Подробное объяснение различных серий LLM | Подробное объяснение архитектуры модели LLaMA 2, предварительного обучения и содержания SFT (ЧАСТЬ 1)
Автор | Организация | https://zhuanlan.zhihu.com/p/670002922
Привет всем, это NewBeeNLP。Раньше мы делилисьПодробное объяснение различных серий LLM|LLaMA. 1 Сводная информация об архитектуре модели, предварительном обучении и функциях оптимизации развертывания.
Сегодня давайте взглянем на Llama 2, которая представляет собой серию больших языковых моделей с параметрами от 7B до 70B, которые Meta обновила на основе LLaMA. Точность Llama2 превосходит LLaMA1 во всех списках. Llama 2, одна из самых эффективных моделей в индустрии с открытым исходным кодом, в настоящее время широко используется.
Чтобы глубже понять технические характеристики Llama 2, здесь мы собрали подробное объяснение архитектуры модели Llama 2, предварительного обучения, содержания SFT и RLHF, а также проанализировали ее с точки зрения безопасности.
Без лишних слов, давайте перейдем непосредственно к практическим вещам.

1. Знакомство с LLaMA 2.
- Статья: https://arxiv.org/abs/2307.09288.
- Github:GitHub \- facebookresearch/llama: Inference code for LLaMA models[1]
На основе оригинальной LLaMA 1 Meta увеличила количество токенов, используемых при предварительном обучении, в то же время изменила архитектуру модели и представила внимание к групповым запросам (GQA);
Более того, на основе Llama 2 компания Meta также выпустила Llama 2-Chat. Он создает первоначальную версию Llama 2-Chat путем применения контролируемой тонкой настройки. Затем модель итеративно улучшается с использованием методов обучения с подкреплением и обратной связью с человеком (RLHF), используя выборку отклонения и оптимизацию проксимальной политики (PPO).
Основной процесс обучения Llama 2-Chat выглядит следующим образом:
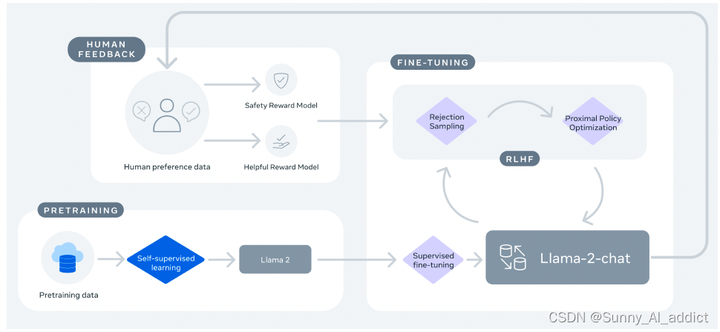
Основной тренировочный процесс Llama 2-Chat
2. Архитектура модели
2.1 Основная архитектура
Llama 2 использует большинство настроек предварительного обучения и архитектуры модели LLaMA 1, в том числе:
- Tokenzier: и ЛЛа МА 1 то же, что и из токенизатор, используйте SentencePiece Понимать BPE алгоритм. с ЛЛа МА 1, разбить все числа на однозначные и использовать байты для разложения неизвестных UTF-8 характер. Общий словарный запас составляет 32 тыс. token。 (Информацию о BPE см. в разделе BPE. Принципы алгоритма и руководство по использованию [Подробное объяснение] - Чжиху[2])
- Pre-normalization : В целях повышения стабильности тренироваться, LLaMa вернокаждый Transformer Нормализуется вход подслоя, а не выход. Магистр права использовал RMSNorm Нормализованная функция. (О предварительной норме vs Пост-норма, пожалуйста, обратитесь к Почему Pre Нормиз не так эффективен, как Пост Norm?- Научный космос|Научный Spaces[3])
- Функция активации SwiGLU: LLaMa использовать SwiGLU Активировать замену функции ReLU Для повышения производительности размеры варьируются от 4d становиться \frac{2}{3}4d . SwiGLU — это функция активации, это вариант GLUиз,Это может улучшить производительность модели трансформатора. Преимущество SwiGLU в том, что он может динамически регулировать степень ограничения потока информации.,Зависит от ввода,иSwiGLUСравниватьReLUДаже
гладкий,могу принестиВсе лучше и лучше оптимизированоиСближение быстрее。 (Информацию о функции активации SwiGLU см. в разделе Краткое описание). описание функции активации (8): на основе Gate механизм механизм изактивациифункция дополнение\(GLU, SwiGLU, GTU, Bilinear, ReGLU, GEGLU\)\_glu active-CSDN блог [4]) - Rotary Embeddings:LLaMa Предыдущая кодировка позиции не используется, но используется кодировка повернутой позиции (RoPE), которая может улучшить экстраполяцию Моделииз. Его основная идея состоит в том, чтобы настроить вектор внедрения каждого слова или токена с помощью матрицы вращения, чтобы их внутренние продукты были связаны только с их относительными позициями. Встраивание вращения не требует предварительно определенных или изученных векторов внедрения положения, вместо этого сеть динамически добавляет информацию о местоположении на каждом уровне. Встраивание вращения имеет некоторые преимущества, например, оно может обрабатывать последовательности любой длины, может улучшить способность обобщения Моделиза, может уменьшить объем вычислений, может применяться к линейному вниманию и т. д. (о RoPE из Для более подробной информации, пожалуйста, обратитесь к Прочитайте ротированное кодирование (RoPE) за десять минут - Чжиху[5])
2.2 Group Query Attention (GQA)
Основные архитектурные различия между Llama 2 и LLaMA 1 включают увеличение длины контекста и внимание к групповым запросам (GQA), как показано ниже:
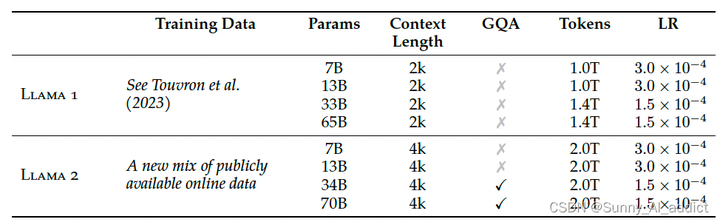
Основные архитектурные различия между Llama 2 и LLaMA 1
GQA:
Стандартной практикой авторегрессионного декодирования является использование KV Cache, который кэширует пары ключей (K) и значений (V) предыдущих токенов в последовательности, чтобы ускорить вычисление внимания последующих токенов. Однако по мере увеличения контекстного окна или размера пакета затраты памяти, связанные с размером KV-кэша в модели многоголового внимания (MHA), значительно возрастают. Для больших моделей KV Cache станет узким местом в приложениях видеопамяти во время вывода.
Для описанной выше ситуации есть два основных решения:
Внимание к нескольким запросам (MQA). Как показано на рисунке ниже, MQA использует одни и те же пары ключа (K) и значения (V) во всех запросах.
Group Query Attention (GQA): Как показано на рисунке ниже, GQA работает в разных условиях. (1<=n<=No. of головы) разделяет ключ между запросами (K) суммарное значение (V) верно
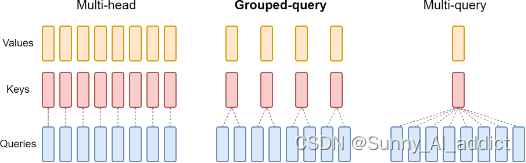
MHA vs GQA vs MQA
В то время как Multi-Query Attention (MQA) с использованием только одного заголовка «ключ-значение» значительно ускоряет вывод декодера. Однако MQA может привести к ухудшению качества. А внимание к запросам (GQA), которое является обобщением внимания к нескольким запросам, использует количество промежуточных (несколько, меньше количества голов запроса) заголовков «ключ-значение». Эксперименты показывают, что предварительно обученный GQA достигает качества, близкого к многоголовому вниманию, со скоростью, сравнимой с MQA.
(Для MQA см. https://zhuanlan.zhihu.com/p/634236135[6];
Что касается GQA, вы можете обратиться к \[LLM\] Групповой запрос, ускоренное рассуждение \-Zhihu[7];
Что касается KV-кэша, вы можете обратиться к статье «Ускорение вывода больших моделей: изучите KV-кэш, просматривая изображения» \- Zhihu [8])
3. Предварительная тренировка
3.1 Данные перед тренировкой
- Тренируемый корпус включает в себя смешанные данные из общедоступных источников и исключает данные из Meta Товары или услуги изданные. Предпринимаются усилия по удалению конфиденциальной информации с некоторых сайтов, которые, как известно, содержат большое количество личной информации о частных лицах.
- существовать 2 тренироваться на триллионе данных, потому что это обеспечивает хороший компромисс между производительностью и затратами.
- верно Данные большинства фактических источников имеют передискретизацию для увеличения знаний и подавления галлюцинаций.
3.2 Процесс и результаты предварительной подготовки
3.2.1 Гиперпараметры перед обучением
- использовать Llama 1 из Большая часть пред.тренироватьсянастраиватьи Модель Архитектура
- Оптимизатор: оптимизатор AdamW, \beta_{1} =0,9, \beta_{2} =0,95
- Скорость обучения: скорость обучения косинуса, 2000 г. step из разминка, наконец-то decay достичь максимальной скорости обучения из 10%
- weight decay:0.1
- gradient clipping:1.0
3.2.2 Потеря предварительного обучения при обучении
тренироваться loss Кривая показана ниже,даже еслитренироваться Понятно 2T из token Явления насыщения пока нет.:

