Подробная информация о сети Kubernetes: практические стратегии устранения неполадок и диагностики сети K8s
введение
Технический опыт
С тех пор, как Google открыл исходный код в 2014 году, Kubernetes быстро вырос. Благодаря мощным возможностям оркестрации контейнеров, гибкой масштабируемости и богатой экосистеме Kubernetes прочно занял первое место в стеке облачных технологий. Это не только платформа управления контейнерами, но и двигатель собственной облачной архитектуры, способствующий непрерывному развитию развертывания, управления и автоматизации приложений, предоставляющий разработчикам беспрецедентную гибкость и мобильность.
Однако,Благодаря огромной гибкости и масштабируемости, обеспечиваемым Kubernetes,Сложность внутренней сетевой архитектуры также становится все более заметной.,Стать инженером по эксплуатации и разработчиком — серьезная задача. Сеть Kubernetes предназначена для обеспечения бесперебойной связи между контейнерами.,В то же время это обеспечивает удобство обнаружения сервисов и реализуемость сетевых политик. Достижение этой цели зависит от ряда сложных компонентов и абстрактных концепций.,включать Сеть подов, Service, Ingress, Network Policy (NetworkPolicy) и Container Network Interface (CNI) и т.д. Каждый шаг настройки и настройки может повлиять на эффективность связи и безопасность всего кластера. Понимание и освоение рабочего механизма сетевой модели Kubernetes имеет решающее значение для эффективного устранения неполадок и решения сетевых проблем.
Система А подразделения развертывается в локальной приватизированной среде с использованием Docker и Kubernetes (сокращенно K8s) для создания очень гибкой и масштабируемой инфраструктуры.。Частное развертывание означает всеиз Все ресурсы и службы работают во внутренней сети.,Не зависит от публичных облачных сервисов,Это дает предприятиям больший контроль и защиту конфиденциальности данных.,Но это также приводит к различным различиям по сравнению с публичными облачными платформами.,В частности, сеть Kubernetes (K8s) может столкнуться с рядом уникальных проблем в частной среде развертывания.,Эти проблемы часто возникают из-за сложности сетевой архитектуры. конфигурация корпоративной интрасети、И совместимость между сетевыми компонентами K8s и частными облачными платформами.
На этом фоне и родилась данная статья.,Создан как практическое руководство из руководства по устранению неполадок Вины.,Ведущие читатели в каждом уголке сети Kubernetes,Раскройте его сложность,Это позволяет быстро обнаружить суть проблемы при возникновении проблем с сетью.,принять эффективные меры,Обеспечьте стабильную работу и эффективную доставку облачных приложений.
Фон неудачи
Эта статья в основном предназначена для документирования + анализа,Потому что собственное рабочее подразделение автора особенное,Поэтому конкретные скриншоты пока предоставить невозможно.,Здесь его также невозможно отобразить напрямую.,Пожалуйста, прости меня! Систему перемещения также называют системой, системой B и т. д.,И так далее.
Конкретная предыстория такова:
Часть первая:Вышестоящее подразделение открыло новую внутреннюю выделенную линию и хочет получить к нам доступ.k8sРазвертывание архитектурыизСистема,Но очень неловко.,Сегмент офисной сети этого устройства такой же, как сегмент сети Pod нашего внутреннего кластера k8s.,И поскольку эта Система чрезвычайно важна для бизнес-системы,Бегать круглосуточно,Поэтому я не смею корректировать это изнутри.,Окончательное решение — использовать пограничный брандмауэр для преобразования NAT, а затем ввести внутренний анализ k8s.。
часть вторая:Когда проблема с сетью решена,Вышестоящее подразделение выдвинуло новые требования,Нам нужно иметь возможность прямого доступа к их доменному имени системы B.,В то время я подумал о том, чтобы добавить разрешение доменных имен непосредственно в нашу мастер-ноду Системаизk8s.,После сохранения результатов и обновления кеша все внешние сервисы в Системе становятся недоступными.,В ходе устранения неполадок выяснилось, что сервис работает нормально.,Внутренний порт сервера пропущен,Однако доступ к другим сегментам сети внутри интрасети недоступен.,Даже если вы удалите предыдущую конфигурацию разрешения доменных имен, вы все равно не сможете получить к ней доступ.,После двух часов устранения неполадок безрезультатно,,Окончательное решение — перезагрузить сервер и вернуться к нормальной работе.。
часть третья:Помимо этих двух фонов,Есть еще одно, более распространенное явлениеизто естьПроблема дрожания контейнерной сети,В прошлом году Система столкнулась с многочисленными задержками в ответе при внешнем доступе к контейнерным сервисам.,иногда быстрый ответ,иногда очень медленно,Иногда может даже случиться так, что приложение сообщит, что сервис временно недоступен.,Эти события часто длятся не более 10 минут и происходят случайным образом.,Трудно воспроизвести,Инструмент экспорта KubeSkoop с открытым исходным кодом в настоящее время используется для отслеживания и обнаружения возникновения этого явления.。
Обзор основ работы в сети Kubernetes
Прежде чем обсуждать устранение неполадок и оптимизацию сети Kubernetes (K8s),,Сначала необходимо заложить прочную теоретическую основу.,Поймите сложную и изысканную сетевую модель, стоящую за этим. Сетевая модель Kubernetes — это один из основных принципов развертывания собственных облачных приложений.,Он разработан с использованием высокой степени абстракции.,Обеспечивает бесперебойную связь между контейнерами,при обеспечении обслуживанияиз Обнаруживаемость и сетевая стратегияизгибкость。Эта модель в основном состоит из трех основных элементов.:Сеть Pod, сервисная сеть и CNI (сетевой интерфейс контейнера),Вместе мы создаем основу сложной сетевой экосистемы Kubernetes.
Сеть подов:PodкакKubernetesсерединаиз Минимальная единица развертывания,Суть сетевой модели заключается в предоставлении каждому поду независимого IP-адреса.,И убедитесь, что прямая связь между модулями осуществляется так же легко, как если бы они находились в одной физической сети. Эта конструкция требует, чтобы базовая сетевая инфраструктура могла идентифицировать и маршрутизировать эти виртуальные IP-адреса модулей.
Сервисная сеть:С масштабом примененияизрасширять,статическийизPodВзаимосвязь затруднена для обеспечения динамического обнаружения служб и балансировки нагрузки.изнуждаться。Kubernetes Появился сервис, обеспечивающий единый вход и фиксированный IP для группы подов с одинаковыми функциями через Label Selector автоматически связывает соответствующую коллекцию Pod для достижения гибкой маршрутизации услуг и прозрачного горизонтального расширения. Кроме того, Kubernetes также поддерживает несколько типов сервисов, таких как ClusterIP, NodePort, LoadBalancer и externalName, для адаптации к различным требованиям к предоставляемым сервисам.
