Оригинал | Серия «Большие модели: первое знакомство с большими моделями»

Автор: Цзинь Имин В этой статье около 6700 слов.,Рекомендуется читать от 10 минут. В данной статье будут проанализированы принцип, процесс обучения, оперативное и сопутствующее внедрение большой Модели.,Помогите читателям получить предварительное представление о Большой модели.В последние годы, с быстрым развитием компьютерных технологий и больших данных, глубокое обучение добилось замечательных результатов в различных областях. Чтобы улучшить производительность модели, исследователи продолжают пытаться увеличить количество параметров модели, тем самым рождая концепцию больших моделей. В этой статье будут проанализированы принципы, процесс обучения, подсказки и соответствующие сведения о применении больших моделей, чтобы помочь читателям получить предварительное представление о больших моделях.
Определение большой модели
Большие модели относятся к моделям глубокого обучения с десятками или даже сотнями миллионов параметров. В последние годы, благодаря быстрому развитию компьютерных технологий и больших данных, глубокое обучение достигло замечательных результатов в различных областях, таких как обработка естественного языка, генерация изображений, промышленная оцифровка и т. д. Чтобы улучшить производительность модели, исследователи продолжают пытаться увеличить количество параметров модели, тем самым рождая концепцию больших моделей. Большая модель, обсуждаемая в этой статье, будет представлена как пример большой языковой модели, которая обычно имеет множество точек.
Основные принципы и характеристики больших моделей
Принцип больших моделей основан на глубоком обучении, которое использует большие объемы данных и вычислительных ресурсов для обучения моделей нейронных сетей с большим количеством параметров. Постоянно регулируя параметры модели, модель может достичь наилучшей производительности в различных задачах. «Большие» характеристики больших моделей обычно выражаются в: огромном количестве параметров, большом объеме обучающих данных и высокой потребности в вычислительных ресурсах. Благодаря своим «большим» характеристикам многие продвинутые модели имеют все больше и больше параметров модели, все лучшую и лучшую производительность обобщения и все более точные выходные результаты в различных специализированных областях. К наиболее популярным задачам на рынке сейчас относятся язык, генерируемый ИИ (продукты типа ChatGPT), изображения, генерируемые ИИ (продукты типа Midjourney) и т. д., и все они применяются на основе концепции генерации. «Генерация» просто означает способность прогнозировать и выводить следующий соответствующий контент на основе данного контента. Например, наиболее интуитивно понятным примером является «Идиомный пасьянс». Большую языковую модель можно рассматривать как интеллектуальную версию функции «Идиомный пасьянс», то есть она выводит следующую статью или предложение на основе последнего слова.
Базовая архитектура, три формы:
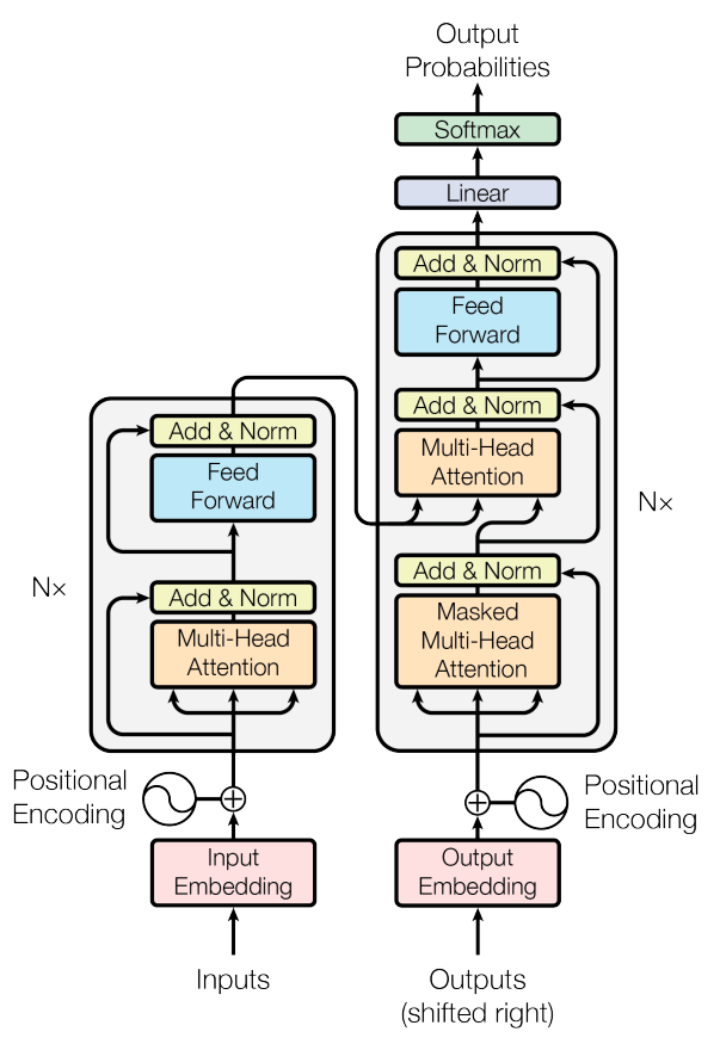
Текущая популярная сетевая архитектура больших моделей на самом деле не содержит большого количества новых технологий. Она по-прежнему использует структуру Трансформатора, самую популярную и эффективную архитектуру в текущей области НЛП. По сравнению с традиционными рекуррентными нейронными сетями (RNN) и сетями долгой краткосрочной памяти (LSTM), Transformer обладает уникальным механизмом внимания (Attention), который эквивалентен усилению понимания модели и обращению большего внимания на более важные слова. в то же время этот механизм обладает лучшим параллелизмом и масштабируемостью, может обрабатывать более длинные последовательности и сразу же становится моделью с фундаментальными возможностями в области НЛП, достигая хороших результатов в различных задачах, связанных с последовательностями текста.
В зависимости от деформации этой сетевой архитектуры основные платформы можно разделить на Encoder-Decoder, Encoder-Only и Decoder-Only, среди которых:
1)Encoder-Only,Содержит только часть кодера,В основном подходит для задач, не требующих генерации последовательности,Сценарии односторонних задач, требующие только кодирования и обработки входных данных.,Например, классификация текста, анализ настроений и т. д.,Этот тип представителя относится к модели BERT.,Например БЕРТ,RoBERT,АЛЬБЕРТ и др.
2)Encoder-Decoder,Содержит как кодер, так и декодер,Обычно используется для задач последовательного преобразования (Seq2Seq).,Например, машинный перевод, генерация диалогов и т. д.,Этот тип представителей представлен Т5, прошедшим обучение в Google.
