Ошибка физического содержимого в резервной копии моментального снимка Elasticsearch
Предыстория проблемы:
Во время обычного процесса резервного копирования моментальных снимков индекса неожиданно произошел сбой. Опросите хранилище и обнаружите, что хранилище недоступно, и возвращается следующая информация журнала исключений.
[xxxx_backup] Could not read repository data because the contents of the repository do not match its expected state.
This is likely the result of either concurrently modifying the contents of the repository by a process other than this cluster or an issue with the repository's underlying storage.
The repository has been disabled to prevent corrupting its contents.
To re-enable it and continue using it please remove the repository from the cluster and add it again to make the cluster recover the known state of the repository from its physical contents.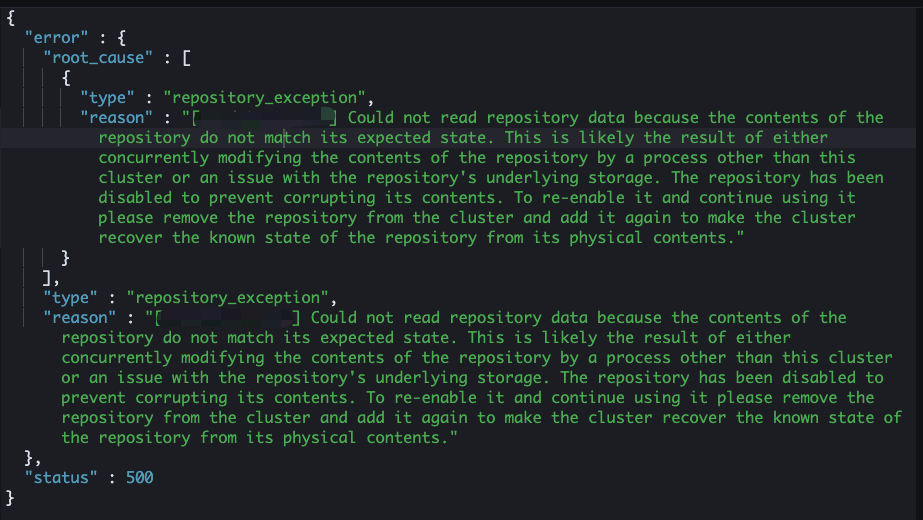
В настоящее время состояние хранилища следующее: все узлы нормально подключены к хранилищу, но хранилище не может получать снимки и не может продолжать выполнять резервное копирование снимков в хранилище.
Причина проблемы:
При записи моментального снимка другие сервисные процессы также изменяют хранилище, в результате чего состояние хранилища становится несоответствующим состоянию, хранящемуся в кластере Elasticsearch, в результате чего хранилище становится недоступным.
1. Содержимое хранилища изменяется одновременно с другими процессами.:Это может привести к тому, что статус склада будет отличаться от Elasticsearch Ожидаемое состояние противоречиво.
2. Основные проблемы с хранением:Вероятно, из-за базового хранилища(нравиться NFS、S3 и т. д.) проблемы.
Решение:
Текущий кластер проекта использует NFS в качестве носителя хранилища и создает хранилище типа «Общая файловая система» на основе es.
1. Удалите и заново добавьте хранилище снимков.
Это позволит кластеру Elasticsearch восстановить известное состояние хранилища из физического контента.
- Удалить склад
DELETE _snapshot/my_backup- Восстановить репозиторий
PUT _snapshot/my_backup
{
"type": "fs", // или другие типы складов, такие как "s3"
"settings": {
"location": "/path/to/repository" // или S3 Название сегмента и т. д.
}
}Здесь мы удаляем хранилище и перестраиваем идентичное хранилище, что эквивалентно предоставлению Elasticsearch возможности обновить состояние хранилища. В то же время эта операция не удалит снимок в хранилище.
2. Проверьте наличие проблем с хранилищем.
В основном без проблем проверяйте базовое хранилище, такое как (NFS, S3 и т. д.).
- NFS-хранилище
Если вы используете хранилище nfs, проверьте, нормально ли зависает nfs и нет ли проблем с разрешениями.
mount | grep nfsОперации чтения и записи можно протестировать в точке монтирования nfs.
touch /path/to/repository/testfile
echo "test" > /path/to/repository/testfileчтобы убедиться в отсутствии ошибок разрешений.
- S3 хранилище
Если вы используете хранилище S3, вам необходимо убедиться, что с бакетом и учетными данными нет проблем. Используйте интерфейс командной строки AWS, чтобы проверить доступность корзины S3.
aws s3 ls s3://my-bucket3. Проверьте одновременный доступ
Убедитесь, что никакие другие процессы или кластеры не обращаются одновременно к репозиторию моментальных снимков и не изменяют его. Если несколько кластеров Elasticsearch используют одно и то же хранилище снимков, может возникнуть несогласованность данных. Каждый репозиторий моментальных снимков должен использоваться только одним кластером.
4. Проверьте журналы Elasticsearch
Используйте журналы для определения возможных причин проблемы.
sudo tail -f /var/log/elasticsearch/elasticsearch.logЕсли ни один из вышеперечисленных методов не может устранить ошибку склада, рассмотрите возможность использования следующих методов.
5. Очистите и инициализируйте склад.
В некоторых случаях может потребоваться вручную очистить содержимое репозитория и повторно его инициализировать. Обратите внимание, что это приведет к потере существующих данных моментального снимка, поэтому действуйте осторожно.
- 1. Остановите кластер Elasticsearch:
Прежде чем выполнять операцию очистки, обязательно остановите кластер Elasticsearch, чтобы избежать одновременного доступа.
- 2. Очистите содержимое склада:
Вручную удалите содержимое каталога репозитория (например, файлы в точке монтирования NFS):
sudo rm -rf /path/to/repository/*- 3. Повторно инициализируйте склад:
Запустите кластер Elasticsearch и повторно добавьте репозиторий снимков.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
