Оптимизация затрат на хранение данных временных рядов Elasticsearch
В этой статье мы представим основные улучшения Elasticsearch в хранении данных временных рядов и предоставим ожидаемую производительность в отношении эффективности хранения.
фон
Elasticsearch недавно вложил значительные средства в хранение и запрос данных временных рядов, уделяя особое внимание повышению эффективности хранения. Благодаря усилиям нескольких проектов экономия хранилища может достигать 60–80 % по сравнению со стандартными показателями. В некоторых сценариях эффективность хранения нашей системы может даже составлять менее одного байта на точку данных, конкурируя с современными специализированными системами баз данных временных рядов (TSDB). Давайте посмотрим на недавние улучшения в эффективности хранения данных временных рядов.
Улучшения хранения данных временных рядов Elasticsearch
синтетический источник (synthetic_source)
По умолчанию,Elasticsearchбудет оригинальнымJSONТело документа хранится в_sourceв поле。Такое хранилище дубликатов не подходит для метрик.,Поскольку метрики обычно проверяются с помощью агрегатных запросов,Это поле не будет использоваться. Чтобы решить эту проблему,Мы представилиsynthetic _source,При необходимости он реконструирует упрощенную версию исходного _source на основе данных, хранящихся в полях документа. Хотя поддерживаемые типы полей ограничены,и Synthesis_source медленнее,Однако эти ограничения мало влияют на наборы данных измерений, которые в основном полагаются на ключевые слова, числовые, логические поля и поля IP и используют агрегатные запросы. Мы работаем над снятием этих ограничений,Сделайте составные источники доступными для любого картографирования.
Размер индекса потоковой передачи данных временных рядов (TSDS) уменьшается на 40–60 % после включения синтетических источников. Поэтому, начиная с выпуска TSDS (v.8.7), синтетические источники включены по умолчанию.
Выделенный кодек
Широко используется система TSDBВыделенный кодек,Сократите количество байтов на точку данных за счет использования хронологического порядка записи показателей.。Наша система расширяет стандартКодек Lucene,поддерживатьКодирование длины пробега、delta-of-deltas(вторая производная)、наибольший общий делительиXORкодирование。кодек вLuceneОбозначение уровня сегмента,Таким образом, старые индексы могут использовать преимущества новейших кодеков при индексировании новых данных.
Чтобы повысить эффективность этих методов сжатия,Индекс по всемПоле измерения(По возрастанию)рассчитанныйидентификаторсортировать,Затем отсортируйте по временной метке (в порядке убывания). Таким образом, Поле измерения (в основном ключевое слово) можно найти с помощью Кодирование длины пробега Эффективное сжатие,Значения метрики группируются во временные ряды и сортируются по времени. Поскольку большинство временных рядов со временем меняются медленно,Встречаются лишь случайные пики,Elasticsearchполагаться наLuceneвертикальная перегородкадвигатель хранения,Этот подход минимизирует различия между последовательно хранящимися данными.,Повышенная эффективность хранения.
Удаление метаданных
_idполя — это поля метаданных, которые однозначно идентифицируют каждый документ.,Ограниченная ценность для измерительных приложений,Потому что анализ временных рядов основан на совокупных запросах, а не на изучении отдельных показателей. с этой целью,TSDS сокращает сохраненные значения, но сохраняет инвертированный индекс для поддержки запросов на поиск документов. Это приводит к сокращению объема хранилища на 10-20%.,Потеря функциональности отсутствует.
Интеграция жизненного цикла
TSDS можно интегрировать с механизмами управления жизненным циклом данных.,нравитьсяILMиЖизненный цикл потока данных。Эти инструменты автоматически удаляют старые индексы.,ILM также поддерживает перемещение индексов на более дешевые уровни хранения (например, использование механических жестких дисков или архивного облачного хранилища) для снижения затрат на хранение.,В то же время это не влияет на производительность запросов часто используемых метрик.,и с минимальным участием пользователя.
Понижение разрешения
Во многих измерительных приложениях,Желательно сохранять детальные данные за короткий период времени (например, поминутные данные за прошедшую неделю).,Для более старых данных вы можете увеличить степень детализации для экономии места (например, почасовые данные за последний месяц).,Ежедневные данные за последние два года)。Понижение разрешенияИспользование предварительно агрегированных показателейСтатистическое представлениеЗаменить исходные метрические данные。Это не только повышает эффективность хранения,Потому что индекс Понижения разрешения составляет лишь часть размера исходного метрического индекса.,Также улучшает производительность запросов,Потому что агрегатные запросы сканируют предварительно агрегированные результаты, а не вычисляют необработанные данные на лету.
