Паркет и ORC: высокопроизводительные столбчатые хранилища Записи молодежных сборов |
Паркет и ORC: высокопроизводительное столбчатое хранилище
Хранилище столбцов, хранилище строк
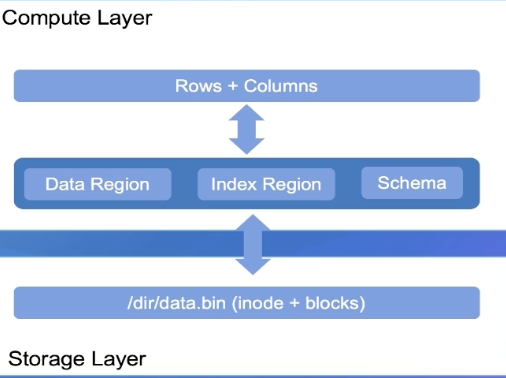
Обзор уровня формата данных
Вычислительный уровень: различные вычислительные механизмы.
Уровень хранения: постоянное хранилище, в котором хранятся данные.
Уровень формата данных: определяет организационный формат в файле уровня хранения. Вычислительный механизм считывает и записывает файлы посредством поддержки уровня формата с точки зрения формы данных с многоуровневой точки зрения.
С многоуровневой точки зрения форма данных,Механизм вычислений ведет себя какRows+Columns,хранилищеслоистыйданные ФормаfileиBlocks、Слой форматаФайл внутреннийиз Расположение данных (Layout+Schema)
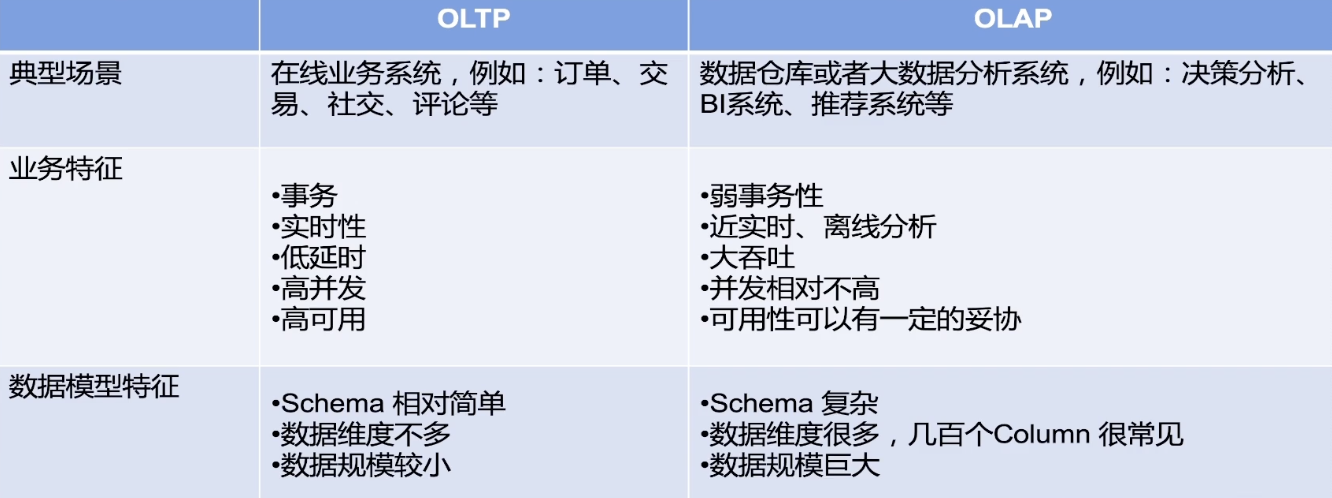
данные Сценарий анализа запроса:OLTP vs. OLAP
OLTP: формат хранения строк (хранилище строк)
Данные каждой строки представляют собой последовательное хранилище в файле.,Чтение всей строки данных эффективно,ОдинокийIOПросто читайте последовательно。Типичные системы являются реляционными.данные Библиотека、key-valueданные Библиотека
OLAP: столбчатый формат хранения (столбцовое хранилище)
Данные каждого столбца в файле представляют собой непрерывное хранилище.,Чтение всего столбца более эффективно,данные в одном столбце имеют один и тот же тип,Кодирование со сжатием более эффективно. Общие крупномасштабные системы анализа данных, такие как SQL-on-Hadoop.,данныеанализ озера и т. д. илиClickHouse,Greenplum,Алибаба ОблакоMaxComputeждатьданныесклад Библиотека Вот и все Формат
Резюме: Уровень формата определяет расположение данных.,Подключиться к вычислительному механизмуихранилище Служить。OLTPиOLAPРазница в сценах очевидна。Бизнес-сценарии определяют техническую реализацию,банковский депозит Применимо кOLTP,Список Применимо кOLAP
Parquet
Parquetбольшойданные Наиболее широко используется в области анализа.из Список Формат;Sparkрекомендоватьхранилище Формат
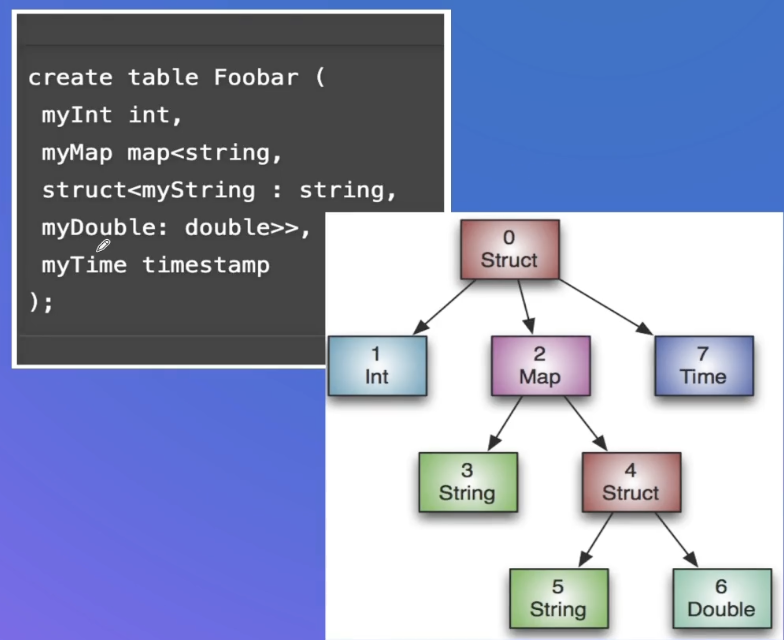
Dremelмодель данных