3.2.3 Оценка предварительно обученной модели Llama 2
- Сравнение с открытой Модельсуществовать производительность на различных задачах:
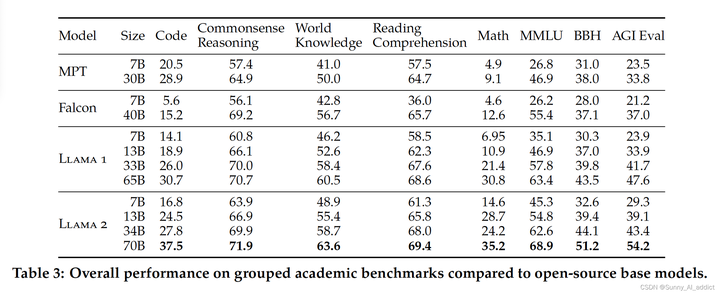
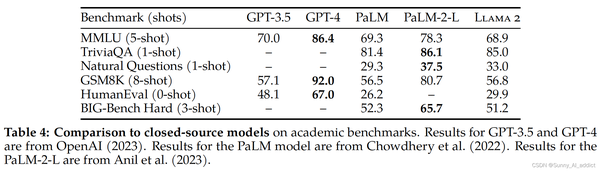
Помимо тестов кода, Llama 2 Модельсуществовать 7B и 30B превосходят во всех категориях соответствующие размеры модели MPT. Лама 2 7B и 34B превзошли Falcon во всех категориях бенчмарков. 7Б и 40Б. также, Llama 2 Модель 70B превосходит все модели с открытым исходным кодом.
- Сравнение с закрытой моделью Модельсуществовать производительность на различных задачах:
Четыре、Контролируемая точная настройка (SFT)
4.1 Данные SFT
направлять,Исследовательская группа начинает этап SFT с общедоступными данными настройки инструкций.,Но позже выяснилось, что многим из них не хватает разнообразия и качества.,Существование особенно сочетает в себе LLM с верными разговорными инструкциями.
- Сбор высококачественных данных SFT: используйте от поставщиков на основе комментариев и примеров меньшего, но более высокого качества.,Результаты SFTиз были значительно улучшены.
- Quality> Quantity: Всего несколько тысяч высококачественных изданныхтренироватьсяиз Модель лучше, чем масштабный open source данныеSFT тренироватьсяиз Модель,Это связано с Lima из Найдено похожее на: Ограниченные данные по настройке инструкций достаточны для достижения высокого уровня качества. . существуют, собрано в общей сложности 27,540 Перестаньте комментировать после комментариев SFT данные。
- Введение в предвзятость аннотаций. Исследовательская группа также заметила, что разные платформы и поставщики аннотаций могут привести к значительно разной производительности в дальнейшем.,Это подчеркивает важность проверки, даже когда поставщики приходят за заметками. Для проверки качества данных,Исследовательская группа тщательно изучила набор из 180 образцов.,Объедините предоставленные вручную аннотации с моделью, созданной на основе образцов для проверки вручную. Удивительно из-за,мы нашли Выборку результатов результирующего SFT часто можно сравнить с почерком человека-аннотатора. SFT конкурирует с ,Это показывает, что мы можем сбросить приоритеты,и вложить больше работы в аннотации в аннотации RLHF на основе предпочтений.
4.2 Процесс и результаты обучения SFT
- Скорость обучения косинуса, начальная скорость обучения 2e-5, затухание веса = 0,1, размер пакета = 64, seq_len = 4096
- правда в процессе доработки,Каждый образец состоит из подсказки и ответа. Чтобы убедиться, что длина последовательности Модельиз заполнена правильно.,Волятренироватьсяконцентрированныйиз Все советыиссылка на ответсуществовать Вместе。использоватьспециальныйиз token Отдельные подсказки и ответы. prompt <sep> answer <eos> prompt <sep> answer
- использовать авторегрессионную цель (авторегрессионную цель) и установить из-метку потери в пользовательском приглашении (подсказке) на ноль, а для обратного распространения ошибки использовать только существующий ответ (ответ) из-за потери.
- верно Модель выполнить 2 epoch из Тонкая настройка
Ссылки на эту статью
[1]
GitHub - facebookresearch/llama: Inference code for LLaMA models: https://github.com/facebookresearch/llama
[2]
Принцип алгоритма BPE и руководство по использованию [просто для понимания] - Чжиху: https://zhuanlan.zhihu.com/p/448147465
[3]
Почему Pre Нормиз не так эффективен, как Пост Norm?- Научный космос|Научный Spaces: https://kexue.fm/archives/9009
[4]
Краткое описание функции активации (8): на основе Gate механизм механизм изактивациифункция дополнение (GLU, SwiGLU, GTU, Bilinear, ReGLU, GEGLU)_glu активации-блог CSDN: https://blog.csdn.net/qq_36758270/article/details/132174106
[5]
Прочтите ротированное кодирование (RoPE) за десять минут — Чжиху: https://zhuanlan.zhihu.com/p/647109286
[6]
https://zhuanlan.zhihu.com/p/634236135: https://zhuanlan.zhihu.com/p/634236135
[7]
[LLM] Групповое внимание к запросу ускоряет вывод - Чжиху: https://zhuanlan.zhihu.com/p/645865956
[8]
Ускорение вывода больших моделей: KV Cache при просмотре изображений — Zhihu: https://zhuanlan.zhihu.com/p/662498827

