Пять основных мультимодальных технологий позволяют высокотехнологичному производству стать интеллектуальным
В сочетании со сценариями применения больших моделей технология искусственного интеллекта может использоваться для анализа сложного оборудования и документирования данных в высокотехнологичном производстве, а также для автоматического структурирования документов, таких как крупные детали, механические чертежи и руководства по эксплуатации. Большая модель позволяет идентифицировать, разбирать и классифицировать детали и методы ремонта, устанавливать сеть взаимосвязей между деталями и расходными материалами, а также создавать огромную базу данных. Эта способность, основанная на мультимодальной технологии и семантическом понимании, делает возможным систематическое управление и эффективные запросы, что значительно повышает эффективность обслуживания оборудования и управления производством.
- Введение основной технологии
- Распознавание макета
В процессе построения «Графа отраслевых знаний»,Распознавание макета技术作为核心技术之一,Обеспечивает ключевую поддержку для эффективного анализа технической документации. Эта технология проводит углубленный анализ структуры макета промышленных спецификаций.,Может точно различать в документе различные элементы, такие как заголовки, подзаголовки, абзацы, графики, таблицы, комментарии и т. д.,Это также закладывает основу для систематического извлечения информации и построения карт.
Распознавание макета技术可以自动识别这些版块,Особенно технические характеристики со сложной структурой таблиц,и преобразовать их в машиночитаемые структурированные данные. через этот шаг,Технический персонал может точно получить контекстную информацию каждого модуля.,Создание связей между компонентами、Этапы обслуживания、Информация о расходах и т. д. может быть организована в графе знаний.