Понижение разрешенияиILMиDSLинтегрированный,Автоматически применять Понижение разрешения и позволяет использовать различные разрешения по мере старения данных. разрешенияданные。
Результаты теста эффективности хранения данных TSDS
Доход от хранилища TSDS
мы проходим сквозь ночьКонтрольный показательотслеживатьTSDSпроизводительность,включатьхранилищеиспользоватьиэффективность。Трассировка TSDB(См. Визуализация использования диска.)показывает влияние наших улучшений хранилища。Следующий,Мы покажем использование хранилища до выпуска TSDS, улучшения после выпуска TSDS и текущий статус.
Трассировка TSDBизданныенабор(k8sмера)Есть девять Поле измерения,Каждый документ содержит в среднем 33 поля (меры и измерения). Индекс содержит измерения за один день,общий116,633,696 документов.
До ES 8.7 набор данных, индексирующий трассировки TSDB, требовал 56,9 ГБ хранилища. Использование хранилища с разбивкой по полям метаданных, полям меток времени, полям измерений и полям мер выглядит следующим образом:
Имя поля | процент |
|---|---|
_id | 5.1% |
_seq_no | 1.4% |
_source | 78.0% |
@timestamp | 1.31% |
Поле измерения | 2.4% |
поле измерения | 5.1% |
Другие поля | 9.8% |
_sourceЮаньданные Поляхранилищезаниматьиз最大贡献者。тольконравиться前面提到из,Синтетические источники — одно из усовершенствований, введенных в нашу измерительную работу для повышения эффективности хранения. Это отражено в выпуске ES 8.7, в котором синтетические источники используются в качестве конфигурации по умолчанию для TSDS. в этом случае,Использование хранилища упало до 6,5 ГБ,Осуществленный8,75 разПовышенная эффективность хранения。Разбить по типу полянравиться Вниз:
Имя поля | процент |
|---|---|
_id | 18.7% |
_seq_no | 14.1% |
@timestamp | 12.6% |
Поле измерения | 3.6% |
поле измерения | 12.0% |
Другие поля | 50.4% |
Это улучшение достигается за счет отказа от хранения поля _source и последовательного хранения показателей для одного и того же временного ряда посредством сортировки индексов, что повышает эффективность стандартного кодека Lucene.
Используйте ES Индекс версии 8.13.4 Трассировка TSDBизданныенаборзанимать4.5GBхранилище,дальнейшее улучшение44%。Разбить по типу полянравиться Вниз:
Имя поля | процент |
|---|---|
_id | 12.2% |
_seq_no | 20.6% |
@timestamp | 14.0% |
Поле измерения | 1.6% |
поле измерения | 6.7% |
Другие поля | 58.6% |
Это значительное улучшение,По сравнению с версией 8.7.0,Основным фактором, способствующим этому, является уменьшение объема памяти, занимаемого полем _id (его хранимое значение сокращается).,и Поле измеренияидругойчисловое значение Поля сжимаются более эффективно благодаря новейшим кодекам временных рядов.。
Большая часть хранилища теперь принадлежит «Другие поля», т.е. предоставляет поля контекста, аналогичные измерениям, но не используется для вычисления идентификатора для сортировки индекса, поэтому его сжатие не так эффективно, как Поле. измерения。
Понижение разрешенияхранилищедоход
Понижение Разрешение жертвует разрешением запросов ради увеличения объема хранилища, в зависимости от Понижения разрешенияинтервал。верно Трассировка Набор данных TSDB (показатели собираются каждые 10 секунд) с интервалом в 1 минуту Понижение разрешения,Результирующий размер индекса составляет 748 МБ.,улучшенный6 раз。Недостатком являетсямера Предварительная агрегация по минутной детализации,Поэтому невозможно проверять отдельные записи показателей или агрегировать их с интервалом меньше минуты (например, каждые 5 секунд). Однако,Результаты агрегирования предварительно вычисленной статистики (минимум, максимум, сумма, количество, среднее) такие же, как и рассчитанные на исходных данных.,поэтому Понижение Разрешение не влияет на точность.
