Основы компьютера | Наборы символов, ASCII, GBK, UTF-8, Unicode, искаженные символы и проблемы с кодировкой символов, которые можно понять с первого взгляда
Обзор
При общении или при использовании потоков ввода-вывода для чтения и записи данных у меня всегда кружится голова. После долгой работы с компьютером вы неизбежно увидите искаженные символы в стиле «призрачных символов», что сбивает людей с толку и особенно раздражает.
В этой статье мы расскажем, почему возникают искаженные символы, а также о взаимосвязи между байтами, символами, наборами символов и кодировками.
Почему появляются искаженные символы?
Основные причины искажения символов следующие:
- несоответствие набора символов:Искаженные Наиболее распространенной причиной появления символов является несовпадение набора символов. Искаженные возникают, когда набор символов, используемый текстом, не соответствует набору символов, используемому программой, которая отображает или обрабатывает текст. символы. Например, если в тексте используется набор символов UTF-8, но программа использует набор символов GBK для анализа текста, результатом будет Искаженные. символы。

Подробную информацию о причинах Кун Джин Као смотрите в конце статьи.
- Ошибка кодирования:Во время передачи или обработки текста,Если текст закодирован неправильно,Также вызывает Искаженные символы. Например, если текст, закодированный в UTF-8, ошибочно анализируется в кодировке GBK, появится «Искаженные». символы. Это как курица разговаривает с уткой.
Путаница, вызванная разными «наборами символов» для кодирования и декодирования, аналогична следующей:
- Мячи для настольного тенниса распроданы (товар ракетки для настольного тенниса распродан/мячи для настольного тенниса распроданы на аукционе)
- Я хочу вареные яйца (я хочу вареные яйца/я хочу вареные яйца)
- Страна А уже готова атаковать страну Б (страна А готова атаковать страну Б/страна А готова ответить на атаку Б)
- Его дядя раньше был учителем математики в хорошей средней школе в Шанхае (его дядя раньше был учителем, но, возможно, не сейчас, его дядя - учитель)
- Собака охотника закусала его до смерти (охотник был закусан до смерти/собака была закушена до смерти)
- Премьер-министр, который любит людей (премьер-министр, который любит людей/мы все любим премьер-министра, который любит людей)
- Этот год очень невезучий, и свиньи большие, как мыши, и чистые как мертвые (Этот год хороший, и мало невезучих, и никаких судебных исков. Свиньи большие, а они как слоны. и мыши дохли. / Этот год такой неудачный, и исков мало, и свиньи большие, как мыши, чистые.)
- Дайте мне номер заказа для проверки (если номер заказа является нечетным/проверьте номер заказа)
- Он поднялся на гору? (Вы когда-нибудь поднимались на эту гору/Вы когда-нибудь поднимались на гору)
- Ему есть что рассказать бесконечные истории (он знает так много историй/о нем можно рассказать бесконечные истории)
- Собака убила охотника (Собака убила охотника/Собака охотника была убита)

- Отсутствует сопоставление персонажей:некоторыйхарактер В наборе может не быть каких-то особенныххарактерили кандзи,Когда эти персонажи появляются в тексте,Если нет правильного сопоставления характеров,приведет к Искаженные символы。

- Ошибка формата текста:Если сам текст имеет ошибки форматирования,Например, отсутствуют необходимые идентификаторы кодировки или экранирование характера.,Также вызывает Искаженные символы。
- Ошибка обработки программы:некоторый Программы могут существовать при обработке текстаbugили ошибка,что приводит к ошибкам синтаксического анализа текста,таким образом производя Искаженные символы。
Чтобы избежать искажения символов, необходимо убедиться, что набор символов текста соответствует набору символов, используемому программой, а метод кодирования должен быть правильно обработан во время передачи или обработки текста. Кроме того, вам также необходимо обратить внимание на правильный формат текста и корректность работы программы.
Зачем кодировать?
Символы должны быть закодированы, прежде чем они смогут быть обработаны компьютерами. Все данные в компьютере при хранении и использовании должны быть представлены в виде двоичных чисел.
Не знаю, задумывались ли вы когда-нибудь о проблеме индивидуальности, то есть Цели. кодировать? Можем ли мы не кодировать? Чтобы ответить на этот вопрос, мы должны вернуться к тому, как компьютеры представляют символы, которые мы, люди, можем понять. Эти символы также являются языками, которые мы, люди, используем. Компьютеры могут обрабатывать только двоичные данные, и для обработки им необходимо преобразовывать текст или символы в двоичную форму. Потому что существует слишком много человеческих языков, слишком много символов для представления этих языков, и невозможно использовать базовую единицу хранения данных в компьютерах. Представлен байт, поэтому его необходимо разделить или выполнить некоторую работу по «трансляции/преобразованию», прежде чем компьютер сможет его понять. В настоящее время в компьютерной области широко используется двоичный язык, содержащий только 0 и 1, который может представлять и хранить только двоичные данные. Любой другой язык, который можно использовать в компьютерах, должен пройти через «перевод/преобразование» и «перевод/преобразование». это в комбинацию 0 и 1. Этот процесс «перевода/преобразования» является кодированием. Кодирование позволяет передавать и хранить текст или символы в компьютерной системе.
