Оригинальный обзор графовых сетей внимания
Когда число неосязаемо, интуиции меньше, а когда число мало, трудно понять детали – Хуа Луоген
1 Введение в нейронную сеть графа внимания
1.1 Принципы и характеристики GAT
Графика, состоящая из точек, линий, поверхностей и тел, представляет собой эффективный инструмент для понимания абстрактных концепций и выражения абстрактных идей. Преимущество графического языка заключается в его способности преодолевать языковые барьеры. Эта способность и технологии в основном развиты людьми для понимания мира. Быстрый прогресс в области информатики и искусственного интеллекта позволяет понять и изучить более глубокие объективные связи между вещами. Рождение графовой нейронной сети (GNN) помогает людям понимать и решать проблемы с помощью графики. Graph Attention Neural Network (GAT) — это специальная нейронная сеть, предназначенная для обработки графически структурированных данных. В отличие от традиционных нейронных сетей, GAT полностью учитывает взаимосвязь между данными при обработке входных данных, что позволяет более точно улавливать корреляцию между данными при обработке данных с графовой структурой. Основным преимуществом GAT является его способность автоматически изучать взаимосвязи между узлами без предварительной настройки вручную.
Основной принцип работы GAT — вычисление взаимосвязей между узлами с помощью механизма внимания. В традиционных нейронных сетях обновление статуса каждого узла выполняется независимо. В GAT обновление статуса каждого узла будет учитывать состояние его соседних узлов. GAT рассчитает вес внимания между узлом и его соседними узлами, а затем обновит статус узла на основе этого веса. Способ обновления информации путем расчета весов позволяет GAT лучше фиксировать структурную информацию в графе. Что касается вычисления весовых показателей и сбора информации, GAT использует механизм скрытого самообслуживания, аналогичный Transformer, который состоит из слоев внимания графа, сложенных вместе. Каждый слой внимания графа получает встраивания узлов в качестве входных данных и выводит преобразованные встраивания узла. будет обращать внимание на встраивание других узлов, с которыми он связан (Великович и др., 2017). В реальной работе GAT подсчет показателей внимания осуществляется с помощью структуры, называемой «голова внимания». Каждая головка внимания вычисляет набор оценок внимания, и в конечном результате результаты всех голов внимания усредняются или объединяются для получения окончательного внедрения узла. Преимущество этого заключается в том, что каждая голова внимания может сосредоточиться на различных функциях или шаблонах, что позволяет GAT захватывать больше информации. Конкретное математическое содержание будет объяснено в следующей статье.
Кроме того, GAT вводит концепцию объединения графов — метода выбора наиболее информативного подмножества узлов, которое может генерировать более различительные графы. В процессе объединения графов GAT использует обучаемый вектор проекции для расчета оценки проекции каждого узла, а затем выбирает оставшиеся узлы на основе оценки проекции. Этот подход может еще больше улучшить производительность GAT. Еще одна важная особенность GAT — слияние на уровне модели. При решении сложных проблем GAT может использовать различные источники информации посредством объединения на уровне модели. Эта способность позволила GAT показать свое превосходство во многих областях, включая распознавание изображений, обработку естественного языка и системы рекомендаций. При распознавании изображений GAT может эффективно управлять взаимоотношениями между пикселями изображения, тем самым повышая точность распознавания изображений. При обработке естественного языка GAT может эффективно обрабатывать взаимосвязи между словами в тексте, тем самым повышая точность понимания текста. В системе рекомендаций GAT может эффективно управлять отношениями между пользователями и продуктами, тем самым повышая точность рекомендаций.
1.2 Примеры GAT в жизни
Чтобы более интуитивно понять нейронную сеть внимания на графе (GAT), принцип ее работы и применения можно раскрыть на примере из реальной жизни.
