От озера данных к озеру метаданных: управление озером метаданных нового поколения TBDS
01. Этап разработки управления метаданными
За годы развития больших данных метаданные можно разделить на три этапа.
Первый этап — это служба метаданных, представленная Hive Metastore, которая в основном обеспечивает хранение и доступ к информации метаданных, такой как таблицы базы данных Hive. Это первая служба управления метаданными Hadoop с открытым исходным кодом, которая почти стала стандартом де-факто, так что последующие вычисления. Такие движки, как Spark, Impala, Trino и т. д., по умолчанию используют стандартный доступ Hive Metastore. Однако по мере того, как масштаб данных растет, а требования к эффективности доступа к данным становятся все выше и выше, выявляются его недостатки, связанные с отсутствием поддержки нескольких каталогов и почти отсутствием возможностей управления метаданными.
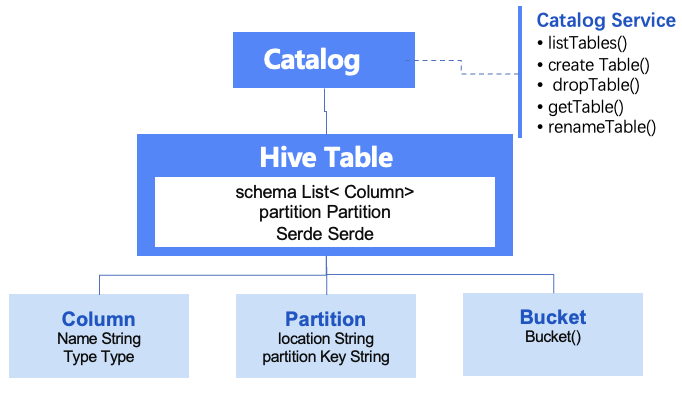
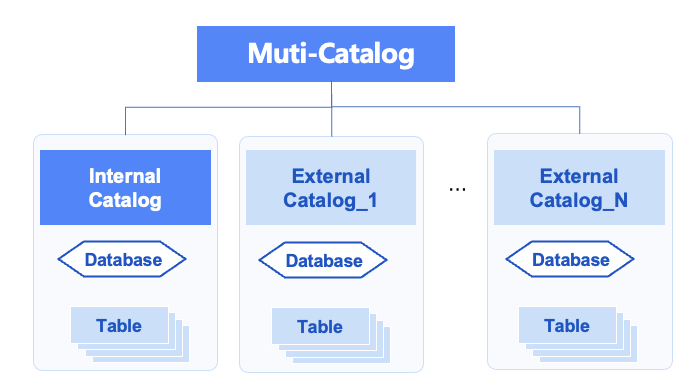
Затем появился второй этап поддержки нескольких источников данных каталога, представленный Trino/Spark's Catalog и Starrocks/Doris Muti-Catalog. По сравнению с Hive Metastore, он поддерживает несколько источников данных Hive и другие источники данных. Это вычислительная основа. Вычисления между источниками в движке разрушают разрозненность данных и достаточны, чтобы справиться с постоянным увеличением масштаба данных и связью между кластерами и источниками данных. Но недостатком является то, что их службы Muti-Catalog находятся в соответствующих компонентах. Они не являются независимыми службами, такими как Hive Metastore, и не могут быть предоставлены другим внешним механизмам. С развитием больших моделей ИИ требования к управлению векторизованными данными функций модели становятся все выше и выше, а также отсутствует поддержка неструктурированных данных.