3)Decoder-Only,Содержит только часть декодера,Обычно используется для задач генерации последовательности.,Например, генерация текста, машинный перевод и т. д. Модель структуры этого типа подходит для задач, требующих генерации последовательностей.,Соответствующая последовательность может быть сгенерирована из входной кодировки. В то же время еще одной важной особенностью является то, что он может выполнять предварительное обучение без присмотра. На предтренировочном этапе,Модель изучает статистические закономерности и семантическую информацию языка с помощью большого количества немаркированных данных. Такой подход позволяет Модели иметь обширные знания и понимание языка. После предварительной тренировки,Модель допускает контролируемую точную настройку.,Для конкретных последующих задач (таких как машинный перевод, генерация текста и т. д.). Представителем этого типа структуры является структура модели GPT, с которой мы хорошо знакомы.,Все сетевые структуры этого семейства постепенно развиваются на основе формы «Только декодер».
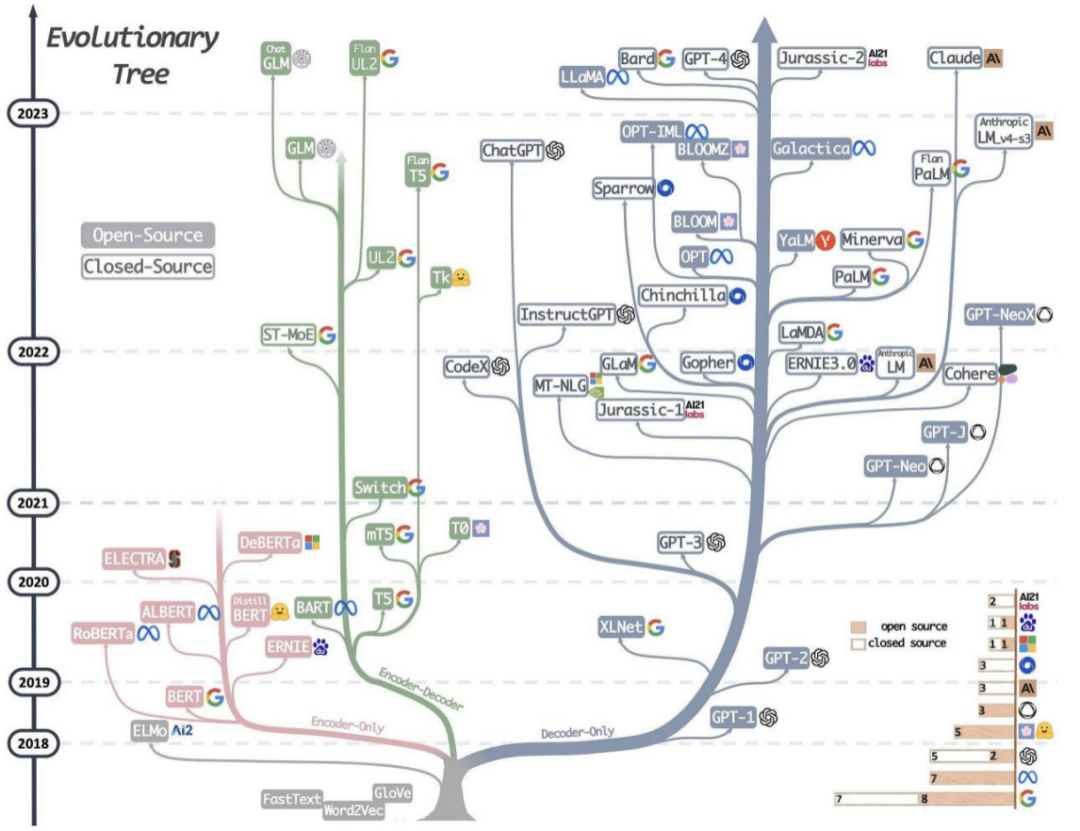
Видно, что многие задачи НЛП могут быть решены с помощью различных сетевых результатов. Это главным образом связано с разнообразием и сложностью задач и данных в области НЛП, а также с гибкостью и возможностями обобщения современных моделей глубокого обучения. В частности, какая эта структура эффективна и, как правило, ее необходимо выбирать на основе конкретных сценариев и данных, а также на основе экспериментальных результатов.
Три ступени обучения
Теперь, когда у нас есть предварительное представление о том, как выглядит большая модель, давайте посмотрим, как ее обучать.
Что касается методов обучения, здесь мы в основном ссылаемся на соответствующие этапы обучения InstructGPT, опубликованные OpenAI. Большинство основных форм основного обучения больших моделей аналогичны:
1. Предварительная подготовка
Предварительное обучение — это первый шаг в обучении большой модели, цель которого — позволить модели изучить статистические закономерности и семантическую информацию языка. Этапы основного этапа предварительного обучения в основном аналогичны, наиболее важным из которых являются данные, которые требуют сбора большого количества немаркированных данных, таких как текст, новости, блоги, форумы и т. д. в Интернете. Эти данные могут быть на нескольких языках, и их необходимо очистить и обработать, чтобы удалить шум, ненужную информацию и личную конфиденциальность, и, наконец, ввести в упомянутую выше языковую модель с детализацией токенизатора. Эти данные очищаются, обрабатываются и используются для обучения и оптимизации языковых моделей. В процессе предварительного обучения модель изучает правила словарного запаса, синтаксиса и семантики, а также взаимосвязь между контекстами. Одна из основных причин, по которой ChatGPT4 от OpenAI может достичь таких потрясающих результатов, заключается в том, что их источник обучающих данных относительно высокого качества.
2. Этап настройки инструкций
После завершения предварительного обучения вы можете использовать тонкую настройку инструкций, чтобы изучить и расширить возможности самой языковой модели. Этот шаг также является важным шагом для многих компаний и научных исследователей по использованию больших моделей.
Настройка инструкций — это этап обучения большой модели. Это особая форма контролируемой точной настройки, позволяющая модели понимать и следовать инструкциям человека. На этапе тонкой настройки инструкций сначала необходимо подготовить ряд задач НЛП и преобразовать каждую задачу в форму инструкций. Инструкции включают человеческие описания задач, которые должна выполнять модель, и ожидаемые выходные результаты. Эти инструкции затем используются для контролируемого обучения на больших предварительно обученных языковых моделях, что позволяет модели улучшить свою производительность при выполнении конкретных задач путем обучения и адаптации к инструкциям.
Чтобы сделать обучение моделей более эффективным и простым, на этом этапе также существует эффективная технология тонкой настройки, которая открывает простой путь к использованию больших моделей для обычных практиков.
Точная настройка с эффективным использованием параметров (PEFT) направлена на достижение эффективного переноса обучения за счет минимизации количества и вычислительной сложности параметров точной настройки, повышения производительности предварительно обученных моделей при выполнении новых задач, тем самым упрощая обучение крупномасштабных предварительно обученных моделей. Стоимость обученных моделей. В процессе обучения параметры предварительно обученной модели остаются неизменными, и требуется лишь небольшая настройка дополнительных параметров для достижения производительности, сравнимой с полной точной настройкой.