На традиционных китайских свадьбах расстановка мест является важной задачей. Организаторам необходимо учитывать взаимоотношения между всеми гостями, чтобы каждому было приятно провести время на свадьбе. Этот процесс можно рассматривать как граф, где каждый гость представляет собой узел, а отношения между гостями представляют собой ребра. Цель организатора – найти оптимальную рассадку, чтобы гости за каждым столом могли гармонично ужиться.
В рамках GAT этот процесс моделируется как механизм внимания. Каждый узел (гость) представлен вектором, называемым встраиванием, который можно рассматривать как особенность или атрибут узла. В этом примере внедрения гостей могут включать информацию об их возрасте, поле, интересах и т. д. Механизм внимания работает путем вычисления сходства между каждым узлом (гостем) и другими узлами (другими гостями), чтобы определить важность каждого узла. Это сходство называется показателем внимания, который рассчитывается с помощью функции, называемой «скалярное произведение внимания». Чем выше показатель внимания, тем лучше связь между этим узлом и другими узлами и тем больше вероятность того, что они расположены в одном и том же положении. В этом примере два гостя могут сидеть за одним столом, если их оценка внимания высока. В ходе этого процесса GAT также учитывает лицо, ответственное за каждую таблицу. Это ответственное лицо должно иметь высокий показатель внимания, потому что ему нужно заботиться о каждом госте за столом и следить за тем, чтобы им всем понравилась свадьба. Это похоже на поиск наиболее важных узлов в графе.
Однако, как и в реальной рассадке свадебных мест, у GAT есть некоторые ограничения. Например, если гостей очень много, подсчитать оценку внимания каждого гостя может быть очень сложно. Кроме того, GAT может игнорировать некоторую важную информацию. Например, у некоторых гостей могут быть не очень хорошие отношения с другими, но они могут быть важными людьми на свадьбе. Это требует введения дополнительной информации при расчете оценки внимания, такой как статус гостей, их вклад в свадьбу и т. д.
В целом, GAT — мощный инструмент, который может помочь решить некоторые сложные проблемы. Однако необходимо понимать и его ограничения, а также учитывать специфику задачи при его использовании. Связав GAT с повседневным опытом, можно лучше понять и применить этот мощный инструмент. Далее в этой статье основное внимание будет уделено принципу работы GAT, а также принципам проектирования и математическим знаниям некоторых алгоритмов.
2 Как работает GAT
В этой статье кратко описывается принцип работы GAT, основанный на порядке, описанном в статье GAT Velickovic et al (2017). Если вы новичок в графическом отображении знаний, связанных с нейронными сетями, рекомендуется сначала перейти к команде DGL (2023) и команде LabML (2023), чтобы понять основные связанные работы.
GAT обычно состоит из нескольких однослойных слоев внимания графа. Ниже приводится объяснение однослойного слоя внимания графа. Ввод N точек и F признаков можно записать как:
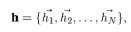
Вот
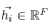
функции в качестве входных данных. Такой входной слой будет генерировать новые объекты для точек, поэтому выходной результат можно выразить как:
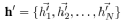
Вот
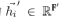
.Чтобы преобразовать входные объекты в многомерные объекты, требуется как минимум научное линейное преобразование. В (Великович и др., 2017) авторы использовали общий метод линейного преобразования для каждой точки и ввели весовую матрицу
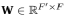
параметризовать линейные преобразования.
2.1 Механизм самообслуживания
В отличие от механизма внимания, самовнимание фокусируется на отношениях между каждой точкой и самой собой и отличается от важных отношений между каждой точкой. Вес выводится в соответствии с соответствующим отношением, а вес присваивается связи между точками. в соответствии с важными отношениями. В сочетании с W, упомянутым выше, (Великович и др., 2017) предложили механизм самовнимания.
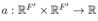
. Следовательно, для узла i важность признака узла j можно измерить по следующей формуле:
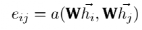
Такой механизм позволяет каждому узлу взаимодействовать друг с другом и исключает все структурированные новые сообщения.
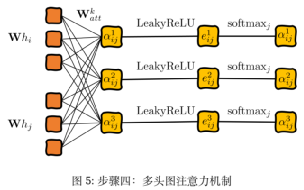
2.2 Механизм многоголового внимания (Многоголовое внимание)
