Подробное объяснение основной технологии генеративного искусственного интеллекта: от GAN до трансформаторов.
В этой статье глубоко исследуются основные технологии генеративного искусственного интеллекта, включая GAN, VAE, авторегрессионные модели и трансформеры, подробно описываются их принципы, методы реализации и практическое применение. В ней сочетаются примеры кода и реальные случаи, чтобы продемонстрировать новейший технологический прогресс. и сценарии применения. Следуйте за автором и делитесь полноценными знаниями об искусственном интеллекте. Автор имеет более чем 10-летний опыт работы в области архитектуры интернет-сервисов, опыт исследований и разработок продуктов искусственного интеллекта, а также опыт управления командой. Он имеет степень магистра Университета Тунцзи в Университете Фудань, член Лаборатории интеллекта роботов Фудань, старший архитектор, сертифицированный Alibaba Cloud. , специалист по управлению проектами, а также занимается исследованиями и разработками продуктов искусственного интеллекта с доходом в сотни миллионов человек.

1. Введение
Генеративный ИИ ИИ), как важная отрасль искусственного интеллекта, добился значительного прогресса во многих областях, изучая большое количество данных для создания новых образцов данных. Генеративный ИИ не только стимулировал широкий интерес к академическим исследованиям, но и продемонстрировал большой потенциал в промышленных приложениях, способствуя генерации. изображения、генерация текста、Быстрое развитие в таких областях, как создание видео.
Прорывы в генеративно-состязательных сетях (GAN)
Генеративно-состязательная сеть (Генеративная Adversarial Networks, GAN) от Яна Гудфеллоу и др. предположили в 2014 году, что посредством игрового обучения между генератором и дискриминатором GAN могут добиться более высокой производительности при генерации. Замечательные успехи достигнуты в области изображения. Например, StyleGAN3 способен генерировать чрезвычайно реалистичные изображения лиц с высоким разрешением. Изображение достигает новых высот в качестве и детализации.
Достижения в области вариационных автоэнкодеров (VAE) и моделей авторегрессии
Вариационные автоэнкодеры (VAE) и авторегрессионные модели предоставляют новые способы генерации данных путем вероятностного моделирования входных данных при их создании. VAE превосходно справляются с созданием реалистичных распределений данных, а авторегрессионные модели, такие как GPT-3, демонстрируют сильные возможности в задачах генерации текста.
Применение трансформаторов
Модель Трансформеры (Трансформеры) благодаря мощным возможностям параллельной обработки и автоматическому механизму. внимания,Прорывной прогресс был достигнут в обработке естественного языка и задачах мультимодальной генерации. GPT-3 и новейшая модель GPT-4 демонстрируют беспрецедентные возможности понимания и генерации языков.,широко используется вгенерация текста、переводить、Диалоговые системы и другие области.
Широкое расширение практического применения
Потенциал генеративного ИИ в практических приложениях постепенно раскрывается. поколение Технология изображений широко используется в художественном творчество, рекламный дизайн и создание киноспецэффектов; текста Технология автоматического письма、Чат-боты и языкпереводить Значительный прогресс был достигнут в;в медицинских и научных исследованиях,Генеративный искусственный интеллект помогает прогнозировать структуры белков, разрабатывать новые лекарства и анализировать медицинские изображения.,Предоставляет новые инструменты для научных открытий.
Технические проблемы и будущие разработки
Хотя генеративный ИИ добился значительного прогресса во многих областях, он по-прежнему сталкивается со многими проблемами, такими как нестабильность обучения моделей, конфиденциальность данных и этические проблемы, а также подлинность и безопасность сгенерированного контента. Ожидается, что в будущем, благодаря постоянным инновациям и оптимизации технологий, генеративный ИИ будет играть более важную роль в более широком спектре областей и способствовать научному, технологическому и социальному прогрессу.
