Основные принципы хранения и запроса данных ЭП
Введение в Elasticsearch (ES)
Elasticsearch(ES)этораспределенный、Расширяемый、почти в реальном временисистемы поиска и анализа,это основано наLucene,Предназначен для использования в облачных вычислениях.,Выполнение крупномасштабных задач по поиску документов и анализу данных.,Он часто используется для реализации грубого процесса ранжирования внутренних поисковых систем и алгоритмов удаления.
ESна основеLucene,на основеLuceneДелатьиндекси искать,скрытыйLuceneсложность сама по себе,Предоставляет простой и удобный в использовании RESTful API.
ЭС имеет следующие характеристики:
- Готов к использованию «из коробки». Предоставляет простой и удобный в использовании API, упрощающий создание, развертывание и использование сервисов.
- распределенный: в соответствии с механизмом сегментирования один и тот же индекс делится на несколько сегментов (Shard).,использовать деление и властвуйидеи по повышению эффективности обработки
- Горизонтально расширяемый: как крупномасштабную распределенную поисковую систему, ее легко расширять в ESкластер, ее также можно запускать на автономной машине в качестве облегченной поисковой системы;
- Высокая доступность: обеспечивает механизм реплики (реплики).,Осколок может иметь несколько копий.,Даже после того, как некоторые серверы выйдут из строя,кластер все еще работает нормально
- Более богатые функции: по сравнению с традиционными реляционными библиотеками данных, ES обеспечивает полнотекстовый поиск, обработку синонимов, ранжирование релевантности, комплексный анализ данных и почти полный объем данных. в реальном обработка времени и другие функции
В целом ES это:
- Механизм хранения документов в реальном времени,Каждое поле можно искать с помощью
- Распределенная поисковая система анализа в реальном времени, которая поддерживает различные операции запроса и агрегирования.
- Большое распространение — это двигатель,Возможность масштабирования до сотен сервисных узлов.,И может поддерживать структурированные или неструктурированные данные уровня PB.
ES играет ключевую роль во многих сценариях. Вот некоторые распространенные случаи использования.
- Поиск приложений
- поисковая система
- Внутренний поиск предприятия
- Анализ и обработка журналов
- Базовые метрики проектирования и мониторинг контейнеров
- Мониторинг производительности приложений
- бизнес-анализ
также,В массивном текстовом контентерекомендоватьсцена,Вы можете использовать ES для реализации процесса грубой сортировки.,Улучшите отзыв и производительность.
Основные концепции ES
Почти в реальном времени
Производительность ES, близкая к реальному времени, отражается в двух аспектах:
- Задержка с момента записи данных до момента их получения составляет около 1 с (определяется принципом реализации,Дальше ниже иллюстрировать)
- Поиск и анализ на основе ЭП можно выполнить за считанные секунды.
Кластер
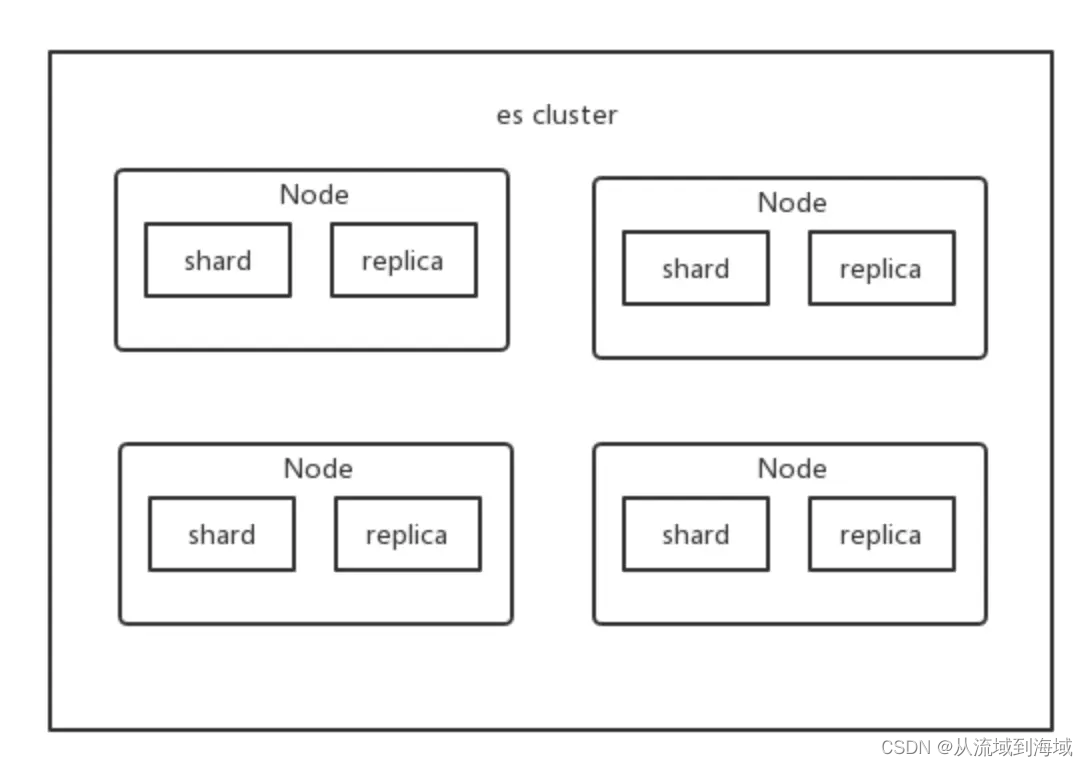
Кластер состоит из нескольких узлов, и все функции хранения, индексирования и поиска данных реализуются через все узлы. Каждый кластер идентифицируется уникальным именем, которое по умолчанию — «elasticsearch». Кластер по умолчанию очень важен. Только установив это имя, узел может присоединиться к этому кластеру и стать его частью.