По сравнению с вышеупомянутым способом обработки h1 в механизме с одним вниманием, механизм с несколькими головками получает h1k в каждой головке внимания. Значения признаков каждой головы в механизме внимания с несколькими головками объединяются, и объединенные признаки выражаются следующим образом:
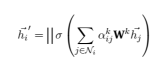
В рамках механизма внимания с несколькими головками окончательное выходное значение больше не будет F’-функциями, а KF’-функциями. При повторных расчетах результаты можно получить путем усреднения
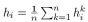
Или векторная конкатенация (Concatenation)
Для получения более подробных объяснений и математических выводов заинтересованные читатели могут продолжить обучение и исследования: (Graph Attention NetworksExperiment 2022; Graph Attention Networks 2022).
2.3 Пошаговая иллюстрация
В этой статье используется пример (LaBonne, 2022), чтобы лучше объяснить, как использовать упомянутые выше методы расчета в узлах. Метод расчета внутреннего внимания для узла 1:
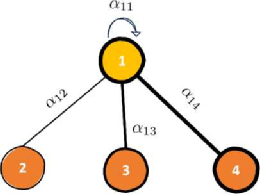
Рисунок 1: Пример иллюстрации
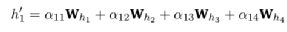
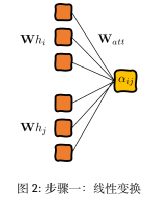
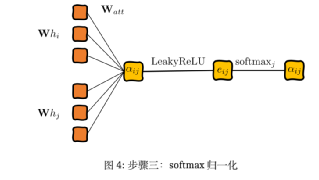
Среди них αij по-прежнему представляет собой важность взаимосвязи признаков между узлами, а hi — вектор атрибутов каждой точки. На основе описанного выше метода расчета механизм внимания графа рассчитает значение внедрения узла 1. Что касается обработки коэффициента корреляции внимания графа в формуле, нам нужно пройти «четыре шага» (LaBonne, 2022): линейное преобразование, функция активации, нормализация softmax и механизм многоголового внимания, чтобы использовать обучение нейронной сети и узел 1. Соответствующие оценки внимания.
Первым шагом является вычисление важности соединения между каждой точкой и точкой и создание пар скрытых векторов путем объединения векторов между двумя точками. Для этого примените линейное преобразование и весовую матрицу Ватта, чтобы добиться:
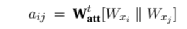
Второй шаг — добавить функцию активации LeakyReLU:
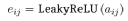
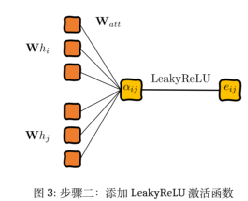
Третий шаг — нормализовать выходные результаты нейронной сети для облегчения сравнения:
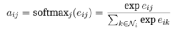
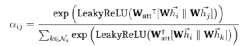
Нормированные показатели внимания можно подсчитать и сравнить, но при этом возникает новая проблема: внимание к себе очень нестабильно. Великович и др., 2017) предложили механизм внимания с несколькими головами, учитывая структуру трансформатора.
Четвертый шаг, в соответствии с упомянутым выше механизмом многоголового внимания, используется здесь для обработки и расчета комплексной доли внимания:
Применение 3GAT в задачах комбинаторной оптимизации
3.1 Задача комбинаторной оптимизации
Задача комбинаторной оптимизации является основной проблемой исследования операций, а также единственным способом для ученых начать изучение исследования операций. Задачи комбинаторной оптимизации являются основной областью компьютерных наук и исследований операций, включающей множество практических приложений, таких как логистика, планирование и проектирование сетей. Задачи комбинаторной оптимизации играют решающую роль во многих практических приложениях. Например, в сфере логистики задачи комбинаторной оптимизации могут помочь людям найти оптимальные маршруты распределения грузов в сложных условиях транспортировки, тем самым экономя транспортные расходы и повышая эффективность грузоперевозок. В задачах планирования комбинаторная оптимизация может помочь людям эффективно распределять ресурсы для удовлетворения различных ограничений, одновременно максимизируя или минимизируя требуемое целевое значение (часто называемое целевой функцией).