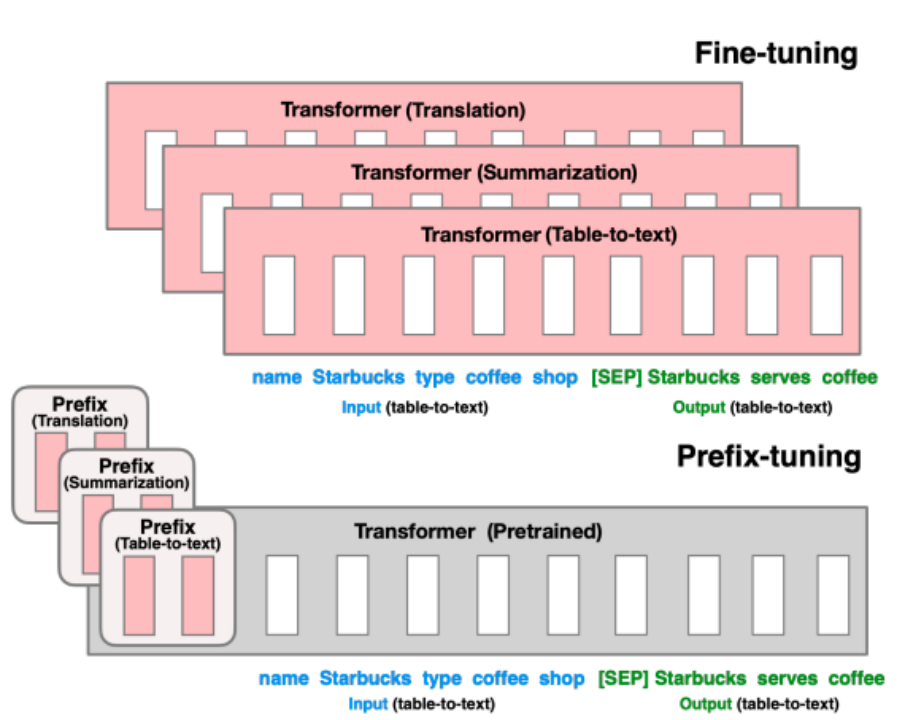
В настоящее время во многих исследованиях изучаются методы PEFT, такие как настройка адаптера и настройка префикса. Среди них метод настройки адаптера фиксирует определенные уровни в предварительно обученной модели при решении конкретных последующих задач и настраивает только параметры нескольких слоев, близких к последующим задачам. Метод Prefix Tuning добавляет некоторые дополнительные параметры на основе предварительно обученной модели. Эти параметры будут обновляться и корректироваться в соответствии с конкретными задачами в процессе обучения.
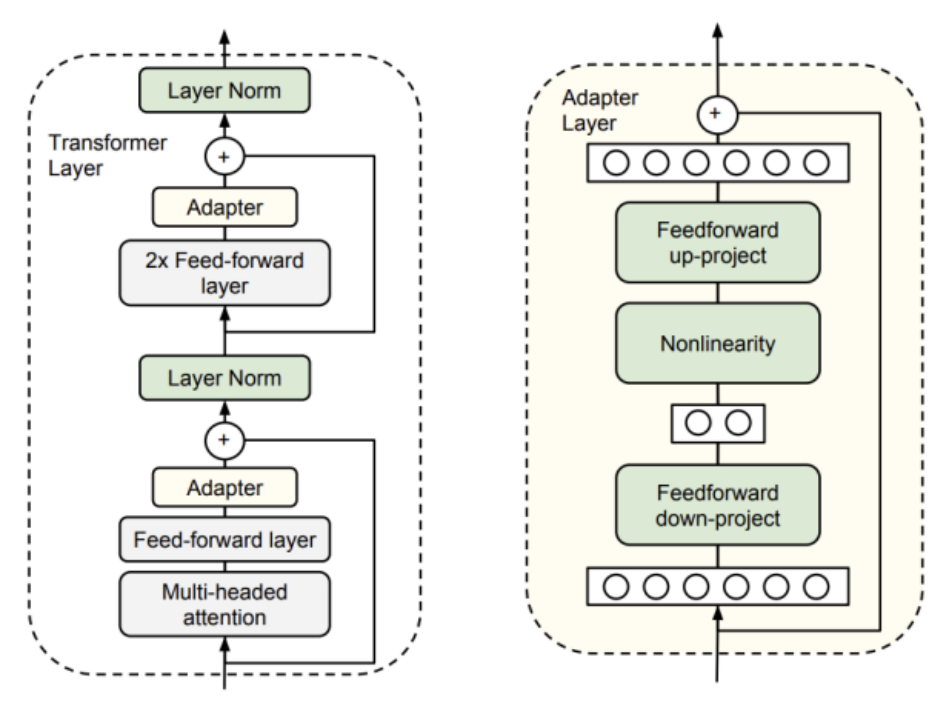
Технология настройки адаптера, обычно используемая в отрасли, — это адаптация низкого ранга (LoRA). Он реализует эффективное трансферное обучение за счет минимизации количества параметров тонкой настройки и вычислительной сложности для повышения производительности предварительно обученных моделей при выполнении новых задач. Основная идея LoRA — разложить матрицу весов предварительно обученной модели на произведение двух матриц низкого ранга. Благодаря такой декомпозиции количество параметров тонкой настройки может быть значительно уменьшено, а сложность вычислений уменьшена. Этот метод очень похож на идею классического уменьшения размерности в машинном обучении. Аналогично, LoRA использует метод разложения по сингулярным значениям (SVD) или метода низкоранговой аппроксимации (Low-Rank Approximation) в технологии матричного разложения для преобразования исходного значения. Весовая матрица разлагается в произведение двух матриц низкого ранга.
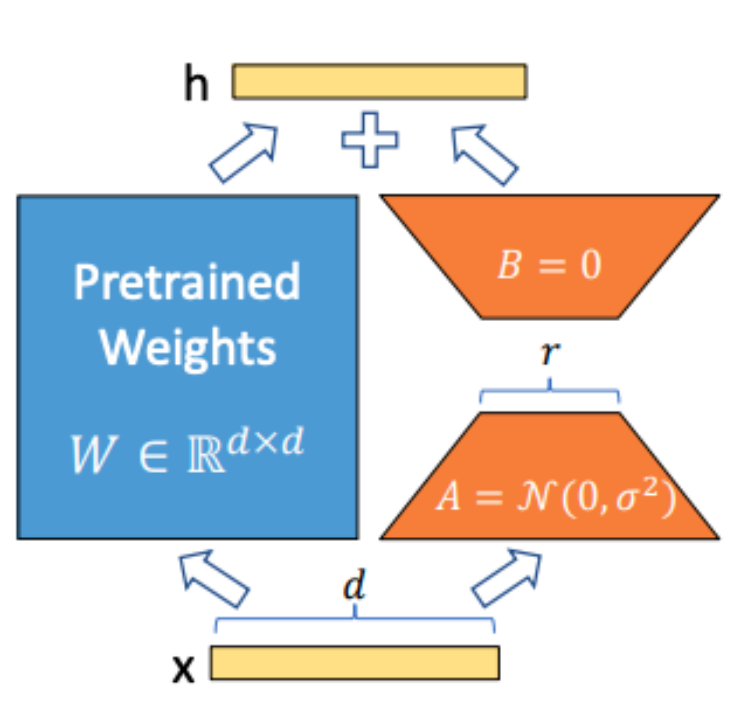
В процессе тонкой настройки LoRA обновляет только параметры этих двух матриц низкого ранга, сохраняя при этом фиксированными другие параметры предварительного обучения. Это позволяет существенно сократить вычислительные ресурсы и время, необходимые для тонкой настройки, и добиться производительности, сравнимой с полной тонкой настройкой, на многих задачах.
Внедрение технологии LoRA делает тонкую настройку крупномасштабных предварительно обученных моделей более эффективной и осуществимой, предоставляя больше возможностей для практического применения.
3. Настройка выравнивания
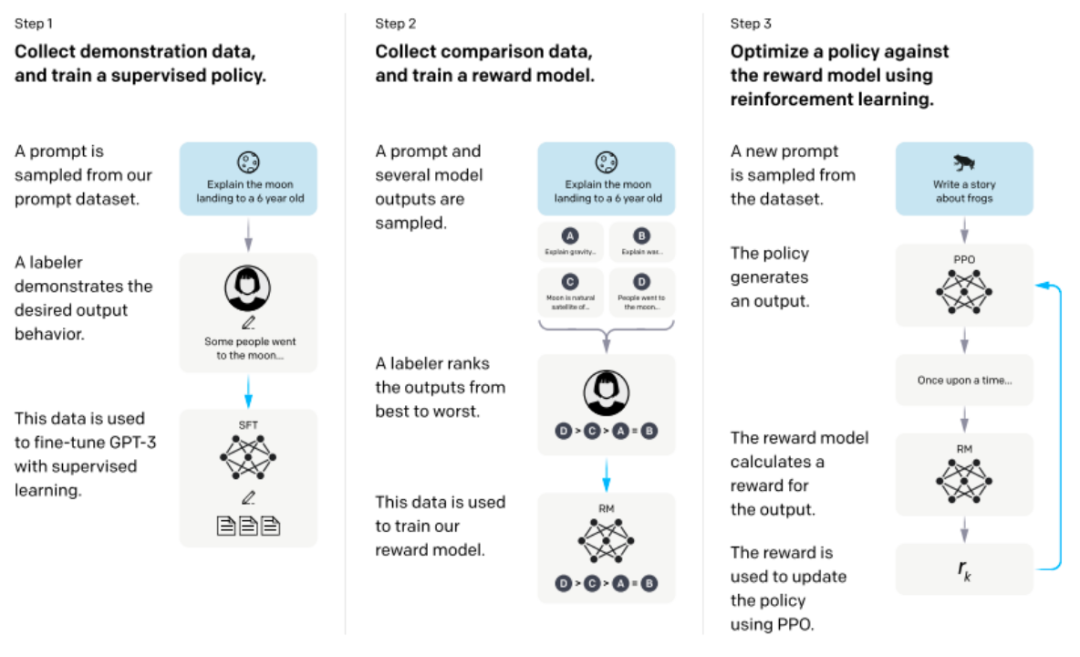
Основная цель — привести языковую модель в соответствие с человеческими предпочтениями и ценностями. Самая важная технология — использовать RLHF (обучение с подкреплением на основе обратной связи с человеком) для точной настройки.
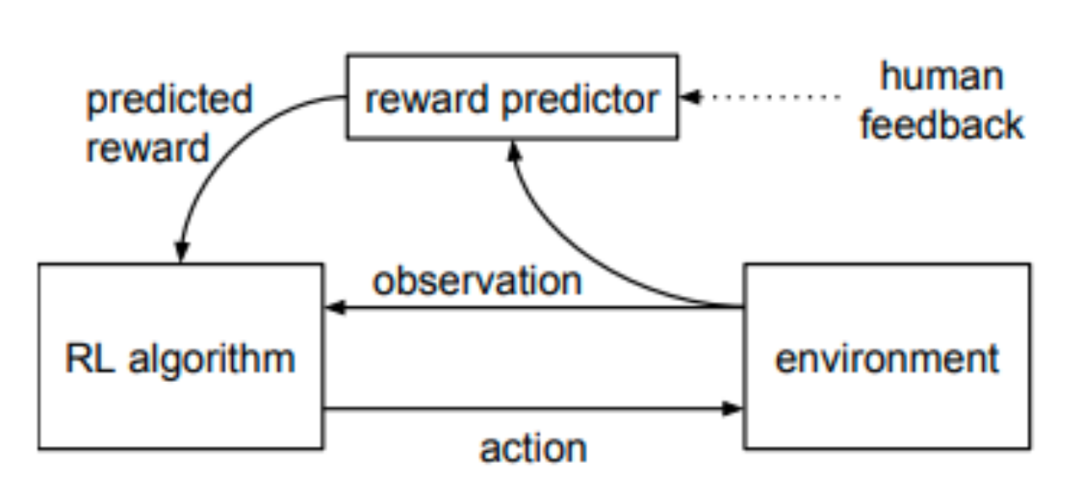
Шаг 1. Контролируемая точная настройка предварительно обученной модели.
Сначала мы собираем коллекцию подсказок и просим аннотаторов писать качественные ответы, а затем используем этот набор данных для контролируемой точной настройки предварительно обученной базовой модели.
Шаг 2. Обучите модель вознаграждения
Этот процесс включает в себя общение с людьми-оценщиками и внесение корректировок и улучшений на основе их отзывов. Оценщики ранжируют ответы, генерируемые моделью, на основе своих личных предпочтений, помогая модели генерировать ответы, более соответствующие человеческим ожиданиям. Этот метод обучения, основанный на обратной связи с человеком, может помочь модели уловить больше характеристик и привычек человеческого языка, тем самым улучшая возможности генерации модели.
Шаг 3. Точная настройка модели обучения с подкреплением
В основном он использует алгоритм оптимизации проксимальной политики (PPO) обучения с подкреплением. Для каждого временного шага алгоритм PPO будет рассчитывать текущее сгенерированное и инициализированное расхождение KL и рассчитывать ожидаемый возврат состояния или действия на основе этого распределения. затем используется для обновления стратегии для дальнейшей оптимизации модели SFT.
Однако у этого алгоритма есть некоторые очевидные недостатки. Например, PPO — это алгоритм, соответствующий политике. Каждое обновление требует сбора новых выборок, что приведет к неэффективности алгоритма, а обновление выполняется во время каждого обучения, поэтому политика обновляется. относительно часты, что приведет к плохой стабильности алгоритма.
Таким образом, в настоящее время появляется множество новых технологий, заменяющих технологию RLHF:
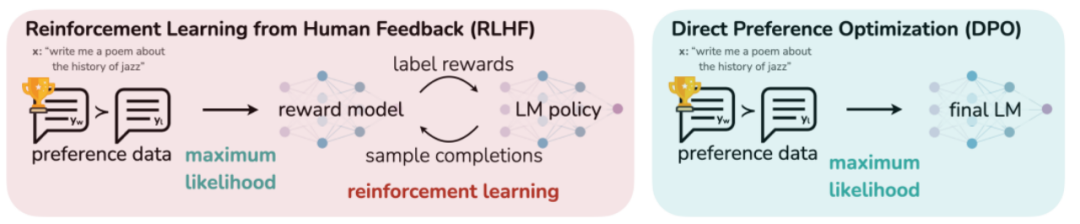
