Озеро и склад интегрированы
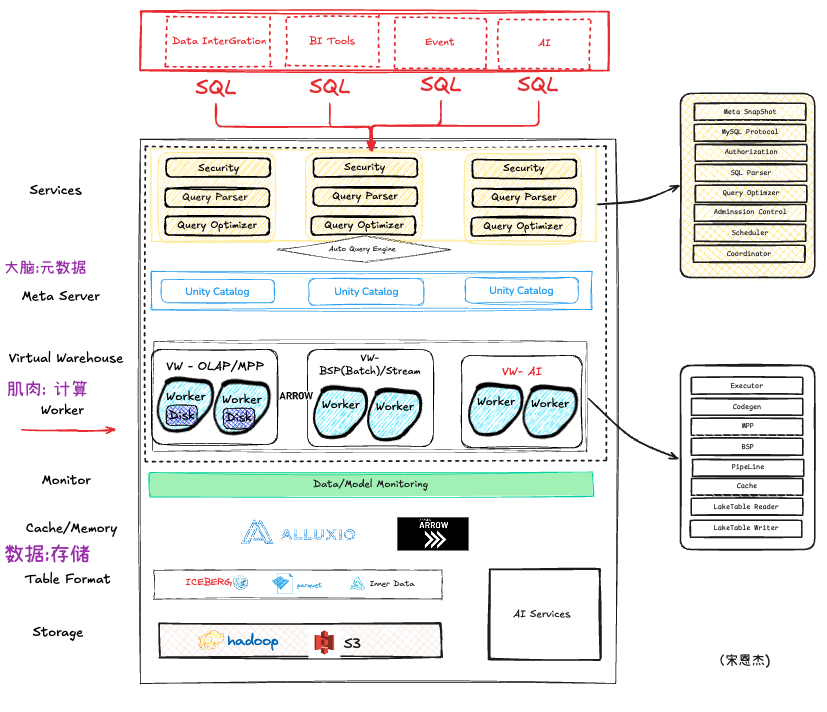
Как человек, в основном занимающийся исследованиями и разработками ядра OLAP, подведите итог существующему пониманию Hucang, приветствуем критику/исправление/обсуждение;
1 Почему Озеро и склад интегрированы так жарко:
Не буду вдаваться в подробности определений озер и складов здесь. Можете поискать.
Я понимаю, что компании с различными вспышками данных в настоящее время сталкиваются с различными проблемами с архитектурой своей платформы данных.,Ищете архитектуру данных, которая адаптируется к компании и платформе,Универсальное решение,Но у каждого может быть разное понимание природы озер и складов.,Озеро и склад объединены.
Я тоже,Понимание должно быть односторонним,Содержание, которое я поглощаю, также отличается от картинки в моей голове.,Я могу только сделать все возможное,ясно выражайся Озеро и склад понимания интеграции, и с каким бизнесом мы сталкиваемся, как нам построить свое Озеро вокруг нашей платформы? и склад интегрированы。
Прежде всего, если объем данных вашей платформы данных составляет менее 100 ТБ и будущее расширение данных ограничено, я думаю, вам не нужно читать статьи такого типа. Создание интегрированного хранилища данных MPP и вычислений в реальном времени на основе вашего хранилища данных. собственное понимание, скорее всего, решит проблему.
2. Классификация углов анализа:
Я думаю, что нам следует сначала классифицировать компоненты данных, а затем попытаться классифицировать их с точки зрения применения. Каждый может критиковать и исправлять:
С точки зрения механизмов данных мы можем разделить их на базы данных, хранилища данных и озера данных. Они также развивались из-за инфляции данных;
С точки зрения архитектуры программного обеспечения мы можем разделить их на: автономную базу данных, распределенную базу данных, базу данных с высоким уровнем параллелизма, бессерверную базу данных;
С точки зрения типов данных мы можем разделить их на: реляционные базы данных и нереляционные базы данных;
Реляционные базы данных, преимущественно (TP, ROLAP), нереляционные базы данных, преимущественно (озеро данных, MOLAP);
В зависимости от технической сложности мы разделяем их на: транзакционные базы данных: высокая степень параллелизма, высокая степень изолированности данных; хранилище данных без транзакций, нестрого согласованная база данных;
С точки зрения эффективности их можно разделить на: онлайн-база данных (база данных, хранилище данных реального времени), автономная база данных (озеро данных, автономное хранилище данных);
По методу обработки данных/или с точки зрения использования он делится на потоковую обработку и пакетную обработку. Потоковая обработка показывает характеристики онлайн и в реальном времени, а пакетная обработка показывает характеристики в автономном режиме и не в реальном времени.
