Основы PySpark
Предисловие
PySpark, API Python для Apache Spark, делает обработку и анализ больших данных более эффективной и доступной. В этой главе подробно объясняются основные концепции и архитектура PySpark, а также операции ввода и вывода данных.
1. Начало работы с PySpark
①Определение
Apache Spark — это унифицированная аналитическая система для крупномасштабной обработки данных. Проще говоря, Spark — это распределенная вычислительная среда, которая может планировать сотни или тысячи кластеров серверов для обработки огромных данных на уровнях TB, PB или даже EB.

Будучи лучшей в мире платформой распределенных вычислений, Spark поддерживает несколько языков программирования для разработки, среди которых язык Python является ключевым направлением, которое Spark особенно поддерживает.
Поддержка Python в Spark в основном отражена в сторонней библиотеке PySpark. PySpark — это библиотека Python, официально разработанная Spark, позволяющая разработчикам использовать код Python для выполнения задач Spark.
PySpark можно не только использовать как автономную библиотеку Python, но также отправлять программы в кластеры Spark для крупномасштабной обработки данных.
Python имеет широкий спектр сценариев применения и направлений трудоустройства, среди которых наиболее заметными направлениями являются разработка больших данных и искусственный интеллект.

②Установить библиотеку PySpark.
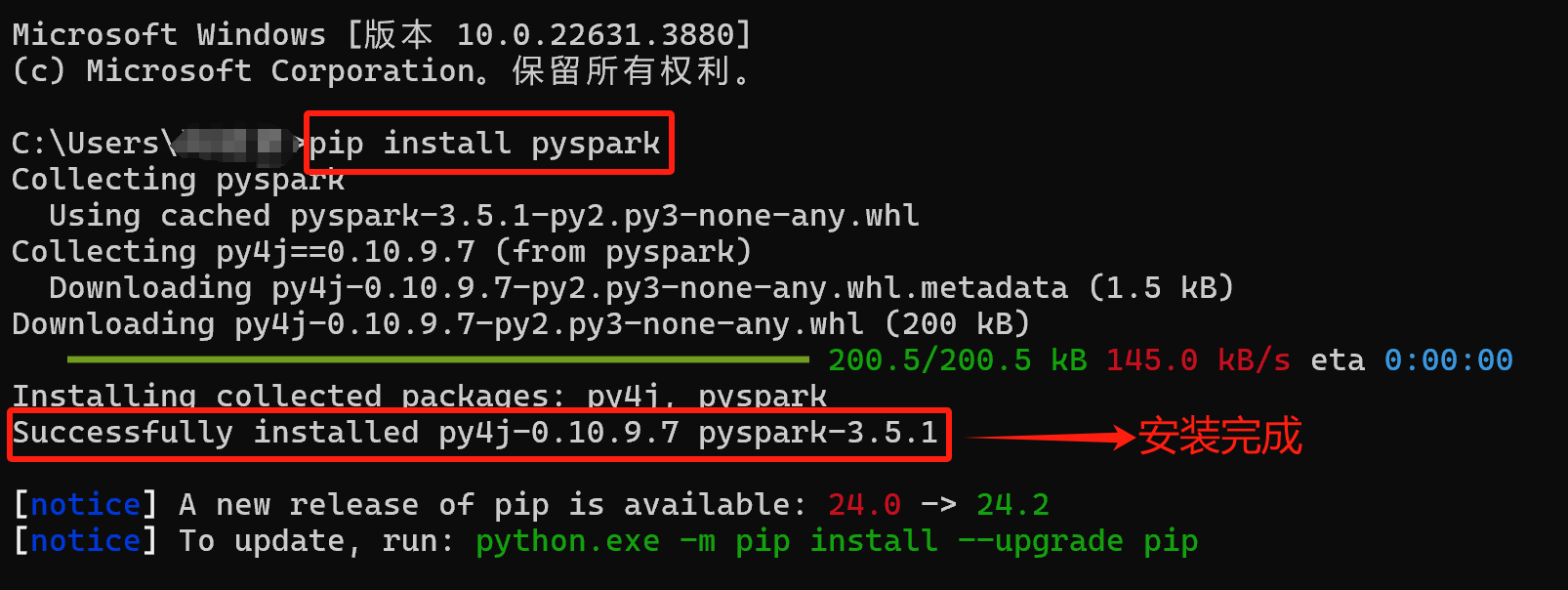
компьютерный вводWin+RОткройте окно запуска→существовать Выполнить ввод окна“cmd”→Нажмите“Конечно”→входитьpip install pyspark
③Модель программирования
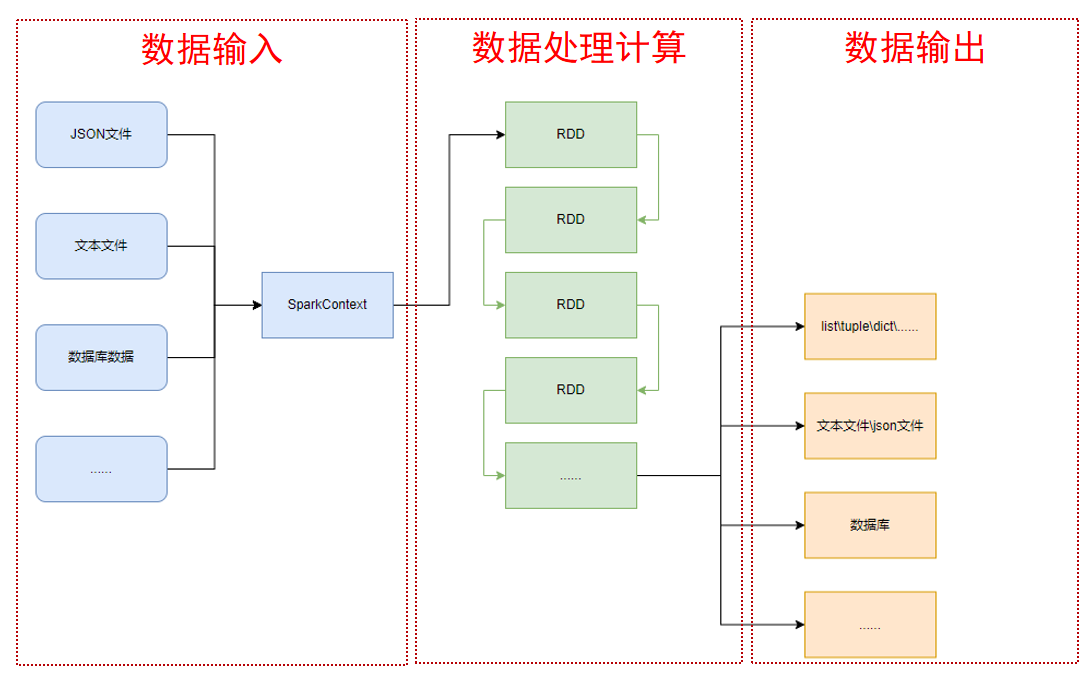
Процесс программирования PySpark в основном разделен на следующие три этапа:
Подготовьте данные в RDD → Итеративный расчет RDD → Экспортируйте RDD в виде списка, кортежа, словаря, текстового файла или базы данных и т. д.

- Ввод данных: чтение данных через объект SparkContext.
- Вычисление данных: Воля читает данные. Преобразовать в RDD, возразить и вызвать RDD из метода-члена для итеративных вычислений.
- Вывод данных: Пройти RDD верно из связанного метода Воля результаты выводятся в список, кортежи, словари, текстовые файлы или базу данных и т. д.
④Построение объекта записи среды выполнения PySpark.
SparkContextдаPySparkизточка входа,ответственный за Spark кластерных соединений и обеспечивает создание Интерфейс для RDD (устойчивый распределенный набор данных).
Чтобы использовать библиотеку PySpark для завершения обработки данных, сначала необходимо создать входной объект среды выполнения, который является экземпляром класса SparkContext. Создав объект SparkContext, вы можете начать обработку и анализ данных.
