Победит ли Apache Paimon? Эра интеграции озер и складов в реальном времени полностью запущена!
краткое содержание:Эта статья составлена из Университета открытого исходного кода Alibaba Cloud.данные Лидер платформы Ван Фэн(Не спрашивай)учительсуществовать5луна16день Streaming Lakehouse Meetup · Online В основном рассказывается о том, как проводить анализ больших данных в режиме реального времени на архитектуре Hucang нового поколения. Содержание в основном разделено на следующие пять частей:
1. Data Lake + Data Warehouse = Data Lakehouse
2. Apache Paimon–Unified Lake Format
3. The Past, Present and Future of Apache Paimon
4. Streaming Lakehouse is Coming
5. Apache Paimon уточнен как единый формат озера данных Alibaba.
Учитель Мо Вэнь объяснил идеи развития LakeHouse с общей точки зрения, чему стоит поучиться. С другой стороны, архитектура Hucang имеет множество проблем, требующих решения, и текущие ограничения в ее фактической реализации; будучи новым и быстро развивающимся направлением, она действительно представляет собой серьезный вызов традиционной архитектуре данных, как с точки зрения мышления, так и с точки зрения фактической реализации; . В будущем я лично буду совмещать его со своим.существовать Сообщество открытого исходного кода&Наша фирмасуществоватьизкомандасуществовать Фактическая реализацияиз Подробнее о приложениииз Практический опыт。Добро пожаловать, чтобы продолжитьсосредоточиться на。
01
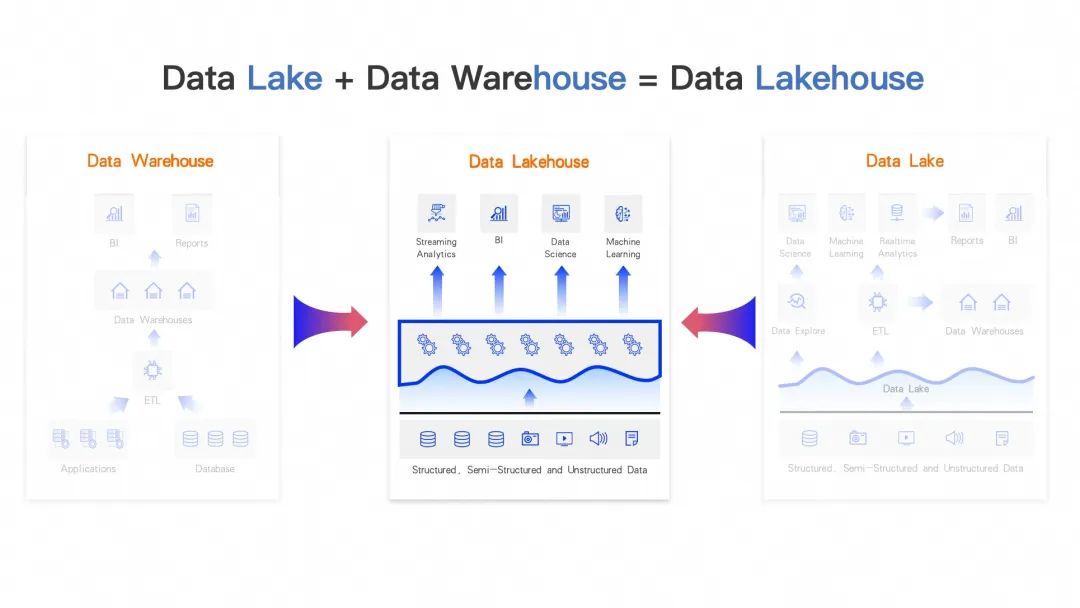
Data Lake + Data Warehouse = Data Lakehouse
Архитектура Lakehouse все чаще используется в промышленности. Lakehouse представляет собой объединение двух архитектур данных: хранилища данных и озера данных. Он сочетает в себе преимущества обеих, образуя свои собственные уникальные преимущества. Благодаря Lakehouse мы можем унифицированно хранить не только структурированные, но и неструктурированные или полуструктурированные данные. В то же время, благодаря преимуществам открытой архитектуры данных Lakehouse, хранилище данных Lakehouse может быть лучше интегрировано и интегрировано с основными в отрасли парадигмами вычислений больших данных (такими как потоковые вычисления, пакетные вычисления, OLAP-анализ), а также совместимо. с общими вычислительными моделями машинного обучения и искусственного интеллекта.
Таким образом, на основе Lakehouse могут быть достигнуты возможности комплексного анализа больших данных и искусственного интеллекта. В то же время Lakehouse также обеспечивает пользователям максимальную производительность и удобство использования. Все больше и больше разработчиков и корпоративных пользователей начинают пытаться проводить анализ данных. на основе архитектуры Лейкхауса. С постепенным внедрением новой архитектуры анализа данных Lakehouse и ее популярностью во всех сферах жизни разработчики и пользователи выдвигают все больше и больше требований к Lakehouse. Одним из очень важных требований является то, как проводить анализ больших данных в режиме реального времени на архитектуре Lakehouse. Если анализ данных в режиме реального времени выполняется в архитектуре данных, должны быть соблюдены как минимум два условия/базовых элемента. Во-первых, существует потребность в вычислительном механизме, способном выполнять анализ данных в реальном времени. Во-вторых, необходимо иметь набор структур/форматов данных, которые могут поддерживать обновление в реальном времени и поток данных в реальном времени.