С точки зрения производительности хранилища: мы разделены на регистры, кэш, память, Nvme, SSD, жесткий диск, облачный жесткий диск, облачный диск, хранилище объектов, хранилище документов (горячее, теплое, холодное хранилище).
Уже неудачные попытки: ТП,AP->HTAP Объявлен провал, то есть невозможный треугольник данных: стоимость, актуальность и производительность могут быть удовлетворены одновременно.
3 Классификация компонентов больших данных:
Компоненты больших данных:
MySQL (система хранения и вычислений, автономная, реляционная, структурированные данные реального времени, транзакционная база данных)
Flink (вычислительная система хранения, потоковая вычислительная машина, в реальном времени, структурированная, полуструктурированная)
OLAP (Doris ClickHouse ADB-MySQL) (система хранения и вычислений, хранилище данных реального времени, реляционное, структурированное, полуструктурированное, хранилище данных реального времени)
Trino, MaxCompute (вычислительная система, работающая в режиме реального времени, оффлайн)
Spark (вычислительный механизм, пакетная обработка, автономный режим, структурированный, полуструктурированный)
Iceberg, Hudi, Paimon, DeltaLake (система хранения данных, работающая в режиме реального времени, автономная, структурированная, полуструктурированная, неструктурированная)
Hadoop (система хранения данных, автономная, полуреального времени, структурированная, полуструктурированная, неструктурированная)
SnowFlake/DataBricks/RedShift Озеро и склад интегрированы?
4 Классификация с точки зрения применения отдельных продуктов:
вид сверху,Или с традиционной точки зрения количества складов.,Вышеуказанные компоненты специально классифицированы,Прямо сейчасСмотри на горы как на горы, смотри на воду как на воду.;
Начинаем с продукта: например, о чем вы думаете
Архитектура ClickHouse должна быть: Zookeeper + ClickHouse + локальное хранилище.
Архитектура ByConity должна быть: FDB + ByConity + распределенное хранилище.
Архитектура Impala должна быть: HiveMetaStore + Impala + Kudu/распределенное хранилище.
Архитектура ADB должна быть: ADB + хранилище/распределенное хранилище.
Архитектура Iceberg должна быть: Iceberg + распределенное хранилище.
Итак, вы заметили, что продукт, по мнению каждого, должен содержать три части: метаданные, данные и движок. Тут еще нужно иметь четкое различие в строении мозга, или вы хотите понимать их как одно и то же, это нормально;
5 Эволюционное мышление:
Далее давайте введем ссылку смотреть на горы, но не на горы, и смотреть на воду, но не на воду:
Озеро и склад интегрированы/Оффлайн и онлайн/облачный родной Означает ли это то же самое:
С точки зрения продукта, я думаю, что Iceberg (Iceberg+hdfs/s3) — это озеро. Вы также можете поискать определение озера данных.
Офлайн-интеграция часто выражается как интеграция самого продукта: например
Интеграция метаданных, например, различные собственные механизмы коммерциализации + набор внешних/мульти/единичных/унифицированных каталогов.
Интеграция движка: Сам движок смешан с многозадачными режимами выполнения: такими как BSP и MPP, или его называют интеллектуальным движком. Из статьи уже реализован ByConity;
Интеграция хранилища: все данные хранятся и управляются единообразно. Независимо от того, является ли конкретное хранилище согласованным и единообразным, здесь не может быть никаких ограничений.
Cloud Native: речь идет больше об уменьшении количества серверов в сервисах, которые он хочет выразить. Например, сам движок реализует эластичное масштабирование и многопользовательскую эксплуатацию, а само хранилище реализует биллинг с оплатой по факту использования, что больше отражается. поставщики облачных услуг.
Наиболее представительными продуктами являются AWS S3, Tencent Cloud COS...
6 WhyОзеро и склад интегрированы
вопрос:
Неравные возможности: разные движки имеют разные сценарии использования, функциональную поддержку, характеристики производительности, стратегии оптимизации и лучшие практики;
Сложность выбора. Несколько двигателей означают разнообразие в выборе технологий, а это и хорошо, и плохо. Плохо то, что это усложняет процесс принятия решений, и нужно взвешивать преимущества и недостатки разных движков и совместимости с существующими платформами;
Сложность долгосрочного планирования: работа с несколькими двигателями затруднит формулирование долгосрочных планов развития технологий;
Хранилища данных: данные не могут эффективно совместно использоваться и интегрироваться между механизмами синхронизации, что ограничивает возможности анализа данных и бизнес-аналитики.
