[Оригинал] Узнайте о происхождении, развитии и границах RAG в одной статье.

Генерация улучшений поиска(Retrieval Augmented Генерация, RAG) в сочетании с поиском (Retrieval) и генерировать (Generation) Два процесса, предназначенные для повышения релевантности, точности и разнообразия машинно-генерируемого текста. RAG облегчает проблему галлюцинаций, извлекая большой объем соответствующей информации перед созданием текстового вывода, а затем передавая эту полученную информацию в качестве контекста в генеративную модель.
Глубокое обучение обработке естественного языка Оригинал Автор: Фрэнк Guan
Иллюзия – дилемма, стоящая перед большими моделями
Хотя чисто генеративные модели, особенно основанные на больших языковых моделях, превосходно генерируют связный и беглый текст, они иногда выдают информацию, не согласующуюся с фактами. Это явление называется галлюцинацией. Галлюцинации часто возникают из-за того, что информация, полученная моделью во время обучения, является неполной или модель слишком самоуверенна, пытаясь создать контент, который кажется разумным, но на самом деле не основан на реальной информации.

Проблема иллюзий также подразумевает, что большая модель представляет собой черный ящик, что делает непрактичным развертывание больших моделей в реальных условиях без дополнительных мер безопасности.

Как решить проблему галлюцинаций?
Что касается проблемы галлюцинаций, предшественники пытались разными способами ее облегчить. Вот несколько распространенных решений: (1) Предопределенные шаблоны ввода Создавайте предопределенные шаблоны, такие как шаблоны подсказок и шаблоны вопросов, чтобы пользователи могли строить запросы таким образом, который будет более способствовать пониманию модели. Было показано, что это повышает точность запросов. Ниже приведен пример предопределенного шаблона langchain:

