Подробное объяснение оптимизации и разработки архитектуры от Hadoop1.0 до Hadoop2.0.
1. Хадуп 1.0
Hadoop1.0 — это первое поколение Hadoop, которое состоит из распределенной системы хранения HDFS и платформы распределенных вычислений. MapReduce состоит из NameNode и нескольких DateNodes, а MapReduce состоит из JobTracker и нескольких TaskTracker.
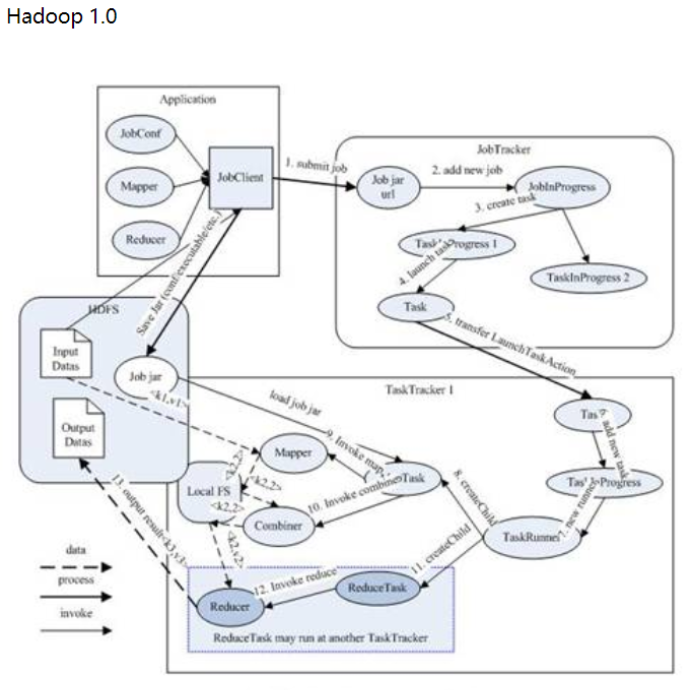
1.1HDFS1.0
HDFS использует модель структуры «главный/подчиненный». Кластер HDFS включает узел имени и несколько узлов данных. Узел имен служит центральным сервером и отвечает за управление пространством имен файловой системы и клиентским доступом к файлам. Среди них главный узел называется узлом Namenode, а подчиненный узел называется узлом DataNode.
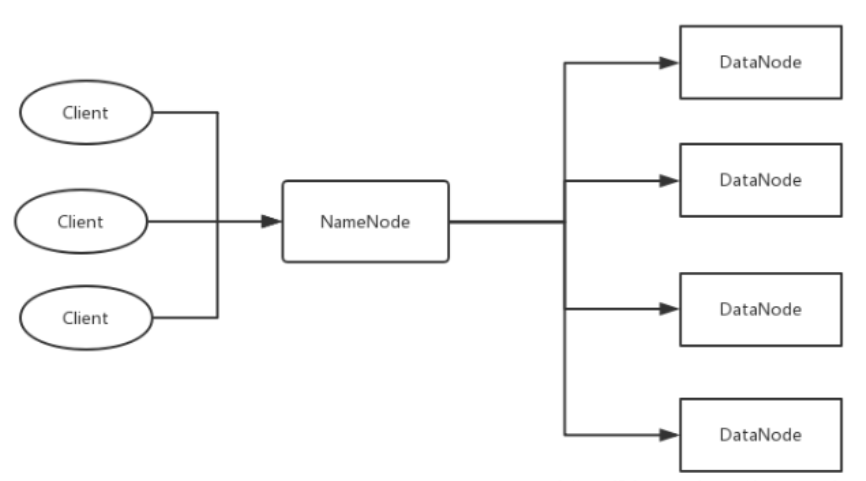
- NameNode управляет всей файловой системой и отвечает за получение запросов на операции пользователя.
- NameNode управляет структурой каталогов всей файловой системы. Так называемая структура каталогов аналогична архитектуре нашей операционной системы Windows.
- NameNode управляет информацией метаданных всей файловой системы. Так называемое обозначение информации метаданных относится к соответствующей информации, относящейся к самому файлу, в дополнение к самим данным.
- NameNode поддерживает соответствие между файлами и последовательностями блоков, а также соответствие между блоками и узлами DataNode. Для третьего узла имени точки сохраните метаданные:
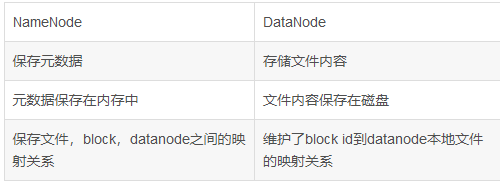
(1). На диске: Fslnage и EditLog.