Однако традиционные алгоритмы комбинаторной оптимизации часто приходится разрабатывать с нуля для каждой новой задачи и требуют тщательного рассмотрения экспертами структуры задачи. Решение задач комбинаторной оптимизации обычно требует большого количества вычислительных ресурсов, особенно для задач, возникающих из реальности. Обычно масштаб самой проблемы очень велик, и традиционные алгоритмы оптимизации могут быть не в состоянии найти решение в течение разумного времени или даже. Решить в пределах досягаемости. Поэтому способы эффективного решения задач комбинаторной оптимизации всегда были в центре внимания исследователей. В последние годы использование цепей Маркова для построения динамического программирования может решить задачи комбинаторной оптимизации, сформулированные в виде однопользовательских игр, определяемых состояниями, действиями и вознаграждениями, включая минимальное связующее дерево, кратчайший путь, задачу коммивояжера (TSP) и задачу выбора маршрута транспортного средства. (ВРП) без экспертных знаний. Этот подход использует обучение с подкреплением для обучения нейронной сети внимания графа (GNN) на немаркированном обучающем наборе графов. Обученная сеть может выводить приближенные решения для новых экземпляров графа за линейное время работы. В задаче TSP GAT может эффективно учитывать соотношение расстояний между городами, чтобы найти кратчайший путь путешествия. В задаче VRP GAT может эффективно управлять взаимоотношениями между транспортными средствами, клиентами и складами, чтобы найти оптимальный маршрут доставки. Результаты этих исследований показывают, что GAT имеет большой потенциал в решении задач комбинаторной оптимизации.
3.2GAT бумажный футляр для планирования пути решения
(Kool et al., 2018) предложили модель, основанную на механизме внимания, аналогичном GAT, для решения различных задач планирования пути, включая TSP, VRP, OP и другие проблемы. В этой статье задача планирования пути (например, TSP) в основном строится как задача на основе графа, а местоположение каждой точки клиента в TSP и другая информация используются в качестве характеристик узла. С помощью кодера-декодера, основанного на механизме внимания, получается результат пути, который представляет собой случайную стратегию π(π|s). Используйте эту стратегию, чтобы найти метод наибольшего пути π в заданной точке тестовых данных. Этот метод параметризуется. по θ и распадается на:
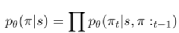
(10)
Процесс декодирования выполняется последовательно. На каждом временном шаге декодер выводит узел πt на основе внедрения кодера и выходных данных, сгенерированных во время. В процессе декодирования добавляется специальный узел контекста для представления контекста декодирования. Декодер вычисляет уровень внимания (под) поверх кодера, но для повышения эффективности отправляет сообщения только узлам контекста. Окончательная вероятность рассчитывается с использованием механизма внимания одной головы. В момент времени t контекст декодера поступает от кодера и вывода до момента t. Для TSP это включает в себя встраивание графа, предыдущего (последнего) узла πt-1 и первого узла π1. Также для расчета выходных вероятностей добавляется финальный слой декодера с одной головкой внимания. В статье оптимизируются потери L за счет градиентного спуска с использованием средства оценки градиента REINFORCE и базовой линии. В статье используется базовый план развертывания. Обновление базовой стратегии является циклическим, и это также лучшая стратегия определения модели для детерминированных жадных решений развертывания.
В статье также подробно обсуждаются стратегии обработки для различных задач. Например, для задачи коммивояжера по сбору вознаграждений (PCTSP) автор использует отдельные параметры в кодировщике для обработки узлов склада и предоставляет вознаграждения и штрафы узлов в качестве входных функций. В контексте декодера авторы использовали текущую/последнюю позицию и оставшуюся награду для сбора. В PCTSP, если оставшееся вознаграждение больше 0 и все узлы не посещены, то узел хранилища невозможно посетить. Только когда узел будет посещен, он будет заблокирован (то есть его нельзя будет посетить).
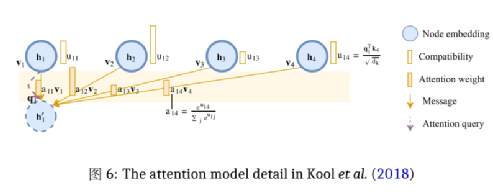
Из-за ограничений по объему в этой статье основное внимание уделяется только тому, как Kool et al (2018) создают алгоритм передачи взвешенной информации между узлами в TSP на основе механизма внимания графа. В графе, построенном в этой статье, взвешенная информация, получаемая узлом, исходит от него самого и окружающих его соседей. Информационная ценность этих битов узла зависит от совместимости его запроса с ключом соседа, как показано на рисунке 6. Автор определяет dk, dv, проектирует и вычисляет соответствующие kiε ℝdk, viε ℝdv, qiε ℝdk. Для соответствующих qi, ki, vi всех точек используется следующий метод вычисления проекции и вложения в hi:
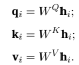