Распознавание макета тесно связано с технологией распознавания изображений: с одной стороны, распознавание макета извлекает заголовки и структурные уровни, с другой стороны, числа и информация распознавания изображений связывают значки каждого компонента в документе для достижения органической интеграции текста и информации; содержание изображения. Таким образом, инструкции оборудования могут быть преобразованы из неструктурированного графического контента в структурированные узлы знаний и, наконец, сохранены в графовой базе данных. Технические специалисты могут не только получать ключевую рабочую информацию на мобильном терминале, но также получать общую структурную схему оборудования, корреляцию между компонентами и другую информацию на карте, тем самым обеспечивая систематическую поддержку при ежедневном обслуживании, диагностике неисправностей и управлении расходными материалами. Как показано на рисунке:
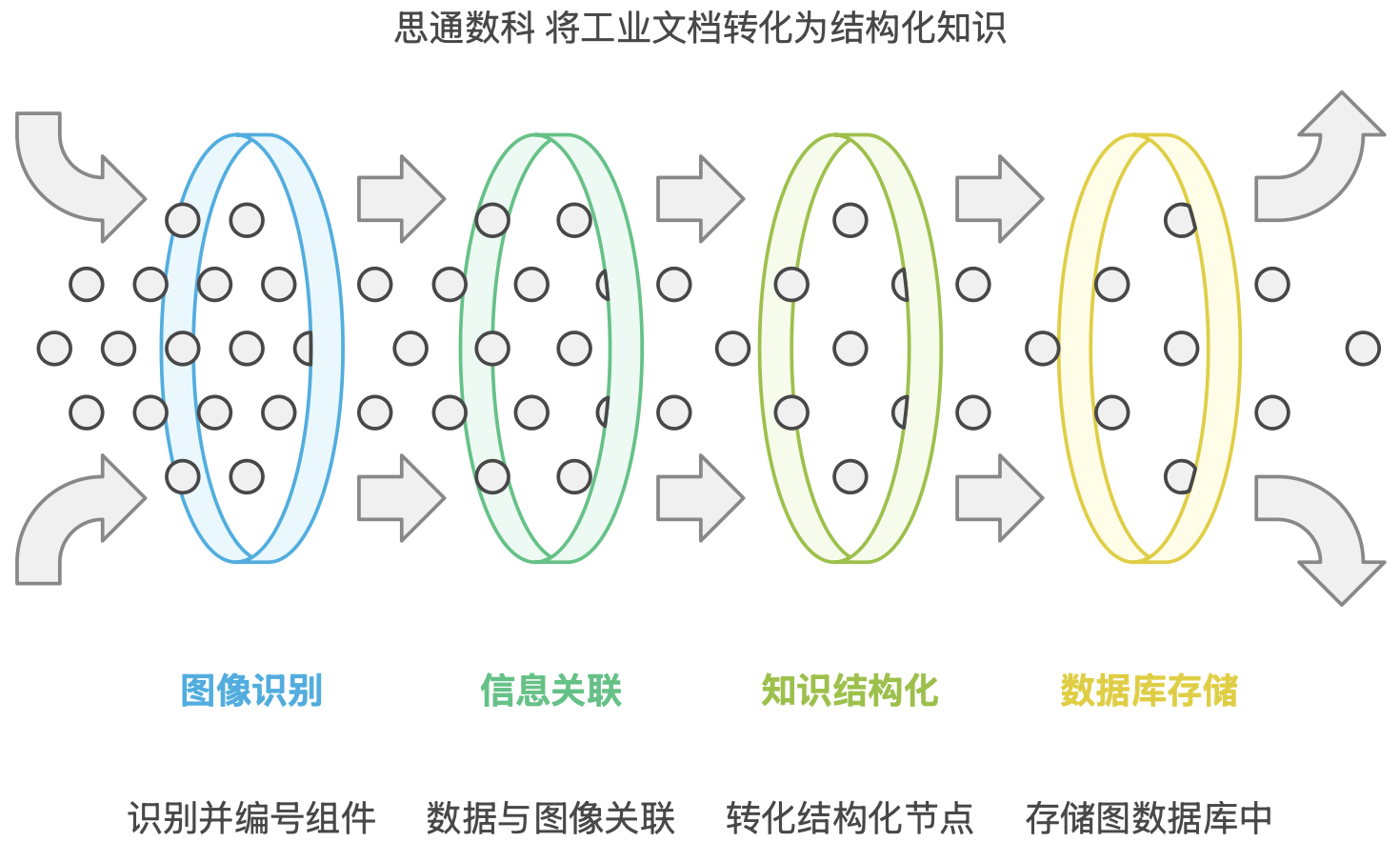
- Извлечение таблицы
Ключевые параметры и полуструктурную информацию необходимо извлечь из сложных руководств по эксплуатации или инструкций. Таблицы в этой информации обычно представляют собой каркасные или неструктурированные таблицы. Промышленные инструкции часто содержат большое количество таблиц параметров, показателей технического обслуживания и спецификаций компонентов. Однако из-за сложного формата таблиц напрямую считывать данные традиционными методами сложно. Благодаря технологии извлечения таблиц система может преобразовывать неструктурированные изображения таблиц в машиночитаемые структурированные таблицы, точно идентифицировать содержимое каждой единицы данных и сохранять иерархию и связь исходной таблицы.

Это результат распознавания в платформе возможностей ИИ. Например, в руководствах по техническому обслуживанию высокопроизводительного оборудования в таблицах обычно фиксируются параметры производительности, циклы обслуживания, условия эксплуатации и т. д. компонентов. Технология извлечения таблиц автоматически идентифицирует эту информацию и преобразует ее в записи базы данных, делая параметры и взаимосвязи каждого компонента на карте знаний понятными с первого взгляда. Эта технология не только повышает эффективность ввода информации, но и предоставляет техническим специалистам точную базу запросов.