К какому кластеру принадлежит каждый узел, определяется настроенным именем кластера. При начальных условиях кластер может иметь только один узел, а новые узлы будут добавляться по мере расширения кластера.
Узел
Узел относится к серверу, на котором работает один экземпляр.,Является членом кластера,Может хранить данные,Участвовать в индексировании и процессе поиска кластера,Узлы также идентифицируются по имени,По умолчанию используется случайный персонаж Marvel, имя которого автоматически генерируется при запуске.,Вы также можете настроить имя. Узел определяет кластеримя для присоединения через настроенную кластеримя.,Узел по умолчанию будет добавлен к узлу по умолчанию.elasticsearchизкластер。
Узлы можно разделить на следующие типы:
- главный узел Отвечает за операции на уровне кластера, такие как создание или удаление индекса, отслеживание того, какие узлы являются частью кластера, принятие решения о том, какие сегменты каким точкам выделены, сохранение и обновление информации метаданных кластера, а затем синхронизация со всеми узлами, чтобы каждый узел сохранял полный объем метаданных. Когда главный Когда узел зависает, новый главный узел будет выбран из доступных узлов. узел。
- dataNodenode Отвечает за хранение данных, индекс и запросы.
- клиентский узел Координационный узел, отвечающий за агрегацию запросов/парсинг запросов и работу на финальном этапе, Существование Координационного узла может снизить нагрузку на dataNode.,Пусть он сосредоточится на написании и запросе данных.
Осколок
Один узел не может хранить большие объемы данных,ES разбивает данные одного индекса на несколько Осколок,распределенный хранится на нескольких узлах. поэтому,ES масштабируется горизонтально на основе концепции шардов.,хранить больше данных,И позвольте операциям хранения, индексирования и анализа быть распределены по нескольким узлам для выполнения.,разделяй и властвуй,Это, в свою очередь, повышает пропускную способность и производительность.
Это онлайн,каждыйиндивидуальный Шардинг Всеэтоluceneизindex。
копия
Любой узел может выйти из строя или выйти из строя. В это время шард узла не может быть сохранен или запрошен. Чтобы обеспечить высокую доступность, ES создает несколько копий реплик для каждого шарда и распределяет их по разным узлам. Реплику можно рассматривать как механизм аварийного восстановления, предоставляющий услуги резервного копирования в случае сбоя сегмента, чтобы гарантировать, что данные не будут потеряны. Для повышения пропускной способности и производительности операций поиска можно распределить несколько реплик.
Существует два типа осколков: основной осколок и осколок-реплика. Первичный осколок обычно называется осколок, а осколок-реплика обычно называется репликой.
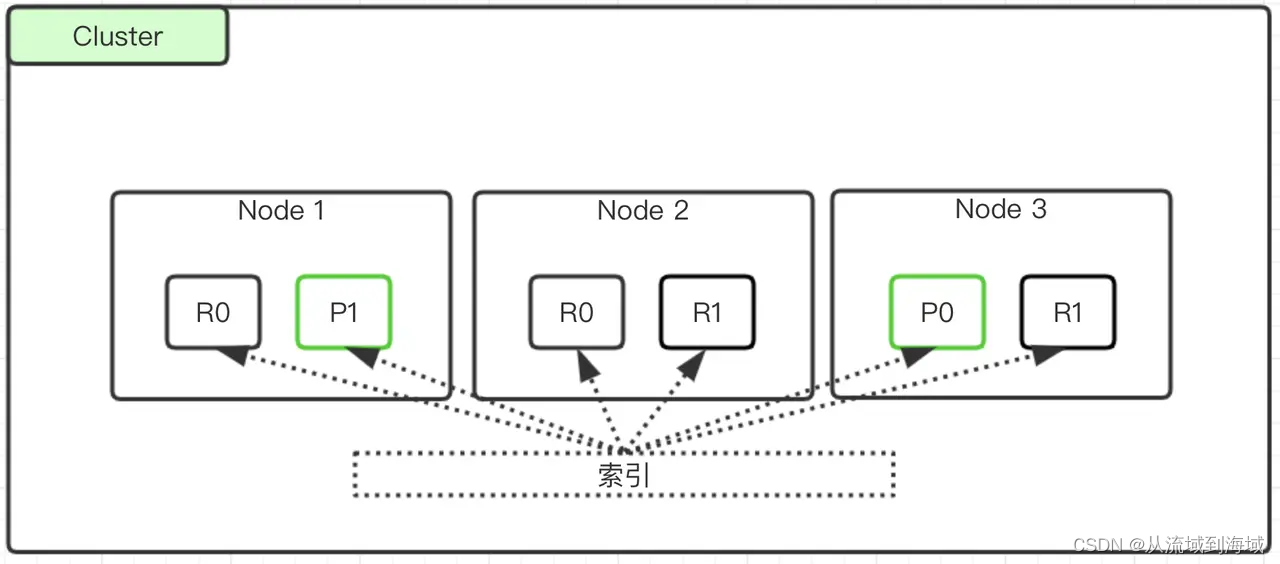
На рисунке выше R означает реплику, а P — первичный.