В целом причины кодирования можно резюмировать следующим образом:
- Наименьшая единица информации, хранящаяся в компьютере, — это байт/байт. 8 индивидуальный бит, поэтому диапазон характеров, которые могут быть выражены, равен 0~255 индивидуальный
- Что люди хотят выразитьсимволслишком,Его нельзя полностью представить одним байтом/байтом.
- Чтобы решить эту проблемуиндивидуальный Противоречивому компьютеру нужениндивидуальныйновые структуры данных char, чтобы добиться от char приезжать Преобразование байтов должно быть закодировано
Как кодируются символы?
Кодирование: Процесс преобразования информации из одной формы или формата в другую. Декодирование: это обратный процесс кодирования. Это как искать это в словаре.
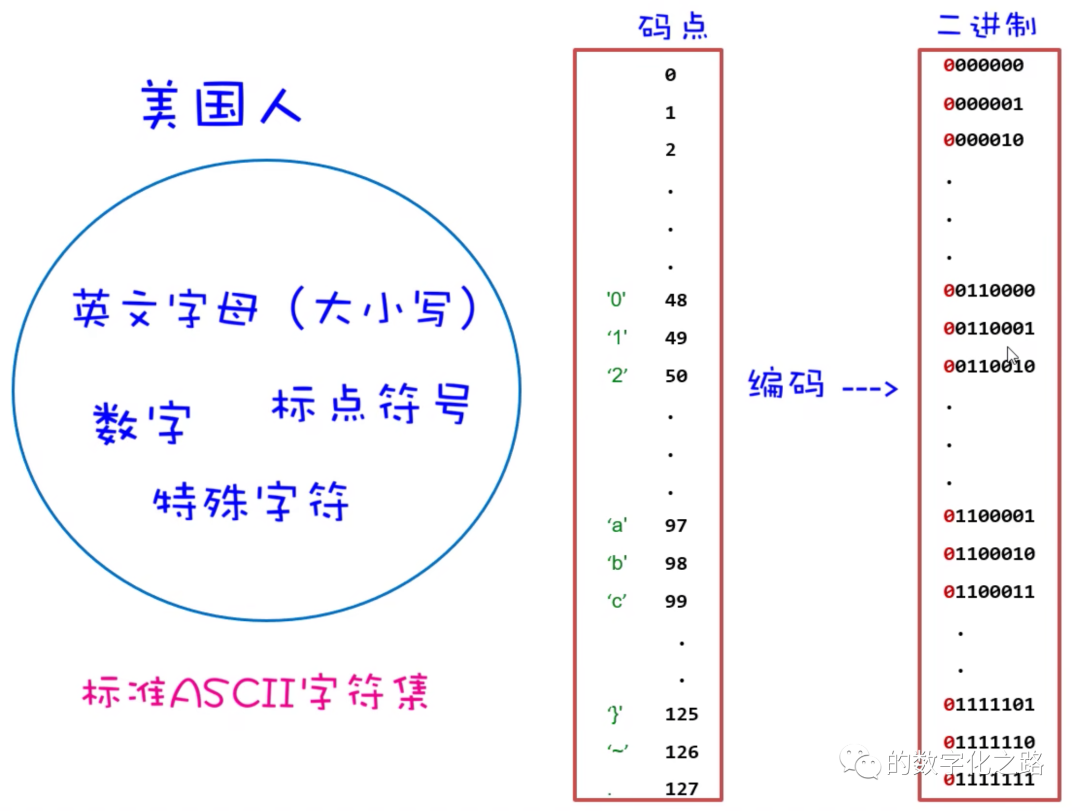
Возьмите набор символов ASCII в качестве примера, чтобы поговорить о том, как кодируются символы:
Пояснение терминов на изображении выше:
характер
характер(Character)Относится к словам, используемым людьми илисимволобщее имя,Включая символы, графические символы, математические символы, буквы, арифметические символы, знаки препинания и другие символы.,и некоторые функциональные символы. Может быть представлен одним или несколькими байтами. Вообще говоря, мы называем характером в определенном множестве,называетсяxxхарактер,Например, ASCII-характер в наборе ASCII-характер.,GB2312символ наборвнутриGB2312характер。
характернабор
характернабор(Character Set, Charset), сборник характеров. Каждый индивидуальныйхарактер имеет уникальное кодовое значение (кодовую точку) в наборе индивидуального характера. Набор символов часто соответствует определенному языковому символу. Все символы или большая часть часто используемых символов составляют набор символов текста, например, набор символов английского языка. Группа характеров с общими характеристиками также может образовывать набор характеров, например набор характеров традиционных китайских иероглифов и набор характеров японских кандзи. Подмножество набора характеров также является набором характеров. Набор характеров обычно используется для обозначения диапазона индивидуумов. Содержащих эти свойства достаточно для ежедневного использования.
