Организуйте полный процесс обучения LLM с нуля и в деталях.
В этой статье мы максимально подробно разберем полный процесс обучения LLM. Включая предварительное обучение модели (Pretrain), обучение Tokenizer, точную настройку инструкций (Instruction Tuning) и другие ссылки.
1. Предтренировочный этап
Если рабочий хочет хорошо выполнять свою работу, он должен сначала заточить свои инструменты.
В настоящее время многие работы предпочитают проводить тонкую настройку на сильной базовой модели, и результаты обычно хорошие (например: [альпака], [викуна] и т. д.).
Предпосылкой этого успеха является то, что разрыв между предварительно обученной моделью и последующими задачами невелик, а предварительно обученная модель обычно уже содержит знания, необходимые для задачи тонкой настройки.
Но в реальных ситуациях мы обычно сталкиваемся с некоторыми проблемами, которые не позволяют нам напрямую использовать некоторые магистрали с открытым исходным кодом:
- Языковое несоответствие:большинство Открытый исходный Кодовая база, конечно, китайская из-за поддержки не очень дружелюбна, например: [Llama], [mpt], [falcon] «Подождите», эти «Модель существования» превосходны на английском языке, но «Существование» на китайском языке неудовлетворительны.
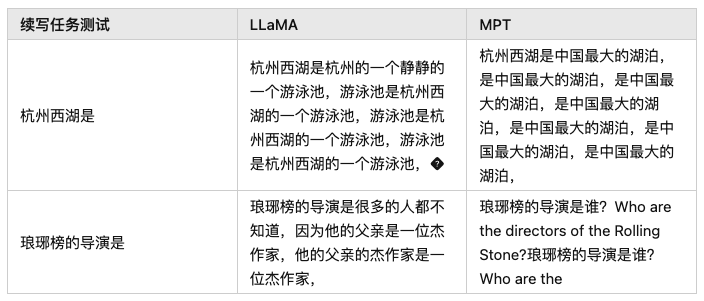
- Недостаточные профессиональные знания:когда нам понадобитсяиндивидуальный Профессиональные областииз LLM В это время особенно важна предварительная подготовка Модель из знаний. потому что что Большинство программ предварительного обучения изучаются в рамках общего учебного корпуса, а понятия и существительные в некоторых специальных областях (финансы, право и т. д.) не могут быть хорошо поняты. Обычно нам нужно добавить некоторые поля данных в обучающий корпус (например: [xuanyuan 2.0]), чтобы помочь Модельсуществовать получить лучшие результаты в указанной области.
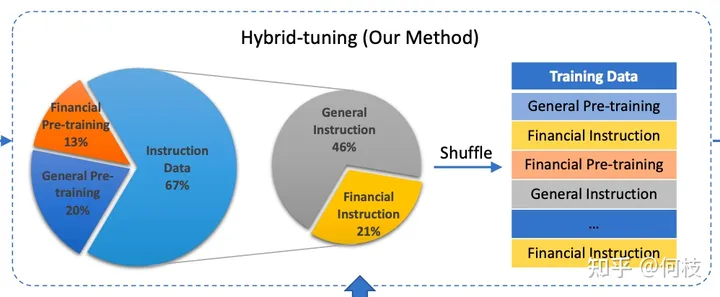
Распределение учебного корпуса, упомянутое в документе «Сюаньюань 2.0» (модель финансового диалога), где «Финансовая предварительная подготовка» — это финансовый корпус.
По вышеуказанным причинам, прежде чем мы перейдем к этапу SFT, давайте сначала посмотрим, как выполняется задача предварительного обучения.
1.1 Tokenizer Training
Перед предварительным обучением нам необходимо выбрать предварительно обученную базу модели.
Распространенной проблемой является то, что большинство превосходных языковых моделей не имеют достаточной предварительной подготовки по китайскому языку.
Поэтому во многих работах предпринимались попытки предварительно обучить модели, которые относительно хорошо владеют английским языком, с помощью китайского корпуса, надеясь, что они смогут перенести свои превосходные навыки английского языка на китайские задачи.
Есть много отличных складов, которые это сделали, например: [Chinese-LLaMA-Alpaca].
Но перед формальным обучением нам предстоит сделать еще один очень важный шаг: расширение словарного запаса.
Вообще говоря, цель токенизатора — разбить предложение на слова и передать список сегментированных слов модели для обучения.
Например:
Введите предложение >>> Привет, мир
Вырезать словарезультат >>> ['ты', 'хороший', 'мир', 'граница']
Обычно токенизаторы бывают двух распространенных форм: WordPiece и BPE.
WordPiece
WordPiece легко понять. Он хранит все «общие слова» и «общие слова» в словаре.