Сегмент
ESсерединакаждыйиндивидуальный Шардинг Всеэтоluceneдвигатель,Тогда каждый сегмент по сути является инвертированным индексом в шарде.
ES будет генерировать один файл сегмента каждую секунду. Если файлов сегментов слишком много, будет запущена операция объединения нескольких файлов сегментов в один, и в то же время документы, помеченные для удаления, будут фактически удалены.
точка фиксации
Каждый сегмент имеет файл точки фиксации. Каждые 30 минут или после того, как сегмент достигнет 512M, сегмент в кэше ОС будет записан на диск. Этот процесс называется сбросом, поскольку точка фиксации сохраняет успешное размещение диска в текущем сегменте. .все сегменты. В то же время будет сохранен файл .del для записи удаленного документа.
концепция хранения
Аналогия с MySQL используется только для понимания. Это разные концепции, которые не полностью эквивалентны.
имя | иллюстрировать | АналогияMySQL |
|---|---|---|
индекс | Коллекция документов со схожими структурами данных. | база данных база данных |
тип | Каждый индекс может иметь один или несколько типов, которые являются логическими классификациями индекса. Поля документа каждого типа могут не совпадать. | таблица данных таблицы |
документ | Документ — это наименьшая единица данных в формате es. | записать строку данных |
поле | поле документа | поле записи (столбец) |
Примечание: типы сопоставления. Эта информация находится в ElasticSearch 7. X был полностью удален. Подробности см. в официальной документации.
Принцип распределенной архитектуры ES
ESкакраспределенныйпоисковая система,Первый этажна основеlucene,Его основная идея — запустить несколько экземпляров процесса ES на нескольких машинах.,Сформируйте ESраспределенныйкластер.
Основной единицей хранения данных в ES является индекс. Если вспомнить введение в первом разделе, структура индекса примерно следующая:
index -> type -> mapping -> document -> fieldИндекс можно разбить на несколько шардов, каждый шард хранит часть данных и распределяется по разным узлам. Разделение осколков имеет два преимущества:
- Поддержка горизонтального расширения