Высокие затраты на эксплуатацию и техническое обслуживание. Процесс обслуживания нескольких двигателей, такой как развертывание, совместимость, настройка, устранение неполадок, а также расширение и сокращение, отнимает много времени и энергии, что делает работу научно-исследовательского персонала сложной и обременительной после возникновения неисправности. , ее нужно быстро найти и решить.
Низкая простота использования: пользователи надеются, что смогут сосредоточиться только на своем основном бизнесе, а не на базовой технологии, и желают иметь простую и удобную в использовании платформу;
Высокая стоимость использования: когда базовый движок меняется, пользователь не хочет, чтобы изменения в базовом движке влияли на его поведение при использовании, и у нас также есть детальные права доступа к данным;
Краткое описание проблемы: для решения проблемы необходимо постоянно вводить новые компоненты в исходную архитектуру. По мере увеличения масштаба бизнеса общую архитектуру становится трудно поддерживать;
Обзор отрасли: Эти проблемы являются общими, и появление крупных моделей определило направление развития платформы данных следующего поколения;
6 How/What Озеро и склад интегрированы
Я понимаю, что это скорее абстрактная логика, я не буду ее объяснять, я посмотрю на вас дальше.
Например, когда MPP впервые назвали хранилищем данных в реальном времени, хранилищем данных или базой данных, люди сначала и даже сейчас могли быть сбиты с толку и сомневаться.
В перспективе: Скорее всего, это по-прежнему будет olap + хранилище данных + озеро данных, но между ними постоянно происходят изменения. Например, Trino сам по себе является движком запросов, но StarRocks развивает его по одной функции. , взаимодействие изменилось, и продукты тоже изменились. Итак, сейчас он появляется в форме объединенных запросов и преобразования диалектов, поэтому я верю, что в будущем он будет унифицирован.
С точки зрения продукта/приложения,текущийРеализуемые решения:
1 Используя сценарий Adhoc озера данных, просто создайте платформу. : Вы можете использовать HDFS. + Iceberg + Trino + Doris Приходите и быстро настройте, HDFS хранилище, Айсберг Отвечает за метаданные и формат данных, Trino отвечает за ускорение, StarRocks Отвечает за ускорение MPP, то есть ускорение озера;ПлюсDoris Благодаря собственным возможностям MPP он также имеет возможность записывать пакетные задачи для выполнения облегченного ETL;
2 Из отчетов BI в реальном времени (офлайн + в реальном времени). Традиционные платформы хранилищ данных уже имеют): Вы можете окружить HDFS + Iceberg + Дорис использует StarRocks Асинхронные материализованные представления,Достижение агрегации и ускорения данных,То есть построить склад на озере。
3 С точки зрения интеграции: унифицированные сервисы данных Doris единообразно принимает службы записи и чтения. Данные разделяются на горячие и холодные данные. Горячие данные являются локальными, а холодные данные попадают в озеро. Поскольку они интегрированы, холодные данные необходимо преобразовать в Iceberg. В озеро укладывается паркет и другие форматы, а затем используется союз. view,Выполняйте горячие и холодныеданныеагрегирование;достигатьданныеединый взгляд на,Прямо сейчасНад складом висит озеро, горячая и холодная стратификация.;
4 Озеро от истинного сознания и склад интегрированы,То естьоблачный роднойПонятно:
One Data: поддерживает как автономную обработку, так и онлайн-разделение для обеспечения согласованности и эффективности данных, то есть данные не обязательно должны быть с открытым исходным кодом;
Одна служба: уровень службы запросов, запись запроса;
Один механизм: уведомление поддерживает метод планирования MPP/BSP для решения проблем вычислительной пропускной способности и высокой производительности с полной гибкостью и изоляцией ресурсов;
отУгол запросаотправление:Вышеупомянутое использование,Логично, что OLAP — это выход.,Реализован единый запрос
отперспектива чтения и письмаОтправляться:Может быть, только первый3,4 варианта,полное объединение,Но в настоящее время внутреннему количеству складов более или менее не хватает некоторых возможностей.,Включая некоторые вопросы, касающиеся внутренней организационной структуры.,Это оказывает незначительное влияние на дальнейшие итерации.
Надеюсь, это чтение вдохновило вас!



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