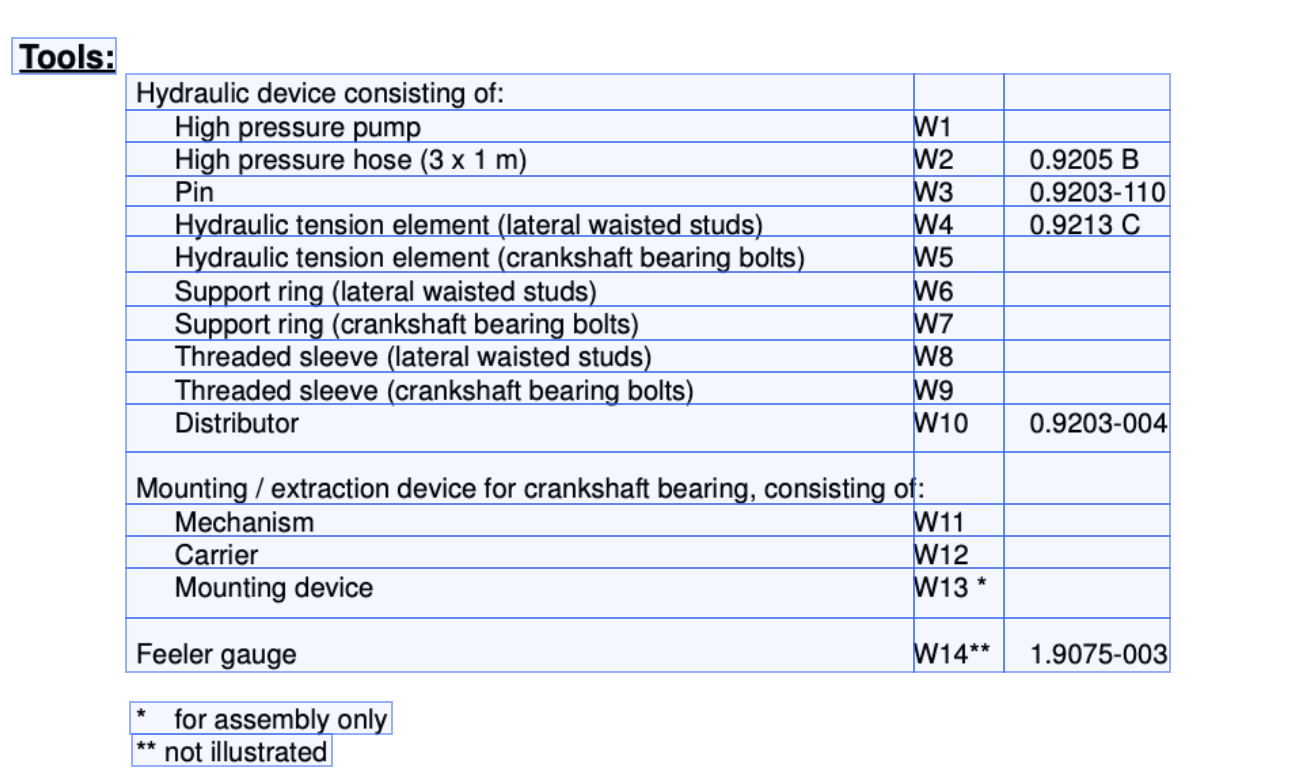
Это конечный результат вывода полностью структурированной таблицы после анализа на платформе AI Engine.
- Извлечение признаков
Извлекайте ключевые объекты (например, имена компонентов, этапы работы, требования к техническому обслуживанию) и связи (например, «компонент-подкомпонент», «компонент-функция») из неструктурированного текста, например инструкций. Этот процесс гарантирует, что каждый элемент руководства по эксплуатации преобразуется в узел данных в графе знаний, что делает информацию структурированной и семантически понятной.
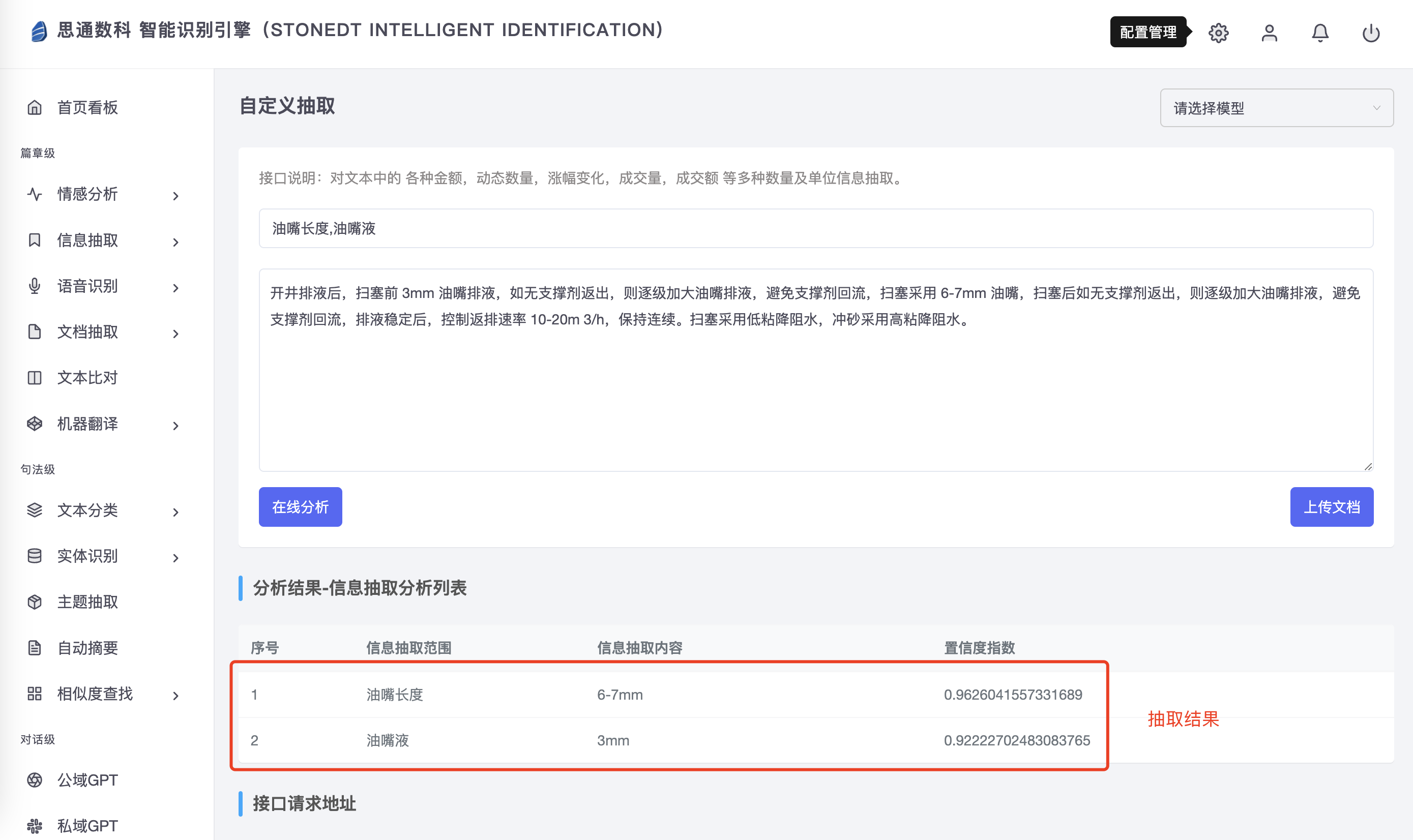
Например, для описания общих процессов технического обслуживания или точек диагностики неисправностей в руководствах соответствующие рабочие этапы и меры предосторожности могут быть автоматически определены с помощью технологии извлечения информации, и эта информация может быть связана с конкретными деталями или условиями эксплуатации