(2). В памяти: информация о сопоставлении, то есть какие блоки содержит файл и в каком узле данных хранится каждый блок.
Существует только один узел имени. Хотя данные можно синхронизировать и резервировать через SecondaryNameNode и NameNode, всегда будет определенная задержка. Если NameNode зависает, данные все равно могут оставаться, если некоторые данные не были синхронизированы с SecondaryNameNode. Потерянный вопрос.
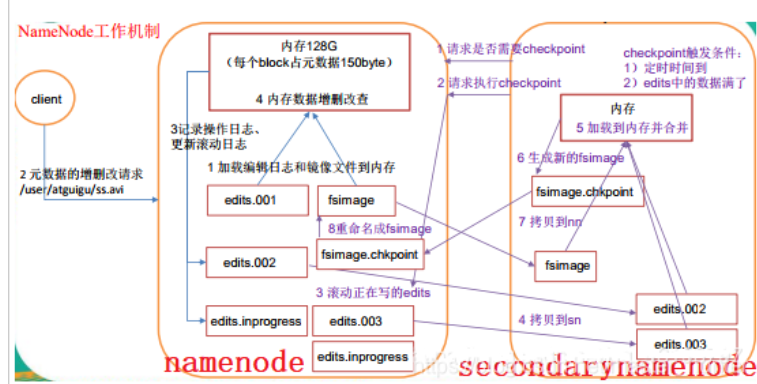
Второй узел имени периодически обменивается данными с узлом первого имени.
дефект:
- Проблема единой точки отказа: NameNode содержит всю информацию метаданных наших файлов пользовательского хранилища. Когда наш NameNode не может загрузить всю информацию метаданных в память, кластер столкнется с крахом. Второй узел имени не может решить проблему единой точки отказа.
- Его нельзя расширить по горизонтали, но можно расширить по вертикали для добавления жестких дисков, но это неудобно и негибко. NameNode одного компьютера должен достичь своего предела.
- Общая производительность системы ограничена пропускной способностью одного узла имени.
- Один namenode не может обеспечить изоляцию между разными программами.
- Secondaryname имеет только функцию холодного резервного копирования.
1.2MadReduce1.0
Для MapReduce это также структура «главный-подчиненный», состоящая из JobTracker (главного) и нескольких TaskTracker (подчиненных).
MapReduce1.0 — это одновременно вычислительная среда и платформа управления ресурсами и планирования.
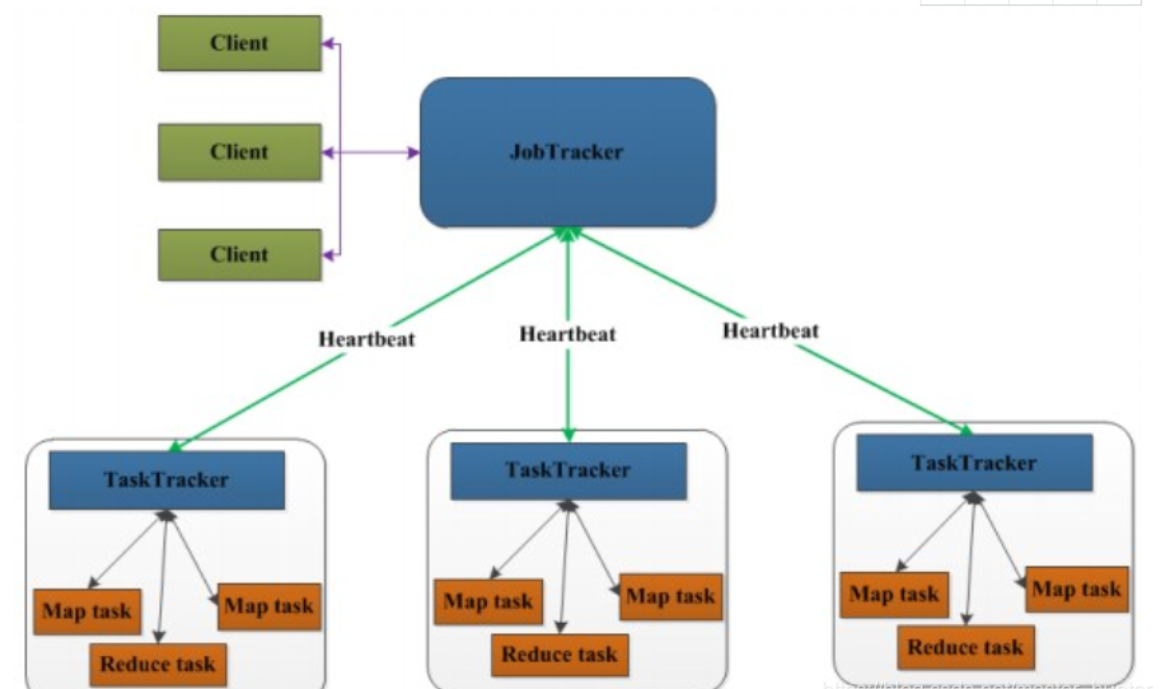
Видно, что JobTracker эквивалентен планировщику управления ресурсами и должен обрабатывать большое количество задач. И если произойдет ошибка, кластер неизбежно рухнет.