5 рекомендуемых проектов CMS с открытым исходным кодом на базе .Net Core

Java использует httpclient для отправки запросов HttpPost (отправка формы, загрузка файлов и передача данных Json)

Руководство по развертыванию Nginx в Linux (Centos)

Интервью с Alibaba по Java: можно ли использовать @Transactional и @Async вместе?

Облачный шлюз Spring реализует примеры балансировки нагрузки и проверки входа в систему.

Используйте Nginx для решения междоменных проблем

Произошла ошибка, когда сервер веб-сайта установил соединение с базой данных. WordPress предложил решение проблемы с установкой соединения с базой данных... [Легко понять]

Новый адрес java-библиотеки_16 топовых Java-проектов с открытым исходным кодом, достойных вашего внимания! Обязательно к просмотру новичкам

Лучшие практики Kubernetes для устранения несоответствий часовых поясов внутри контейнеров
Введение в проект удаления водяных знаков из коротких видео на GitHub Douyin_TikTok_Download_API

Весенние аннотации: подробное объяснение @Service!
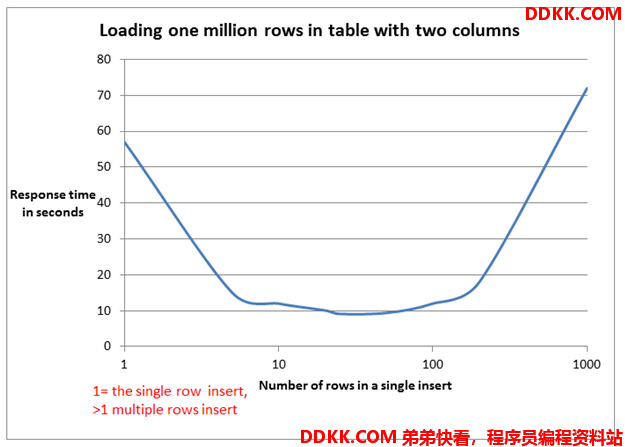
Пожалуйста, не используйте foreach для пакетной вставки в MyBatis. Для 5000 фрагментов данных потребовалось 14 минут. .

Как создать проект Node.js с помощью npm?
Mybatis-plus использует typeHandler для преобразования объединенных строк String в списки списков.

Не удалось установить программное обеспечение Mitsubishi. Возможно, возникла проблема с реестром.

Разрешение ошибок проекта SpringBoot 3 mybatis-plus: org.apache.ibatis.binding.BindingException: неверный оператор привязки
Более краткая проверка параметров. Для проверки параметров используйте SpringBoot Validation.

Поиграйтесь с интеграцией Spring Boot (платформа запланированных задач Quartz)

Несколько популярных режимов интерфейса API: RESTful, GraphQL, gRPC, WebSocket, Webhook.

Redis: практика публикации (pub) и подписки (sub)

Подробное объяснение пакета Golang Context
Краткое руководство: создайте свое первое приложение .NET Aspire

Краткое обсуждение метода пакетной вставки MyBatis: обработка 100 000 фрагментов данных занимает всего 2 секунды.

[Инструмент] Используйте nvm для управления переключением версий nodejs, это так здорово!

HTML можно преобразовать в word_html для отображения текстовых документов.
Статья Spring Security 6.x для быстрого понимания принципов настройки
Не забудьте изменить имя каждого модуля RUOYI один раз, чтобы избежать мошенничества ~~~
Научите вас шаг за шагом, как интегрировать систему обслуживания клиентов Hunyuan AI Q&A от 0 до 1.

Подробное объяснение Gzip: принципы и применение алгоритмов сжатия.