2. Создание состязательных сетей GAN
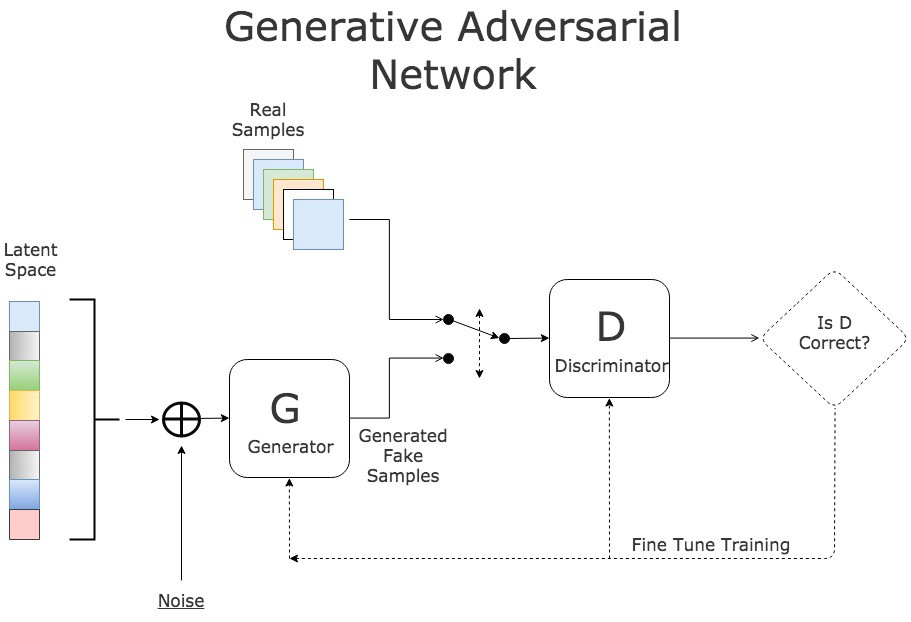
Генеративно-состязательная сеть (Генеративная Adversarial Networks, GAN) являются важным прорывом в области генеративного искусственного интеллекта. С 2014 года Ян С тех пор, как Гудфеллоу и др. предложили это, GAN быстро стали основным направлением создания Моделей. Благодаря своему уникальному механизму состязательного обучения GAN широко использовались при создании. изображения、увеличение Он продемонстрировал отличные возможности в работе с данными и во многих других приложениях.
Основные понятия GAN
GAN состоят из двух основных частей: Генератора и Дискриминатора. Генератор отвечает за генерацию данных из случайного шума.,Попытка обмануть дискриминатор; в то время как дискриминатор пытается отличить реальные данные от сгенерированных данных. Оба постоянно оптимизируются посредством состязательного обучения.,Последний генератор способен генерировать реалистичные данные.
Генератор
Задача генератора — получить случайные векторы шума и преобразовать их в выборки, аналогичные обучающим данным. В его архитектуре обычно используются транспонированные сверточные нейронные сети для повышения дискретизации данных.
import torch
import torch.nn as nn
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
nn.ConvTranspose2d(100, 512, 4, 1, 0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.ConvTranspose2d(512, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.ConvTranspose2d(256, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.ConvTranspose2d(128, 64, 4, 2, 1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.ConvTranspose2d(64, 3, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, input):
return self.main(input)
# Инициализируйте генератор и отобразите структуру
netG = Generator()
print(netG)
Дискриминатор
Задача дискриминатора — получить выборки данных и определить, являются ли они реальными данными. В его архитектуре обычно используются сверточные нейронные сети для реализации понижающей дискретизации данных.
