План проектирования крупномасштабной кластерной учебной платформы (Wanka) MegaScale: масштабирование большой языковой модели. Учебное видеоруководство.
1. Зачем нужен обучающий кластер Wanka:
Я не буду на этом акцентировать внимание, потому что большая языковая модель — это здорово.,машинный перевод,Диалог человека и компьютера демонстрирует большой потенциал и прикладную ценность.。Размер модели и размер обучающих данных определяют возможности модели.,Для реализации современных моделей,Люди работали над триллионами токенов для обучения больших моделей с триллионами параметров. Это требует создания крупномасштабного кластера искусственного интеллекта с десятками тысяч графических процессоров для обучения LLM (большая языковая модель).
2. Проблемы обучающего кластера Ванка:
1、Достичь больших масштабовВысокая эффективность обучения;(Можно ли эффективно использовать вычислительную мощность Ванки?)
2、Достичь больших масштабовтренировка высокой стабильности;(Слишком много карт, и каждая из них может работать неправильно.,Легко вызвать различные поломки)
3. Принципы построения обучающего кластера Ванка:
1. Совместное проектирование алгоритмов и систем.
2. Уменьшите объем/время связи, дублирование связи и вычислений.
3. Оптимизировать процесс расчета без снижения точности
4. Глубокая наблюдаемость
Факторы, которые следует учитывать при разработке учебного кластера Ванка:
1. Алгоритм
2. Распределенное параллельное решение
3. Загрузка данных
4. Сеть и общение
5. Оператор нижнего уровня
6、Отказоустойчивость кластераи мониторинг производительности
Видеоурок
1.6 Масштабная оптимизация загрузки обучающих данных, устранение избыточных загрузчиков, параллельная загрузка данных, кластер Wanka MegaScale_bilibili_bilibili 1.7 Масштабное обучение кластеров, оптимизация инициализации связи, топология сети_bilibili_bilibili
1.9 Почему объединение базовых операторов может ускорить расчет_bilibili_bilibili
Видеоуроки все еще обновляются
4.1 Оптимизация алгоритма LLM
Оптимизация алгоритма выполняется без ущерба для точности модели для достижения высокой эффективности обучения в масштабе.
4.1.1 Механизм параллельного внимания (параллельное внимание)

Добавьте комментарий к изображению, не более 140 слов (по желанию)
Как показано в формуле (1) выше, результат, рассчитанный с помощью Attention, вводится как LN, и LN вычисляется. После расчета LN он вводится как MLP, а затем рассчитывается MLP. Это последовательный процесс расчета.
В улучшенной формуле (2) после расчета LN MLP и Внимание могут рассчитываться параллельно. Следовательно, параллельное внимание может сократить время вычислений.
4.1.2 Внимание к скользящему окну (SWA)
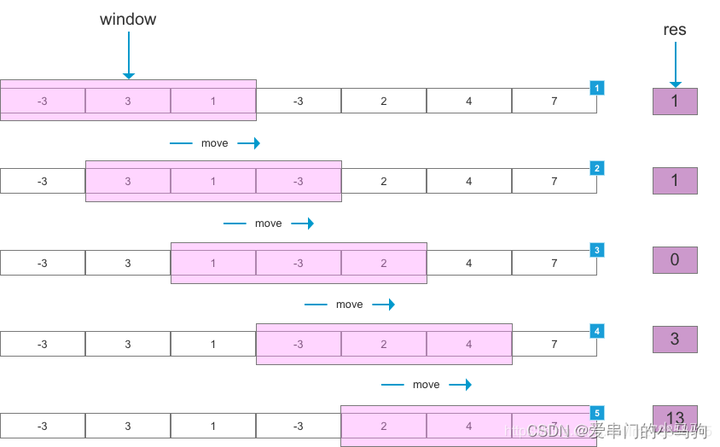
Добавьте комментарий к изображению, не более 140 слов (по желанию)
Поскольку предложение представляет собой временной ряд, когда мы прогнозируем следующее слово на основе существующей последовательности, чем раньше слово, тем слабее корреляция со словом, которое я хочу предсказать. Мы можем установить окно и игнорировать слова перед окном, чтобы уменьшить объем вычислений. Каждый раз, когда предсказано слово, окно перемещается на один кадр назад, чтобы предсказать следующий, поэтому оно называется скользящим окном.
Например, если мы предсказываем следующее слово «Маленький, который любит ходить в гости», мы можем напрямую использовать всю последовательность «Маленький, который любит ходить в гости», чтобы предсказать слово «лошадь». Мы не можем предсказать «лошадь», используя слово «любовь». Расстояние слишком велико, а корреляция слишком слаба. Мы можем установить длину окна 4 и предсказать слово «лошадь», используя «маленький, который приходит в дверь», игнорируя «любовь» и уменьшая объем вычислений. Но мы предсказали слово «лошадь». При предсказании следующего слова мы игнорируем слова «любовь» и «чуань» и напрямую используем «дверную пони», чтобы предсказать следующее слово. Проведите пальцем назад на один пробел? и игнорировать слово «строка». Вот почему его называют раздвижным окном.
4.1.3 Оптимизатор LAMB
Масштабное обучение ограничено размером партии. В частности, увеличение размера пакета может повлиять на сходимость модели. LAMB может масштабировать размер пакета до 4 раз без потери точности. Почему увеличение количества обучающих данных в пакете сокращает время обучения Ха-ха-ха, Сяо Пони, который любит к нам приходить, заботливо нарисовал для всех картинку (почему так продуманно, без лайков не могу объяснить), как показано на рисунке ниже. Для обучения одних и тех же данных требуется время:
Добавьте комментарий к изображению, не более 140 слов (по желанию)
4.2 Решение для распределенного обучения
4.2.1 Перекрытие параллельной передачи данных