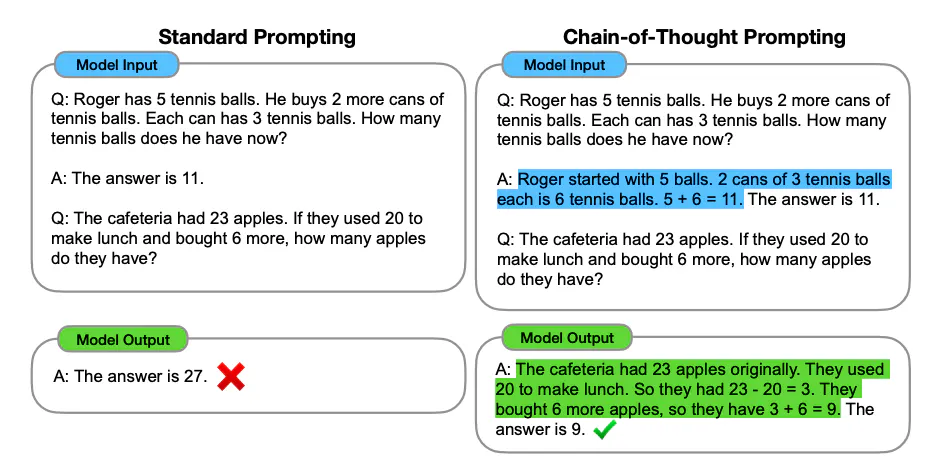
(2) Рассуждение Вывод цепочки мыслей (CoT) — это метод, используемый для повышения производительности больших языковых моделей при решении сложных задач, особенно тех, которые требуют многоэтапных рассуждений. Он решает проблему, направляя модель на создание серии интерпретативных промежуточных шагов, а не на непосредственную генерацию окончательного ответа. Этот метод позволяет не только повысить точность ответов, но и в определенной степени облегчить проблему галлюцинаций.
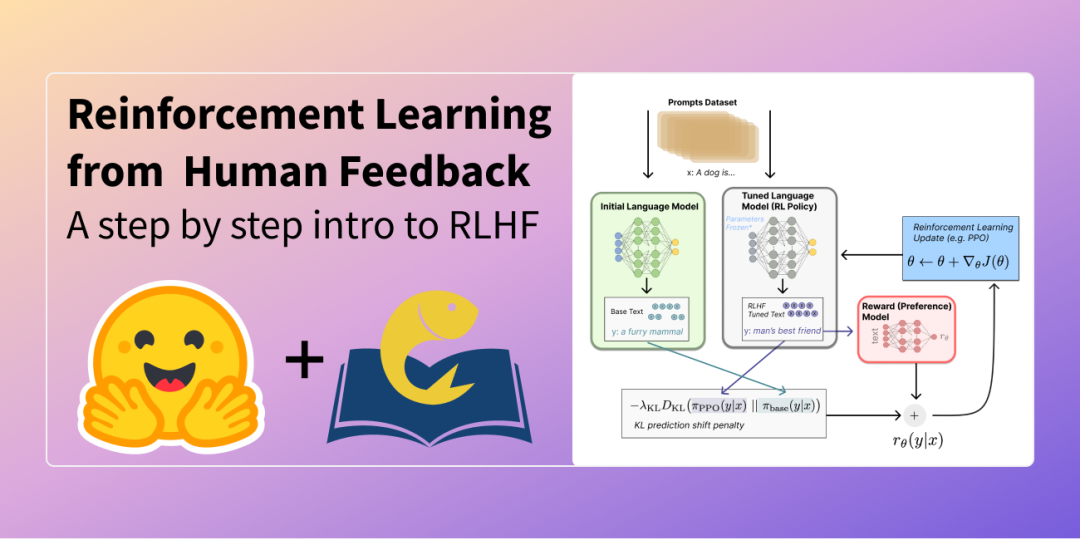
(3) Обратная связь Обучение с подкреплением на основе обратной связи с человеком (RLHF) — это метод повышения производительности больших языковых моделей путем объединения обратной связи с человеком и обучения с подкреплением для точной настройки модели. Этот метод позволяет оценщикам напрямую указывать на ошибки посредством отрицательной обратной связи и особенно эффективен для решения проблемы галлюцинаций в генеративных моделях.
(4) Конфигурация и поведение модели На сгенерированный результат сильно влияют различные параметры модели, такие как температура, top-p и т. д. Более высокие значения температуры способствуют случайности и творчеству, а более низкие значения температуры делают результат более детерминированным. Эти параметры обеспечивают гибкость для точной настройки и обеспечивают баланс между созданием разнообразных ответов и обеспечением точности.
