Оптимизация передачи больших данных при фронтенд-разработке: практические советы по улучшению производительности API-интерфейса
Прежде чем начать статью, я хотел бы порекомендовать несколько хороших статей, написанных другими! Если вам интересно, вы также можете прочитать это!
Сегодняшняя рекомендация: разделение дел | Схема двоичного шифрования при передаче больших данных
Ссылка на статью:https://cloud.tencent.com/developer/article/2465951
Статья под названием Me Ah Qi начинается с базовой концепции шифрования данных и подробно знакомит с типами алгоритмов шифрования (симметричное шифрование, асимметричное шифрование, алгоритм хэширования и т. д.), предоставляя читателям всестороннюю теоретическую базу. Это четко структурированное, поэтапное объяснение помогает читателям быстро понять основные принципы технологии шифрования.
С наступлением эры больших данных,Все больше и больше интерфейсных приложений нуждаются в обработке огромных объемов данных, полученных с серверов. Для приложений, в которых интерфейс API возвращает большой объем данных.,Как обеспечить эффективную передачу данных, снизить влияние на производительность внешнего интерфейса и улучшить взаимодействие с пользователем,стала большой проблемой во фронтенд-разработке. Эта статья будет с точки зрения фронтенд-разработки.,Поделитесь, как оптимизировать интерфейсы API для передачи больших объемов данных.,В том числе Пейджинг данных, Ленивая загрузка, сжатая передача и другие технические средства.,И подробно объясните на примерах кода.
Проблемы передачи больших объемов данных
В традиционных интерфейсных приложениях интерфейсы API обычно возвращают большой объем данных. Особенно при выполнении анализа данных, создании отчетов и других сценариях часто необходимо загружать большой объем информации одновременно. Передача такого большого объема данных столкнется со следующими проблемами:
- Узкое место в производительности:Когда интерфейсный браузер получает и отображает большие объемы данных,Могут возникать задержки страницы,Влияет на пользовательский опыт.
- Давление на полосу пропускания сети:Когда объем передаваемых данных слишком велик,Пропускная способность сети может легко стать узким местом,Вызывает задержку ответа на запросы интерфейса.
- Использование памяти слишком велико:Загрузка слишком большого количества данных потребляет память браузера,Это может даже привести к сбою браузера.
Чтобы справиться с этими проблемами, при разработке внешнего интерфейса необходимо принять соответствующие технические стратегии и оптимизировать процесс загрузки данных.
Часто используемые методы оптимизации
Пейджинг данных
Пейджинг данных — классическое решение для передачи больших объемов данных.,Разделив данные на небольшие части,Загружайте только часть за раз,Избегайте загрузки слишком большого количества данных одновременно.
1.1 Идеи реализации пейджинга
Передавая параметры номера страницы и количества элементов на странице, сервер возвращает данные пакетами, а внешний интерфейс динамически запрашивает данные с разных страниц в соответствии с потребностями.
1.2 Пример кода: реализация пейджингового запроса
Предположим, у нас есть интерфейс API, который возвращает список, содержащий большой объем данных.,Параметры запроса для пейджинга:pageиsize,Каждый запрос возвращает 100 фрагментов данных.
// Данные запроса пейджинга
async function fetchPageData(page = 1, size = 100) {
const response = await fetch(`/api/data?page=${page}&size=${size}`);
const data = await response.json();
return data;
}
// Динамически загружать данные следующей страницы
let currentPage = 1;
const size = 100;
function loadMoreData() {
fetchPageData(currentPage, size).then(data => {
// визуализировать данные
renderData(data.items);
currentPage += 1; // Обновить номер текущей страницы
});
}Ленивая загрузка
Ленивая загрузка(Lazy Загрузка) — это метод загрузки по требованию. Запрос будет инициирован только тогда, когда пользователь прокручивает страницу до конца или ему необходимо отобразить определенную часть данных, что снижает ненужную передачу данных.