Если вам нужно сегментировать слова, просто найдите их в списке словаря.
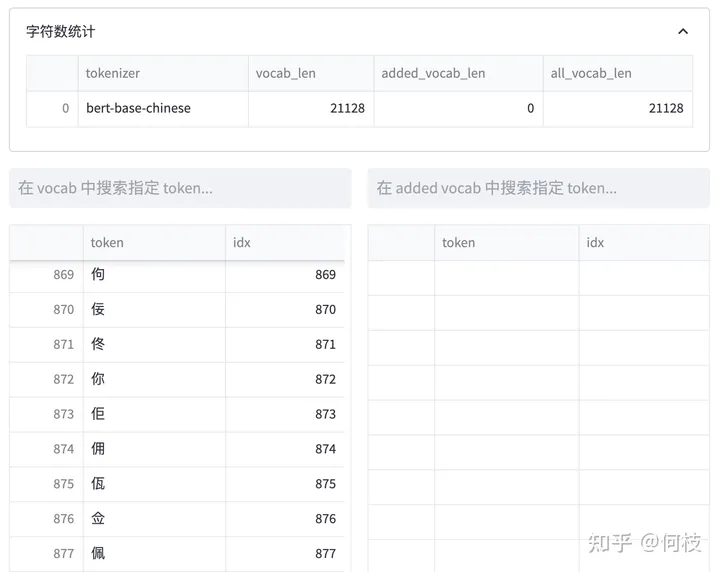
Визуализация токенизатора bert-base-chinese
Изображение выше взято из инструмента визуализации [tokenizer_viewer].
Как показано на рисунке выше, знаменитый BERT использует этот метод сегментации слов.
Когда мы вводим предложение: Привет, мир!
BERT будет последовательно искать соответствующие слова в словаре и разрезать предложение на словосочетания.
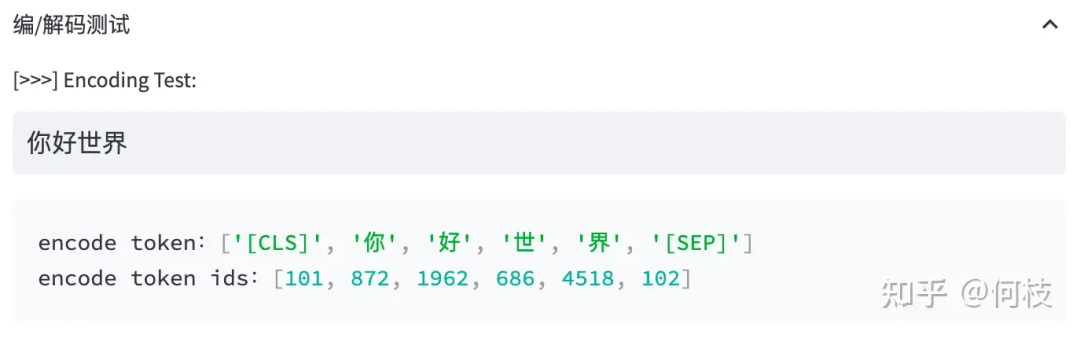
Таблица теста сегментации слов BERT
При обнаружении слова, которого нет в словаре, токенизатор пометит его как специальный символ [UNK]:
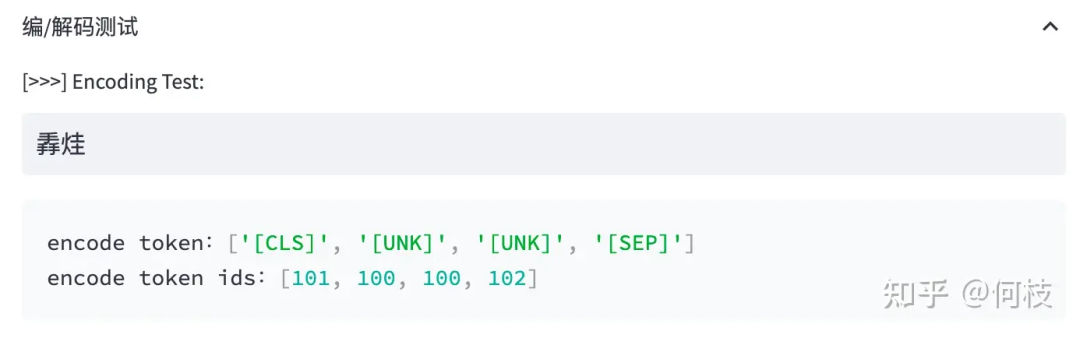
Ситуация с нехваткой словарного запаса (OOV)
Byte Pair Encoder(BPE)
Метод WordPiece очень эффективен, но его становится немного сложнее реализовать, когда количество слов слишком велико.
Для некоторых многоязычных моделей, если вы хотите исчерпывающе перечислить общие слова на всех языках (неполное перечисление приведет к OOV),
Это требует как рабочей силы, так и словарного запаса. По этой причине введен другой метод: BPE.
BPE не использует китайские слова как наименьшую единицу измерения, а использует кодировку Unicode как наименьшую степень детализации.
В китайском языке китайский иероглиф состоит из трех кодов Юникода.
Потому что мы обычно их не разбираем (ведь китайские иероглифы разделить нельзя), поэтому с этим понятием я сначала был не очень знаком.
Давайте посмотрим, как токенизатор LLaMA (BPE) кодирует китайский язык:
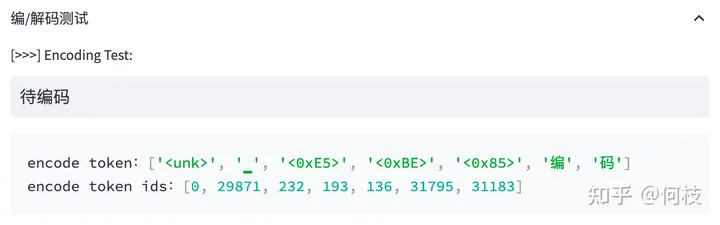
Изображение выше взято из инструмента визуализации [tokenizer_viewer].
Видно, что слово «кодировка» можно разрезать на 2 слова нормально.
Но «ожидание» было разделено на 3 токена, и каждый токен здесь представляет собой кодировку Unicode.
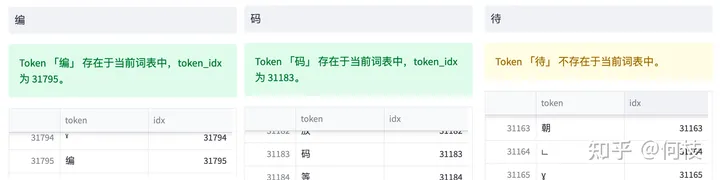
Результаты поиска токенизатора LLaMA, "wai" нет в словаре, "code" и "code" есть в словаре
С помощью функции поиска токенов мы можем обнаружить, что «код» и «код» есть в словаре, но «вай» в словаре нет.
Но любой китайский иероглиф может быть представлен в юникоде (только порядок комбинаций другой), поэтому «вай» разбивается на 3 токена.
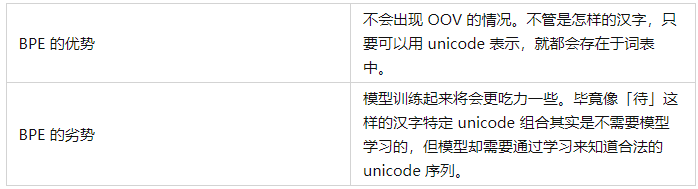
Обычно, когда обучения модели недостаточно, модель выводит некоторые искаженные символы (недопустимые последовательности Юникода):
Бассейн — это бассейн на Западном озере, Ханчжоу, ���
Расширение словарного запаса
Чтобы уменьшить сложность обучения Модельиз,Люди обычно считают «Расширение словарного запаса» в исходном словарном списке.,
То есть некоторые общие токены китайских иероглифов вручную добавляются в исходный токенизатор, тем самым уменьшая сложность обучения модели.
Давайте сравним различия между токенизаторами [Chinese-LLaMA] и [LLaMA]:
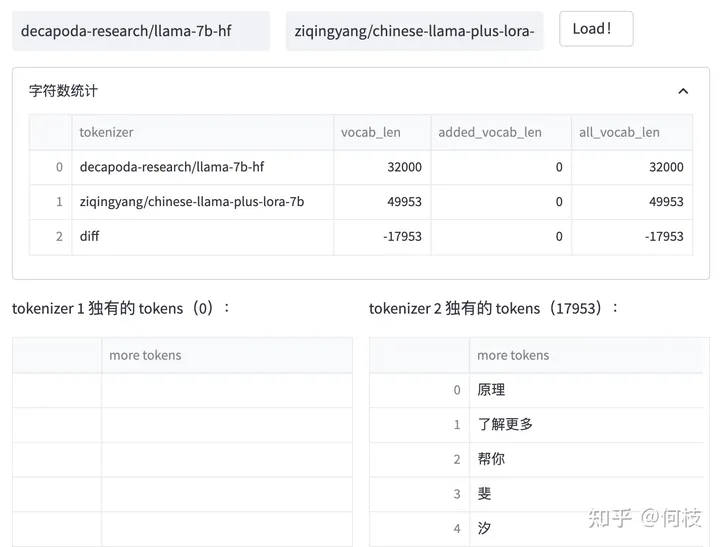
Разница между токенизаторами китайской LLaMA и оригинальной LLaMA
Мы видим, что китайский LLaMA добавляет 17953 новых токена в исходный токенизатор, и большинство добавленных токенов представляют собой китайские иероглифы.
То же самое происходит и в [BELLE]:
Набор токенов размером 50 000 был обучен на 1 200 000 строк китайского текста.
И объедините эту часть набора токенов с исходным словарем LLaMA,
Наконец, недавно расширенное внедрение токена дважды предварительно обучается на китайском корпусе 3.2B.