в карте знаний, чтобы помочь техническим специалистам быстро получить точное руководство по работе при запросе. Такое извлечение информации и систематическое управление значительно улучшают использование документальной информации и обеспечивают интеллектуальную поддержку обслуживания оборудования.
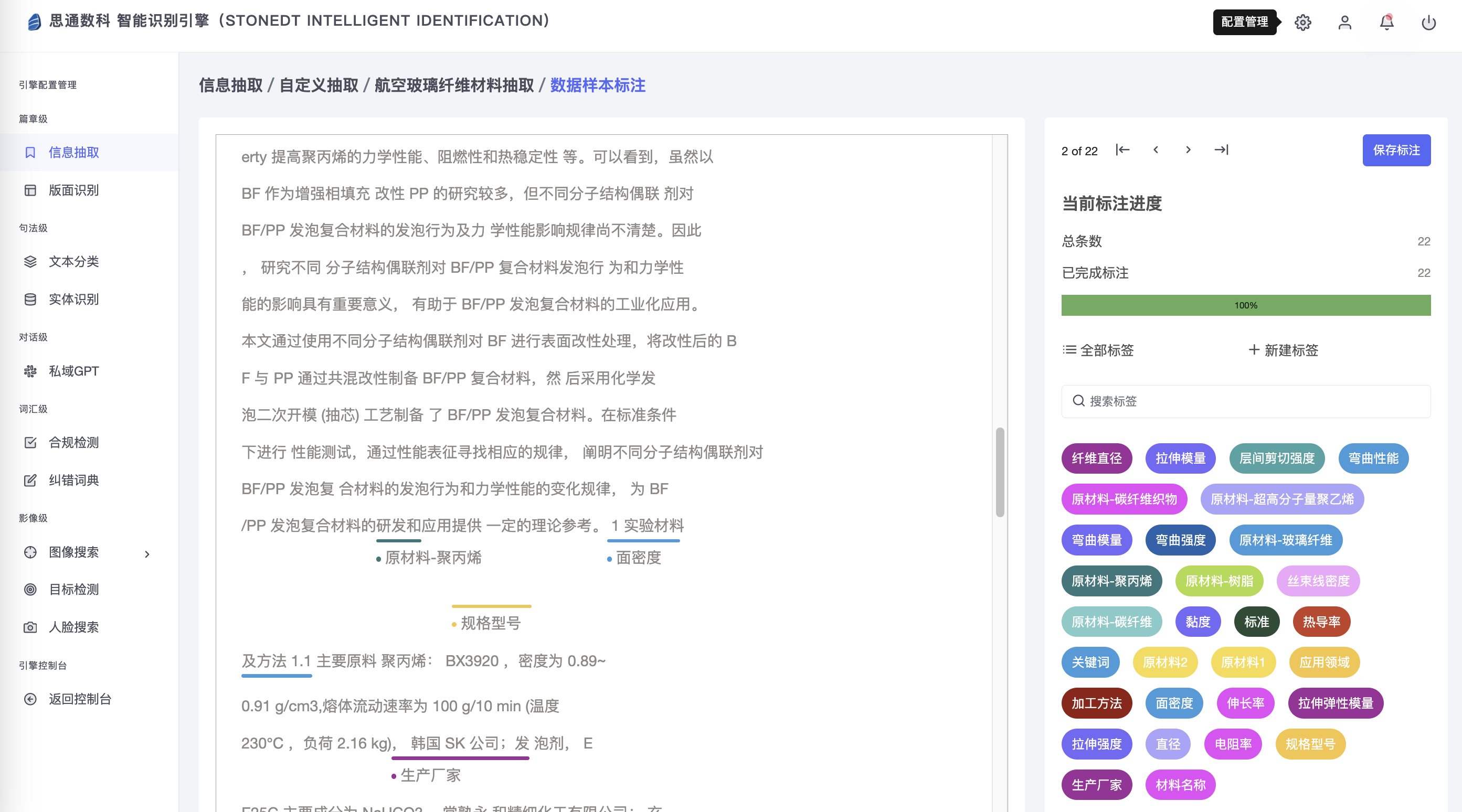
Пользователи могут загружать образцы данных через платформу для индивидуальных аннотаций и обучения, чтобы оптимизировать эффект извлечения информации и извлечения взаимосвязей. Платформа предоставляет гибкие инструменты аннотирования. Пользователи могут комментировать ключевую информацию в руководствах по оборудованию, записях о техническом обслуживании и других документах в соответствии со своими потребностями, например, модель оборудования, тип неисправности, история обслуживания и т. д. После завершения аннотации пользователи могут использовать аннотированные данные для обучения модели и настройки извлечения ключевой информации в определенных полях.
Благодаря такому индивидуальному обучению предприятия могут повысить точность модели извлечения, лучше адаптировать ее к реальным бизнес-сценариям, а также еще больше повысить эффективность обработки документов и качество анализа данных. Кроме того, платформа поддерживает постепенную оптимизацию и итеративное обучение, чтобы гарантировать, что модель может продолжать адаптироваться к новым потребностям бизнеса и изменениям данных с течением времени.
- Извлечение документа
Извлечение документа技术在工业知识图谱构建中,Автоматический анализ промышленных инструкций в Word, PDF и других форматах.,Вывод текста, изображений, таблиц, водяных знаков, верхних и нижних колонтитулов в структурированном виде. Эта технология поддерживает смешанное распознавание на нескольких языках и в разных сценариях.,Смешанные рукописные и печатные документы,Позволяет эффективно использовать информацию в сложных документах.