Добавьте комментарий к изображению, не более 140 слов (по желанию)
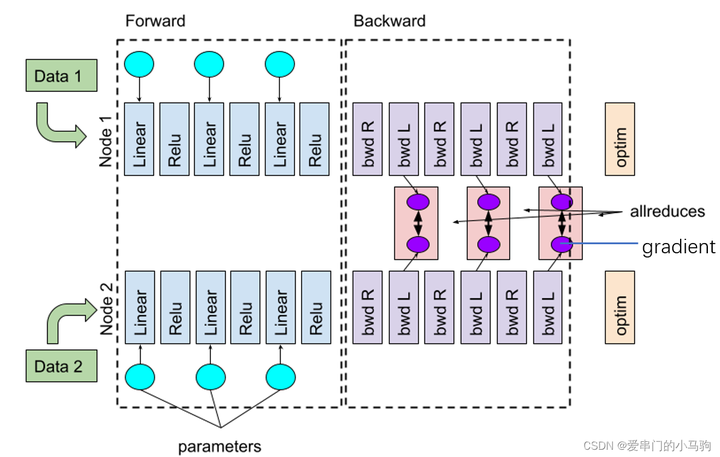
Добавьте комментарий к изображению, не более 140 слов (по желанию)
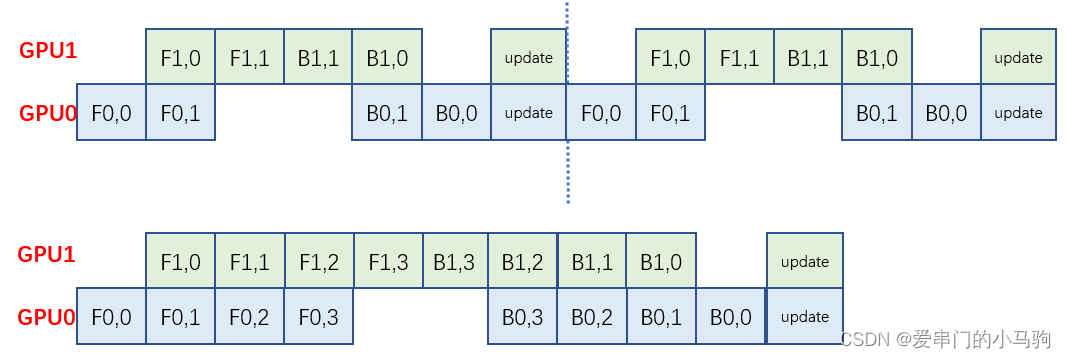
Фактически, DDP и FSDP Pytorch уже выполнили перекрытие обучения и связи, как показано на рисунке выше. Например, во время процесса обратного расчета связь «Уменьшение-разброс» передается после завершения части расчета. во время последующего обратного процесса вычислений одновременно для связи происходит перекрытие вычислительной связи.
Но с этим есть проблема, то есть после того, как я завершу обратный расчет, произойдет связь «Уменьшение-разброс». Прежде чем начнется прямой расчет, для выполнения расчета потребуется хотя бы одна операция «Всесобрать». нет перекрытия связи.
Таким образом, в ходе этих двух коммуникационных процессов,Предварительная загрузка данных,Приди и уступи дорогуСвязь пересекается с загрузкой данных。
4.2.2 Перекрытие параллельных коммуникаций конвейера
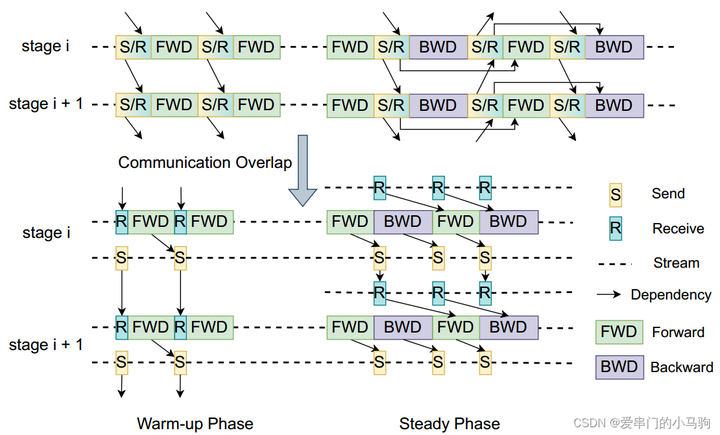
Добавьте комментарий к изображению, не более 140 слов (по желанию)
При параллелизме прямого конвейера, когда один графический процессор завершает расчет и одновременно отправляет данные следующему графическому процессору, выполняется следующий расчет. То есть отправка данных пересекается с прямыми вычислениями.
Ха-ха-ха,Можно ли использовать ту же технику в обратном порядке?,Следующий обратный расчет выполняется при отправке данных. Я видел несколько сообщений в блоге, в которых говорилось,Вот прием и обратный путь,Лично я так не думаю.,Расчеты можно производить только после получения данных.,Все еще здесьsendиbackwardперекрытие。(Ха-ха-ха, студенты должны быть уверены в себе, иметь смелость бросать вызов экспертам и просто вовремя исправлять их, если они допускают ошибки. Ха-ха-ха, если мой маленький пони, который любит заглядывать, ошибается, худшее, что он может сделать, — это опубликовать видео, чтобы извиниться и признать, что у него это плохо получается.)
Поскольку прямые и обратные вычисления относительно независимы, можно ли перекрывать прямой прием приема и обратный обратный расчет, а также обратный расчет приема и процесс прямого вычисления перекрываться. Разве здесь не перекрываются получение и вычисления?
4.2.3 Перекрытие тензорной параллельной связи
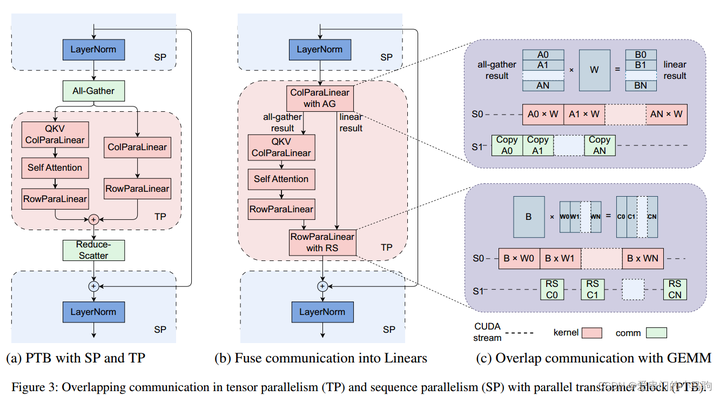
Добавьте комментарий к изображению, не более 140 слов (по желанию)
Суть здесь заключается в сегментировании данных, когда тензоры параллельны: (1) Для части связи allgather allgather вычисляет первый срез данных, чтобы последующие вычисления были параллельны связи (2) Для части связи «Уменьшение-разброс» «Уменьшите»; -Scatter-связь осуществляется после расчета первой части, чтобы последующие расчеты и связь были параллельны.
4.3 Предварительная обработка данных и оптимизация загрузки
4.3.1 Асинхронная предварительная обработка данных
Асинхронная предварительная обработка данных, предварительная обработка/загрузка данных начинается, когда обучение завершает градиент синхронизации связи.
4.3.2 Устранение избыточных загрузчиков данных
Каждый графический процессор имеет собственный загрузчик данных, который сначала считывает данные в память процессора. Одна и та же параллельная группа тензоров имеет один и тот же вход, поэтому для загрузки данных в память ЦП необходим только один загрузчик данных, а затем каждый графический процессор загружает данные в свою собственную видеопамять.
4.4 Оптимизация инициализации связи
По мере увеличения размера кластера инициализация коллективной группы связи становится трудоемкой и неудобной, что влияет на настройку параметров и отладку.
(1) Когда на этапе синхронизации используется блокировка, она основана на внутренней реализации TCPStore в Pytorch, которая работает в однопоточном режиме с блокировкой чтения и записи. Замените TCPStore на Redis, который является неблокирующим и асинхронным.
(2) Уменьшите ненужную синхронизацию при блокировке глобального барьера.
4.5 Кластер
4.5.1 Топология кластера
Коммутаторы уровня 3 соединены по топологии, аналогичной CLOS. Два уровня являются позвоночно-листовыми, как показано на рисунке, а третий уровень показан на рисунке ниже.