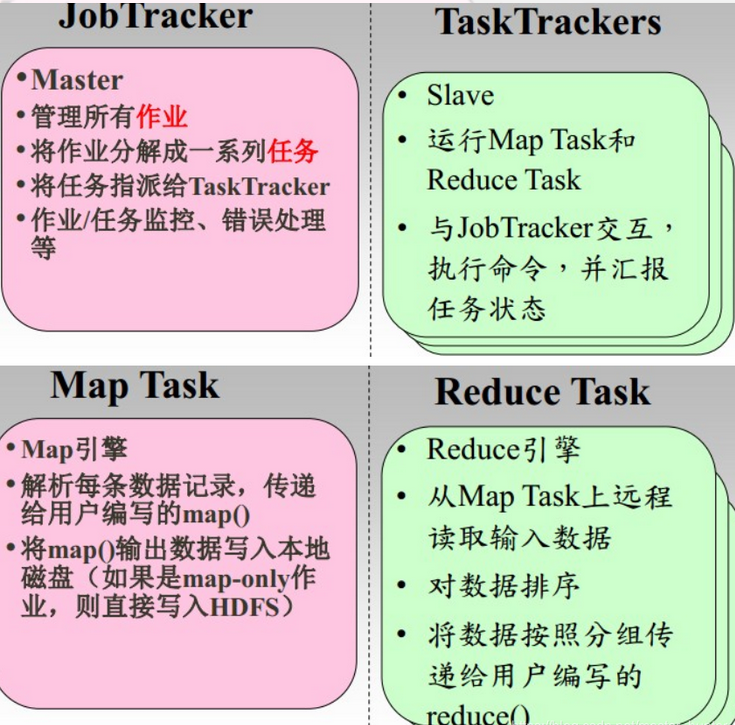
Функции каждой роли:
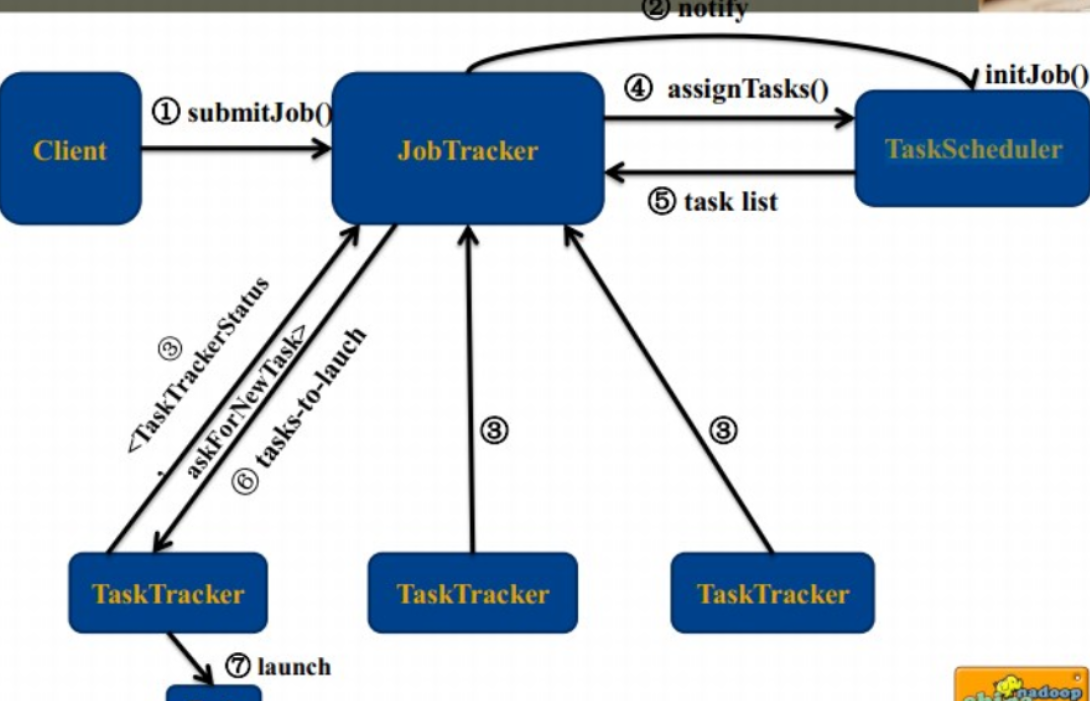
Блок-схема планирования работы:
дефект:
- Существует проблема единой точки отказа. Как только главный узел выходит из строя, JobTracker выходит из строя, и другие узлы больше не могут работать.