общийхарактернабор:ASCIIхарактернабор、GB2312символ набор、BIG5персонаж набор、GBKхарактернабор、GB18030персонажнабор、набор символов Unicode и многое другое.
кодовая точка
В терминологии характерного кодирования его также называют кодовой точкой (Code Точка), составленная кодовой точканабор,это одининдивидуальныйхарактернабортаблица кодированиядля каждогоиндивидуальныйхарактер Назначьте одининдивидуальныйтолькочислоID。 Например, код ASCII содержит 128индивидуальнуюкодовую. точка, диапазон 016, база приезжать7F16, расширенный код ASCII включает 256индивидуальнуюкодовую точка, диапазон — 016, база приезжать FF16, а Unicode содержит 1 114 112индивидуальную кодовую точка, диапазон 016, база приезжать10FFFF16, база.
Одна и та же кодовая точка не обязательно отображается на один и тот же характер в разных наборах символов. Это также является прямой причиной обращения символов.
характеркодирование
код характера(Персонаж Кодировка) определяет, должен ли каждый индивидуальный «характер» использовать один индивидуальный байт или несколько индивидуальных символов. Секция хранения, байты которой используются для хранения, — это правило преобразования/трансляции характера в наборе характеров в определенный объект в указанной коллекции определенным образом. Благодаря этой кодировке внешние программы могут вызывать указанный характер из файла набора символов. В наших обычных компьютерных файлах шрифтов используется кодировка набора символов. При вводе текста с помощью метода ввода или просмотре веб-страниц характер будет вызываться из файла шрифта с использованием указанной кодировки набора символов. Например, характер кодируется как шаблон битовой строки, состоящий из двух отдельных цифр 0–1 и индивидуальных цифр 0–9. Последовательность натуральных чисел или электрических импульсов и т. д., то есть процесс установления соответствующей связи (т. е. отношения отображения) между набором характеров и заданным набором. Это базовая технология обработки информации. Общие примеры включают кодирование латинского алфавита в код Морзе и код ASCII.

Сборка символов влияет на кодирование символов. Например, существует более 80 000 китайских иероглифов.,Определенно нельзя использовать однобайтовую кодировку ASCII.,Потому что ASCII может выразить слишком мало характера,Я не могу уместить столько китайских иероглифов.
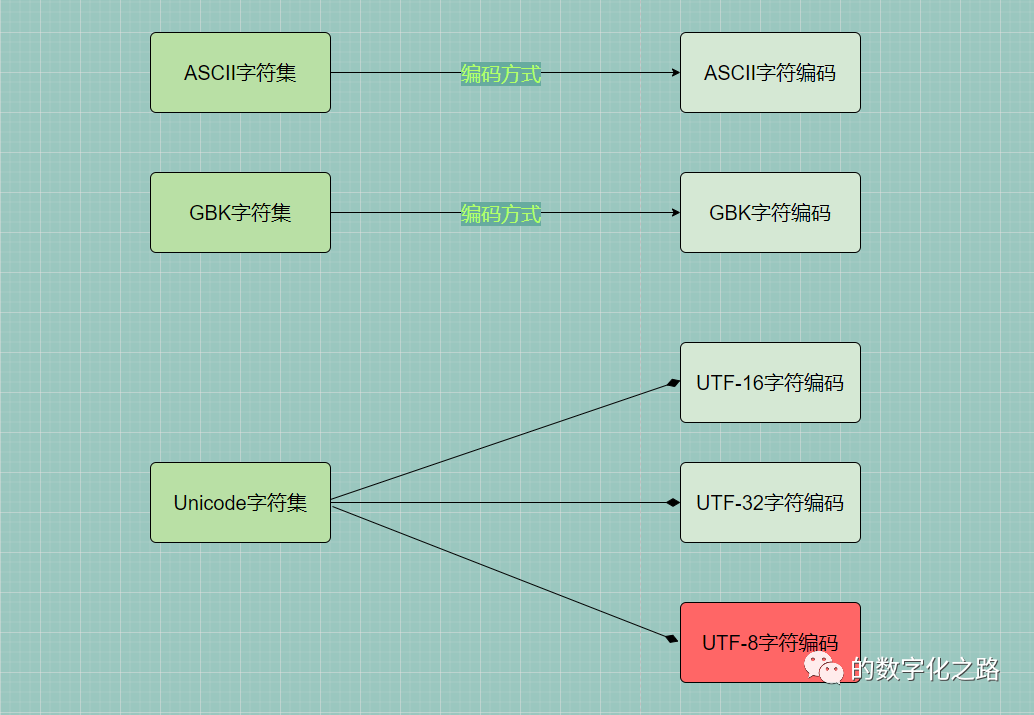
Когда различные страны и регионы формулируют стандарты кодирования, «набор символов» и «кодирование» обычно формулируются одновременно.
кусочек:Также известен как“Кусочек”,Самая маленькая единица хранения данных в компьютере.,да binary Аббревиатура цифры (двоичная цифра), обозначающая одну цифру в двоичной системе.