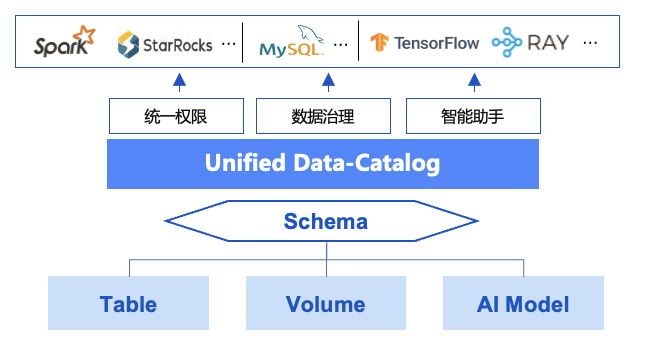
Третий этап можно назвать Единым каталогом данных. Он находится в зачаточном состоянии и представлен Unity Catalog и Gravitino. Это единый сервис метаданных для структурированных и неструктурированных данных, открытости и доступности для облаков и регионов. Он полностью поддерживает неструктурированные и полуструктурированные векторные данные, используемые искусственным интеллектом и экосистемой больших данных Hive, формат таблиц озера данных, файловую систему/хранилище объектов Hdfs и другие данные, а также традиционные базы данных и хранилища данных, поддерживающие унифицированный доступ Jdbc. управление и управление данными, а также происхождение данных поддерживают несколько экосистем вычислительных механизмов, и на основе этого предоставляются службы данных с унифицированными разрешениями, унифицированными моделями каталогов и открытыми API.
Таким образом, в эпоху Data+AI, столкнувшись с интеграцией неструктурированных данных AI и больших данных, а также с потребностью в более сложных возможностях управления данными из разных источников, TBDS разработала унифицированную систему озера метаданных нового поколения в третьем этап.
02. Решение нового поколения для управления озером метаданных
Новая система озера метаданных TBDS в основном включает в себя унифицированный уровень службы доступа, унифицированный уровень управления Lakehouse, унифицированный уровень разрешений метаданных и унифицированный уровень соединения модели каталога в соответствии с уровнями. Мы представили Gravitino и на основе его управления данными, прав доступа к данным и других возможностей интегрировали и оптимизировали большое количество существующих возможностей TBDS, чтобы сформировать законченную систему с замкнутым циклом.
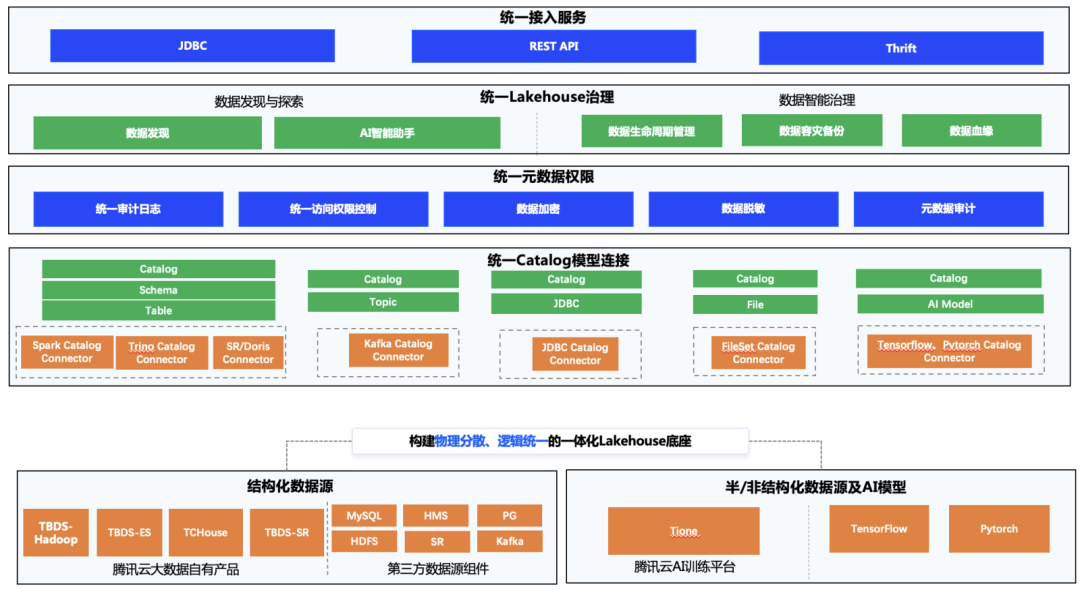
Служба унифицированного доступа предоставляет пользователям или механизмам открытые стандартные интерфейсы API для выполнения различных операций с озером метаданных, а также предоставляет три способа доступа к метаданным: JDBC, REST API и протокол Thrift. JDBC обычно подходит для пользователей, которые хотят напрямую управлять унифицированной метаданной с помощью операторов SQL, например, для показа таблиц; REST API предназначен для разработчиков исходного кода, которые хотят получать информацию о метаданных, например, службы управления страницами WebUI. Thrift — это соединитель для механизмов; например, доступ к метаданным, вычислительный механизм Spark использует протокол Thrift в соединителе для получения единого каталога метаданных для вычислительного механизма для выполнения дальнейших вычислений.