Оптимизация прямых предпочтений (DPO) — это технология, которая заменяет традиционную RLHF. В статье автор предлагает использовать модель вознаграждения, которая отражает человеческие предпочтения, и связывает сопоставление между функцией вознаграждения и оптимальной стратегией для максимизации ограниченного вознаграждения. проблему в одноэтапную проблему обучения политике. Затем большая языковая модель без присмотра настраивается посредством обучения с подкреплением, чтобы максимизировать предполагаемое вознаграждение. Этот алгоритм прост, эффективен и легок в вычислительном отношении. Он не требует соответствия модели вознаграждения, требует только одноэтапного обучения и не требует большого количества корректировок гиперпараметров. Таким образом, он обычно лучше, чем традиционный RLHF. качества ответа. Кроме того, RLAIF заменяет первоначальный RLHF PPO для обучения с точки зрения выборки и генерации оценок для модели вознаграждения за обучение.
метод ДПО
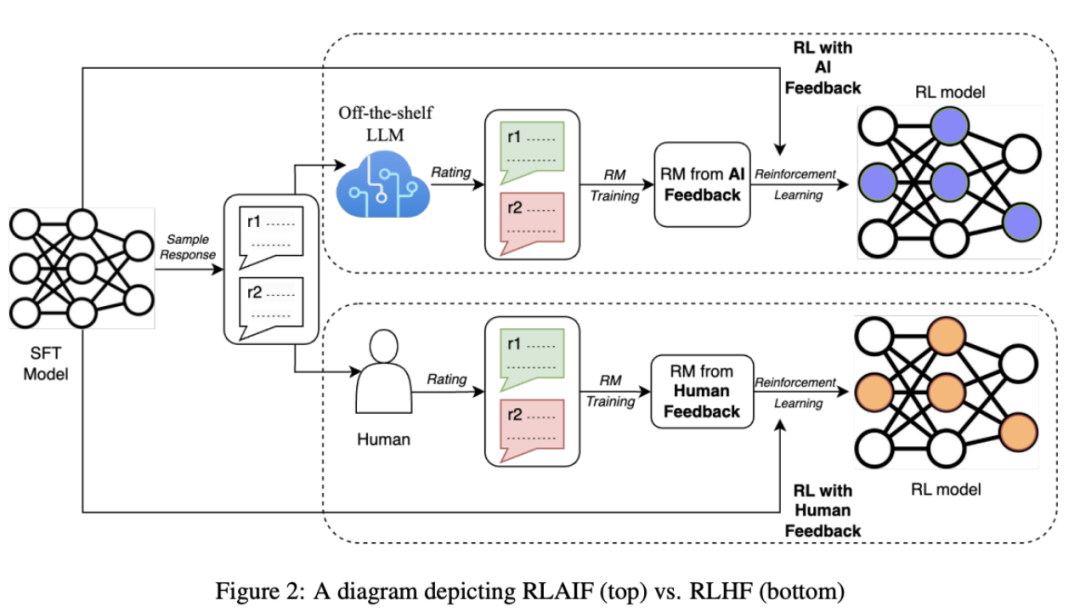
Точная настройка выравнивания — это критический этап, на котором используется обучение с подкреплением для точной настройки на основе отзывов людей с целью дальнейшей оптимизации генеративных возможностей модели. Он постоянно оптимизирует возможности создания модели посредством взаимодействия с людьми-оценщиками и пользователями, чтобы лучше соответствовать человеческим ожиданиям и потребностям.
Prompt
В качестве технической отрасли больших моделей первым шагом для многих людей при знакомстве с большими моделями является написание подсказок, и это действительно одна из важных технологий разработки больших моделей, а также ключевой шаг в решении множество проблем практического применения.
Основная идея технологии подсказок заключается в том, чтобы помочь модели генерировать выходные данные, соответствующие требованиям, путем предоставления модели одного или нескольких подсказок или фраз. По сути, потенциал самой языковой модели стимулируется посредством соответствующих параметров инициализации (то есть соответствующего описания языка ввода). Например, в задаче классификации текста мы можем предоставить модели список меток категорий и попросить ее сгенерировать текст, связанный с этими категориями, в задаче машинного перевода мы можем предоставить модели фрагмент текста в цели; язык и попросите его перевести этот текст.
Подсказки можно разделить на следующие четыре типа в зависимости от распространенных сценариев использования:
Zero-Shot Prompt: При использовании в сценарии с нулевой выборкой модель выполняет обработку задач в соответствии с подсказками или инструкциями и не требует специального обучения для каждой новой задачи или поля. Этот тип модели обычно используется как наиболее распространенный метод оценки для обучения. универсальные большие модели.
Few-Shot Prompt: При использовании в сценариях с несколькими выборками модель изучает конкретные задачи на небольшом количестве примеров и использует методы трансферного обучения для повышения производительности обобщения. Этот тип подсказок также используется во многих практических случаях применения для точной настройки и обучения больших моделей.
Chain-of-thought prompt:Этот типpromptОбычно используется при рассуждениях о сложных задачах.,Он решает проблему шаг за шагом, направляя Модель,Продемонстрируйте ход рассуждений и логические связи в виде серии последовательных шагов. С помощью этого пошагового метода рассуждения,Модель может постепенно получать больше информации,и накапливать правильные выводы на протяжении всего процесса рассуждения.
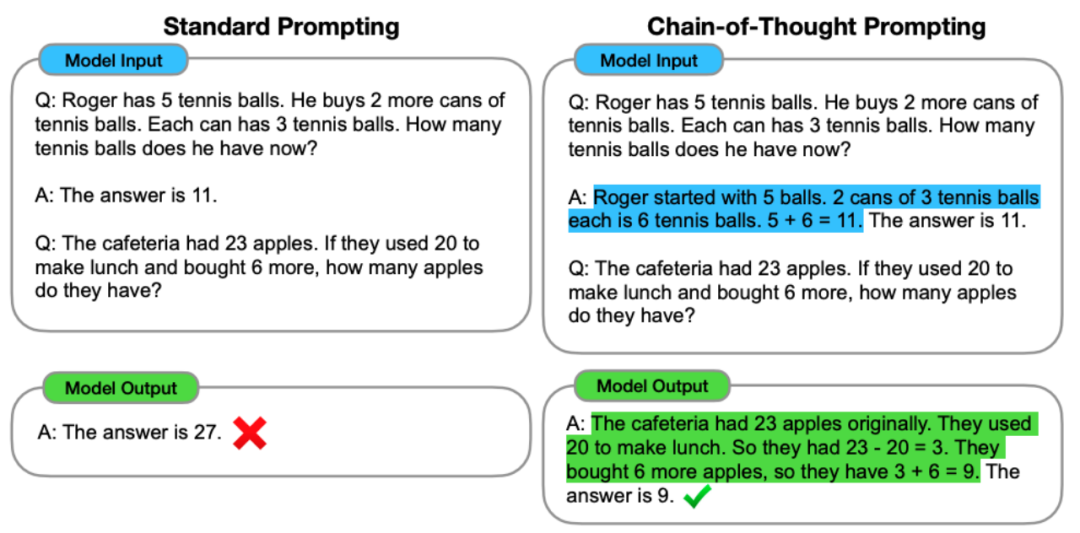
Multimodal prompt:Этот типpromptСодержит дополнительную информацию,В основном он объединяет информацию различных модальностей (например, текст, изображения, аудио и т. д.).,сформировать мультимодальную подсказку,Помочь Модели лучше понять и обработать входные данные. Например, в системе вопросов и ответов.,Вопросы и связанные изображения могут быть предоставлены как мультимодальные входные данные.,Чтобы помочь Модели лучше понять смысл и контекст вопроса.,и генерировать более точные и полные ответы.
В конкретной практике разработка подходящих подсказок для оптимизации на основе сценария также является важным шагом в разработке больших моделей. Этот шаг также является ключом к реализации потенциальных мощных возможностей больших моделей. Модель одно кольцо.
Применение большой модели
В настоящее время большие модели начали коммерциализироваться во многих областях. Помимо таких известных продуктов, как ChatGPT, существуют также следующие основные приложения:

1) Продукты Office Copilot:Microsoft впервые попробовала использовать большие Модельвозможность доступа к своемуOfficeПрограммное обеспечение серии,существоватьWordДокументы можно редактировать в Подвести Подвести итоги и внести предложения по доработке и редактированию вы также можете Подвести данную статью. Итог: пользователи, у которых всегда были головные боли при выполнении различных сложных операций Excel, теперь снизили порог использования и могут справиться с этим напрямую через описания; PowerPoint может автоматически генерировать отображаемый контент, распознавая запрос, используйте естественный язык непосредственно в Outlook. Для создания электронной почты; контент и другие функции для создания настоящего секретаря с искусственным интеллектом.
2) Продукты Github Copilot:Генерируйте различные функциональные коды непосредственно через диалог.,Включая помощь в написании тестовых примеров,Объяснение фрагментов кода и проблем отладки программы.,Эта функция позволила добиться революционного прогресса в повышении производительности программистов.,Позвольте разработчикам лучше понимать бизнес,Проектирование системы,Архитектурный дизайн и другие более сложные требования.
2) Продукты образовательных знаний:Спасибо большое Модель Хорошее понимание и запас знаний,Многие компании также внедряют свои продукты знаний в приложения.,Например, ChatPDF может помочь исследователям, которые часто читают статьи, быстро извлекать информацию из статей с помощью методов вопросов и ответов.,понимаю также Подвести итого важный контент, который значительно повышает эффективность чтения новых статей для людей, изучающих языки, программа под названием Call; Программное обеспечение Энни может фактически заменить роль преподавателя разговорной речи и позволяет практиковать устный диалог в любое время и в любом месте в течение неограниченного времени.