Байты (октет/байт):измерение информации в компьютераходин Список семян Кусочек,Одна цифра представляет «0» или «1».,Каждый8индивидуальный Кусочек(bit)сформировать одининдивидуальный Байты (октет/байт)。
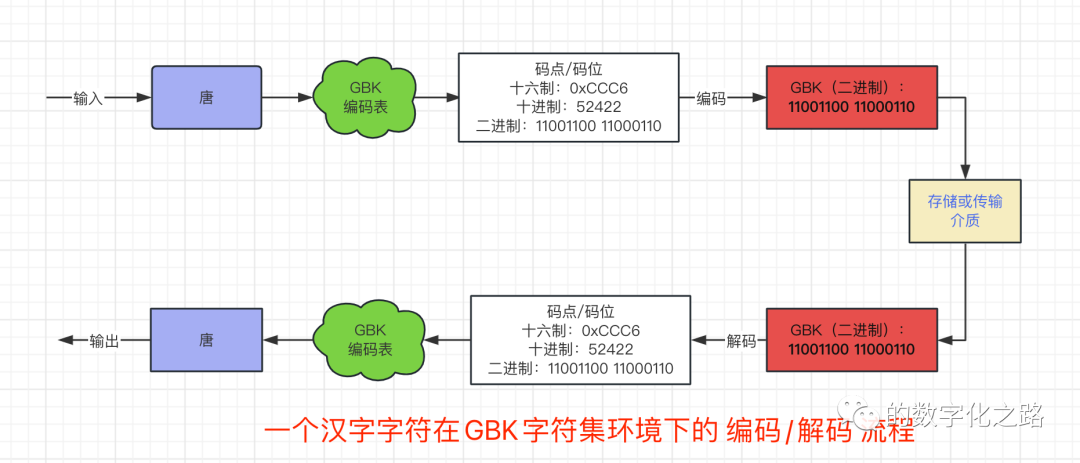
GBKодининдивидуальныйкитайскийхарактеркодированиебуду использовать дваиндивидуальныйхранение в байтовом формате Положение ГБК: Первая цифра первого байта китайского иероглифа должна быть 1
Зачем нужна коллекция персонажей?
Чтобы слова или символы разных стран или этнических групп могли храниться и отображаться на компьютере, компьютер сначала должен уметь их понимать. Существует слишком много символов, которые люди хотят выразить. Если вы хотите, чтобы компьютер понимал все символы, это слишком большая и ненужная нагрузка. Когда он был первоначально разработан, кто знал, что компьютеры станут настолько популярными? Например, если вы хотите прочитать книгу на английском языке, следует ли вам вместе выучить японский язык, а затем прочитать книгу на английском языке? С точки зрения управления проектами этот подход «позолочен», а с точки зрения начальника он называется «снять штаны и пукнуть», ведь достаточно просто выучить английский.
При поставке системы исследователям нужно только убедиться, что компьютер может понимать и выражать характер в определенном диапазоне. Набор характеров в этом индивидуальном диапазоне и есть набор характеров.
Почему так много характерных серий? Разве не было бы достаточно сделать что-то вроде индивидуального?
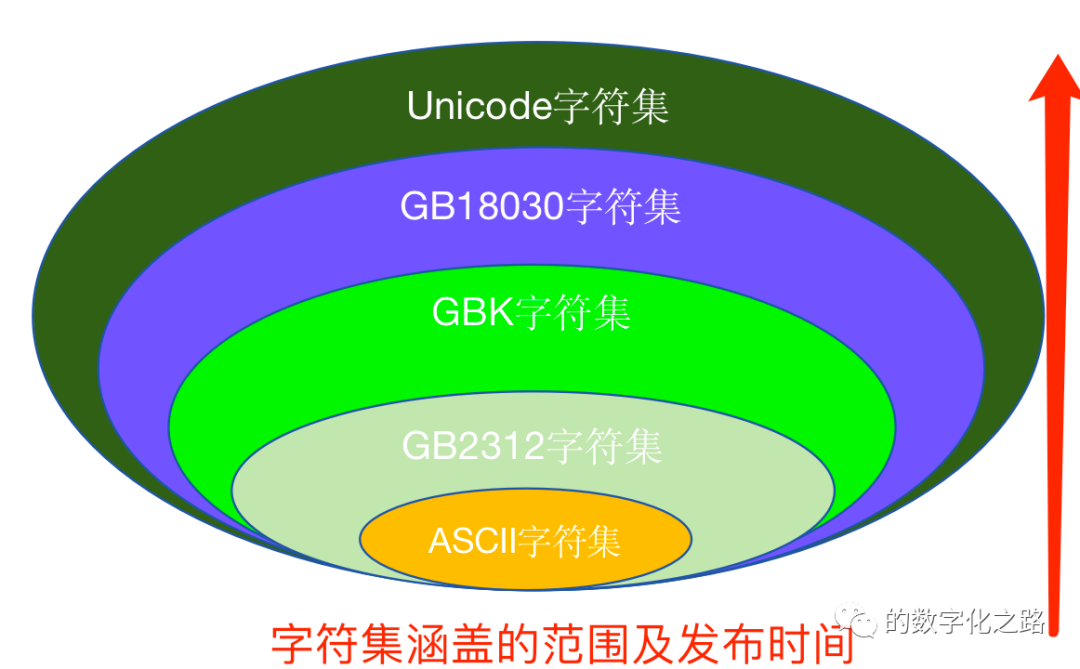
За формулирование наборов характеров приходится платить, и существуют исторические причины, по которым существует так много наборов характеров. Текущий универсальный код(Unicodeкодированиестандартный)Уже содержит весь текст в мире、символ、число、Пунктуация и др. характер.