Унифицированное управление Lakehouse фокусируется на организационной эффективности метаданных и выполняет планирование данных, объединение, управление жизненным циклом, анализ происхождения, аварийное восстановление и резервное копирование и т. д. для обеспечения качества данных, а также обеспечивает обнаружение и исследование данных, а также возможности интеллектуального помощника искусственного интеллекта для интеллектуального управления. найти данные для пользователей, распознавание номеров, пользовательский опыт. Существуют также некоторые возможности, такие как горячие и низкие температуры данных, управление слиянием небольших файлов и происхождение данных, которые также предоставляются этим уровнем.
Унифицированные разрешения для метаданных. Учитывая исходные системы разрешений для нескольких источников данных, таких как Ranger, RBAC, IAM и т. д., механизм плагинов предназначен для открытого доступа к различным внешним системам разрешений и обеспечивает унифицированное определение модели разрешений и метод использования для них. внешний мир. Полное унифицированное управление и контроль. Он также предоставляет унифицированные возможности для аудита данных, шифрования данных и снижения чувствительности данных.
Соединение единой модели каталога. При наличии нескольких систем метаданных источников данных унифицированная модель каталога предназначена для описания метаданных Hive, метаданных файловой системы, метаданных темы очереди сообщений, метаданных JDBC, метаданных модели AI и другой информации, чтобы обеспечить следующее: данные; исходный компонент может распознавать единую модель каталога и предоставляет соединители каталога для различных источников данных, которые совместимы с реализациями интерфейса, включая библиотечные таблицы, функции, представления, ScanBuilder, WriterBuilder и т. д. Этот уровень не только обеспечивает унифицированное управление метаданными из нескольких источников данных, но также поддерживает быстрый объединенный анализ источников данных более низкого уровня.
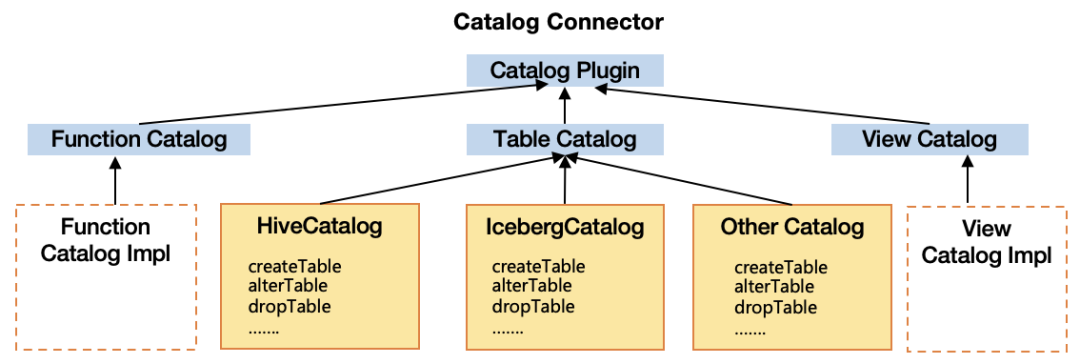
Благодаря комплексному управлению структурированными, полуструктурированными и неструктурированными данными с помощью новой унифицированной системы озер метаданных TBDS предприятия могут получить полную инвентаризацию активов данных Data+AI, защищая пользователей от технических различий различных компонентов структурных источников данных и внешних Обеспечьте унифицированные возможности метаданных. Особенно в структурированных данных больших данных он лучше реализует унификацию и связь метаданных хранилища озер.
