Оригинальные улучшения YOLOv8: несколько новых улучшений | Сохранение исходной информации — алгоритм отделяемой по глубине свертки (MDSConv) |
💡💡💡В этой статье представлены самоисследования, инновации и улучшения: Улучшение 1) Сохранение исходной информации — свертка с разделением по глубине (MDSConv), которая решает проблему невозможности взаимодействия с информацией между исходными каналами векторного слоя (например, классическая сетка с разделением по глубине). свертка);
Улучшение 2) Предложить алгоритм быстрой глобальной пространственной пирамиды рецептивных полей (Improve-SPPF) для интеграции локальных рецептивных полей и глобальных рецептивных полей для уменьшения воздействия различных масштабов;
Улучшение 3) Улучшенная версия CA: решена проблема, связанная с тем, что механизм внимания CA не эффективно использует важную информацию. Поэтому разработана система координатного внимания «включай и работай», которая сочетает в себе среднее и максимальное объединение;
Улучшение 4) На основе улучшенной версии MDSConv и CA создана структура, которая поддерживает исходный уровень разделения глубины информации (MDSLayer) для защиты обширной информации между каналами без ухудшения качества;
включено
YOLOv8 оригинальный и самостоятельно разработанный
💡💡💡Эксклюзивная первая новинка (оригинал) во всей сети, подходит для бумаги! ! !
💡💡💡 Нововведения Саммита компьютерного зрения 2024 года применимы к Yolov5, Yolov7, Yolov8 и другим сериям Yolo. В статье в рубрике представлены все этапы и исходный код, которые помогут вам легко приступить к волшебному изменению сети! ! !
💡💡💡Ключевой момент: прочитав эту колонку, вы также сможете в будущем спроектировать волшебную сеть, выполнять волшебные изменения в разных местах сети (магистральная, головная, обнаружение, потеря и т. д.) для достижения инноваций! ! !
2. Как присоединиться к YOLOv8
2.1 Создайте новый ultralytics/nn/block/MD.py
import torch
from torch import nn
import warnings
class BaseConv(nn.Module):
def __init__(self, in_channels, out_channels, ksize, stride, groups=1, bias=False, act="silu"):
super().__init__()
pad = (ksize - 1) // 2
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=ksize, stride=stride, padding=pad, groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001, momentum=0.03)
self.act = get_activation(act, inplace=True)
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class SiLU(nn.Module):
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
def get_activation(name="silu", inplace=True):
if name == "silu":
module = SiLU()
elif name == "relu":
module = nn.ReLU(inplace=inplace)
elif name == "lrelu":
module = nn.LeakyReLU(0.1, inplace=inplace)
else:
raise AttributeError("Unsupported act type: {}".format(name))
return module2.2 yolov8_improve_sppf.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, improve_sppf, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
2.4 yolov8_improve_CA.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, improve_CA, [1024]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
2.5 yolov8_MDSConv.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [15, 1, MDSConv, [64,3]] # 22
- [18, 1, MDSConv, [128,3]] # 23
- [21, 1, MDSConv, [256,3]] # 24
- [[22, 23, 24], 1, Detect, [nc]] # Detect(P3, P4, P5)
от CSDN AI, маленький монстр

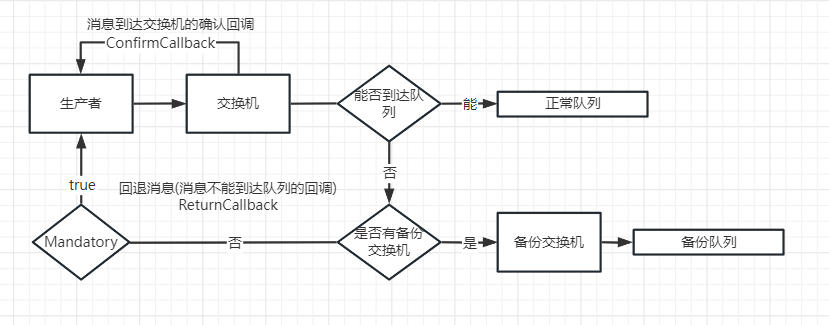
Подробное объяснение механизма подтверждения выпуска сообщений RabbitMQ.

На этот раз полностью поймите протокол ZooKeeper.

Реализуйте загрузку файлов с использованием минимального WEB API.