CNI (сетевой интерфейс контейнера):Чтобы реализовать описанную выше сетевую модель,Kubernetes использует подход с использованием плагинов,Разрешить пользователям выбирать подходящие сетевые решения в соответствии с их собственными потребностями.,этотто естьCNI(Container Network Интерфейс) роль. CNI предоставляет набор стандартных спецификаций интерфейса, которые позволяют использовать сторонние сетевые плагины (такие как Flannel, Calico, Weave). Net и т. д.), отвечающий за создание, удаление сети Pod, выделение IP-адресов и другие операции, обеспечивая гибкость и переносимость конфигурации сети.
Эти три основных элемента также составляют четыре типа требований к коммуникации, которые также являются целями проектирования сетевой модели Kubernetes.
- Связь между контейнерами внутри одного пода(Contarner to Contarner)
- Связь между модулями(Pod to Pod)
- Service приезжать Связь между модулями(Service to Pod)
- Связь между внешними кластерами и Сервисом(External to Service)
Связь между контейнерами внутри одного пода
Сетевая модель Kubernetes обеспечивает эффективную связь между контейнерами внутри пода. Поскольку все контейнеры в модуле используют одно и то же сетевое пространство имен.,Включает IP-адрес и пространство порта,И нет проблемы конфликта портов между разными модулями. Каждый модуль имеет свой собственный IP-адрес.,поэтому Контейнеры могут проходить напрямуюlocalhostилиинтерфейс обратной связи(loopback interface)общаться,Никакой дополнительной настройки не требуется. Такая конструкция значительно упрощает сценарии приложений, предусматривающие тесное сотрудничество между несколькими контейнерами в одном поде.,Например, контейнер обрабатывает запросы внешнего интерфейса.,Контейнер на другой стороне выполняет фоновые вычисления. Как показано ниже,Pod N Связь между Contarner1, Container2 и Container3 является контейнерной связью.
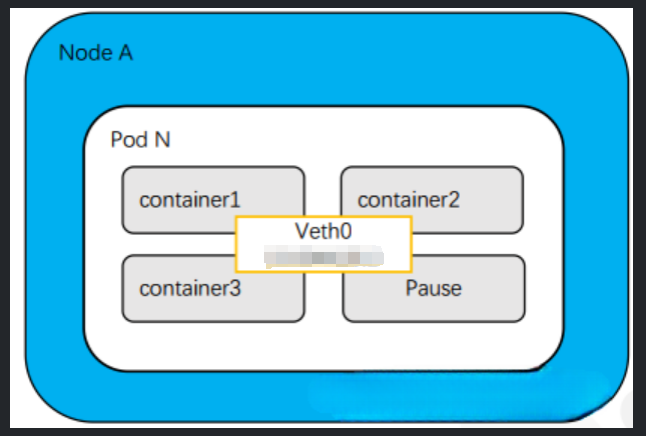
Связь между модулями
Kubernetes Назначьте каждому поду уникальный IP-адрес и потребуйте от сетевой инфраструктуры (обычно реализуемой через плагин CNI) маршрутизации этих подов. IP для обеспечения прямой связи между подами. Это означает, что независимо от того, на каком узле кластера развернуты поды, они могут взаимодействовать друг с другом, как если бы они находились в одной локальной сети. Эта функция имеет решающее значение для создания распределенных систем приложений, в которых взаимодействие между сервисами является частым и сложным.
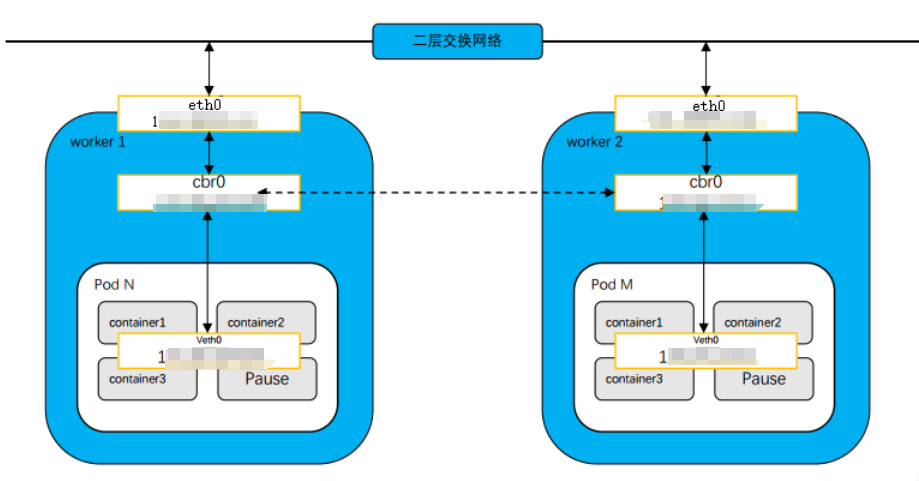
Каждый модуль содержит один или несколько контейнеров (container1,Container2 иContainer3), а также специальный контейнер с именем Pause. Функция контейнера Pause — предоставить общее сетевое пространство для других контейнеров.
На каждом рабочем узле имеется коммутационная сеть уровня 2 (cbr0), которая используется для соединения пода и хоста. Каждый модуль имеет независимый IP-адрес и расположен в отдельной подсети.
Связь между модулями может быть реализована через коммутационную сеть уровня 2.,Потому что у каждого Pod есть свой MAC-адрес. Когда под отправляет пакет другому поду,MAC-адрес назначения пакета будет установлен на MAC-адрес принимающего Podiz. в этом случае,Пакет данных будет передаваться через коммутационную сеть уровня 2.,Непосредственно к узлу, где находится целевой под.
Как только пакет добраться до узла назначения,Он войдет в целевой под через интерфейс cbr0. Затем,Пакет будет направлен в модуль назначения в соответствующем контейнере. Эта маршрутизация обычно осуществляется с помощью правил iptables.,Эти правила направляют трафик в правильный контейнер.
Service приезжать Связь между модулями
Вышеописанным способом,Хотя у каждого пода есть свой IP-адрес.,Но эти адреса не доступны по всему миру.。Чтобы сделать их доступными для внешних сетейPod,Сервис необходимо использовать для прокси и балансировки нагрузки. Служба предоставляет поду список общедоступных IP-адресов и конечных точек.,Внешние сети могут получить доступ к сервису через этот IP-адрес.
Чтобы реализовать обнаружение сервисов и балансировку нагрузки, Kubernetes Введено понятие Сервиса。Serviceпо тегуселектор(label selectors)обязательностьприезжать Группа с таким же ярлыкомизPods,Обеспечьте для этих подов единый вход и стабильный IP-адрес. Когда клиент инициирует запрос через СервисизIP и порт,Kube-proxy (компонент сетевого прокси-сервера Kubernetes) будет прозрачно пересылать запрос одному или нескольким модулям в серверной части в соответствии с политикой конфигурации (например, опросом, минимальным количеством подключений и т. д.). Этот механизм обеспечивает высокую доступность и масштабируемость сервисов.,В то же время это также упрощает управление конфигурацией клиента.