Давайте посмотрим, почему в процессе рождения существует так много разных наборов характеров:
Если бы компьютерами пользовались только американцы, проблем не было бы.
Но позже, когда некоторые европейские страны также начали использовать компьютеры,Например, Франция и Германия. они найдут,Характер нашей страны не входит в число ваших индивидуальных характеров.

Таким образом, Франция и Германия расширили свою деятельность на основе исходного кода ASCII. Исходный первый 0 был изменен на 1, то есть приезжать был расширен со 128индивидуальныйхарактер до 256индивидуальныйхарактер, то есть добавлено 128индивидуальный. Набор символов, который включает в себя новые 128 индивидуальных символов на основе набора символов ASCII, называется расширенным набором символов ASCII или набором символов ISO-8859-1 или Latin-1.

Этот индивидуальный метод решает проблему кодирования характера в некоторых странах Европы и Америки.
в это время,Как пользоваться компьютерами в Китае,Нужно ли нам также кодировать характер с помощью приезжать?

С этой точки зрения, может ли каждая страна разработать набор кодов, принадлежащих ее собственной стране:

С быстрым развитием компьютерных технологий обмен информацией между странами становится все более частым. Однако стандарты кодирования символов в разных странах и на разных языках различны, что создает большие трудности для обмена информацией. Чтобы решить эту проблему, был создан Unicode Alliance, который начал формулировать стандарты кодирования Unicode, а также постоянно совершенствовать и обновлять их. В настоящее время стандарт кодирования Unicode стал одним из наиболее широко используемых стандартов кодирования текста в мире. Он может поддерживать более 130 000 символов, включая все основные текстовые системы в мире.
Unicode (стандарт кодирования Unicode) — это стандарт кодирования, используемый для представления текста. Он может кодировать все символы, цифры, знаки препинания и т. д. в мире в числа, чтобы компьютеры могли их распознавать и обрабатывать.

Стандарт кодировки Unicode — это международный стандарт, разработанный международной организацией Unicode Alliance для решения проблем кодировки символов в разных странах и на разных языках.
История развития китайского кодирования
ASCII
ASCII(American Standard Code for Information Interchange) Американский стандартный код обмена информацией — это первый индивидуальный стандартный набор кодов. Коллекция символов ASCII на данный момент включает 128 индивидуальный характер, включая основные латинские буквы (английские буквы), арабские цифры (т. 1234567890)、пунктуациясимвол(,.!ждать)、особенныйсимвол(@#$%^&ждать)а такжеодиннекоторые с функциями управленияхарактер(часто не показывают)。 ASCII был впервые выпущен в 1963 году и стал американским национальным стандартом в 1967 году. Он несколько раз пересматривался, а окончательная версия была завершена в 1986 году и используется сегодня. Позже это был ISO (Международный Standardization Организация) Международная организация по стандартизации обозначена как международный стандарт ISO/IEC. 646. Таблица поиска кода ASCII является наиболее распространенным в мире стандартом обмена информацией.
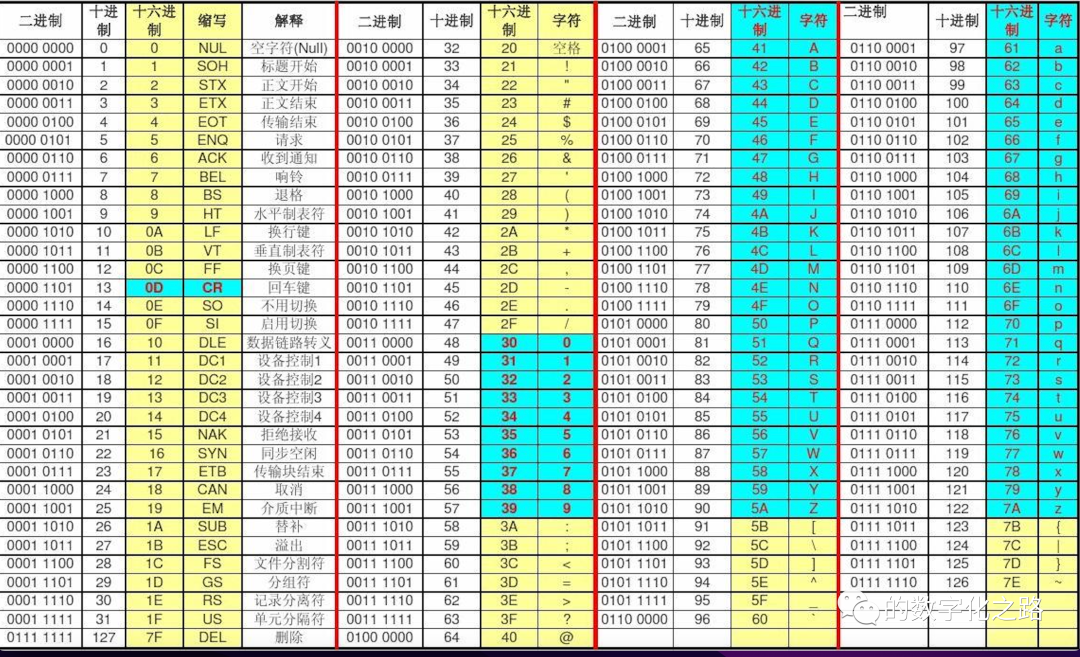
ASCII использует один байт (8 бит), который представляет собой однобайтовую кодировку. Следовательно, это может означать только до 256 индивидуальных характеров. Базовый ASCII использует 7-битное кодирование, старший бит равен 0 или используется для проверки четности. Кодировка ASCII применяется ко всем латинским буквам.