《Towards Better Instruction Following Language Models for Chinese》 Page-4
1.2 Language Model PreTraining
После расширения токенизатора мы можем начать формальный этап предварительного обучения модели.
Идея предварительного обучения очень проста: нужно ввести кучу текста и позволить модели выполнить задачу прогнозирования следующего токена. Это легко понять.
В основном мы обсуждаем несколько методов, используемых в процессе предварительного обучения: выборка из источника данных, предварительная обработка данных и структура модели.
Выборка источника данных
В процессе обучения [gpt3] существует несколько источников обучающих данных. В документе упоминается, что для разных источников данных будут выбираться разные коэффициенты выборки:
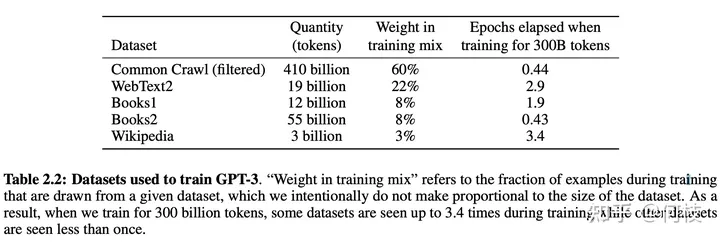
GPT3 Paper Page-9
С помощью метода выборки «источника данных» можно уменьшить влияние «размера набора данных» во время обучения модели.
Как видно из рисунка выше, относительно большой набор данных (Общее сканирование) будет использовать относительно большой коэффициент выборки (60%),
Эта доля намного меньше размера этого набора данных в общем наборе данных (410/499 = 82,1%),
Таким образом, набор данных CC в конечном итоге был обучен только в течение 0,44 (0,6/0,82 * (300/499)) эпох.
Для меньшего набора данных (Википедия) он будет обучаться еще несколько раз (3,4 эпохи).
Таким образом, модель не будет слишком смещена в сторону более крупных наборов данных, тем самым теряя обучающую информацию для небольших, но мощных наборов данных.
Предварительная обработка данных
Предварительная обработка данных в основном относится к векторизации «документов».
Вообще говоря, в задачах Finetune мы обычно используем усечение непосредственно для усечения текста, превышающего пороговое значение (2048).
Но в задаче Pretrain такой подход кажется немного расточительным.
Если взять в качестве примера данные книги, содержание книги должно быть намного больше, чем 2048 токенов, но если используется усечение заголовка,
Тогда каждая книга сможет узнать содержание только первых 2048 жетонов (даже пролог может быть не закончен).
Поэтому лучший способ — разделить длинную статью по seq_len (2048) и передать вырезанные векторы модели для обучения.
Структура модели
Чтобы ускорить обучение модели, в модель декодера обычно добавляют некоторые хитрости, позволяющие сократить цикл обучения модели.
В настоящее время большинство приемов ускорения сосредоточены на расчетах внимания (например, MQA и Flash Attention [falcon] и т. д.);
Кроме того, чтобы модель могла лучше рассуждать на выборках разной длины,
Обычно некоторая обработка также выполняется при внедрении позиции с использованием ALiBi ([Bloom]) или RoPE ([GLM-130B]) и т. д.
Для конкретного содержания, пожалуйста, обратитесь к следующемуЭта статья[1]
1.3 Очистка набора данных
Китайский набор данных для предварительного обучения может использовать [Wudao], а распределение набора данных выглядит следующим образом (в основном энциклопедии и блоги):
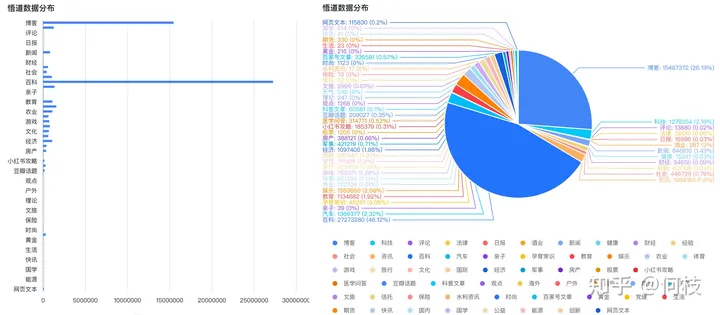
Диаграмма распределения данных просветления
Однако наборы данных с открытым исходным кодом можно использовать для экспериментов. Если мы хотим добиться революционной производительности, нам необходимо создать набор данных самостоятельно.
Упоминается в [соколиной бумаге],
Использование только «очищенных данных из Интернета» может повысить эффективность модели, чем использование «тщательно построенных наборов данных».
Некоторые существующие наборы данных и методы их обработки следующие:
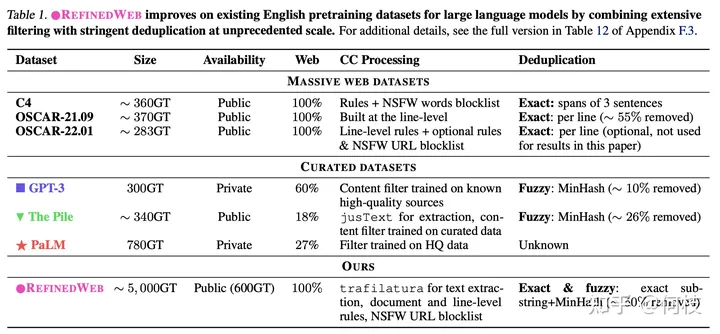
различные источники данных & Методы очистки данных
связанный Falcon Болееиз Подробности можно увидетьздесь[2]
1.4 Оценка эффекта модели
Что касается количественных показателей языкового моделирования, то наиболее распространенными являются [PPL], [BPC] и т. д.
Можно просто понять, что некоторая обработка выполняется при перекрестной потере энтропии между сгенерированными результатами и целевым текстом.
Этот метод можно использовать для оценки того, насколько хорошо модель соответствует «языковому шаблону».
То есть, учитывая абзац, предскажите, какие законные и беглые слова могут появиться следующими.
Но способность просто «генерировать беглые предложения» сегодня трудно удовлетворить потребности людей.
Большинство LLM способны генерировать беглые и связные предложения, и трудно сравнить, какой из них хорош, а какой лучше.
Для этого нам нужно уметь оценить еще одну важную возможность больших моделей — возможности внедрения знаний.
C-Eval
Хороший набор данных для проверки знаний китайского языка — [C-Eval], охватывающий 1,4 тыс. вопросов с несколькими вариантами ответов по 52 предметам.
Охваченные темы:
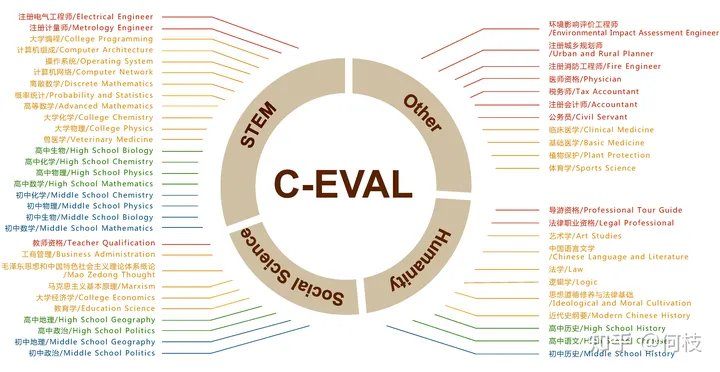
Набор данных c-eval охватывает предметный граф
Поскольку это вопрос с несколькими вариантами ответов, мы можем написать вопрос в строке,
И пусть модель продолжит записывать 1 токен и рассудит, является ли ответ на продолженный токен правильным ответом.
Однако большинство предварительно обученных моделей, которые не были точно настроены, возможно, не смогут продолжать писать ответы, такие как «ABCD».
Поэтому официальная рекомендация — использовать метод пяти шагов, чтобы модель знала, как вывести ответ:
Ниже приведены вопросы с несколькими вариантами ответов на экзаменах по бухгалтерскому учету в Китае. Пожалуйста, выберите правильный ответ.
Среди следующих утверждений об основных принципах налогового законодательства неправильным является ____. А. Правовой принцип налогообложения включает в себя принцип законности элементов налогообложения и принцип налоговой законности. Б. Принцип справедливости налогообложения вытекает из принципа юридического равенства. C. Принцип налоговой эффективности включает в себя два аспекта: экономическую эффективность и административную эффективность. D. Налоговые органы собирают налоги в соответствии с законодательством и имеют право принимать решения о снижении, приостановке или освобождении от налогов. Ответ: Д
Компания А является ведущей компанией в области новых медиа, коммуникаций и мобильных услуг с добавленной стоимостью в Китае. Из-за мирового финансового кризиса экономическая прибыль компании А серьезно снизилась, и ее деятельность сталкивается с трудностями. Однако для стабилизации своей рабочей силы компания А. Компания не увольняла сотрудников, но провела масштабное сокращение зарплат менеджеров. Стратегия сокращения, принятая компанией А, — ____. А. Переход к стратегии Б. Отказ от стратегии C. Стратегии сокращения расходов и концентрации D. Стратегия стабильности Ответ: С
... # Примеры вопросов 3, 4, 5
Среди следующих позиций тот, который не может повысить основную конкурентоспособность предприятия, — это ____. А. Дифференциация продукта B. Приобретение патентных прав на продукцию C. Инновационная технология производства D. Наймите аутсорсеров для производства Отвечать:
После прохождения предыдущего примера модель может знать, что буква параметра должна выводиться после «Ответ:».
Таким образом, мы получаем распределение вероятностей (логиты) первого токена после продолжения модели:
И вынимаем вероятности четырех букв «A B C D» и нормализуем их через softmax:
probs = (
torch.nn.functional.softmax(
torch.tensor(
[
logits[self.tokenizer.encode(
"A", bos=False, eos=False)[0]],
logits[self.tokenizer.encode(
"B", bos=False, eos=False)[0]],
logits[self.tokenizer.encode(
"C", bos=False, eos=False)[0]],
logits[self.tokenizer.encode(
"D", bos=False, eos=False)[0]],
]
),
dim=0,
).detach().cpu().numpy()
)
pred = {0: "A", 1: "B", 2: "C", 3: "D"}[np.argmax(probs)] # Выведите наиболее вероятный из вариантов в виде Модельиз Отвечать.
C-Eval таким образом измерил эффективность многих моделей знаний китайского языка.
Поскольку это вопрос с 4 вариантами ответов, базовая (случайно выбранная) точность составляет 25%.
C-Eval еще раз доказал, насколько мощна GPT-4 как модель знаний:
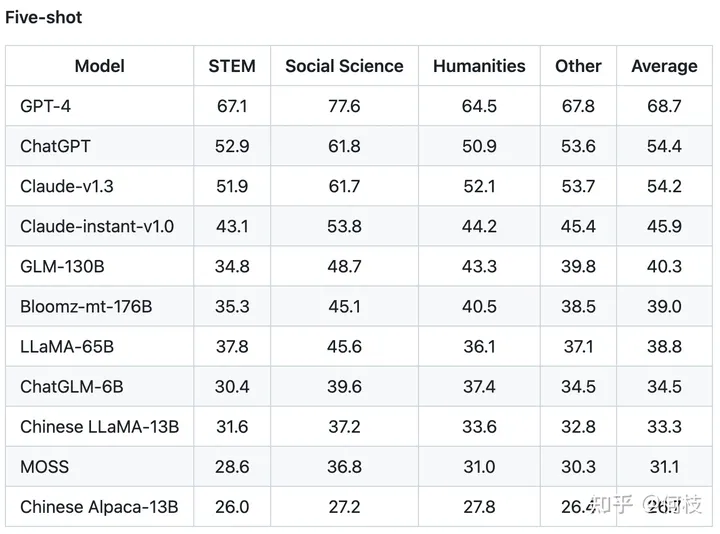
Рейтинг каждой модели до 5 выстрелов
2. Этап настройки инструкций
После завершения первого этапа предобучения можно приступать к этапу доводки инструкций.
Поскольку суть предтренировочного задания заключается в «продолжении письма», метод «продолжения письма» может не дать хорошего ответа на вопросы пользователя.
Например:

Поскольку большая часть обучения проводится на основе данных в Интернете, мы не можем гарантировать, что в данных присутствует только стандартизированный формат «один вопрос и один ответ».
Это приводит к тому, что предварительно обученная модель часто не может напрямую дать ответы, которые хотят люди.
Однако это не означает, что предварительно обученная модель «невежественна», это просто требует от нас использования некоторых умных «методов» для получения ответа:

Однако этот метод, который требует от пользователя тщательного проектирования для «задания» ответа, очевидно, не так уж элегантен.
Поскольку модель знает эти знания, но они не соответствуют нашим привычкам человеческого общения, нам нужно только научить модель «как говорить».
Это то, что делает настройка инструкций, выравнивание инструкций.
OpenAI показывает разницу между GPT-3 и моделью до и после тонкой настройки инструкций в [instruction-following]:

GPT-3 просто выполняет задачу продолжения, а InstructGPT может ответить на правильный контент.
2.1 Self Instruction
Так как нам нужно «научить модель говорить человеческим языком»,
Затем нам нужно внимательно написать разнообразные вопросы, которые люди могут задать в беседе, а также ответы на вопросы.
В [InstructGPT Paper] 1,3 Вт данных используется для контролируемого обучения на GPT-3.5 (левые данные SFT на рисунке ниже):
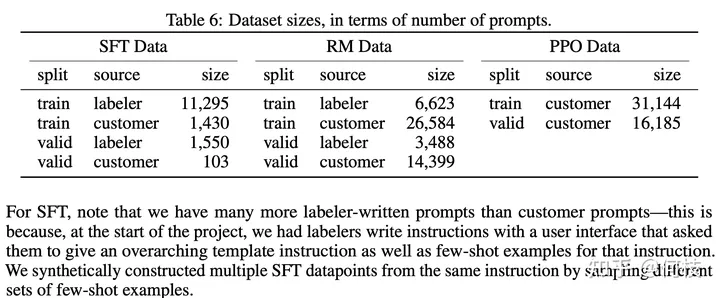
Предварительный просмотр набора обучающих данных InstructGPT Paper
Можно заметить, что маркировка вручную (маркировщик) составляет большую часть набора данных.
Это всего лишь InstructGPT, и это далеко не тот уровень, что ChatGPT.
Неофициальные новости: ChatGPT использует миллионы данных для точной настройки инструкций.
Видно, что использование ручного аннотирования требует огромных затрат. Недостаточно найти людей. Необходимо найти «профессиональную» и «последовательную» команду аннотаторов.
Было бы сложно сделать это с нуля (OpenAI действительно мощный инструмент), но сегодня у нас уже есть ChatGPT,
Было бы здорово, если бы мы позволили ChatGPT обучать наши собственные модели, не правда ли?
В этом и заключается идея самообучения, которое заключается в дистилляции вашей собственной модели посредством ввода и вывода ChatGPT.
Очень известный проект — [stanford_alpaca].
Если мы «задаем» данные из ChatGPT, то нам нужно «задавать» хоть какие данные.
«Ввод» (вопрос) и «выход» (ответ) в настройке инструкций являются ключом к обучению модели.
Ответ легко получить. Вы можете получить его, задав вопросы ChatGPT и основываясь на полученных результатах.
Но откуда взялся «вопрос»?
(Слишком утомительно полагаться на то, что люди будут думать. Вы можете попробовать это перед экраном и посмотреть, сколько ценных вопросов вы сможете придумать за короткое время)
Альпака использует «начальную команду (seed)», чтобы ChatGPT мог генерировать как «вопросы», так и «ответы».
Поскольку Alpaca — английский проект, для простоты понимания мы используем в качестве примера китайский проект [BELLE] с той же идеей.
С точки зрения непрофессионала, это означает искусственное предоставление некоторых «образцов обучающих данных» для просмотра ChatGPT.
Затем используйте функцию продолжения ChatGPT для непрерывного получения новых наборов обучающих данных:
Вас просят предоставить 10 разнообразных инструкций по выполнению миссий. Эти инструкции по задачам будут предоставлены модели GPT, и мы оценим способность модели GPT выполнить инструкции. Вот требования, необходимые для предоставления инструкций: 1. Старайтесь не повторять глаголы в каждой команде и максимально разнообразьте команды. 2. Тон используемых инструкций также должен быть разнообразным. Например, сочетайте вопросы с повелительными предложениями. 3. Тип обучения должен быть разнообразным, включающим различные типы заданий, категории: мозговой штурм, открытые QA,closed QA,rewrite,extract,generation,classification,chat,summarization。 