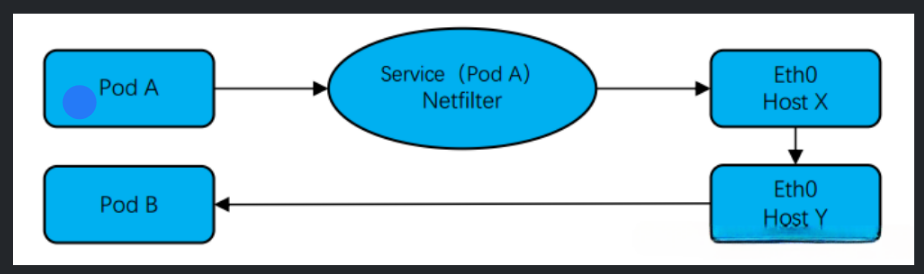
Среди них Сервис — это логическая концепция, представляющая группу модулей с одной и той же меткой. В Kubernetes Service передает селектор меток (label selector)чтобы определить, какойPodПринадлежитService。когдаServiceполучатьприезжатьодинпо запросу,Он перенаправит запросприезжатьзадняя частьизодинилинесколькоPod。
В этом процессе Netfilter играет ключевую роль. Netfilter — это механизм фильтрации и распределения сетевых пакетов в ядре Linux, который позволяет изменять и маршрутизировать пакеты при их прохождении через сетевой стек. В Kubernetes Netfilter используется для реализации функции балансировки нагрузки Service.
Конкретно,Когда запрос достигает Сервиса,Netfilter запросит целевой IP-адрес и порт. Если целевой IP-адрес — СервисизIP-адрес,Netfilter перенаправит запрос на модуль в серверной части. Этот процесс называется SNAT (трансляция исходного адреса). Netfilter случайным образом выберет внутренний модуль и заменит запрос IP-адреса источника на IP-адрес службы.,Таким образом, внутренний модуль сможет узнать, что запрос исходит от Сервиса, а не напрямую от клиента.
Запрос будет отправлен через хост X или хост Eth0 на выбранный под. Это связано с тем, что в Kubernetes.,Каждый под имеет собственное сетевое пространство.,И каждый узел также имеет свое сетевое пространство. Чтобы позволить модулям взаимодействовать с другими модулями и внешними сетями,Каждому узлу требуется мост,Для того, чтобы соединить сетевое пространство Подиз с узлом прибытия из сетевого пространства. В Кубернетесе,Этот мост называется cbr0.
поэтому,Когда запрос на проживание достигает узла,Он будет подключен к выбранному изPod через cbr0. Затем,Запросы будут перенаправляться в соответствующий контейнер в модуле. Эта маршрутизация обычно осуществляется с помощью правил iptables.,Эти правила направляют трафик в правильный контейнер.
Связь между внешними кластерами и Сервисом
Чтобы предоставить внешним клиентам доступ к сервисам внутри кластера, Kubernetes Предусмотрено несколько методов: NodePort, LoadBalancer и Ingress. NodePort предоставляет услуги по определенному порту на каждом узле, обеспечивая прямой внешний доступ через порт IP + узла; LoadBalancer (в среде общедоступного облака) автоматически создает облачного провайдера и балансировщик нагрузки для направления внешнего трафика в Сервис, и Ingress проходит один шаг; кроме того, обеспечивает уровень HTTP/HTTPS правил маршрутизации, позволяя на основе пути или доменного имени будут маршрутизироваться внешние запросы, приезжающие из различных сервисов. Эти механизмы гарантируют, что облачные приложения смогут не только В кластере все работает гладко и может безопасно и эффективно взаимодействовать с внешним миром.
① NodePort:Таким образом,Kubernetes откроет статический порт (NodePort) на каждом узле кластера.,через этот порт,Внешние клиенты могут напрямую получить доступ к сопоставлению служб прибытия из Pods. Конкретно,Пользователи могут получить доступ к Сервису через любой узел кластера по IP-адресу плюс NodePort.,Формат такой
<NodeIP>:<NodePort>Этот метод прост и понятен.,Подходит для тестовой среды или существуют ограничения на доступ к источникам из сценариев.,но, пожалуйста, обратите внимание,Поскольку все узлы предоставляют один и тот же порт,Может принести определенные риски безопасности,И сетевой трафик необходимо вручную распределять по каждому узлу.,Автоматическая балансировка нагрузки невозможна.
② LoadBalancer:когдануждатьсядляServiceобеспечить более высокий уровеньизвозможность внешнего доступа,Особенно, когда требуется автоматическая балансировка нагрузки и высокая доступность.,LoadBalancer становится предпочтительным решением. В этом режиме,Kubernetes будет интегрироваться с поставщиками облачных услуг,автоматически созданоодинснаружиотделениебалансировщик нагрузки(нравитьсяAWSизELB、GCPизLoad Балансир и др.). Этот внешний балансировщик нагрузки отвечает за прием внешнего трафика и его распределение в соответствии с заданными политиками (такими как опрос, минимальное количество подключений и т. д.). кластераизнесколькоузел,Затем получите доступ к соответствующему сервису через NodePort. Этот метод не только обеспечивает лучший внешний доступ,Это также обеспечивает высокую доступность и масштабируемость услуг.,Он особенно подходит для крупномасштабного развертывания приложений в производственных средах. Следует отметить, что из,При использовании типа службы LoadBalancer взимается плата за облачные услуги.,А настройка и управление относительно сложны,Ему необходимо тесно сотрудничать со службой балансировки нагрузки поставщика облачных услуг.
③ Ingress:IngressдляKubernetesКластеризация обеспечивает более гибкий и мощныйиз Механизмы управления трафиком и маршрутизации。отличается отNodePortнапрямую Служитьобязательностьприезжатьузелизстатическийпорт,Он также отличается от LoadBalancer распределением входов внешнего доступа через облачного провайдера и балансировщик нагрузки.,Ingress работает на более высоком уровне — уровне HTTP/HTTPS.,поддерживатьна на основе имени хоста и URL-пути из правил маршрутизации, чтобы иметь возможность разумно направлять входящий трафик туда, куда приезжать Внутри кластера Несколько служб по разным путям.
Ресурс Ingress определяет ряд правил.,Эти правила описывают, как перенаправлять внешние запросы во внутреннюю Службу. на самом деле,Ingressнуждаться与одинIngress Используется в сочетании с контроллером, который является компонентом, который фактически выполняет логику маршрутизации и балансировки нагрузки. Вход Контроллер отслеживает изменения во входящих ресурсах и соответствующим образом настраивает свою серверную службу балансировки нагрузки или обратный прокси-сервер для достижения правильной маршрутизации запросов.
Например,Вы можете установить правило,Приводит к перенаправлению трафика, посещающего www.example.com/blogiz, для обработки содержимого блога изService.,Трафик www.example.com/shopиз направлен на платформу электронной коммерции изService.,Все это делается под одной и той же точкой входа (обычно с одним общедоступным IP-адресом).,Значительно повышает гибкость и удобство сопровождения архитектуры приложений.
Подвести итог Давайте поговорим:
- NodePort предоставляет базовые возможности внешнего доступа, подходящие для простого тестирования или требований ограниченного доступа.