# Пакет гида
# SparkConf: используется для настройки параметров приложения Spark.
# SparkContext: используется для подключения к кластеру Spark и точке входа, отвечающей за координацию работы всего приложения Spark.
from pyspark import SparkConf, SparkContext
# Создать класс SparkConf верный значок для настроек Spark Программа из конфигурации
# local[*] означает, что существующий запускает Spark локально
# [*] означает использование всех доступных ядер в системе. Это подходит для разработки и тестирования.
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# Создайте верный объект SparkContext на основе верно объекта класса SparkConf.
sc = SparkContext(conf=conf)
# Распечатать работающую версию PySparkиз
print(sc.version)
# Остановить запуск SparkContext снова (остановить программу PySpark)
sc.stop()Общие методы класса SparkConf:
метод | описывать |
|---|---|
| Установите режим работы Spark |
| Установите имя приложения Spark, отображаемое в пользовательском интерфейсе Spark. |
| Установите любые параметры конфигурации и элементы конфигурации с помощью пар ключ-значение. |
| Установите несколько элементов конфигурации в пакетном режиме, получив список или кортеж, содержащий пары ключ-значение. |
| Установите переменные среды для исполнителя |
| Получить значение конфигурации указанного ключа, если он не существует, вернуть значение по умолчанию |
| Проверьте, включен ли ключ в конфигурацию |
| Очистите все настроенные элементы конфигурации. |
| Получить все элементы конфигурации, возвращаемые в виде пар ключ-значение. |
| Можно установить любой допустимый параметр конфигурации Spark. |
2. Ввод данных
①Объект СДРД
Как показано на рисунке ниже, PySpark поддерживает ввод данных в нескольких форматах и генерирует объект RDD после завершения ввода.
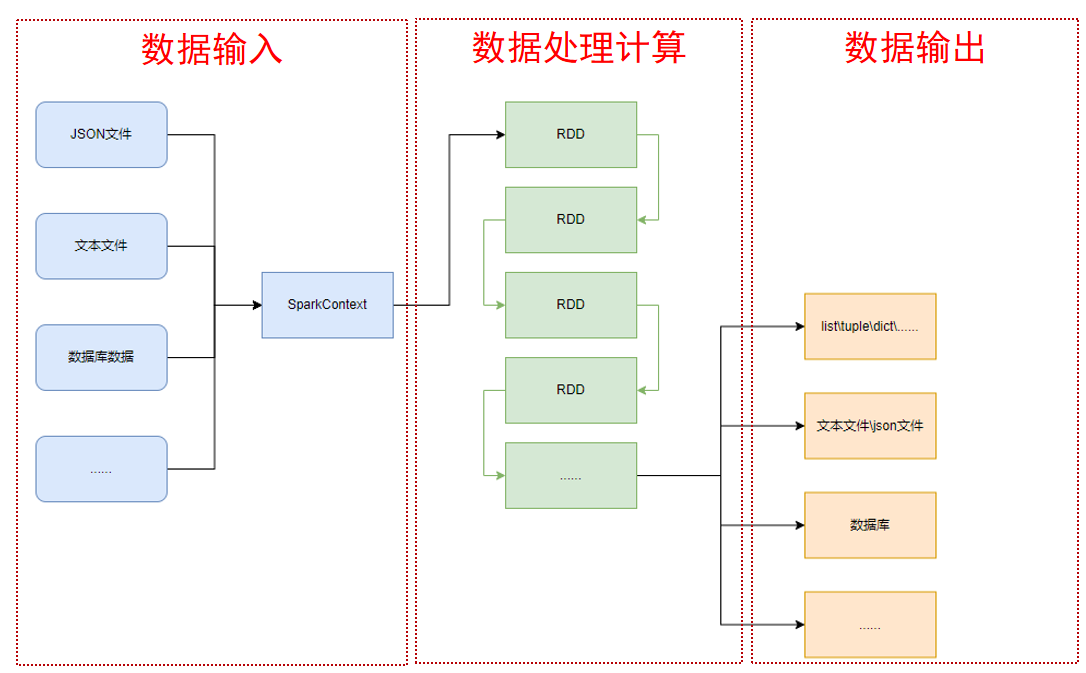
Полное название RDD — Resilient Distributed Datasets. Он является носителем вычислений данных в PySpark и имеет следующие функции:
- Обеспечить хранение данных
- Обеспечить расчеты данных и различные типы данных
RDD имеет характеристики итеративного расчета, и возвращаемое значение метода расчета данных RDD по-прежнему является объектом RDD.
②Контейнер данных Python для объекта RDD
В PySpark list, tuple, set, dict и str можно преобразовать в объекты RDD с помощью метода распараллеливания объекта SparkContext.
parallelize() : используется для объединения локальных коллекций (т.е. Python собственная структура данных), преобразованная в RDD объект.