Добавьте комментарий к изображению, не более 140 слов (по желанию)
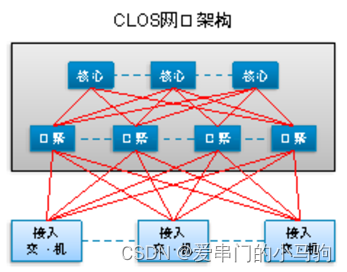
Добавьте комментарий к изображению, не более 140 слов (по желанию)
4.5.2 Уменьшение коллизий хэшей ECMP
ECMP (многопутевая маршрутизация с равной стоимостью) — многопутевая балансировка нагрузки с равной стоимостью. Например, есть два пути, по которым можно добраться. ECMP вычисляет хеш-значение на основе IP, номера порта и т. д. (Это обсуждается в Интерпретации исходного кода NCCL 1).
Определите, какой путь выбрать, вычислив значение хеш-функции. Поскольку IP, номер порта и т. д. абсолютно одинаковы, вычисленное значение хеш-функции также составляет одну страницу, что может гарантировать, что один и тот же сеанс всегда будет проходить по одному и тому же пути, и предотвратить прерывание сеанса.
Я действительно не понимаю, как уменьшить конфликты хешей ECMP. Я исследую это позже, когда у меня будет время.
4.5.3 Контроль перегрузок
IB (Infiniband) не очень дорог и является частным протоколом, но он обязательно будет быстрым. Ethernet ссылается на него и разрабатывает RoCE v2. Что касается IB, он наследует ограничения сети без потерь IB и предлагает PFC (управление потоком на основе приоритетов). Когда буфер коммутатора вот-вот переполнится, PFC напрямую уведомляет восходящий порт и грубо приостанавливает любую передачу данных.
Появилось DCQCN (квантовое уведомление о перегрузке центра обработки данных). DCQCN включает в себя три компонента: сетевую карту отправителя, коммутатор и сетевую карту получателя.
1. Недостаточно кэша коммутатора. Пересылаемые пакеты данных помечаются вероятностью в зависимости от степени перегрузки, что указывает на то, что коммутатор вот-вот выйдет из строя.
2. Принимающая сетевая карта получает помеченный пакет данных и знает, что коммутатор умирает, поэтому отправляет пакет данных отправляющей сетевой карте.
3. Когда принимающая сетевая карта получает пакет данных, который коммутатор не может обработать, она замедляет отправку в соответствии с вероятностью. Я какое-то время не получал пакетов от коммутатора, поэтому начал его ускорять.
4.5.4 Настройка тайм-аута повторной передачи
Параметры в NCCL можно настроить для управления таймером повторной передачи и счетчиком повторов, а адаптивная повторная передача сетевой карты включена.
4.6 Операторы низкого уровня
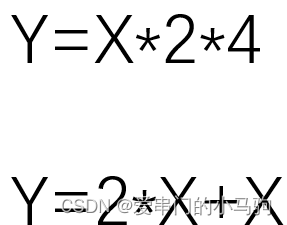
Добавьте комментарий к изображению, не более 140 слов (по желанию)
Объединение операторов оптимизирует процесс вычислений. Например, в первом приведенном выше расчете X изначально умножалось дважды, чтобы получить Y. Сначала оно было умножено на 2, а затем умножено на 4. Операторы были объединены, и X было умножено на 8 за один раз, что уменьшило объем вычислений. .
Слияние операторов может не только оптимизировать процесс вычислений, но иногда также оптимизировать процесс чтения и записи. Например, во втором вычислении выше сначала прочитайте X и умножьте его на 2, чтобы получить результат, затем прочитайте X и сложите результат, чтобы получить Y. После слияния вам нужно прочитать X только один раз.
4.5 Отказоустойчивость Кластера