- LoadBalancer обеспечивает более высокий уровень внешнего доступа и автоматическое распределение трафика через службу балансировки нагрузки облачного провайдера, подходящую для производственных сред.
- Ingress еще больше повышает интеллектуальность и гибкость управления трафиком, поддерживает сложную маршрутизацию на основе URL-путей и имен хостов и является незаменимой частью построения современной микросервисной архитектуры.
В приведенной выше части в основном рассматриваются несколько основных аспектов сетевой модели Kubernetes и принципов связи. Ниже приводится краткий анализ этой ошибки.
Неудачи и анализ
Часть 1. Адрес вне кластера Kubernetes конфликтует с сетевым сегментом Pod или Service внутри кластера.
При возникновении конфликта сегментов сети наиболее вероятно возникновение следующих трех проблем:
- конфликт: если внешний IP адрес или сегмент сети по сравнению с внутренним Pod или Service из IP Перекрытие диапазона,Маршрутизация сетевых пакетов может запутать。этот是因для Kubernetes Внутри Кластер Внешний из сети отличить невозможно.
- Проблема с маршрутизацией: Сетевая маршрутизация может отдать приоритет одной из сетей. Например, если IP считается частью внутренней сети, от Pod Приехать Внешний сервис запросов никогда не может покинуть кластер.
- Доступ к сервису: если внешний IP Адрес считается Внутри кластера Часть из Доступ к сервисам извне кластера может стать проблематичным.
Проблема на этот раз — Kubernetes Кластер не может различать внутренние и внешние сети.,Создание путаницы при передаче данных,Запрос на обслуживание не может быть правильно направлен к месту назначения.,Внешние устройства не могут эффективно получить доступ к Системе.
Лучше всего справиться с этой проблемойиз Решение естественноХорошо поработайте над распределением сетевых адресов во время предварительного планирования.,Обеспечить строгую изоляцию отдела Внутрикластера от внешних сетей с использованием диапазонов IP-адресов.,Избегайте любого дублирования. Это включает в себя предварительное определение независимых и неконфликтных пулов IP-адресов для модулей Pod, служб и, возможно, интерфейсов внешнего доступа, таких как NodePort и LoadBalancer.,таким образом ву источникаУстраните риск конфликта,Обеспечьте бесперебойную и безопасную сетевую связь. Но это все,Нет возможности изменить это,Поэтому нам нужно найти другой путь.
Вторая мысльприезжатьизметодто есть МожетПозвольте вышестоящему подразделению изменить сегмент своей офисной сети, или мы изменим сетевой сегмент модуля или службы в кластере k8s.,Но это предложение было быстро отвергнуто. Потому что они наши начальники,Почему вы хотите это изменить? А поскольку Система чрезвычайно критична,Даже если мы напрямую изменим сегмент сети Kubernetes Внутри кластера Подили Сервисиз, это обязательно приведет к прерыванию существующей службы.,Влияет на непрерывность бизнеса.
Третья мысльприезжатьизметодто естьпреобразование NAT,Это также может быть наименее дорогой вариант. Установите правила трансляции сетевых адресов (NAT) на брандмауэре в соответствующем месте. Когда вышестоящее подразделение просит приехать,Сопоставление прибытия посредством преобразования NAT в неконфликтный диапазон адресов.,а затем переслать егоприезжатьK8sВнутри кластераиз Под. Таким образом, даже если исходный адрес изначально такой же, как у PodConflict сегментов сети, но будет преобразован в безопасный и приемлемый адрес во время фактического процесса передачи.
Четвертый тип – этоотделение ОтделениеодинОбратный прокси-сервер или шлюз API,Но это значит, что будут новыеРабота на уровне развертывания,И из-за нехватки времени,Так что этот план в конечном итоге был отложен.
финальный,Мы до сих пор используемпреобразование NATЭту проблему решил。

Конкретный процесс реализации также относительно прост, с той лишь разницей, что из-за ограниченных функций нашего брандмауэра мы попросили другую сторону настроить NAT на выходном брандмауэре. Конкретные моменты, которые необходимо уточнить, — это преобразование исходного IP-адреса. диапазон, целевой диапазон IP-адресов и политика сопоставления портов, тип NAT и т. д.
Вдохновение, которое принесла мне эта ошибка, заключается в том, что в Kubernetes кластерС самого начала этапа проектирования нам действительно необходимо учитывать уникальность и резервирование адресного пространства сети.Понятно,Вы не можете слепо копировать онлайн-уроки.,При этом игнорируются характеристики собственной среды и возможные внешние факторы.
Часть 2. Сбой внешней службы после добавления разрешения доменного имени на главный узел.
Эта Вина очень смертельна.,Инициатором инцидента в то время был член моей команды.,Первоначальное намерение состоит в том, чтобы решить проблему внутреннего разрешения внешних доменных имен k8s.,Но поскольку он мало знаком с этой архитектурой,Итак, я напрямую изменил файл ishost на сервере главного узла.,После внесения изменений я обнаружил, что они не вступили в силу.,Я только что перезапустил сетевую карту.,После перезапуска вся Система полностью рухнула.,Вначале даже соответствующий порт внутри сервера не мог быть доступен через telnet.,После некоторых операций доступ к серверу наконец стал возможен.,Но порт внешнего доступа по-прежнему заблокирован.,После двух часов устранения неполадок прямого решения проблемы проживания найдено не было.,финальныйпроходитьПерезагрузите серверрешать。
Давайте кратко поговорим об этой ошибке здесь, Kubernetes. кластерКонфигурация по умолчаниюОбычно только разбор Внутри кластераотделениеиз Название службы(проходитьCoreDNSилиkube-dnsСлужить),Возможность прямого разрешения внешних доменных имен слаба.,Но мы все равно можем добиться разрешения имен внешних доменов с помощью некоторых конфигураций.,Ниже представлен пример использования k8s coredns для разрешения имен внешних доменов кластера.,Подробную информацию можно найти в официальной документации.(https://kubernetes.io/docs/concepts/services-networking/dns-pod-service/?spm=a2c6h.12873639.0.0.4e9e5cb0ph0Om9 )。
Изменить файл конфигурации coredns
Запустите следующую команду и добавьте перезапись stop этототделениеблок подконфигурации(https://coredns.io/plugins/rewrite/) ,Может将解析请求серединасоответствоватьприезжатьизxxx.a.b.c.comиз Преобразование доменного именидляxxx.default.svc.cluster.localанализировать,и вернутьсяизрезультатсерединаиз Доменное имя все еще отображаетсядляxxx.a.b.c.com:
kubectl edit cm/coredns -n kube-systemИзмените его следующим образом:
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
rewrite stop {
name regex (.*)\.a\.b\.c\.com {1}.default.svc.cluster.local
answer name (.*)\.default\.svc\.cluster\.local {1}.a.b.c.com
}
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . /etc/resolv.conf {
max_concurrent 1000
}
cache 30
loop
reload
loadbalance
}
kind: ConfigMap
metadata:
creationTimestamp: "2024-06-02T12:12:21Z"
name: coredns
namespace: kube-system
resourceVersion: "251"
uid: be64b336-a0bf-4217-829b-78fbb062463cПосле изменения этого,Подождите несколько минут, и конфигурация автоматически вступит в силу.,В это время можно проанализировать правильный результат «приехать».