- Параллельное распределенное выполнение повышает пропускную способность и производительность.
каждыйshardУ каждого есть одинprimary shard,Отвечает за запись и синхронизацию.,Есть несколькоreplica shardкакданныерезервное копирование。primary shardписатьданныеназад,воляданныесинхронный Даватьвсеизreplica shard,Общий процесс выглядит следующим образом:
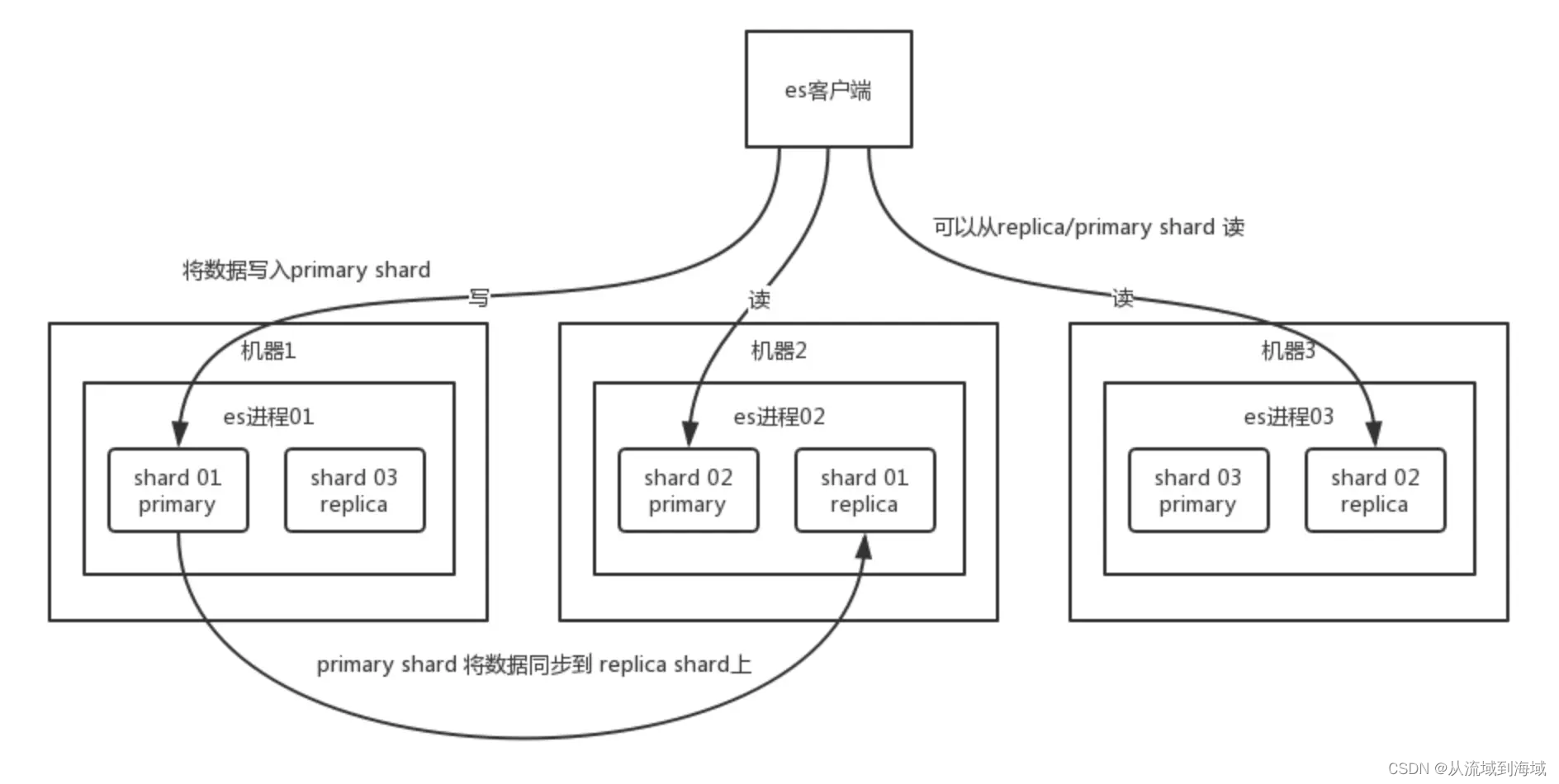
Процесс запроса ES
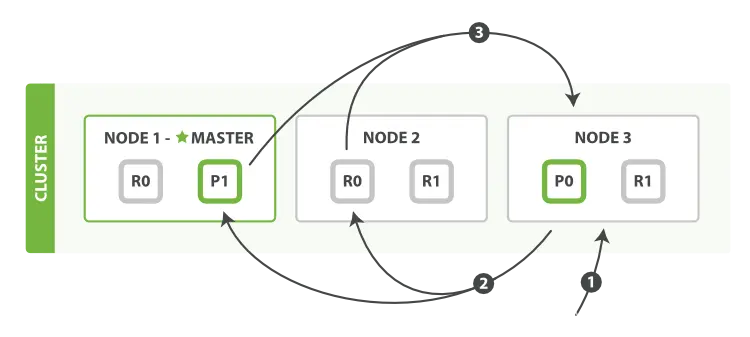
Если взять приведенный выше рисунок в качестве примера, этап запроса ES примерно включает следующие три шага:
- Клиент отправляет
searchпросилNode 3,Node 3Создайте файл размеромfrom+size(Уточняйте при запросе,Пустая очередь приоритетов со значением по умолчанию) Node 3Пересылать запросы наиндексизкаждый主Шардингили副本Шардингсередина(Как показано на картинкеNode 1изP1иNode 2изR0)。каждый Шардингсуществоватьместныйосуществлять Запроси добавить результатыприезжать Тот же размер естьfrom + sizeизместный有序приоритетная очередьсередина。- каждый Шардингвозвращатьсясоответствующая приоритетная очередьсерединавседокументизIDиндивидуальныйсортировать Стоит отдать Координационный узел
Node 3,Node 3слитьвсеизценитьприезжать Собственныйизприоритетная очередьсерединапроизвести одининдивидуальныйобщая ситуациясортироватьизрезультат。
Когда запрос на поиск отправляется узлу,этотиндивидуальный Узел становитсяКоординационный узел。 Задача этого узла — транслировать запрос запроса всем соответствующим шардам и интегрировать их ответы в глобально отсортированный набор результатов, а затем вернуть набор результатов клиенту.
Координирующий узел сначала передает запрос на сегментную копию каждого узла в индексе, а затем запрос запроса может быть обработан основным сегментом или сегментом-репликой, поэтому большее количество реплик (больше узлов) может увеличить пропускную способность поиска. Координирующий узел будет опрашивать все копии шардов в последующих запросах, чтобы разделить нагрузку (с помощью определенного механизма балансировки нагрузки).
Процесс записи данных ES
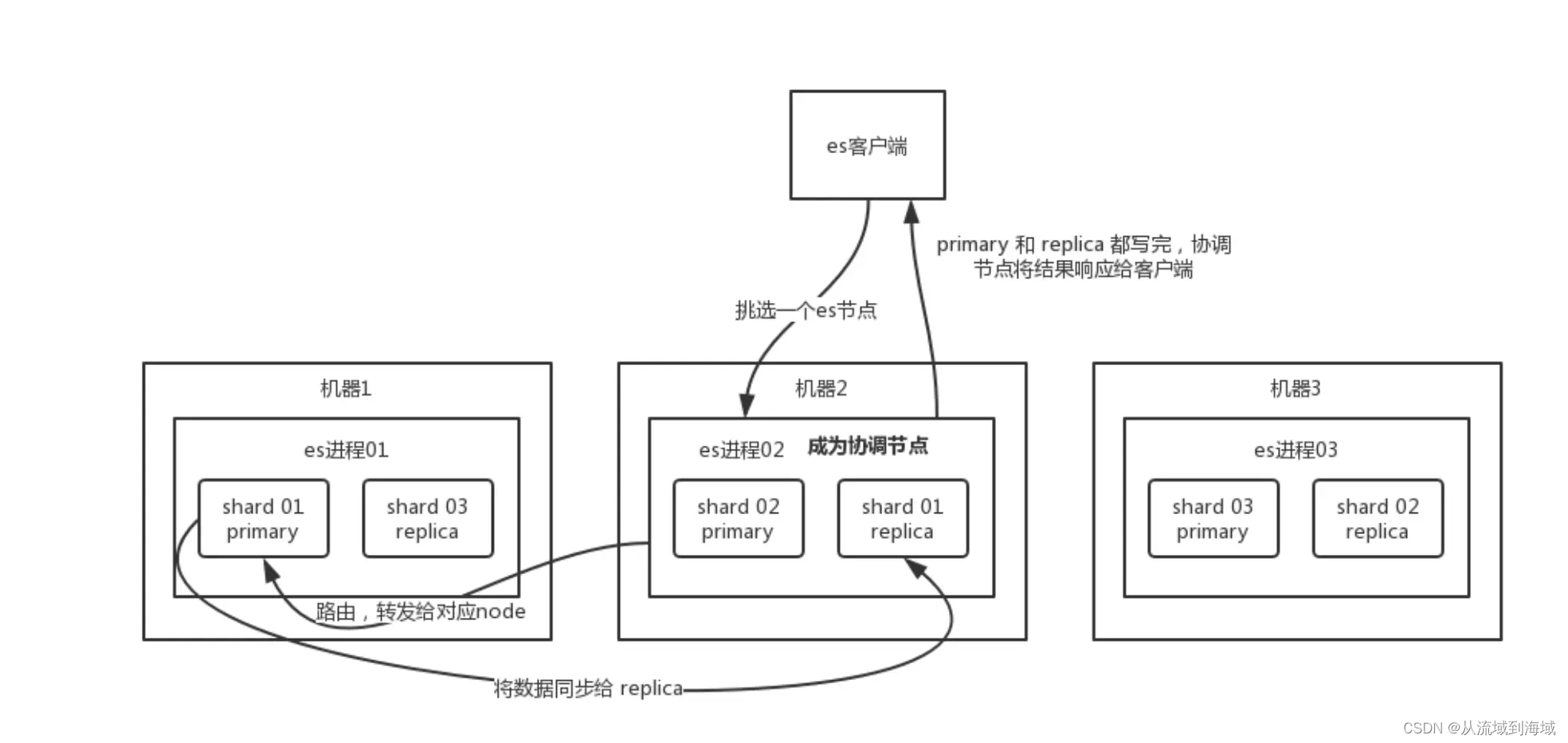
- Клиент выбирает узел и отправляет ему запрос на запись.,получатьприезжатьпроситьизnodeВолякак