Демо1 Laravel5.2 — генерация и хранение URL-адресов
Spring boot интегрирует Kafka и реализует отправку и потребление информации (действительно при личном тестировании)
Мысли о решениях по внутренней реализации сортировки методом перетаскивания

Междоменный доступ к конфигурации nginx не может вступить в силу. Междоменный доступ к странице_Page

Как написать текстовый контент на php

PHP добавляет текстовый водяной знак или водяной знак изображения к изображениям – метод инкапсуляции
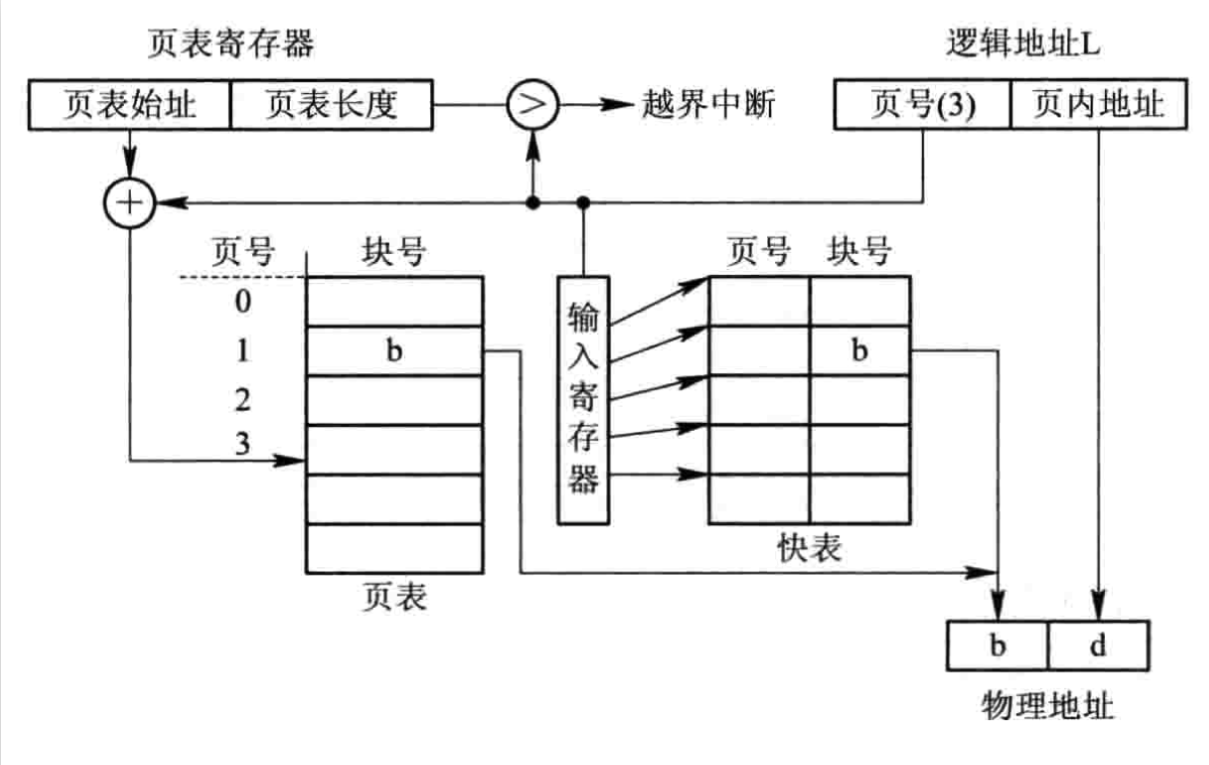
Интерпретация быстрой таблицы (TLB)

Интерфейс WeChat API (полный) — оплата WeChat/красный конверт WeChat/купон WeChat/магазин WeChat/JSAPI