Если более низкое разрешение приемлемо,Причем измерение производится с часовыми интервалами. Понижение разрешения,Полученный индекс Понижения разрешения будет занимать всего 56 МБ памяти. Следует отметить, что,Это улучшение13,3 раза,Это в 60 раз ниже ожидаемого. Это связано с тем, что все индексы должны хранить дополнительные метаданные для каждого сегмента.,Это постоянные накладные расходы,Становится более заметным по мере уменьшения размера индекса.
Подвести итог
На графике ниже показано изменение эффективности хранения данных в разных версиях.,А также дополнительная экономия, которую предлагает Понижение разрешения. пожалуйста, обрати внимание,Вертикальная ось находится в логарифмическом масштабе.
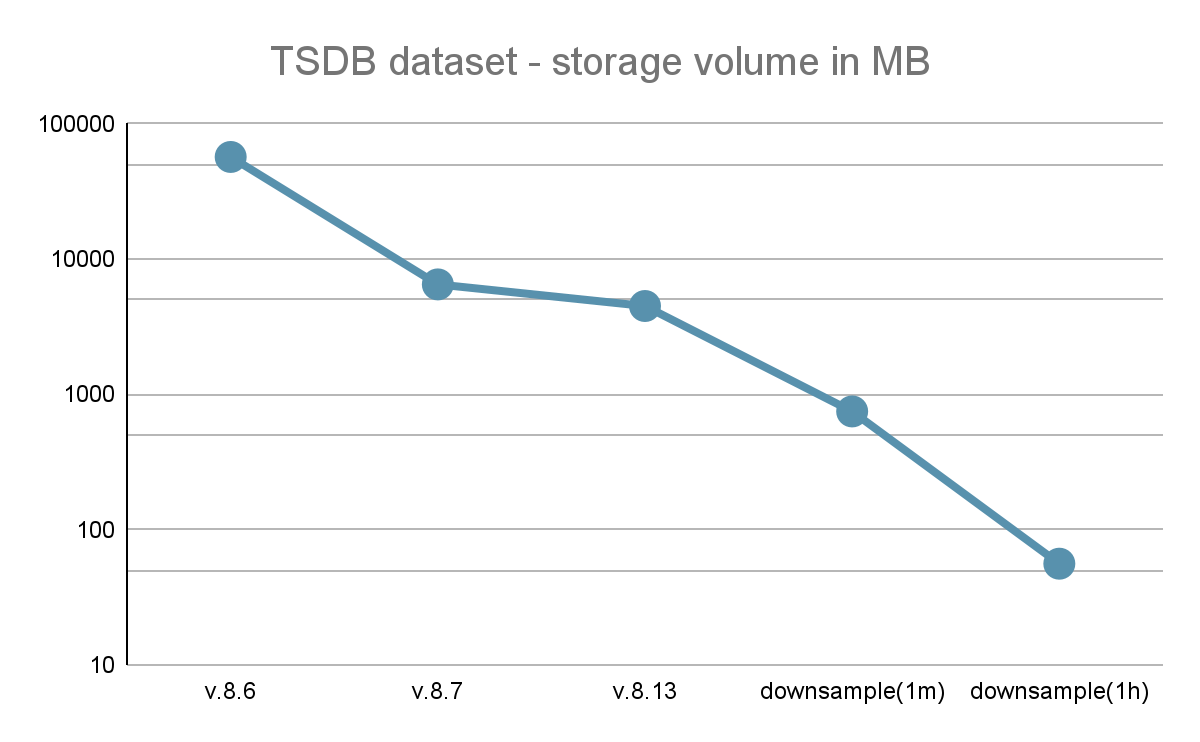
общий,过去из版本使我们измера服务изхранилищеэффективность提高了12,5 раз。нравитьсяпрошедший Понижение разрешенияуменьшитьхранилищезанимать,Вот этотчисловое значениеможет быть достигнуто1000 разили выше。
Рекомендации по настройке TSDS
В этом разделе мы рассмотрим лучшие практики настройки TSDS для повышения эффективности хранения.