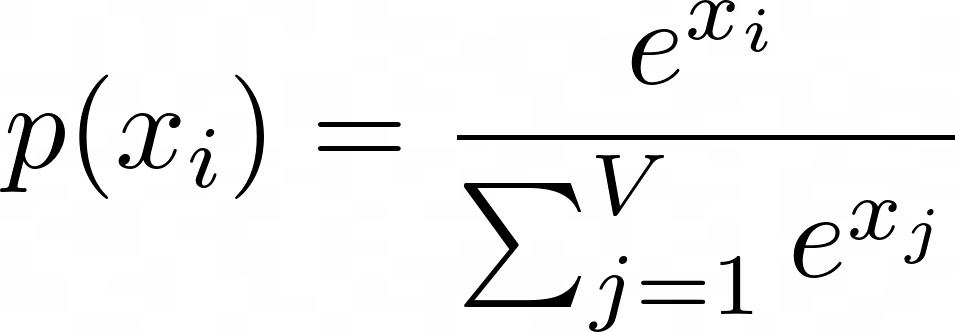
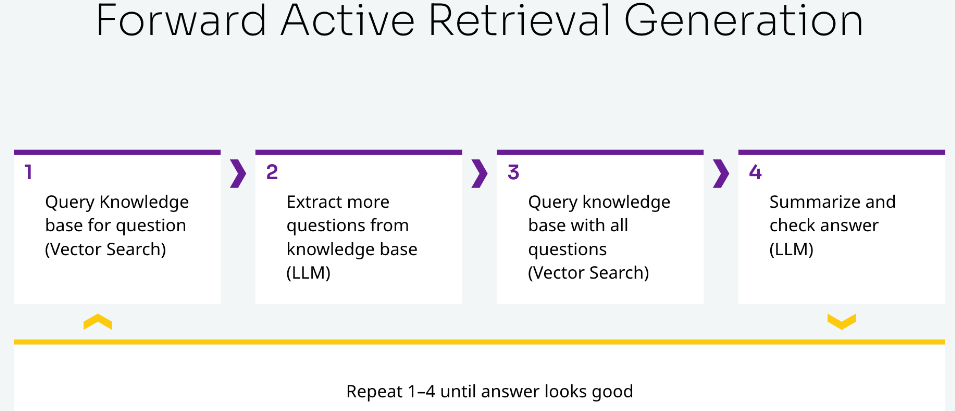
(5) Итерационный запрос (Итерация) Агенты ИИ выполняют итеративные запросы к большим языковым моделям. Повторение несколько раз может помочь нам получить лучший ответ. Когда пользователь задает вопрос, большая языковая модель запрашивает в базе знаний похожие вопросы. Затем запросите базу данных векторов со всеми вопросами, обобщите ответы и проверьте, выглядят ли ответы разумными. Если разумный ответ не найден, эти шаги повторяются до тех пор, пока он не будет найден.
Генерация улучшений поиска
Генерация улучшений поиск (RAG) — это метод вспомогательной генерации текста с использованием информации из внешних источников данных. Это практика объединения поиска с генерацией, получение соответствующей информации путем доступа к внешним библиотекам данных (обычно возвращающих необходимую информацию в виде фрагментов). Объедините полученную информацию с вопросами, исходными от пользователя, в подсказки, что позволит Big Language Model изучать знания из подсказок, содержащих внешнюю информацию (в контексте обучение) и дать правильный ответ. [Льюис et al., 2020]