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Conv2d(3, 64, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(128, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(256, 512, 4, 2, 1, bias=False),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(512, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
# Инициализируйте дискриминатор и отобразите структуру
netD = Discriminator()
print(netD)
Механизм обучения GAN
Процесс обучения GAN можно рассматривать как игровой процесс. Генератор и дискриминатор оптимизируются поочередно, чтобы в конечном итоге достичь равновесия Нэша. В процессе обучения цель генератора — максимизировать вероятность того, что дискриминатор вынесет неправильное суждение, а цель дискриминатора — максимизировать вероятность правильного суждения. В частности, цель обучения может быть выражена следующей формулой:
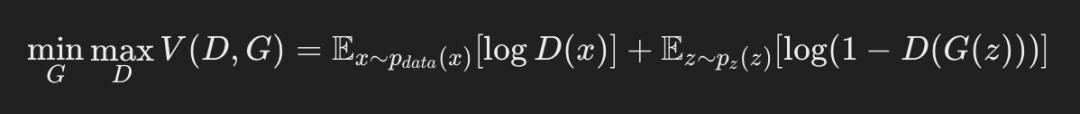
Пример кода процесса обучения
Ниже приведена базовая структура кода для обучения GAN с использованием PyTorch:
import torch.optim as optim
# Функции потерь и оптимизаторы
criterion = nn.BCELoss()
optimizerD = optim.Adam(netD.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=0.0002, betas=(0.5, 0.999))
for epoch in range(num_epochs):
for i, data in enumerate(dataloader, 0):
# Обновить дискриминатор
netD.zero_grad()
real = data[0].to(device)
batch_size = real.size(0)
label = torch.full((batch_size,), real_label, device=device)
output = netD(real).view(-1)
errD_real = criterion(output, label)
errD_real.backward()
D_x = output.mean().item()
noise = torch.randn(batch_size, 100, 1, 1, device=device)
fake = netG(noise)
label.fill_(fake_label)
output = netD(fake.detach()).view(-1)
errD_fake = criterion(output, label)
errD_fake.backward()
D_G_z1 = output.mean().item()
errD = errD_real + errD_fake
optimizerD.step()
# генератор обновлений
netG.zero_grad()
label.fill_(real_label)
output = netD(fake).view(-1)
errG = criterion(output, label)
errG.backward()
D_G_z2 = output.mean().item()
optimizerG.step()
# Распечатать прогресс обучения
if i % 50 == 0:
print(f'[{epoch}/{num_epochs}][{i}/{len(dataloader)}] '
f'Loss_D: {errD.item():.4f} Loss_G: {errG.item():.4f} '
f'D(x): {D_x:.4f} D(G(z)): {D_G_z1:.4f} / {D_G_z2:.4f}')
Практические случаи применения
генерация изображения
GAN достигли замечательных результатов в области генерации изображений. StyleGAN3 — это усовершенствованная GAN, предложенная NVIDIA.,Способен генерировать реалистичные изображения лиц с высоким разрешением. Его главное нововведение заключается в улучшении архитектуры и процесса обучения генератора.,Полученное изображение более реалистично в деталях и общей структуре.
увеличение данных
В науке о данных и машинном обучении нехватка данных является распространенной проблемой. GAN могут расширять наборы обучающих данных за счет создания новых образцов данных и особенно широко используются в таких областях, как медицинские изображения и текстовые данные. Например, при обработке медицинских изображений GAN могут генерировать новые образцы поражений, тем самым повышая производительность моделей обнаружения заболеваний.