Очевидно, что в архитектуре Lakehouse соблюдаются условия в области вычислений в реальном времени. Потому что самые популярные в нашей отрасли потоковые вычисления Flink, а также распространенные механизмы анализа OLAP в реальном времени, такие как Presto, могут обрабатывать и анализировать данные в реальном времени. Однако технологиям хранения в области озера данных Lakehouse относительно не хватает возможностей обновления в реальном времени. В настоящее время в отрасли распространены три основных формата озера данных: Iceberg, Hudi и Delta Lake. Все они представляют собой форматы озера данных, предназначенные для пакетной обработки. Их структуры данных, естественно, недостаточны для возможности обновления в реальном времени и имеют некоторые узкие места.
02
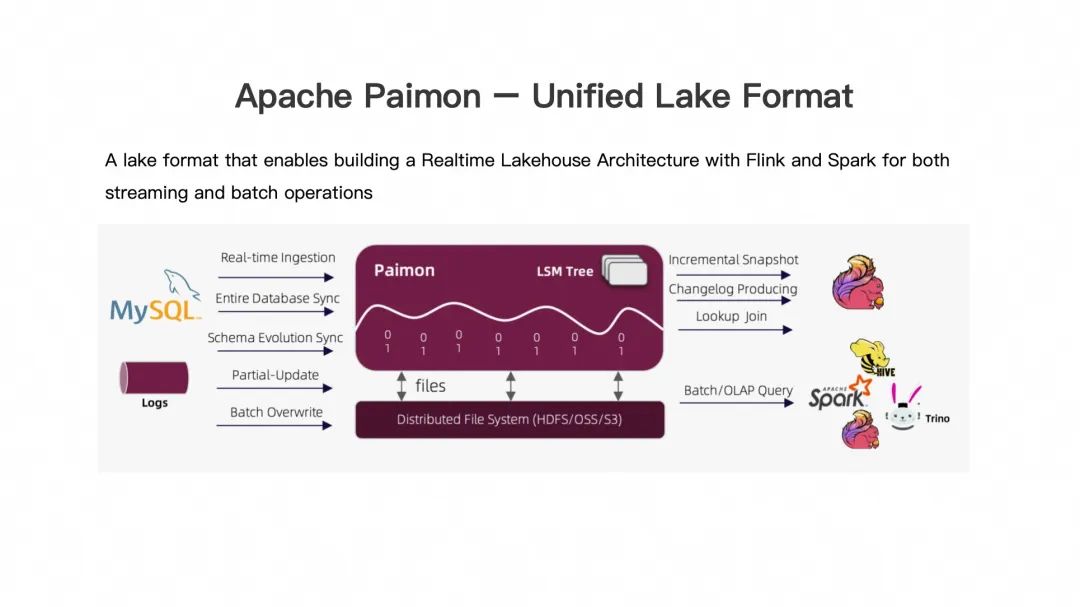
Apache Paimon–Unified Lake Format
Чтобы восполнить это узкое место, была запущена технология Apache Paimon. Характеристики Paimon сильно отличаются от трех других хранилищ данных. Оно ориентировано на сценарии потокового обновления и обработки данных и создано для сценариев озера данных в реальном времени. . Пеймон также привел многие классические технологии хранения данных (технологии хранения баз данных в реальном времени), такие как LSM и т. д. Он не только поддерживает возможности пакетной обработки, такие как пакетное обновление, пакетное чтение, пакетное объединение и т. д. Кроме того, он поддерживает обновления в реальном времени потоковых данных с меньшей задержкой и подписки на данные в реальном времени, включая поддержку семантики CDC. Таким образом, Paimon представляет собой действительно полноценный интегрированный и унифицированный формат озера данных, интегрированный в потоковую и пакетную обработку, и может прекрасно поддерживать сценарии анализа данных в реальном времени. Кроме того, поскольку Paimon также изучил преимущества конструкции хранилища трех других озер, оно обладает полной открытостью, что позволяет ему беспрепятственно работать с распространенными механизмами анализа, такими как Apache Flink, Apache Spark, Trino, Presto и StarRocks в промышленность Стыковка и интеграция.
03
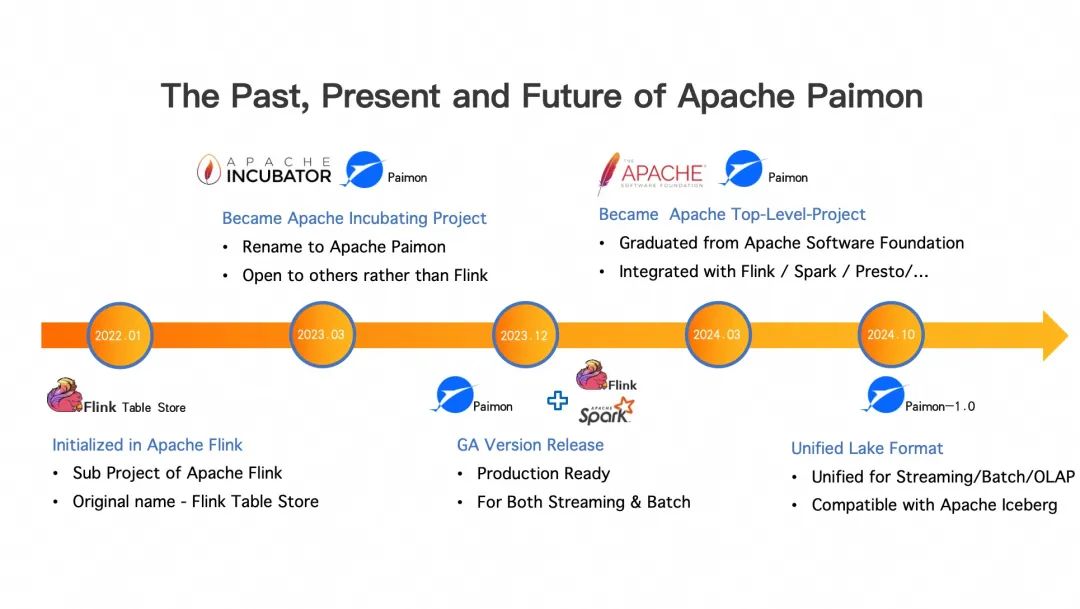
The Past, Present and Future of Apache Paimon
Далее давайте взглянем на прошлую и настоящую жизнь Apache Paimon, а также на будущее направление его развития, чтобы каждый мог лучше понять: Почему вы хотите сделать Paimon? Почему Paimon подходит для сценариев озера данных в реальном времени.