Пользователи спрашивают большие языковые модели о недавних громких событиях, таких как OpenAI и Elon. Маска). Поскольку Великая Модель ограничена данными предварительного обучения, ей не хватает знаний о недавних событиях. Генерация улучшений поиска Модель Этот пробел восполняется за счет получения последних выдержек из документов из внешней базы знаний.。Например,Он получил новостные статьи, связанные с расследованием. Эти статьи затем объединяются с исходным вопросом в обширную подсказку.,Позволяет большой модели синтезировать правильный ответ.
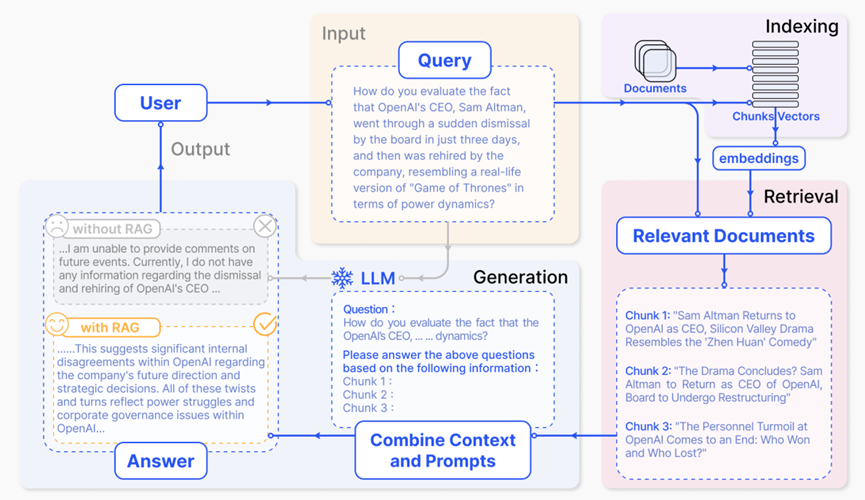
Картинка из бумаги:Gao, Yunfan, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. "Retrieval-Augmented Generation for Large Language Models: A Survey." arXiv e-prints (2023): arXiv-2312.
Основные компоненты RAG
(1) База данных векторов (Вектор Database) Библиотека векторных данных — это система библиотеки данных, специально разработанная для эффективного хранения и извлечения векторных данных. Данные часто существуют в форме многомерных векторов, таких как текст, изображения или другие типы данных, которые преобразуются в векторы путем внедрения модели. Эти векторы представляют характеристики и семантическую информацию исходных данных и могут использоваться для различных задач поиска по сходству и анализа данных. Библиотека векторных данных обеспечивает эффективный способ обработки крупномасштабной сбора векторов путем оптимизации структуры хранения и алгоритма извлечения таких векторных данных. Генерация улучшений Ключевым шагом в поиске Модели является извлечение соответствующей информации из крупномасштабных коллекций данных, которая впоследствии используется для генерации ответов по Модели. Библиотека векторных данных может быстро получить вектор данных, наиболее похожий на вектор запроса, что значительно ускоряет процесс и повышает эффективность и точность поиска информации. (2) Поиск запроса (Retriever) В поколении улучшений Поиск — это процесс, в котором искатель извлекает наиболее релевантную информацию для данного запроса из крупномасштабной коллекции документов или базы знаний путем сравнения представления запроса (обычно вектора) с каждым документом в сборе документов. Представление выполнено. через ретривер, Генерация улучшений система поиска имеет доступ к более широкому спектру информации, которая обновляется в режиме реального времени, тем самым расширяя объем знаний Модели при решении проблем. Цель — найти информацию, которая лучше всего поможет сгенерировать системный ответ на запрос.