- JobTacker перегружен, а накладные расходы слишком высоки, если задач много.
- Часто возникает переполнение памяти, и при выделении ресурсов учитывается только количество задач MapReduce, а не ЦП и память.
- Необоснованное разделение ресурсов (принудительное разделение на слоты, включая слот карты и слот уменьшения)
2.Хадуп2.0
По сравнению с Hadoop 1.0, версия 2 намного лучше. В этом нет никаких сомнений. С новыми обновлениями ухудшиться невозможно.
Давайте подробнее рассмотрим, что добавлено во вторую версию.
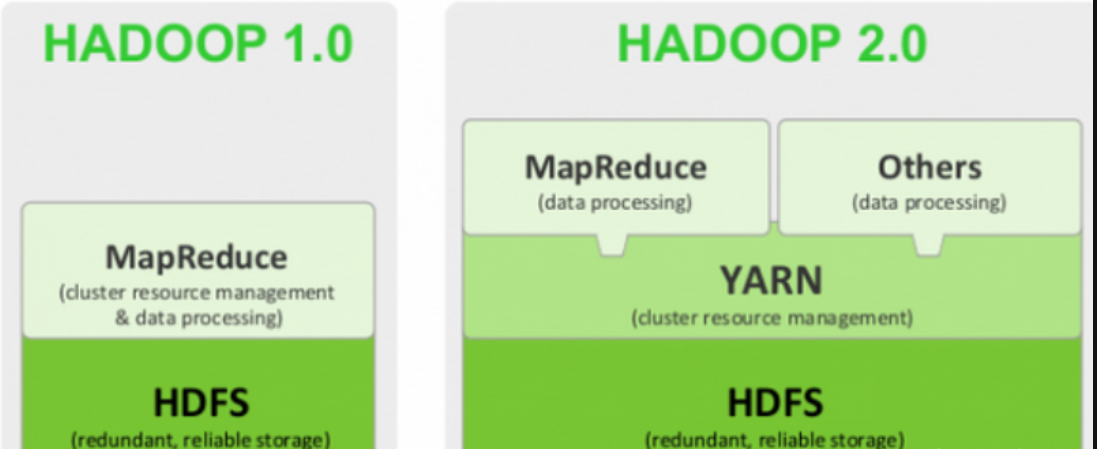
2.1HDFS2.0
2.1.1HDFS HA
HDFS HA (High Availability) предназначен для решения проблемы единой точки отказа.
