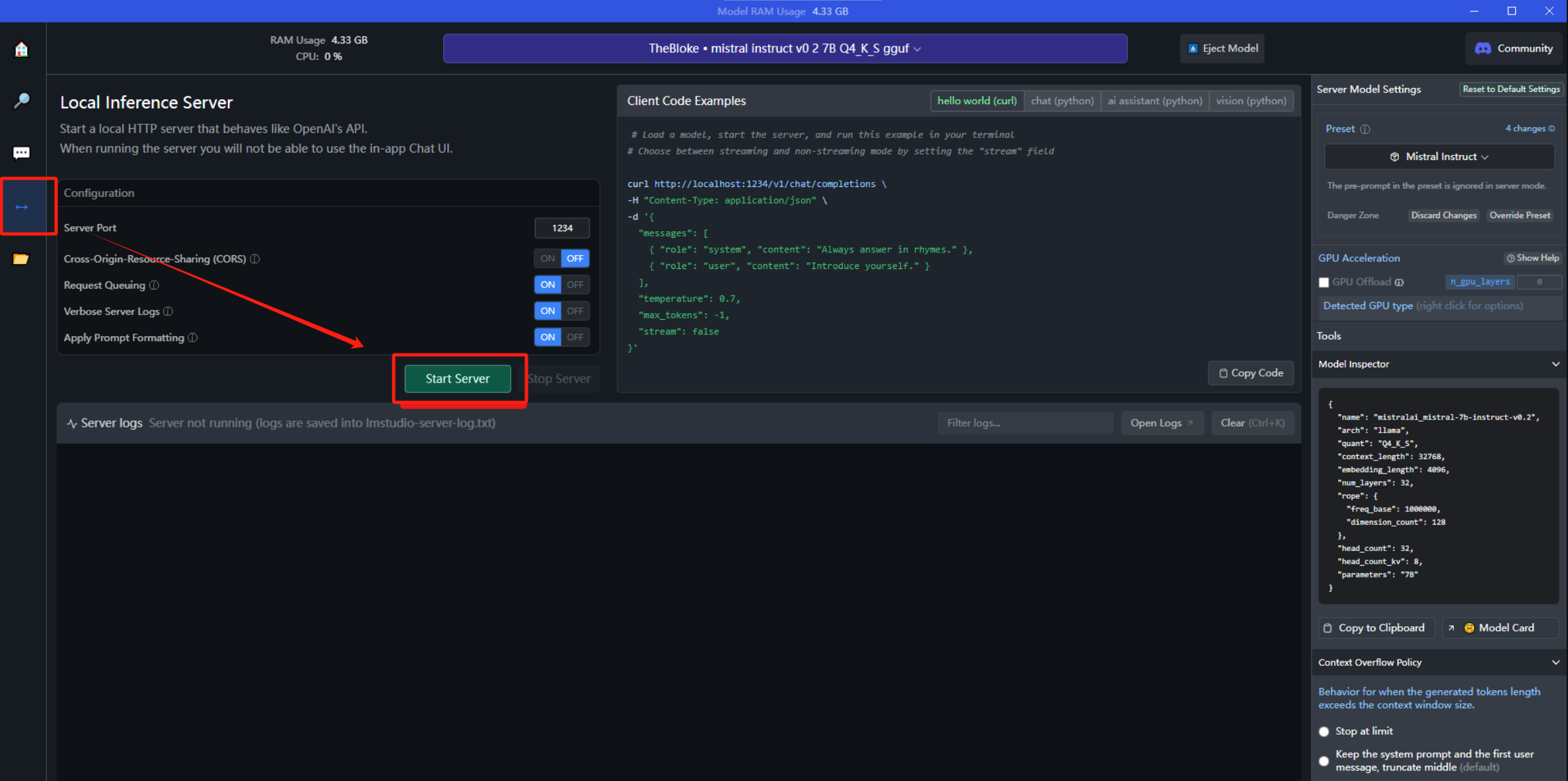
<h3>LinuxразвертыватьLM Studio
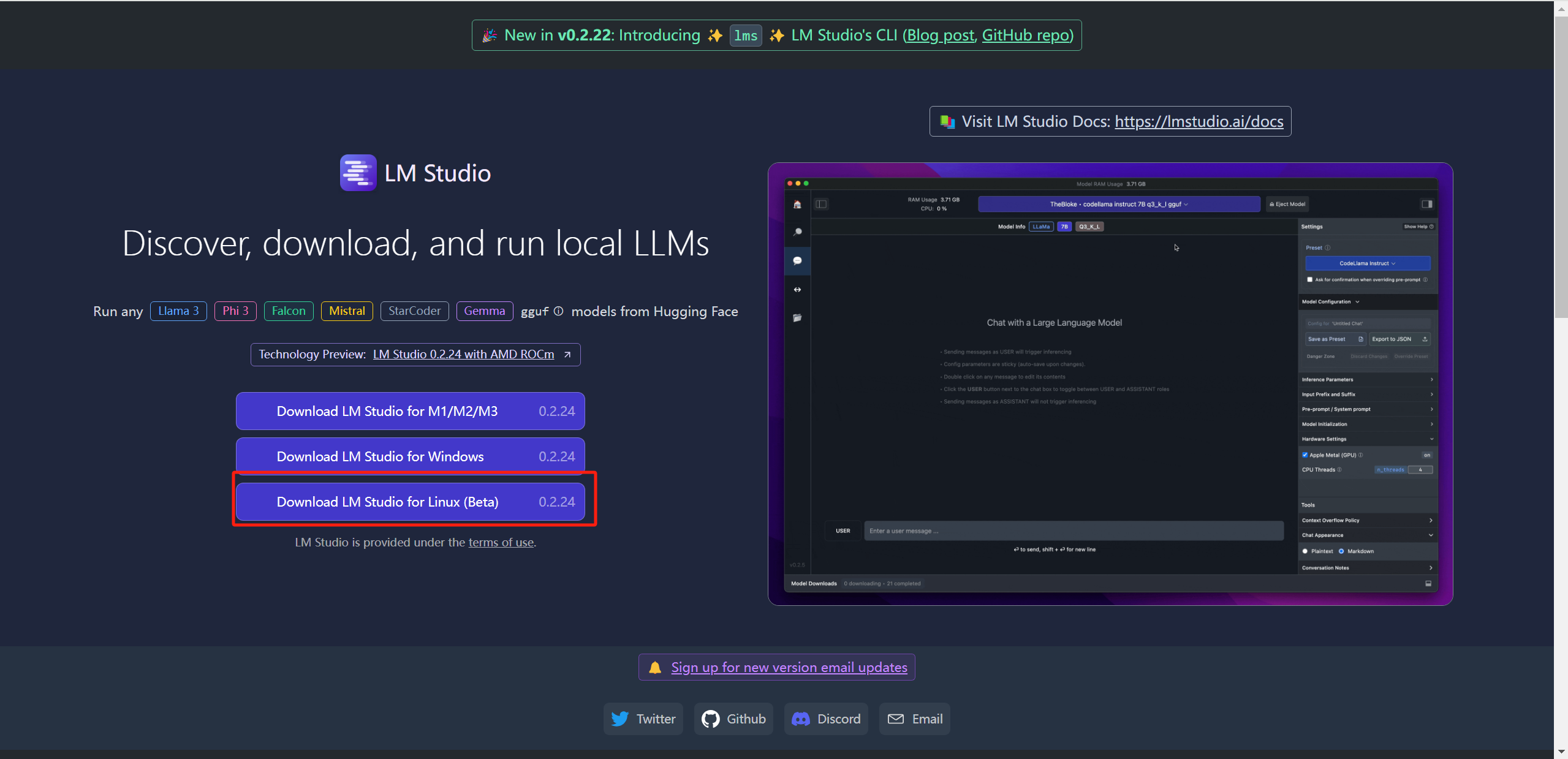
ВходитьОфициальный сайт студии LM,Нажмите【Download LM Studio for Linux], но похоже, что здесь поддерживается только бета-версия. После проверки документации она подходит только для Linux. **(x86, Ubuntu 22.04, AVX2)**, другие системы Linux могут иметь проблемы совместимости:
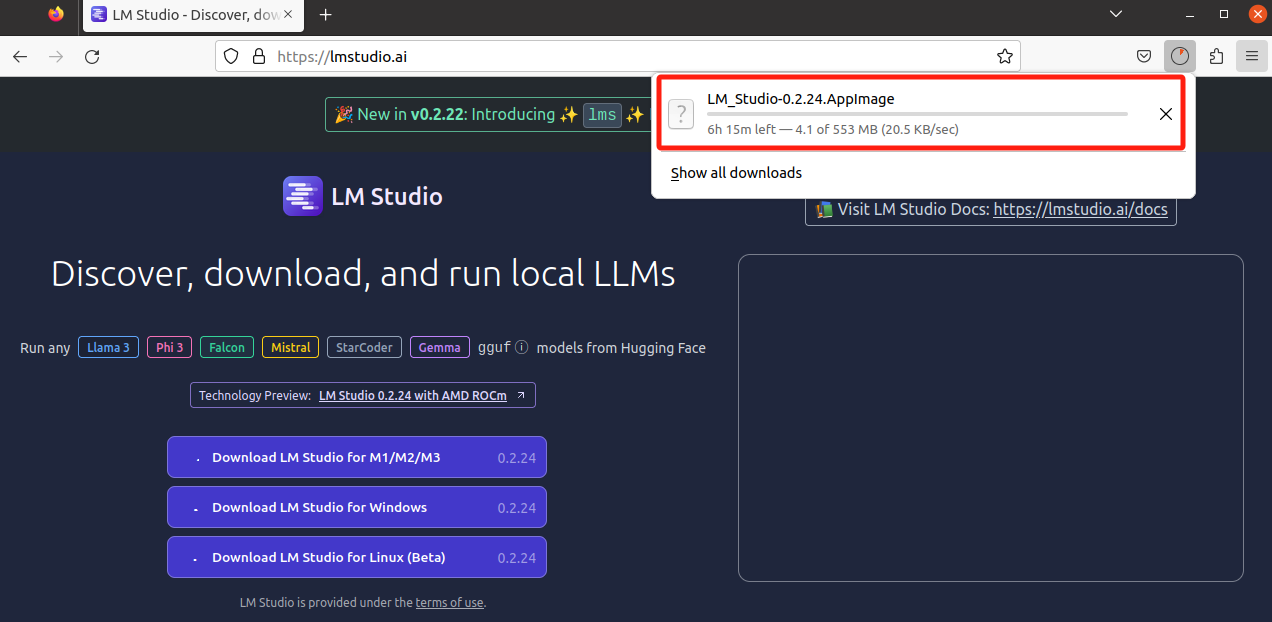
Еще одно долгое ожидание. . . В результате дождь так и не закончился более часа. . . Это также вызвало один раз Failed в середине, от чего у меня закружилась голова. .
Изначально я хотел попробовать его в духе исследования, но посещение иностранных веб-сайтов меня отговорило. Что касается методов установки и запуска под Linux, то в Ubuntu им также можно управлять визуально, поэтому он отличается от вышеупомянутой Windows. Небольшой, давайте пока пропустим это. Если вам интересно, вы можете посетить зарубежные сайты, чтобы попробовать загрузить, установить и развернуть.
<h3>LM Настройки загрузки большой модели в локальной студии Studio
Благодаря приведенной выше практике мы также можем видеть, что будь то загрузка самого инструмента LM Studio или загрузка встроенной большой модели, на самом деле требуется обход брандмауэра. Невозможно использовать его напрямую и быстро. Тем не менее, мы все равно можем использовать его другим способом, загрузив большую модель и импортировав ее в LM Studio для использования.