Или вы можете добавить записи хоста прямо в него, следующим образом:
apiVersion: v1
data:
Corefile: |
.:53 {
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
upstream
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
hosts {
XXX.XXX.XXX.XXX Доменное имя, которое необходимо разрешить
fallthrough
}
prometheus :9153
forward . /etc/resolv.conf {
max_concurrent 1000
}
cache 30
loop
reload
loadbalance
}
kind: ConfigMap
metadata:
creationTimestamp: "2024-06-02T12:12:21Z"
name: coredns
namespace: kube-system
resourceVersion: "251"
uid: be64b336-a0bf-4217-829b-78fbb062463cОба вышеуказанных метода могут реализовать разрешение кластера внешних доменных имен, но если вы не меняете собственный файл конфигурации, вы также можете настроить resolv.conf кластера серверов k8s. добавитьdnsСлужитьустройство,Обновить еще разk8sкластерkube-dnsперестроить, чтобы достичьприезжатьанализиз。
Выполните следующую команду, чтобы проверить файл resolv.confg в кластере и убедиться, что все конфигурации DNS в кластере согласованы. Если они несогласованы, их необходимо изменить вручную, чтобы они были согласованными.
cat /etc/resolv.confЕще раз проверьте контейнер coredns в кластере Kubernetes.
kubectl get pods -n kube-system<p style="text-align:center">
</p>
Просто удалите эти два и дождитесь автоматической реконструкции.
kubectl -n kube-system delete pod coredns-5d78c9869d-4ljkw
kubectl -n kube-system delete pod coredns-5d78c9869d-zmjmr <p style="text-align:center">
</p>
Вышеупомянутое в основном описывает несколько методов реализации кластерного разрешения внешних доменных имен. Это немного надуманно, но действительно весьма полезно.
Что касается этого сбоя, поскольку бизнес-отдел постоянно нас убеждал, у нас не было другого выбора, кроме как перезапустить сервер, чтобы решить проблему. К счастью, она была успешно решена.
Эта Вина приносит вдохновение,Обучение персонала действительно имеет решающее значение,Особенно в средах, которые полагаются на технологическую инфраструктуру. Эффективные тренировки могут не только улучшить техническую силу членов команды.,Это также может повысить их способность принимать спокойные суждения и быстро реагировать в случае возникновения чрезвычайных ситуаций; в то же время они могут быть бдительными;,Когда дело доходит до проживания, сложная сеть корректировок,Следует принять более строгий и научный подход.,По крайней мере заранееизпланирование、пробный тест、И подробный план отката.
Часть 3. Проблема дрожания контейнерной сети
Если быть честным,В настоящее время мы все еще не можемизлечиватьизметод,Потому что это действительно сложно расследовать.,Каждый раз, когда это происходит, он автоматически восстанавливается через 10 минут.,(Бывают даже случаи, когда персонал эксплуатации и технического обслуживания, а также сам бизнес-персонал не замечают аномалии),Если вы хотите вернуться снова, вам придется подождать до следующего раза.
Используемый здесь метод предназначен главным образом для предотвращения возникновения таких событий за счет возможности наблюдения и позиционирования.,использоватьприезжатьизинструментKubeSkoop exporter。
KubeSkoop exporter
Дефекты сложных ссылок, основанных на сетевой обработке и традиционных инструментах в сценариях облачных контейнеров. Проект KubeSkoop был основан на требованиях к сетевому наблюдению в облачной среде.
Прежде чем представить часть KubeSkoop для мониторинга сети, которая является экспортером KubeSkoop, давайте сначала рассмотрим общую ситуацию с проектом KubeSkoop.
KubeSkoop — это автоматическая система диагностики проблем контейнерной сети. Он предоставляет возможности диагностики одним щелчком мыши для сценариев, в которых сеть по-прежнему недоступна, например, из-за исключений разрешения DNS и недоступности служб. Он обеспечивает мониторинг в реальном времени проблем с нестабильностью сети, таких как увеличенная задержка, случайные сбросы и случайная потеря пакетов. способность. KubeSkoop обеспечивает диагностику всего канала одним щелчком мыши, анализ задержек сетевых станций, а также идентификацию аномальных событий в сети и возможности отслеживания.
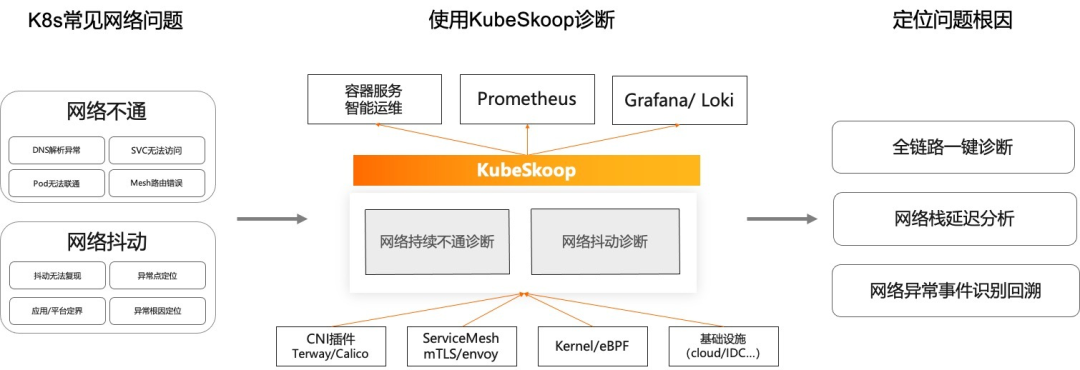
Экспортер KubeSkoop отслеживает аномалии сети контейнеров на основе нескольких источников данных, таких как eBPF, procfs, netlink и т. д. Он предоставляет возможности мониторинга сети на уровне модулей и может предоставлять индикаторы мониторинга сети, записи событий сетевых аномалий и потоки событий в реальном времени, включая драйверы, сетевые фильтры, TCP и т. д. Полный стек протоколов и десятки аномальных сценариев, связанных с наблюдаемыми системами, такими как Прометей и Локи, в облаке.
KubeSkoop exporter Предоставляются зонды для сбора информации в разных местах ядра, а также поддерживаются возможности горячей замены и загрузки зондов по требованию. Включенные датчики будут Prometheus индексили Это ненормальное событиеизформа показывает, что собраноприезжатьиз Статистикаили Сетевая аномалия。
Как использовать
KubeSkoop Exporter подходит для ежедневного мониторинга и устранения неполадок в случае возникновения нештатных сетевых проблем. Эти два сценария используют экспортер KubeSkoop по-разному, которые кратко представлены ниже.
