Подробное объяснение PySpark (5) RDD для больших данных Python
Подробное объяснение СДР
Зачем вам нужен РДД?
- Прежде всего, Spark предлагался для решения задач MR-вычислений, таких как итеративные вычисления, такие как машинное обучение или графовые вычисления.
- Есть надежда, что можно будет предложить итеративную структуру данных на основе памяти и ввести эластичный распределенный набор данных RDD.
- Почему RDD отказоустойчив?
- RDD зависит от отношений зависимости
- reduceByKeyRDD-----mapRDD-----flatMapRDD
- Кроме того, многие механизмы, такие как кэширование, широковещательные переменные и механизмы контрольных точек, решают проблемы отказоустойчивости.
- Почему RDD может выполнять вычисления в памяти?
- Сама конструкция RDD основана на итеративных вычислениях в памяти.
- RDD — это абстрактная структура данных.
Что такое РДД?
- Эластичный распределенный набор данных RDD
- Эластичность: может храниться в памяти или на диске.
- Распределенное: распределенное хранилище (разделение) и распределенные вычисления.
- данныенабор:данныеизнаборобъединить
определение СДР
- RDD — это неизменяемая, разделяемая и распараллеливаемая коллекция.
- Дважды нажмите клавишу Shift в pycharm, чтобы просмотреть исходный код, rdd.py.
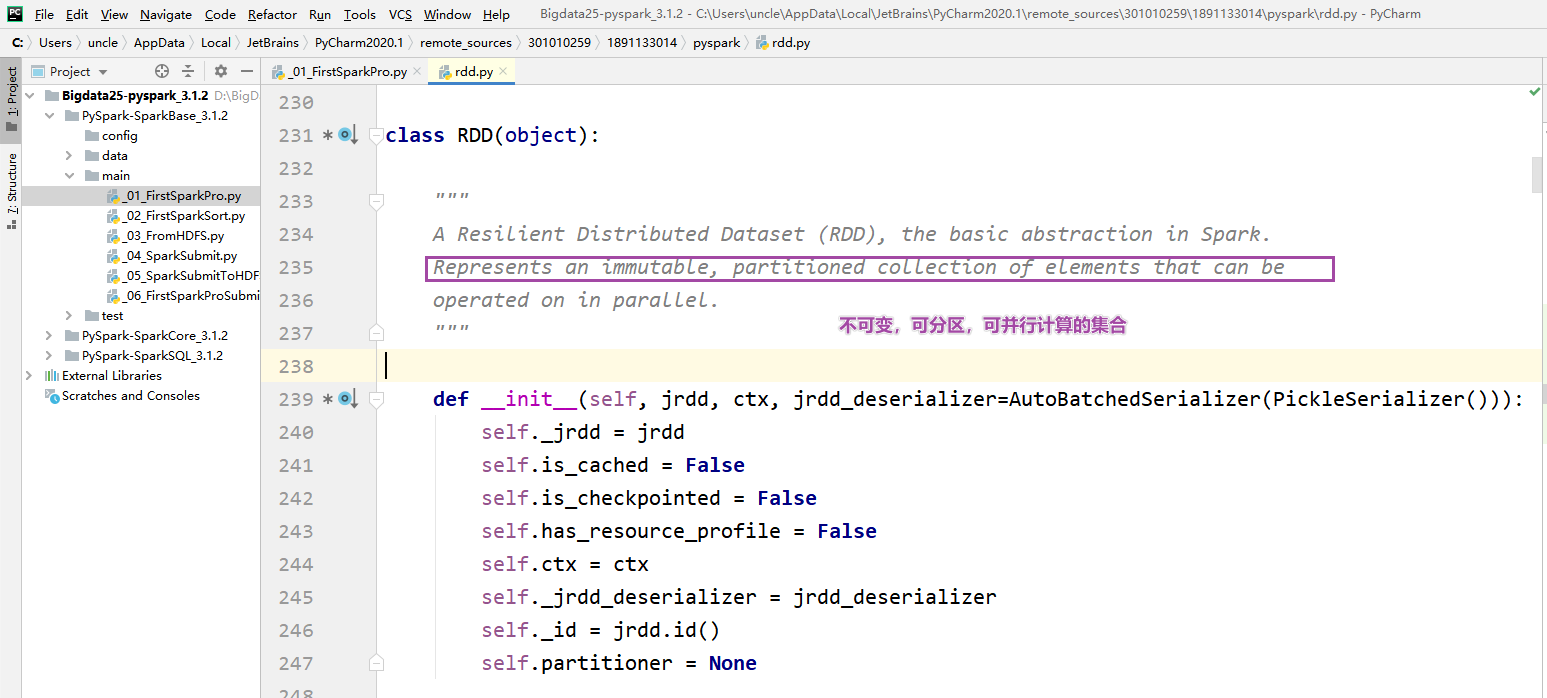
- RDD предоставляет пять основных атрибутов
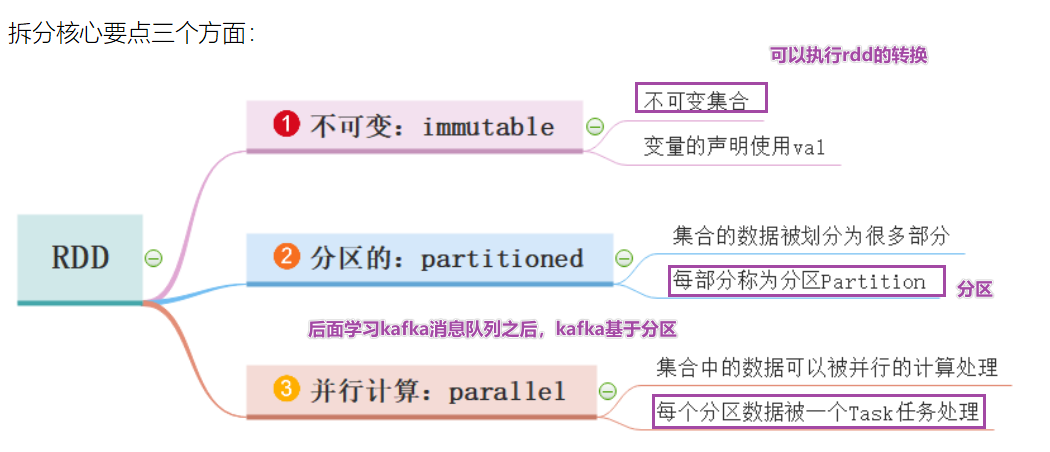
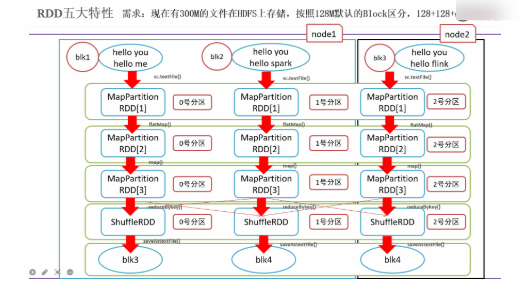
5 основных характеристик RDD
- Пять основных характеристик RDD:
- 1-RDD состоит из серии разделов, списка разделов.
- 2-Функция расчета
- 3-Зависимости, сокращение по ключу зависит от карты и плоской карты.
- 4-(Необязательно) Раздел ключ-значение,Для данных типа «ключ-значение» Разделом по умолчанию является HashРаздел.,Диапазон Раздел и т. д. можно изменить.
- 5-(Необязательно) Приоритет местоположения, мобильные компьютеры не требуют мобильного хранилища.