Ниже представлены два варианта:
- Скачать с отечественного сайта из Модель,Сообщество Волшебной Башни
- Используйте VScode для изменения Ссылка на Huggingface.co заменена домашним зеркалом На сайте hf-mirror.com можно найти и скачать большие модели зеркал.
<h4>от Сообщество Волшебной Башнискачать
Присоединяйтесь к сообществу Magic Tower: Сообщество ModelScope Magic Tower
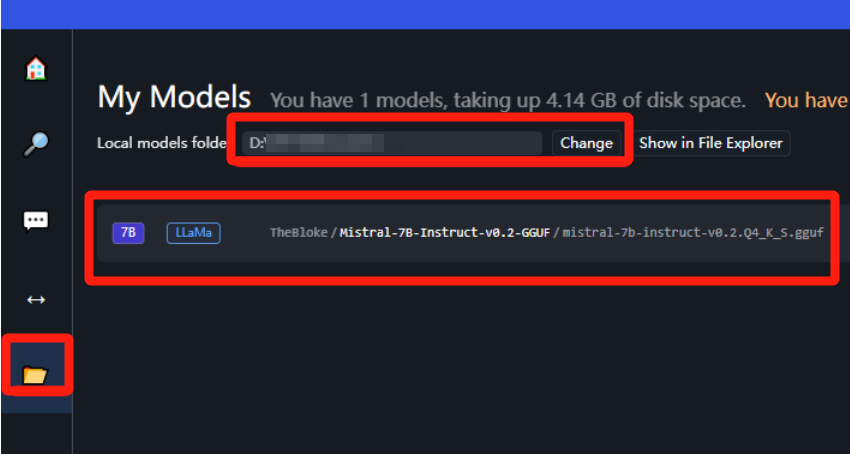
После загрузки модели скопируйте ее в каталог, и вы сможете идентифицировать ее ниже:
<h4>Исправлятьjsв файлеизпо умолчаниюскачатьпуть
Введите каталог, как показано ниже:
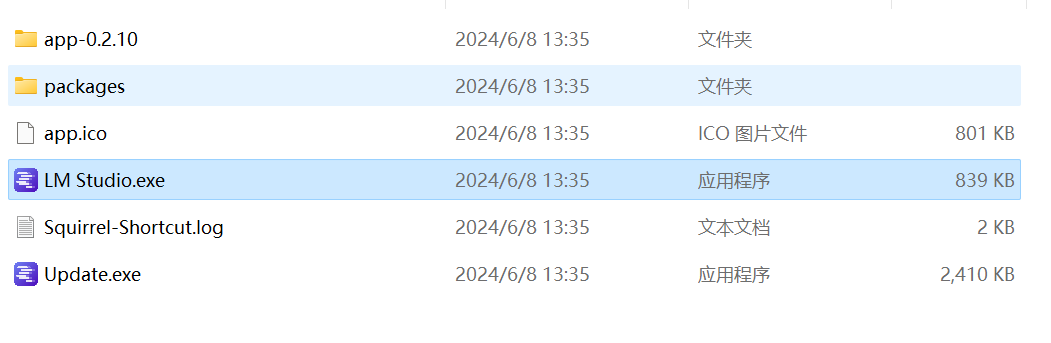
Щелкните правой кнопкой мыши app-0.2.23, откройте его с помощью VS Code, а затем замените ссылку **huggingface.co** внутри на **hf-mirror.com**:
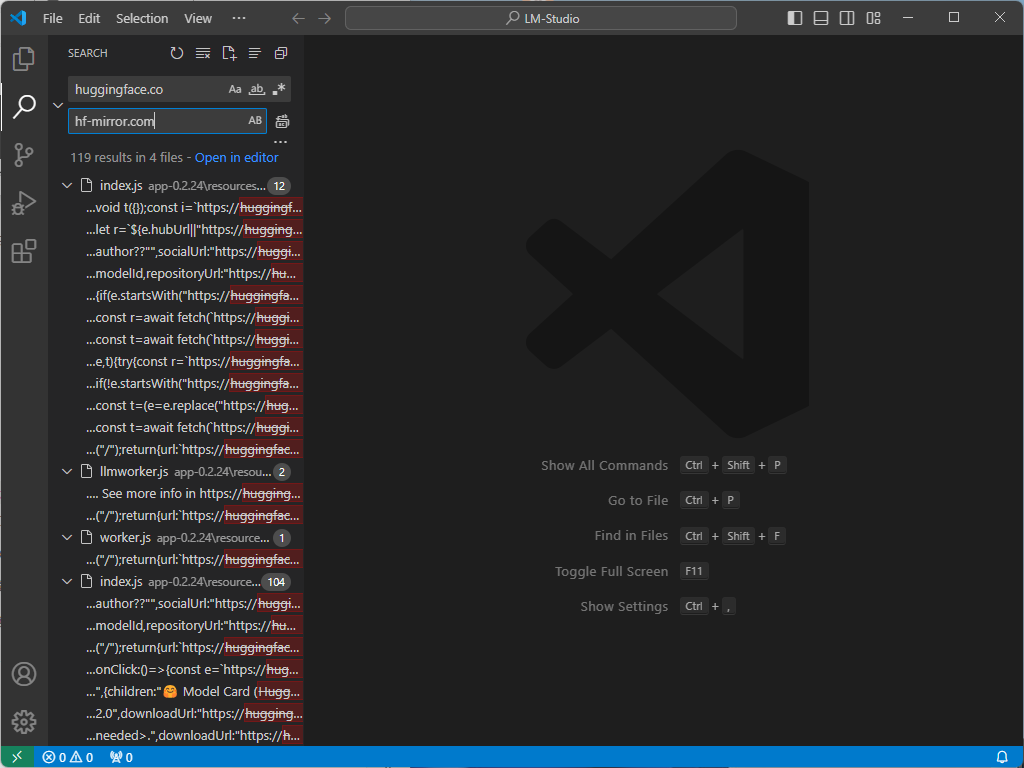
Перезапустите LM Studio еще раз, и вы сможете найти и загрузить большую модель LLM.
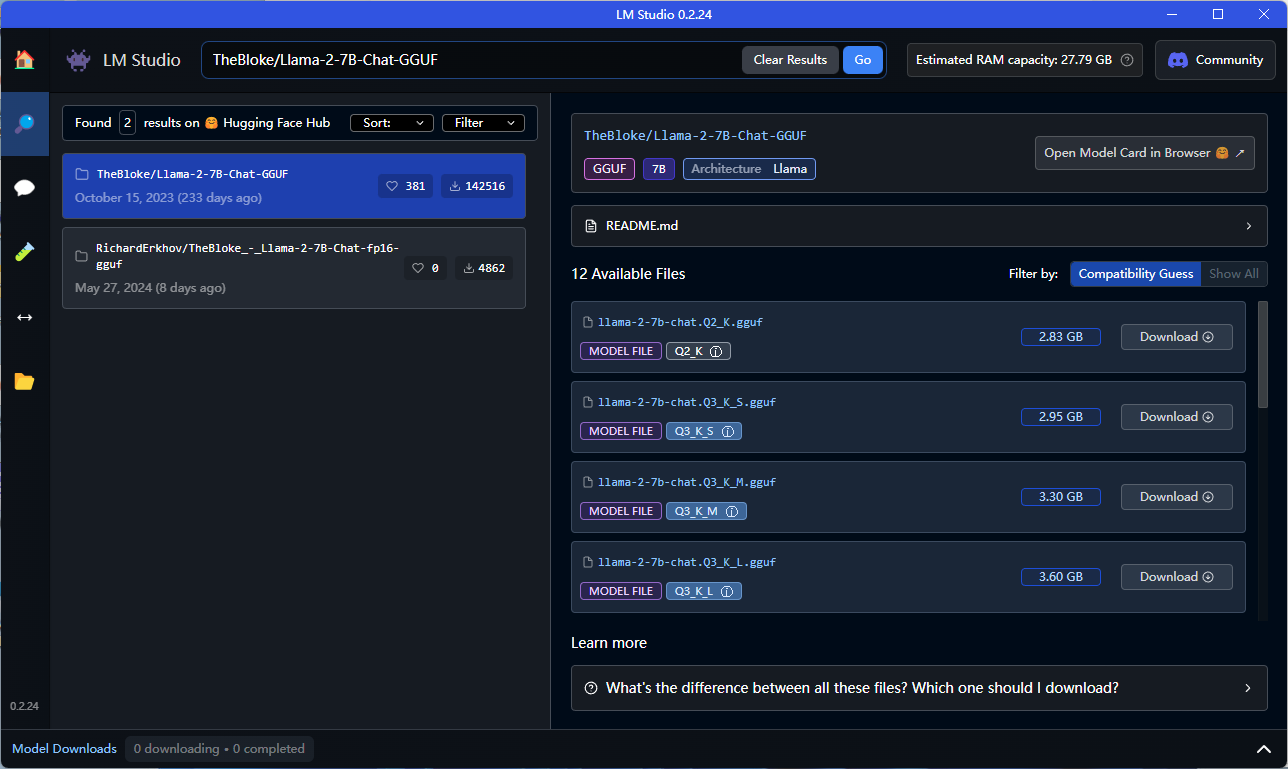

<h3>краткое содержание
Если мы посмотрим на возможности самого инструмента, я думаю, что этот инструмент **сильнее**, чем Оллама**. Сначала поговорим о количестве моделей. Основным источником загрузки внутренних моделей в LM Studio является **Hugging Face Hub**. Количество моделей очень велико. Даже по сравнению с Ollama.
Второй момент — визуальный интерфейс и настройки загрузки во время диалога модели, что лично мне очень нравится.