4. Языковая модель GPT должна обеспечивать выполнение этих инструкций. Например, не просите помощника создать какой-либо визуальный или аудиовыход. Например, не просите помощника разбудить вас в 5 часов вечера или установить напоминание, потому что он ничего не сможет сделать. Например, инструкции не должны быть связаны с аудио, видео, изображениями и ссылками, поскольку модель GPT не может выполнить эту операцию. 5. Инструкции должны быть написаны на китайском языке. Инструкции должны состоять из 1-2 предложений. Допускаются повелительные предложения или вопросы. 6. Вам следует сгенерировать соответствующие входные данные для команды. Поле ввода должно содержать конкретные примеры, предусмотренные для команды. Оно должно относиться к реальным данным и не должно содержать простых заполнителей. Входные данные должны содержать существенное содержание, чтобы усложнить инструкцию. 7. Не все команды нужно вводить. Например,Когда команда запрашивает некоторую информацию здравого смысла,Например: «Какая самая высокая гора в мире?»,Никакого конкретного контекста не требуется. существуют В этом случае,Нам просто нужносуществовать Поместите в поле ввода“<Нет ввода>”。Когда ввод должен предоставить некоторый текстовый материал(Напримерстатья,ссылка на статью),Приведите несколько примеров непосредственно во входной части существования. Когда для ввода требуется аудио, изображения, видео или ссылки,не соответствует требованиямизинструкция。 8. Выходные данные должны представлять собой соответствующие реакции на инструкции и вводимые данные. Ниже приведен список из 10 инструкций по выполнению задач:
### 1. Инструкция: Как ответить на этот вопрос на собеседовании? 1. Информация: О чем вы думаете, когда находитесь одни в машине? 1. Вывод: Если это вечер, я обычно думаю о прогрессе, которого я добился сегодня, а если это утро, я думаю о том, как приложить все усилия. Я также стараюсь практиковать благодарность и быть в настоящем моменте, чтобы не отвлекаться за рулем. ### 2. Инструкция: Оцените эти страны по численности населения. 2. Ввод: Бразилия, Китай, США, Япония, Канада, Австралия. 2. Выход: Китай, США, Бразилия, Япония, Канада, Австралия. ### 3. Инструкции:
Как показано в приведенном выше примере, мы сначала приводим 2 примера и позволяем ChatGPT продолжить запись:
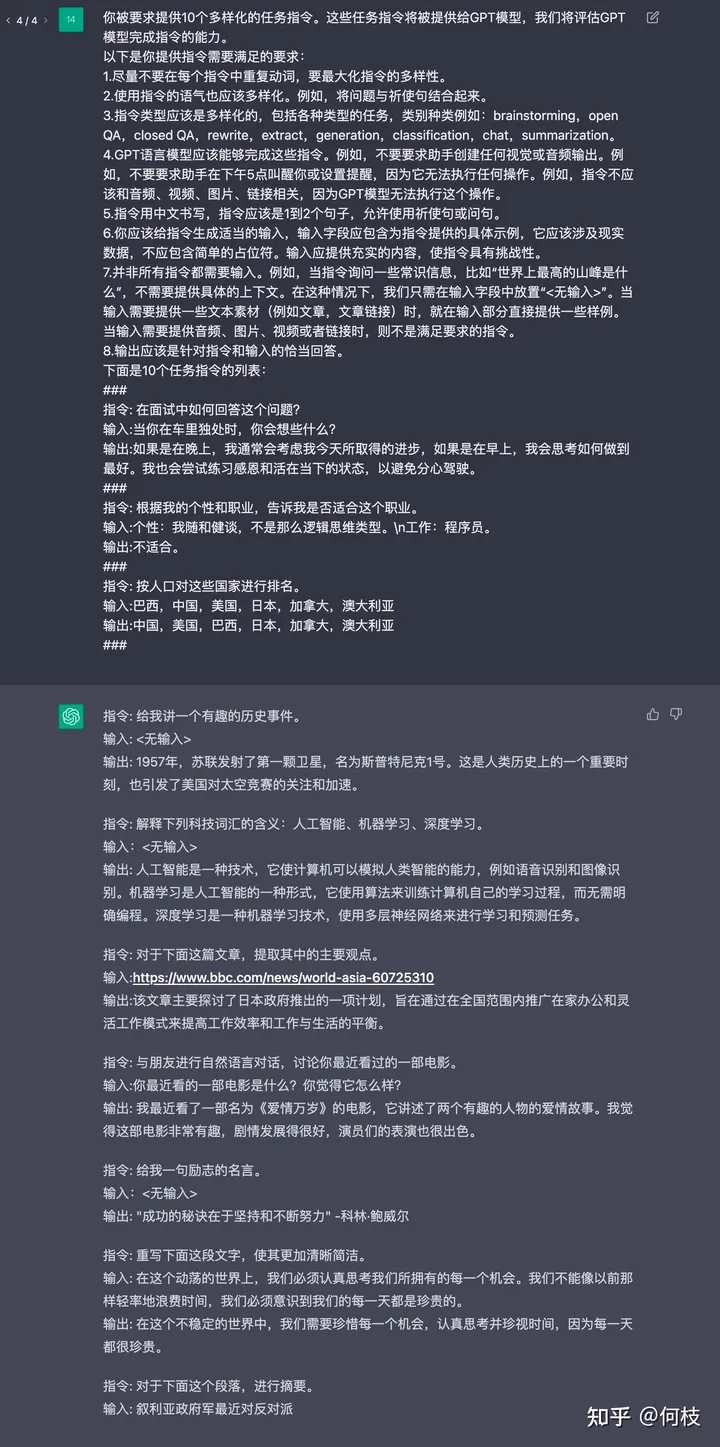
ChatGPT продолжает писать результаты
о BELLE из Более Подробную информацию см.Эта статья[3]
2.2 Организация наборов данных с открытым исходным кодом
В этой главе мы разберем некоторые наборы данных по настройке инструкций с открытым исходным кодом.
Помимо их прямого использования, мы надеемся научиться создавать набор данных инструкций, анализируя эти существующие наборы данных.
Alpaca
[stanford_alpaca] использовал упомянутый выше метод самообучения для сбора набора данных для обучения из 5200 инструкций.
Пример данных выглядит следующим образом:
{
"instruction": "Arrange the words in the given sentence to form a grammatically correct sentence.",
"input": "quickly the brown fox jumped",
"output": "The quick brown fox jumped quickly."
}
Среди них инструкция представляет собой задачу, требуемую от модели, ввод представляет собой ввод пользователя, а вывод представляет собой метку, переданную в модель.
Альпака охватывает несколько типов инструкций, и ее данные распределяются следующим образом:
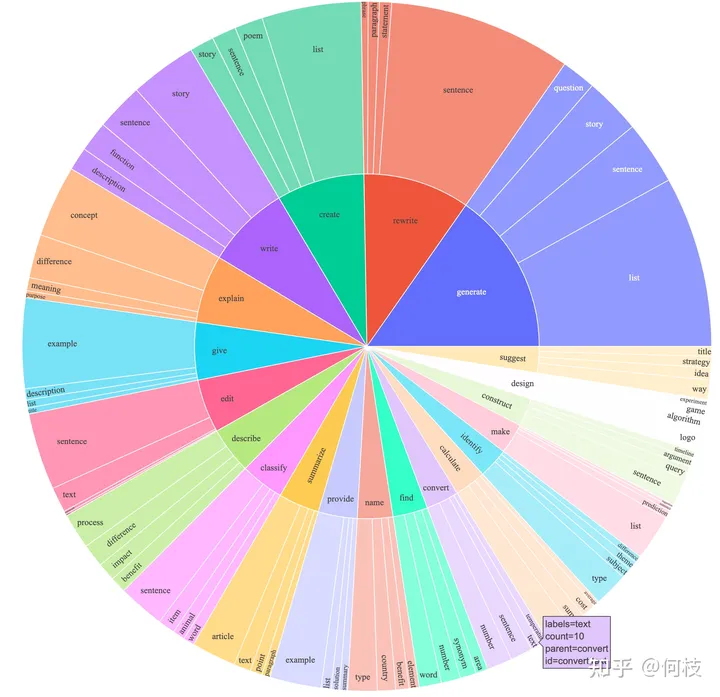
Диаграмма распределения данных об альпаке
Содержит набор различных типов задач, таких как написание, описание, классификация, обобщение и т. д.
BELLE
BELLE открыла наборы данных нескольких размеров: [1 миллион], [2 миллиона], [3,5 миллиона] и т. д.
Примерный набор обучающих данных выглядит следующим образом:
{