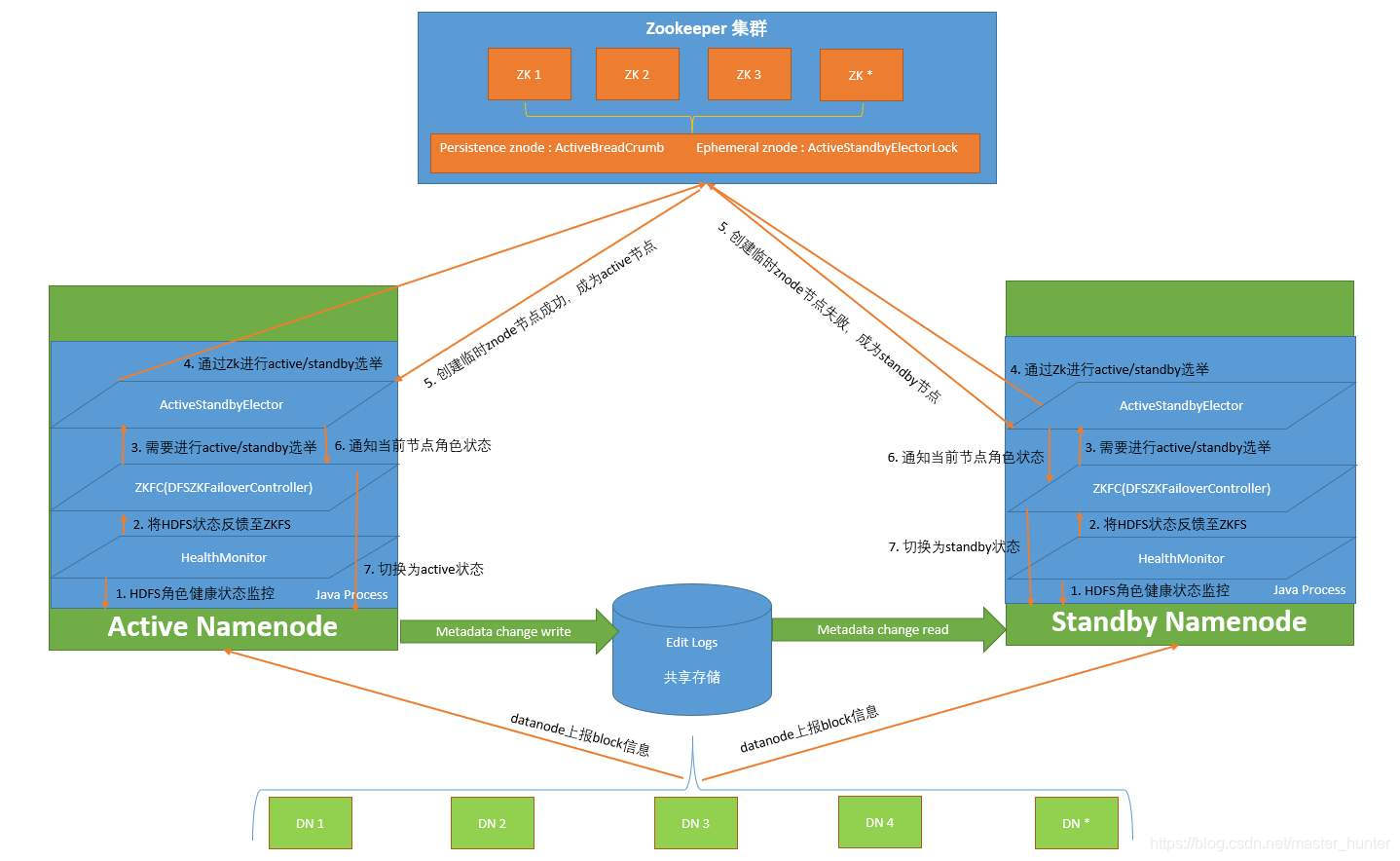
JN: узел журнала JounrnalNode. В течение периода обучения для развертывания JN обычно используются 3 узла.
ZKFC: полное имя — ZooKeeper Failover Controller. Его номер совпадает с количеством NN. Он отвечает за мониторинг состояния работоспособности узлов NN и отправку контрольных сигналов в ZK, чтобы указать, что он все еще работает. и статус NN зависает, то ZK может быть разрешено немедленно выбрать новый NN (на самом деле переключатель состояния резервного NN называется активным), поэтому ZKFC является демон-процессом NN и обычно развертывается на нем. тот же узел, что и соответствующий ему NN.
ЗК: ZooKeeper, когда активная NN умирает, из резервного узла NN выбирается новая NN, которая будет служить активной NN для предоставления внешних услуг. Один развертывается с нечетным количеством узлов. Рекомендуется, чтобы при масштабе вашего кластера менее 50 единиц ZK обычно развертывал 7 узлов; при наличии от 50 до 100 узлов ZK имел 9 или 11 узлов, а при количестве более 100 узлов — более 11 узлов; Но чем больше развертываний, тем лучше, чем больше процессов ЗК, тем больше времени требуется на расчет и тем дольше идут выборы, так что это как раз уместно.