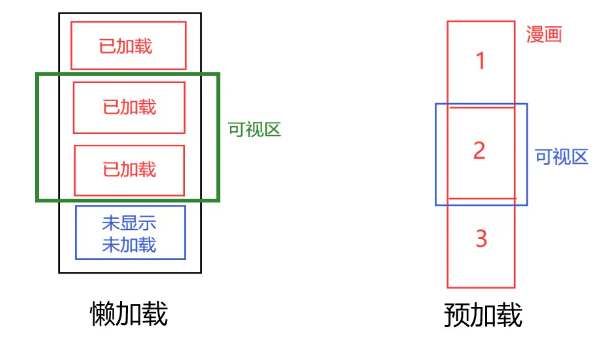
2.1 Идеи реализации Ленивой загрузки
Прослушивая событие прокрутки, оценивается, близко ли оно к нижней части страницы. Если оно близко, инициируется новый запрос API для загрузки данных.
2.2 Пример кода: Ленивая загрузкавыполнить
// Прослушайте событие прокрутки, чтобы определить, близко ли оно к низу.
window.addEventListener('scroll', () => {
if (window.innerHeight + window.scrollY >= document.body.offsetHeight - 100) {
loadMoreData(); // Загрузить больше данных, когда они близки к дну
}
});
// Данные начальной загрузки
loadMoreData();Сжатие данных
Размер данных во время передачи напрямую влияет на время загрузки и потребление полосы пропускания. Использование Сжатия данных может эффективно уменьшить объем данных, возвращаемых API, и повысить эффективность загрузки.
3.1 Идеи реализации Сжатие данных
Данные могут быть сжаты на стороне сервера,Затем распакуйте данные на внешнем интерфейсе для использования.。Общие методы сжатия включают в себяJSONсжатие(Например черезgzipилиbrotli)。
3.2 Пример кода: Сжатие данныхиметь дело с
Предположим, что данные, возвращаемые сервером, имеют формат JSON.,использоватьgzipсжатиепередача инфекции,Интерфейс передает заголовок ответаContent-EncodingОпределите, нужна ли декомпрессия。
// Проверьте, нужно ли распаковать ответ
async function fetchCompressedData(url) {
const response = await fetch(url);
if (response.headers.get('Content-Encoding') === 'gzip') {
const buffer = await response.arrayBuffer();
const decompressedData = pako.ungzip(new Uint8Array(buffer), { to: 'string' });
return JSON.parse(decompressedData);
}
return await response.json();
}Серверная push и WebSocket
Для некоторых приложений с высокими требованиями к работе в режиме реального времени, таких как котировки акций, мгновенный чат и т. д., интерфейсная часть может использовать WebSocket для передачи данных, чтобы избежать частых запросов на опрос.
4.1 Идеи реализации WebSocket
Протокол WebSocket позволяет устанавливать постоянное соединение между клиентом и сервером, а сервер может активно передавать данные клиенту, уменьшая нагрузку, связанную с частыми запросами.
4.2 Пример кода: передача данных через WebSocket
// Установить соединение WebSocket
const socket = new WebSocket('ws://example.com/data');
// Прослушивать сообщения, отправленные сервером
socket.onmessage = function(event) {
const data = JSON.parse(event.data);
renderData(data);
};
// Отправить запрос
socket.send(JSON.stringify({ action: 'get_data' }));Решение для внешней реализации
Реализация пейджинговой связи
Решение с подкачкой — это наиболее распространенный метод оптимизации, который позволяет эффективно избежать проблем с производительностью, вызванных одновременной загрузкой больших объемов данных. При реализации внешнего интерфейса в сочетании с внутренним интерфейсом подкачки данные могут динамически загружаться и отображаться для улучшения взаимодействия с пользователем.
function fetchData(page = 1) {
fetch(`/api/data?page=${page}`)
.then(response => response.json())
.then(data => {
renderData(data.items);
});
}Ленивая загрузкавыполнить
Ленивая загрузка в основном прослушивает события прокрутки, чтобы определить, нужно ли пользователю загружать больше данных. Общие случаи использования включают списки с бесконечной прокруткой.
window.addEventListener('scroll', () => {
if (window.innerHeight + window.scrollY >= document.body.offsetHeight - 200) {
loadMoreData();
}
});Сжатие данныхиметь дело с
Чтобы сэкономить полосу пропускания и повысить скорость ответа, интерфейсная часть должна обрабатывать данные, возвращаемые с сервера, для операций распаковки.