03. Унификация разрешений на метаданные
Оптимизация системы Hadoop
Мы завершили управление разрешениями различных источников данных с помощью плагина унифицированных разрешений единой системы метаданных. Далее мы подробно представим нашу оптимизацию разрешений в системе Hadoop.
Базовые разрешения на данные вычислительных механизмов в системе Hadoop в основном реализуются через Ranger. Однако структура разрешений Ranger основана на дифференциации компонентов (службы), даже если разные компоненты ядра (служба) используют один и тот же элемент Hive. Для таблиц базы данных вы должны. также создайте политики разрешений и плагины Ranger с одинаковой семантикой для каждого отдельного вычислительного механизма в Ranger. Плагин Ranger будет регулярно синхронизировать полную политику компонента с локальной памятью для построения дерева политик для локальной аутентификации, а авторизация будет проходить через Ranger. Плагин передает запросы к Ranger Admin.
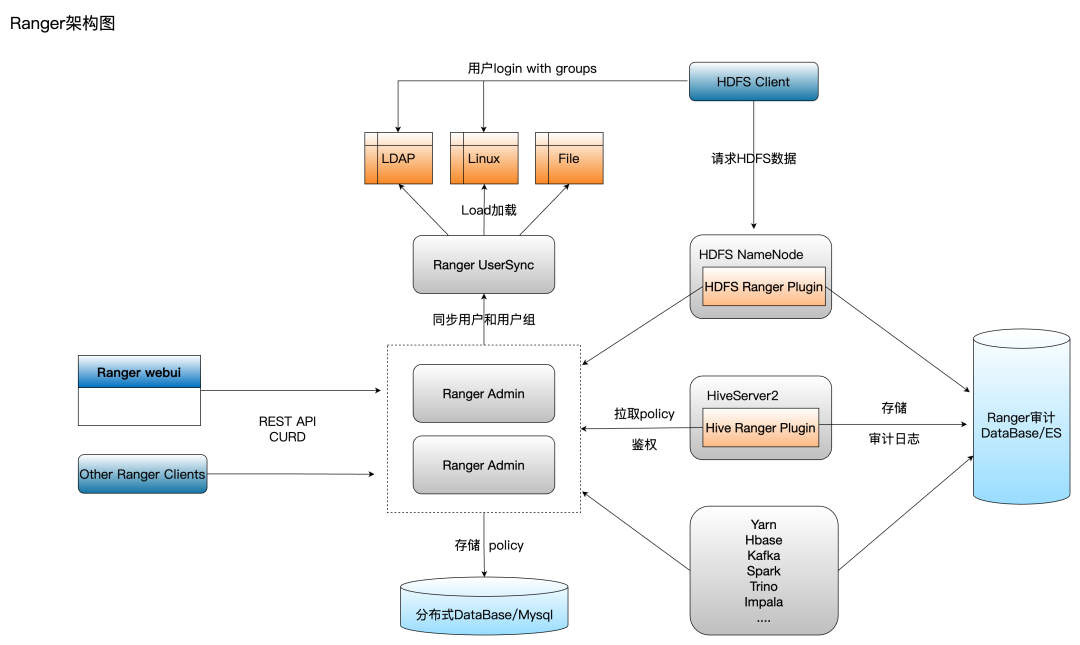
По мере увеличения количества вычислительных механизмов и количества стратегий с течением времени проблемы, возникающие из-за этой архитектуры, все больше влияют на производительность и эффективность пользователей:
[1] Пользователи будут выбирать разные вычислительные механизмы на основе различных сценариев сегментации. Вычислительные механизмы, основанные на таблицах базы данных Hive в версии TBDS, включают Hive, Spark, Trino, Impala и т. д. Необходимо использовать одну и ту же таблицу Hive, используемую в разных вычислительных механизмах. Установлено в Ranger. Создание одинаковых разрешений для таблиц библиотеки для каждого компонента увеличивает стоимость и понимание настройки разрешений для пользователей, увеличивает сложность и затрудняет управление.