Кластер высокой доступности настроен с двумя узлами имен: «Активный» и «Резервный», чтобы он не попадал в одну точку отказа. Активный узел имени отвечает за обработку всех клиентских запросов, а резервный узел имени служит резервным узлом, сохраняя достаточно системных метаданных для обеспечения возможности быстрого восстановления в случае сбоя узла имени. Другими словами, в HDFS HA узел имени в состоянии ожидания обеспечивает «горячее резервное копирование». При выходе из строя активного узла имени его можно немедленно переключить на резервный узел имени, не затрагивая обычные внешние службы системы.
Поскольку узел имени, которому будет присвоено имя, является активным «горячим резервным копированием», информация о состоянии активного узла имени должна быть синхронизирована с узлом имени, которому будет присвоено имя, в реальном времени. Синхронизация состояния двух узлов имен может быть достигнута с помощью общей системы хранения, такой как NFS (сетевая файловая система), QJM (менеджер журнала кворума) или Zookeeper. Активный узел имени записывает обновленные данные в общую систему хранения. Резервный узел имени всегда будет контролировать систему. При обнаружении новых записей он немедленно считывает данные из общедоступной системы хранения и загружает их в свою собственную память, что гарантируется. быть полностью синхронизирован с активным состоянием namenode. Кроме того, узел имени хранит информацию о сопоставлении из базы данных (блока) с фактическим местом хранения, то есть, какой узел данных хранит каждый блок данных. Когда узел данных присоединяется к кластеру HDFS, он сообщает список содержащихся в нем блоков данных узлу имени. Эта операция уведомления будет периодически выполняться через «контрольный сигнал», чтобы гарантировать актуальность сопоставления блоков узла имени.
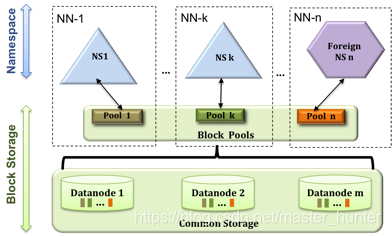
2.1.2Федерация HDFS (Федерация)
HDFS1.0 использует конструкцию узла с одним именем, но по-прежнему существуют такие проблемы, как масштабируемость, производительность и изоляция. Федерация HDFS вполне может решить три вышеупомянутых аспекта проблем.
- Федерация HDFS использует несколько независимых узлов имен, позволяющих службам именования HDFS расширяться по горизонтали. Эти узлы имен управляют своими собственными пространствами имен и блоками соответственно. Они находятся в отношениях федерации друг с другом и не требуют пакетной координации. и обратная совместимость
- В федерации HDFS все узлы имен будут совместно использовать ресурсы хранения базовых узлов данных, а узлы данных отчитываются перед всеми узлами имен.
- Блоки, принадлежащие одному и тому же пространству имен, образуют «пул блоков».
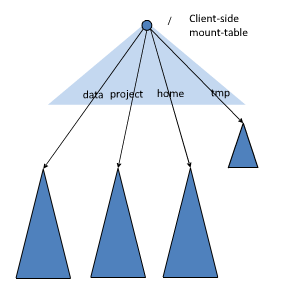
- Для нескольких пространств имен в федерации можно использовать метод таблицы монтирования на стороне клиента для совместного использования данных и доступа к ним.
- Клиенты могут получать доступ к различным точкам монтирования для доступа к различным подпространствам имен.
- Смонтируйте каждое пространство имен в глобальную «таблицу монтирования», чтобы обеспечить глобальное совместное использование данных.
- То же пространство имен монтируется в персональную таблицу монтажа и называется пространством имен программного обеспечения приложения.
Конструкция Федерации HDFS может решить следующие проблемы узлов с одним именем:
- Масштабируемость кластера HDFS. Каждый из нескольких узлов имени отвечает за часть каталога, поэтому кластер можно расширить до большего количества узлов. В отличие от HDFS1.0 количество файловых хранилищ ограничено из-за ограничений памяти.
- Производительность более эффективна. Несколько именных узлов управляют разными данными. И в то же время предоставляя услуги внешнему миру, он обеспечит пользователям более высокую пропускную способность чтения и записи.
- Хорошая изоляция. Пользователи могут по мере необходимости передавать разные бизнес-данные в разные узлы имен для управления, так что влияние между разными предприятиями минимально.
Следует отметить, что Федерация HDFS не может решить проблему единой точки отказа. Другими словами, у каждого узла имени есть проблема с единственной точкой отказа. Для каждого узла имени необходимо развернуть резервный узел, чтобы справиться с сбоем. влияние узла на бизнес.