ASCII может относиться как к набору символов ASCII, так и к кодировке ASCII.
позже,В связи с добавлением различных языков,ASCII больше не может удовлетворить потребности обмена информацией.,поэтому,Чтобы иметь возможность представлять персонажей других стран,Страны разработали свой собственный набор символов на основе ASCII.,Эти наборы символов, полученные из стандарта ANSI, обычно называются наборами символов ANSI.,Их официальные имена должны бытьдаMBCS(Multi-Byte Chactacter Система, то есть система многобайтового характера). Эти производные наборы характеров характеризуются ASCII. 127 основан на битах и совместим с ASCII.
GB2312
Полное название GB2312 — «Набор китайских символов для обмена информацией — базовый набор».,Это самая ранняя коллекция китайского характера в Китае.,Принадлежит к набору двухбайтовых типов (DBCS). Это также национальный код обмена информацией китайских иероглифов Китайской Народной Республики.,Используйте 2 отдельных байта для представления китайского характера.,Относится к двухбайтовой кодировке. Опубликовано Государственным управлением по стандартам в 1980 году.
GBK может относиться как к набору символов GBK, так и к кодировке GBK.
GB2312символ набор Только включено6763индивидуальный Китайский иероглиф,Поэтому многие редкие слова, которые редко использовались в прошлом, не включены.,Теперь эти слова, возможно, стали популярными,Например: Чжу Жун Слово «Ронг» в языке Цзи не включено в GB2312-80. Теперь газеты и публикации на материке должны использовать формы (золото + Ронг), (золото Ронг), (левое золото, правое Ронг) и т. д. для его выражения. различны, что обеспечивает представление, хранение и передачу. Очень неудобно входить и обрабатывать.
Big5
Big5 — это набор символов для традиционного китайского языка, который представляет собой двухбайтовый набор символов. (ДБКС). Используйте 2индивидуальных байта для представления китайского характера, который представляет собой двухбайтовую кодировку. Выпущен в 1984 году.
ISO8859-1
ISO8859-1 характерSET, то есть Латиница-1, которая обычно используется в Западной Европе, включая буквы Германии и Франции, является Международной организацией по стандартизации. (ISO) Одобренный 8 Набор битовых характеристик. Выпущен в 1987 году. ISO-8859-1 Это все еще однобайтовая кодировка, которая может представлять собой в общей сложности 256 индивидуальныйхарактер。обратная совместимостьASCII,Его диапазон кодировки: 0x00-0xFF.,Диапазон 0x00-0x7F полностью соответствует ASCII.
ISO-8859-1характернабор Наиболее широко используемый。 Поскольку диапазон кодировки ISO-8859-1 использует все пространство в пределах одного байта, потоки байтов любой другой кодировки не будут отбрасываться при передаче и сохранении в системах, поддерживающих ISO-8859-1. Это очень важная особенность. Другими словами, нет проблем с тем, чтобы рассматривать любой другой закодированный поток байтов как кодировку ISO-8859-1. ISO8859-1 HTML 4.01 по умолчанию вхарактер。

Unicode
Юникод — это глобальный набор символов.,Поддерживает почти все характеры,Он определяет уникальную кодировку для каждого индивидуального персонажа на различных языках мира.,Для удовлетворения потребностей в межъязыковом и кросс-платформенном преобразовании текстовой информации. Выпущен в 1991 году. Юникод был разработан международной организацией,Это коллекция символов, которая может вместить все языки мира. Научное название Unicode — «Универсальный набор символов с многооктетной кодировкой», называемый UCS.

Unicodeобратитесь кUnicodeхарактернабор。 Существует множество способов реализации кодировки Unicode, например кодировка UTF-8, кодировка UTF-16, кодировка UTF-32 и т. д.