- 1-
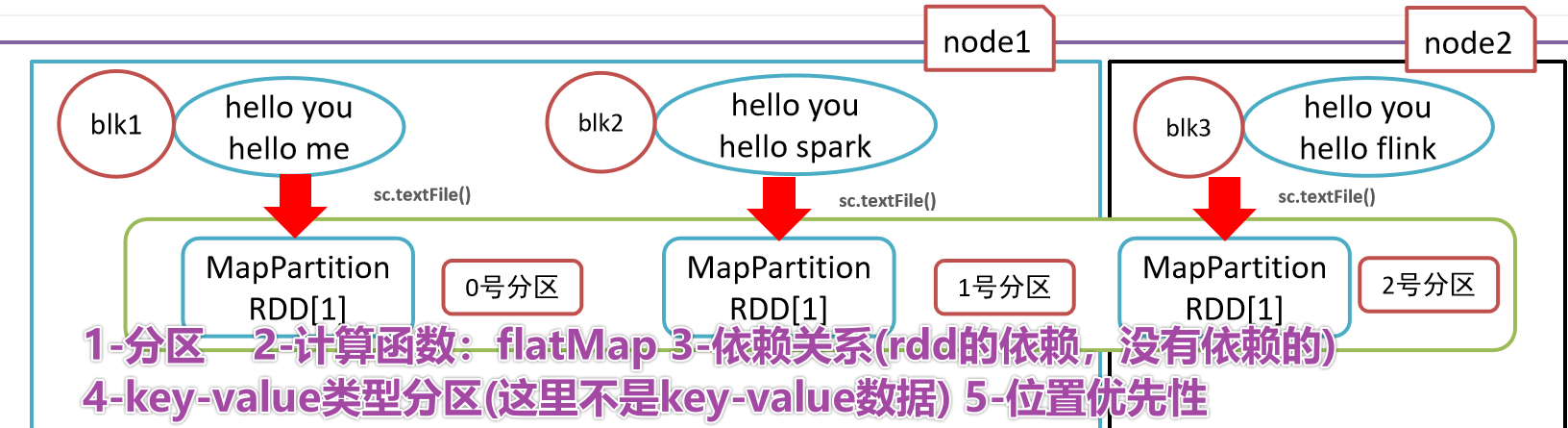
- 2-
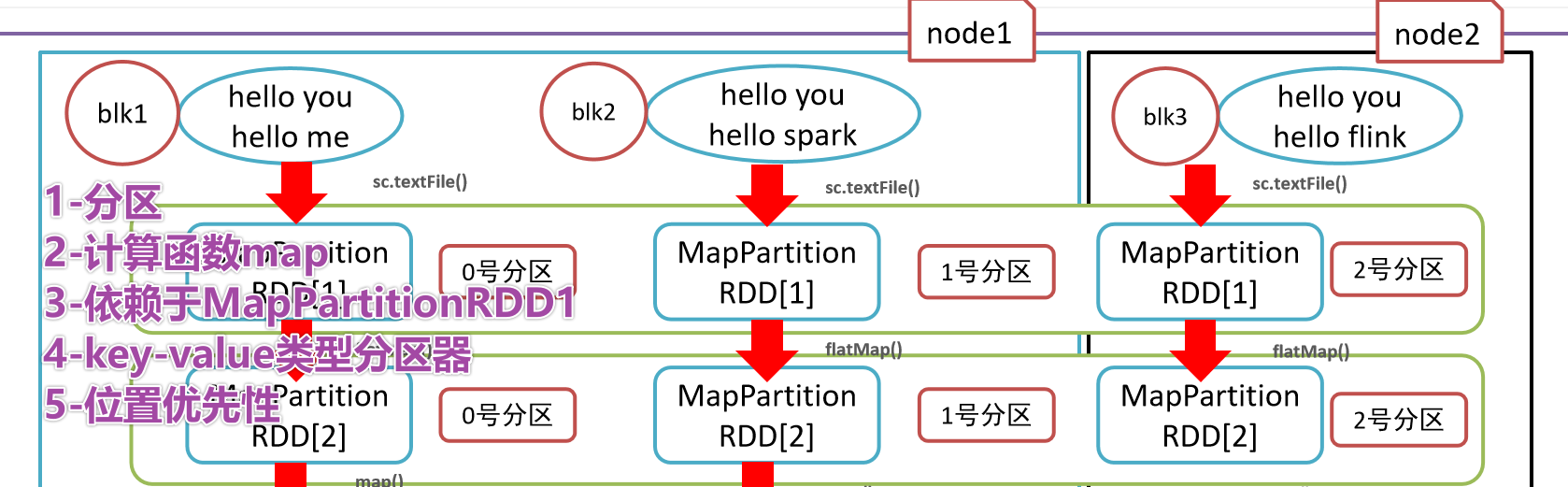
- 3-
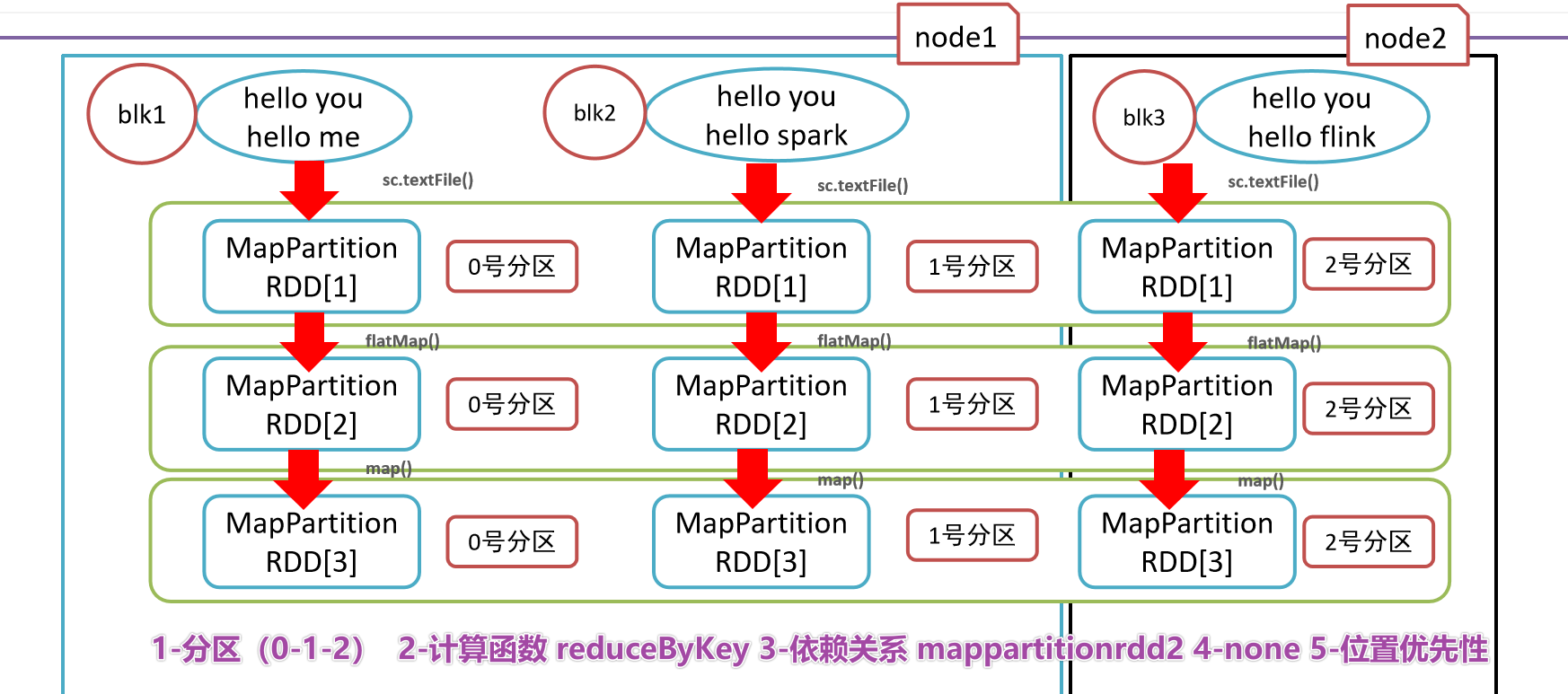
- 4-
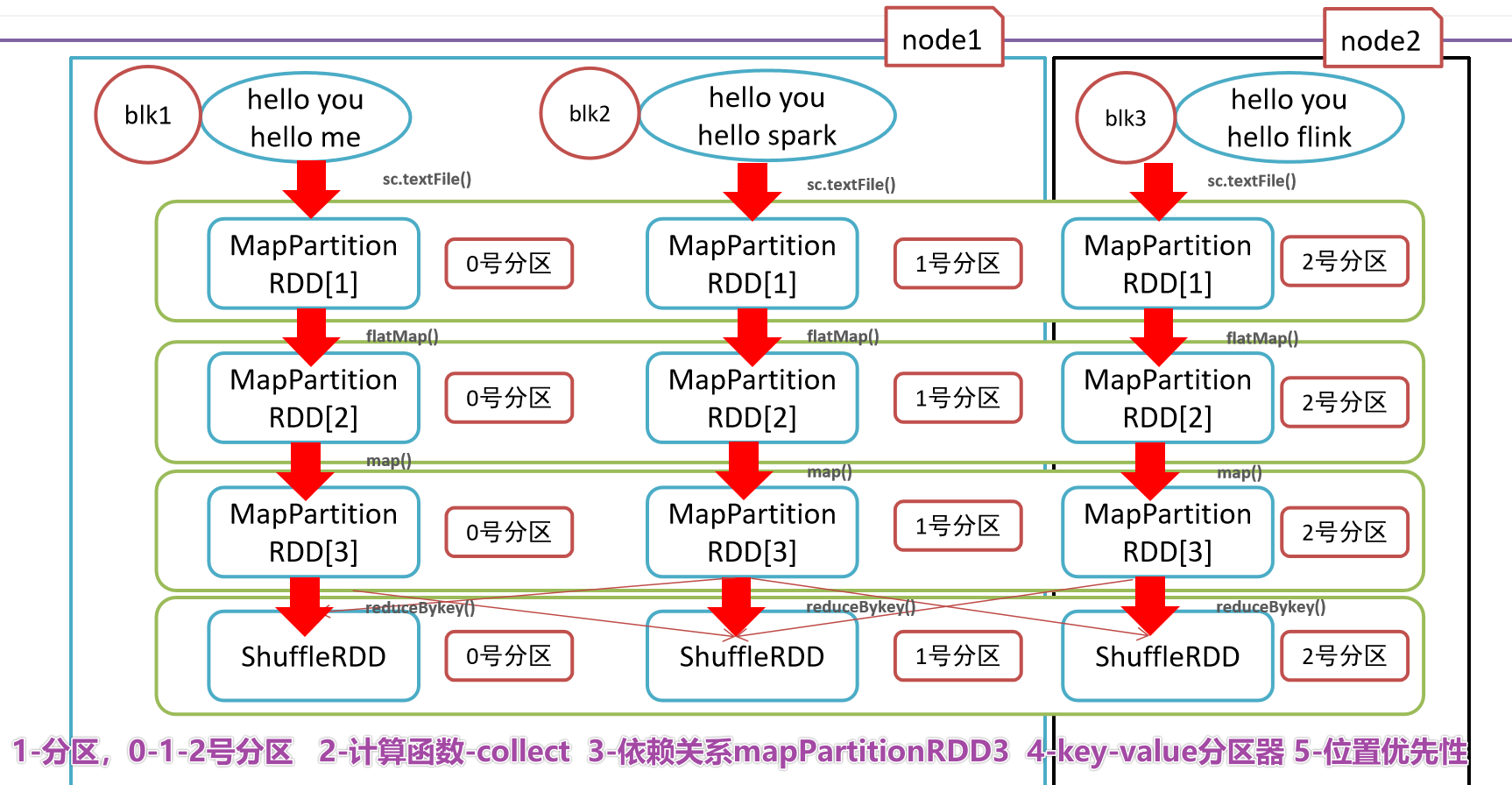
- 5-Заключительная иллюстрация
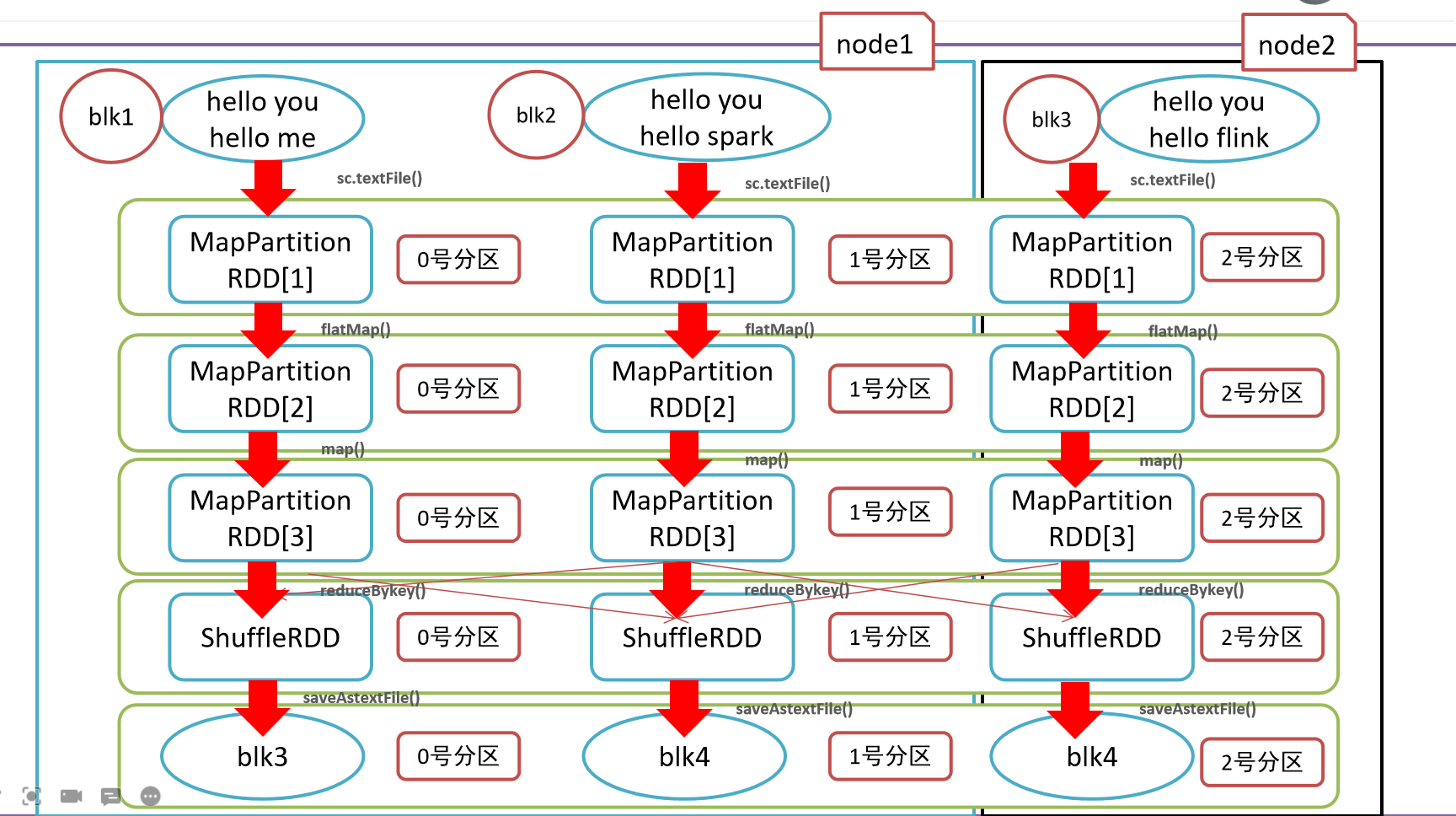
- Краткое изложение пяти основных атрибутов RDD
- 1-Список разделов
- 2-Функция расчета
- 3-Зависимости
- Разделитель с 4 ключами
- 5-позиционный приоритет
Функции RDD — память не требуется
- Раздел
- только чтение
- полагаться
- кэш
- checkpoint
СДР в WordCount
Создание РДД
Существует два способа создания РДД в PySpark.