Преобразование Java-объекта в json string_complex json-строки в объект

Примените сегментацию слов jieba (версия Java) и предоставьте пакет jar

matinal: Самый подробный анализ управления разрешениями во всей сети SAP. Все управление разрешениями находится здесь.
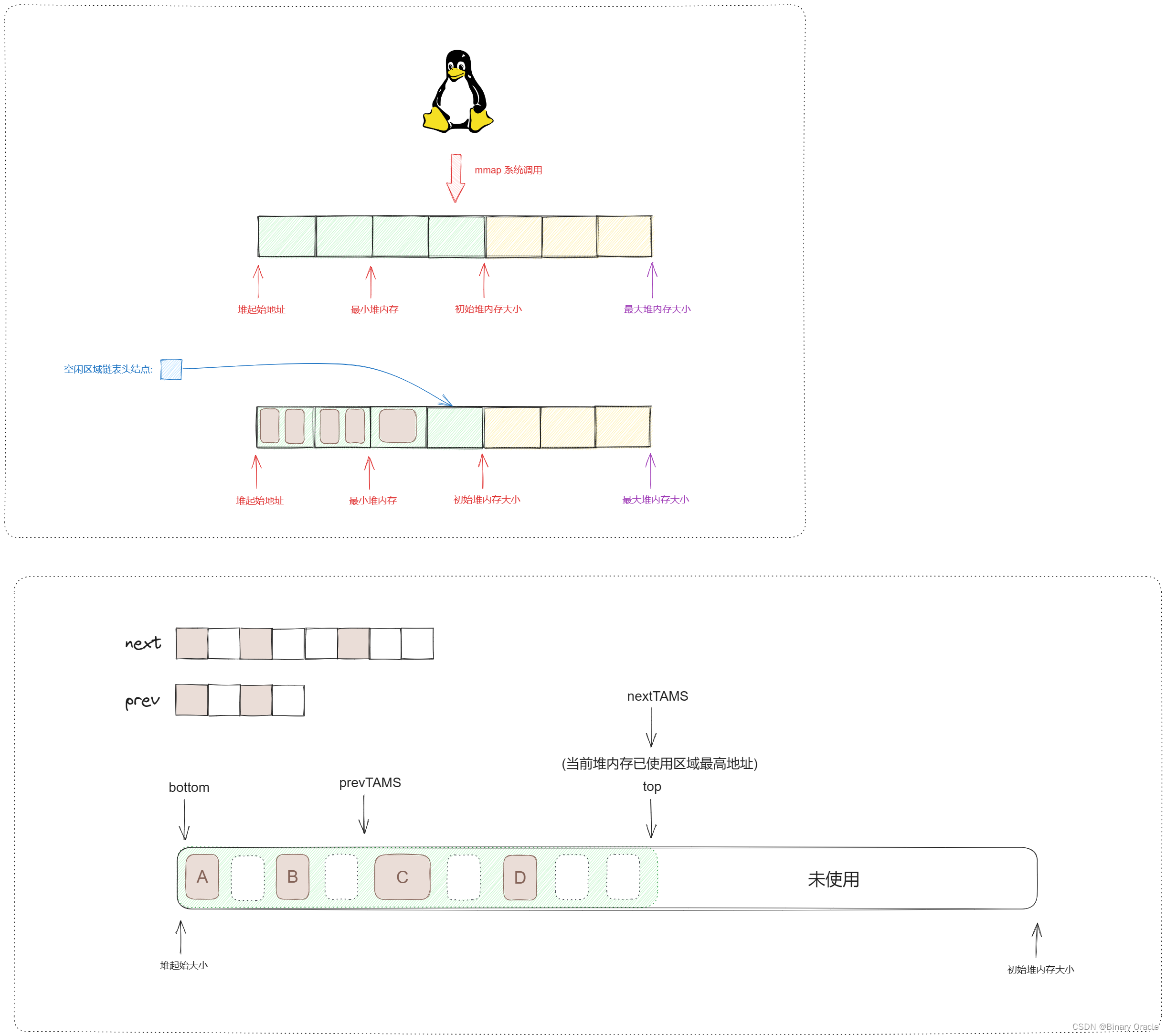
Коротко расскажу обо всем процессе работы алгоритма сборки мусора G1 --- Теоретическая часть -- Часть 1
[Спецификация] Результаты и исключения возврата интерфейса SpringBoot обрабатываются единообразно, поэтому инкапсуляция является элегантной.

Интерпретация каталога веб-проекта Flask

Что такое подробное объяснение файла WSDL_wsdl

Как запустить большую модель ИИ локально
Подведение итогов десяти самых популярных веб-фреймворков для Go
5 рекомендуемых проектов CMS с открытым исходным кодом на базе .Net Core

Java использует httpclient для отправки запросов HttpPost (отправка формы, загрузка файлов и передача данных Json)

Руководство по развертыванию Nginx в Linux (Centos)

Интервью с Alibaba по Java: можно ли использовать @Transactional и @Async вместе?

Облачный шлюз Spring реализует примеры балансировки нагрузки и проверки входа в систему.

Используйте Nginx для решения междоменных проблем

Произошла ошибка, когда сервер веб-сайта установил соединение с базой данных. WordPress предложил решение проблемы с установкой соединения с базой данных... [Легко понять]

Новый адрес java-библиотеки_16 топовых Java-проектов с открытым исходным кодом, достойных вашего внимания! Обязательно к просмотру новичкам

Лучшие практики Kubernetes для устранения несоответствий часовых поясов внутри контейнеров