// Распаковать с помощью pako
import pako from 'pako';
async function fetchCompressedData(url) {
const response = await fetch(url);
const buffer = await response.arrayBuffer();
const decompressedData = pako.ungzip(new Uint8Array(buffer), { to: 'string' });
return JSON.parse(decompressedData);
}Передовые методы оптимизации
В базовых методах оптимизации, таких как пейджинг, Ленивая загрузкаждать)снаружи,Есть также несколько более продвинутых решений по оптимизации.,Эти решения могут обеспечить большее повышение производительности в более сложных сценариях.,Подходит для крупномасштабных приложений и сценариев с высокочастотным обновлением данных.
Шардинг данных и параллельные запросы
Когда объем данных, возвращаемых интерфейсом API, очень велик, одиночный запрос может выполняться очень медленно или даже вызывать тайм-аут. В это время вы можете рассмотреть возможность фрагментации данных (chunking), разделения большого набора данных на несколько небольших запросов и их параллельной отправки для повышения эффективности загрузки.
5.1 Идеи реализации шард-запроса
С помощью сегментированных запросов внешний интерфейс может запрашивать несколько фрагментов данных параллельно во время одной загрузки, вместо того, чтобы загружать всю огромную коллекцию данных одновременно. Это позволяет полностью использовать пропускную способность сети и сократить время ответа на один запрос.
5.2 Пример кода: параллельные запросы и объединение данных
// Данные запроса сегмента, при условии, что каждый запрос возвращает 100 фрагментов данных.
async function fetchChunkedData(page = 1, size = 100, totalItems = 500) {
const totalPages = Math.ceil(totalItems / size);
const requests = [];
for (let i = 0; i < totalPages; i++) {
requests.push(fetch(`/api/data?page=${i + 1}&size=${size}`));
}
// Дождитесь завершения всех запросов
const responses = await Promise.all(requests);
// Анализ всех данных ответа
const data = await Promise.all(responses.map(response => response.json()));
// Объединить все данные с разбивкой на страницы
const allData = data.flatMap(pageData => pageData.items);
return allData;
}Добавив Пейджинг данныхи Параллельные запросыобъединить,Интерфейсная часть может получить несколько фрагментов данных за короткое время.,Уменьшите задержку одного запроса.
Оптимизировать формат передачи данных
Формат данных, возвращаемый интерфейсом API, также оказывает большое влияние на эффективность передачи. JSON в настоящее время является наиболее часто используемым форматом передачи данных.,Но при работе с большими объемами данных,Эффективность передачи JSON не оптимальна. Для оптимизации эффективности передачи,Разработчики могут рассмотреть возможность использования других форматов.,НапримерProtocol Buffers(Protobuf)илиMessagePackждать,Они более компактны и быстрее сериализуются и десериализуются, чем JSON.
6.1 Использование Protobuf для передачи данных
Protocol Buffersсделан изGoogleНезависимость от языка разработки、Платформонезависимый формат обмена данными,По сравнению с JSON,Он имеет меньший размер и более высокую скорость обработки при обработке больших данных. Чтобы использовать Protobuf,Как интерфейсная, так и серверная часть должны поддерживать кодеки Protobuf.
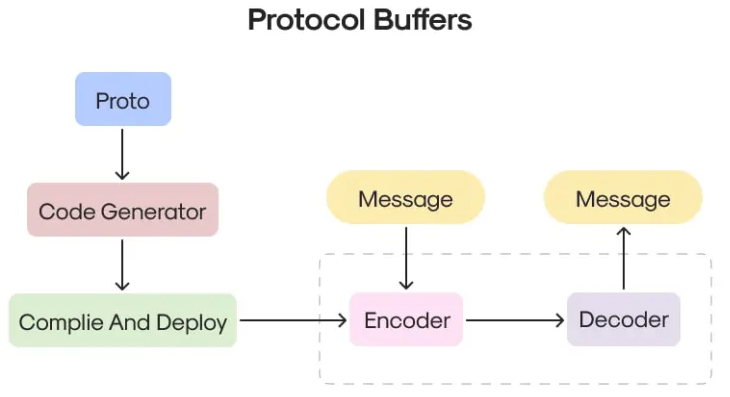
6.2 Пример кода: использование Protobuf во внешнем интерфейсе
// Предположим, что сервер возвращает данные в формате Protobuf.
async function fetchProtobufData(url) {
const response = await fetch(url);
const buffer = await response.arrayBuffer();
// Предположим, у нас есть файл определения сообщения protobuf.
const data = protobuf.decode(MyProtoMessage, new Uint8Array(buffer));
return data;
}В этом примере мы используем Protobuf для кодирования и декодирования данных, уменьшая размер данных и ускоряя передачу данных.