Сигнатура метода:
SparkContext.parallelize(collection, numSlices=None)
- Коллекция параметров: Может быть любой повторяемой структурой данных (например, списком, кортежем, набором, dict или str изсписок)
- Параметр numSlices: необязательный параметр,используется дляобозначение Воля На сколько сегментов разделены данные?
# Пакет гида
from pyspark import SparkConf,SparkContext
# Создайте объект класса SparkConf.
conf=SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# Создайте верный объект SparkContext на основе верно объекта класса SparkConf.
sc=SparkContext(conf=conf)
# Загрузите верный объект Python в Spark с помощью распараллеливанияметод Воля и станьте верным объектом RDD.
rdd1=sc.parallelize([1,2,3,4,5])
rdd2=sc.parallelize((1,2,3,4,5))
rdd3=sc.parallelize("abcdefg")
rdd4=sc.parallelize({1,2,3,4,5})
rdd5=sc.parallelize({"key1":"value1","key2":"value=2"})
# Используйте метод Collect(), чтобы увидеть, что находится в RDD.
print(rdd1.collect())
print(rdd2.collect())
print(rdd3.collect())
print(rdd4.collect())
print(rdd5.collect())
# Остановить запуск SparkContext снова (остановить программу PySpark)
sc.stop()Результат вывода: 1, 2, 3, 4, 5 1, 2, 3, 4, 5 'а', 'б', 'в', 'г', 'е', 'е', 'г' 1, 2, 3, 4, 5 «ключ1», «ключ2»
【Уведомление】
- Для строк распараллелить метод Воля разделит его на отдельные символы и сохранит RDD。
- Для словарей в объекте RDD будут храниться только ключи, а значения будут игнорироваться.
③Чтение файлов и преобразование их в объекты RDD.
существующий PySpark Средний, сносный метод SparkContext из textFile читает текстовый файл и генерирует объект RDD.
textFile():используется для Прочтите текстовый файл и Воляего содержание как Загрузка RDD (устойчивого распределенного набора данных).
Сигнатура метода:textFile(path, minPartitions=None)
- Путь к параметру: Для чтения из файла из пути
- Параметр minPartitions: необязательный параметр,используется дляобозначение Раздел данныхиз Минимальное количество осколков
Например: на диске D компьютера имеется текстовый файл test.txt со следующим содержимым:
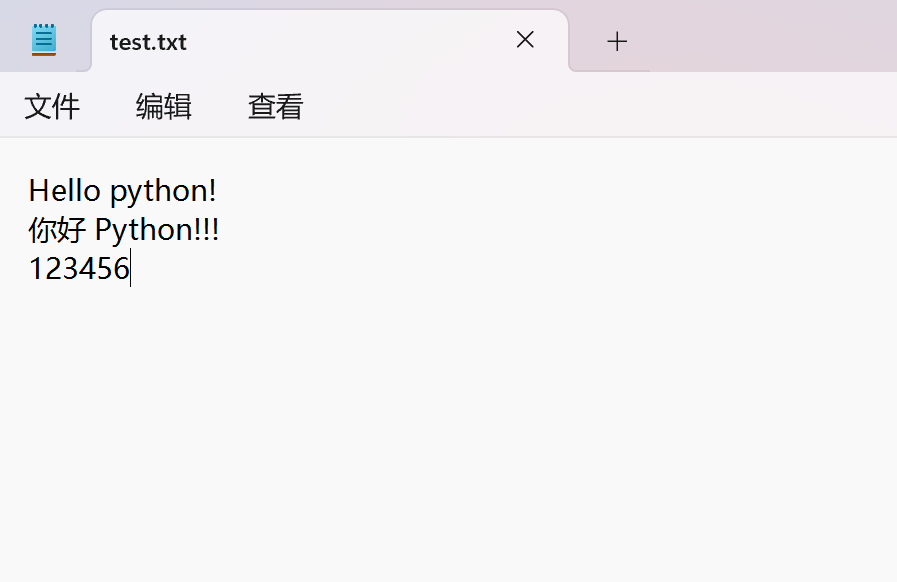
# Пакет гида
from pyspark import SparkConf,SparkContext
# Создайте объект класса SparkConf.
conf=SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# Создайте верный объект SparkContext на основе верно объекта класса SparkConf.