Добавьте комментарий к изображению, не более 140 слов (по желанию)
4.5.1 Обнаружение сердцебиения
Сообщения Heartbeat отслеживают отклонения и выдают ранние предупреждения при их обнаружении.
Мониторинг на миллисекундном уровне: IP-адрес, имя модуля, информация об оборудовании, состояние обучения, трафик RDMA и немедленный сигнал тревоги при обнаружении ошибок или аномалий трафика.
4.5.2 Самодиагностика
Легкая диагностика неисправностей программного и аппаратного обеспечения позволяет быстро и автоматически обнаруживать проблемы.
Тест внутренней сети хоста: (1) тест пропускной способности сетевой карты RDMA для конечной точки хоста (узла памяти и графического процессора).
(2) Проверка соединения и пропускной способности между разными сетевыми картами RDMA на одном хосте.
Тест NCCL: (1) общий тест между графическими процессорами на сервере.
(2) Тестирование сервера allreduce под тем же коммутатором.
Примечание. Allreduce также можно использовать для тестирования различных базовых операторов связи. Базовые операторы связи и протоколы связи с сокращением и без сокращения, такие как alltoall, различаются.
4.5.3 Восстановление
Двухэтапная контрольно-пропускная точка, быстрое сохранение и вызов
Двухэтапное быстрое сохранение Checkpoint: первый этап Checkpoint записывается в память хоста;
Одновременно с обучением модели второго этапа Checkpoint записывается из памяти в HDFS.
Двухэтапный быстрый вызов контрольной точки: на первом этапе один графический процессор считывает контрольную точку из HDFS;
На втором этапе данные передаются всем остальным графическим процессорам, которым требуются те же данные.
4.5.4 Визуализация мониторинга производительности
При мониторинге производительности необходимо обращать внимание на зависимость между графическим процессором и графическим процессором. Он не основан напрямую на скорости работы графического процессора для определения производительности графического процессора. Когда входные данные для GPUA предоставляются GPUB, возможно, сам GPUA работает медленно и его производительность низкая, или же GPUB работает медленно, из-за чего создается впечатление, что GPUA работает медленно.