ежедневный мониторинг

существоватьежедневный В мониторинге рекомендуется использовать Prometheus собирать KubeSkoop exporter Метрики раскрыты и опционально переданы Loki Приходите, чтобы собрать событие исключения из журнала. Доступ к индикаторам и журналам сбораприжатизиз можно получить через Grafana Рынок отображается. Кубе Ску exporter Готовый Grafana Большую тарелку можно использовать напрямую.
После настройки индикатора сбора и рынка вам еще нужно KubeSkoop exporter Сделайте некоторую настройку самостоятельно. В нашем ежедневном мониторинге, чтобы повлиять на бизнес-трафик, мы можем выборочно включить некоторые зонды с низкими накладными расходами, например, на основе porcfs Большинство исследований, частично основанных на netlink、eBPF малозатратный зонд. Если используется Локи, тоже надо заодно настроить Loki из Служитьадрес,и включите его. После завершения этих приготовлений,Мы можем посмотреть на индикаторы и события, которые позволяют приезжать на рынок.
При ежедневном мониторинге необходимо обращать внимание на аномалии некоторых чувствительных показателей. Например, происходит аномальное внезапное увеличение количества новых подключений или увеличение количества неудачных попыток установления соединения, увеличение количества сообщений о сбросе и т. д. Для этих индикаторов, которые, очевидно, могут отражать отклонения, мы также можем настроить сигналы тревоги для более быстрого вмешательства для устранения неполадок и восстановления в случае возникновения отклонений.
Устранение неполадок исключений

Когда мы проходим ежедневный Обнаружив, что могут иметь место сетевые аномалии с точки зрения деловых сигналов тревоги, журналов ошибок и т. д., вам необходимо сначала провести простую классификацию типов сетевых аномалий, таких как TCP Сбой при установлении соединения, дрожание задержки в сети и т. д. Благодаря простой классификации это может лучше помочь нам определить направление устранения неполадок.
В зависимости от типа проблемы мы можем включить зонд, применимый к проблеме, в зависимости от типа проблемы. Например, если существует проблема с джиттером задержки в сети, мы можем включить параметрocketlatency, чтобы обратить внимание на задержку приложения при чтении данных из сокета, или включить kernellatency, чтобы отслеживать задержку в ядре.
После включения этих зондов мы можем использовать настроенную Grafana для наблюдения за индикаторами или результатами событий, предоставляемыми зондами. В то же время аномальные события также можно наблюдать напрямую через журнал Pod или команду инспектора в контейнере экспортера. Если результаты зонда, который мы открыли на этот раз, не являются аномальными или если мы не можем сделать вывод о основной причине проблемы, мы можем рассмотреть возможность открытия других зондов, чтобы продолжить помогать нам в обнаружении проблемы.
На основании этих полученных показателей и аномальных событий,В конечном итоге мы найдем причину проблемы. Основная причина проблемы может быть связана с корректировкой некоторых параметров в системе.,или Он появляется в программе пользователя. В зависимости от основной причины мы можем скорректировать эти параметры системы или оптимизировать программный код.
Конкретная часть расследования включает в себя детали прибытия.,Больше подробностей здесь нет,Вот несколько практических советов.
Начинайте быстро
Диагностика в один клик
skoop -s xxx.xxx.xxx.xxx -d xxx.xxx.xxx.xxx -p номер порта --http # Выполнить диагностическую команду,Укажите исходный каталог,Передайте --http, чтобы предоставить результаты диагностики через локальную веб-службу.После завершения диагностики результаты диагностики будут выведены и их можно будет открыть визуальным способом.

Диагностика дрожания сети и проблем с производительностью сети
Экспортер Skoop и его комбинацию наблюдаемости с Prometheus, Grafana и Loki можно быстро развернуть в кластере Kubernetes, выполнив следующие действия:
kubectl apply -f https://raw.githubusercontent.com/alibaba/kubeskoop/main/deploy/skoopbundle.yamlВыполните следующие действия, чтобы подтвердить завершение установки и получить доступ:
# ПроверятьSkoop статус экспортера
kubectl get pod -n kubeskoop -l app=skoop-exporter -o wide
# Проверить датчик сбора данных Probe из рабочего состояния
kubectl get --raw /api/v1/namespaces/kubeskoop/pods/skoop-exporter-t4d9m:9102/proxy/status |jq .
# Получите сервис Prometheus из записи
kubectl get service -n kubeskoop prometheus-service -o wide
# Получите вход в консоль Grafana.
kubectl get service -n kubeskoop grafana -o wideЭто правда, что некоторые сетевые проблемы можно диагностировать с помощью таких инструментов, как KubeSkoop, который помогает выявить проблемы с дрожаниями на уровне контейнерной сети. Однако при столкновении со сложными и непредсказуемыми сетевыми средами частного облака с более высокими уровнями безопасности это часто не удается. так легко выявить и устранить проблемы с дрожанием. Устраните первопричину, поэтому некоторые проблемы все еще остаются.
Другие распространенные сбои сети в k8s
Общие идеи по устранению неполадок
Аномальная сетевая связь между различными службами в кластере Kubernetes проявляется в виде тайм-аута запроса, сбоя соединения или медленного ответа, что приводит к прерыванию зависимостей между службами, недоступности функций зависимых служб или снижению производительности и может даже повлиять на всю архитектуру микросервиса, вызывая цепочку. Реакция вызывает общую нестабильность системы.
Метод устранения неполадок:
Шаг 1. Проверьте конфигурацию и состояние сети Pod
Просмотрите конфигурацию сети Pod:
kubectl describe pod <pod-name> -n <namespace>Ключевыми моментами здесь являются концентрация наРаздел «События»Есть ли какая-либо конфигурация сети?из Сообщение об ошибке,и правильно ли назначен IP-адрес,Если исключений нет, модуль снова находится в рабочем состоянии.
kubectl get pods -n <namespace>Проверьте, находится ли модуль в состоянии «Выполняется», если нет, проверьте его статус (например, CrashLoopBackOff) и проанализируйте журнал дальше.
Шаг 2. Проверка сетевого подключения
Здесь мы в основном используем для тестирования широко используемую команду ping.
Чтобы проверить соединение между модулями, выполните следующие команды для проверки соединения на двух проблемных модулях, например, используйте ping или nc (netcat).
# Выполнить в исходном модуле
kubectl exec -it <source-pod-name> -n <namespace> -- ping <destination-pod-ip>
# или Используйте nc для проверки подключения порта.
kubectl exec -it <source-pod-name> -n <namespace> -- nc -zv <destination-pod-ip> <port>Шаг 3. Просмотр правил сетевой политики
Если с вышеизложенным проблем нет, возможно, это проблема сетевой политики. Выполните следующую команду, чтобы проверить, существует ли сетевая политика, ограничивающая доступ между модулями.
kubectl get networkpolicies -n <namespace>Если есть соответствующие стратегии,исследовать Чтовходная спецификация и выходная спецификацияправило,Убедитесь, что необходимые коммуникации не были случайно отключены.