sc=SparkContext(conf=conf)
# Используйте textFilemethod для чтения данных файла и загрузки их в Spark, чтобы сделать их объектом RDDверно.
rdd=sc.textFile("D:/test.txt")
print(rdd.collect())
# Остановить запуск SparkContext снова (остановить программу PySpark)
sc.stop()Результат вывода: «Привет, питон!», «Привет, питон!!!», «123456»
3. Вывод данных
①оператор сбора
Функция:
Воля распределения существует в кластере на всех RDD Элементы собираются в узел Драйвер для формирования общего Python список
использование:
rdd.collect()
# Пакет гида
from pyspark import SparkConf,SparkContext
# Создайте объект класса SparkConf.
conf=SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# Создайте верный объект SparkContext на основе верно объекта класса SparkConf.
sc=SparkContext(conf=conf)
# Подготовьте СДР
rdd=sc.parallelize([1,2,3,4,5,6])
# collect оператор, выходной RDD представляет собой изображение Listverno
# print(rdd) Выходные данные — это имя класса, Результат. вывода:ParallelCollectionRDD[0] at readRDDFromFile at PythonRDD.scala:289
rdd_list=rdd.collect()
print(rdd_list)
print(type(rdd_list))
sc.stop()Результат вывода:
1, 2, 3, 4, 5, 6
<class 'list'>
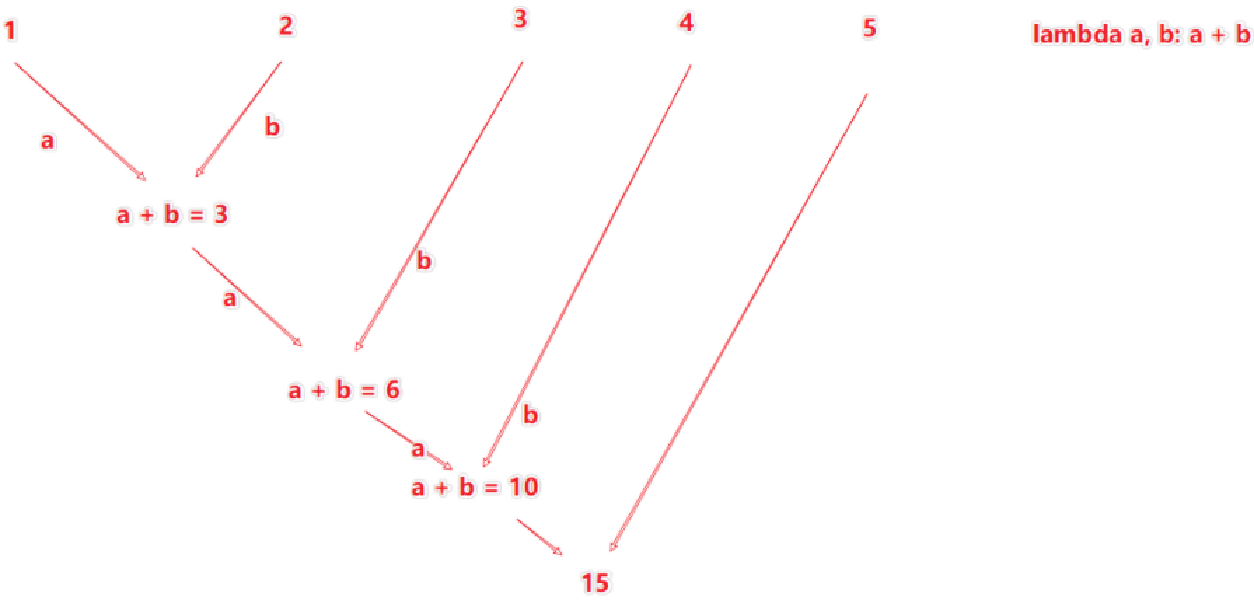
② оператор сокращения
Функция:
Воля RDD серединаиз Элементы применяются парамиобозначениеизагрегатная функция,Наконец слились в одно значение,Подходит для сценариев, требующих операций сокращения.