2.2YARN
Идея дизайна YARN состоит в том, чтобы разделить три основные функции оригинального JobTacker.
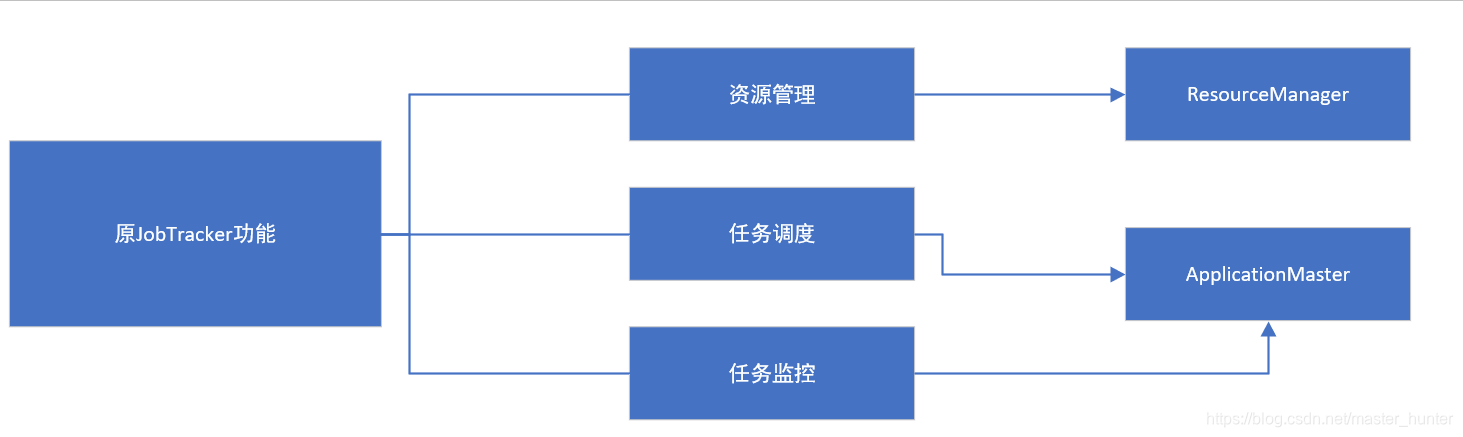
После Hadoop2.0 функции управления ресурсами и планирования в MapReduce1.0 были разделены и образовали YARN. Это чистая среда управления ресурсами и планирования, а не вычислительная среда. MapReduce, лишенный функций управления и планирования ресурсов, стал MapReduce2.0. Это чистая вычислительная среда, работающая на YARN. Она больше не отвечает за службы планирования и управления ресурсами, но YARN обеспечивает управление ресурсами и планирование. Служить.
Процесс планирования заданий YARN
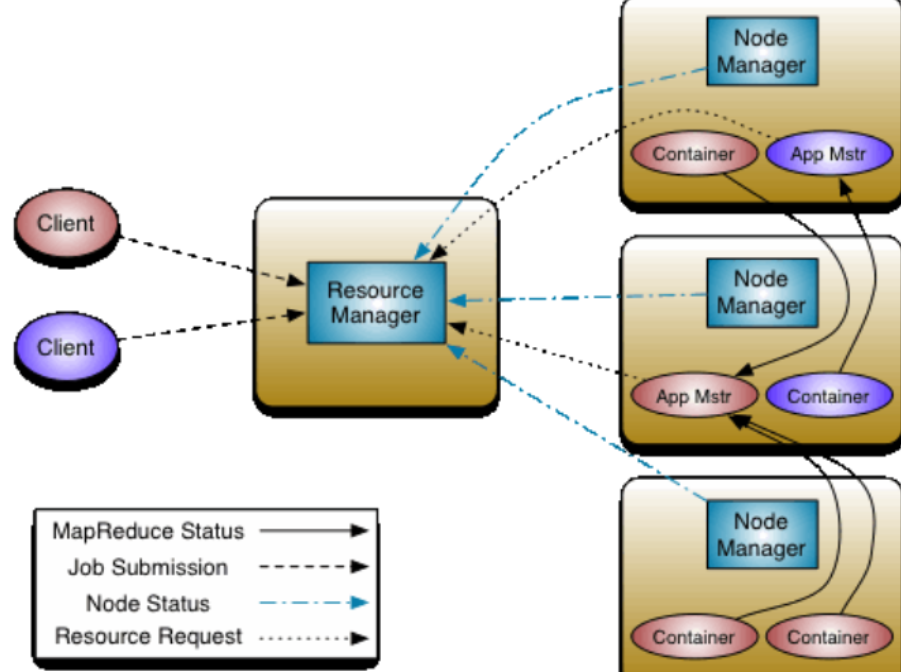
2.2.1ResourceManager
- Обрабатывать запросы клиентов
- Запуск/мониторинг ApplicationMaster
- Мониторинг NodeManager
- Распределение ресурсов и планирование
ResourceManager обладает полномочиями принятия решений по распределению всех ресурсов в системе, отвечает за распределение ресурсов всех приложений в кластере и имеет основное и глобальное представление ресурсов кластера. Таким образом, пользователям предоставляется справедливое, основанное на мощности, локализованное планирование ресурсов. Динамически выделяйте определенные узлы для запуска приложений в зависимости от потребностей программы, приоритетов планирования и доступных ресурсов. Он работает в координации с NodeManager на каждом узле и ApplicationMaster каждого приложения.