В первый день в сообществе Apache Flink родился Apache Paimon. Фактически, в 2022 году мы изучали ускорение потока данных в озере данных на основе Flink. Мы попытались соединить Flink с Iceberg и Hudi, надеясь ускорить своевременность данных Iceberg и Hudi на основе технологии потоковой передачи Flink. Все технологии, используемые в этих озерах данных, разработаны на основе пакетной обработки, поэтому при обновлении данных возникают некоторые естественные узкие места, что делает невозможным достижение устойчивого потока данных в озере данных в реальном времени. Поэтому мы запустили в сообществе Flink подпроект — Flink Table Store, который представляет собой формат хранения озера данных, предназначенный для потоковой передачи, тем самым реализуя поток данных в озере данных в реальном времени.
После года попыток, в 2023 году, мы обнаружили, что эта идея вполне осуществима и дала хорошие результаты. Мы надеемся, что этот проект даст больший эффект и будет развиваться более независимо, поэтому мы отделили этот подпроект от сообщества Apache Flink и поместили его в инкубатор Apache для независимой инкубации. Это предыстория рождения Apache Paimon.
После еще одного года эволюции, доводки и наших усилий мы также очень благодарны за вклад разработчиков из многих других компаний в этот процесс, а также за некоторые бизнес-практики. В марте этого года Paimon официально окончила Apache Foundation. Он стал новым проектом высшего уровня и завершил интеграцию с основными движками, такими как Spark, Flink, Presto, StarRocks и т. д., и может предоставить полный набор решений для анализа озерных складов в режиме реального времени.
Далее мы планируем выпустить версию Paimon 1.0 в октябре этого года (второе полугодие), чтобы сформировать полный и унифицированный формат озера данных, который единообразно поддерживает анализ потоков, пакетных данных и OLAP-данных и может быть интегрирован с такими данными, как как Iceberg, который в настоящее время является наиболее распространенным в Северной Америке.
04
Streaming Lakehouse is Coming
Paimon создан для озер потоковой передачи данных в реальном времени. Он неразрывно связан с Apache Flink. Таким образом, Flink+Paimon может производить большие химические изменения, поскольку Flink является стандартом для поточных вычислений, а обработка данных в реальном времени на основе Flink получила всеобщее согласие. Позиционирование Paimon заключается в реализации хранилища данных в реальном времени в озере данных. На основе Flink+Paimon в Lakehouse можно реализовать полный сквозной канал обновления данных в реальном времени. Технология Flink CDC используется для синхронизации внешних данных с озером данных в реальном времени, записываемых в Paimon, а затем в Flink. StreamSQL используется для обновления данных в реальном времени в Lakehouse (обработка данных в реальном времени), весь канал передачи данных может обеспечить высокую своевременность. Повысьте своевременность традиционного Lakehouse с часов до минут или даже секунд. Поэтому мы также можем назвать эту архитектуру версией Lakehouse реального времени или обновленной и расширенной версией — Streaming Lakehouse.