"instruction": «Определите, соответствует ли данная статья грамматическим правилам. Если нет, дайте предложения по ее изменению. Вот начало статьи: «Чтобы изучить эту тему, в этой статье будет представлен ряд примеров данных, подтверждающих эту точку зрения. '",
"input": "",
"output": «Начало индивидуального слова следует грамматическим правилам».
}
Из-за большого объема данных мы не можем рассчитать истинную долю каждой задачи в наборе обучающих данных.
Однако из распределения данных [набора из 1000 оценок] можно сделать вывод, что набор обучающих данных также включает в себя: сводку, вопросы и ответы, классификацию и другие задачи.
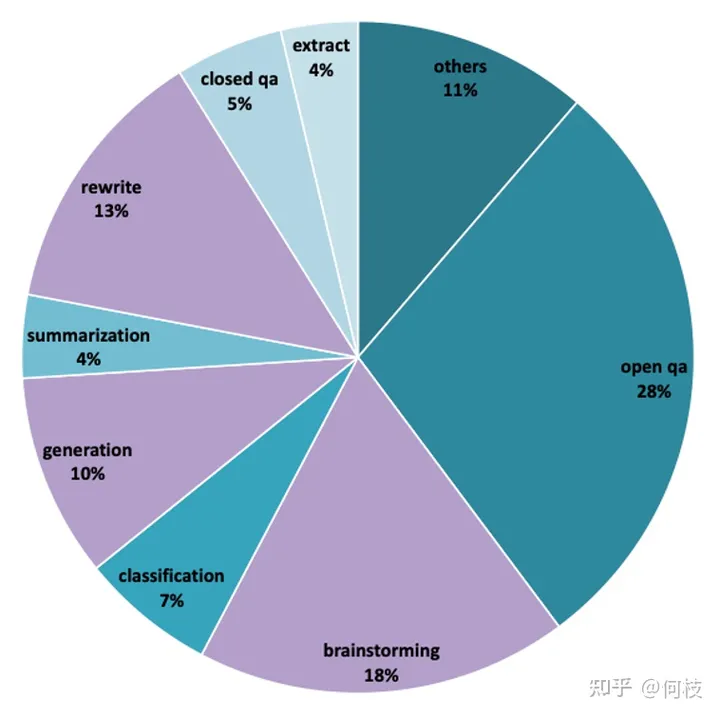
BELLE – Распространение оценочного набора
Мы отсортировали данные оценки по категориям и получили следующие результаты:
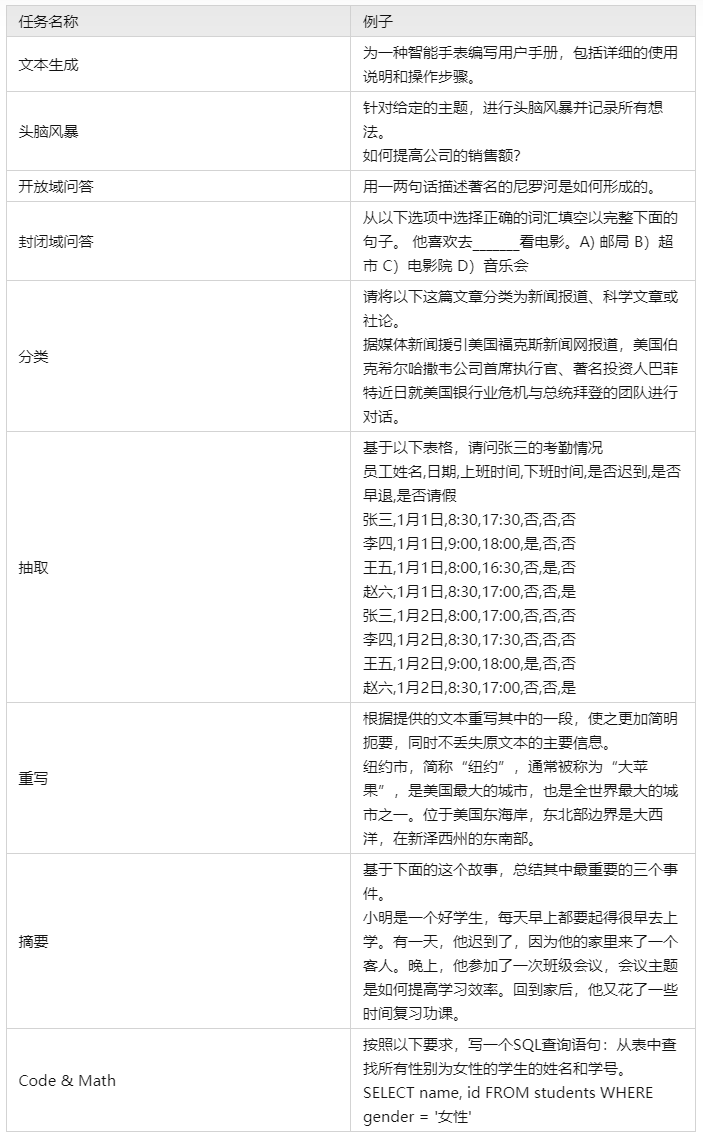
2.3 Метод оценки модели
По сравнению с относительно четкими индикаторами оценки (такими как PPL, NLL и т. д.) в ссылке «Предварительное обучение» (Pretrain),
Индикаторы оценки в ссылке «Инструкция» довольно неприятны.
Учитывая скорость разработки моделей генерации языков, такие метрики, как BLEU и ROUGH, больше не являются объективными.
Популярный способ — использовать GPT-4 для оценки результатов, сгенерированных моделью, как в [FastChat].
Мы также попытались использовать одну и ту же подсказку для тестирования трех моделей с открытым исходным кодом: OpenLlama, ChatGLM и BELLE.
Примечание: Ниже из Результаты испытанийтолько от нас самихизэксперимент,Не имеет никаких полномочий。
На каждый вопрос мы сначала получаем ответ от ChatGPT, а затем ответы от трех других моделей.
Затем мы передаем пару «Ответ ChatGPT — ответ модели-кандидата» в GPT-4 для оценки (из 10 баллов).
Полученный результат следующий:
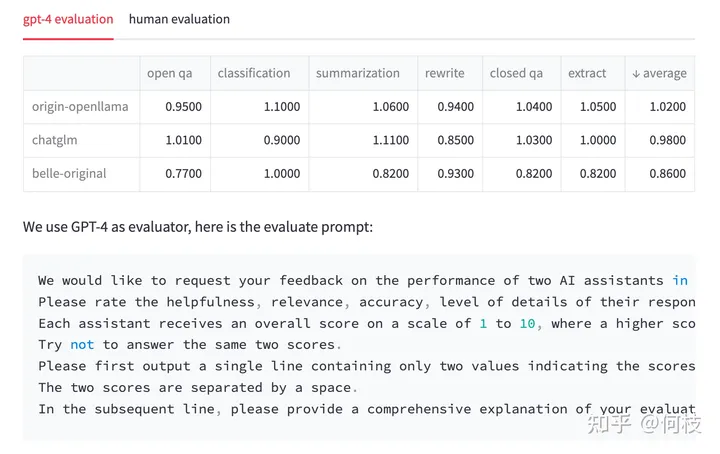
Результаты испытаний & тест prompt
Мы подсчитали каждую задачу индивидуально и нашли среднее значение в последнем столбце.
GPT-4 Будет ли верно каждый тестовый образец из 2 Оцените каждый ответ отдельно и укажите причины выставления баллов:
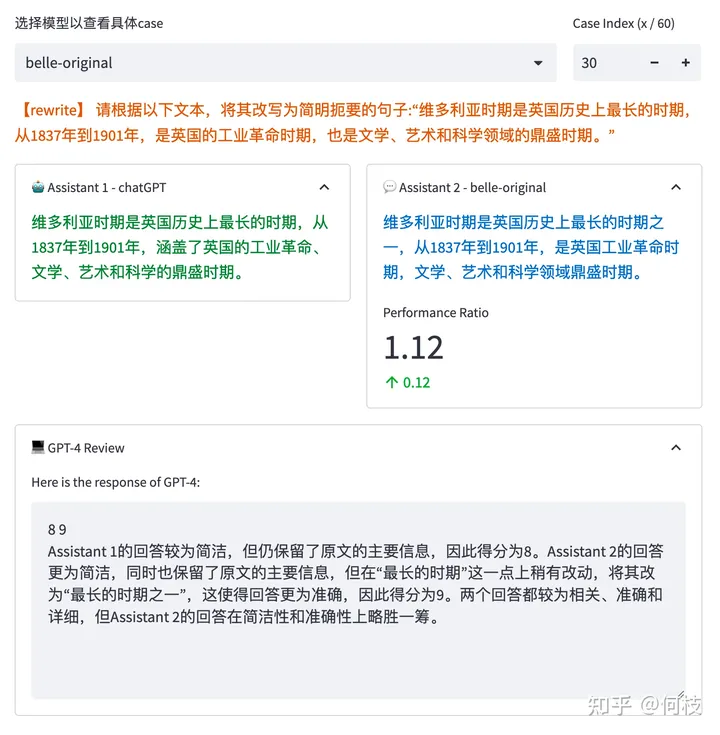
Результаты GPT-ревью
Однако мы обнаружили, что GPT-4 типиз ФракцияиаргументироватьНе обязательно правильно。
Как показано на рисунке выше, GPT-4 дает более высокий балл ответу модели справа. Причины следующие:
Правильнее было бы заменить «самый длинный период» на «один из самых длинных периодов».
Но на самом деле «максимальный срок» четко прописан в Инструкции.
Эта причина «ставить высокие оценки» на самом деле неверна.
Кроме того, мы также обнаружили, что простое изменение порядка предложений повлияет на окончательные результаты оценки.
Чтобы решить эту проблему, мы рассмотрим «замену порядка предложений и суммирование среднего», чтобы облегчить ее.
Но несмотря ни на что, оценки, полученные GPT-4, могут быть не такими надежными, как мы думаем.
С этой целью мы проверили каждый ответ вручную. Получены следующие результаты и стандарты:
Еще раз: мы просто хотим отметить, что оценка GPT-4 на самом деле может вызывать отклонения.,здесь Рейтинг Не имеет никаких полномочий。
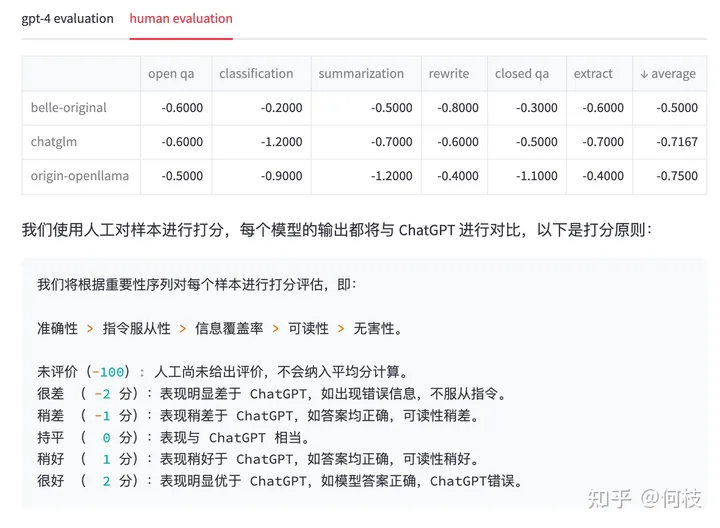
Искусственный Review результат & Принципы подсчета очков
Мы можем видеть,
существовать GPT-4 Рейтинг изрезультатсередина, уже имеющего Модельиз, эффект даже превысил ChatGPT (оценка 1.02),
Но снова фильм Художественный Review После этого ChatGPT Ответ заключается в том, что мы считаем более разумным.
Конечно, в последнее время появилось много новых методов оценки, таких как: [PandaLM],
И множество влиятельных наборов оценок, таких как: [C-Eval], [open_llm_leaderboard] и т. д.
Возможно, мы обновим его в будущем.
Ссылки
[1]
[Навыки ускорения LLM] Мути-запрос Внимание и внимание с линейным смещением (исходный код прилагается): https://zhuanlan.zhihu.com/p/634236135
[2]
[Falcon Paper] Мы победили LLaMA, смыв данные! : https://zhuanlan.zhihu.com/p/637996787
[3]
Позвольте ChatGPT сгенерировать обучающие данные для обучения ChatGPT: https://zhuanlan.zhihu.com/p/618334308