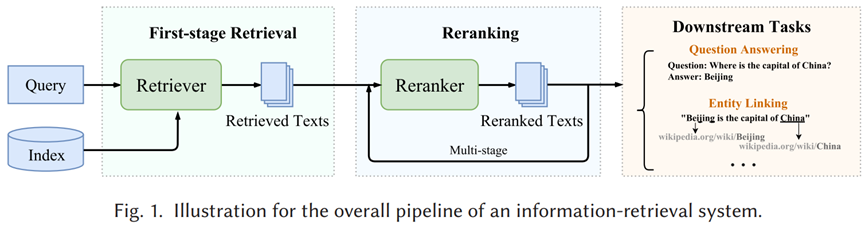
Картинка из бумаги:Zhao, W. X., Liu, J., Ren, R., & Wen, J. R. (2024). Dense text retrieval based on pretrained language models: A survey. ACM Transactions on Information Systems, 42(4), 1-60.
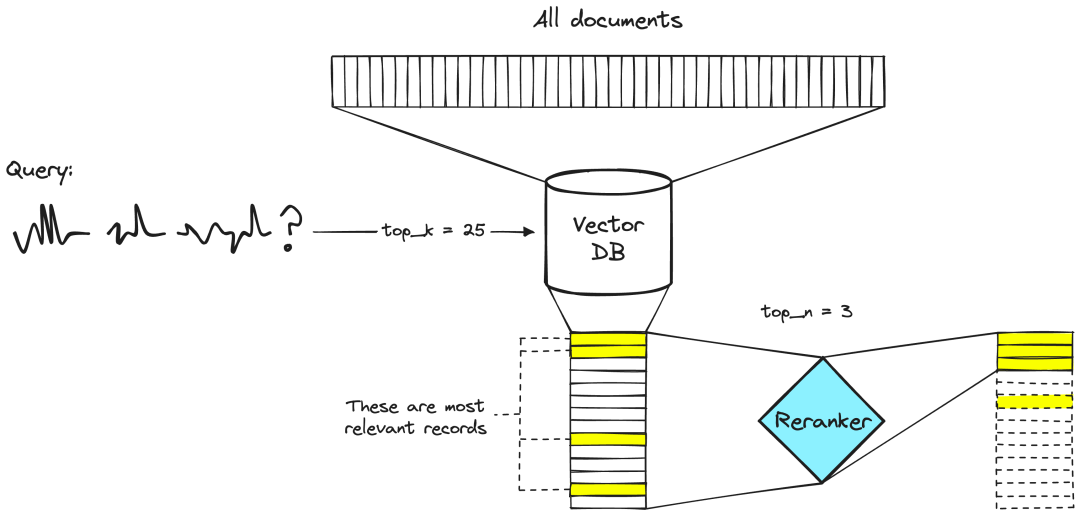
(3) Изменение рейтинга Мы можем выполнять семантический поиск во многих текстовых документах, возможно, от десятков тысяч до десятков миллиардов связанных документов. Однако, поскольку большие языковые модели имеют ограничения на объем передаваемого текста, нам необходимо отсортировать качество документа, а затем вернуть документы top-k для следующего этапа поиска и генерации. В реранкере по паре запрос-документ выводится оценка сходства. Мы используем эту оценку для изменения порядка документов в зависимости от их релевантности нашему запросу.
(4) Сгенерировать ответ (Генератор) Целое поколение улучшений В системе поиска генератор — это компонент, ответственный за генерацию окончательного текстового вывода на основе полученной информации. Он использует полученную информацию для построения ответов или выполнения конкретных задач по генерации текста. Генератор учитывает несколько полученных документов или фрагментов информации и объединяет их содержимое для создания последовательного, логически последовательного вывода. Этот процесс включает в себя все аспекты языкового производства, включая выбор словарного запаса, грамматическую структуру и связность содержания. Потому что поколение улучшений определение не только используется для рассуждений о фактах, но также может использоваться для генерации кодов, изображений и т. д. Поэтому, сталкиваясь с различными последующими задачами, Модель-генератор вывела множество вариантов. TransformerModel часто используется в задачах генерации текста; VisualGPT часто используется для генерации текстовых описаний из изображений; Diffusion в основном используется для создания изображений на основе текстовых подсказок; Codex фокусируется на создании кода из текстовых описаний;
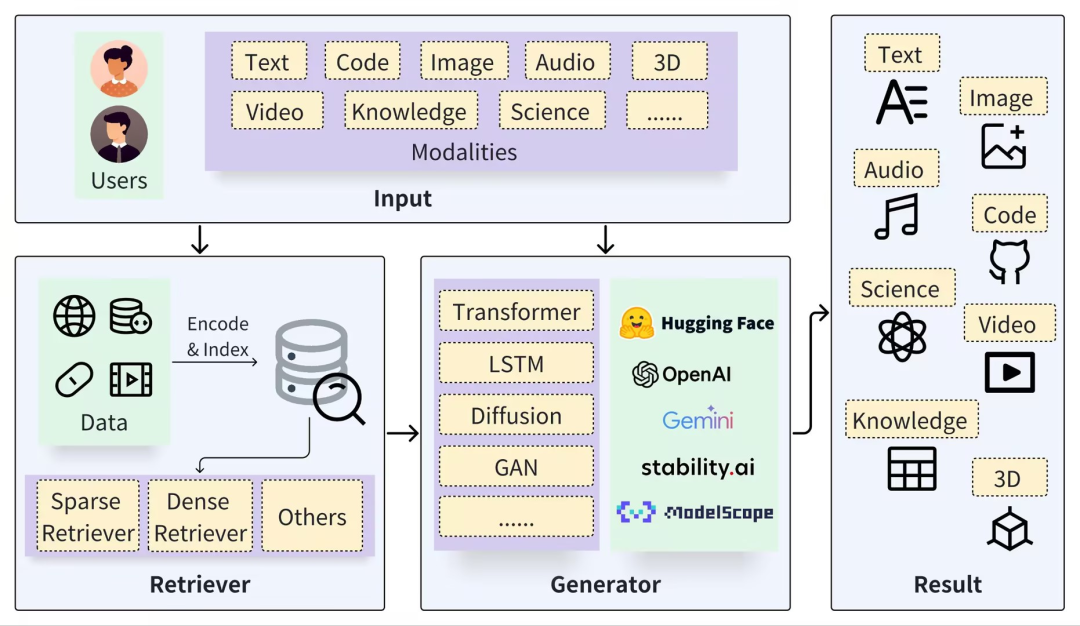
Картинка из бумаги:https://github.com/hymie122/RAG-Survey
Генерация улучшений поискапередовой