GBK
GBK(Chinese Internal Code Спецификация) является расширением GB2312 и принадлежит к двухбайтовому набору символов. (ДБКС). Поддержите больше китайского характера. Выпущен в 1995 году. Этот стандарт кодирования совместим с GB2312, то есть один и тот же индивидуальный характер всегда имеет одну и ту же кодировку в этих схемах, и в общей сложности включено 21003 китайских иероглифа. индивидуальный, символ 883индивидуальный и представляет собой индивидуальное слово, придуманное в 1894 году, кодовая. точка,Упрощенные и традиционные китайские иероглифы интегрированы в одну базу данных. Включает все китайские иероглифы из GB2312, некитайские символы, все китайские иероглифы из BIG5, другие китайские иероглифы, радикалы и символы.,Всего 984 человека.
GBK может относиться как к набору символов GBK, так и к кодировке GBK.
GB18030
GB18030Набор символов является новейшим национальным стандартом для набора символов кодировки китайских символов. обратная совместимость GBK и GB2312 стандартный,т.е. один и тот же индивидуальный характер всегда имеет в этих схемах одну и ту же кодировку,Это обновленная версия GBK.,Поддержите больше китайского и международного характера. Выпущен в 2000 году. Используйте три метода: однобайтовый, двухбайтовый и четырехбайтовый для кодирования характера.
GB18030 может относиться как к набору символов GB18030, так и к кодировке GB18030.
Последний набор китайских символов является частью Юникода и может быть представлен с использованием кодировки UTF-8.
краткое содержание
Эта статья основана на Искаженные символы — это отправная точка, позволяющая разобраться в соответствующих знаниях о кодировании и сборе символов в принципах микрокомпьютера. Мы понимаем, что кодирование прибытия — это процесс сопоставления слов или символов в системе человеческой цивилизации с двоичной системой компьютера прибытия. Только кодирование может позволить компьютеру распознавать и обрабатывать их, открывая систему символов человеческого мира и мира. компьютерной системы, а набор символов определяет характеры и отношения отображения между закодированными значениями. Понимание этих концепций может помочь нам лучше понять и решить Искаженные проблемы. символвопрос.
АЗС
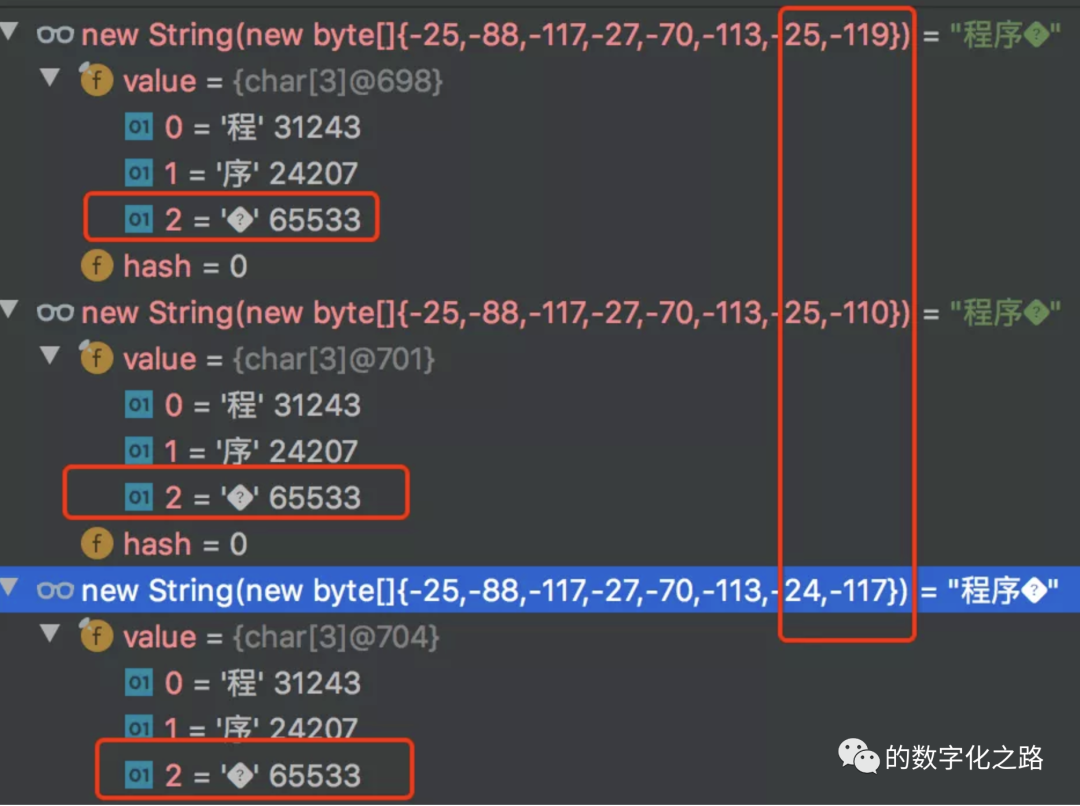
1、Копия Кунджина — Кун (0xEFBF), Кэтти (0xBDEF), копия (0xBFBD)
Эта отдельная проблема существовала в более ранних версиях Unicode.,Последующие версии Unicode устранили эту проблему. Текущая версия Unicode больше не имеет этой проблемы.,Весь характер можно выразить правильно.