Добавьте комментарий к изображению, не более 140 слов (по желанию)

Добавьте комментарий к изображению, не более 140 слов (по желанию)
в заключение:
Хотя точность обучения модели остается неизменной, достигается коэффициент использования вычислительной мощности Model FLOPs Utilization (MFU) 55,2%, что в 1,34 раза выше, чем у самой совершенной среды обучения с открытым исходным кодом Megatron LM.

Добавьте комментарий к изображению, не более 140 слов (по желанию)
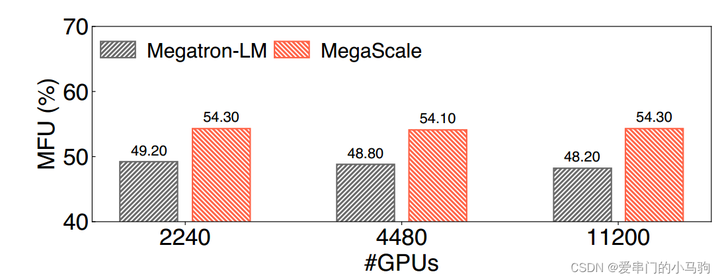
Добавьте комментарий к изображению, не более 140 слов (по желанию)

Добавьте комментарий к изображению, не более 140 слов (по желанию)
Оригинальная ссылка:
[2402.15627] MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs (arxiv.org)



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