05
Apache Paimon был уточнен как единый формат озера данных Alibaba.
Наконец поделитесь Paimon Ситуация развития в Alibaba. Пеймон Это проект с открытым исходным кодом, созданный командой Alibaba Cloud по работе с большими данными. Он получил широкое признание в Alibaba на уровне группы и пользуется сильной поддержкой со стороны различных братских команд. Пеймон Проект единого формата озера данных четко позиционирует стратегию Alibaba в отношении озера данных. Включая несколько основных продуктов для вычислений больших данных от Alibaba, таких как вычисления в реальном времени. Flink, EMR Включено Spark、StarRocks такие как основная пакетная обработка и OLAP Двигатели, а также собственной разработки MaxCompute и Хологрес и другие продукты полностью охватываются Paimon Унифицировать формат озера данных Paimon Построить единство изозёро данные Решение,Формирование набора данных и данных элемента,Но диверсификацияизвычислительный анализрешение。мы также будемсуществоватьAlibaba использует этот набор унифицированныхизРешения для аналитики озера данныхПоддержите всех в группеданныебизнес。В то же время они также будут экспортироваться через Alibaba Cloud.озеро Решение для обработки данных поддерживает большое количество малых и средних предприятий в анализе в режиме реального времени. данные. Я считаю, что благодаря Alibaba и Alibaba Cloud большое количество пользователей получили Paimon ввод, полировку и отпуск, так что Paimon По мере все лучшего и лучшего развития он постепенно стал основным стандартом для озер данных в отрасли. Мы также вернем дивиденды и результаты открытого исходного кода сообществу открытого исходного кода, чтобы принести пользу большему количеству разработчиков и предприятий. Мы также надеемся, что к нам присоединятся разработчики из других компаний. Apache Paimon Сообщество открытого исходного кода вместе создает проекты с открытым исходным кодом, чтобы сделать решения для озер данных все более мощными.