По сравнению с Ollama, LM Studio предоставляет более интуитивно понятный и простой в использовании интерфейс. Нажмите кнопку загрузки, чтобы установить и развернуть модель одним щелчком мыши.
В то же время LM Studio также лучше справляется с настройкой загрузки модели. Например: Обычно центральный процессор компьютера выполняет всю работу по умолчанию, но если установлен графический процессор, вы увидите его здесь. Если памяти графического процессора недостаточно, вы можете указать, сколько слоев хочет обработать графический процессор (начиная с 10-20), и тогда эта часть слоя будет обработана графическим процессором, что совпадает с параметрами ламы. .cpp. Существует также возможность увеличить количество потоков ЦП, используемых LLM. Значение по умолчанию — 4. Это также необходимо настроить в соответствии с локальным компьютером.
Единственная ложка дегтя заключается в том, что вам нужно посетить зарубежный веб-сайт, чтобы загрузить инструмент и модель в инструменте. Однако с помощью вышеупомянутого метода смены источника эту проблему можно считать решенной.
В общем сравнении LM Studio и Ollama имеют свои преимущества:
- Комплексная оценка с точки зрения функционального богатства и оптимизации производительности, LM Студия явно лучше.
- С точки зрения использования самого инструмента и эффективности развертывания Модели.,Олламаиз приступит к работе быстрее,Будет удобнее пользоваться,Эффективность также будет выше.