[2] Поскольку количество библиотечных таблиц и стратегий продолжает увеличиваться, локальная память, занимаемая подключаемым модулем Ranger, также продолжает увеличиваться. Ценность производственного опыта TBDS заключается в том, что в случае 1 миллиона стратегий объем потребляемой памяти составляет от 10 до 20 ГБ. . В режиме кластера Spark каждое задание Spark будет иметь драйвер Spark, а каждый драйвер Spark — подключаемый модуль Spark Ranger. Когда в большом кластере параллельно выполняется большое количество пакетных заданий Spark, потребление памяти кластером очень велико только для драйвера Spark. Это не только приводит к потере большого количества вычислительных ресурсов памяти кластера. Spark Driver также склонен к OOM, что приводит к нестабильности задач.
Единые разрешения TBDS на основе метаданных
Разрешения на данные — это, по сути, описания информации управления доступом для различных ресурсов данных (файлов/путей, каталогов, баз данных, таблиц, столбцов и т. д.), поскольку ресурсы метаданных представлены общей моделью сущности в системе метаданных, описанием выражений, разрешениями. также могут использоваться как вспомогательные атрибуты ресурсов. Наше решение — внедрить новый плагин унифицированных метаданных Ranger для унификации разрешений.
Чтобы реализовать унифицированные метаданные, плагин Ranger в основном должен выполнить следующую конструкцию:
[1] Внедрить описание определения Ranger Service Def: оно включает определение ресурсов, которые имеет Сервис (например, каталог, база данных/схема, таблица, столбец, udf и т. д.), определение зависимостей между несколькими ресурсами и действия доступа к ресурсам (такие как выбор, вставка, удаление, использование и т. д.), определение информации о соединении для доступа к ресурсам и некоторая информация о конфигурации, такая как снижение чувствительности и фильтрация строк. Как упоминалось ранее, разрешения Ranger различаются по Сервису (компоненту) в первоначальном архитектурном проекте. Мы следуем дизайну Ranger, но концептуально рассматриваем унифицированные метаданные как специальный Сервис, который необходимо нести. В определении ресурса мы определяем общие ресурсы на основе объекта. модель общих метаданных каталога Hive, определяемых унифицированными метаданными. С их помощью можно описать и выразить разрешения общих ресурсов нескольких вычислительных механизмов. Однако все еще существуют некоторые ресурсы, которые не входят в определение унифицированных метаданных. Например, механизм Trino имеет свои собственные уникальные ресурсы sessionproperty и trinouser. Если эти ресурсы не определены, разрешения не будут контролироваться, когда Trino выполняет связанные операторы SQL. к этим ресурсам. Наконец, мы интегрируем уникальные ресурсы каждого движка (несколько), чтобы сформировать единое описание определения ranger-servicedef.json.