4) Поисковые системы и рекомендательные системы:большой Модель Может применяться к корпоративным поисковым системам и системам рекомендаций.,алгоритм через глубокое обучение,Точно понимать поисковые намерения пользователей,Предоставляйте более точные результаты поиска и персонализированный рекомендуемый контент. Это помогает улучшить пользовательский опыт,Повысьте привязчивость пользователей,Улучшите коэффициенты конверсии и продажи вашего бизнеса.
5) Индивидуальная большая модель бизнеса компании:большой Модель Иметь универсальныйпроизводительностьсила,Однако производительность во многих сценариях с нулевой выборкой по-прежнему не так хороша, как у продуктов, используемых в настоящее время в этой области.,Например, в некоторых вертикальных полях,в том числе промышленные зоны,Медицинская сфера,Задавайте профессиональные вопросы в областях управления и других сценариях.,Использование исследовательских вопросов все еще требует тонкой настройки в конкретных сценариях.,Этот вид индивидуального обслуживания также может привести к значительному повышению эффективности и экономии средств предприятий.,Это относительно перспективный бизнес.
6) Рассчитайте связанные отрасли добычи и переработки:Многие компании являютсясуществовать Активно исследовать на основеGPU、FPGAиASICТехнология аппаратного ускорения производства,Для поддержки больших скоростей обучения и вывода. также,Развитие технологии облачных вычислений также обеспечило дополнительную поддержку вычислительных ресурсов для обучения Da Model.,В будущем технологические компании будут активно изучать технологии распределенного обучения и вывода на основе облачных вычислений.

