Опыт применения HBase в крупномасштабных наборах данных
Сценарии применения HBase в крупномасштабных наборах данных
HBase подходит для следующих сценариев обработки крупномасштабных наборов данных:
Сценарии применения | Подробное описание |
|---|---|
Анализ журналов в реальном времени | HBase может хранить и анализировать миллионы записей журнала каждый день, поддерживая запросы и анализ в реальном времени. |
Хранение данных социальных сетей | HBase может хранить большие объемы данных о взаимодействии с пользователем и быстро отвечать на запросы пользователей. |
Хранение данных временных рядов | HBase особенно подходит для хранения данных датчиков или данных мониторинга с отметкой времени, поддерживая быстрый поиск. |
Обработка геопространственных данных | HBase может хранить и обрабатывать крупномасштабные геопространственные данные и подходит для картографических сервисов или служб определения местоположения. |
Обработка данных рекомендательной системы | В системе рекомендаций HBase может хранить данные о поведении пользователей и поддерживать персонализированные рекомендации в режиме реального времени. |
Общим для этих Сценариев применения является то, что,Большой размер данных,Частые требования к записи и запросам,Конструкция HBase вполне может удовлетворить эти потребности.
Проектирование модели данных HBase
Модель данных HBase отличается от традиционных реляционных баз данных. Ее конструкция более гибкая. Метод хранения на основе семейств столбцов позволяет эффективно хранить полуструктурированные или неструктурированные данные. При применении крупномасштабных наборов данных особенно важно рациональное проектирование моделей данных.
- модель данныхпринципы проектирования
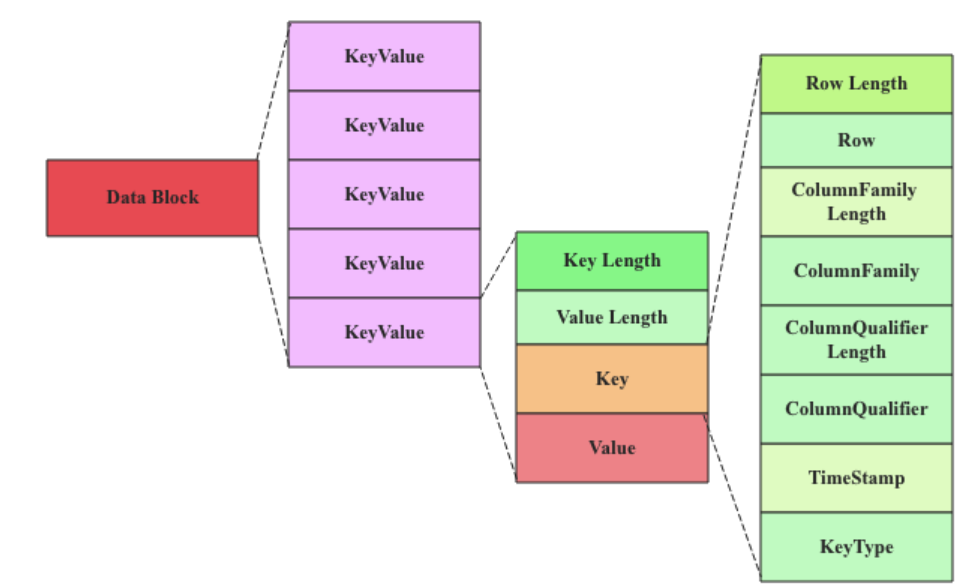
принципы проектирования | Подробное описание |
|---|---|
избегайте жарких мест | При разработке RowKey избегайте концентрации большого объема данных на определенных конкретных ключах, что может привести к снижению производительности. |
Будьте осторожны при проектировании семейств колонн. | Каждое семейство столбцов будет храниться в виде отдельного файла, поэтому при проектировании семейства столбцов необходимо учитывать баланс между чтением и хранением. |
Предварительно зонированный дизайн | Для таблиц с очень большим объемом ожидаемых данных проектирование разделов можно выполнить заранее, чтобы избежать перегрузки RegionServer. |
Настройки срока жизни | Для данных, чувствительных ко времени, вы можете установить TTL (время жизни) для автоматического удаления данных с истекшим сроком действия. |
Сжатие и контроль версий | Вы можете настроить стратегии сжатия данных для семейств столбцов и контролировать количество версий, чтобы уменьшить использование пространства хранения. |
- Анализ случая
Взяв в качестве примера данные о поведении пользователей в социальной сети, мы создаем таблицу для хранения лайков, комментариев, репостов и других действий пользователя:
- имя таблицы:
user_activity - кланы:
interaction - Список:
like、comment、share - RowKey:пользовательIDи комбинация временных меток поведения,Формат:
userID_timestamp
в этом дизайне,RowKey гарантирует, что поведенческие данные хранятся в хронологическом порядке.,Проблемы с горячей зоной исключены. в то же время,кланыinteractionИспользуется для хранения различных типов поведения пользователя.。
Масштабная оптимизация записи данных для HBase
В приложениях с крупномасштабными наборами данных производительность записи напрямую влияет на общую эффективность системы. Чтобы улучшить производительность записи HBase, вы можете оптимизировать ее по следующим аспектам.