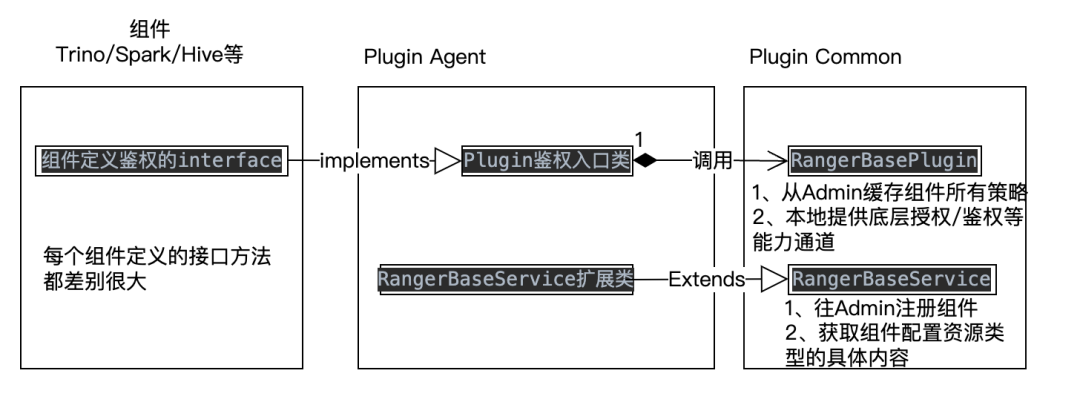
【2】Реализовать кодовую реализацию агента плагина Ranger. На следующем рисунке представлена диаграмма взаимоотношений Ranger в коде плагина. Вы можете видеть, что каждый компонент определяет свой собственный интерфейс и абстрактный метод авторизации/аутентификации для ACL управления разрешениями. Ranger реализует базовый общий универсальный канал аутентификации плагина (обеспечивает регулярную синхронизацию всех политик). из Ranger Admin в локальную память для построения древовидной структуры политики памяти и предоставления общего тела запроса RangerAccessRequest для метода аутентификации и авторизации дерева политик), плагин Часть агента играет роль связующего звена между прошлым и будущим. Для реализации конкретной логики необходимо определить интерфейсы и абстрактные методы в соответствии с компонентами агента. Конкретную логику можно резюмировать как процесс преобразования доступа к различным ресурсам. структуры, определенные различными компонентами, в RangerAccessRequest, предоставляемый Plugin Common.
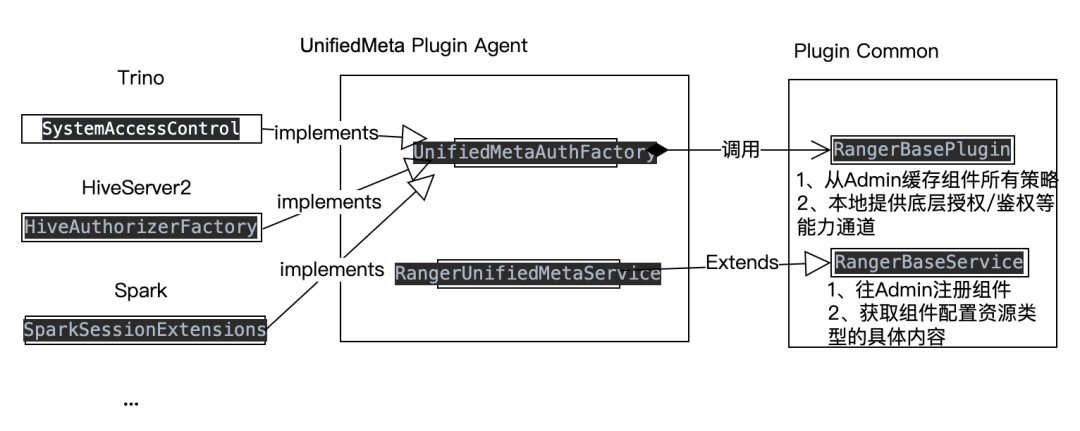
Поскольку интерфейсы и схемы абстракции, определенные каждым компонентом, сильно различаются, наша идея состоит в том, чтобы абстрагировать один и тот же общий фабричный класс UnifiedMetaAuthFactory для реализации конкретной логики самоопределяемых методов аутентификации/авторизации для всех механизмов.
Наконец, TBDS имеет унифицированные права доступа к данным, снижение чувствительности данных, фильтрацию данных и другие возможности. Все они используют одну и ту же службу Ranger. Ниже представлена страница входа и реализации в TBDS.