Среди них WQ и WK — два набора матриц параметров размерами dk × dh, а размер WV равен (dv × dh) (рекомендуется читателям, которые хотят узнать больше о настройках и методах расчета q, k). , v в Трансформере, зайдите в WMathor (2020))
Совместимость между двумя точками достигается путем расчета значения uij между qi узла i и kj точки j (Великович и др., 2017):
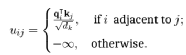
Установка -∞ позволяет избежать передачи информации друг другу несвязными точками. Благодаря совместимости конструкции, аналогичной eij в Velickovic et al (2017), Халил и др. (2017) рассчитывают вес внимания aij следующим образом:
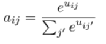
В конце концов узел i получит вектор h’i, который содержит выпуклую комбинацию вектора vj:
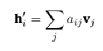
4 Заключение
4.1 Будущее развитие и перспективы применения GAT
Способность сетей внимания на графах (GAT) решать задачи комбинаторной оптимизации, особенно задачу коммивояжера (TSP) и задачу выбора маршрута транспортного средства (VRP), была широко продемонстрирована. Однако следует также отметить, что хотя ГАТ и показало превосходство в этих вопросах, оно не всесильно. Для некоторых конкретных проблем может потребоваться разработка конкретных моделей или алгоритмов для их решения. Поэтому при изучении задачи необходимо выбирать подходящие инструменты для решения различных задач комбинаторной оптимизации, исходя из конкретных условий задачи и решающих характеристик GAT.
GAT также играет разные роли в других областях. Например, Чжан и др. (2022) предложили новую архитектуру GAT, которая может отражать потенциальную корреляцию между знаниями графов в разных масштабах. Эта новая архитектура GAT превосходит традиционную модель GAT как по точности прогнозирования, так и по скорости обучения.
Кроме того, Шао и др. (2022) предложили новую динамическую модель внимания с несколькими графами, которая может решать проблемы долгосрочного пространственно-временного прогнозирования. Эта модель представляет контекстную информацию каждого узла путем построения новой графовой модели и использует долгосрочную пространственно-временную структуру зависимости данных. Эксперименты с этим методом на двух крупномасштабных наборах данных показывают, что он может значительно улучшить производительность существующих графовых моделей нейронных сетей в задачах долгосрочного пространственно-временного прогнозирования.
GAT также широко используется в прогнозировании фондового рынка. Чжао и др. (2022) предложили метод прогнозирования движения запасов, основанный на сетях двойного внимания. Сначала был построен граф знаний о рынке, содержащий два типа организаций (включая листинговые компании и связанных с ними руководителей) и смешанные отношения (включая явные и неявные отношения). Затем предлагается сеть двойного внимания, с помощью которой можно изучить сигнал переполнения импульса на графике знаний рынка для прогнозирования акций. Результаты экспериментов показывают, что предлагаемый метод превосходит девять современных базовых методов прогнозирования запасов.
В целом, графическая перспектива предоставляет исследованиям совершенно новый способ понимания и решения проблем. Осмысление и преобразование существующих проблем в графическую форму может не только раскрыть новые аспекты и характеристики проблемы, но также может привести к новым инновациям. Точно так же графическое размышление о новых проблемах может принести неожиданную выгоду. Преимущество этого подхода в том, что он помогает ученым лучше понять структуру и сложность проблемы и, таким образом, найти более эффективные решения. Я надеюсь, что, начиная с этого введения в GAT, вы сможете больше узнать о принципах графовых нейронных сетей и больше применять их в своем обучении и исследованиях. Использование GAT может оказать надежную поддержку при решении проблем.
Об авторе
Автор, Дэн Ян, является аспирантом, прошедшим совместное обучение в Школе менеджмента Сианьского университета Цзяотун и Школе системной инженерии Городского университета Гонконга. Его исследовательское направление — применение обучения с подкреплением в городской логистике. Окончил с отличием степень магистра в области транспортного машиностроения в Университете Южной Калифорнии. Когда-то он работал в лос-анджелесском офисе инженерно-консалтинговой компании HATCH и является зарегистрированным EIT в Калифорнии. Он завоевал такие титулы, как «Тридцать выдающихся молодых предпринимателей младше тридцати лет» по версии AACYF в 2017 году и «Десять выдающихся китайско-американских молодых людей в Соединенных Штатах» в 2019 году. В настоящее время он является вице-президентом Федерации зарубежных китайцев Баотоу, членом Федерации зарубежных китайцев и Европейской и Американской ассоциации выпускников.
