Оптимизация производительности Apache Spark: устранение перетасовки для эффективной обработки данных
Apache Spark произвел революцию в обработке больших данных благодаря своим возможностям распределенных вычислений. Однако на производительность Spark может повлиять распространенная проблема, называемая «перетасовка». В этой статье мы рассмотрим, что такое перемешивание, его причины, проблемы, связанные с ним, а также эффективные решения для оптимизации производительности Apache Spark.
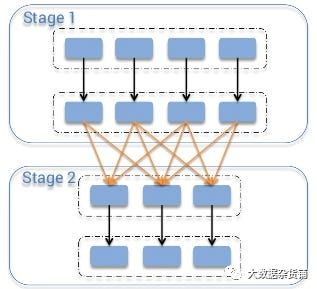
Иллюстрация: операция перемешивания
1. Понимание перемешивания
Под перемешиванием понимается процесс перераспределения данных по разделам в Apache Spark. Это побочный эффект обширных преобразований, таких как операции группировки, различения, упорядочения и объединения. Во время перераспределения данные обмениваются и реорганизуются по сети, чтобы гарантировать группировку записей с одинаковым ключом.
2. Причины перетасовки
Перетасовка в первую очередь вызвана операциями, требующими реорганизации данных по разделам. Широкая трансформация предполагает агрегацию или объединение данных из нескольких разделов, что требует перемещения и реорганизации данных по кластеру. Например, операции соединения требуют сопоставления и объединения данных из разных наборов данных, что приводит к значительному перемешиванию.
3. Проблемы, связанные с перемешиванием
Shuffle может вызвать несколько проблем с производительностью, которые влияют на эффективность и скорость заданий Spark:
- Увеличение сетевого ввода-вывода. Операции перемешивания включают обмен и передачу данных по сети, что приводит к увеличению накладных расходов на сетевой ввод-вывод (I/O). Увеличение объема данных в случайном порядке приводит к перегрузке сетевых ресурсов, что приводит к замедлению времени выполнения и снижению общей пропускной способности.
- Ресурсоемкость: Shuffle требует дополнительных вычислительных ресурсов, включая процессор, память и дисковый ввод-вывод. Повышенное использование ресурсов во время тасования может привести к конкуренции за ресурсы, увеличению времени выполнения заданий и снижению эффективности.
4. Решения, позволяющие избежать перетасовки
Чтобы оптимизировать производительность Apache Spark и смягчить влияние перемешивания, можно использовать несколько стратегий:
- Уменьшите сеть Ввод-вывод: используя меньшее количество и более крупных рабочих узлов, его можно уменьшить перемешивание сети во время объема ввода-вывода. Узлы большего размера позволяют обрабатывать больше данных локально, сводя к минимуму необходимость передачи данных по сети. Этот подход может повысить производительность за счет уменьшения задержек, связанных с сетевой связью.
- Уменьшите количество столбцов и отфильтруйте строки. Уменьшение количества перетасовываемых столбцов и фильтрация ненужных строк перед перетасовкой могут значительно сократить объем передаваемых данных. Устраняя ненужные данные на ранних стадиях конвейера, вы минимизируете влияние перестановок и повышаете общую производительность.
- Использовать широковещательное хэш-соединение. Широковещательное хэш-соединение — это метод, который передает меньший набор данных операции соединения всем рабочим узлам.,Тем самым уменьшая необходимость в перемешивании. Этот подход использует копирование в памяти и устраняет нагрузку на сеть, связанную с перетасовкой.,Тем самым улучшая производительность соединения.
- Используйте технологию сегментирования. Бактинг — это технология, которая организует данные в сегменты на основе хеш-функций. Предварительно разбивая и сохраняя данные в сегментах, Spark избавляет от необходимости перемешать. Эта технология оптимизации уменьшает перемещение данных между разделами, тем самым сокращая время выполнения.
5. Заключение
Перетасовка (процесс перераспределения данных по разделам) — распространенная проблема с производительностью в Apache Spark. Это может привести к увеличению количества операций ввода-вывода в сети, конкуренции за ресурсы и замедлению выполнения заданий. Однако влияние тасования можно смягчить, используя такие стратегии, как сокращение сетевого ввода-вывода, сокращение столбцов и фильтрация строк для минимизации размера данных, использование широковещательных хеш-соединений и использование методов группирования. Эти методы оптимизации повышают производительность Apache Spark, обеспечивая эффективную обработку данных и более быстрый анализ. Раскройте весь потенциал Apache Spark, решая проблемы, связанные с перемешиванием, и оптимизируя конвейеры обработки данных.
Автор оригинала: VivekR



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