художественное творчество
GANsсуществоватьхудожественное Применение в творчестве также очень широко. Обучая GAN созданию произведений искусства, художники и дизайнеры могут исследовать новые творческие стили и выражения. Например, DeepArt использует технологию GAN для создания изображений в художественном стиле и предоставления пользователям персонализированных художественных изображений. творчество Служить。
3. Вариационные автоэнкодеры VAE
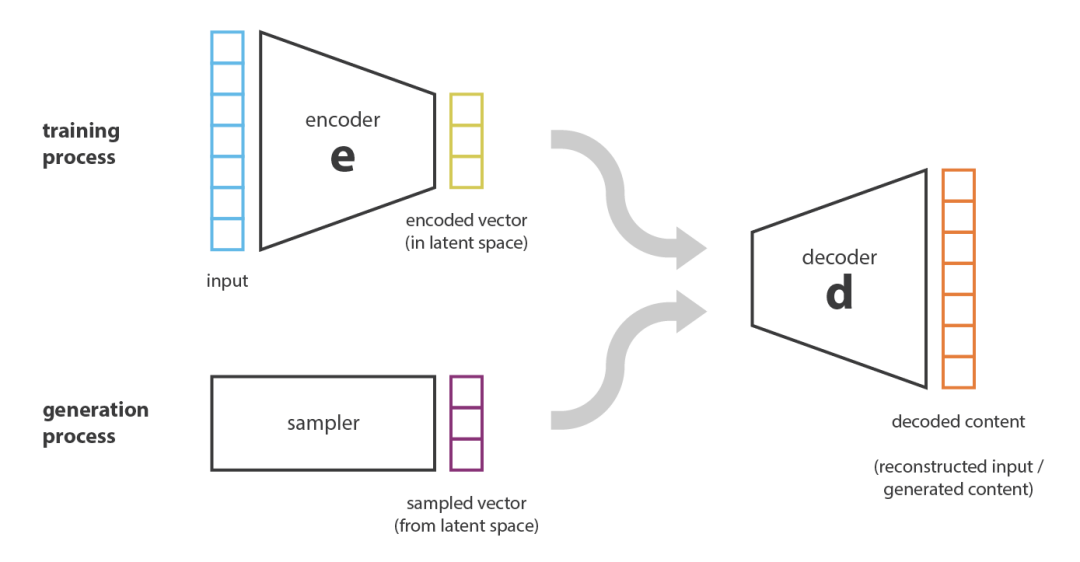
Вариационный автоэнкодер Autoencoders, VAE) — еще одна основная технология генеративного искусственного интеллекта. VAE устраняют ограничения традиционных автоматических методов создания новых моделей путем введения вероятностной модели и вариационного вывода. VAE в генерации изображения、Уменьшение размерности данныхи Обнаружение Он имеет важные применения в аномалиях и других аспектах.
Основные понятия VAE
Ограничения автоэнкодеров
Традиционные автокодировщики используют кодировщик для сжатия входных данных в потенциальное представление, а затем используют декодер для восстановления входных данных. Однако традиционные автокодировщики имеют ограничения при генерации новых данных, поскольку их скрытое пространство не моделирует распределения вероятностей явно.
Принцип вариационного автоэнкодера
Вариационные автоэнкодеры (VAE) решают проблему генерации традиционных автоэнкодеров путем введения вероятностного моделирования. Основная идея состоит в том, чтобы сопоставить входные данные со скрытым пространством с известным распределением (обычно распределением Гаусса) и оптимизировать его путем максимизации нижней границы доказательства (ELBO).
Цель вариационного автоэнкодера достигается за счет следующих шагов:
- кодер:войдетданные( x ) отображается в потенциальное представление ( z ) условное распределение вероятностей ( q(z|x) )。
- декодер:из погружениясуществоватьвыражать ( z ) генерироватьданные ( x ) Условное распределение вероятностей ( p(x|z) )。
- Цель оптимизации:Максимизируйте вариационную нижнюю границу(ELBO),Формула:

Реализация кодера и декодера
Вот базовый пример кода для реализации VAE с использованием PyTorch:
import torch
import torch.nn as nn
import torch.nn.functional as F
class VAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(VAE, self).__init__()
# кодер
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2_mean = nn.Linear(hidden_dim, latent_dim)
self.fc2_logvar = nn.Linear(hidden_dim, latent_dim)
# декодер
self.fc3 = nn.Linear(latent_dim, hidden_dim)
self.fc4 = nn.Linear(hidden_dim, input_dim)
def encode(self, x):
h1 = F.relu(self.fc1(x))
return self.fc2_mean(h1), self.fc2_logvar(h1)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
h3 = F.relu(self.fc3(z))
return torch.sigmoid(self.fc4(h3))
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
# Инициализируйте VAE и отобразите структуру
input_dim = 784 # В качестве примера возьмем набор данных MNIST.