(1)RAG + Knowledge Graph Во-первых, мы можем использовать большие языковые модели для извлечения ключевых сущностей из вопросов пользователей. Подграфы затем извлекаются на основе этих объектов. Наконец, большая модель использует полученный контекст (информацию о матрице смежности сущностей) для генерации ответов.
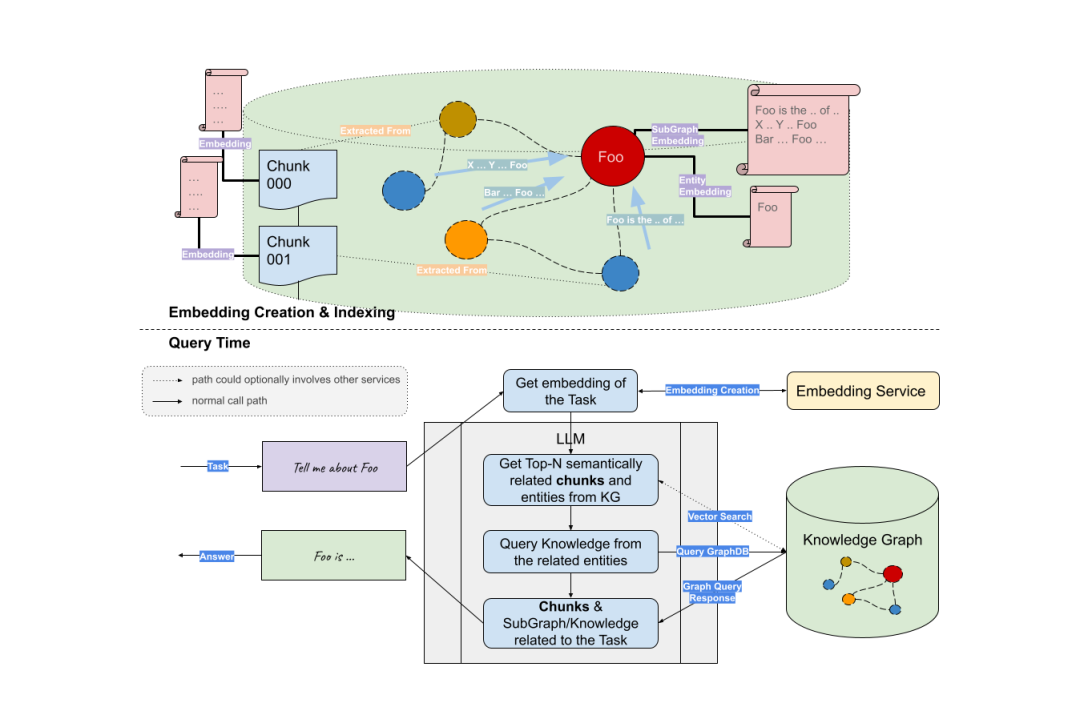
Ссылки:https://siwei.io/graph-rag/
(2)RAG + Tree В статье представлены новые методы рекурсивного встраивания, кластеризации и суммирования текстовых блоков, построения деревьев с разными уровнями суммирования снизу вверх. Первоначально корпус поиска разбивается на короткие непрерывные тексты длиной 100. Затем используйте SBERT для встраивания предложений. Чтобы сгруппировать похожие блоки текста, можно использовать алгоритмы кластеризации. После кластеризации для обобщения сгруппированных текстов используется языковая модель. Текст этих сводок затем повторно встраивается. Этот процесс продолжается до тех пор, пока дальнейшая кластеризация не станет невозможной. Итак, у нас есть структурированное многоуровневое древовидное представление исходного документа.
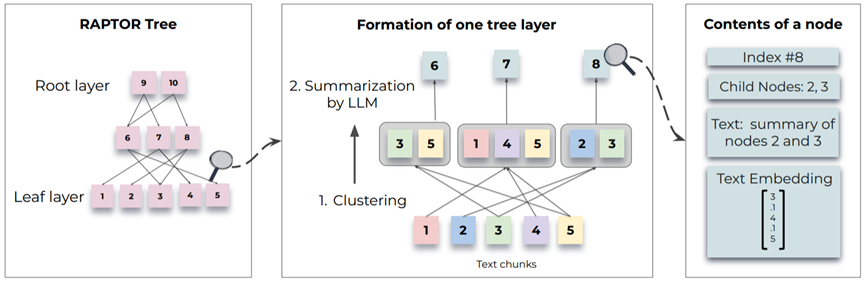
Картинка из бумаги:Sarthi, Parth, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. "RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval." In The Twelfth International Conference on Learning Representations. 2024.
Эндрю из Стэнфордского университета позавчера NgсуществоватьDeepLearning.AIОткрыт новый курсKnowledge Graphs for RAG,Объясните, как использовать график знаний для получения сложных взаимосвязей между несколькими типами данных, чтобы обеспечить более точную генерацию улучшений определения.
Ссылка на курс:https://www.deeplearning.ai/short-courses/knowledge-graphs-rag/
Примечание. Некоторые изображения в этой статье взяты из изображений Google в Интернете.
Справочное чтение: (1)https://thenewstack.io/3-ways-to-stop-llm-hallucinations/ (2)https://www.simform.com/blog/reinforcement-learning-from-human-feedback/ (3)https://masterofcode.com/blog/hallucinations-in-llms-what-you-need-to-know-before-integration#:~:text=Facilitate%20Domain%20Adaptation%20and%20Augmentation,queries%20and%20generate%20relevant%20responses. (4)https://medium.com/@cooper.white_86633/ai-hallucinations-the-ethical-burdens-of-using-chatgpt-5e62dd0f75c7 (5)https://www.simform.com/blog/llm-hallucinations/