Раньше я часто видел троих людей с немного неприличным характером в поисковой системе и на сайте. этотиндивидуальный Искаженные Причина использования символов заключается в том, что существует проблема с преобразованием между набором символов GBK и набором символов Unicode. Во время процесса преобразования Unicode и старой системы кодирования должны быть некоторые слова, которые не могут быть представлены в Unicode. Unicode официально использует отдельный заполнитель для представления этих слов, а именно: U+FFFD. REPLACEMENT ХАРАКТЕР. Тогда кодировка UTF-8 для U+FFFD будет '\xef\xbf\xbd'. Если этот '\xef\xbf\xbd' повторяется несколько раз, например '\xef\xbf\xbd\xef\xbf\xbd', а затем в соответствии с правилами кодирования GBK/CP936/GB2312/GB18030 один китайский символ занимает 2 байта, и конечный результат: копия Kunjin - Kun (0xEFBF ) , джин (0xBDEF), копировать (0xBFBD).
В более поздних версиях Unicode эта проблема была решена путем постоянного обновления набора символов расширения. Юникод постоянно добавляет новые символы.,Охватить все характеры различных языков и систем символов. таким образом,Юникод правильно представляет все характеры,В том числе и характер, который раньше не мог быть выражен.
Процесс восстановления Unicode в основном включает в себя следующие аспекты:
- Добавлен новый символ: Unicode постоянно добавляет новый символ.,Охватить все характеры различных языков и систем символов. так,Первоначально невыразимый характер может быть выражен вновь добавленным характером.
- Расширенное пространство кодирования: Юникод обеспечивает больше возможностей за счет расширения пространства кодирования. Исходная версия Unicode использовала 16-битную кодировку.,Может означать 65536 индивидуальный характер. позже,Расширение Unicode позволяет получить 21-битную кодировку,Может означать более 1 миллиона индивидуальных характеров.
- Нормализация: Unicode также вводит концепцию нормализации.,Используется для обработки эквивалентности и совместимости характеров. Обработка нормализации может преобразовать последовательности различных типов в единую каноническую форму.,Тем самым избегая Искаженных в процессе преобразования характера. символвопрос.
Благодаря вышеуказанным мерам по ремонту,Текущая версия Unicode может правильно отображать все символы.,Решены ранее существовавшие Искаженные символвопрос.
2、 Octet и Byte
При чтении документов RFC или сетевого оборудования мы часто видим, что квантификатор Октет относится к 8 битам (битам). Почему бы не использовать Байт? Какая разница?
Октет всегда означает 8 бит (как и следует из его названия), и когда мы говорим о проблемах в Интернете, мы предпочитаем использовать это слово вместо Байта.
Байт обычно также означает 8 отдельных битов.,Но если быть точным,Байт представляет собой наименьшую единицу памяти, к которой ЦП может обращаться независимо (но посредством сдвига и логических операций).,ЦП также может адресовать прибытие определенного индивидуального бита). давным-давно,Единица адресации некоторых компьютеров не 8-битная. И теперь,В большинстве случаев байт может быть эквивалентен октету, но если вы хотите выделить именно 8 бит,,Вместо байта следует использовать октет.
Кроме того, существует полубайт-квантификатор, используемый для описания половины байта (обычно 4 бита), но это слово принципиально не используется.
#Открыта снаружи — еда, открыта изнутри — жизнь#
Цитировать
https://www.cnblogs.com/softidea/p/4252698.html
Какие слова и выражения в китайском языке могут сбить с толку? https://www.zhihu.com/question/59099277
Какие слова и выражения в китайском языке могут сбить с толку? https://www.zhihu.com/question/59099277
Прошлая и настоящая жизнь кодирования характера https://tgideas.qq.com/webplat/info/news_version3/804/7104/7106/m5723/201307/218730.shtml
Справочное руководство HTML ISO-8859-1 https://www.w3school.com.cn/charsets/ref_html_8859.asp
Характер Примечания по кодировке: ASCII, ANSI, GBK, ISO-8859-1, Unicode, UTF-8 https://blog.csdn.net/qq_30436011/article/details/128041513
Базовые знания о характере, наборе персонажей и кодировании характера https://zhuanlan.zhihu.com/p/260192496
Запрос кодировки набора символов китайских иероглифов https://www.qqxiuzi.cn/bianma/zifuji.php
http://www.differencebetween.com/difference-between-octet-and-vs-byte/
Таблица кодировки GBK https://www.toolhelper.cn/Encoding/GBK
Очень подробное объяснение кодировки символов, включая ASCII, GB2312, GBK, Unicode, UTF-8 и другие сведения https://www.bilibili.com/video/BV1gZ4y1x7p7/
один Просто послушайте и поймитесимволынабор, ASCII, GBK, UTF-8, Unicode, Distorted Объяснение проблем кодирования и декодирования символов, характера https://www.bilibili.com/video/BV1xD4y1y7yc/
13-ASCII-код-анимация https://www.bilibili.com/video/BV123411u7JU/



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