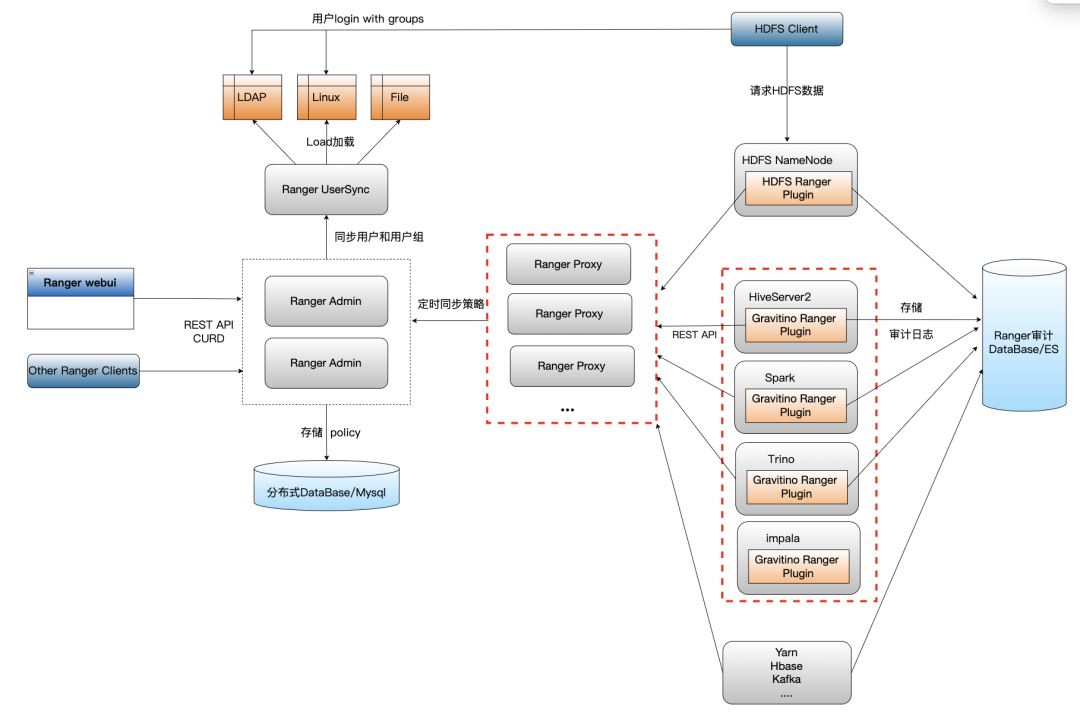
Прокси-сервер облегченного плагина Ranger TBDS
Плагин Ranger регулярно синхронизирует все политики с локальной памятью. Самым большим преимуществом является аутентификация в локальной памяти. Во время аутентификации нет необходимости обращаться к администратору Ranger. Требуемый доступ Ranger Admin меняется с триггера пользователя на триггер таймера. ., что значительно сокращает количество запросов к Ranger Admin, обеспечивая стабильность Ranger и предоставляя более высокие возможности производительности. Кроме того, даже если служба Ranger зависает, локальный плагин можно использовать в дополнение к дереву политики памяти и файлам кэша персистентности политик, обеспечивая высокую связность и низкую связанность с точки зрения надежности службы. С точки зрения Ranger, эта архитектура очень хороша, но с глобальной точки зрения выполнения заданий кластера больших данных возникают вышеупомянутые проблемы нерационального использования ресурсов и простого OOM, с которыми сталкиваются задания Spark. Однако если вы вернетесь к отправке всех запросов аутентификации в Ranger Admin, Ranger Admin также будет кэшировать политики, хранящиеся в БД, и эти кэшированные обновления будут заблокированы, поскольку существуют запросы политики записи, которые будут обновлять кеш при увеличении трафика. Конфликт блокировок будет очень серьезным. В это время производительность администратора Ranger значительно снизится, а проблема с давлением Ranger станет еще большей. Поэтому мы должны обеспечить следующие возможности:
● Давление на доступ к запросу администратора Ranger контролируется и не будет инициироваться запросами пользователей.
● Скорость локальной аутентификации компонентов ядра должна быть выше.