hidden_dim = 400
latent_dim = 20
vae = VAE(input_dim, hidden_dim, latent_dim)
print(vae)
Реализация функции потерь
При обучении VAE необходимо определить соответствующие функции потерь, включая потери при реконструкции и потери при расхождении KL. Ниже приведен код реализации:
def loss_function(recon_x, x, mu, logvar):
BCE = F.binary_cross_entropy(recon_x, x, reduction='sum')
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLD
Практическое применение ВАЭ
генерация изображения
VAEsВ поколении Приложения в области изображений широко распространены. Например, в наборе данных MNIST VAE способны генерировать реалистичные изображения рукописных цифр. Путем выборки скрытого пространства можно создать бесконечное количество образцов изображений, улучшая качество изображения. изображения Разнообразие задач.
Уменьшение размерности данных
VAE сжимают и реконструируют данные,Способен эффективно выполнять извлечение признаков и извлечение признаков. По сравнению с традиционными методами уменьшения размерности, такими как PCA,VAE способны улавливать нелинейную структуру данных.,Обеспечивает более богатое потенциальное представление.
Обнаружение аномалий
Потому что VAE хорошо справляются с восстановлением обычных данных.,И ошибка реконструкции велика при работе с исключениями данных.,Поэтому VAE широко используются при обнаружении аномалий. Например,Обнаружение неисправностей промышленного оборудования,VAE могут отслеживать ошибки реконструкции с помощью,Своевременно обнаруживайте неисправности оборудования.
4. Авторегрессионные модели.
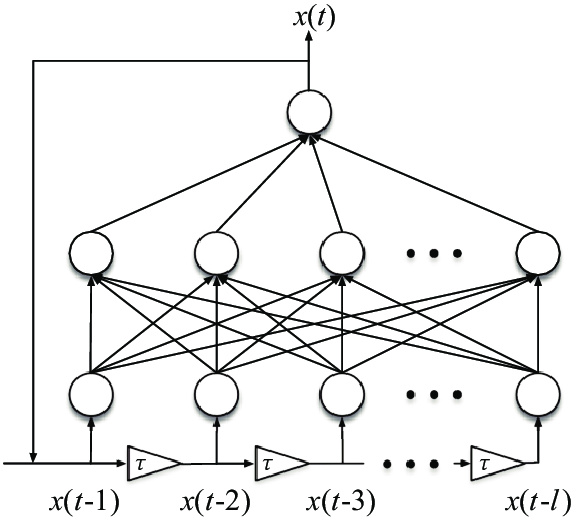
Авторегрессионная модель Модели) — важная категория в генеративном ИИ. Моделируя условные зависимости в последовательности, авторегрессионная модель может постепенно генерировать последовательности последовательностей, таких как текст, аудио и изображения. Авторегрессионная модель в обработке естественного языка、генерация речиигенерация изображения и другие области имеют широкий спектр применения.
Основные понятия авторегрессионных моделей
Определение авторегрессионной модели
Авторегрессионная модель — это статистическая модель, используемая для описания зависимостей в последовательности данных. Основная идея заключается в том, что данные в текущий момент зависят от данных в предыдущий момент. В генеративном искусственном интеллекте авторегрессионные модели генерируют всю последовательность, шаг за шагом предсказывая следующую точку данных.
Формульное представление авторегрессионной модели
Процесс генерации авторегрессионной модели можно выразить как:

Реализация авторегрессионной модели
Базовая модель авторегрессии
Простейшая авторегрессия Модельлинеен Авторегрессионная модель Integrated Moving Average, ARIMA), который предполагает, что данные на текущий момент представляют собой линейную комбинацию предыдущих данных. Для генеративного ИИ мы обычно используем более сложные модели глубокого обучения, такие как рекуррентные нейронные сети (RNN), сети долгосрочной краткосрочной памяти (LSTM) и трансформаторы.