Java перехватывает строку после определенного символа_java, как перехватить строку

Давайте кратко поговорим о технологии копирования на записи.

Выполнение собственных условий SQL-запроса в MyBatis Plus

Напоминание о выпуске общедоступной учетной записи WeChat (интерфейс сообщения шаблона общедоступной учетной записи WeChat)
5 шагов для установки среды протокола

Наиболее полные коды состояния HTTP
На основе языка Go мы шаг за шагом научим вас внедрять структуру системы управления серверной частью.
Эффективное управление журналами с помощью Spring Boot и Log4j2: подробное объяснение конфигурации

Что делать, если telnet не является внутренней или внешней командой [легко понять]

php-объект для анализа json_php json

Введение в принцип запуска Springboot, процесс запуска и механизм запуска.

Высокоуровневые операции Mongo, если данные не существуют, вставка и обновление, если они существуют (pymongo)
Проектирование и внедрение системы управления электронной коммерцией на базе Vue и SpringBoot.

Статья длиной в 9000 слов знакомит вас с процессом запуска SpringBoot — самым подробным процессом запуска SpringBoot в истории — с изображениями и текстом.

Как настроить размер экрана в PR. Учебное пособие по настройке размера видео в PR [подробное объяснение]
Элегантный и мощный: упростите операции ElasticSearch с помощью easy-es
Проект аутентификации по микросервисному токену: концепция и практика

【Java】Решено: org.springframework.http.converter.HttpMessageNotWritableException.
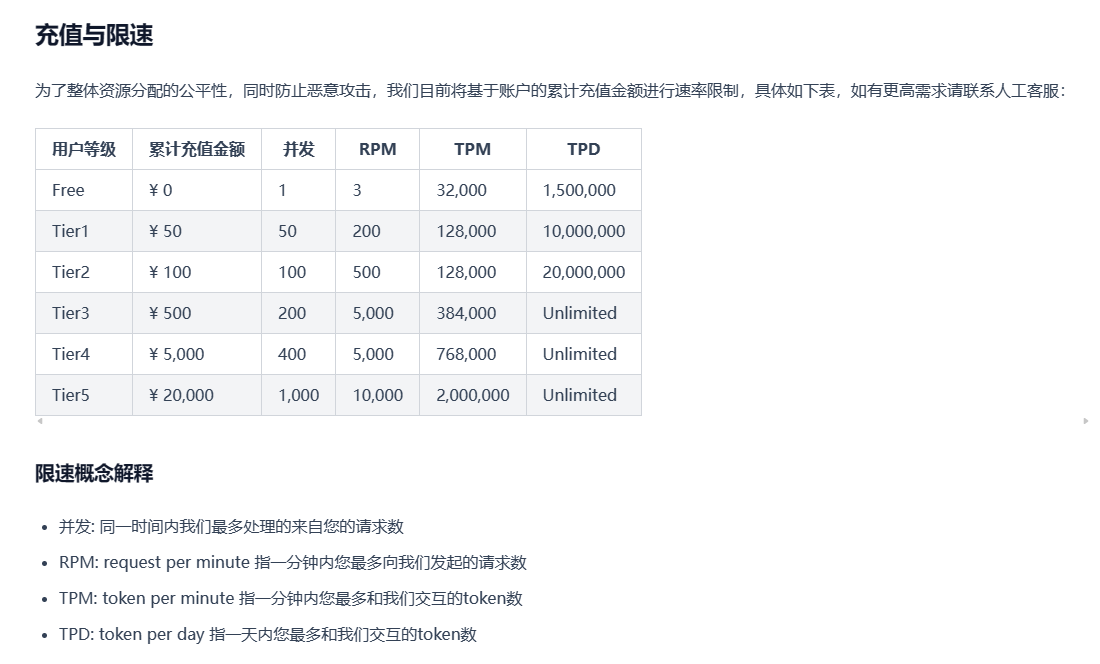
Изучите Kimi Smart Assistant: как использовать сверхдлинный текст, чтобы открыть новую сферу эффективной обработки информации
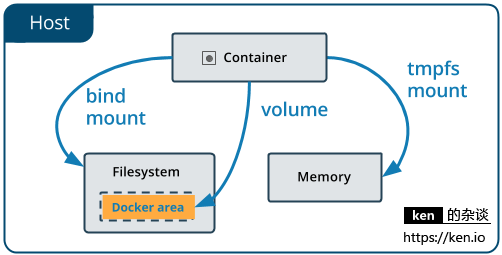
Начало работы с Docker: использование томов данных и монтирования файлов для хранения и совместного использования данных