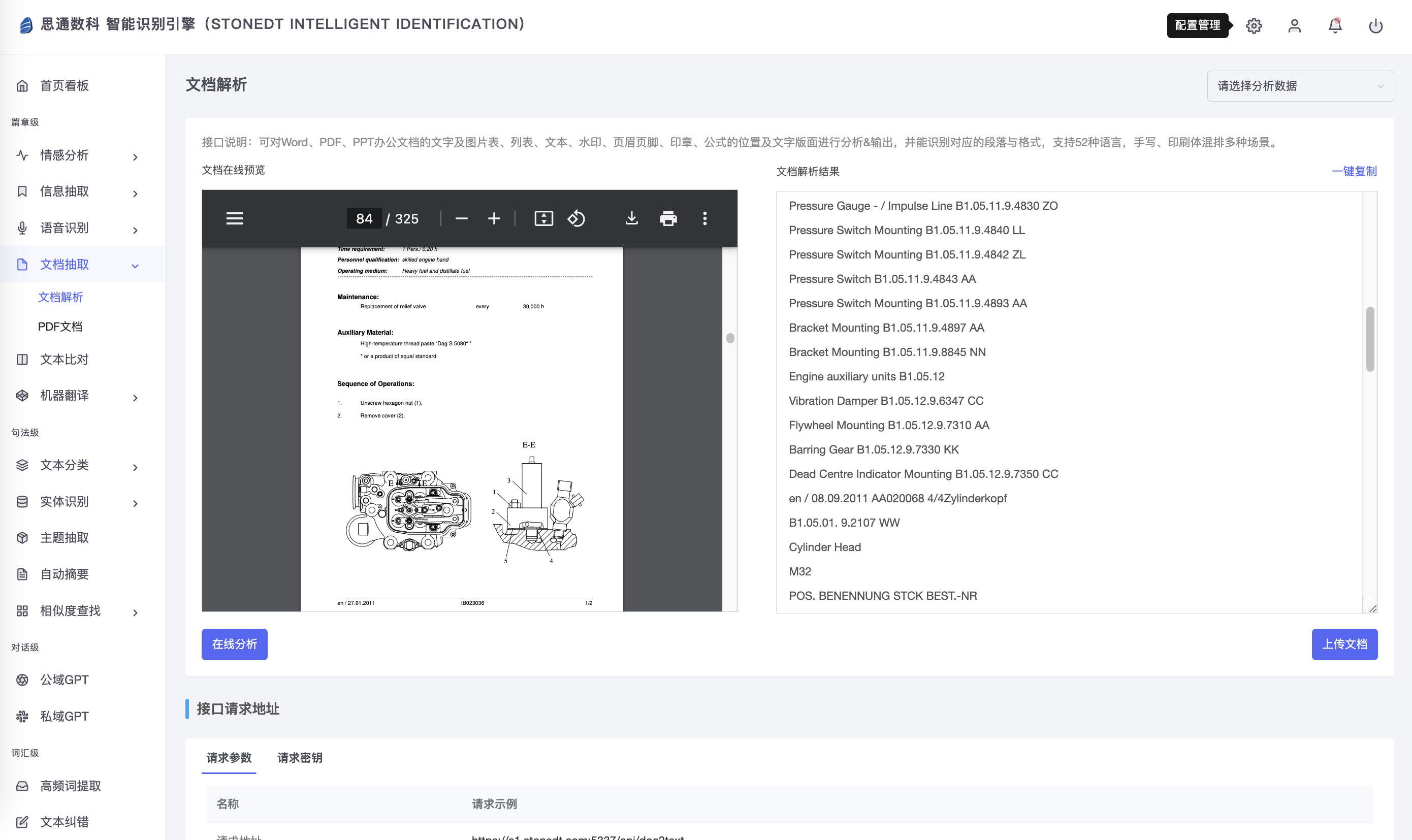
В проектных приложениях технология извлечения документов позволяет не только извлекать схемы и текстовые описания оборудования, но также отделять подробную информацию об этапах технического обслуживания, эксплуатационных характеристиках и деталях, а также классифицировать и архивировать их в соответствии с логической структурой содержимого документа. Наконец, это извлеченное содержимое импортируется в базу данных графов, что помогает техническим специалистам эффективно запрашивать и использовать подробную информацию в документах в графе знаний, тем самым значительно повышая эффективность управления документами и использования данных.
- Распознавание текста OCR
В промышленных руководствах большая часть содержания представлена в виде изображений и текста, особенно в виде схем деталей, блок-схем операций, этапов технического обслуживания и т. д. Технология оптического распознавания символов может идентифицировать текстовую информацию на этих изображениях и преобразовывать ее в текстовые данные для облегчения последующей структурированной обработки и извлечения данных. Например, с помощью технологии распознавания OCR названия компонентов оборудования, характеристики, циклы обслуживания и другая информация могут быть автоматически извлечены из отсканированных документов и встроены в базу данных графов для формирования основных данных графа знаний.