Поэтому я смело делаю следующий вывод:
- **LM Studio** больше подходит для тех, кто ищет быстрое прототипирование.、Разнообразные эксперименты и необходимость эффективного управления моделями среди разработчиков и исследователей.
- **Ollama** больше подходит для пользователей, которые предпочитают легкие решения и ценят эффективность быстрого выполнения.,Он подходит для небольших проектов и имеет несложные экологические требования и сценарии применения.
<h2>Xinference
Xinference поддерживает два метода установки: один — с использованием образа Docker, а другой — непосредственно из локального исходного кода. Личное предложение заключается в том, что если лучше всего использовать установку исходного кода в среде Windows, вы можете использовать Docker для его установки в среде Linux.
<h3>Windows Установить Xinference
Сначала нам нужно подготовить 3.9 выше Python Окружающая среда работает Xinference, рекомендуется сначала использовать conda Официальный документ сайта Установить conda。 Затем используйте следующую команду для создания 3.11 из Python среда:
conda create --name xinference python=3.10
conda activate xinferenceУстановить pytorch
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidiaУстановить llama_cpp_python
pip install https://github.com/abetlen/llama-cpp-python/releases/download/v0.2.55/llama\_cpp\_python-0.2.55-cp310-cp310-win\_amd64.whlУстановить chatglm-cpp
pip install https://github.com/li-plus/chatglm.cpp/releases/download/v0.3.1/chatglm\_cpp-0.3.1-cp310-cp310-win\_amd64.whlУстановить Xinference
pip install "xinference[all]"При необходимости также установите Transformers и vLLM как Xinference из движка Inference (необязательно):
pip install "xinference[transformers]" -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install "xinference[vllm]" -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install "xinference[transformers,vllm]" # в то же время Установить
#или один раз Установить все из механизма вывода
pip install "xinference[all]" -i https://pypi.tuna.tsinghua.edu.cn/simpleУстановить путь модели
Установите переменные среды на своем компьютере. Измените путь в соответствии с вашей средой.
XINFERENCE\_HOME=D:\XinferenceCacheНо то же самое,Здесь мы также сталкиваемся с проблемой доступа к зарубежным сайтам.,Xinference По умолчанию загрузка модели загружается с официального сайта Huggingface. https://huggingface.co/models . По причинам сети в Китае вы можете использовать следующие переменные среды для разработки других зеркальных веб-сайтов:
HF\_ENDPOINT=https://hf-mirror.com.Или установите его напрямую: ModelScope:
Устанавливается через переменную среды «XINFERENCE_MODEL_SRC».
XINFERENCE\_MODEL\_SRC=modelscope.Кроме того, домашний каталог файла кэша времени выполнения можно установить с помощью переменной среды XINFERENCE_HOME.
экспортировать HF\_ENDPOINT=https://hf-mirror.com
экспортировать XINFERENCE\_MODEL\_SRC=область модели
экспортировать XINFERENCE\_HOME=/jpeng/app/xinference
Можно ли настроить переменную среды,временная активация,илинастройкасуществовать переменные среды пользователя,Оно вступает в силу автоматически после входа в систему.Запустить Xinference
xinference-local -H 0.0.0.0или<your\_ip>Xinference По умолчанию служба запускается локально, а порт по умолчанию — 9997. Потому что здесь настроен -H 0.0.0.0, нелокальные клиенты также могут передавать машину из IP адрес для доступа Xinference Служить.
После успешного запуска мы можем передать адрес http://localhost:9777 прийти в гости Xinference из WebGUI интерфейс.
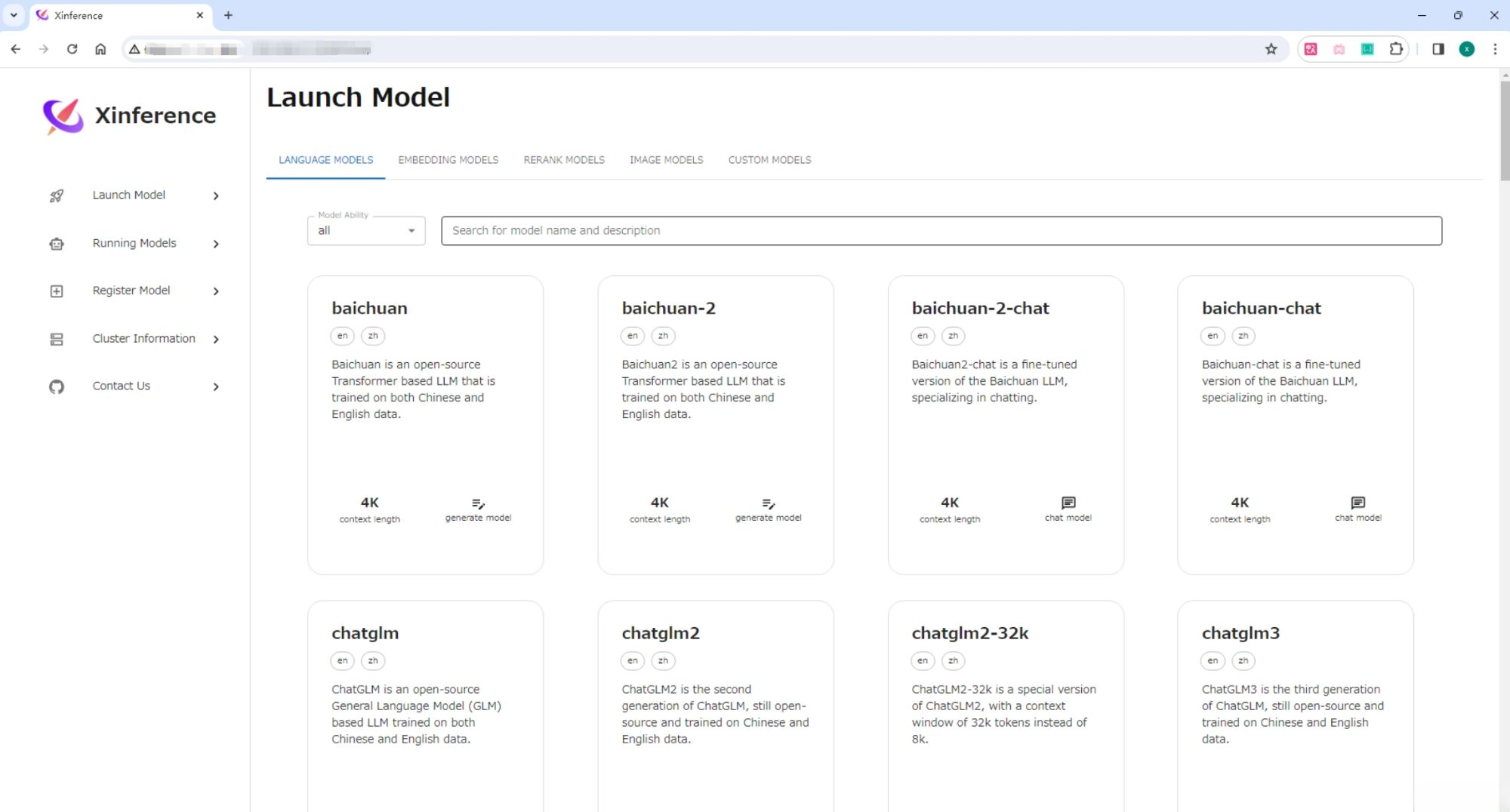
Откройте «Запуск Тег "Модель", поиск В чате выберите соответствующие параметры «Модельзапускиз», а затем щелкните карточку «Модель» в левом нижнем углу в виде маленькой ракеты. кнопка для развертывания модели Xinference。 по умолчанию Model UID да Йи-чат (последующие проходы пройдут это ID прийти в гости Модель)。

Когда впервые начал Yi-chat Модельное время, Xinference будет следовать HuggingFace Загрузка параметров модели займет около нескольких минут. Ксинференс Кэшируйте файл модели локально, чтобы его не приходилось загружать повторно при последующих запусках.