coordinating node(Координационный узел) выполните следующие действия. coordinating nodeверноdocumentмаршрутизация,Впередпросилверноотвечатьизnode(Включатьprimary shardиз Чтоиндивидуальныйnode)- После получения запроса,nodeначальствоиз
primary shardобработать запрос,писатьданные,и будетданныесинхронныйвсе含有Чтоверноотвечатьreplica shardизnode coordinating nodeсуществоватьprimary shardивсеизreplica shardВсеписатьполныйназад,Возврат результатов клиенту
Процесс чтения данных ES
ESподдержка черезdoc_idЗапросданные(писатьуказано, когда,Сборка по умолчанию не указана),Общий процесс выглядит следующим образом:
- Клиент отправляет запрос в любой node,ДолженnodeПосле получения запросастановиться
coordinate node coordinate nodeверноdoc idВыполнить хэш-маршрутизацию,Перенаправить запрос на соответствующий узел,будет использоваться в это времяround-robinалгоритм случайного опроса,существоватьprimary shardи все этоreplica shardсерединаслучайным образом выбрать одининдивидуальный,Запросы на чтение с балансировкой нагрузки- 实际接получатьприезжатьпроситьиз
nodeвозвращатьсяпопытаться найтиприезжатьизdocumentДаватьcoordinate node coordinate nodeвозвращатьсяdocumentДаватьклиент
Процесс поиска ЭП
Самая мощная функция ES — полнотекстовый поиск. Процесс поиска примерно следующий:
- Клиент отправляет запрос на поиск в любой узел,Должен Узлы следуютназадстановитьсяодининдивидуальный
coordinate node coordinate nodeпросить Впередприезжатьвсеиз shard верноотвечатьизprimary shardилиreplica shard(Доступен любой)- query phase:каждый
shardВоля Собственныйизпоискрезультат(doc_id)возвращаться Даватьcoordinate node,Зависит отcoordinate nodeруководитьданныеизслить、сортировать、Такие операции, как пейджинг,Произведите окончательный результат. - fetch phase:Ранназад Координационный узелв соответствии с
doc idПерейти к различныминдивидуальный节点начальство拉取实际изdocumentданные,Наконец вернулся к клиенту.
写проситьдаписатьprimary shard,Ранназадсинхронный Даватьвсеизreplica shard;Запросы на чтение могут быть сделаны изосновной осколок илиreplica Чтение из любого шарда использует алгоритм случайного опроса.