Параллельное создание RDD rdd1=sc.paralleise([1,2,3,4,5])
Создать RDD из файла
rdd2=sc.textFile(“hdfs://node1:9820/pydata”)
Код:
# -*- coding: utf-8 -*-
# Program функция: два способа создания RDD
'''
Первый способ: использование распараллеленных коллекций, по сути, передача локальной коллекции в качестве параметра в sc.pa.
Второй способ: используйте sc.textFile для чтения внешних файловых систем, включая hdfs и локальные файловые системы.
1. Подготовьте вход в SparkContext и подайте заявку на ресурсы.
2- Первый метод с использованием создания rdd
3-секундный метод с использованием создания rdd
4-Закрыть SparkContext
'''
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
print("=========createRDD==============")
# 1 - Подготовьте вход в SparkContext и подайте заявку на ресурсы.
conf = SparkConf().setAppName("createRDD").setMaster("local[5]")
sc = SparkContext(conf=conf)
# 2 - Первый метод, созданный с использованием rdd
collection_rdd = sc.parallelize([1, 2, 3, 4, 5, 6])
print(collection_rdd.collect()) # [1, 2, 3, 4, 5, 6]
# 2-1 Как использовать API, чтобы получить количество Разделов в rdd
print("rdd numpartitions:{}".format(collection_rdd.getNumPartitions())) # 5
# 3 - Второй метод, созданный с использованием rdd
file_rdd = sc.textFile("/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/words.txt")
print(file_rdd.collect())
print("rdd numpartitions:{}".format(file_rdd.getNumPartitions())) # 2
# 4 - ЗакрытьSparkContext
sc.stop()Чтение небольшого файла
Создать RDD из внешних данных
- http://spark.apache.org/docs/latest/api/python/reference/pyspark.html#rdd-apis

# -*- coding: utf-8 -*-
# Program функция: два способа создания RDD
'''
1. Подготовьте вход в SparkContext и подайте заявку на ресурсы.