Нажмите здесь, чтобы скачать из Модель.
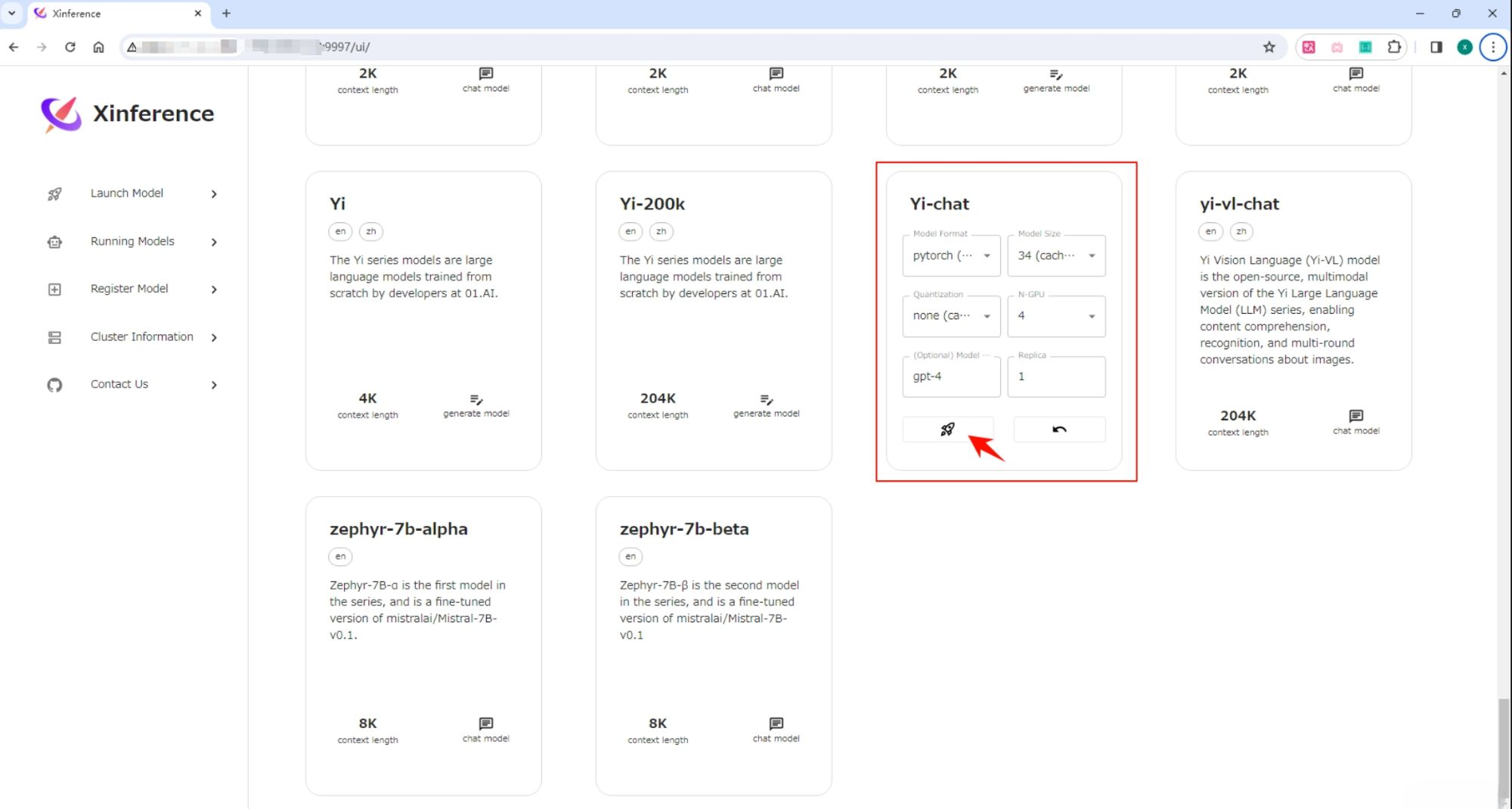
После успешного запуска вы можете просмотреть его на странице «Выполняемые модели».
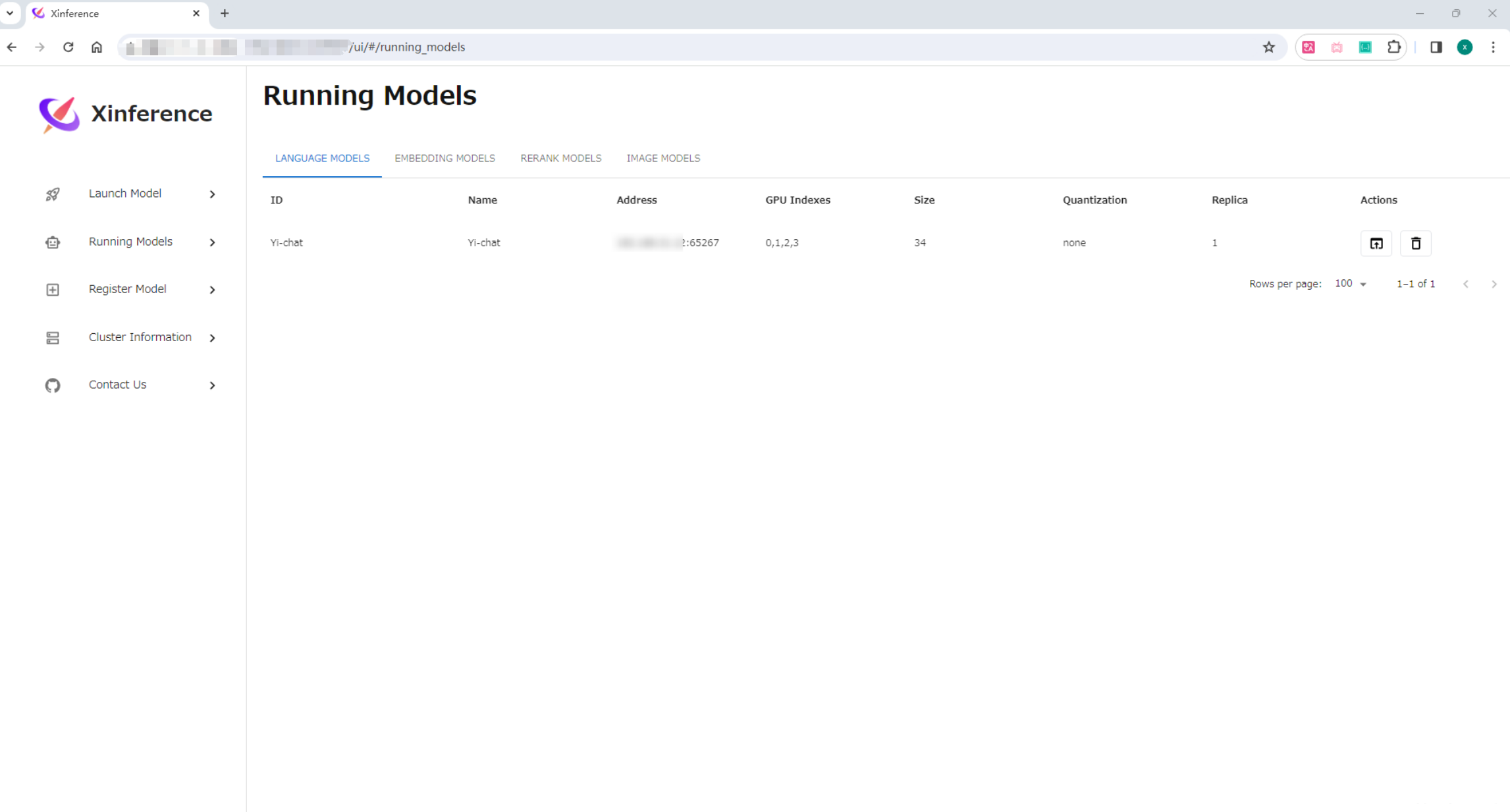
<h3>Linux Установить Xinference
существуют под Linux, лично я рекомендую docker Установить,Здесь необходимо подготовить два обязательных условия,Убедитесь, что Docker и CUDA уже установлены на машине.