Реализация моделей авторегрессии с использованием RNN
Вот пример кода, использующий PyTorch для реализации простой RNN для генерации текстовых последовательностей:
import torch
import torch.nn as nn
import torch.optim as optim
# Определение RNNМодель
class RNNModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNNModel, self).__init__()
self.hidden_size = hidden_size
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x, hidden):
out, hidden = self.rnn(x, hidden)
out = self.fc(out)
return out, hidden
def init_hidden(self, batch_size):
return torch.zeros(1, batch_size, self.hidden_size)
# Настройки параметров
input_size = 10
hidden_size = 20
output_size = 10
batch_size = 5
seq_length = 15
# Инициализируйте модель и параметры
model = RNNModel(input_size, hidden_size, output_size)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Пример создания данных
data = torch.randn(batch_size, seq_length, input_size)
labels = torch.randint(0, output_size, (batch_size, seq_length))
# Модель обучения
hidden = model.init_hidden(batch_size)
model.train()
for epoch in range(10):
optimizer.zero_grad()
output, hidden = model(data, hidden)
loss = criterion(output.view(-1, output_size), labels.view(-1))
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}, Loss: {loss.item()}')
Применение модели авторегрессии
обработка естественного языка
Авторегрессионная модель в обработке естественного языка(NLP)Наиболее широко используется в,Предварительно обученные языки, такие как Модель GPT-3. GPT-3 — крупномасштабный авторегрессионный язык. Модель,Способен генерировать высококачественный текст на естественном языке. Основная идея состоит в том, чтобы дословно генерировать текст на основе заданного контекста.,Сделайте сгенерированный контент связным и грамматическим.
генерация речи
В поколении В области речи авторегрессионная модель также продемонстрировала сильные возможности. Например, WaveNet — это генерация, основанная на авторегрессионной модели. речисеть,Путем моделирования условной вероятности аудиосэмплов,Способен генерировать высококачественные речевые сигналы. Процесс генерации WaveNet выполняется выборка за выборкой.,Сделайте сгенерированную речь естественной и деликатной.
генерация изображения