Основной обязанностью ResourceManager является планирование, то есть распределение доступных ресурсов в системе между конкурирующими приложениями, и он не фокусируется на управлении состоянием каждого приложения.
ResourceManager в основном состоит из двух компонентов: Планировщик и Менеджер приложений. Планировщик — это планировщик ресурсов, который в основном отвечает за координацию распределения ресурсов различных приложений в кластере и обеспечение эффективности работы всего кластера. Роль планировщика — это чистый планировщик. Он отвечает только за планирование контейнеров и не заботится о мониторинге приложений, их статусе работы и другой информации. Аналогично, он не может перезапустить задачи, выполнение которых не удалось из-за сбоя приложения или ошибок оборудования.
Планировщик спроектирован как подключаемый компонент. YARN не только предоставляет множество доступных планировщиков, но также позволяет пользователям создавать планировщики в соответствии со своими потребностями.
Контейнер (Container) — это единица динамического распределения ресурсов. Каждый контейнер инкапсулирует определенный объем процессора, памяти, диска и других ресурсов, тем самым ограничивая объем ресурсов, которые может использовать каждое приложение.
2.2.2ApplicationMaster
- Запросите ресурсы для приложений и назначьте их внутренним задачам.
- Планирование задач, мониторинг и отказоустойчивость
ApplicationManager в основном отвечает за получение запросов на отправку заданий, выделение первого контейнера приложению для запуска ApplicationMaster, а также отвечает за мониторинг ApplicationMaster и перезапуск контейнера, запускающего ApplicationMaster, при возникновении сбоя.
2.2.3NodeManager
- Управление ресурсами на одном узле
- Обработка команд из ResourceManager
- Обработка команд из ApplicationMaster
NodeManager — это агент «рабочего процесса» узла Yarn. Он управляет независимыми вычислительными узлами в кластере Hadoop. Он в основном отвечает за связь с ResourceManager, отвечающим за запуск и управление жизненным циклом контейнеров приложения, а также за мониторинг их ресурсов. использование (процессора и памяти), отслеживание состояния мониторинга узлов, управление журналами и т. д. и доложить РМ.
При запуске NodeManager NodeManager регистрируется в ResourceManager, а затем отправляет контрольный пакет для ожидания инструкций от ResourceManager. Основная цель — управлять контейнером приложения, назначенным ему менеджером ресурсов. NodeManager отвечает только за управление собственным Контейнером. Он не знает информацию о запущенных на нем приложениях. Во время выполнения благодаря совместной работе NodeManager и ResourceManager эта информация будет постоянно обновляться, чтобы обеспечить максимальную работу всего кластера.
Подвести итог
Hadoop1.0 в основном имеет следующие недостатки:
- Низкий уровень абстракции, требующий ручного кодирования.
- ограниченная выразительная способность
- Разработчики сами управляют зависимостями между заданиями
- Трудно увидеть общую логику программы.
- Выполнение итеративных операций неэффективно
- Пустая трата ресурсов
- Плохая производительность в реальном времени
Оптимизация и развитие Hadoop в основном отражаются в двух аспектах:
- С одной стороны, это улучшение архитектуры двух основных компонентов Hadoop: MapReduce и HDFS.
- С другой стороны, другие компоненты экосистемы Hadoop постоянно пополняются за счет добавления новых компонентов, таких как Pig, Tez, Spark и Kafka.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