Protocol Bufferопределение、Поддерживает необязательные и повторяющиеся поля.、Поддержка вложенных типов (вложенные типы сохраняют только данные конечных узлов)
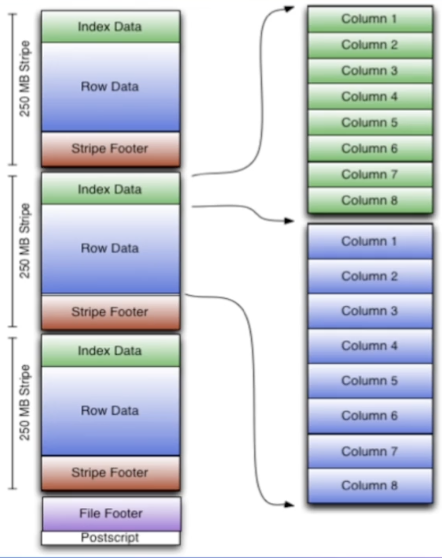
Расположение данных
RowGroup: каждая группа строк содержит определенное количество строк фиксированного размера.
ColumnChunk:RowGroupРазделить на несколько столбцовColumnChunk
Страница: ColumnChunk по-прежнему внутренне делится на страницы.,Общие советы8KBразмер。сжатиеикодированиеизбазовая единица。сохранено согласноизданные Типы делятся наData Page、Dictionary Page、Index Page
FooterСохранение метаинформации файла:Schema、Config、Metadata(Rowgroup Meta、Column Meta)
кодированиеEncoding
Plainпрямойхранилищеоригинальныйданные
Кодирование длины прогона (RLE) подходит для сценариев, где база столбцов небольшая и имеется много повторяющихся значений, таких как перечисления, логические значения, фиксированные параметры и т. д.
Bit-Pack Encoding:СотрудничатьRLEкодированиеиспользовать,Сделайте хранилище пластиковых номеров более компактным
Кодировка словаря Словарь Кодирование в основном используется для кодирования строк.,Подходит для случаев, когда основание колонны невелико.,Построить словарную таблицу,написатьDictionary Page;Пучокданныеиспользовать словарьindexзаменять,Затем используйтеRLEкодирование
В сценарии по умолчаниюparquet-mrбудет автоматически основываться наданные Выбор функции。в бизнесе сопределениесцена,Можно использоватьorg.apache.parquet.column.values.factory.ValuesWriteFactory
сжатиеcompression
pageЗаканчиватьencodingпосле,Компресс
Поддерживает несколько алгоритмов сжатия.
snappy: блок скорости сжатия, низкая степень сжатия, подходит для горячих данных.
gzip: медленная скорость сжатия, высокая степень сжатия, подходит для холодных данных.
zstd: новый алгоритм сжатия.,сжатие Сравниватьиgzipпочти,исжатие速度Сравнивать肩snappy
Рекомендуемый выборsnappyилиzstd,Полностью протестируйте эффект сжатия в зависимости от типа бизнеса.,и влияние на производительность запросов
индексIndex
По сравнению с традиционными базами данных поддержка индексов очень грубая.