- Пакетная запись
HBaseподдерживать Пакетная запись данных, что может снизить нагрузку на сетевой ввод-вывод и повысить эффективность записи. Пакетная записьможет пройтиHBaseКлиентput(List<Put>)Реализация метода。
- Журнал упреждающей записи (WAL)
В пути записи HBase каждая операция записи сначала записывается в журнал WAL (журнал упреждающей записи), чтобы обеспечить надежность данных. Но в некоторых случаях, например при обработке временных данных, вы можете отключить журнал WAL, чтобы повысить скорость записи.
- Установите разумный размер MemStore
MemStore в HBase — это пространство памяти, используемое для кэширования записанных данных. Когда MemStore достигает определенного порога, данные сбрасываются на диск. Установив соответствующий размер MemStore, можно сократить частые операции очистки, тем самым повысив производительность записи.
- пример кода:Пакетная запись огромных данных
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
import java.util.ArrayList;
import java.util.List;
public class HBaseBatchWriteExample {
public static void main(String[] args) throws Exception {
// Создать конфигурацию HBase
Configuration config = HBaseConfiguration.create();
// Установить соединение
try (Connection connection = ConnectionFactory.createConnection(config)) {
// Получить таблицу
Table table = connection.getTable(TableName.valueOf("user_activity"));
// Пакетная записьданные List<Put> puts = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
Put put = new Put(Bytes.toBytes("user_" + i + "_" + System.currentTimeMillis()));
put.addColumn(Bytes.toBytes("interaction"), Bytes.toBytes("like"),Bytes.toBytes("1"));
puts.add(put);
}
// представлять на рассмотрение Пакетная запись
table.put(puts);
System.out.println("Batch write completed.");
}
}
}В приведенном выше коде мы передаем Пакетную записьспособHBaseповерхностьuser_activityнаписано в1000Данные о поведении пользователя:
- Подключиться к HBase:Пройди первым
ConnectionFactory.createConnection(config)Создать сHBaseсвязь。 - Создать объект размещения:Для каждого действия пользователя мы создаем
Putобъект,И RowKey и кланы указаны. - Пакетная запись:Конвертировать несколькоPutобъектвставить
putsСписокповерхностьсередина,тогда пройдиtable.put(puts)выполнить Пакетная запись。
Этот метод может эффективно повысить эффективность записи, особенно при обработке крупномасштабных данных.
Масштабная оптимизация чтения данных HBase
Сценарии на крупномасштабных наборах данных применениясередина,Производительность чтения также имеет решающее значение. HBase предоставляет различные стратегии оптимизации чтения.,Повысить эффективность запросов к крупномасштабным наборам данных.
- Используйте фильтры
HBase поддерживает различные фильтры, такие как фильтрация диапазона RowKey, фильтрация столбца и т. д., которые могут эффективно сократить ненужную передачу данных и тем самым повысить эффективность запросов.
- Кэш BlockCache
HBase использует механизм BlockCache для кэширования часто используемых блоков данных в памяти, чтобы сократить операции дискового ввода-вывода. Правильная настройка размера BlockCache позволяет значительно повысить производительность чтения.