2. Чтение внешних файлов с помощью методов sc.textFile и sc.wholeTextFile.
3-ЗакрытьSparkContext
'''
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
print("=========createRDD==============")
# 1 - Подготовьте вход в SparkContext и подайте заявку на ресурсы.
conf = SparkConf().setAppName("createRDD").setMaster("local[5]")
sc = SparkContext(conf=conf)
# 2 - Для чтения внешних файлов используйте методы sc.textFile и sc.wholeTextFile\
file_rdd = sc.textFile("/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/ratings100")
wholefile_rdd = sc.wholeTextFiles("/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/ratings100")
print("file_rdd numpartitions:{}".format(file_rdd.getNumPartitions()))#file_rdd numpartitions:100
print("wholefile_rdd numpartitions:{}".format(wholefile_rdd.getNumPartitions()))#wholefile_rdd numpartitions:2
print(wholefile_rdd.take(1))# путь, конкретное значение
# Как получить Wholefile_rdd, чтобы получить конкретное значение
print(type(wholefile_rdd))#<class 'pyspark.rdd.RDD'>
print(wholefile_rdd.map(lambda x: x[1]).take(1))
# 3 - ЗакрытьSparkContext
sc.stop()* Как просмотреть Раздел rdd? getNumPartitions()Расширенное чтение: Как определить количество разделов RDD
# -*- coding: utf-8 -*-
# Program функция: два способа создания RDD
'''
Первый способ: использование распараллеленных коллекций, по сути, передача локальной коллекции в качестве параметра в sc.pa.
Второй способ: используйте sc.textFile для чтения внешних файловых систем, включая hdfs и локальные файловые системы.
1. Подготовьте вход в SparkContext и подайте заявку на ресурсы.
2- Первый метод с использованием создания rdd
3-секундный метод с использованием создания rdd
4-Закрыть SparkContext
'''
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
print("=========createRDD==============")
# 1 - Подготовьте вход в SparkContext и подайте заявку на ресурсы.
conf = SparkConf().setAppName("createRDD").setMaster("local[*]")
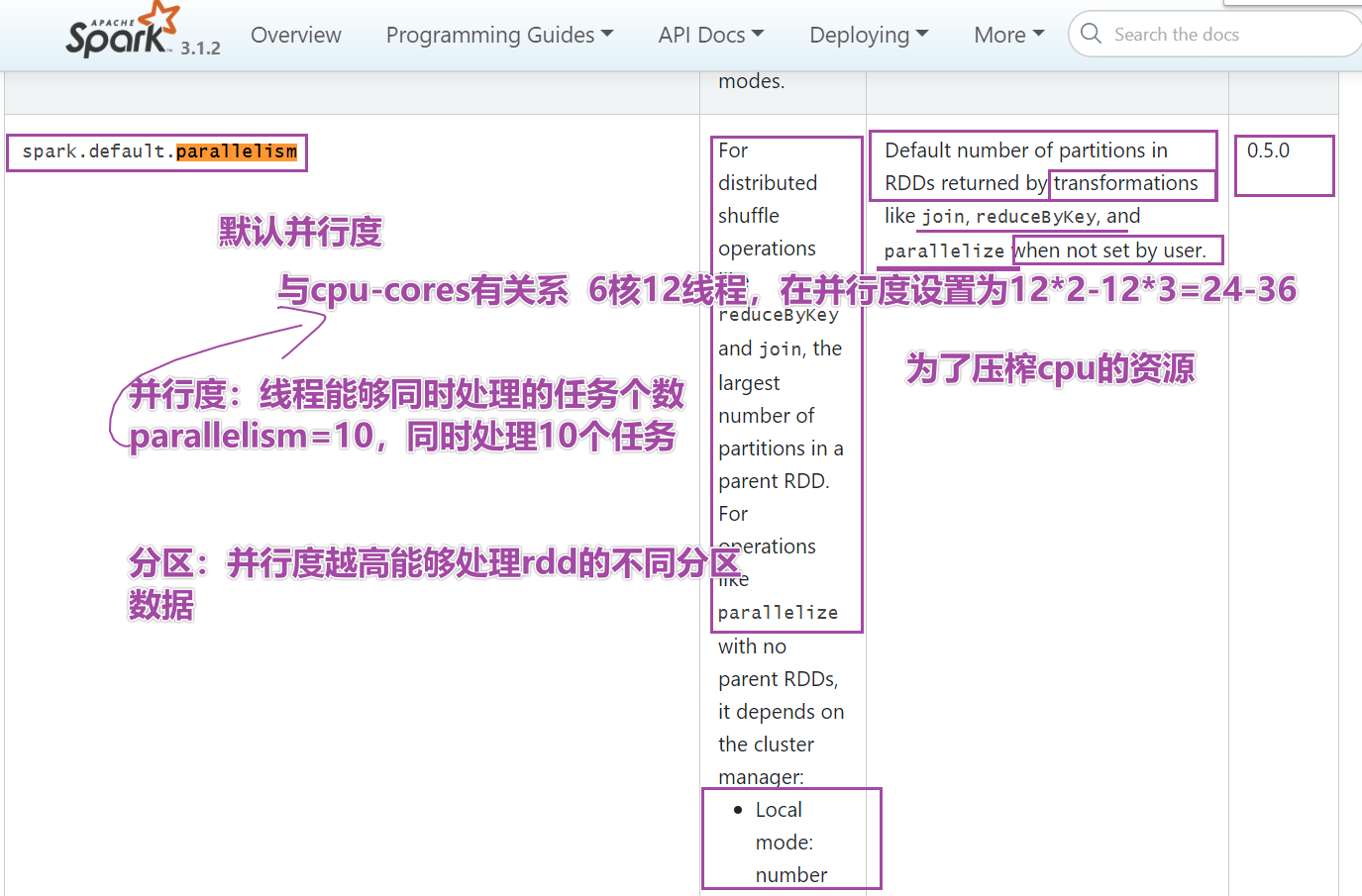
# conf.set("spark.default.parallelism",10)#Переписать степень параллелизма по умолчанию, 10
sc = SparkContext(conf=conf)