References
1.DGL Team. 9 Graph Attention Network (GAT) Deep Graph Library (DGL). https: //docs .dgl.ai/ en/0.8.x/tutorials/models/1_gnn/9_gat.html (2023).
2.Graph Attention Networks LabML. https://nn.labml.ai/graphs/gat/index.html (2023).
3.Graph Attention Networks Experiment LabML. https://nn.labml.ai/graphs/gat/experiment. html (2023).
4.Khalil, E., Dai, H., Zhang, Y., Dilkina, B. & Song, L. Learning combinatorial optimization algorithms over graphs. Advances in neural information processing systems 30 (2017).
5.Kool, W., Van Hoof, H. & Welling, M. Attention, learn to solve routing problems! arXiv preprint arXiv:1803.08475 (2018).
6.LabML Team. Graph Neural Networks LabML. https://nn.labml.ai/graphs/index.html (2023).
7.LaBonne, M. Graph Attention Networks: Theoretical and Practical Insights https : / / mlabonne . github.io/blog/posts/2022-03-09-graph_attention_network.html (2023).
8.Shao, W., Jin, Z., Wang, S., Kang, Y., Xiao, X., Menouar, H., Zhang, Z., Zhang, J. & Salim, F. Long-term Spatio-Temporal Forecasting via Dynamic Multiple-Graph Attention. arXiv preprint arXiv:2204.11008 (2022).
9.Velickovic, P., Cucurull, G., Casanova, A., Romero, A., Lio, P., Bengio, Y., et al. Graph attention networks. stat 1050, 10–48550 (2017).
10.WMathor. Graph Attention Networks https://wmathor.com/index.php/archives/1438/ (2023).
11.Zhang, W., Yin, Z., Sheng, Z., Li, Y., Ouyang, W., Li, X., Tao, Y., Yang, Z. & Cui, B. Graph attention multilayer perceptron in Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (2022), 4560–4570.
12.Zhao, Y., Du, H., Liu, Y., Wei, S., Chen, X., Zhuang, F., Li, Q. & Kou, G. Stock Movement Prediction Based on Bi-Typed Hybrid-Relational Market Knowledge Graph Via Dual Attention Networks. IEEE Transactions on Knowledge and Data Engineering (2022).REFERENCES
Монтажер: Ван Цзин
Знакомство с исследовательским отделом Datapai
данные Исследовательский отдел Pai был создан в начале 2017 года.,кИнтерес как основаРазделить на несколько групп,Каждая группа следует общей задаче исследовательского отдела.Обмен знаниямииПрактика планирования проектов,Каждый имеет свои особенности:
Группа моделей алгоритма:Активно формируйте команду для участияkaggleВ ожидании игры,Оригинальная серия статей с пошаговыми инструкциями;
Группа исследований и анализа:Исследование посредством интервью и других методов.данные Приложение,Откройте для себя красоту продуктов данных;
Группа системных платформ:отслеживать большойданные&Технологический рубеж платформы системы искусственного интеллекта,эксперт по разговорам;
Группа обработки естественного языка:Важнее практики,Активно участвовать в конкурсах и планировать различные проекты по анализу текста;
Группа больших данных производства:Придерживайтесь мечты о промышленной мощи,Сочетание промышленности, научных кругов, исследований и правительства,Узнайте ценность данных;
Группа визуализации данных:Объединение информации и искусства,Откройте для себя красоту данных,Научитесь рассказывать истории визуально;
Группа веб-сканеров:Сканировать информацию о сети,Сотрудничайте с другими группами для разработки творческих проектов.
Нажмите «Прочитать оригинальный текст» в конце статьи, чтобы записаться волонтёром отдела исследования данных. Всегда найдется подходящая для вас группа~.
Инструкция по перепечатке
Если вам необходимо перепечатать, укажите автора и источник на видном месте в начале статьи (перепечатано из: Datapi THUID: DatapiTHU) и разместите привлекательный QR-код Datapi в конце статьи. Если у вас есть статьи с оригинальным логотипом, отправьте [Название статьи — имя и идентификатор публичной учетной записи, подлежащей авторизации] на контактный адрес электронной почты, чтобы подать заявку на авторизацию в белом списке, и отредактируйте его при необходимости.
Несанкционированная перепечатка и адаптация будут преследоваться за юридическую ответственность в соответствии с законом.