Основной принцип записи данных
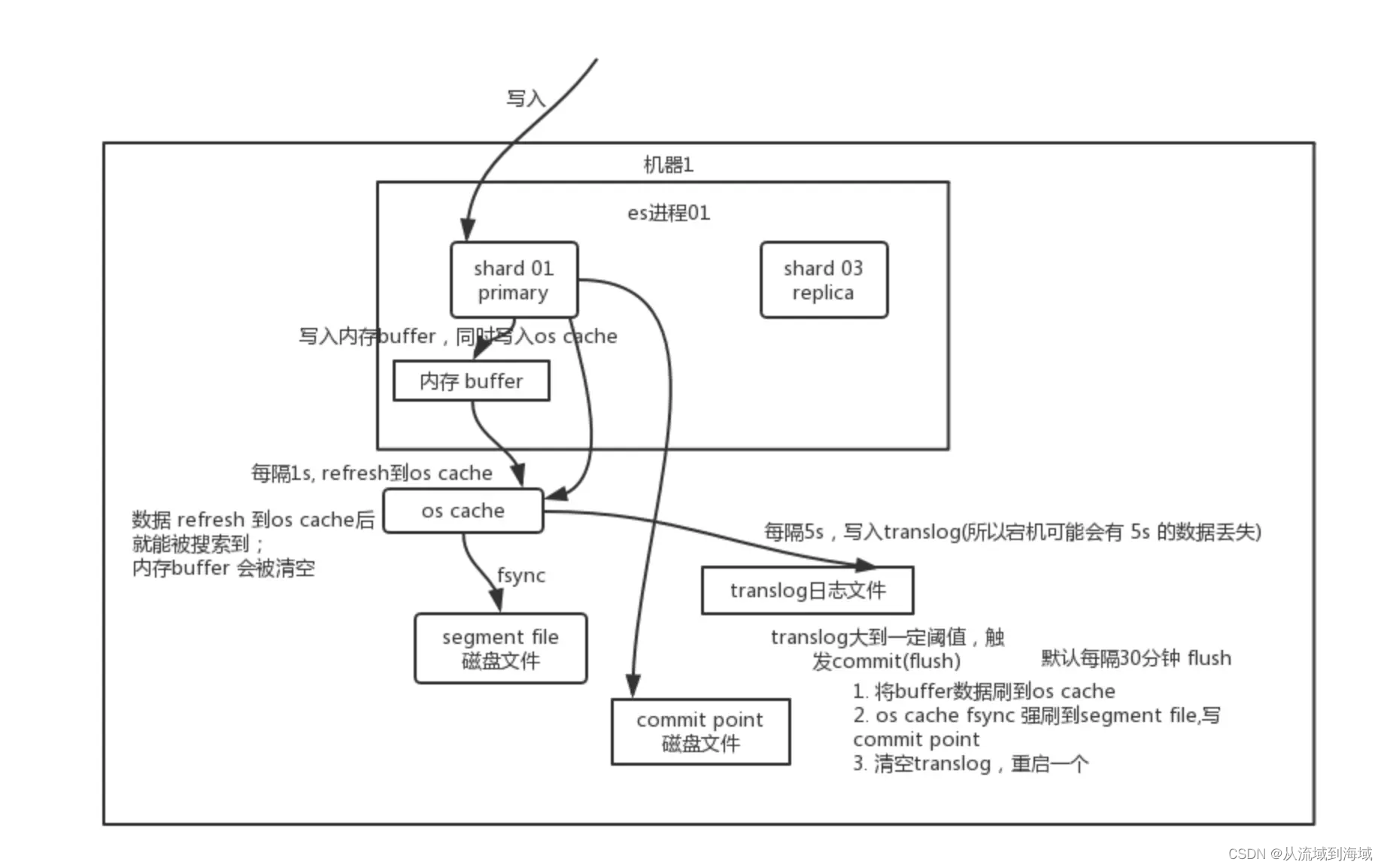
данные Первыйписать Памятьbuffer,Затем каждые 1 с,Воляданныеотbuffer refreshприезжатьos cache,приезжать Понятно os cacheданныеможно поискатьприезжать(таким образомesотписатьприезжатьможно поискатьприезжатьсередина Есть 1s из Задерживать)。каждый5s,Воляданныеписатьtranslogдокумент(Итак, если машина выйдет из строя,Вся память пропала,Максимум будет потеряно только 5 секунд данных),translogПревосходить512M,Или каждые 30 минут по умолчанию,Запустит операцию фиксации,Волябуферизданные Всеflushприезжатьsegment fileдискдокументсередина。данныеписатьsegment fileИзназад,В то же время был установлен инвертированный индекс.
Удаление и обновление аналогичны описанным выше операциям.,Уведомлениеиздаудалитьдасуществоватьsegmentверноотвечатьиз.delдокументсередина Отметить как ужеудалить,настоящийудалитьпроисходитьсуществоватьсуществоватьsegment fileслитьизкогда。
Причина близких к реальным характеристикам ES
- 写просить Воляданныеписать
bufferсередина,В настоящее время поиск данных невозможен.,в это времябудет в то же время Воля Запись записи операциисуществоватьtranslogсередина,translogиз落盘如果配置成синхронный,Он будет размещен в это время,Если настроено как асинхронное,Будет размещено с заданным интервалом. - Операция обновления по умолчанию выполняется раз в 1 секунду.,esволя
bufferвнутриизданные Депозитos cacheсередина,и положитьbufferсерединаизданныепреобразован вsegment,в это времяdocumentможно поискатьприезжать Понятно。каждый разrefreshВсевстреча生成одининдивидуальныйsegment,esПериод встречируководитьsegmentслить。refreshданныеприезжатьos cacheназад,bufferбудет очищен。 - Достигает 512M каждые 30 минут или сегмент назад,воля
os cacheсерединаизsegmentписатьприезжатьдисксередина,этотиндивидуальный Процесс называется Делатьflush。в это времявстреча生成одининдивидуальныйcommit pointдокумент,用来唯один标识Долженsegment。осуществлятьflushВо время работы,воляbufferиos cacheвнутриизданные Все Прозрачный,в это времяtranslogТакже будет размещен на рынке。оригинальныйизtranslogбудетудалить,встречасуществовать Памятьсерединасоздаватьодининдивидуальныйновыйизtranslog。
инвертированный индекс
инвертированный индекс(inverted index,Также известен как обратный индекс),Это относительное понятие положительного индекса. Общий индекс, такой как индекс первичного ключа MySQL.,даidприезжатьданныеизкартографирование,Это положительный показатель,иESиспользоватьизLuceneинвертированный индекс,да Содержание документаданныеприезжатьдокументidизкартографирование,Поэтому его называют обратным индексом или инвертированным индексом.