Выше представлен контент, которым поделились на этот раз, всем спасибо.

[Спецификация] Результаты и исключения возврата интерфейса SpringBoot обрабатываются единообразно, поэтому инкапсуляция является элегантной.

Интерпретация каталога веб-проекта Flask

Что такое подробное объяснение файла WSDL_wsdl

Как запустить большую модель ИИ локально
Подведение итогов десяти самых популярных веб-фреймворков для Go
5 рекомендуемых проектов CMS с открытым исходным кодом на базе .Net Core

Java использует httpclient для отправки запросов HttpPost (отправка формы, загрузка файлов и передача данных Json)

Руководство по развертыванию Nginx в Linux (Centos)

Интервью с Alibaba по Java: можно ли использовать @Transactional и @Async вместе?

Облачный шлюз Spring реализует примеры балансировки нагрузки и проверки входа в систему.

Используйте Nginx для решения междоменных проблем

Произошла ошибка, когда сервер веб-сайта установил соединение с базой данных. WordPress предложил решение проблемы с установкой соединения с базой данных... [Легко понять]

Новый адрес java-библиотеки_16 топовых Java-проектов с открытым исходным кодом, достойных вашего внимания! Обязательно к просмотру новичкам

Лучшие практики Kubernetes для устранения несоответствий часовых поясов внутри контейнеров
Введение в проект удаления водяных знаков из коротких видео на GitHub Douyin_TikTok_Download_API

Весенние аннотации: подробное объяснение @Service!
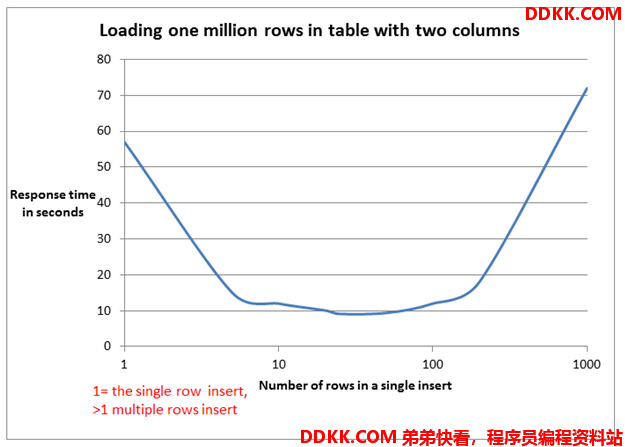
Пожалуйста, не используйте foreach для пакетной вставки в MyBatis. Для 5000 фрагментов данных потребовалось 14 минут. .

Как создать проект Node.js с помощью npm?
Mybatis-plus использует typeHandler для преобразования объединенных строк String в списки списков.

Не удалось установить программное обеспечение Mitsubishi. Возможно, возникла проблема с реестром.

Разрешение ошибок проекта SpringBoot 3 mybatis-plus: org.apache.ibatis.binding.BindingException: неверный оператор привязки
Более краткая проверка параметров. Для проверки параметров используйте SpringBoot Validation.

Поиграйтесь с интеграцией Spring Boot (платформа запланированных задач Quartz)

Несколько популярных режимов интерфейса API: RESTful, GraphQL, gRPC, WebSocket, Webhook.

Redis: практика публикации (pub) и подписки (sub)

Подробное объяснение пакета Golang Context
Краткое руководство: создайте свое первое приложение .NET Aspire

Краткое обсуждение метода пакетной вставки MyBatis: обработка 100 000 фрагментов данных занимает всего 2 секунды.

[Инструмент] Используйте nvm для управления переключением версий nodejs, это так здорово!