Изучите Kimi Smart Assistant: как использовать сверхдлинный текст, чтобы открыть новую сферу эффективной обработки информации
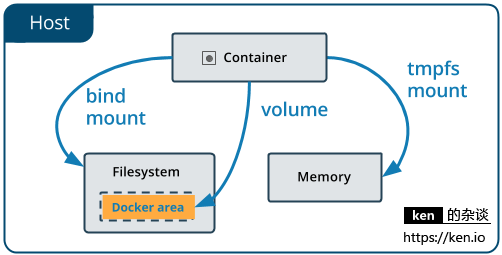
Начало работы с Docker: использование томов данных и монтирования файлов для хранения и совместного использования данных

Использование Python для реализации автоматической публикации статей в публичном аккаунте WeChat
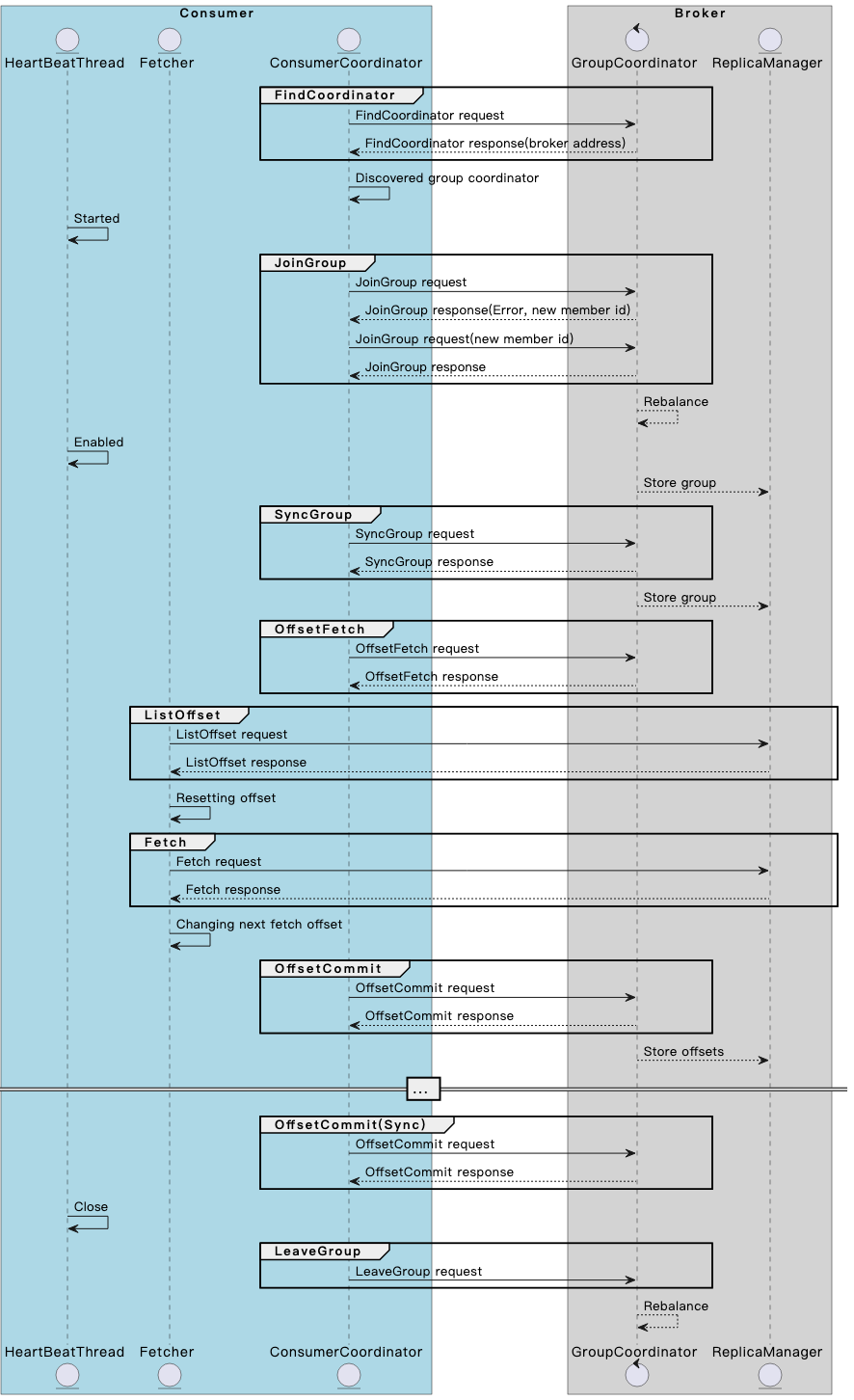
Разберитесь в механизме и принципах взаимодействия потребителя и брокера Kafka в одной статье.
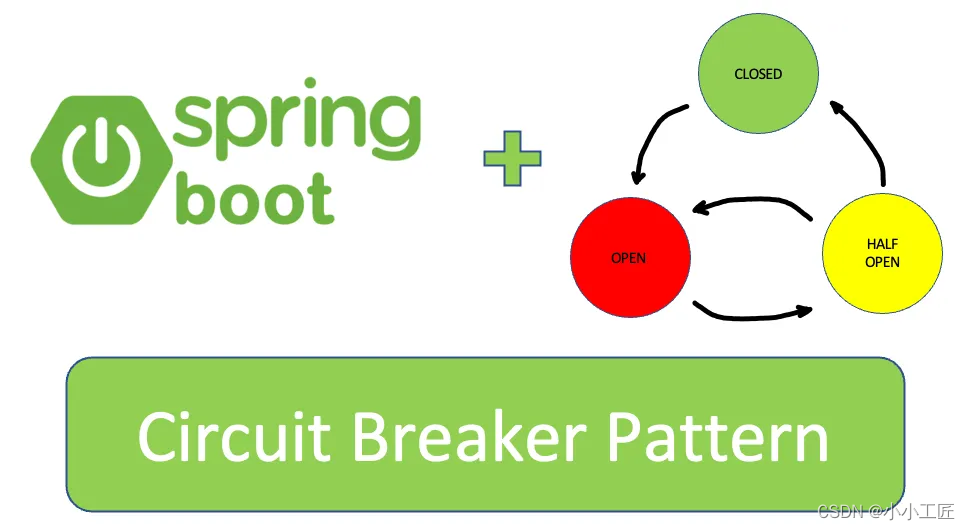
Spring Boot — использование Resilience4j-Circuitbreaker для реализации режима автоматического выключателя_предотвращения каскадных сбоев