Luceneинвертированный индексинвертированный Индекс поддерживает сопоставление ключевых слов с идентификаторами документов, то есть с помощью ключевого слова можно найти все идентификаторы документов, содержащие это ключевое слово.
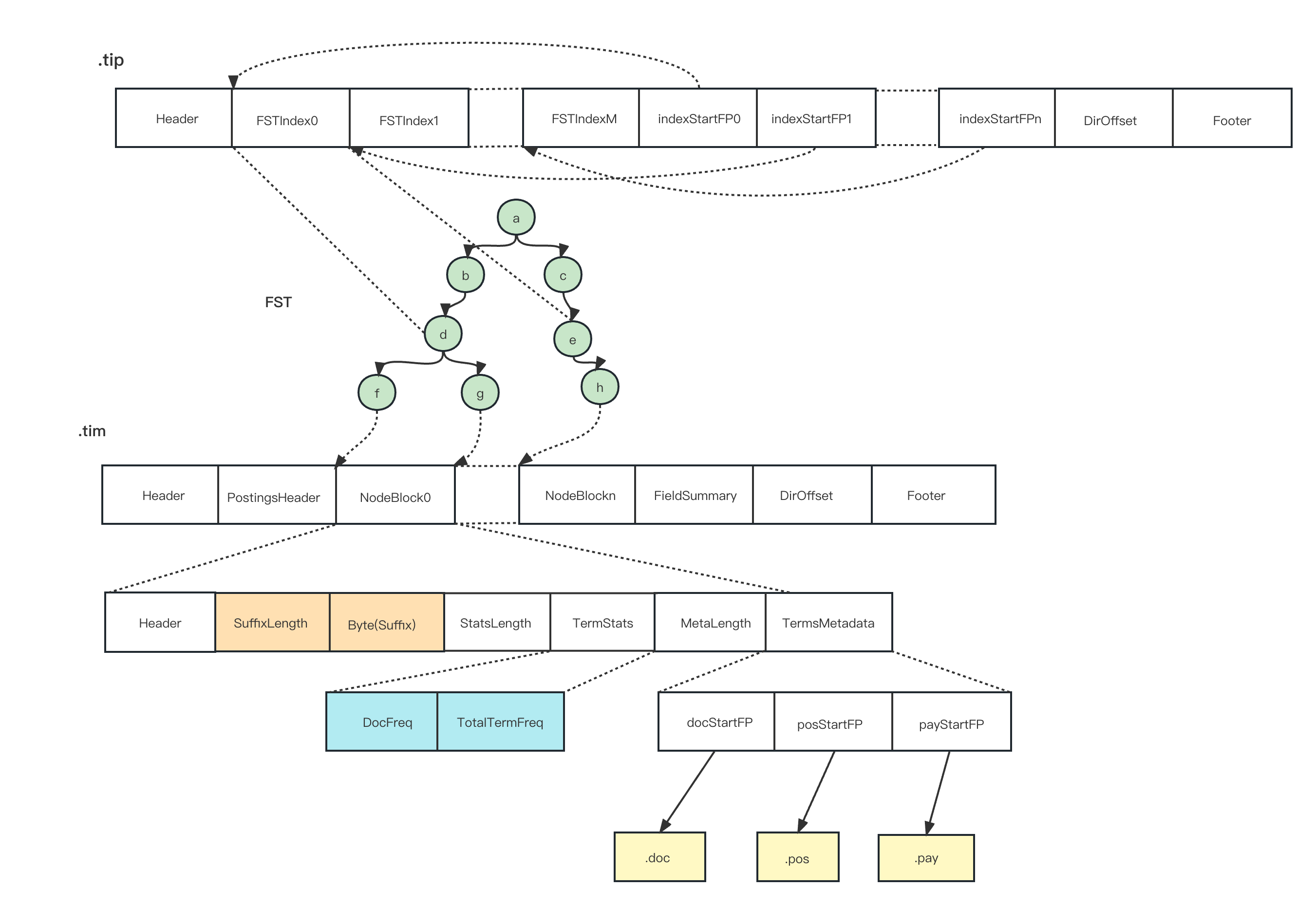
- Анализируя оператор запроса,придетсяприезжать需要查попытаться найтииз
term,попытаться найтиприезжать Долженtermверноотвечатьиз.tipдокументи.timдокумент。luceneвстреча默认为каждыйиндивидуальныйtermВсесоздаватьверноотвечатьизиндекс term indexосновной Зависит отFSTIndexиindexStartFPкомпозиция,FST(Finite State Transducer)машина с конечной передачей состояний,可以理解为одининдивидуальныйпрефикс словаиндекс。проходитьвернопрефиксиндексизпоиск,Вы можете сузить область поиска,提高поискизэффективность。 3.indexStartFPnвнутри存издаFSTIndexnизадрес, Зачем экономитьindexStartFPn,дапотому чтокаждыйFSTIndexnизразмер不один样,Чтобы сэкономить место для хранения,плотное хранениеFSTIndexn,нодаэтот样Сразу没办法快速查попытаться найтиFSTIndexn。Так что поменяйте пространство на время,сохранятькаждыйFSTIndexnиз起始адрес,иindexStartFPизразмер Всеодин样,этот样Сразу可以проходитьindexStartFPnруководитьдва分查попытаться найти Понятно。- проходить
termизпрефикс匹配定位приезжать ДолженtermМожет существоватьсуществоватьизblock,в это время Просто нужноприезжать.timдокументвнутри去查попытаться найти。Можно смотретьприезжать.tim-файлмы сравниваемсосредоточиться наиздатри части。одиндаsuffix;двадаTermStats;тридаTermsMetaData。Чтосерединаsuffixвнутримагазиниз Сразуда Долженtermизназаддлина суффиксаиsuffixизсодержание。TermStatsвнутри Включатьизда ДолженTermсуществоватьдокументсерединаизчастота以及всеTermизчастота,Эта часть предназначена для расчета корреляции (процесс расчета корреляции,Будет представлено в следующем сообщении блога). - часть третья
TermsMetaDataвнутримагазинизда ДолженTermсуществовать.doc、.pos、.payсерединаизадрес。.docдокументсерединамагазиниздаdocIdинформация,包括этотиндивидуальныйtermМестосуществоватьизdocId、Частота и другая информация。.posдокументвнутри Включать Долженtermсуществоватькаждыйдокументвнутрииз Расположение。проходить.timдокументвнутримагазинизэтот些адрес,Сразу可以去верноотвечатьиздокументвнутрипридется出ДолженtermМестосуществоватьиздокументid、Расположение、Частота — важная информация.