6.3 Использование MessagePack для передачи данных
MessagePackэто еще один эффективный формат двоичной сериализации.,Он может обеспечить целостность данных, в то время как,Значительно сжимает размер данных.
// Использование MessagePack для передачи данных
async function fetchMessagePackData(url) {
const response = await fetch(url);
const buffer = await response.arrayBuffer();
// Декодирование данных с помощью библиотеки MessagePack.
const data = msgpack.decode(new Uint8Array(buffer));
return data;
}По сравнению с JSON, MessagePack позволяет значительно уменьшить объем данных, что имеет очевидные преимущества, особенно когда необходимо передать большое количество повторяющихся полей или данных со сложной структурой.
Хранение и кэширование внешних данных
Для больших данных, которые необходимо часто загружать,Интерфейсная часть может рассмотреть возможность кэширования данных.,Избегайте повторных запросов данных. Современные браузеры предлагают множество вариантов хранения данных.,включатьlocalStorage、sessionStorage、IndexedDBждать,Эти решения для хранения данных могут помочь интерфейсной части снизить зависимость от интерфейсов API.
7.1 использоватьlocalStorageданные кэша
localStorageЭто решение для локального хранения данных, предоставляемое браузером.,Может использоваться для сохранения Хранить данные. Его недостатком является ограниченная емкость (обычно 5 МБ).,Подходит для хранения данных, которые обновляются реже.
// Проверьте, существует ли кеш
function loadDataFromCache() {
const cachedData = localStorage.getItem('apiData');
return cachedData ? JSON.parse(cachedData) : null;
}
// Если кеша нет, загружаем данные из API
async function loadData() {
const cachedData = loadDataFromCache();
if (cachedData) {
renderData(cachedData);
} else {
const data = await fetchDataFromAPI();
localStorage.setItem('apiData', JSON.stringify(data));
renderData(data);
}
}7.2 использоватьIndexedDBданные кэша
Для больших наборов данных,Можно считатьиспользоватьIndexedDB。Он поддерживает хранение больших объемов данных.,И поддерживает индексный запрос,Более гибкий.
// Использование IndexedDB для хранения данных
function saveDataToIndexedDB(data) {
const request = indexedDB.open('myDatabase', 1);
request.onupgradeneeded = (event) => {
const db = event.target.result;
db.createObjectStore('dataStore', { keyPath: 'id' });
};
request.onsuccess = (event) => {
const db = event.target.result;
const transaction = db.transaction('dataStore', 'readwrite');
const store = transaction.objectStore('dataStore');
data.forEach(item => store.put(item)); // Хранить данные
};
}
// Загрузить данные из IndexedDB
function loadDataFromIndexedDB() {
const request = indexedDB.open('myDatabase', 1);
return new Promise((resolve, reject) => {
request.onsuccess = (event) => {
const db = event.target.result;
const transaction = db.transaction('dataStore', 'readonly');
const store = transaction.objectStore('dataStore');
const allData = store.getAll();
allData.onsuccess = () => resolve(allData.result);
allData.onerror = reject;
};
request.onerror = reject;
});
}Оптимизация синхронизации данных между сервером и интерфейсом
Для некоторых приложений с высокими требованиями к работе в режиме реального времени,Интерфейсному интерфейсу необходимо не только эффективно запрашивать данные,Данные также необходимо эффективно синхронизировать.。Распространенным подходом является объединениеGraphQLили ВОЗRESTfulОпрос интерфейса,СотрудничатьWebSocketВыполнение дополнительных обновлений данных。
8.1 Использование GraphQL для дополнительных запросов данных
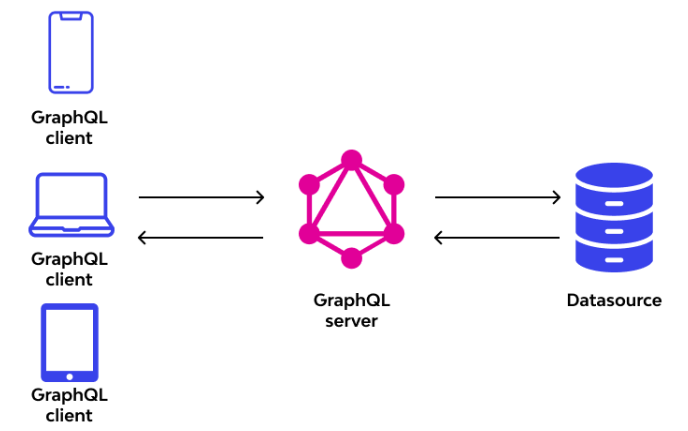
GraphQLэто новый язык запроса данных,Интерфейсный модуль может точно запрашивать необходимые данные.,Это позволяет избежать одновременной загрузки слишком большого количества избыточных данных в традиционных интерфейсах RESTful. Через GraphQL,Интерфейс может запрашивать определенные поля по запросу.,Уменьшите объем передаваемых данных.