Min-Max Index:Записыватьpageвнутреннийcolumnизmin_valueиmax_value
Column Index:footerвнутриизcolumn metadataВключатьcolumnChunkизвсеpageизMin-Max value
Offset Index:Записыватьpageв файлеизoffsetиpageизrow range
bloom filter
parquet.bloom.filter.enabled- Для сценариев, когда основание колонны относительно велико,Или фильтрация неотсортированных столбцов,Min-Max Index很难发挥作用
- 引入bloom filter加速过滤匹配判定
- 每个ColumnChunkизсохранение заголовкаизbloom filterданные
- footerЗаписыватьbloom filterизpage offset
сортироватьOrdering
- Концепция аналогична кластерному индексу
- Сортировка помогает лучше отфильтровывать ненужные группы строк или страницы.,за небольшую суммуданныеseekОчень полезно
- parquet FormatподдерживатьsortingColumns
- parquet LibraryНет в настоящее времяподдерживать
- Положитесь на бизнес-сторону, чтобы обеспечить порядок на основе характеристик запроса
фильтр с понижениемPredicate PushDown
- parquet mrБиблиотекавыполнить,Внедрить эффективный механизм фильтрации
- Входящее со стороны двигателяfilter expression
- parquet mrПревратить в бетонcolumnиз条件匹配
- 查询footerвнутриизcolumn index,Найдите конкретный номер строки
- Возвращает действительные данные на сторону движка
векторизованное чтение искровой интеграции
- Векторизованное чтение реализовано на основе класса parquetFileFormat.
- Переключатель векторизованного чтения
spark.sql.parquet.ebableVectorizeReader - Векторизованное чтение является стандартной практикой для основных механизмов анализа больших данных и может значительно повысить производительность запросов.
- sparkкbatchизпуть отparquetчитатьданные,Нажмите внизиз Логика тоже адаптируетсяbatchиз Способ
ORCПодробное объяснение
ORC — один из наиболее широко используемых форматов списка в области анализа больших данных.,отhiveпроект
модель данных
- ORCдаст включая корневой узелиз Создайте по одному для каждого промежуточного узлаcolumn
- Вложенные типыилиили тип коллекцииподдерживатьиparquetбольшая разница
- необязательный и повторяющийсяПоля зависят от родительских узлов Записыватьдополнительная информация для повторенияassemblyданные
Расположение данных
- похожийparquet
- rooter+stripe+column+page(row group) структура
- encoding/compression/indexподдерживатьначальствоиparquetпочти единогласно
ACIDВведение в функцию
- поддерживатьHive Transactionsвыполнить,В настоящее время существуют толькоhiveИнтегрируйте себя
- похожийdelta lake/hudi/iceberg
- на основеBase+Delta+Compactionиздизайн
паркет против ORC
- С принципиального уровня,максимумиз Разница в том, что дляnestedTypeисложный типиз处理начальство
- parquetиз算法начальство要复杂很多,приноситьизcpuиз开销Сравниватьorcнемного больше
- orcиз Алгоритм относительно прост,Но читать далееданные
- Следовательно, влияние этой разницы на бизнес-результаты зависит от фактического бизнес-сценария.
Эволюция списка
Хранение столбцов в хранилище данных
- clickhouseизmergeTreeКак и двигательна основе Список Строитьиз
- По умолчанию следующееcolumnрасколоть
- Поддержка более богатых индексов
- Общая тенденция интеграции озер и складов
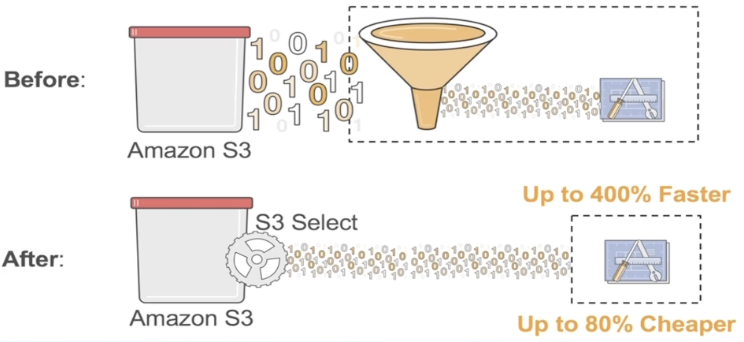
Сторона хранения, опускающаяся вниз
- Больше работы по передаче данных на сторону обслуживания хранилища
- Чем ближе это к данным, тем выше эффективность фильтрации с понижением.
- НапримерAWS S3 SelectФункция
испытание:хранилищебоковое восприятиеschema、Совместимость и интеграция вычислительной экосистемы、column family



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