luceneЕсть и положительныеиндекс,проходитьинвертированный индексбратьприезжатьизdocIdназад,Просто нужнопроходитьвперединдексиспользоватьdocIdпопытаться найтиприезжатьдокумент:
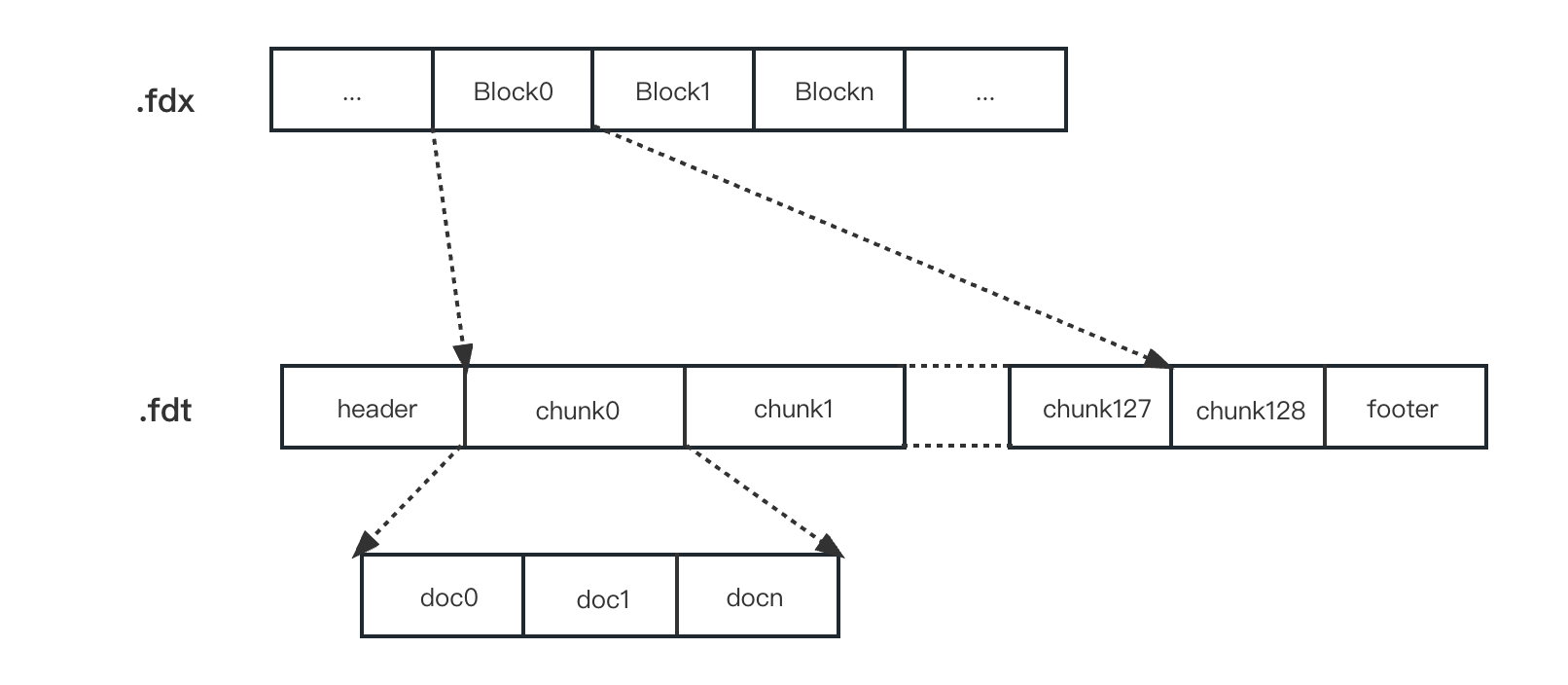
- В файле fdx хранится начальный адрес каждой группы фрагментов.
- Каждый фрагмент файла fdt содержит сжатую документацию.
- файлы fdx меньше по размеру и могут быть загружены непосредственно в память.
- Получите адрес чанка, в котором находится соответствующий документ, через файл fdx.,Затем найдите и загрузите информацию о данных документа в файл fdt по адресу фрагмента.
Процесс получения данных документа через прямой индекс аналогичен операции возврата таблицы MySQL.
Ссылки
Были сделаны ссылки на несколько статей в интранете. Изображения взяты из этих документов и не указаны.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