авторегрессионный Модель В поколении Приложения для работы с изображениями включают PixelRNN и PixelCNN, которые генерируют изображения попиксельно и способны фиксировать сложные зависимости в изображениях. Например, PixelCNN моделирует каждый пиксель по распределение вероятностей, генерировать качественные изображения.
пять、Трансформеры
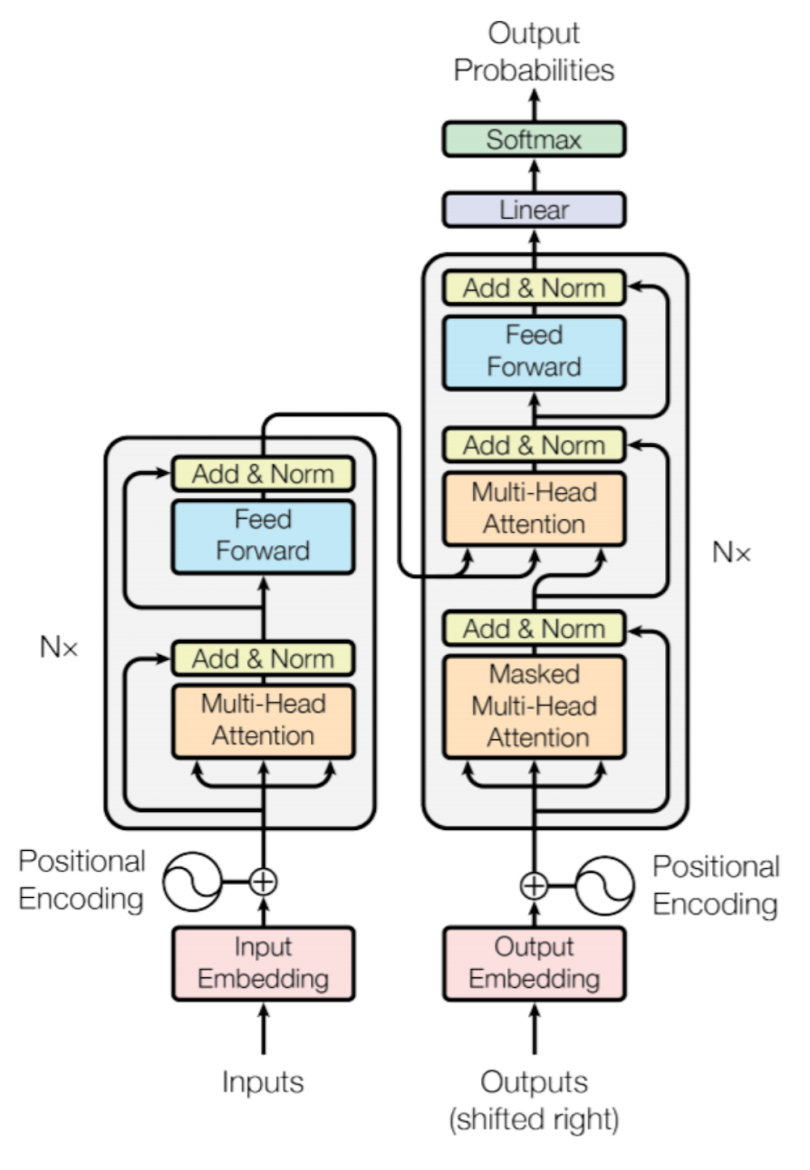
Трансформеры (Transformers) стали революционной технологией в области генеративного искусственного интеллекта за последние годы. С момента предложения Васвани и др. в 2017 году Трансформеры широко используются в обработке естественного языка (НЛП), компьютерном зрении (CV) и кросс-модальной. Он продемонстрировал отличные характеристики и широкое применение в задачах генерации. Основное преимущество Transformers заключается в его мощных возможностях параллельных вычислений и способности эффективно обрабатывать зависимости на больших расстояниях.
Основные понятия Трансформеров
механизм внимания
Суть Трансформеров заключается в их механизме. внимание, тем более, что механизм внимания(Self-Attention)。механизм внимание позволяет модели обрабатывать каждый входной фокус на всю входную последовательность, тем самым фиксируя глобальные зависимости. В частности, поскольку механизм внимание Вычислить корреляцию между каждым элементом входной последовательности и другими элементами,Затем выполните взвешенную сумму на основе этих корреляций.,тем самым создавая новое представление.
бычье внимание
бычье внимание(Multi-Head Внимание) путем распараллеливания нескольких механизмов внимание, еще больше расширяет возможности Модели улавливать различные характеристики и зависимости. бычье Формула внимания такова:
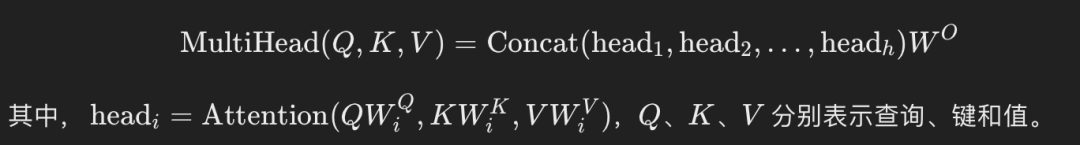
кодирование положения
Поскольку Трансформеры не имеют рекурсивной структуры, необходимо ввести кодирование. положения(Positional Кодирование) для ввода информации о положении элементов в последовательности. кодирование Положение обычно определяется с помощью функций синуса и косинуса:
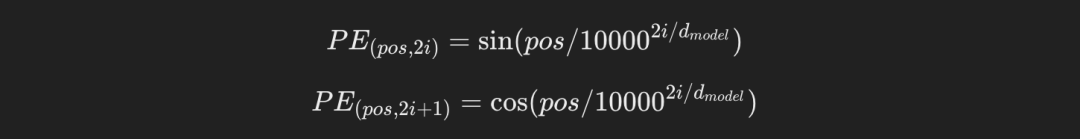
Архитектура кодировщика-декодера
Transformersиспользовать Архитектура кодировщика-декодера. кодер состоит из нескольких слоев кодирования, каждый уровень кодирования содержит бычье внимание и нейронная сеть прямого распространения (Feed-Forward Neural Network, FFN); декодер также состоит из нескольких слоев декодирования, за исключением бычьего, похожего на кодер. Помимо внимания и FFN, он также включает Cross-Attention для обработки вывода кодера.