RasaGpt — платформа чат-ботов на основе Rasa и LLM.

Nomic Embed: воспроизводимая модель внедрения SOTA с открытым исходным кодом.

Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Малые цели имеют очевидные преимущества | ICASSP2023

Урок 1 серии Libtorch: Тензорная библиотека Silky C++

Руководство по локальному развертыванию Stable Diffusion: подробные шаги и анализ распространенных проблем

Полностью автоматический инструмент для работы с видео в один клик: VideoLingo

Улучшения оптимизации RT-DETR: облегченные улучшения магистрали | Support Paddle облегченный rtdetr-r18, rtdetr-r34, rtdetr-r50, rtdet

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | Деформируемое внимание с большим ядром (D-LKA Attention), большое ядро свертки улучшает механизм внимания восприимчивых полей с различными функциями

Создано Datawhale: выпущено «Руководство по тонкой настройке развертывания большой модели GLM-4»!

7B превышает десятки миллиардов, aiXcoder-7B с открытым исходным кодом Пекинского университета — это самая мощная модель большого кода, лучший выбор для корпоративного развертывания.

Используйте модель Huggingface, чтобы заменить интерфейс внедрения OpenAI в китайской среде.

Оригинальные улучшения YOLOv8: несколько новых улучшений | Сохранение исходной информации — алгоритм отделяемой по глубине свертки (MDSConv) |

Второй пилот облачной разработки | Быстро поиграйте со средствами разработки на базе искусственного интеллекта

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция с нулевым кодированием и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

Решенная Ошибка | Загрузка PyTorch медленная: TimeoutError: [Errno 110] При загрузке факела истекло время ожидания — Cat Head Tiger

Brother OCR, библиотека с открытым исходным кодом для Python, которая распознает коды проверки.
Новейшее подробное руководство по загрузке и использованию последней демонстрационной версии набора данных COCO.

Выпущен отчет о крупной модели финансовой отрасли за 2023 год | Полный текст включен в загрузку |

Обычные компьютеры также могут работать с большими моделями, и вы можете получить личного помощника с искусственным интеллектом за три шага | Руководство для начинающих по локальному развертыванию LLaMA-3

Одной статьи достаточно для анализа фактора транскрипции SCENIC на Python (4)

Бросая вызов ограничениям производительности небольших видеокарт, он научит вас запускать большие модели глубокого обучения с ограниченными ресурсами, а также предоставит полное руководство по оценке и эффективному использованию памяти графического процессора!

Команда Fudan NLP опубликовала 80-страничный обзор крупномасштабных модельных агентов, в котором в одной статье представлен обзор текущего состояния и будущего агентов ИИ.

[Эксклюзив] Вы должны знать о новой функции JetBrains 2024.1 «Полнострочное завершение кода», чтобы решить вашу путаницу!

Краткое изложение базовых знаний о регистрации изображений 1.0

Новейшее подробное руководство по установке и использованию библиотеки cv2 (OpenCV, opencv-python) в Python.

Легко создайте локальную базу знаний для крупных моделей на основе Ollama+AnythingLLM.

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание решения. Повторная попытка с помощью файла (графическое руководство).

Одна статья поможет вам понять RAG (Retrival Enhanced Generation) | Введение в концепцию и теорию + практику работы с кодом (включая исходный код).

Эволюция архитектуры шлюза облачной разработки