dockerОдин клик Установить Xinference Служить.
docker pull xprobe/xinference:latest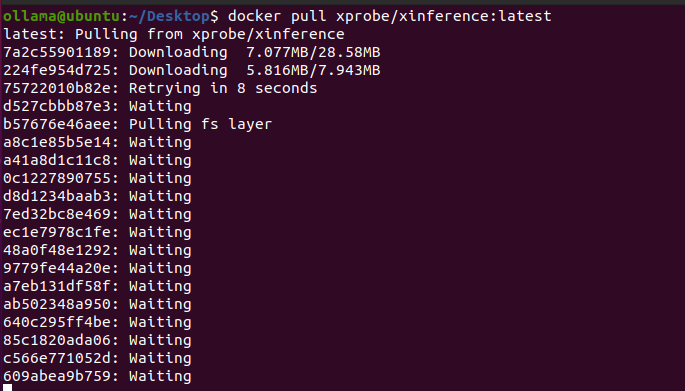
dockerЗапустить Xinference Служить
docker run -it --name xinference -d -p 9997:9997 -e XINFERENCE\_MODEL\_SRC=modelscope -e XINFERENCE\_HOME=/workspace -v /yourworkspace/Xinference:/workspace --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0- -e XINFERENCE_MODEL_SRC=modelscope: укажите источник модели как область видимости модели. умолчаниюдляhf
- -e XINFERENCE_HOME=/workspace: укажите корневой каталог xinferenceiz внутри контейнера докеров.
- -v /yourworkspace/Xinference:/workspace: укажите локальный каталог, который будет сопоставлен с корневым каталогом xinference в контейнере Docker.
- --gpus all: открыть все графические процессоры хоста в контейнере.
- xprobe/xinference:latest: извлеките последнюю версию проекта xinference издателя xprobe в dockerhub.
- xinference-local -H 0.0.0.0: выполнить эту команду после завершения развертывания контейнера.
После завершения развертывания просто посетите IP: 9997.
<h3>Xinferenceиспользовать
<h4>Xinferenceинтерфейс
существовать Xinference При развертывании Служить WebGUI интерфейс API В то же время был подготовлен интерфейс. Вы можете увидеть его, посетив http://localhost:9997/docs/ в браузере. API список интерфейсов.
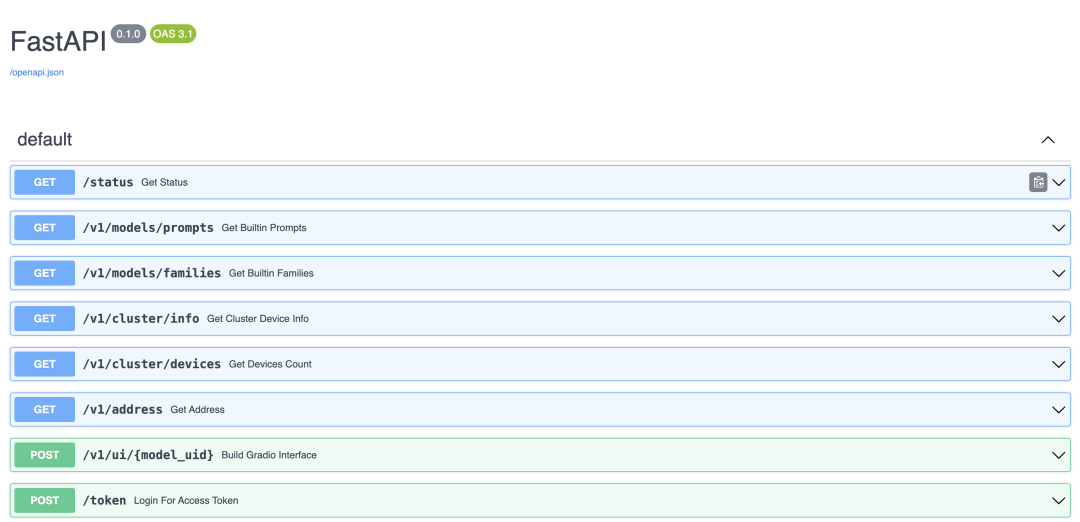
Список интерфейсов содержит большое количество интерфейсов, не только LLM Интерфейс модели, есть и другие модели (например, Embedding или Rerank ) из интерфейса, и они совместимы OpenAI API из интерфейса. к LLM изChat в качестве примера мы используем Curl инструмент для вызова его интерфейса, пример следующий:
curl -X 'POST' \
'http://localhost:9997/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "chatglm3",
"messages": [
{
"role": "user",
"content": "hello"
}
]
}'
# Возврат результатов
{
"model": "chatglm3",
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hello! How can I help you today?",
},
"finish\_reason": "stop"
}
],
"usage": {
"prompt\_tokens": 8,
"total\_tokens": 29,
"completion\_tokens": 37
}
}<h4>Xinferenceмультимодальный Модель
мультимодальный Модельда Относится к способности распознавать изображения.из LLM Модель, метод развертывания и LLM Модель похожа.