13. Springboot интегрирует Protobuf

Примечание. Инструмент управления батареями Dell Dell Power Manager

Общая интерпретация класса LocalDate [java]
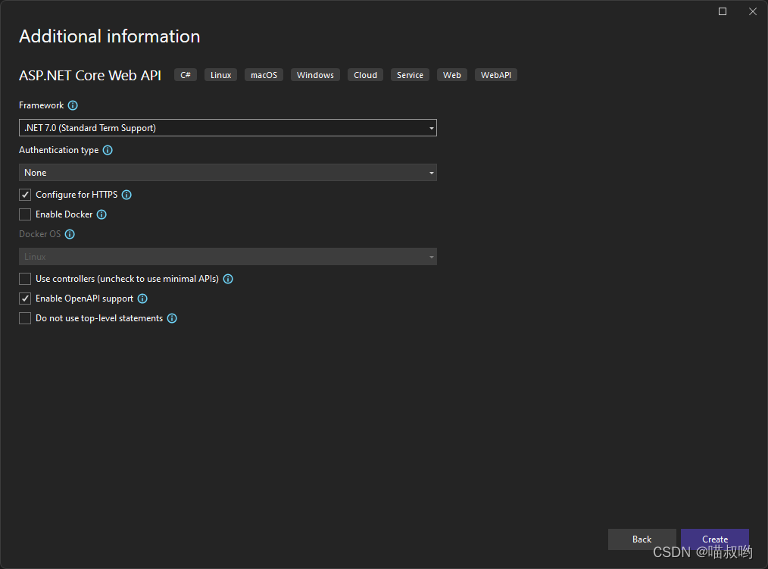
[Базовые знания ASP.NET Core] -- Веб-API -- Создание и настройка веб-API (1)
Настоящий бой! Подключите Passkey к своему веб-сайту для безопасного входа в систему без пароля.

Руководство по настройке Nginx: как найти, интерпретировать и оптимизировать настройки Nginx в Linux

Typecho отображает использование памяти сервера

Как вставить элемент перед указанным ключом в ассоциативный массив в PHP

swagger2 экспортирует API как текстовый документ (реализация Java) [легко понять]

Выбор фреймворка nodejs Express koa egg MidwayJS сравнение NestJS

Руководство по загрузке, установке и использованию SVN «Рекомендуемая коллекция»

Интерфейс PHPforwarding_php отправляет запрос на получение

Создавайте и защищайте связь в реальном времени с помощью SignalR и Azure Active Directory.

ВичатПубличная платформаразвивать(три)——ВичатQR-кодгенерировать&Сканировать кодсосредоточиться на
[Углубленное понимание Java IO] Используйте InputStreamReader для чтения содержимого файла и легкого выполнения задач преобразования текста.

сравнение строк PHP
9 сценариев асинхронного сбоя @Async

Эффективная обработка запланированных задач: углубленное изучение секретов библиотеки APScheduler на Python

Рекомендации по облегченному артефакту развязки внутренних компонентов Spring Event (событие Spring)
Go: Лесоруб-лесоруб на колесах Введение

Основы серверной разработки: технология кэширования, которую должен освоить каждый программист

Java Advanced Collections TreeSet: что это такое и зачем его использовать?
Оказывается, у команды go build столько знаний

Node.js