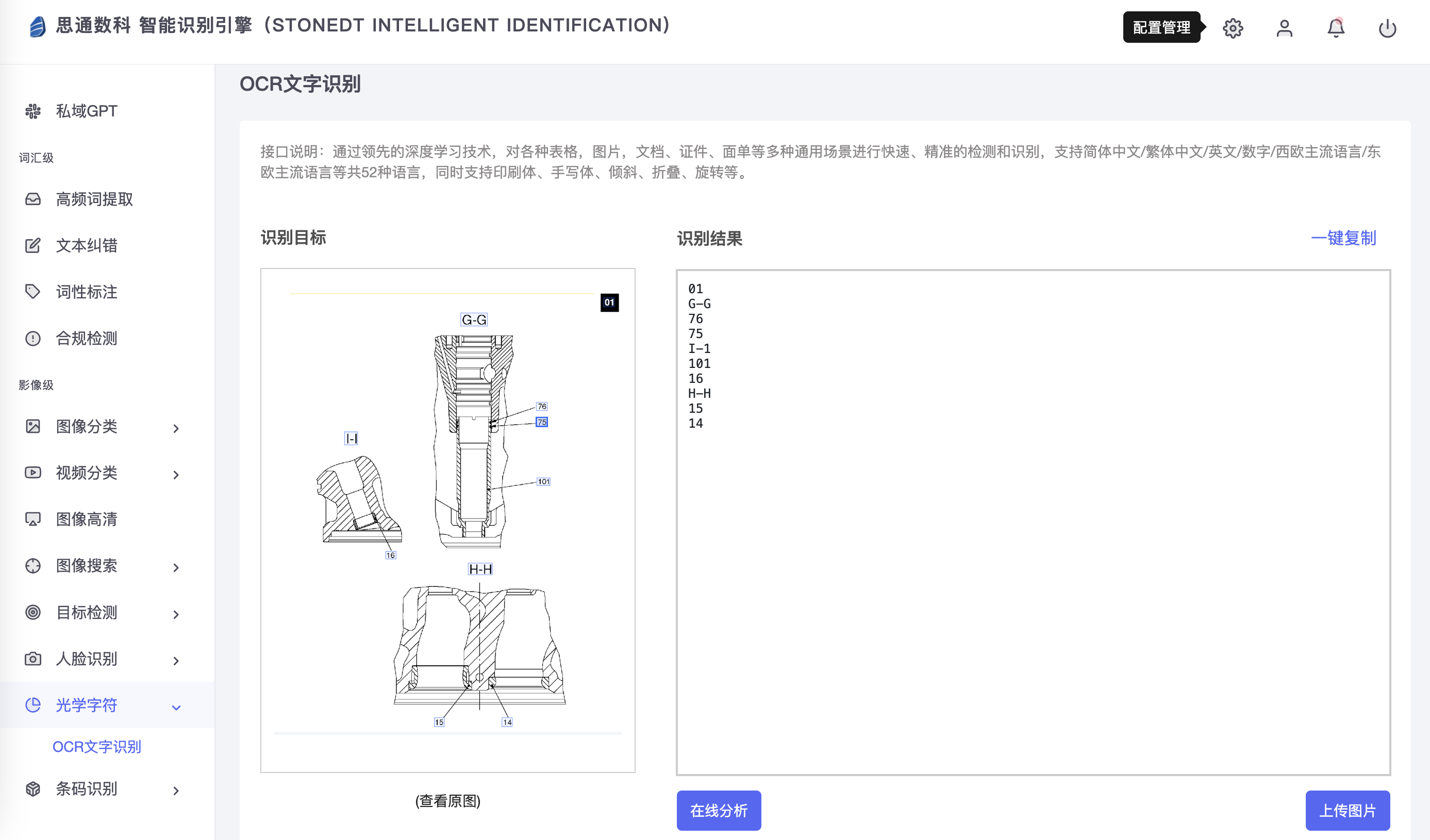
В этом процессе технология оптического распознавания символов не только помогает преобразовать информацию в бумажных или графических документах в структурированный текст, но также предоставляет точные исходные данные для последующего извлечения информации, извлечения таблиц и т. д., тем самым повышая эффективность построения всего графа промышленных знаний. точность.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