В дополнение к этому, он также включает в себя исследования и приложения в области оптимизации алгоритмов, конфиденциальности и безопасности данных, а также интерпретируемости моделей. Ежедневно появляется множество применений больших моделей. Большие модели по-прежнему имеют большой потенциал развития в будущем. большие модели, такие как Baidu Wenxin Large Model, также создают панораму больших моделей для общесистемной индустриализации.

Задача большой модели
Большие модели также создают некоторые практические проблемы:
1. Риски безопасности данных:с одной стороныбольшой Модельпотребности в обучениибольшойколичественныйданныеподдерживать,Однако многие данные связаны с вопросами конфиденциальности и неприкосновенности частной жизни.,Например, информация о клиентах, транзакции и т. д. Необходимо обеспечить сохранность данных при обучении большой Модели.,Предотвратите утечку и неправомерное использование данных. Когда OpenAI выпустила модель ChatGPT, потребовалось несколько месяцев, чтобы убедиться, что данные безопасны и соответствуют нормальным стандартам человеческих ценностей.
2. Высокая стоимость:большой Модельобучениеи Потребности в развертываниибольшойколичественный计算ресурсилюдисиларесурс,Стоимость очень высока. Для некоторых малых и средних предприятий,Трудно нести эти расходы,Также сложно получить адекватную техническую поддержку и ресурсы.
3. Невозможно гарантировать достоверность контента:большой Модель Может составлять слова,Нет никакой гарантии, что контент является подлинным, заслуживающим доверия и хорошо документированным. В настоящее время пользователи могут только проверять, является ли сгенерированный контент подлинным и заслуживающим доверия, только в соответствии со своими потребностями.,Трудно быть авторитетным и убедительным.
4. Невозможно добиться управляемости затрат:прямое обучениеи Развертывание сотен миллиардов параметровбольшой Модель Стоимость слишком высока,Приложения уровня предприятия должны использовать основу модели миллиардного уровня.,Тренируйте разные вертикальные модели в соответствии с различными потребностями,Предприятиям необходимо нести только расходы на вертикальное обучение. но,Как добиться эффективного вертикального обучения,Как контролировать расходы,Это по-прежнему одна из проблем, стоящих перед большой Моделью.
Существует еще много возможностей для улучшения решения вышеуказанных проблем, и необходимы дальнейшие исследования и изучение новых технологий и методов. Например, для обеспечения безопасности данных можно использовать шифрование данных, защиту конфиденциальности и другие технологии; эффективность и производительность больших моделей можно повысить за счет улучшения архитектуры модели, оптимизации алгоритмов обучения и, кроме того, использования распределенных вычислений с открытым исходным кодом и совместного использования; Ресурсы моделей можно использовать для сокращения затрат и содействия популяризации и применению больших моделей.
Подвести итог
Наконец, разработка крупных моделей является неизбежной тенденцией технологического прогресса в нынешнюю эпоху искусственного интеллекта и может даже соперничать по историческому значению с промышленной революцией. Недавно исследователи из Массачусетского технологического института обнаружили, что языковые модели действительно могут понимать время и пространство мира. Это исследование еще раз показывает, что у больших моделей есть множество скрытых способностей, которые ждут нашего открытия. В долгосрочной перспективе обучение общей технологии искусственного интеллекта (AGI) должно стать лишь вопросом времени. Как соответствующие практики, мы можем разрабатывать более эффективные и стабильные алгоритмы обучения и постоянно исследовать верхний предел больших моделей. Как обычные люди, нам необходимо использовать эту технологию, по крайней мере, в нашей повседневной работе и жизни, мы также можем наслаждаться огромными преимуществами. это приносит удобно.
ссылка:
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A., Kaiser, Ł. and Polosukhin, I. (2017).Attention Is All You Need.
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C.L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, J. and Lowe, R. (2022). Training language models to follow instructions with human feedback.arXiv:2203.02155 [cs]. [online] Available at: https://arxiv.org/abs/2203.02155.
Houlsby, N., Giurgiu, A., Jastrzȩbski, S., Morrone, B., De Laroussilhe, Q., Gesmundo, A., Attariyan, M. and Gelly, S. (n.d.).Parameter-Efficient Transfer Learning for NLP. [online] Available at: http://proceedings.mlr.press/v97/houlsby19a/houlsby19a.pdf.
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L. and Chen, W. (2021). LoRA: Low-Rank Adaptation of Large Language Models.arXiv:2106.09685 [cs]. [online] Available at: https://arxiv.org/abs/2106.09685.
Openai, C., Deepmind, J., Brown, T., Deepmind, M., Deepmind, S. and Openai, D. (n.d.).Deep Reinforcement Learning from Human Preferences. [online] Available at: https://arxiv.org/pdf/1706.03741.pdf.
Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C., Finn, C., & Cz Biohub. (n.d.). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. https://arxiv.org/pdf/2305.18290.pdf
Xiang, L., Li and Liang, P. (n.d.).Prefix-Tuning: Optimizing Continuous Prompts for Generation. [online] Available at: https://arxiv.org/pdf/2101.00190.pdf.
Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., Du, Y., Yang, C., Chen, Y., Chen, Z., Jiang, J., Ren, R., Li, Y., Tang, X., Liu, Z. and Liu, P. (2023). A Survey of Large Language Models.arXiv:2303.18223 [cs]. [online] Available at: https://arxiv.org/abs/2303.18223.
Gulcehre, C., Paine, T.L., Srinivasan, S., Konyushkova, K., Weerts, L., Sharma, A., Siddhant, A., Ahern, A., Wang, M., Gu, C., Macherey, W., Doucet, A., Firat, O. and de Freitas, N. (2023).Reinforced Self-Training (ReST) for Language Modeling. [online] arXiv.org. doi:https://doi.org/10.48550/arXiv.2308.08998.
Lee, H., Phatale, S., Mansoor, H., Lu, K., Mesnard, T., Bishop, C., Carbune, V. and Rastogi, A. (2023).RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback. [online] arXiv.org. doi:https://doi.org/10.48550/arXiv.2309.00267.
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q. and Zhou, D. (2022). Chain of Thought Prompting Elicits Reasoning in Large Language Models.arXiv:2201.11903 [cs]. [online] Available at: https://arxiv.org/abs/2201.11903.
Khattak, M., Rasheed, H., Maaz, M., Khan, S., Fahad, S. and Khan (n.d.).MaPLe: Multi-modal Prompt Learning. [online] Available at: https://arxiv.org/pdf/2210.03117.pdf [Accessed 21 Oct. 2023].
Gurnee, W. and Tegmark, M. (n.d.).LANGUAGE MODELS REPRESENT SPACE AND TIME. [online] Available at: https://arxiv.org/pdf/2310.02207.pdf [Accessed 15 Oct. 2023].
Монтажер: Хуан Цзиянь
Знакомство с исследовательским отделом Data Pi
данные Исследовательский отдел Pai был создан в начале 2017 года.,кИнтерес как основаРазделить на несколько групп,Каждая группа следует общей задаче исследовательского отдела.Обмен знаниямииПрактика планирования проектов,Каждый имеет свои особенности:
Группа моделей алгоритма:Активно формируйте команду для участияkaggleВ ожидании игры,Серия оригинальных статей с пошаговыми инструкциями;
Группа исследований и анализа:Исследования посредством эксклюзивных интервью и других методовбольшойданные Приложение,Откройте для себя красоту продуктов данных;
Группа системных платформ:отслеживатьбольшойданные&Технологический рубеж платформы системы искусственного интеллекта,эксперт по разговорам;
Группа обработки естественного языка:Важнее практики,Активно участвовать в конкурсах и планировать различные проекты по анализу текста;
Группа больших данных производства:Придерживайтесь мечты о промышленной мощи,Сочетание промышленности, научных кругов, исследований и правительства,Узнайте ценность данных;
Группа визуализации данных:Объединение информации и искусства,Откройте для себя красоту данных,Научитесь рассказывать истории визуально;
Группа веб-сканеров:Сканировать информацию о сети,Сотрудничайте с другими группами для разработки творческих проектов.
Нажмите «Прочитать оригинальный текст» в конце статьи, чтобы записаться волонтёром отдела исследования данных. Всегда найдется подходящая для вас группа~.
Инструкция по перепечатке
Если вам необходимо перепечатать, укажите автора и источник на видном месте в начале статьи (перепечатано из: Datapi THUID: DatapiTHU) и разместите привлекательный QR-код Datapi в конце статьи. Если у вас есть статьи с оригинальным логотипом, отправьте [Название статьи — имя и идентификатор общедоступной учетной записи, подлежащей авторизации] на контактный адрес электронной почты, чтобы подать заявку на авторизацию в белом списке, и отредактируйте его при необходимости.
Несанкционированная перепечатка и адаптация будут преследоваться за юридическую ответственность в соответствии с законом.
Нажмите“Прочитайте оригинальную статью”Присоединяйтесь к организации~