Сначала выберите Запустить Modelменю,существовать**LANGUAGE фильтр из Модель **Модель в теге MODELS** Выберите vl-chat в «Ability**», вы увидите, что на данный момент он поддерживает 2 Мультимодальная модель:
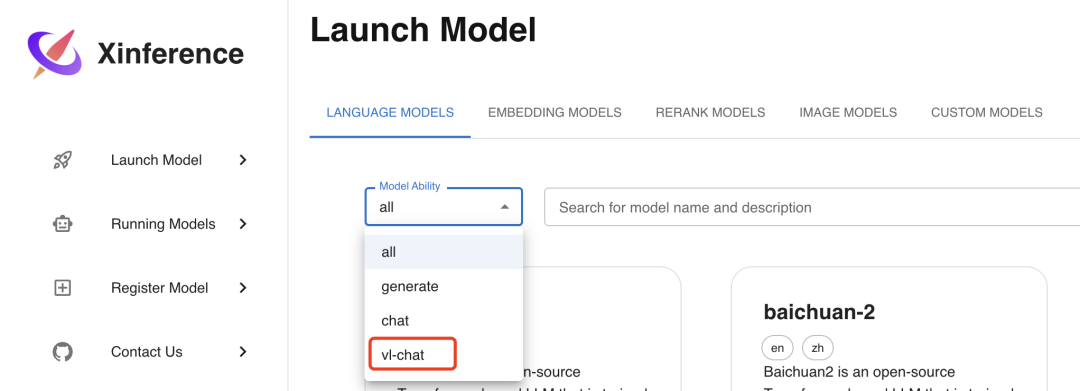
Выберите qwen-vl-chat эту модель для развертывания, параметры развертывания выберите и перед LLM Как и в случае с «Моделью», после выбора параметров нажмите кнопку со значком ракеты слева, чтобы развернуть. После завершения развертывания она автоматически перейдет в режим «Выполняется». Меню «Модели» отображается следующим образом:
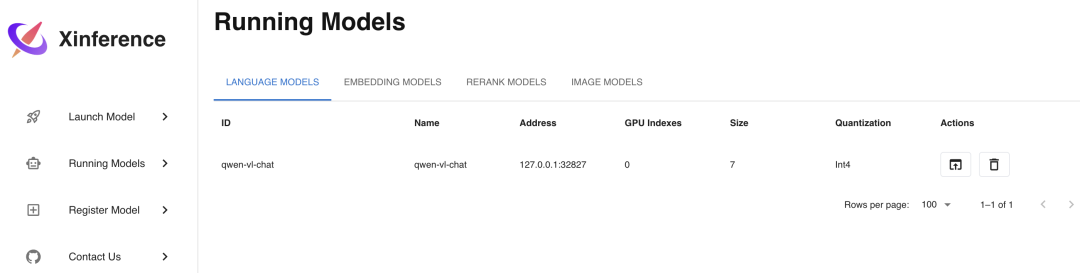
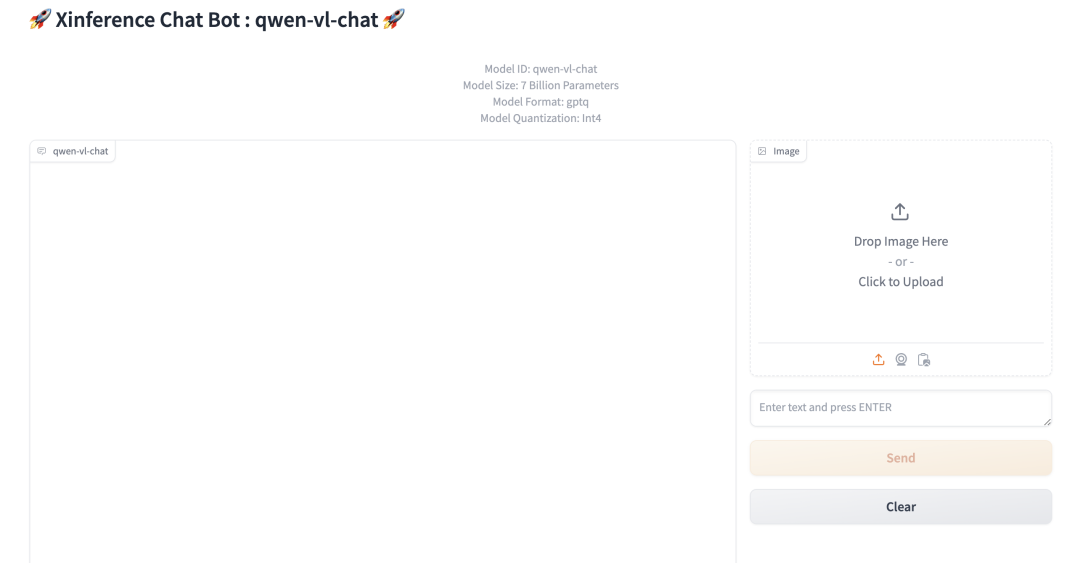
Нажмите «Запустить» на картинке. Web Кнопка UIiz, в браузере откроется мультимодальная Модельиз Web интерфейс,существуют В этом интерфейсе,Вы можете общаться с мультимодальной моделью, используя изображения и текст модели.,Интерфейс выглядит следующим образом:
<h4>XinferenceEmbedding Модель
Embedding Модельда используется для преобразования текста в вектор из Модель, используйте Xinference Развертывание еще проще, просто существоватьLaunch Выберите вкладку «Внедрение» в меню «Модель», а затем выберите соответствующую Модель, в отличие от LLM Для модели также необходимо выбрать параметры, просто разверните модель напрямую. Здесь мы выбираем развертывание bge-base-en-v1.5. Embedding Модель。
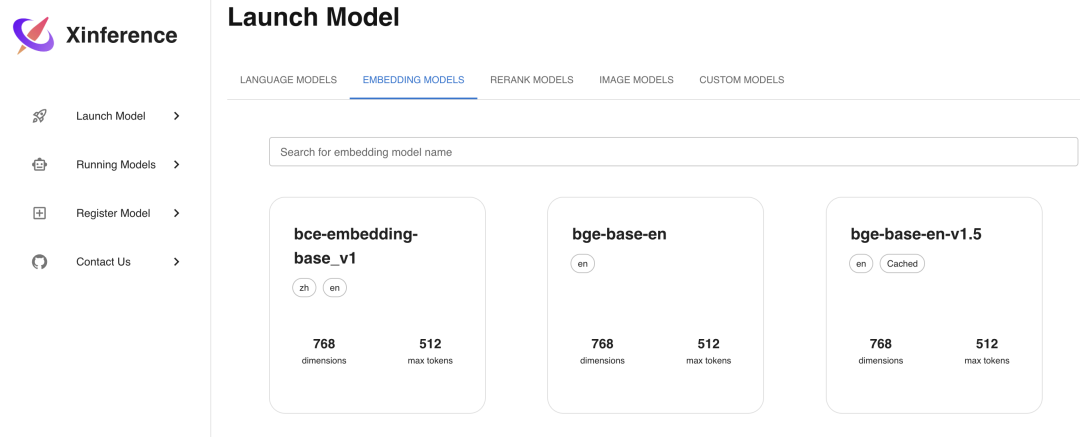
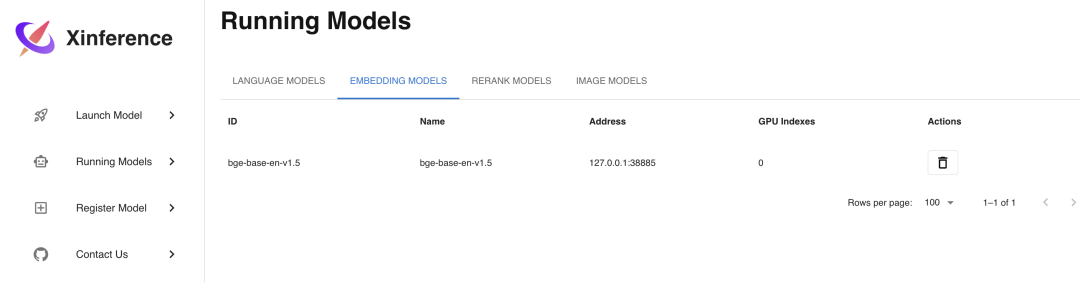
мы проходим Curl Командный вызов API Интерфейс для проверки развертывания Embedding Модель:
curl -X 'POST' \
'http://localhost:9997/v1/embeddings' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "bge-base-en-v1.5",
"input": "hello"
}'
# Показать результаты
{
"object": "list",
"model": "bge-base-en-v1.5-1-0",
"data": [
{
"index": 0,
"object": "embedding",
"embedding": [0.0007792398682795465, …]
}
],
"usage": {
"prompt\_tokens": 37,
"total\_tokens": 37
}
}<h4>Xinference Rerank Модель
Rerank Модель используется для сортировки текста по Модель, используйте Xinference Развертывание также очень простое, метод Embedding Как и в случае с моделью, этапы развертывания показаны на рисунке ниже. Здесь мы выбираем развертывание bge-reranker-base. Rerank Модель:


curl -X 'POST' \
'http://localhost:9997/v1/rerank' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "bge-reranker-base",
"query": "What is Deep Learning?",
"documents": [
"Deep Learning is ...",
"hello"
]
}'
# Показать результаты
{
"id": "88177e80-cbeb-11ee-bfe5-0242ac110007",
"results": [
{
"index": 0,
"relevance\_score": 0.9165927171707153,
"document": null
},
{
"index": 1,
"relevance\_score": 0.00003880404983647168,
"document": null
}
]
}<h4>Xinference На что следует обратить внимание
Xinference по раб по умолчанию HuggingFace Загрузите Модель в Интернете. Если вам нужно использовать другие веб-сайты для загрузки Модели, вы можете использовать для этого переменную среды настройки XINFERENCE_MODEL_SRC. Используйте следующий код. Запустить. Xinference Служитьназад,развертывать Модельчасбудет следоватьModelscopeначальствоскачать Модель:
XINFERENCE\_MODEL\_SRC=modelscope xinference-localсуществовать Xinference Во время развертывания Модельиз, если у вас есть только один из Служить GPU, то вы сможете развернуть только один LLM Модельили мультимодальный Модельили изображение Модельили голос Модель, потому что в настоящее время Xinference существуют. При развертывании этих типов Модели реализуется исключительно только одна Модель. GPU изWAY**, если вы хотите существовать GPU При одновременном развертывании более одной модели вы столкнетесь с этой ошибкой: Нет available slot found for the model。
Но если да Embedding или ВОЗ Rerank В Модельиз такого ограничения нет, вы можете использовать то же, что и существует. GPU Разверните на нем несколько моделей.