# 2 - Первый метод, созданный с использованием rdd,
collection_rdd = sc.parallelize([1, 2, 3, 4, 5, 6],5)
# 2-1 Как использовать API, чтобы получить количество Разделов в rdd
print("rdd numpartitions:{}".format(collection_rdd.getNumPartitions())) #2
# Резюме: Sparkconf устанавливает local[5] (степень параллелизма по умолчанию), sc.parallesise напрямую использует Раздел, и число равно 5.
# Если установлен spark.default.parallelism, степень параллелизма по умолчанию, sc.parallesise напрямую использует номер раздела, равный 10.
# Наивысший приоритет имеет второй параметр внутри функции. 3
# 2-2 Как распечатать содержимое каждого раздела
print("per partition content:",collection_rdd.glom().collect())
# 3 - Второй метод, созданный с использованием rdd
# minPartitions — это наименьшее количество разделов, а окончательное количество разделов основано на фактической печати.
file_rdd = sc.textFile("/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/words.txt",10)
print("rdd numpartitions:{}".format(file_rdd.getNumPartitions()))
print(" file_rdd per partition content:",file_rdd.glom().collect())
# Если sc.textFile читает несколько файлов в папке, количество Разделов здесь в основном зависит от количества файлов, и Раздел, написанный вами, не будет работать.
# file_rdd = sc.textFile("/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/ratings100", 3)
# 4 - ЗакрытьSparkContext
sc.stop()* Сначала проясните ситуацию,Количество разделов,Здесь все основано на том, что вы видите,Особенно в sc.textFile

- Два важных API
- Номер раздела getNumberPartitions
- Разделить внутренний элемент glom().collect()
постскриптум
📢Домашняя страница блога:https://manor.blog.csdn.net
📢Лайки приветствуются 👍 собирать ⭐Оставьте сообщение 📝 Поправьте меня, если есть ошибки! 📢Эту статью написал Maynor Оригинал, впервые опубликовано на Блог CSDN🙉 📢Мне кажется,что самый ласковый и долгий взгляд в этой жизни отдан моему мобильному телефону⭐ 📢Колонка постоянно обновляется,Добро пожаловать на подписку:https://blog.csdn.net/xianyu120/category_12453356.html



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