- Предварительно разделенное чтение
Когда масштаб данных велик, данные можно распределить по нескольким регионам посредством предварительного секционирования, чтобы повысить производительность одновременного чтения.
- пример кода:Используйте фильтры запроса данных
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.filter.BinaryPrefixComparator;
import org.apache.hadoop.hbase.filter.CompareFilter;
import org.apache.hadoop.hbase.filter.RowFilter;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseFilterReadExample {
public static void main(String[] args) throws Exception {
// Создать конфигурацию HBase
Configuration config = HBase
Configuration.create();
// Установить соединение
try (Connection connection = ConnectionFactory.createConnection(config)) {
// Получить таблицу
Table table = connection.getTable(TableName.valueOf("user_activity"));
// Установить объекты проверки
Scan scan = new Scan();
// Настройки строкового фильтр, соответствующий префиксу RowKey — «user_100»
RowFilter filter = new RowFilter(CompareFilter.CompareOp.EQUAL,
new BinaryPrefixComparator(Bytes.toBytes("user_100")));
scan.setFilter(filter);
// Получить результаты сканирования
ResultScanner scanner = table.getScanner(scan);
// Обход и вывод результатов
scanner.forEach(result -> {
String rowKey = Bytes.toString(result.getRow());
String like = Bytes.toString(result.getValue(Bytes.toBytes("interaction"), Bytes.toBytes("like")));
System.out.println("RowKey: " + rowKey + ", Like: " + like);
});
// Закрыть сканер
scanner.close();
}
}
}В приведенном выше коде,Мы использовали функцию фильтра HBase,проходитьRowFilterОтфильтровать"user_100"Данные о поведении пользователей в начале:
- Фильтр строкового фильтра:проходить
RowFilterиBinaryPrefixComparator,Мы реализовали фильтрацию запросов на основе префикса RowKey. - Сканировать объект:
Scanобъект Используется для установки области запроса.ифильтр,финальныйпроходитьtable.getScanner(scan)Получите результаты。
Этот метод может эффективно повысить производительность при запросе крупномасштабных наборов данных и снизить нагрузку на передачу данных.
Масштабируемость HBase в крупномасштабных наборах данных
- динамическое расширение
HBase — это хорошо масштабируемая система, которая может динамически расширять RegionServer в соответствии с ростом объема данных. Когда масштаб данных увеличивается, возможности обработки можно улучшить, добавив узлы RegionServer.
- Автоматическое сегментирование данных
HBase распределяет данные по разным серверам региона с помощью механизма автоматического сегментирования (разделения регионов). По мере увеличения объема данных HBase автоматически разделит данные на новые регионы для поддержания эффективной работы системы.
- Горизонтальное расширение
HBase использует архитектуру Master-Slave, а узлы RegionServer можно расширять горизонтально, что означает, что система может добавлять серверы в соответствии с фактическим объемом данных для достижения эффективного хранения и обработки данных.
HBase продемонстрировал свою высокую масштабируемость и эффективную производительность чтения и записи при работе с крупномасштабными наборами данных. Правильно разрабатывая модели данных, оптимизируя производительность записи и чтения и используя распределенную архитектуру HBase, предприятия могут легко справиться с потребностями в хранении и обработке больших объемов данных.
Опыт применения | Подробное описание |
|---|---|
Правильно проектируйте модели данных | проходитьизбегайте жарких мест、кланы Дизайн、Такие принципы, как предварительное разделение,Повышение производительности хранения и запросов к крупномасштабным данным. |
Пакетная запись повышает производительность записи | Повышение эффективности записи за счет пакетной записи, оптимизации WAL, размера MemStore и других стратегий. |
Используйте фильтры для оптимизации производительности запросов | Повысьте эффективность запросов к крупномасштабным наборам данных с помощью таких механизмов, как фильтры RowKey и BlockCache. |
Динамическое расширение и горизонтальное расширение | HBase имеет возможность динамического и горизонтального расширения, а также может адаптироваться к постоянному росту объема данных. |



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