Каждый документ содержит несколько показателей
Хотя Elasticsearch использует вертикальное секционирование для хранения каждого поля отдельно, поля по-прежнему логически группируются внутри документов. Поскольку меры имеют общие измерения, включение как можно большего количества мер в каждый индексный документ позволяет лучше амортизировать накладные расходы на хранение измерений и метаданных. Напротив, хранение только одной метрики и связанных с ней измерений для каждого документа максимизирует накладные расходы на измерения и метаданные, что приводит к раздуванию хранилища.
Конкретно,Мы количественно оцениваем влияние количества показателей, содержащихся в каждом документе, с использованием синтетического набора данных. Когда мы включаем все меры (20) в каждый индексируемый документ,TSDSизхранилищеиспользовать量仅为0,9 байта на точку данных,Близка к производительности современных специализированных метрических систем (0,7 байта на точку данных). Напротив,Когда для каждого индексированного документа имеется только одна метрика,TSDSнуждаться20 байт на точку данных,Использование хранилища значительно увеличивается. поэтому,Имеет смысл объединить как можно больше показателей в каждом индексированном документе и использовать одни и те же значения измерений.
Обрезать ненужные размеры
Архитектура Elasticsearch позволяет нашему сервису метрик иметь управляемые затраты на производительность, когда количество временных рядов на одну метрику (т. е. произведение кардинальности измерения) достигает миллионов или более, что значительно превышает показатели конкурирующих систем. Однако размеры занимают значительное пространство, а высокая мощность снизит эффективность нашей техники сжатия TSDS. Поэтому важно тщательно продумать, какие поля включить в индексный документ метрик, и активно сократить его до минимального набора измерений, необходимого для создания информационных панелей и устранения неполадок.
Интересным примером была карта наблюдаемости, содержащая поле IP, которое, как выяснилось, содержало до 16 IP-адресов (IPv4, IPv6), что серьезно влияло на объем хранилища и пропускную способность индексации, хотя практически не использовалось. Замена его машинными тегами привела к значительному улучшению хранилища без потери возможности отладки.
Используйте управление жизненным циклом
ILMстарые могут быть、不常访问изданные移动到更便宜изхранилище Параметры,иILMиЖизненный цикл потока данныхможет быть обработан с помощьюданныестарениеиудалитьмераданные。Этот полностью автоматизированный подход снижаетхранилищерасходы,Нет необходимости менять сопоставление или конфигурацию индекса.,Поэтому очень рекомендуется.
также,Стоит рассмотреть возможность решения проблемы старения данных путем Понижения разрешения в обмен на хранилище. Эта технология позволяет существенно сэкономить место для хранения данных.,Это также делает приборную панель более отзывчивой.,До тех пор, пока приемлемо снижение разрешения для старых данных – обычное явление в практических приложениях.,Потому что мало кто изучает данные, полученные несколько месяцев назад, с точностью до минуты.
Следующий шаг
за последние несколько лет,Мы добились значительных улучшений в измерении занимаемой площади хранилища. Мы намерены применить эти оптимизации к типам данных, отличным от показателей.,Особенно данные журналов. Хотя некоторые функции специфичны для метрик,нравиться Понижение разрешения, но мы по-прежнему хотим добиться сокращения объема хранилища в 2–4 раза за счет конфигурации индекса для конкретного журнала.
Несмотря на сокращение накладных расходов на хранение полей метаданных, необходимых для всех индексов Elasticsearch.,Мы планируем сократить эти поля более агрессивно. Хорошими полями-кандидатами являются _id и _seq_no. также,Существует также возможность применять более продвинутые методы индексации для временных меток и других полей, поддерживающих запросы диапазона.,нравитьсяразреженный индекс。
Понижение Механизм разрешения имеет большой потенциал для повышения производительности запросов, если допустимо небольшое увеличение объема памяти. Одна из идей — поддержать несколько Понижений. Разрешение разрешения (например, необработанные данные, ежечасно и ежедневно). В случае перекрытия периодов времени механизм запросов автоматически выбирает наиболее подходящее разрешение для каждого запроса. Это позволит пользователям указывать Понижение на основе шкалы времени панели мониторинга. разрешения, делая его более отзывчивым и запуская Понижение в течение нескольких минут после индексации. разрешение. Его также можно разблокировать, чтобы сохранить исходные данные и Понижение. разрешение данных, возможно, с использованием более медленного/дешевого уровня хранения.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