Шаг 4. Проверьте конфигурацию службы.
kubectl describe service <service-name> -n <namespace>
kubectl get endpoints <service-name> -n <namespace>Выполните приведенную выше команду еще раз, чтобы подтвердить тип службы.、селектор、Правильно ли настроена конфигурация порта?,и убедитесьServiceИмеются соответствующие конечные точки,То есть внутренний список подов.
Шаг 5. Просмотр журналов кластера
В зависимости от узла, на котором расположен аномальный под, проверьте логи kubelet и сетевых плагинов на узле, чтобы найти информацию о конфигурации сети, попытках подключения или ошибках.
kubectl logs <problematic-pod-name> -n <namespace>1. Тайм-аут модуля при доступе к внешним сервисам
Феномен: Время ожидания модуля истекло при попытке доступа к внешней службе, такой как база данных или API.
Анализ причин:Обычно этоegressправило Не правильно установлено,В результате трафик не может выходить из кластера.
Метод устранения неполадок:
Шаг 1. Подтвердите сетевую политику
Сначала проверьте, существует ли сетевая политика, ограничивающая доступ модуля Pod к внешней сети, и убедитесь, что нет правил, блокирующих исходящий (исходящий) трафик.
kubectl get networkpolicies -n <namespace>Шаг 2. Просмотрите конфигурацию сети Pod
Подтвердите конфигурацию сети модуля, особенно правила iptables и таблицы маршрутизации. Войдите во внутреннюю проверку Pod:
kubectl exec -it <pod-name> -n <namespace> -- bashВыполните следующую команду в модуле, чтобы просмотреть таблицу маршрутизации:
ip routeИ проверьте правила iptables:
iptables -L -nvШаг 3. Проверьте внешние подключения
Попробуйте получить доступ к внешним службам непосредственно из модуля, например проверить связь с общедоступным DNS-сервером или проверить подключение порта:
ping 8.8.8.8
nc -vz example.com 443Шаг 4. Проверка разрешения DNS
Если доступ к службе зависит от имени домена, проверьте, нормально ли разрешение DNS:
nslookup www.baidu.comШаг 5. Проверка исходящей конфигурации
Если обнаружено, что политика сети ограничивает исходящий трафик, вы можете создать или изменить политику сети, чтобы разрешить внешний доступ. Например, сетевая политика, которая разрешает весь исходящий трафик:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-egress
spec:
podSelector: {}
policyTypes:
- Egress
egress:
- {}Затем примените эту стратегию:
kubectl apply -f allow-egress.yaml -n <namespace>В производственной среде обязательно настройте политику в соответствии с фактической ситуацией и открывайте только необходимые порты и цели, чтобы обеспечить безопасность системы.
2. Сервис ClusterIP недоступен.
Феномен: Адрес ClusterIP службы недоступен из кластера.
Анализ причин: неправильная конфигурация службы Kubernetes или служба kube-proxy ненормальна.
Метод устранения неполадок:
Шаг 1. Подтвердите статус услуги
Это клише. Первый шаг — подтвердить статус сервиса и проверить, создан ли сервис и находится ли он в нормальном состоянии:
kubectl get svc -n <namespace>Вам необходимо убедиться, что служба существует и ее тип — ClusterIP.
Шаг 2. Проверьте сведения об услуге
Просмотрите подробную информацию о сервисе, обращая внимание на то, правильно ли настроены ClusterIP, сопоставление портов и селектор:
kubectl describe svc <service-name> -n <namespace>подтверждатьEndpointsсписоксерединаСуществует хотя бы один IP-адрес пода.,Это указывает на то, что сервис может найти подходящий вариант изPod.
Шаг третий: проверьте разрешение DNS
В проблемном модуле попробуйте разрешить имя службы, чтобы убедиться, что DNS работает:
kubectl exec -it <problematic-pod-name> -n <namespace> -- nslookup <service-name>В это время обычно вы сможете увидеть IP-адрес кластера, соответствующий службе прибытия.
Шаг 4. Проверка сетевого подключения
Запустите проверку ping или TCP-соединения от проблемного модуля к ClusterIP и порту службы:
kubectl exec -it <problematic-pod-name> -n <namespace> -- bash -c "nc -zv <service-cluster-ip> <service-port>"Шаг 5: проверка статуса kube-прокси
kube-proxy отвечает за сетевой прокси-сервер сервиса и обеспечивает его правильную работу на всех узлах:
kubectl get pods -n kube-system | grep kube-proxyЕсли возникла проблема с kube-proxy, проверьте его журнал:
kubectl logs <kube-proxy-pod-name> -n kube-systemШаг 6. Перезапустите kube-прокси.
Если ничего из вышеперечисленного не является ненормальным, в крайнем случае вы можете перезапустить службу kube-proxy на всех узлах, что может решить возможные временные проблемы, но вы должны быть осторожны! :
sudo systemctl restart kube-proxy3 . Ingress 502 Bad Gateway
когдаиспользоватьIngressВстреча с ресурсомприезжать502 Bad Ошибка шлюза, означающая, что входной контроллер неправильно получает ответ от серверной службы.
Шаг 1. Проверьте конфигурацию входящего ресурса
Сначала убедитесь, что конфигурация входящего ресурса правильна, включая путь, имя службы, порт и т. д.:
kubectl describe ingress <ingress-name> -n <namespace>Шаг 2. Проверьте конфигурацию входящего ресурса.
Проверьте, правильно ли работают связанные службы и модули:
kubectl get svc -n <namespace>
kubectl get pods -n <namespace>Убедитесь, что модуль не имеет статуса CrashLoopBackOff или Error, а служба имеет правильное сопоставление портов и селектор.
Шаг 3. Проверьте конечные точки
Убедитесь, что служба привязана к правильному поду:
kubectl describe svc <service-name> -n <namespace>существоватьвыходсередина НаходитьEndpointsотделениеточка,Убедитесь, что у вас есть Под список ИП.
Шаг 4. Просмотр журнала Ingress-контроллера
В зависимости от используемого Ingress-контроллера (например, Nginx Ingress Controller, Istio Ingress Gateway и т. д.) получите его журналы для получения дополнительной информации:
# Для Нгинкс Ingress Controller
kubectl logs -l app.kubernetes.io/name=ingress-nginx -n ingress-nginxПроанализируйте журналы на наличие сообщений об ошибках или предупреждений, связанных с ошибками 502.
Шаг 5. Подтвердите доступность серверной службы
Попробуйте получить доступ к серверной службе непосредственно с узла или модуля, где расположен Ingress, чтобы устранить проблемы с сетью:
kubectl run -it --rm --restart=Never debug --image=busybox -- /bin/sh -n <namespace>
# Выполнить в новом модуле
nc -vz <backend-service-ip> <service-port>Шаг 6. Перезапустите контроллер Ingress.
Если описанные выше действия не помогли устранить проблему, попробуйте перезапустить модуль Ingress Controller:
kubectl delete pod <ingress-controller-pod-name> -n <ingress-controller-namespace>Приложение: Часто используемые команды устранения неполадок k8s.