RasaGpt — платформа чат-ботов на основе Rasa и LLM.

Nomic Embed: воспроизводимая модель внедрения SOTA с открытым исходным кодом.

Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Малые цели имеют очевидные преимущества | ICASSP2023

Урок 1 серии Libtorch: Тензорная библиотека Silky C++

Руководство по локальному развертыванию Stable Diffusion: подробные шаги и анализ распространенных проблем

Полностью автоматический инструмент для работы с видео в один клик: VideoLingo

Улучшения оптимизации RT-DETR: облегченные улучшения магистрали | Support Paddle облегченный rtdetr-r18, rtdetr-r34, rtdetr-r50, rtdet

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | Деформируемое внимание с большим ядром (D-LKA Attention), большое ядро свертки улучшает механизм внимания восприимчивых полей с различными функциями

Создано Datawhale: выпущено «Руководство по тонкой настройке развертывания большой модели GLM-4»!

7B превышает десятки миллиардов, aiXcoder-7B с открытым исходным кодом Пекинского университета — это самая мощная модель большого кода, лучший выбор для корпоративного развертывания.

Используйте модель Huggingface, чтобы заменить интерфейс внедрения OpenAI в китайской среде.

Оригинальные улучшения YOLOv8: несколько новых улучшений | Сохранение исходной информации — алгоритм отделяемой по глубине свертки (MDSConv) |

Второй пилот облачной разработки | Быстро поиграйте со средствами разработки на базе искусственного интеллекта

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция с нулевым кодированием и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

Решенная Ошибка | Загрузка PyTorch медленная: TimeoutError: [Errno 110] При загрузке факела истекло время ожидания — Cat Head Tiger

Brother OCR, библиотека с открытым исходным кодом для Python, которая распознает коды проверки.
Новейшее подробное руководство по загрузке и использованию последней демонстрационной версии набора данных COCO.

Выпущен отчет о крупной модели финансовой отрасли за 2023 год | Полный текст включен в загрузку |

Обычные компьютеры также могут работать с большими моделями, и вы можете получить личного помощника с искусственным интеллектом за три шага | Руководство для начинающих по локальному развертыванию LLaMA-3

Одной статьи достаточно для анализа фактора транскрипции SCENIC на Python (4)

Бросая вызов ограничениям производительности небольших видеокарт, он научит вас запускать большие модели глубокого обучения с ограниченными ресурсами, а также предоставит полное руководство по оценке и эффективному использованию памяти графического процессора!

Команда Fudan NLP опубликовала 80-страничный обзор крупномасштабных модельных агентов, в котором в одной статье представлен обзор текущего состояния и будущего агентов ИИ.

[Эксклюзив] Вы должны знать о новой функции JetBrains 2024.1 «Полнострочное завершение кода», чтобы решить вашу путаницу!

Краткое изложение базовых знаний о регистрации изображений 1.0

Новейшее подробное руководство по установке и использованию библиотеки cv2 (OpenCV, opencv-python) в Python.

Легко создайте локальную базу знаний для крупных моделей на основе Ollama+AnythingLLM.

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание решения. Повторная попытка с помощью файла (графическое руководство).

Одна статья поможет вам понять RAG (Retrival Enhanced Generation) | Введение в концепцию и теорию + практику работы с кодом (включая исходный код).

Эволюция архитектуры шлюза облачной разработки