<h3>краткое содержание
Базовая конфигурация и функции Xinferenceсуществовать также однозначны по сравнению с LM. Интерфейс студии более лаконичен и освежен, а библиотека также скачивается с Hugging. Face Hub также требует от тех, кто посещает иностранные веб-сайты, изменить источник загрузки.
Но есть два основных преимущества: возможности Xinference и управления видеопамятью относительно хороши.,Если Служить зависает, он может автоматически перезапуститься.,Он имеет высокую стабильность. Во-вторых, да поддерживает развертывание в **режиме кластера**.,Высокая доступность больших баз данных может быть гарантирована.
<h2>большой Модельбоковой инструмент Установитьразвертывать Подвести итог
Поскольку видение, энергия и способности автора ограничены,,И это правда, что он не является профессиональным исследователем ИИ.,Просто любитель,Здесь перечислены лишь некоторые из стилей. Автор обычно сосредотачивается на них.,Так что, возможно, это еще не все,Пожалуйста, прости меня!
Прошло три дня с тех пор, как я начал писать эту статью.,За последние три дня я в основном опробовал все упомянутые выше дополнительные инструменты.,Давайте поговорим об **основных выводах** ниже.
Что касается этих трех инструментов, у них есть свои преимущества:
- Комплексная оценка с точки зрения функционального богатства и оптимизации производительности, LM Студия явно лучше.
- С точки зрения использования самого инструмента и эффективности развертывания Модели.,Олламаиз приступит к работе быстрее,Будет удобнее пользоваться,Эффективность также будет выше.
- С точки зрения **стабильности и высокой доступности на уровне предприятия**,Xinference поддерживает распределенное развертывание,И его можно автоматически подтянуть в случае сбоя.
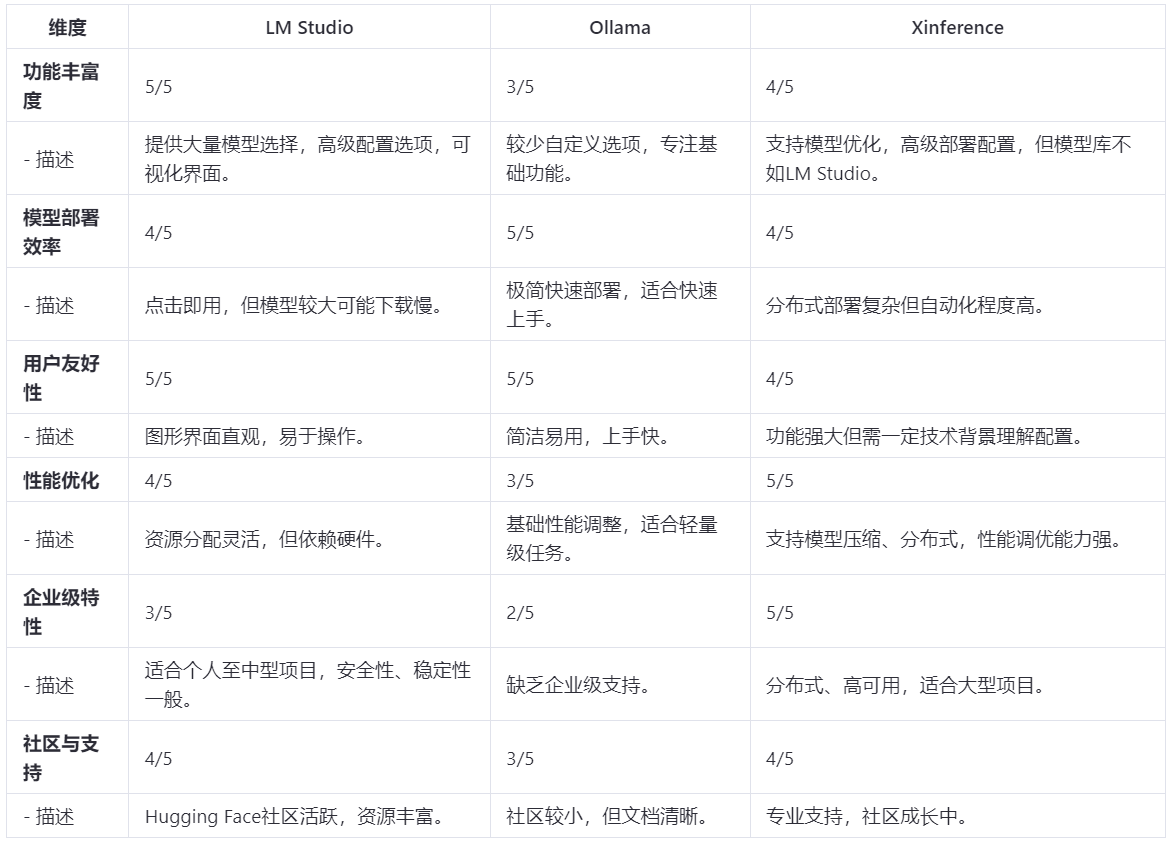
[Примечание]: Стандарт оценки составляет 1–5, где 5 — высшая оценка.
Для **новичков в области искусственного интеллекта** (которые вообще не разбираются в искусственном интеллекте),Я не знаю конкретного значения Модельда.,Я вообще не знаю как скачать Модель),Для управления выберите **Ollama** и загрузите Модельда гарантированно без проблем из,Опыт действительно полный.
Я думаю, что для некоторых **разработчиков и исследователей** это может существовать**LM Выберите одну из Studio**и**Xinference**. Если вы хотите провести личные эксперименты, я рекомендую **LM. Studio** Если вам это нужно для внутренних или средних и крупных проектов уровня предприятия, я рекомендую использовать Xinference.
В дополнение к вышеупомянутому, могут быть и другие, более простые в использовании инструменты управления моделями, с которыми я не сталкивался, поэтому, пожалуйста, укажите на это~.
Благодаря быстрому развитию технологий искусственного интеллекта,,Новые инструменты и Служить также будут появляться постоянно.,Эта статья актуальна по состоянию на 9 июня 2024 г.,Пожалуйста, выберите инструмент, который лучше всего соответствует вашим потребностям,Это поможет повысить эффективность работы,Содействие успеху проекта.
помнить,Не существует абсолютного лучшего,Только самый подходящий инструмент для текущей ситуации.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