Использование Python для реализации автоматической публикации статей в публичном аккаунте WeChat
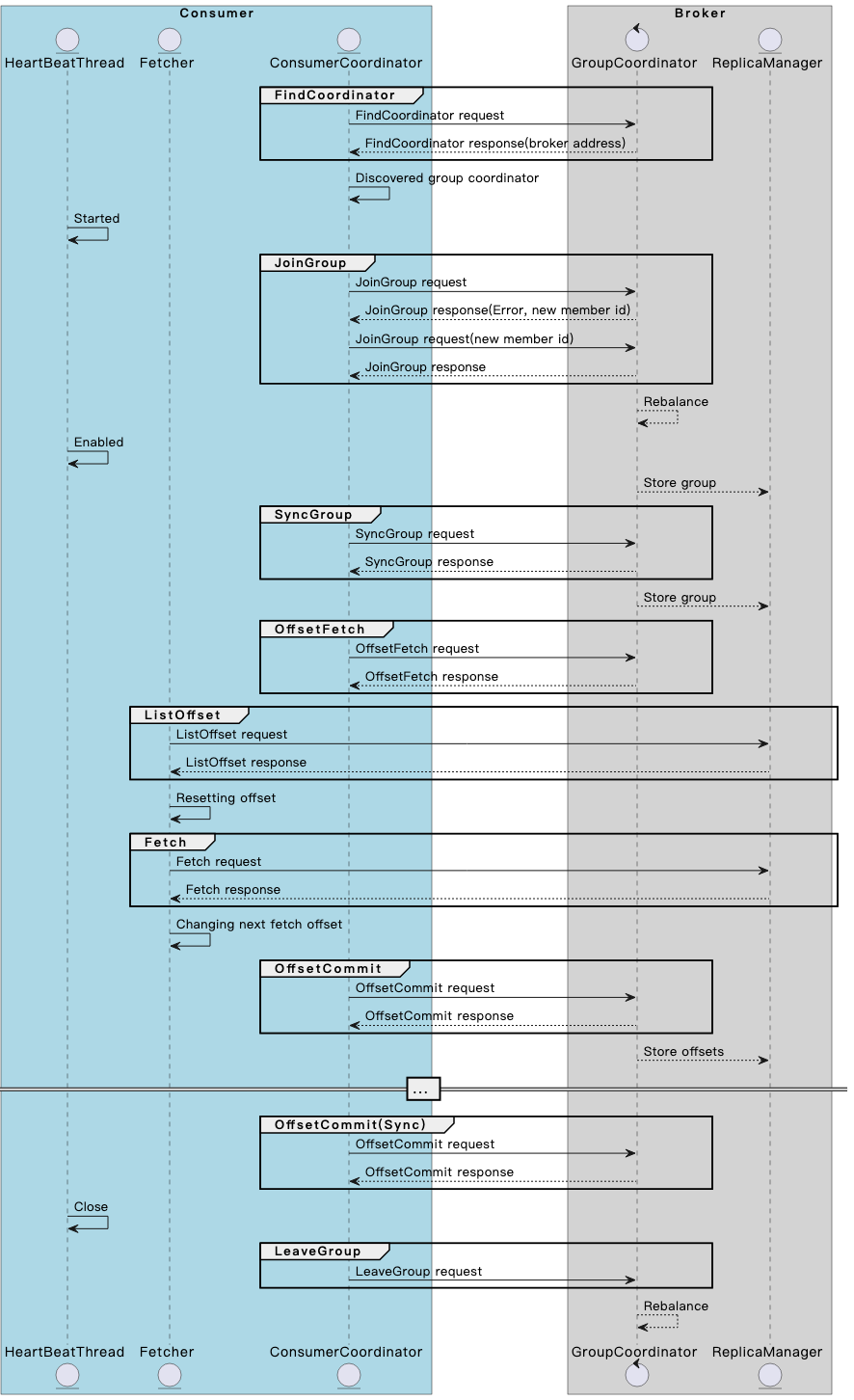
Разберитесь в механизме и принципах взаимодействия потребителя и брокера Kafka в одной статье.
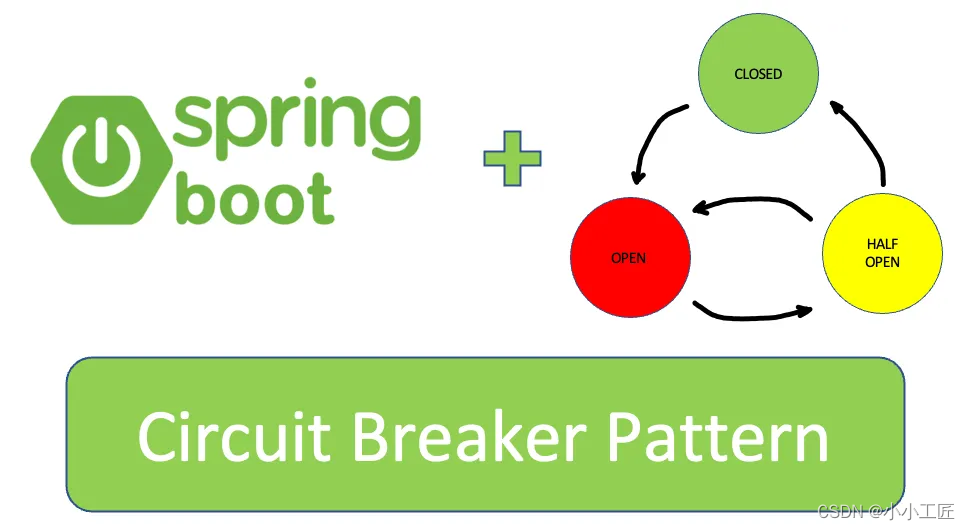
Spring Boot — использование Resilience4j-Circuitbreaker для реализации режима автоматического выключателя_предотвращения каскадных сбоев

13. Springboot интегрирует Protobuf

Примечание. Инструмент управления батареями Dell Dell Power Manager

Общая интерпретация класса LocalDate [java]
[Базовые знания ASP.NET Core] -- Веб-API -- Создание и настройка веб-API (1)
Настоящий бой! Подключите Passkey к своему веб-сайту для безопасного входа в систему без пароля.

Руководство по настройке Nginx: как найти, интерпретировать и оптимизировать настройки Nginx в Linux