Ниже приведен пример кода упрощенного кодировщика Transformer, реализованного в PyTorch:
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, embed_size, heads):
super(MultiHeadAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert self.head_dim * heads == embed_size, "Embedding size needs to be divisible by heads"
self.values = nn.Linear(self.head_dim, embed_size, bias=False)
self.keys = nn.Linear(self.head_dim, embed_size, bias=False)
self.queries = nn.Linear(self.head_dim, embed_size, bias=False)
self.fc_out = nn.Linear(embed_size, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.embed_size
)
out = self.fc_out(out)
return out
class TransformerBlock(nn.Module):
def __init__(self, embed_size, heads, dropout, forward_expansion):
super(TransformerBlock, self).__init__()
self.attention = MultiHeadAttention(embed_size, heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = nn.Sequential(
nn.Linear(embed_size, forward_expansion * embed_size),
nn.ReLU(),
nn.Linear(forward_expansion * embed_size, embed_size)
)
self.dropout = nn.Dropout(dropout)
def forward(self, value, key, query, mask):
attention = self.attention(value, key, query, mask)
x = self.dropout(self.norm1(attention + query))
forward = self.feed_forward(x)
out = self.dropout(self.norm2(forward + x))
return out
class Encoder(nn.Module):
def __init__(self, embed_size, num_layers, heads, device, forward_expansion, dropout, max_length):
super(Encoder, self).__init__()
self.embed_size = embed_size
self.device = device
self.word_embedding = nn.Embedding(max_length, embed_size)
self.position_embedding = nn.Embedding(max_length, embed_size)
self.layers = nn.ModuleList(
[
TransformerBlock(
embed_size,
heads,
dropout=dropout,
forward_expansion=forward_expansion,
)
for _ in range(num_layers)
]
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)
out = self.dropout(self.word_embedding(x) + self.position_embedding(positions))
for layer in self.layers:
out = layer(out, out, out, mask)
return out
# Инициализировать кодер и отобразить структуру
embed_size = 512
num_layers = 6
heads = 8
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
forward_expansion = 4
dropout = 0.1
max_length = 100
encoder = Encoder(embed_size, num_layers, heads, device, forward_expansion, dropout, max_length).to(device)
print(encoder)
Применение трансформаторов
обработка естественного языка
существоватьобработка естественного В области языка (НЛП) «Трансформеры» показали большие возможности. BERT на основе трансформаторов (двунаправленный Encoder Representations from Трансформаторы)иGPT(Генераторные Pre-trained Transformer) модель, которая значительно повышает производительность таких задач, как машинный перевод, генерация текста и вопросно-ответные системы. Например, модель GPT-3 OpenAI может генерировать высококачественный текст на естественном языке и широко используется в таких областях, как диалоговые системы, создание контента и генерация кода. 。
компьютерное зрение
Transformersсуществоватькомпьютерное Важный прогресс также был достигнут в области зрения. Ви Т(Видение Transformer) использует механизм Transformers, разделяя изображение на фрагменты фиксированного размера и рассматривая каждый фрагмент как элемент последовательности. внимание обрабатывает данные изображений. ViT достигает превосходной производительности в задачах классификации изображений, демонстрируя потенциал Трансформеров в задачах машинного зрения по сравнению с традиционными сверточными нейронными сетями (CNN). 。
Кросс-модальная генерация
Transformersсуществовать Кросс-модальная Отличная производительность в задачах генерации, таких как модель DALL-E от OpenAI. DALL-E демонстрирует возможности Transformers в работе с мультимодальными изображениями путем преобразования текстовых описаний в изображения. Модель способна генерировать изображения высокого качества и широко используется в художественном оформлении. творчество, рекламный дизайн и генерация контента. 。



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