Сбой контейнерной сети
Убедитесь, что контейнер запущен и работает правильно и правильно настроен для использования правильной сети.
Выполните команду, чтобы убедиться, что модуль запущен и работает правильно.
kubectl get podsВыполните команду, чтобы подтвердить правильность конфигурации сети контейнера.
kubectl describe pod <pod-name>Проверьте, правильно ли настроены сетевые конфигурации модулей и контейнеров, такие как IP-адрес, маска подсети, шлюз, DNS и т. д.
Выполните команду, чтобы просмотреть информацию о конфигурации сети контейнера.
kubectl describe pod <pod-name>Выполните команду, чтобы просмотреть информацию о сетевом интерфейсе контейнера.
kubectl exec <pod-name> -- ifconfigПроверьте, правильно ли работает сетевой плагин, и попробуйте перезапустить сетевой плагин.
Если вы используете сетевой плагин Flannel, выполните команду, чтобы просмотреть информацию журнала Flannel.
kubectl logs -n kube-system -l k8s-app=flannelЕсли вы используете сетевой плагин Calico, выполните команду, чтобы просмотреть информацию журнала Calico.
kubectl logs -n kube-system -l k8s-app=calico-nodeПерезапустите сетевой плагин: если вы используете сетевой плагин Flannel, выполните команду
kubectl delete pod -n kube-system -l k8s-app=flannelЕсли вы используете сетевой плагин Calico, выполните команду.
kubectl delete pod -n kube-system -l k8s-app=calico-nodeПроверьте, правильно ли работает сетевое оборудование, например, неисправны ли коммутаторы, маршрутизаторы, межсетевые экраны и т. д.
Проверьте журналы или информацию о конфигурации сетевого устройства, чтобы убедиться, что сетевое устройство работает правильно.
Попробуйте провести диагностику с помощью инструментов Kubernetes, таких как kubectl, чтобы просмотреть состояние и журналы модулей и контейнеров.
Выполните команду, чтобы просмотреть информацию журнала контейнера.
kubectl logs <pod-name>Выполните команду, чтобы просмотреть информацию о состоянии контейнера.
kubectl describe pod <pod-name>Если описанный выше метод не может решить проблему, вы можете рассмотреть возможность повторного развертывания сети контейнера или замены сетевого модуля.
Если вы используете сетевой плагин Flannel, выполните команду, чтобы повторно развернуть сетевой плагин Flannel.
kubectl delete -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml && kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml,Если вы используете сетевой плагин Calico, выполните команду, чтобы повторно развернуть сетевой плагин Calico.
kubectl delete -f https://docs.projectcalico.org/manifests/calico.yaml && kubectl apply -f https://docs.projectcalico.org/manifests/calico.yamlСбой сетевой политики
Посмотреть все сетевые политики:
kubectl get networkpolicies --all-namespacesПросмотр сведений о сетевой политике:
kubectl describe networkpolicy <network-policy-name> -n <namespace>Проверьте правильность правил сетевой политики:
kubectl get networkpolicy <network-policy-name> -n <namespace> -o yamlУбедитесь, что контейнер правильно помечен:
kubectl get pods --selector=<label-selector> -n <namespace> -o wideПроверьте, правильно ли настроен порт контейнера:
kubectl get pods <pod-name> -n <namespace> -o yamlПроверьте правильность настройки узла:
kubectl get nodes -o wideПроверьте, правильно ли работает сетевое устройство:
kubectl logs <network-device-pod-name> -n <namespace>Если ваш кластер Kubernetes использует сетевую политику Calico, вы можете использовать следующую команду:
Посмотреть все сетевые политики Calico:
kubectl get networkpolicies.projectcalico.org --all-namespacesПросмотрите подробную информацию о сетевой политике Calico:
kubectl describe networkpolicy <network-policy-name> -n <namespace>Проверьте правильность правил сетевой политики Calico:
kubectl get networkpolicy <network-policy-name> -n <namespace> -o yamlПроверьте, правильно ли работает сетевое устройство Calico:
kubectl logs -n kube-system -l k8s-app=calico-nodeОшибка DNS
Проверьте, подключено ли сетевое устройство:
ping <network-device-ip>Проверьте информацию журнала сетевого устройства:
kubectl logs <network-device-pod-name> -n <namespace>Проверьте информацию о конфигурации сетевого устройства:
kubectl exec -it <network-device-pod-name> -n <namespace> -- <command> <arguments>Проверьте информацию о версии сетевого устройства:
kubectl exec -it <network-device-pod-name> -n <namespace> -- <command> <arguments>Проверьте состояние подключения сетевых устройств:
kubectl exec -it <network-device-pod-name> -n <namespace> -- <command> <arguments>Подвести итог
В этой статье всесторонне рассматривается построение и устранение неполадок сетевой системы Kubernetes, начиная с Технический. опыт Отъезд,идти углубленно проанализировали четыре основных элемента сетевой модели Kubernetes из: Сеть подов、Service、CNI (сетевой интерфейс контейнера) и средства связи между ними. В статье раскрывается сложность сети на трех практических примерах: Внутренний и внешний конфликт. сегментов сетиизNATрешатьплан、Разрешение доменного имени главного узла приводит к прерыванию обслуживания и восстановлению、А джиттер контейнерной сети обнаруживается с помощью инструмента мониторинга KubeSkoopiz. В этих случаях особое внимание уделяется сетевому планированию и дальновидности.、Стратегии преодоления трудностей、Важность мониторинга и ценность непрерывного обучения.
При рассмотрении процесса устранения неполадок сети Kubernetes (K8s),Вы также сможете глубоко понять несколько ключевых моментов прибытия.,Это не только технические аспекты практики.,Это также совершенствование стратегий и методов мышления:
- Предварительное планирование является основой, а профилактика является приоритетом.:проблемы с сетьюизфундаментальныйрешатьспособсуществоватьдля профилактики,Обязательно обеспечьте уникальность и резервирование адресного пространства сети при первоначальном планировании.,избегать внутри и снаружи Конфликт сегментов сети. Разумное проектирование сетевой архитектуры и планирование адресов являются первой линией обороны во избежание коррупции в будущем.
- Глубокое понимание сетевых моделей:идти глубжевладелецK8sсетевая модельизкаждая ссылка,Включая Pod, Service, принцип работы CNIиз и Ingress и т.д.,Это основа для устранения неполадок. Поймите, как эти основные элементы работают вместе,Это ключ к решению проблемы.
- Меняйте с осторожностью:любые изменения конфигурации,Например, модификация DNS,Нужно быть осторожным и осторожным,Чтобы не влиять на общую ситуацию. Управление изменениями требует стратегий планирования и отката.
Благодаря быстрому развитию технологий управление сетями Kubernetes переходит в новую эру интеллекта в будущем. Мы надеемся использовать возможности машинного обучения, чтобы получить представление о тенденциях поведения сети, прогнозировать потенциальные конфликты и узкие места в производительности, автоматически настраивать конфигурации. и стремиться к достижению значительных результатов. Сократите ручное вмешательство и повысьте эффективность автономности.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