// Запросить данные с помощью GraphQL
async function fetchGraphQLData(query) {
const response = await fetch('/graphql', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ query })
});
const { data } = await response.json();
return data;
}
// Пример запроса GraphQL
const query = `
query {
users {
id
name
email
}
}
`;
fetchGraphQLData(query).then(data => {
console.log(data.users);
});GraphQL поддерживает запросы по требованию, что особенно важно для приложений с большими объемами данных, чтобы избежать ненужной передачи данных.
Подвести итог
во фронтенд разработке,Поскольку объем данных продолжает увеличиваться,Как оптимизировать передачу больших данных через API-интерфейсы, стало ключом к повышению производительности приложений и удобства пользователей. В этой статье представлены различные распространенные решения по оптимизации.,включать Пагинация、Ленивая загрузка、Сжатие данные, параллельные запросы и т. д. предоставляют возможные решения для различных сценариев загрузки данных. В то же время в этой статье также обсуждаются некоторые более продвинутые методы оптимизации, такие как Шардинг. данных и параллельные запросы、Используйте более эффективные форматы данных (например, Protobuf и MessagePack).、Кэширование внешних данныхждать,Эти технологии могут значительно повысить производительность интерфейсных приложений.,Особенно при работе с большими объемами данных.
- Пагинация и Ленивая загрузка:Этоиметь дело с Два наиболее распространенных метода для больших объемов данных。Пагинация может эффективно уменьшить объем данных, запрашиваемых за раз.,Ленивая загрузка может загружать данные по требованию,Не загружайте слишком много контента одновременно. Благодаря этим двум технологиям,Интерфейсная часть может значительно снизить влияние загрузки данных на производительность.,Улучшите пользовательский опыт.
- Сжатие данных с оптимизированными форматами передачи:использовать
gzip、brotliждатьсжатиетехнология,объединитьProtocol BuffersилиMessagePackждать Эффективный формат данных,Может эффективно снизить потребление полосы пропускания при передаче данных,Улучшите скорость ответа. - Параллельные запросы и сегментирование данных:Для сценариев с большими данными,Использование параллельных запросов,Разделите данные на небольшие фрагменты и запрашивайте их одновременно,Может значительно сократить задержку одного запроса.,Повысьте эффективность загрузки данных.
- Хранение и кэширование внешних данных:Разумно используйте локальное хранилище, предоставляемое браузером.имеханизм кэширования,нравиться
localStorage、IndexedDB,Можно избежать повторного запроса одних и тех же данных.,Дальнейшее улучшение производительности приложений,Особенно, когда к одним и тем же данным обращаются часто. - Синхронизация данных в реальном времени с GraphQL:Для данных, которые необходимо обновлять в режиме реального времени,В сочетании с WebSocket, GraphQL и другими технологиями.,Может обеспечить синхронизацию данных в режиме реального времени,Уменьшите количество ненужных опросов и запросов,Улучшите отзывчивость приложений.
Благодаря этим техническим средствам интерфейсные разработчики могут более эффективно решать большие задачи по передаче данных, сокращать задержки при загрузке страниц и улучшать общий пользовательский опыт. В реальных приложениях разработчики могут выбирать подходящие технические решения на основе конкретных сценариев и гибко использовать различные методы оптимизации, чтобы приложения могли сохранять хорошую производительность при работе с большими объемами данных.
Поскольку интерфейсные технологии продолжают развиваться, в будущем появятся новые технологии и инструменты оптимизации. Разработчикам необходимо продолжать уделять внимание и повторять свои собственные решения по оптимизации, чтобы адаптироваться к меняющимся потребностям и задачам.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