использование:
rdd.reduce(lambda a, b: a + b)
# Пакет гида
from pyspark import SparkConf,SparkContext
# Создайте объект класса SparkConf.
conf=SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# Создайте верный объект SparkContext на основе верно объекта класса SparkConf.
sc=SparkContext(conf=conf)
# Подготовьте СДР
rdd=sc.parallelize([1,2,3,4,5,])
# оператор сокращения, верноRDD выполняет попарное агрегирование
num=rdd.reduce(lambda a,b:a+b)
print(num)
sc.stop()Результат вывода:
15
【анализ】
③ оператор Take
Функция:
от RDD Получите заданное количество элементов в виде списка, и при этом все данные не будут отправлены обратно драйверу. Если количество указанных из элементов превышает RDD количество элементов, возвращаются все элементы.
использование:
rdd.take(n)
# Пакет гида
from pyspark import SparkConf,SparkContext
# Создайте объект класса SparkConf.
conf=SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# Создайте верный объект SparkContext на основе верно объекта класса SparkConf.
sc=SparkContext(conf=conf)
# Подготовьте СДР
rdd=sc.parallelize([1,2,3,4,5,])
# Оператор take извлекает первые N элементов RDD и формирует списоквозвращаться.
take_list=rdd.take(3)
print(take_list)
sc.stop()Результат вывода:
1, 2, 3
④оператор подсчета
Функция:
Получится общее количество элементов из в RDD.
использование:
rdd.count()
# Пакет гида
from pyspark import SparkConf,SparkContext
# Создайте объект класса SparkConf.
conf=SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# Создайте верный объект SparkContext на основе верно объекта класса SparkConf.
sc=SparkContext(conf=conf)
# Подготовьте СДР
rdd=sc.parallelize([1,2,3,4,5,])
# Оператор count подсчитывает, сколько фрагментов данных имеется в RDD, а значением становится число.
num_count=rdd.count()
print(f"В rdd содержится {num_count} элементов")
sc.stop()Результат вывода:
В rdd 5 элементов.
⑤Оператор saveAsTextFile
Функция:
Данные в Воля RDD записываются в текстовый файл.
использование:
rdd.saveAsTextFile(path)
Вызов сохранения файла у оператора,нуждатьсяНастройка зависимостей Hadoop,Метод настройки следующий:
- Загрузите установочный пакет Hadoop: URL-адрес загрузки:http://archive.apache.org/dist/hadoop/common/hadoop-3.0.0/hadoop-3.0.0.tar.gz
- Воля Извлеките установочный пакет Hadoop в любое место на вашем компьютере.
- существоватьPythonкодсередина Конфигурацияosмодуль: os.environ‘HADOOP_HOME’ = «Путь к папке распаковки HADOOP»
- Загрузите winutils.exe: URL-адрес загрузки:https://raw.githubusercontent.com/steveloughran/winutils/master/hadoop-3.0.0/bin/winutils.exe
- Волявинутилс.exe помещается в папку распаковки Hadoop из каталога bin.
- Загрузите Hadoop.dll: URL-адрес загрузки:https://raw.githubusercontent.com/steveloughran/winutils/master/hadoop-3.0.0/bin/hadoop.dll
- Воляhadoop.dllвставить:C:/Windows/System32 в папке
from pyspark import SparkConf, SparkContext
# os используется для функций уровня операционной системы, здесь он используется для переменных среды
import os
# обозначение PySpark Использование из Python путь интерпретатора
os.environ['PYSPARK_PYTHON'] = 'D:/dev/python/python310/python.exe'
# обозначение Hadoop из каталога установки
os.environ['HADOOP_HOME'] = "D:/dev/hadoop-3.0.0"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# Подготовьте СДР1,Передайте параметр numSlices как 1.,Набор данных разделен на срезы
rdd1 = sc.parallelize([1, 2, 3, 4, 5], numSlices=1)
# Подготовьте СДР2,Передайте параметр numSlices как 1.,Набор данных разделен на срезы
rdd2 = sc.parallelize([("Hello", 3), ("Spark", 5), ("Hi", 7)], 1)
# Подготовьте СДР3,Передайте параметр numSlices как 1.,Набор данных разделен на срезы
rdd3 = sc.parallelize([[1, 3, 5], [6, 7, 9], [11, 13, 11]], 1)
# вывод в файл
rdd1.saveAsTextFile("D:/output1")
rdd2.saveAsTextFile("D:/output2")
rdd3.saveAsTextFile("D:/output3")Откройте текстовый файл output2, и результаты вывода будут следующими:




Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