● Память компонентов ядра и ресурсы памяти кластерных вычислений не будут увеличиваться экспоненциально с увеличением количества заданий.
Наша идея оптимизации заключается в реализации облегченного прокси-сервиса плагина. Этот прокси-сервис предоставляет внешние интерфейсы REST API, которые точно такие же, как аутентификация/авторизация Ranger Admin. Внутренняя логика аутентификации/авторизации относится к механизму плагина Ranger и запланирована. из Ranger Admin синхронизирует все политики с локальной памятью прокси-сервера, используя файл кэша в качестве резервной копии. Служба прокси обрабатывает запросы аутентификации локально и не передается администратору Ranger. Запросы политики авторизации на запись/обновление пересылаются администратору Ranger для обработки так же, как и плагин. Таким образом, служба Proxy в основном не имеет большой бизнес-логики. Она выполняет только запланированную синхронизацию для построения дерева политики памяти и получения запросов REST для аутентификации в локальной памяти. По сравнению с Ranger Admin, который имеет множество операций блокировки с отслеживанием состояния, Proxy является очень легким. и сервис без гражданства, который можно бесконечно расширять параллельно, чтобы разделить нагрузку.
В плагине Ranger мы переключаемся на перехват всей локальной логики, связанной с аутентификацией, и отправляем запрос аутентификации в прокси-службу через сетевой HTTP.
Поскольку логика прокси-службы проста и обеспечивается локальная аутентификация, скорость ответа обратного пакета в плагин также очень высока. В то же время производительность прокси-службы очень высока и может быть расширена для решения проблемы давления доступа. вызвано большим количеством пользовательских SQL-запросов. Плагин компонента больше не кэширует весь объем в локальной памяти. Стратегия также решает проблемы, вызванные ростом памяти. Ниже приведена окончательная схема архитектуры унифицированных разрешений Ranger.
Кроме того, мы В Рейнджере также были сделаны некоторые другие оптимизации производительности.,Доведите производительность TBDS Ranger до предела. После производственной статистики и многочисленных испытаний под давлением,существоватьБолее миллионаВ случае стратегии,500 в секундуСтратегия чтения и записи одновременных запросов,RangerСреднее время ответа на запросы политики чтения составляет500msо,Писать/Среднее время ответа на запросы политики обновления составляет1200msо,Интервал времени, в течение которого плагин/прокси-сервер синхронизируется с последней политикой:
● Оптимизировать механизм транзакций в стратегии записи Ranger Admin после завершения.
● Плагин/прокси-сервер Ranger синхронизирует полную политику записи логики файла локального кэша и меняет синхронную запись на асинхронную запись.
● Ranger Admin обновляет степень детализации блокировок кэша и разбивает некоторую логику на небольшие блокировки.
● Некоторые структуры данных в дереве политики памяти были изменены со списка на набор, что значительно сокращает временную сложность поиска.
После тестирования примерно в 3–5 раз быстрее, чем последняя стабильная версия Ranger 2.5, представленная в сообществе. Другие важные оптимизации включают в себя:
04. Резюме
Система метаданных нового поколения TBDS прорывает остров данных с помощью новой системы метаданных,Внедрение объединенных вычислений с помощью нескольких вычислительных механизмов.,Издержки бизнеса значительно снизились. А в озере данных сценарии ИИ реализуют унификацию метаданных и автоматическое управление данными.,Обеспечивая интеллектуальный и эффективный доступ к данным, он также предоставляет унифицированные возможности безопасности «Разрешения», основанные на глубокой разработке и оптимизации Ranger.,Сделайте данные более разумными, контролируемыми и простыми в использовании. В будущем мы будем выполнять больше функций, чтобы унифицировать родословную данных юаней и поддерживать больше вычислений в механизме вычислений, а также объединить большие данные со сценариями искусственного интеллекта.,позволятьданныеи вычислительная мощностьУмнее, эффективнее и более взаимосвязаны.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
